

Veröffentlicht: 30. Januar 2025
Viele WebAssembly-Anwendungen im Web profitieren genauso wie native Anwendungen von Multithreading. Mit mehreren Threads können mehr Aufgaben parallel ausgeführt werden und die Hauptarbeit wird vom Hauptthread weg verlagert, um Latenzprobleme zu vermeiden. Bis vor Kurzem gab es einige häufige Probleme mit solchen mehrstufigen Anwendungen im Zusammenhang mit Zuweisungen und E/A. Glücklicherweise können die neuesten Funktionen in Emscripten bei diesen Problemen sehr hilfreich sein. In diesem Leitfaden erfahren Sie, wie diese Funktionen in einigen Fällen zu einer Geschwindigkeitssteigerung von mehr als 10-fach führen können.
Skalierung
Die folgende Grafik zeigt die effiziente skalierte Ausführung mehrerer Threads bei einer reinen mathematischen Arbeitslast (aus dem Benchmark, den wir in diesem Artikel verwenden):
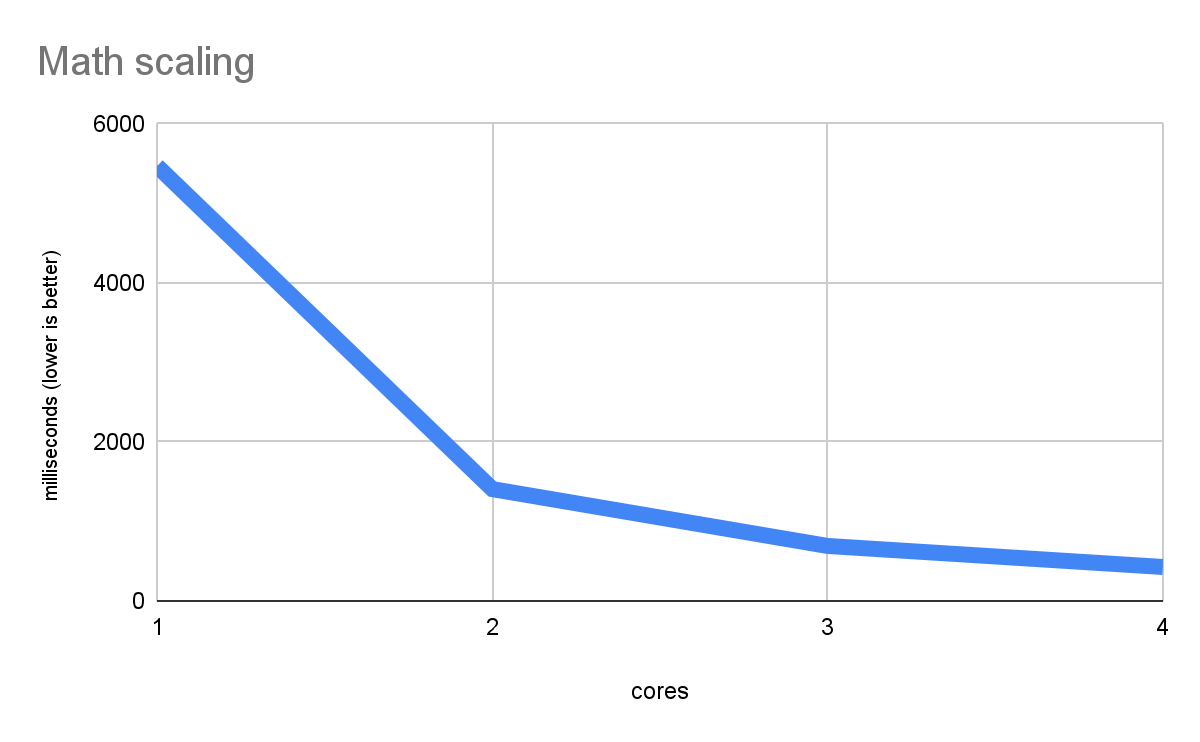
Dabei wird die reine Rechenleistung gemessen, die jeder CPU-Kern für sich allein erbringen kann. Die Leistung steigt also mit mehr Kernen. Eine solche absteigende Linie mit einer höheren Leistung ist genau das, was eine gute Skalierung ausmacht. Außerdem zeigt es, dass die Webplattform mehrstufigen nativen Code sehr gut ausführen kann, obwohl Webworker als Grundlage für Parallelität verwendet werden, Wasm anstelle von echtem nativem Code und andere Details, die weniger optimal erscheinen.
