

เผยแพร่เมื่อวันที่ 30 มกราคม 2025
แอปพลิเคชัน WebAssembly จำนวนมากบนเว็บได้รับประโยชน์จากมัลติเธรดเช่นเดียวกับแอปพลิเคชันเนทีฟ เทรดหลายรายการช่วยให้งานจำนวนมากทํางานได้แบบขนานกัน และย้ายงานที่มีภาระหนักออกจากเทรดหลักเพื่อหลีกเลี่ยงปัญหาเวลาในการตอบสนอง จนกระทั่งเมื่อไม่นานมานี้ ปัญหาที่พบได้ทั่วไปซึ่งอาจเกิดขึ้นกับแอปพลิเคชันแบบหลายเธรดดังกล่าวเกี่ยวข้องกับการจัดสรรและ I/O แต่โชคดีที่ฟีเจอร์ล่าสุดใน Emscripten ช่วยแก้ปัญหาเหล่านั้นได้เป็นอย่างมาก คู่มือนี้แสดงให้เห็นว่าฟีเจอร์เหล่านี้ช่วยเพิ่มความเร็วได้ 10 เท่าหรือมากกว่านั้นในบางกรณี
การปรับสเกล
กราฟต่อไปนี้แสดงการปรับขนาดแบบหลายเธรดอย่างมีประสิทธิภาพในเวิร์กโหลดคณิตศาสตร์ล้วน (จากการทดสอบประสิทธิภาพที่เราจะใช้ในบทความนี้)
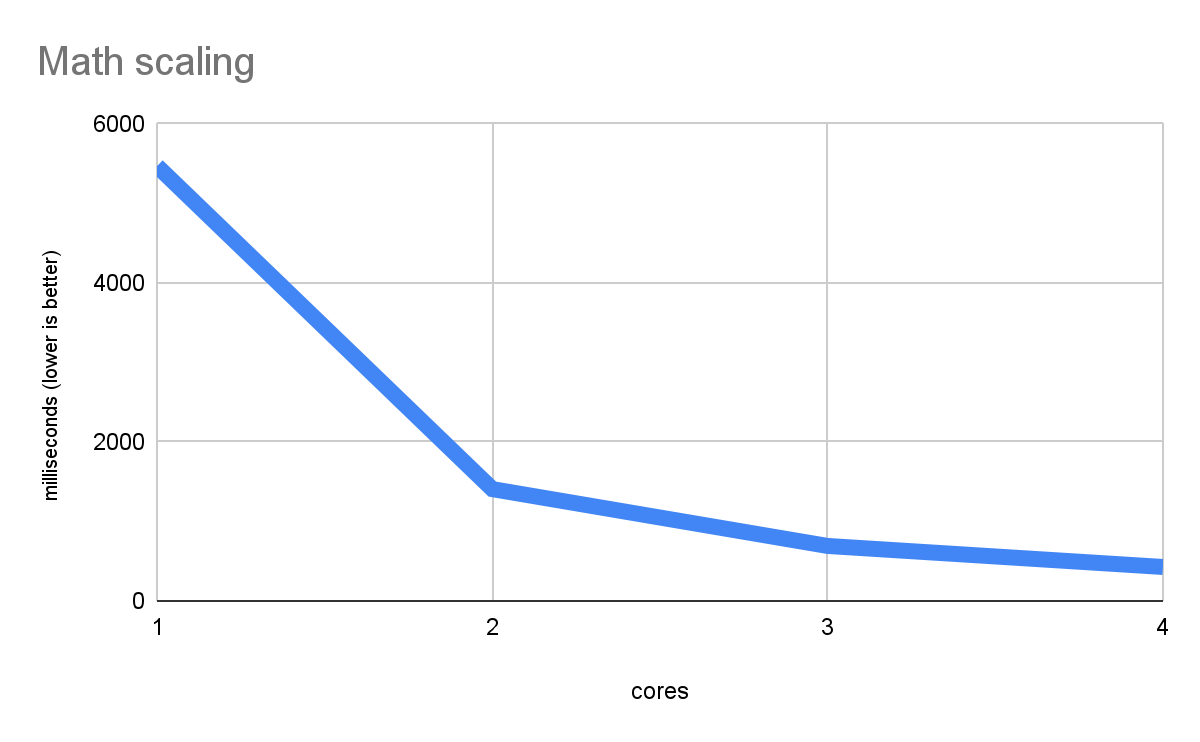
ซึ่งจะวัดการประมวลผลล้วนๆ เป็นสิ่งที่แกน CPU แต่ละแกนทำได้ด้วยตนเอง ดังนั้นประสิทธิภาพจะดีขึ้นเมื่อมีแกนมากขึ้น เส้นประสิทธิภาพที่เร็วขึ้นซึ่งลดลงเช่นนี้คือลักษณะการปรับขนาดที่ดี และแสดงให้เห็นว่าแพลตฟอร์มเว็บสามารถเรียกใช้โค้ดเนทีฟแบบหลายเธรดได้เป็นอย่างดี แม้ว่าจะใช้ Web Worker เป็นพื้นฐานสำหรับการทำงานแบบขนาน และใช้ Wasm แทนโค้ดเนทีฟจริง และรายละเอียดอื่นๆ ที่อาจดูไม่เหมาะสมก็ตาม
