

Data di pubblicazione: 30 gennaio 2025
Molte applicazioni WebAssembly sul web sfruttano il multithreading, come le applicazioni native. Più thread consentono di eseguire più attività in parallelo e spostano il lavoro pesante dal thread principale per evitare problemi di latenza. Fino a poco tempo fa, con queste applicazioni multithread potevano verificarsi alcuni problemi comuni relativi ad allocazioni e I/O. Fortunatamente, le funzionalità recenti di Emscripten possono essere di grande aiuto per risolvere questi problemi. Questa guida mostra in che modo queste funzionalità possono portare a miglioramenti della velocità fino a 10 volte in alcuni casi.
Scalabilità
Il seguente grafico mostra una scalabilità multithread efficiente in un carico di lavoro matematico puro (dal benchmark che utilizzeremo in questo articolo):
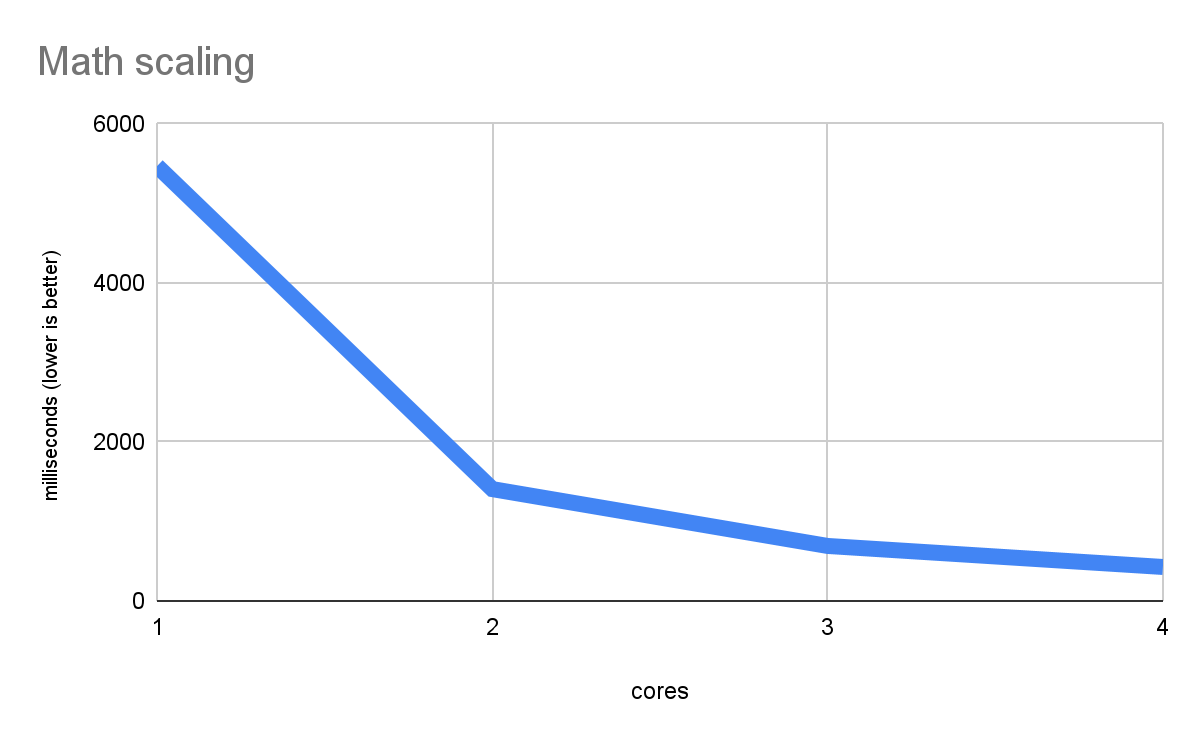
Misura il calcolo puro, qualcosa che ogni core della CPU può fare autonomamente, quindi le prestazioni migliorano con un maggior numero di core. Una linea discendente di rendimento più rapido è esattamente ciò che si intende per scalabilità efficace. Inoltre, dimostra che la piattaforma web può eseguire molto bene il codice nativo multithread, nonostante l'utilizzo di worker web come base per il parallelismo, l'utilizzo di Wasm anziché di vero codice nativo e altri dettagli che potrebbero sembrare meno ottimali.
