

पब्लिश किया गया: 30 जनवरी, 2025
वेब पर मौजूद कई WebAssembly ऐप्लिकेशन, नेटिव ऐप्लिकेशन की तरह ही मल्टीथ्रेडिंग का फ़ायदा पाते हैं. एक से ज़्यादा थ्रेड की मदद से, एक साथ ज़्यादा काम किए जा सकते हैं. साथ ही, मुख्य थ्रेड पर ज़्यादा काम करने से बचने के लिए, भारी काम को मुख्य थ्रेड से हटाया जा सकता है. हाल ही तक, ऐसे कई थ्रेड वाले ऐप्लिकेशन में कुछ सामान्य समस्याएं आ सकती थीं. ये समस्याएं, ऐलोकेशन और I/O से जुड़ी होती थीं. सौभाग्य से, Emscripten की हाल ही की सुविधाओं से इन समस्याओं को हल करने में काफ़ी मदद मिल सकती है. इस गाइड में बताया गया है कि इन सुविधाओं की मदद से, कुछ मामलों में गति में 10 गुना या उससे ज़्यादा की बढ़ोतरी कैसे हो सकती है.
स्केलिंग:
यहां दिए गए ग्राफ़ में, पूरी तरह से मैथ वाले वर्कलोड में, मल्टी-थ्रेड वाली स्केलिंग को बेहतर तरीके से दिखाया गया है. यह ग्राफ़, इस लेख में इस्तेमाल किए जाने वाले बेंचमार्क से लिया गया है:
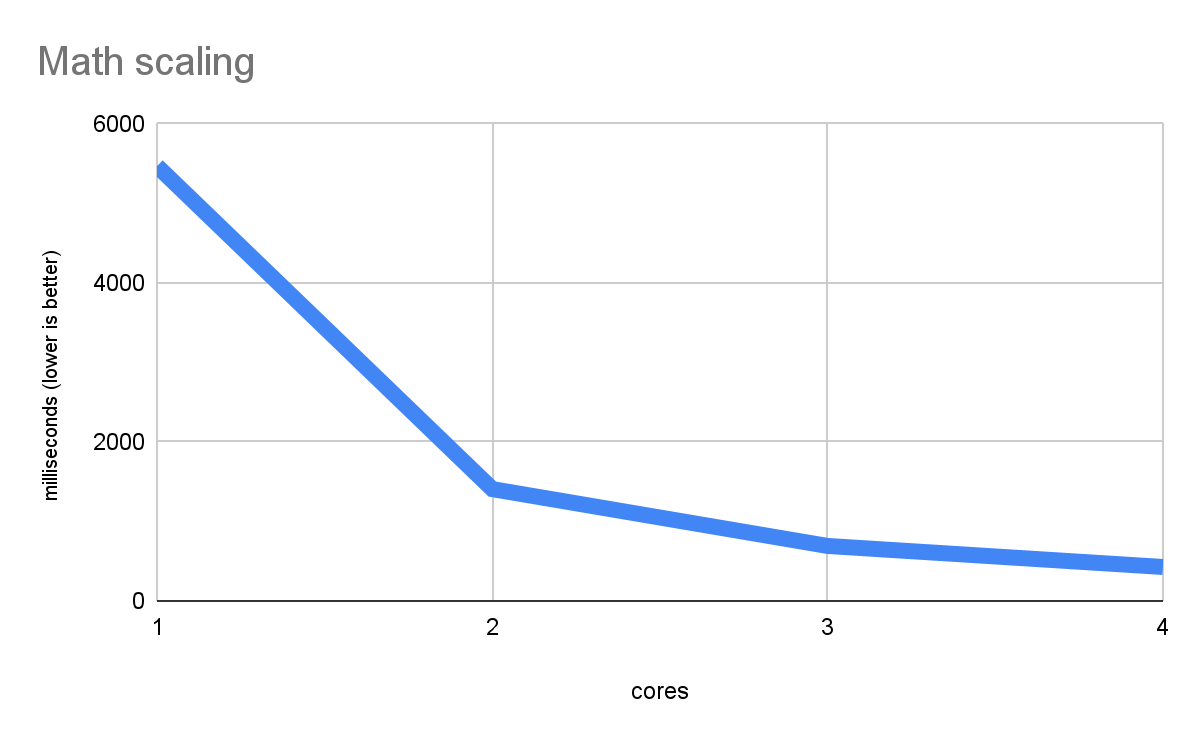
यह सिर्फ़ कंप्यूटेशन को मेज़र करता है. यह ऐसा काम है जिसे हर सीपीयू कोर अपने-आप कर सकता है. इसलिए, ज़्यादा कोर होने पर परफ़ॉर्मेंस बेहतर होती है. बेहतर परफ़ॉर्मेंस की ऐसी लाइन, स्केलिंग के सही नतीजों की निशानी होती है. इससे पता चलता है कि वेब प्लैटफ़ॉर्म, एक से ज़्यादा थ्रेड वाले नेटिव कोड को बेहतर तरीके से चला सकता है. भले ही, इसमें पैरलललिज़्म के आधार के तौर