การจัดการกอง: malloc/free
malloc และ free เป็นฟังก์ชันมาตรฐานที่สำคัญในไลบรารีของภาษาแบบหน่วยความจำเชิงเส้นทั้งหมด (เช่น C, C++, Rust และ Zig) ซึ่งใช้จัดการหน่วยความจำทั้งหมดที่ไม่ได้เป็นแบบคงที่ทั้งหมดหรืออยู่ในสแต็ก Emscripten ใช้ dlmalloc โดยค่าเริ่มต้น ซึ่งเป็นการใช้งานที่กะทัดรัดแต่มีประสิทธิภาพ (และยังรองรับ emmalloc ด้วย ซึ่งกะทัดรัดกว่าแต่ช้ากว่าในบางกรณี) อย่างไรก็ตาม ประสิทธิภาพแบบหลายเธรดของ dlmalloc จะจํากัดเนื่องจากมีการล็อก malloc/free แต่ละรายการ (เนื่องจากมีตัวจัดสรรแบบรวมเพียงรายการเดียว) คุณจึงอาจพบการแย่งกันใช้ทรัพยากรและความล่าช้าหากมีการจองหน่วยความจำจำนวนมากในหลายเธรดพร้อมกัน สิ่งที่จะเกิดขึ้นเมื่อคุณทำการทดสอบประสิทธิภาพที่เน้นmallocอย่างหนักมากมีดังนี้
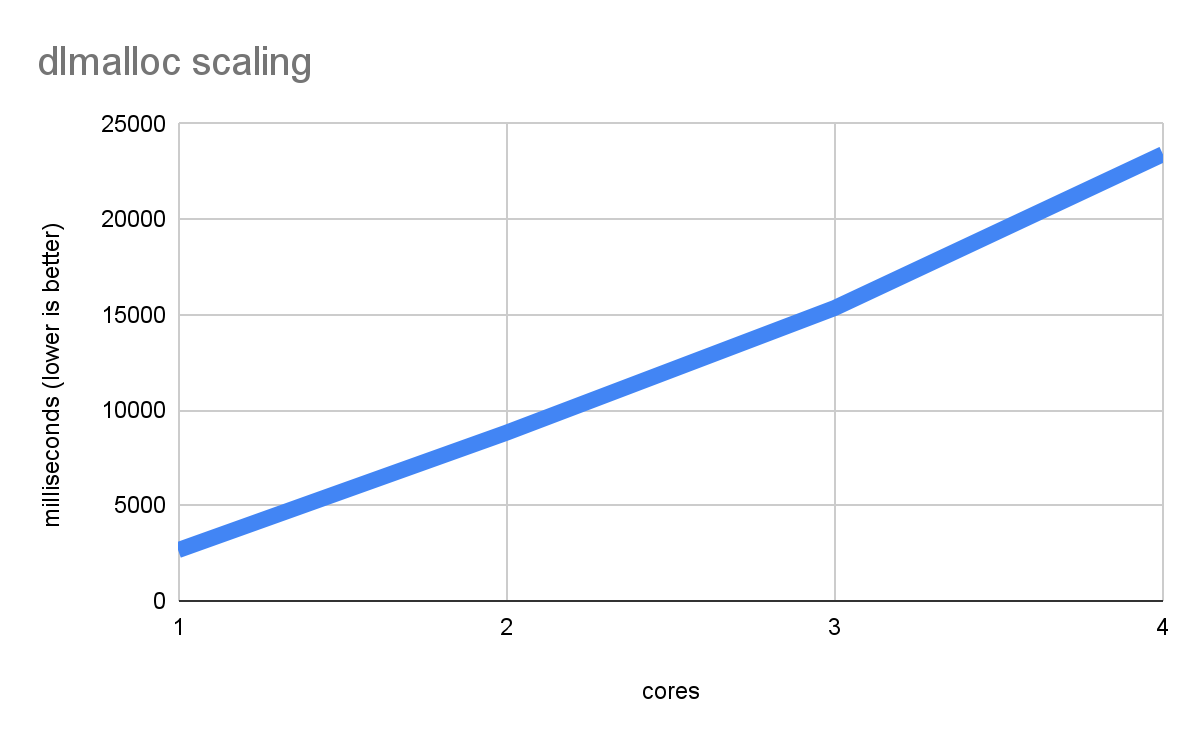
ไม่เพียงแต่จะไม่ได้ประสิทธิภาพเพิ่มขึ้นเมื่อมีแกนประมวลผลมากขึ้น แต่ประสิทธิภาพกลับแย่ลงเรื่อยๆ เนื่องจากแต่ละเธรดต้องรอmallocการล็อกเป็นเวลานาน กรณีนี้ถือเป็นกรณีที่แย่ที่สุด แต่ก็อาจเกิดขึ้นได้กับเวิร์กโหลดจริงหากมีการจองเพียงพอ
mimalloc
dlmalloc มีเวอร์ชันที่เพิ่มประสิทธิภาพแบบหลายเธรด เช่น ptmalloc3 ซึ่งจะใช้อินสแตนซ์ตัวจัดสรรแยกต่างหากต่อเธรดเพื่อหลีกเลี่ยงการแย่งกันใช้