Gestione dell'heap: malloc/free
malloc e free sono funzioni critiche della libreria standard in tutti i linguaggi con memoria lineare (ad esempio C, C++, Rust e Zig) su cui si basa la gestione di tutta la memoria non completamente statica o sullo stack. Per impostazione predefinita, Emscripten utilizza dlmalloc, un'implementazione compatta ma efficiente (supporta anche emmalloc, che è ancora più compatto, ma in alcuni casi più lento). Tuttavia, le prestazioni multithread di dlmalloc sono limitate perché richiede un blocco su ogni malloc/free (in quanto esiste un singolo allocatore globale). Di conseguenza, puoi riscontrare conflitti e rallentamenti se hai molte allocazioni in molti
thread contemporaneamente. Ecco cosa succede quando esegui un benchmark incredibilmente malloc-intensivo:
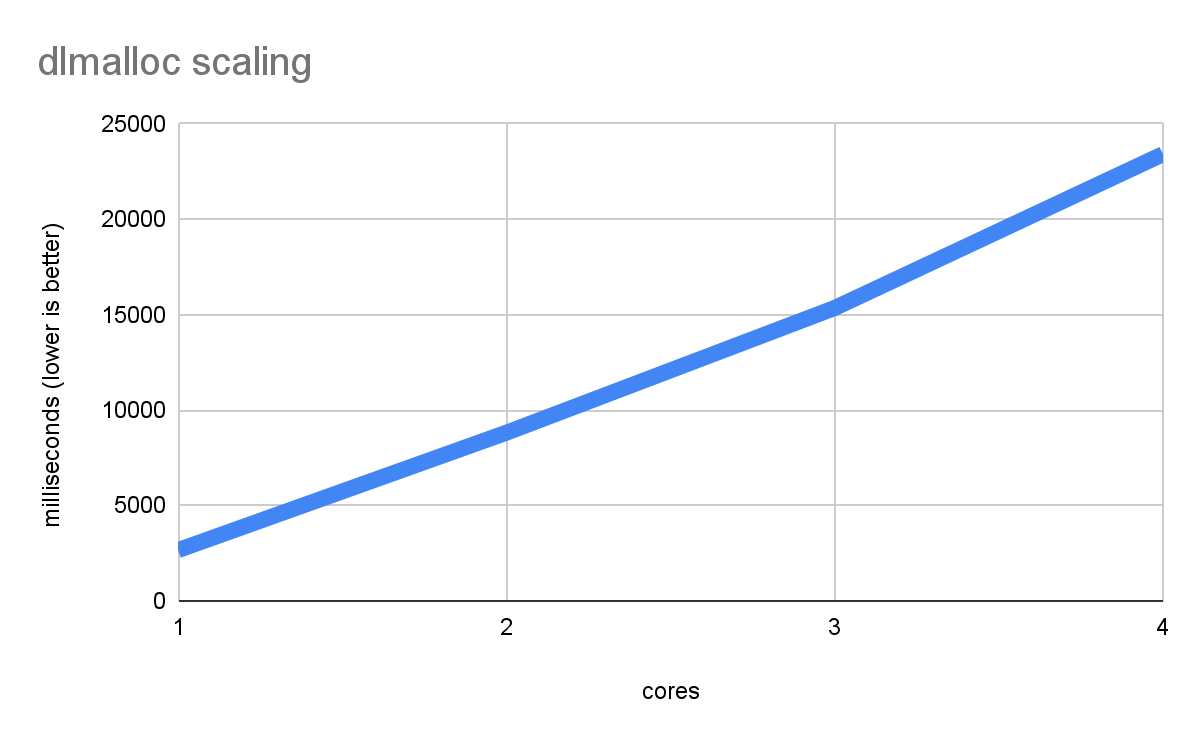
Non solo le prestazioni non migliorano con un maggior numero di core, ma peggiorano sempre di più, poiché ogni thread finisce per attendere per lunghi periodi di tempo il blocco malloc. Si tratta del caso peggiore possibile, ma può verificarsi in carichi di lavoro reali se sono disponibili allocazioni sufficienti.
mimalloc
Esistono versioni di dlmalloc ottimizzate per il multithreading, come ptmalloc3, che implementa un'istanza di allocatore separata per thread, evitando la contesa.