Heap-Verwaltung: malloc/free
malloc und free sind wichtige Standardbibliotheksfunktionen in allen Sprachen mit linearem Arbeitsspeicher (z. B. C, C++, Rust und Zig), die für die Verwaltung aller Speicherbereiche verwendet werden, die nicht vollständig statisch sind oder sich auf dem Stack befinden. Emscripten verwendet standardmäßig dlmalloc, eine kompakte, aber effiziente Implementierung. Es wird auch emmalloc unterstützt, das noch kompakter, aber in einigen Fällen langsamer ist. Die Leistung von dlmalloc in einem Mehrfach-Thread ist jedoch begrenzt, da für jede malloc/free eine Sperre erforderlich ist (da es nur einen globalen Allocator gibt). Daher kann es zu Konflikten und Verzögerungen kommen, wenn viele Threads gleichzeitig viele Zuweisungen vornehmen. Wenn Sie einen extrem malloc-intensiven Benchmark ausführen, passiert Folgendes:
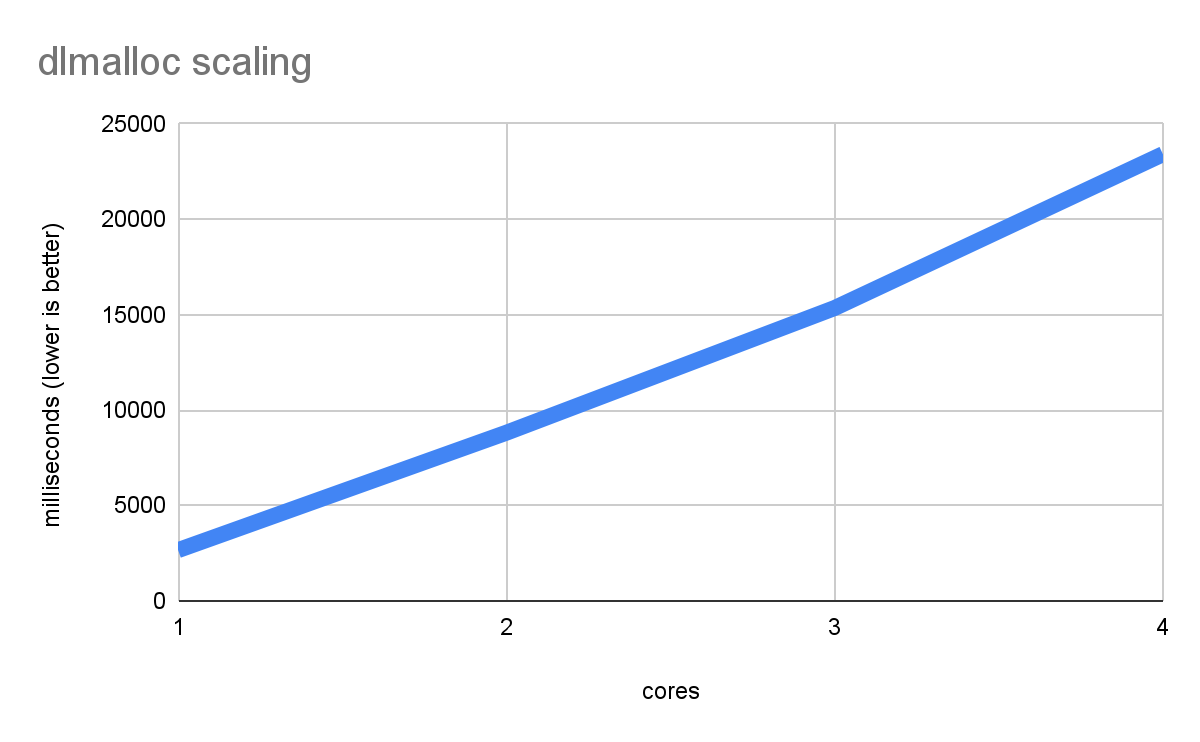
Die Leistung verbessert sich nicht nur nicht mit mehr Kernen, sondern wird immer schlechter, da jeder Thread lange auf die malloc-Sperre wartet. Dies ist der schlimmste Fall, der aber bei realen Arbeitslasten auftreten kann, wenn genügend Zuweisungen vorhanden sind.
mimalloc
Es gibt für dlmalloc optimierte Versionen für mehrere Threads, z. B. ptmalloc3, die eine separate Allocator-Instanz pro Thread implementiert, um Konflikte zu vermeiden.
Es gibt mehrere andere Allocatoren mit Multithreading-Optimierungen, z. B. jemalloc und tcmalloc. Emscripten hat sich auf das neue Projekt mimalloc konzentriert, einen gut konzipierten Allocator von Microsoft mit sehr guter Portabilität und Leistung. So verwenden Sie die Funktion:
emcc -sMALLOC=mimalloc
Hier sind die Ergebnisse für den malloc-Benchmark mit mimalloc:

Super! Die Leistung wird jetzt effizient skaliert und wird mit jedem zusätzlichen Kern immer schneller.
