
La historia de lo que se envió, cómo se midió el impacto y las compensaciones que se realizaron.

Contexto
Busca casi cualquier tema en Google y verás una página que se reconoce al instante con resultados significativos y relevantes. Lo que probablemente no sabías es que esta página de resultados de la búsqueda, en ciertas situaciones, se entrega a través de una potente tecnología web llamada trabajador en segundo plano.
Lanzar la compatibilidad con los trabajadores del servicio para la Búsqueda de Google sin afectar negativamente el rendimiento requirió a decenas de ingenieros que trabajaban en varios equipos. Esta es la historia de lo que se envió, cómo se midió el rendimiento y qué compensaciones se realizaron.
Motivos clave para explorar los trabajadores de servicio
Agregar un trabajador de servicio a una app web, al igual que hacer cualquier cambio arquitectónico en tu sitio, debe hacerse con un conjunto claro de objetivos en mente. Para el equipo de la Búsqueda de Google, había algunos motivos clave por los que valía la pena explorar la adición de un trabajador de servicio.
Almacenamiento en caché limitado de los resultados de la búsqueda
El equipo de Búsqueda de Google descubrió que es común que los usuarios busquen los mismos términos más de una vez en un período breve. En lugar de activar una solicitud de backend nueva solo para obtener lo que probablemente sean los mismos resultados, el equipo de Búsqueda quería aprovechar el almacenamiento en caché y entregar esas solicitudes repetidas de forma local.
No se puede descartar la importancia de la actualización, y, a veces, los usuarios buscan los mismos términos de forma reiterada porque es un tema en evolución y esperan ver resultados actualizados. El uso de un trabajador de servicio permite al equipo de Búsqueda implementar una lógica detallada para controlar la vida útil de los resultados de la búsqueda almacenados en caché de forma local y lograr el equilibrio exacto entre velocidad y actualización que creen que mejor se adapta a los usuarios.
Experiencia sin conexión significativa
Además, el equipo de la Búsqueda de Google quería proporcionar una experiencia significativa sin conexión. Cuando un usuario quiere obtener información sobre un tema, quiere ir directamente a la página de la Búsqueda de Google y comenzar a buscar, sin preocuparse por tener una conexión a Internet activa.
Sin un trabajador de servicio, visitar la página de búsqueda de Google sin conexión solo llevaría a la página de error de red estándar del navegador, y los usuarios tendrían que recordar volver y volver a intentarlo una vez que se restablezca la conexión. Con un trabajador de servicio, es posible publicar una respuesta HTML sin conexión personalizada y permitir que los usuarios ingresen su búsqueda de inmediato.
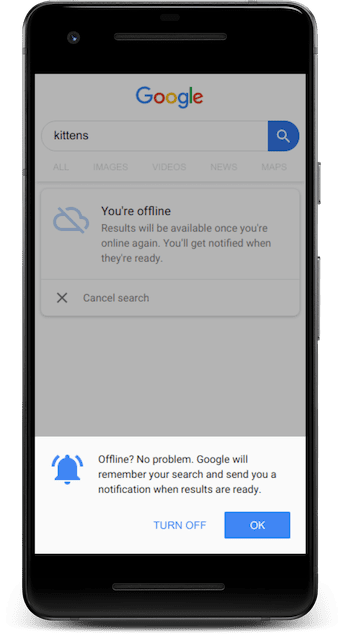
Los resultados no estarán disponibles hasta que haya una conexión a Internet, pero el trabajador de servicio permite que la búsqueda se aplace y se envíe a los servidores de Google en cuanto el dispositivo vuelva a estar en línea con la API de sincronización en segundo plano.
Almacenamiento en caché y entrega de JavaScript más inteligente
Otra motivación fue optimizar el almacenamiento en caché y la carga del código de JavaScript modularizado que potencia los diversos tipos de funciones en la página de resultados de la búsqueda. El empaquetado de JavaScript ofrece varios beneficios que tienen sentido cuando no hay participación de un trabajador del servicio, por lo que el equipo de Búsqueda no quería dejar de empaquetar por completo.
Cuando el equipo de Búsqueda usó la capacidad de un trabajador de servicio para crear versiones y almacenar en caché fragmentos detallados de JavaScript durante el tiempo de ejecución, sospechó que podría reducir la cantidad de rotación de la caché y garantizar que el JavaScript que se vuelva a usar en el futuro se pueda almacenar en caché de manera eficiente. La lógica dentro de su trabajador de servicio puede analicen una solicitud HTTP saliente para un paquete que contiene varios módulos de JavaScript y completarlo uniendo varios módulos almacenados en caché de forma local, lo que, en la práctica, significa "desmembrar" cuando sea posible. Esto ahorra ancho de banda del usuario y mejora la capacidad de respuesta general.