Esistono diversi altri allocatori con ottimizzazioni per il multithreading, come
jemalloc e tcmalloc. Emscripten ha deciso di concentrarsi sul recente progetto mimalloc, un allocatore di Microsoft ben progettato con portabilità e prestazioni molto buone. Utilizzalo nel seguente modo:
emcc -sMALLOC=mimalloc
Ecco i risultati del benchmark malloc utilizzando mimalloc:
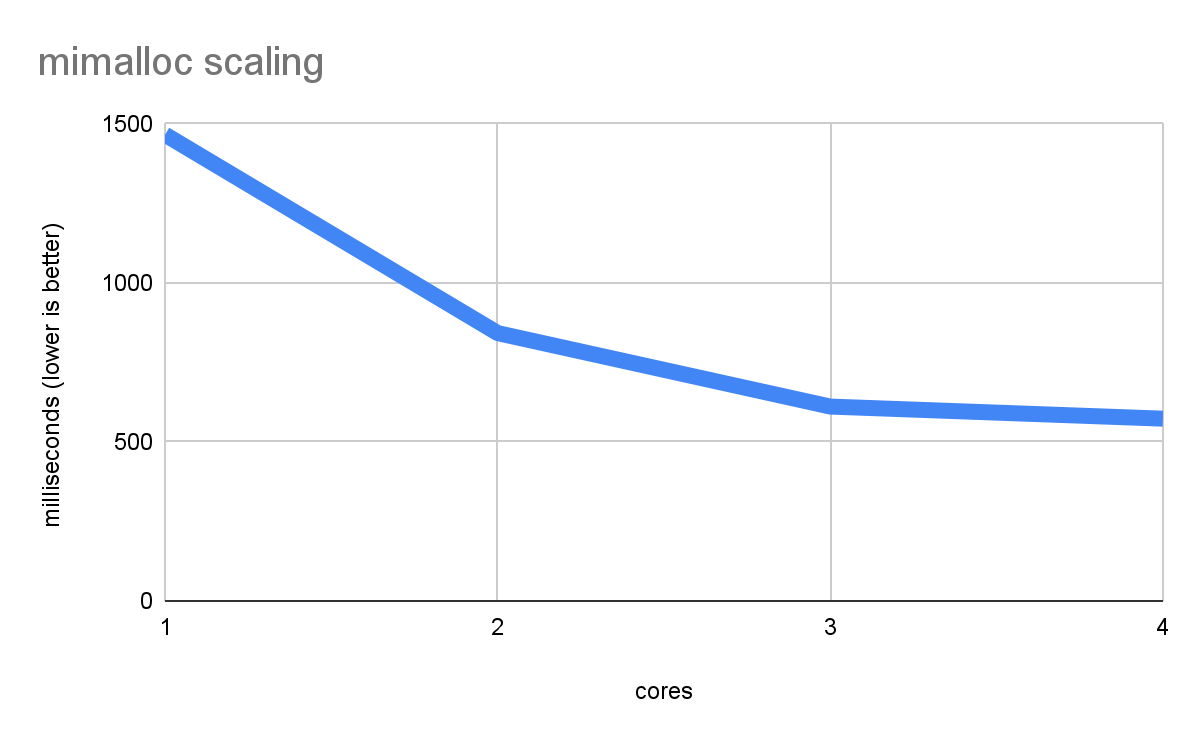
Perfetto! Ora le prestazioni si adattano in modo efficiente, diventando sempre più veloci con ogni nucleo.