पर वेब वर्कर्स का इस्तेमाल किया जाता है. साथ ही, इसमें असल नेटिव कोड के बजाय WASM का इस्तेमाल किया जाता है. इसके अलावा, इसमें ऐसी अन्य जानकारी भी शामिल होती है जो शायद कम ऑप्टिमाइज़ की गई हो.
ढेर मैनेजमेंट: malloc/free
malloc और free, सभी लीनियर-मेमोरी भाषाओं (उदाहरण के लिए, C, C++, Rust, और Zig) में स्टैंडर्ड लाइब्रेरी के अहम फ़ंक्शन हैं. इनका इस्तेमाल, पूरी तरह से स्टैटिक या स्टैक पर मौजूद न होने वाली मेमोरी को मैनेज करने के लिए किया जाता है. Emscripten डिफ़ॉल्ट रूप से dlmalloc का इस्तेमाल करता है. यह कॉम्पैक्ट है, लेकिन बेहतर तरीके से काम करता है. यह emmalloc के साथ भी काम करता है. यह dlmalloc से ज़्यादा कॉम्पैक्ट है, लेकिन कुछ मामलों में धीमा है. हालांकि, dlmalloc की मल्टी-थ्रेड की परफ़ॉर्मेंस सीमित होती है, क्योंकि यह हर malloc/free पर लॉक लगाता है. ऐसा इसलिए होता है, क्योंकि एक ही ग्लोबल एलोकेटर होता है. इसलिए, अगर एक साथ कई थ्रेड में कई एलोकेशन हैं, तो आपको धीमेपन और रुकावट का सामना करना पड़ सकता है. जब बहुत ज़्यादा malloc-भारी
बेंचमार्क चलाया जाता है, तो क्या होता है:
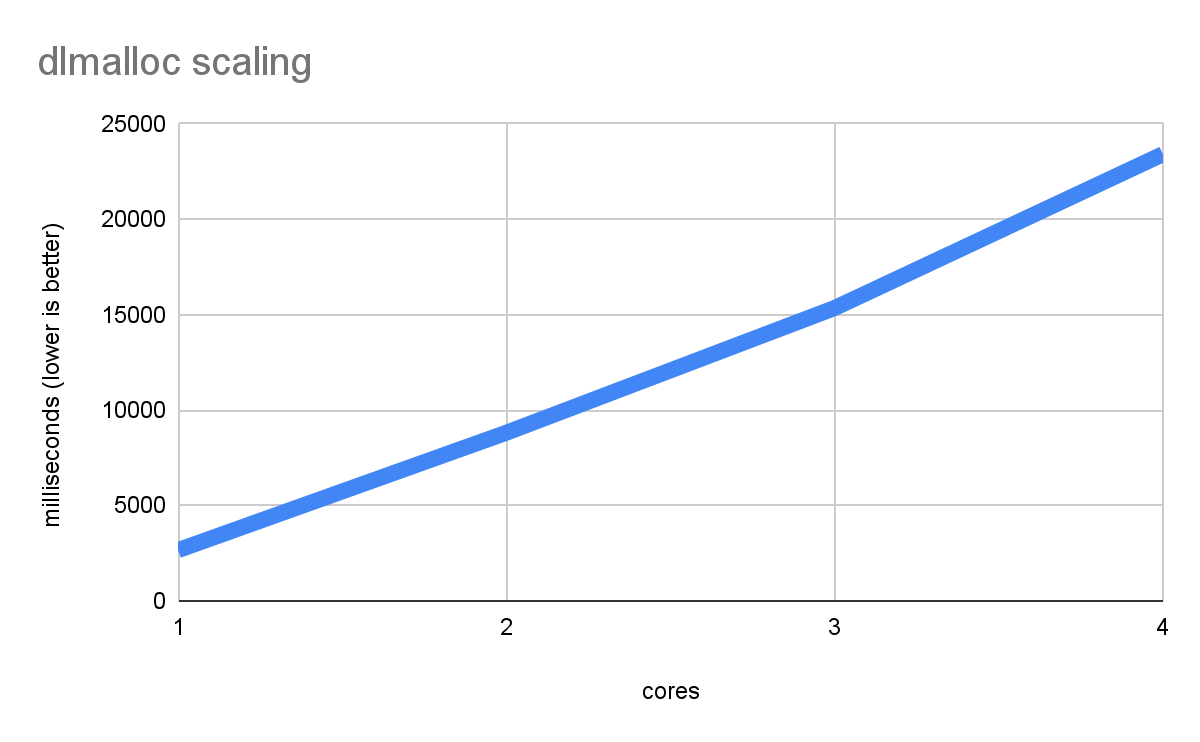
ज़्यादा कोर होने पर, परफ़ॉर्मेंस न सिर्फ़ बेहतर नहीं होती, बल्कि यह और भी खराब होती जाती है. ऐसा इसलिए होता है, क्योंकि हर थ्रेड को malloc लॉक के लिए लंबे समय तक इंतज़ार करना पड़ता है. यह सबसे खराब स्थिति है. हालांकि, ज़रूरत के मुताबिक एलोकेशन होने पर, असल वर्कलोड में ऐसा हो सकता है.