También hay beneficios de rendimiento cuando se usa JavaScript almacenado en caché que entrega un trabajador de servicio: en Chrome, se almacena y reutiliza una representación de código de bytes analizado de ese JavaScript, lo que genera menos trabajo que se debe realizar en el tiempo de ejecución para ejecutar el código JavaScript en la página.
Desafíos y soluciones
Estos son algunos de los obstáculos que se debían superar para lograr los objetivos establecidos del equipo. Si bien algunos de estos desafíos son específicos de la Búsqueda de Google, muchos de ellos se aplican a una amplia variedad de sitios que podrían considerar una implementación de trabajador de servicio.
Problema: sobrecarga del trabajador de servicio
El mayor desafío, y el único bloqueo real para lanzar un trabajador de servicio en la Búsqueda de Google, fue garantizar que no hiciera nada que pudiera aumentar la latencia percibida por el usuario. La Búsqueda de Google se toma el rendimiento muy en serio y, en el pasado, bloqueó el lanzamiento de funciones nuevas si estas generaban incluso decenas de milisegundos de latencia adicional para una población determinada de usuarios.
Cuando el equipo comenzó a recopilar datos de rendimiento durante sus primeros experimentos, fue evidente que habría un problema. El código HTML que se muestra en respuesta a las solicitudes de navegación para la página de resultados de la búsqueda es dinámico y varía mucho según la lógica que se debe ejecutar en los servidores web de la Búsqueda. Actualmente, el trabajador de servicio no puede replicar esta lógica y mostrar el HTML almacenado en caché de inmediato. Lo mejor que puede hacer es pasar las solicitudes de navegación a los servidores web de backend, lo que requiere una solicitud de red.
Sin un trabajador de servicio, esta solicitud de red se realiza inmediatamente después de la navegación del usuario. Cuando se registra un trabajador de servicio, siempre se debe iniciar y se le debe dar la oportunidad de ejecutar sus controladores de eventos fetch, incluso cuando no haya posibilidad de que esos controladores de recuperación hagan algo más que ir a la red. La cantidad de tiempo que se tarda en iniciar y ejecutar el código del trabajador del servicio es una sobrecarga pura que se agrega a cada navegación:

Esto coloca a la implementación del trabajador de servicio en una desventaja de latencia demasiado grande para justificar cualquier otro beneficio. Además, el equipo descubrió que, según la medición de los tiempos de inicio del trabajador de servicio en dispositivos reales, había una distribución amplia de los tiempos de inicio, y algunos dispositivos móviles de gama baja tardaban casi tanto en iniciar el trabajador de servicio como en realizar la solicitud de red para el HTML de la página de resultados.
Solución: Usa la carga previa de navegación
La función más importante que permitió al equipo de la Búsqueda de Google continuar con el lanzamiento del trabajador de servicio es la carga previa de navegación. El uso de la carga previa de navegación es una ventaja de rendimiento clave para cualquier trabajador de servicio que necesite usar una respuesta de la red para satisfacer las solicitudes de navegación. Proporciona una sugerencia al navegador para que comience a realizar la solicitud de navegación de inmediato, al mismo tiempo que se inicia el trabajador de servicio:

Siempre que el tiempo que tarda el trabajador de servicio en iniciarse sea inferior al tiempo que tarda en recibir una respuesta de la red, no debería haber ninguna sobrecarga de latencia que introduzca el trabajador de servicio.
El equipo de Búsqueda también debía evitar usar un trabajador de servicio en dispositivos móviles de gama baja, en los que el tiempo de inicio del trabajador de servicio podría exceder la solicitud de navegación. Como no hay una regla estricta sobre lo que constituye un dispositivo “de gama baja”, se ideó la heurística de comprobar la RAM total instalada en el dispositivo. Cualquier cantidad inferior a 2 gigabytes de memoria se incluía en la categoría de dispositivos de gama baja, en la que el tiempo de inicio del trabajador de servicio sería inaceptable.
Otro aspecto que debes tener en cuenta es el espacio de almacenamiento disponible, ya que el conjunto completo de recursos que se almacenarán en caché para su uso futuro puede alcanzar varios megabytes. La interfaz navigator.storage permite que la página de la Búsqueda de Google determine con anticipación si sus intentos de almacenar en caché los datos corren el riesgo de fallar debido a fallas en la cuota de almacenamiento.