ยังมีตัวจัดสรรอื่นๆ อีกหลายตัวที่มีการเพิ่มประสิทธิภาพแบบหลายเธรด เช่น jemalloc และ tcmalloc Emscripten จึงตัดสินใจมุ่งเน้นที่โปรเจ็กต์ mimalloc ล่าสุด ซึ่งเป็นตัวจัดสรรที่ออกแบบมาอย่างดีจาก Microsoft ที่ย้ายข้อมูลได้และมีประสิทธิภาพดีมาก วิธีใช้มีดังนี้
emcc -sMALLOC=mimalloc
ผลลัพธ์ของการเปรียบเทียบ malloc โดยใช้ mimalloc มีดังนี้

งั้นก็แจ๋วเลย ตอนนี้ประสิทธิภาพจะปรับขนาดได้อย่างมีประสิทธิภาพ โดยจะเร็วขึ้นเรื่อยๆ เมื่อมีแกนประมวลผลมากขึ้น
หากคุณดูข้อมูลประสิทธิภาพของแกนกลางเดียวในกราฟ 2 รายการสุดท้ายอย่างละเอียด จะเห็นว่า dlmalloc ใช้เวลา 2660 มิลลิวินาที และ mimalloc ใช้เวลาเพียง 1466 มิลลิวินาที ซึ่งเร็วขึ้นเกือบ 2 เท่า ข้อมูลนี้แสดงให้เห็นว่าแม้ในแอปพลิเคชันแบบเธรดเดียว คุณก็อาจเห็นประโยชน์จากการเพิ่มประสิทธิภาพที่ซับซ้อนยิ่งขึ้นของ mimalloc แต่โปรดทราบว่าการเพิ่มประสิทธิภาพนี้อาจทำให้ขนาดโค้ดและการใช้หน่วยความจำเพิ่มขึ้น (ด้วยเหตุนี้ dlmalloc จึงยังคงเป็นค่าเริ่มต้น)
ไฟล์และ I/O
แอปพลิเคชันจำนวนมากต้องใช้ไฟล์ด้วยเหตุผลหลายประการ เช่น โหลดด่านในเกมหรือโหลดแบบอักษรในโปรแกรมแก้ไขรูปภาพ แม้แต่การดำเนินการอย่าง printfก็ยังใช้ระบบไฟล์อยู่เบื้องหลัง เนื่องจากจะพิมพ์โดยการเขียนข้อมูลไปยัง stdout