mimalloc
dlmalloc के मल्टी-थ्रेड वाले ऑप्टिमाइज़ किए गए वर्शन मौजूद हैं, जैसे कि ptmalloc3. यह हर थ्रेड के लिए एक अलग एलोकेटर इंस्टेंस लागू करता है, ताकि विवाद से बचा जा सके.
jemalloc और tcmalloc जैसे कई अन्य एलोकेटर, मल्टीथ्रेडिंग ऑप्टिमाइज़ेशन के साथ मौजूद हैं. Emscripten ने हाल ही में शुरू किए गए mimalloc प्रोजेक्ट पर फ़ोकस करने का फ़ैसला लिया है. यह Microsoft का एक बेहतर तरीके से डिज़ाइन किया गया ऐलोकेटर है, जो बेहतर परफ़ॉर्मेंस के साथ-साथ आसानी से एक प्लैटफ़ॉर्म से दूसरे प्लैटफ़ॉर्म पर काम करता है. इसका इस्तेमाल इस तरह करें:
emcc -sMALLOC=mimalloc
mimalloc का इस्तेमाल करके, malloc बेंचमार्क के लिए ये नतीजे मिले:

बढ़िया! अब परफ़ॉर्मेंस बेहतर तरीके से स्केल होती है और हर कोर के साथ तेज़ होती जाती है.
अगर पिछले दो ग्राफ़ में एक-कोर की परफ़ॉर्मेंस के डेटा को ध्यान से देखा जाए, तो आपको पता चलेगा कि dlmalloc को 2660 मिलीसेकंड और mimalloc को सिर्फ़ 1466 मिलीसेकंड लगे. इसका मतलब है कि mimalloc की स्पीड दो गुना ज़्यादा है. इससे पता चलता है कि सिंगल-थ्रेड वाले ऐप्लिकेशन पर भी, आपको mimalloc के बेहतर ऑप्टिमाइज़ेशन से फ़ायदे मिल सकते हैं. हालांकि, ध्यान दें कि इसकी वजह से कोड के साइज़ और मेमोरी के इस्तेमाल में कमी आती है. इस वजह से, dlmalloc डिफ़ॉल्ट तौर पर बना रहता है.