Esto dejó al equipo de Búsqueda con varios criterios que podrían usar para determinar si usar o no un trabajador de servicio: si un usuario llega a la página de la Búsqueda de Google con un navegador que admite la carga previa de navegación y tiene al menos 2 gigabytes de RAM y suficiente espacio de almacenamiento libre, se registra un trabajador de servicio. Los navegadores o dispositivos que no cumplan con ese criterio no tendrán un trabajador de servicio, pero seguirán viendo la misma experiencia de la Búsqueda de Google que siempre han tenido.
Un beneficio adicional de este registro selectivo es la capacidad de enviar un trabajador de servicio más pequeño y eficiente. Orientar la publicación a navegadores bastante modernos para ejecutar el código del trabajador de servicio elimina la sobrecarga de la transpilación y los polyfills para navegadores más antiguos. Esto terminó por quitar alrededor de 8 kilobytes de código JavaScript no comprimido del tamaño total de la implementación del trabajador de servicio.
Problema: Permisos de service worker
Una vez que el equipo de Búsqueda ejecutó suficientes experimentos de latencia y tuvo la confianza de que el uso de la carga previa de navegación les ofrecía una ruta viable y neutral en cuanto a latencia para usar un trabajador de servicio, algunos problemas prácticos comenzaron a tomar protagonismo. Uno de esos problemas tiene que ver con las reglas de alcance del trabajador de servicio. El alcance de un service worker determina de qué páginas puede tomar el control.
El alcance funciona según el prefijo de la ruta de URL. Para los dominios que alojan una sola app web, esto no es un problema, ya que, por lo general, solo usarías un service worker con el alcance máximo de /, que podría tomar el control de cualquier página del dominio.
Sin embargo, la estructura de la URL de la Búsqueda de Google es un poco más complicada.
Si al trabajador del servicio se le otorgara el alcance máximo de /, podría controlar cualquier página alojada en / (o el equivalente regional), y hay URLs en ese dominio que no tienen nada que ver con la Búsqueda de Google.www.google.com Un alcance más razonable y restrictivo sería /search, que, al menos, eliminaría las URLs completamente no relacionadas con los resultados de la búsqueda.
Lamentablemente, incluso esa ruta de URL de /search se comparte entre diferentes tipos de resultados de la Búsqueda de Google, y los parámetros de consulta de URL determinan qué tipo específico de resultado de la búsqueda se muestra. Algunos de esos tipos usan bases de código completamente diferentes a las de la página de resultados de la búsqueda web tradicional. Por ejemplo, la Búsqueda de imágenes y la Búsqueda de Shopping se publican en la ruta de URL /search con diferentes parámetros de consulta, pero ninguna de esas interfaces estaba lista para enviar su propia experiencia de trabajador del servicio (aún).
Solución: Crea un framework de envío y enrutamiento
Si bien hay algunas propuestas que permiten algo más potente que los prefijos de ruta de URL para determinar los alcances del trabajador de servicio, el equipo de la Búsqueda de Google no pudo implementar un trabajador de servicio que no hacía nada para un subconjunto de páginas que controlaba.
Para solucionar este problema, el equipo de Búsqueda de Google creó un marco de trabajo de envío y enrutamiento personalizado que se podía configurar para verificar criterios como los parámetros de consulta de la página del cliente y usarlos para determinar qué ruta de código específica seguir. En lugar de codificar reglas de forma fija, el sistema se diseñó para ser flexible y permitir que los equipos que comparten el espacio de URL, como la Búsqueda de imágenes y la Búsqueda de Shopping, agreguen su propia lógica de trabajador del servicio más adelante, si deciden implementarla.
Problema: Resultados y métricas personalizados
Los usuarios pueden acceder a la Búsqueda de Google con sus Cuentas de Google, y su experiencia con los resultados de la búsqueda se puede personalizar en función de los datos específicos de su cuenta. Los usuarios que accedieron a su cuenta se identifican mediante cookies del navegador específicas, que son un estándar antiguo y ampliamente admitido.
Sin embargo, una desventaja de usar cookies del navegador es que no se exponen dentro de un service worker y no hay forma de examinar automáticamente sus valores y asegurarse de que no hayan cambiado debido a que un usuario salió de su cuenta o cambió de cuenta. (Se está trabajando para llevar el acceso a las cookies a los trabajadores de servicio, pero, en el momento de escribir este artículo, el enfoque es experimental y no es muy compatible).