โดยทั่วไปแล้ว ปัญหานี้จะไม่เกิดขึ้นในแอปพลิเคชันแบบเธรดเดียว และ Emscripten จะหลีกเลี่ยงการลิงก์การรองรับระบบไฟล์อย่างเต็มรูปแบบโดยอัตโนมัติหากคุณต้องการแค่printf อย่างไรก็ตาม หากใช้ไฟล์ การเข้าถึงระบบไฟล์แบบหลายเธรดจะมีความซับซ้อน เนื่องจากต้องซิงค์การเข้าถึงไฟล์ระหว่างเธรด การใช้งานระบบไฟล์เดิมใน Emscripten ซึ่งเรียกว่า "JS FS" เนื่องจากติดตั้งใช้งานใน JavaScript ได้ใช้รูปแบบการใช้งานระบบไฟล์แบบง่ายในเธรดหลักเท่านั้น เมื่อใดก็ตามที่อีกเธรดหนึ่งต้องการเข้าถึงไฟล์ เธรดดังกล่าวจะส่งคำขอไปยังเธรดหลัก ซึ่งหมายความว่าเทรดอื่นจะบล็อกคำขอข้ามเทรด ซึ่งเทรดหลักจะจัดการในท้ายที่สุด
รูปแบบที่เรียบง่ายนี้เหมาะสําหรับกรณีที่มีเพียงชุดข้อความหลักที่เข้าถึงไฟล์ ซึ่งเป็นรูปแบบที่พบได้ทั่วไป แต่หากมีเธรดอื่นทำการอ่านและเขียน ปัญหาก็จะเกิดขึ้น ประการแรก เทรดหลักจะทํางานให้กับเทรดอื่นๆ ซึ่งทําให้เกิดความล่าช้าที่ผู้ใช้มองเห็น จากนั้น เทรดในเบื้องหลังจะรอให้เทรดหลักว่างเพื่อทำงานที่ต้องการ จึงทำให้ทุกอย่างช้าลง (หรือแย่กว่านั้น คุณอาจพบปัญหาการล็อกคิวหากเทรดหลักกำลังรอเทรดที่ทำงานอยู่)
WasmFS
Emscripten แก้ปัญหานี้ด้วยการใช้ระบบไฟล์ใหม่อย่าง WasmFS WasmFS เขียนด้วย C++ และคอมไพล์เป็น Wasm ซึ่งแตกต่างจากระบบไฟล์เดิมที่ใช้ JavaScript WasmFS