Se esamini attentamente i dati relativi al rendimento del nucleo singolo negli ultimi due grafici, noterai che dlmalloc ha impiegato 2660 ms e mimalloc solo 1466, con un miglioramento della velocità di quasi 2 volte. Ciò dimostra che anche in un'applicazione a thread singolo potresti trarre vantaggio dalle ottimizzazioni più sofisticate di mimalloc, anche se tieni presente che ciò comporta un costo in termini di dimensioni del codice e utilizzo della memoria (per questo motivo, dlmalloc rimane l'impostazione predefinita).
File e I/O
Molte applicazioni devono utilizzare file per vari motivi. Ad esempio, per caricare livelli in un gioco o caratteri in un editor di immagini. Anche un'operazione come printf
utilizza il file system sotto il cofano, perché stampa scrivendo dati in stdout.
Nelle applicazioni a thread singolo, in genere non si tratta di un problema ed Emscripten eviterà automaticamente il collegamento del supporto completo del file system se hai bisogno solo di printf. Tuttavia, se utilizzi i file, l'accesso al file system multithread è complicato perché l'accesso ai file deve essere sincronizzato tra i thread. L'implementazione originale del file system in Emscripten, chiamata "JS FS" perché implementata in JavaScript, utilizzava il semplice modello di implementazione del file system solo nel thread principale. Ogni volta che un altro thread vuole accedere a un file, inoltra una richiesta al thread principale. Ciò significa che l'altro thread si blocca su una richiesta tra thread, che alla fine viene gestita dal thread principale.
Questo modello semplice è ottimale se solo il thread principale accede ai file, che è un pattern comune. Tuttavia, se altri thread eseguono letture e scritture, si verificano problemi. Innanzitutto, il thread principale finisce per eseguire operazioni per altri thread, causando una latenza visibile all'utente. Poi, i thread in background finiscono per attendere che il thread principale sia libero per svolgere il lavoro necessario, quindi le cose rallentano (o, peggio, puoi finire in un deadlock se il thread principale è attualmente in attesa di quel thread di lavoro).
WasmFS
Per risolvere il problema, Emscripten ha una nuova implementazione del file system, WasmFS. WasmFS è scritto in C++ e compilato in Wasm, a differenza del file system originale scritto in JavaScript. WasmFS supporta l'accesso al file system da più thread con un overhead minimo, archiviando i file nella memoria lineare Wasm, che viene condivisa tra tutti i thread. Ora tutti i thread possono eseguire I/O file con prestazioni uguali e spesso possono persino evitare di bloccarsi a vicenda.