फ़ाइलें और I/O
कई ऐप्लिकेशन को अलग-अलग वजहों से फ़ाइलों का इस्तेमाल करना पड़ता है. उदाहरण के लिए, किसी गेम में लेवल लोड करने या इमेज एडिटर में फ़ॉन्ट लोड करने के लिए. printf जैसे ऑपरेशन भी, फ़ाइल सिस्टम का इस्तेमाल करता है. ऐसा इसलिए, क्योंकि यह stdout में डेटा लिखकर प्रिंट करता है.
आम तौर पर, सिंगल-थ्रेड वाले ऐप्लिकेशन में यह समस्या नहीं होती. अगर आपको सिर्फ़ printf की ज़रूरत है, तो Emscripten अपने-आप फ़ाइल सिस्टम के पूरे सपोर्ट को लिंक करने से बचेगा. हालांकि, अगर फ़ाइलों का इस्तेमाल किया जाता है, तो मल्टी-थ्रेड वाले फ़ाइल सिस्टम का ऐक्सेस मुश्किल हो जाता है, क्योंकि फ़ाइल का ऐक्सेस, थ्रेड के बीच सिंक होना चाहिए. Emscripten में फ़ाइल सिस्टम को लागू करने का मूल तरीका, "JS FS" कहलाता है. ऐसा इसलिए, क्योंकि इसे JavaScript में लागू किया गया था. इसमें सिर्फ़ मुख्य थ्रेड पर फ़ाइल सिस्टम को लागू करने के आसान मॉडल का इस्तेमाल किया गया था. जब भी कोई दूसरी थ्रेड किसी फ़ाइल को ऐक्सेस करना चाहती है, तो वह मुख्य थ्रेड को अनुरोध भेजती है. इसका मतलब है कि दूसरी थ्रेड, किसी दूसरी थ्रेड से किए गए अनुरोध पर ब्लॉक हो जाती है. हालांकि, मुख्य थ्रेड इस अनुरोध को मैनेज करती है.
यह आसान मॉडल तब सबसे अच्छा होता है, जब सिर्फ़ मुख्य थ्रेड फ़ाइलों को ऐक्सेस करता है. यह एक सामान्य पैटर्न है. हालांकि, अगर दूसरी थ्रेड में डेटा पढ़ा और लिखा जाता है, तो समस्याएं आती हैं. पहला, मुख्य थ्रेड, अन्य थ्रेड के लिए काम करता है. इससे उपयोगकर्ता को इंतज़ार करना पड़ता है. इसके बाद, बैकग्राउंड थ्रेड, अपना काम करने के लिए मुख्य थ्रेड के खाली होने का इंतज़ार करती हैं. इससे प्रोसेस धीमी हो जाती है. इसके अलावा, अगर मुख्य थ्रेड फ़िलहाल उस वर्कर थ्रेड का इंतज़ार कर रही है, तो प्रोसेस पूरी होने में और भी ज़्यादा समय लग सकता है.
WasmFS
इस समस्या को ठीक करने के लिए, Emscripten में एक नया फ़ाइल सिस्टम लागू किया गया है, जिसे WasmFS कहा जाता है. WasmFS को C++ में लिखा गया है और इसे Wasm में कंपाइल किया गया है. यह ओरिजनल फ़ाइल सिस्टम से अलग है, जो JavaScript में था. WasmFS, फ़ाइल सिस्टम को कम से कम ओवरहेड के साथ कई थ्रेड से ऐक्सेस करने की सुविधा देता है. इसके लिए, फ़ाइलों को Wasm लीनियर मेमोरी में सेव किया जाता है, जिसे सभी थ्रेड के बीच शेयर किया जाता है. अब सभी थ्रेड, एक जैसी परफ़ॉर्मेंस के साथ फ़ाइल I/O कर सकते हैं. साथ ही, अक्सर वे एक-दूसरे को ब्लॉक करने से भी बच सकते हैं.
फ़ाइल सिस्टम के एक सामान्य मानदंड से पता चलता है कि पुराने JS FS की तुलना में, WasmFS का फ़ायदा बहुत ज़्यादा है.