รองรับการเข้าถึงระบบไฟล์จากหลายเธรดโดยมีค่าใช้จ่ายเพิ่มเติมน้อยที่สุด โดยจัดเก็บไฟล์ไว้ในหน่วยความจำเชิงเส้นของ Wasm ซึ่งแชร์กันระหว่างเธรดทั้งหมด ตอนนี้เทรดทั้งหมดสามารถทำ I/O ของไฟล์ได้อย่างมีประสิทธิภาพเท่าๆ กันและมักจะหลีกเลี่ยงการบล็อกกันเองได้
การทดสอบประสิทธิภาพของระบบไฟล์แบบง่ายแสดงให้เห็นถึงข้อได้เปรียบอย่างมากของ WasmFS เมื่อเทียบกับ FS ของ JS เดิม
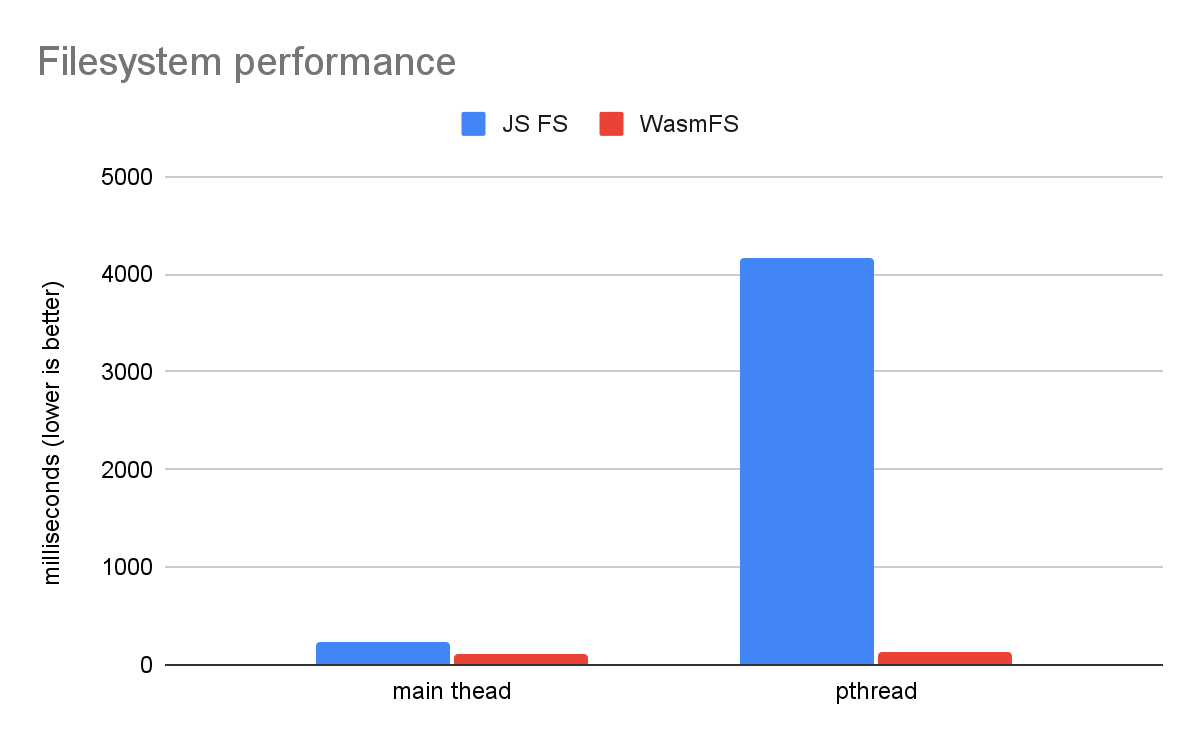
ซึ่งจะเปรียบเทียบการเรียกใช้โค้ดระบบไฟล์ในเธรดหลักโดยตรงกับการเรียกใช้ใน pthread รายการเดียว ใน JS FS เวอร์ชันเก่า การดำเนินการระบบไฟล์ทั้งหมดต้องได้รับการส่งผ่านพร็อกซีไปยังเธรดหลัก ซึ่งทำให้การดำเนินการช้าลงหลายเท่าใน pthread เนื่องจาก JS FS ไม่ได้แค่อ่าน/เขียนไบต์บางส่วน แต่มีการติดต่อสื่อสารข้ามเธรด ซึ่งเกี่ยวข้องกับการล็อก คิว และการรอ ในทางตรงกันข้าม WasmFS สามารถเข้าถึงไฟล์จากเธรดใดก็ได้เท่าๆ กัน แผนภูมิจึงแสดงให้เห็นว่าแทบไม่มีความแตกต่างระหว่างเธรดหลักกับ pthread ด้วยเหตุนี้ WasmFS จึงเร็วกว่า JS FS 32 เท่าเมื่อใช้ pthread
โปรดทราบว่ายังมีความแตกต่างในเธรดหลักด้วย โดย WasmFS จะเร็วกว่า 2 เท่า นั่นเป็นเพราะ JS FS จะเรียกใช้ JavaScript สําหรับการดำเนินการของระบบไฟล์ทุกครั้ง ซึ่ง WasmFS หลีกเลี่ยง WasmFS จะใช้ JavaScript