Un semplice benchmark del file system mostra l'enorme vantaggio di WasmFS rispetto al precedente JS FS.
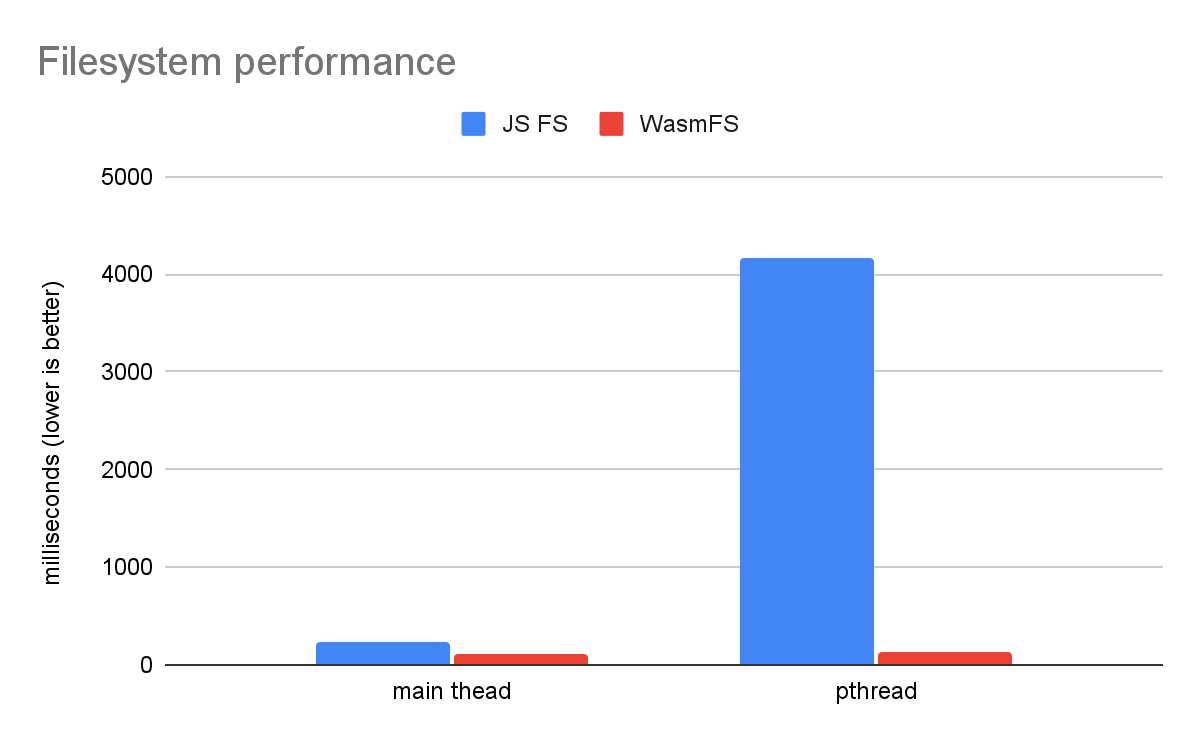
Viene confrontato l'esecuzione del codice del file system direttamente sul thread principale con l'esecuzione su un singolo pthread. Nel vecchio FS JS, ogni operazione del file system deve essere proxy al thread principale, il che lo rende più lento di un ordine di grandezza su un pthread. Questo perché, anziché leggere/scrivere solo alcuni byte, il file system JS esegue la comunicazione tra thread, che prevede blocchi, una coda e attesa. Al contrario, WasmFS può accedere ai file da qualsiasi thread in modo uguale, pertanto il grafico mostra che non c'è praticamente alcuna differenza tra il thread principale e un pthread. Di conseguenza, WasmFS è 32 volte più veloce del sistema file JS su un pthread.
Tieni presente che esiste anche una differenza nel thread principale, in cui WasmFS è due volte più veloce. Questo perché il file system JS chiama JavaScript per ogni operazione sul file system, cosa che WasmFS evita. WasmFS utilizza JavaScript solo se necessario (ad esempio per utilizzare un'API web), pertanto la maggior parte dei file WasmFS rimane in Wasm. Inoltre, anche quando è richiesto JavaScript, WasmFS può utilizzare un thread di supporto anziché il thread principale per evitare la latenza visibile all'utente. Per questo motivo, potresti notare miglioramenti della velocità utilizzando WasmFS anche se la tua applicazione non è multithread (o se è multithread, ma utilizza i file solo nel thread principale).
Utilizza WasmFS come segue:
emcc -sWASMFS
WasmFS viene utilizzato in produzione ed è considerato stabile, ma non supporta ancora tutte le funzionalità del vecchio FS JS. D'altra parte, include alcune nuove funzionalità importanti come il supporto del file system privato di origine (OPFS, vivamente consigliato per lo spazio di archiviazione permanente). A meno che non ti serva una funzionalità che non è stata ancora trasferita, il team di Emscripten consiglia di utilizzare WasmFS.
Conclusione
Se hai un'applicazione multithread che esegue molte allocazioni o utilizza
file, potresti trarre grandi vantaggi dall'utilizzo di WasmFS e/o mimalloc. Entrambi sono
semplici da provare in un progetto Emscripten semplicemente ricompilando con i flag
descritti in questo post.
Potresti anche provare queste funzionalità se non utilizzi i thread: come accennato in precedenza, le implementazioni più moderne sono dotate di ottimizzazioni che in alcuni casi sono evidenti anche su un singolo core.