Wenn Sie sich die Daten für die Einzelkernleistung in den letzten beiden Diagrammen genauer ansehen, sehen Sie, dass dlmalloc 2.660 ms und mimalloc nur 1.466 ms benötigte, was einer Verdoppelung der Geschwindigkeit entspricht. Das zeigt, dass Sie auch bei einer einzeiligen Anwendung von den ausgefeilteren Optimierungen von mimalloc profitieren können. Allerdings ist dies mit einem höheren Codevolumen und einer höheren Arbeitsspeichernutzung verbunden. Aus diesem Grund bleibt dlmalloc die Standardeinstellung.
Dateien und E/A
Viele Anwendungen müssen aus verschiedenen Gründen Dateien verwenden. Beispiel: Laden von Levels in einem Spiel oder Schriftarten in einem Bildeditor. Selbst bei einem Vorgang wie printf wird das Dateisystem verwendet, da beim Drucken Daten in stdout geschrieben werden.
Bei einzeiligen Anwendungen ist das in der Regel kein Problem. Emscripten vermeidet automatisch die Verknüpfung mit der vollständigen Unterstützung des Dateisystems, wenn Sie nur printf benötigen. Wenn Sie jedoch Dateien verwenden, ist der Zugriff auf das Dateisystem mit mehreren Threads schwierig, da der Dateizugriff zwischen den Threads synchronisiert werden muss. Die ursprüngliche Dateisystemimplementierung in Emscripten, die wegen ihrer Implementierung in JavaScript „JS FS“ genannt wurde, verwendete das einfache Modell, das Dateisystem nur im Hauptthread zu implementieren. Wenn ein anderer Thread auf eine Datei zugreifen möchte, wird eine Anfrage an den Hauptthread weitergeleitet. Das bedeutet, dass der andere Thread auf eine threadübergreifende Anfrage wartet, die der Hauptthread schließlich verarbeitet.
Dieses einfache Modell ist optimal, wenn nur der Haupt-Thread auf Dateien zugreift, was ein gängiges Muster ist. Wenn jedoch andere Threads Lese- und Schreibvorgänge ausführen, treten Probleme auf. Erstens führt der Hauptthread Arbeit für andere Threads aus, was zu einer für den Nutzer sichtbaren Latenz führt. Die Hintergrundthreads warten dann darauf, dass der Hauptthread kostenlos ist, um die erforderlichen Aufgaben auszuführen. Das führt zu einer Verlangsamung oder, schlimmer noch, zu einem Deadlock, wenn der Hauptthread gerade auf diesen Worker-Thread wartet.
WasmFS
Um dieses Problem zu beheben, hat Emscripten eine neue Dateisystemimplementierung namens WasmFS. WasmFS ist in C++ geschrieben und wird in Wasm kompiliert, im Gegensatz zum ursprünglichen Dateisystem, das in JavaScript geschrieben war. WasmFS unterstützt den Dateisystemzugriff über mehrere Threads mit minimalem Overhead, indem die Dateien im linearen Wasm-Speicher gespeichert werden, der von allen Threads gemeinsam genutzt wird. Alle Threads können jetzt Datei-E/A mit gleicher Leistung ausführen und oft können sie sich sogar gegenseitig blockieren.
Ein einfacher Dateisystem-Benchmark zeigt den enormen Vorteil von WasmFS im Vergleich zum alten JS-Dateisystem.