यह सीधे मुख्य थ्रेड पर फ़ाइल सिस्टम कोड चलाने की तुलना, एक pthread पर चलाने से करता है. पुराने JS FS में, हर फ़ाइल सिस्टम ऑपरेशन को मुख्य थ्रेड पर भेजा जाना चाहिए. इससे pthread पर, फ़ाइल सिस्टम की परफ़ॉर्मेंस काफ़ी धीमी हो जाती है! ऐसा इसलिए होता है, क्योंकि JS FS सिर्फ़ कुछ बाइट पढ़ने/लिखने के बजाय, क्रॉस-थ्रेड कम्यूनिकेशन करता है. इसमें लॉक, कतार, और इंतज़ार शामिल होता है. इसके मुकाबले, WasmFS किसी भी थ्रेड से फ़ाइलों को समान रूप से ऐक्सेस कर सकता है. इसलिए, चार्ट से पता चलता है कि मुख्य थ्रेड और pthread के बीच कोई फ़र्क़ नहीं है. इस वजह से, pthread पर WasmFS, JS FS से 32 गुना ज़्यादा तेज़ है.
ध्यान दें कि मुख्य थ्रेड में भी अंतर है, जहां WasmFS दोगुना तेज़ है. इसकी वजह यह है कि JS FS, हर फ़ाइल सिस्टम ऑपरेशन के लिए JavaScript को कॉल करता है. हालांकि, WasmFS ऐसा नहीं करता. WasmFS, ज़रूरत पड़ने पर ही JavaScript का इस्तेमाल करता है. उदाहरण के लिए, वेब एपीआई का इस्तेमाल करने के लिए. इससे ज़्यादातर WasmFS फ़ाइलें Wasm में रहती हैं. इसके अलावा, JavaScript की ज़रूरत होने पर भी, WasmFS मुख्य थ्रेड के बजाय हेल्पर थ्रेड का इस्तेमाल कर सकता है, ताकि उपयोगकर्ता को इंतज़ार न करना पड़े. इस वजह से, आपको WasmFS का इस्तेमाल करके, ऐप्लिकेशन की स्पीड में बढ़ोतरी दिख सकती है. भले ही, आपका ऐप्लिकेशन मल्टी-थ्रेड वाला न हो या मल्टी-थ्रेड वाला होने के बावजूद, सिर्फ़ मुख्य थ्रेड पर फ़ाइलों का इस्तेमाल करता हो.
WasmFS का इस्तेमाल इस तरह करें:
emcc -sWASMFS
WasmFS का इस्तेमाल प्रोडक्शन में किया जाता है और इसे स्टेबल माना जाता है. हालांकि, यह अभी तक JS FS की सभी सुविधाओं के साथ काम नहीं करता. दूसरी ओर, इसमें कुछ नई और अहम सुविधाएं भी शामिल हैं. जैसे, ऑरिजिन प्राइवेट फ़ाइल सिस्टम (ओपीएफ़एस) के लिए सहायता. ओपीएफ़एस को लगातार स्टोरेज के लिए ज़्यादा से ज़्यादा इस्तेमाल करने का सुझाव दिया जाता है. Emscripten टीम का सुझाव है कि जब तक आपको ऐसी सुविधा की ज़रूरत न हो जिसे अब तक पोर्ट नहीं किया गया है, तब तक WasmFS का इस्तेमाल करें.
नतीजा
अगर आपके पास एक मल्टी-थ्रेड वाला ऐप्लिकेशन है, जो बहुत सारे ऐलोकेशन करता है या फ़ाइलों का इस्तेमाल करता है, तो WasmFS और/या mimalloc का इस्तेमाल करके आपको काफ़ी फ़ायदा मिल सकता है. Emscripten प्रोजेक्ट में, दोनों को आज़माना आसान है. इसके लिए, इस पोस्ट में बताए गए फ़्लैग के साथ फिर से कॉम्पाइल करें.
अगर थ्रेड का इस्तेमाल नहीं किया जा रहा है, तो भी इन सुविधाओं को आज़माया जा सकता है: जैसा कि पहले बताया गया है, नए तरीके से लागू किए गए थ्रेड, ऑप्टिमाइज़ेशन के साथ आते हैं. इनकी वजह से, कुछ मामलों में एक कोर पर भी बेहतर परफ़ॉर्मेंस मिलती है.