เฉพาะเมื่อจำเป็นเท่านั้น (เช่น เพื่อใช้ Web API) ซึ่งจะทำให้ไฟล์ WasmFS ส่วนใหญ่อยู่ใน Wasm นอกจากนี้ แม้ว่าจะต้องใช้ JavaScript แต่ WasmFS จะใช้เธรดตัวช่วยแทนเธรดหลักได้ เพื่อหลีกเลี่ยงเวลาในการตอบสนองที่ผู้ใช้มองเห็น ด้วยเหตุนี้ คุณจึงอาจเห็นว่าความเร็วเพิ่มขึ้นจากการใช้ WasmFS แม้ว่าแอปพลิเคชันจะไม่เป็นแบบหลายเธรด (หรือเป็นแบบหลายเธรดแต่ใช้ไฟล์ในเธรดหลักเท่านั้น)
ใช้ WasmFS ดังนี้
emcc -sWASMFS
WasmFS ใช้กับเวอร์ชันที่ใช้งานจริงและถือว่าเสถียร แต่ยังไม่รองรับฟีเจอร์ทั้งหมดของ JS FS เดิม ในทางกลับกัน เวอร์ชันนี้ก็มีฟีเจอร์ใหม่ที่สำคัญบางอย่าง เช่น การรองรับระบบไฟล์ส่วนตัวต้นทาง (OPFS ซึ่งเราขอแนะนำอย่างยิ่งสำหรับพื้นที่เก็บข้อมูลถาวร) ทีม Emscripten แนะนำให้ใช้ WasmFS เว้นแต่คุณจะต้องใช้ฟีเจอร์ที่ยังไม่ได้พอร์ต
บทสรุป
หากมีแอปพลิเคชันแบบหลายเธรดที่มีการจองหรือใช้ไฟล์จำนวนมาก คุณอาจได้รับประโยชน์อย่างมากจากการใช้ WasmFS และ/หรือ mimalloc ทั้งสองวิธีนั้นใช้งานได้ง่ายในโปรเจ็กต์ Emscripten โดยเพียงคอมไพล์อีกครั้งด้วย Flag ที่อธิบายไว้ในโพสต์นี้
คุณอาจลองใช้ฟีเจอร์เหล่านั้นด้วยหากไม่ได้ใช้เธรด ดังที่ได้กล่าวไว้ก่อนหน้านี้ การใช้งานที่ทันสมัยมากขึ้นมาพร้อมกับการเพิ่มประสิทธิภาพที่เห็นได้ชัดแม้ในบางกรณีที่ใช้เพียง 1 คอร์