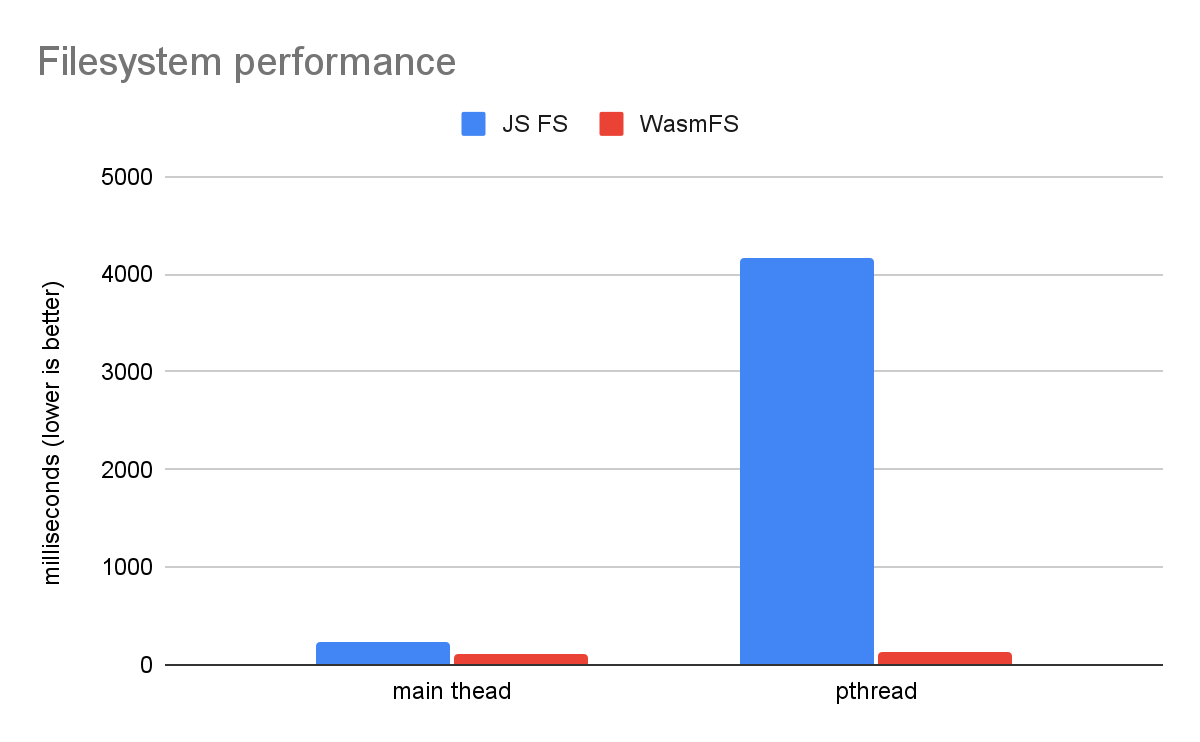
Hier wird verglichen, wie sich die Ausführung des Dateisystemcodes direkt im Hauptthread von der Ausführung in einem einzelnen pthread unterscheidet. Beim alten JS-Dateisystem muss jeder Dateisystemvorgang an den Hauptthread weitergeleitet werden, was die Ausführung auf einem pthread um mehr als eine Größenordnung verlangsamt. Das liegt daran, dass das JS-Dateisystem nicht nur einige Bytes liest und schreibt, sondern eine threadübergreifende Kommunikation durchführt, die Sperren, eine Warteschlange und Wartezeiten umfasst. WasmFS kann dagegen von jedem Thread gleichmäßig auf Dateien zugreifen. Das Diagramm zeigt daher, dass es praktisch keinen Unterschied zwischen dem Haupt- und einem pthread gibt. Daher ist WasmFS 32-mal schneller als das JS-Dateisystem, wenn es auf einem pthread ausgeführt wird.
Beachten Sie, dass es auch einen Unterschied beim Haupt-Thread gibt, bei dem WasmFS doppelt so schnell ist. Das liegt daran, dass das JS-Dateisystem für jeden Dateisystemvorgang JavaScript aufruft, was bei WasmFS vermieden wird. WasmFS verwendet JavaScript nur bei Bedarf, z. B. um eine Web-API zu verwenden. Daher bleiben die meisten WasmFS-Dateien in Wasm. Auch wenn JavaScript erforderlich ist, kann WasmFS einen Hilfs-Thread anstelle des Haupt-Threads verwenden, um für Nutzer sichtbare Latenzen zu vermeiden. Daher können Sie mit WasmFS Geschwindigkeitsverbesserungen erzielen, auch wenn Ihre Anwendung nicht mehrstufig ist (oder mehrstufig ist, aber Dateien nur im Hauptthread verwendet).
So verwenden Sie WasmFS:
emcc -sWASMFS
WasmFS wird in der Produktion verwendet und gilt als stabil, unterstützt aber noch nicht alle Funktionen des alten JS-Dateisystems. Andererseits enthält es einige wichtige neue Funktionen wie die Unterstützung für das Origin Private File System (OPFS, das für dauerhaften Speicher dringend empfohlen wird). Sofern Sie keine Funktion benötigen, die noch nicht portiert wurde, empfiehlt das Emscripten-Team die Verwendung von WasmFS.
Fazit
Wenn Sie eine mehrstufige Anwendung haben, die viele Zuweisungen vornimmt oder Dateien verwendet, können Sie von der Verwendung von WasmFS und/oder mimalloc stark profitieren. Beides lässt sich ganz einfach in einem Emscripten-Projekt ausprobieren, indem Sie es einfach mit den in diesem Beitrag beschriebenen Flags neu kompilieren.
Sie können diese Funktionen auch ausprobieren, wenn Sie keine Threads verwenden: Wie bereits erwähnt, bieten die moderneren Implementierungen Optimierungen, die sich in einigen Fällen sogar auf einem einzelnen Kern bemerkbar machen.