Una discrepancia entre la vista del trabajador del servicio del usuario que accedió actualmente y el usuario real que accedió a la interfaz web de la Búsqueda de Google podría generar resultados de la búsqueda personalizados de forma incorrecta o registros y métricas atribuidos de forma incorrecta. Cualquiera de esas situaciones de falla sería un problema grave para el equipo de la Búsqueda de Google.
Solución: Envía cookies con postMessage
En lugar de esperar a que se inicien las APIs experimentales y proporcionen acceso directo a las cookies del navegador dentro de un trabajador de servicio, el equipo de la Búsqueda de Google optó por una solución provisional: cada vez que se carga una página controlada por el trabajador de servicio, la página lee las cookies relevantes y usa postMessage() para enviarlas al trabajador de servicio.
Luego, el trabajador del servicio verifica el valor actual de la cookie en función del valor que espera y, si hay una discrepancia, toma medidas para purgar cualquier dato específico del usuario de su almacenamiento y volver a cargar la página de resultados de la búsqueda sin ninguna personalización incorrecta.
Los pasos específicos que realiza el trabajador del servicio para restablecer todo a un modelo de referencia son particulares para los requisitos de la Búsqueda de Google, pero el mismo enfoque general puede ser útil para otros desarrolladores que trabajan con datos personalizados basados en cookies de navegadores.
Problema: experimentos y dinamismo
Como se mencionó, el equipo de la Búsqueda de Google depende en gran medida de la ejecución de experimentos en producción y de la prueba de los efectos de funciones y códigos nuevos en el mundo real antes de activarlos de forma predeterminada. Esto puede ser un desafío con un trabajador de servicio estático que depende en gran medida de los datos almacenados en caché, ya que habilitar o inhabilitar experimentos para los usuarios suele requerir comunicación con el servidor de backend.
Solución: Secuencia de comandos del trabajador de servicio generada de forma dinámica
La solución que eligió el equipo fue usar una secuencia de comandos de trabajador de servicio generada de forma dinámica, que el servidor web personaliza para cada usuario individual, en lugar de una sola secuencia de comandos de trabajador de servicio estático que se genera con anticipación. La información sobre los experimentos que podrían afectar el comportamiento del trabajador de servicio o las solicitudes de red en general se incluye directamente en estas secuencias de comandos personalizadas del trabajador de servicio. El cambio de los conjuntos de experiencias activas de un usuario se realiza a través de una combinación de técnicas tradicionales, como las cookies del navegador, y la publicación de código actualizado en la URL del trabajador del servicio registrado.
El uso de una secuencia de comandos de service worker generada de forma dinámica también facilita la provision de una salida de emergencia en el caso improbable de que una implementación de service worker tenga un error fatal que se deba evitar. La respuesta del trabajador del servidor dinámico podría ser una implementación no operativa, lo que inhabilitaría de manera efectiva el trabajador del servicio para algunos o todos los usuarios actuales.
Problema: coordinación de actualizaciones
Uno de los desafíos más difíciles que enfrentan las implementaciones de trabajadores del servicio en el mundo real es idear una compensación razonable entre evitar la red en favor de la caché y, al mismo tiempo, garantizar que los usuarios existentes reciban actualizaciones y cambios críticos poco después de que se implementen en producción. El equilibrio correcto depende de muchos factores:
- Si tu app web es una app de una sola página duradera que un usuario mantiene abierta de forma indefinida, sin navegar a páginas nuevas.
- Cuál es la cadencia de implementación para las actualizaciones de tu servidor web de backend
- Si el usuario promedio toleraría usar una versión un poco desactualizada de tu app web o si la actualización es la prioridad principal.
Mientras experimentaba con los trabajadores del servicio, el equipo de la Búsqueda de Google se aseguró de mantener los experimentos en ejecución en varias actualizaciones de backend programadas para garantizar que las métricas y la experiencia del usuario coincidieran más con lo que los usuarios recurrentes terminarían viendo en el mundo real.
Solución: Equilibra la actualización y la utilización de la caché
Después de probar varias opciones de configuración, el equipo de la Búsqueda de Google descubrió que la siguiente configuración proporcionaba el equilibrio adecuado entre la actualización y el uso de la caché.
La URL de la secuencia de comandos del trabajador del servicio se entrega con el encabezado de respuesta Cache-Control: private, max-age=1500 (1,500 segundos o 25 minutos) y se registra con updateViaCache establecido en "all" para garantizar que se respete el encabezado. Como puedes imaginar, el backend web de la Búsqueda de Google es un gran conjunto de servidores distribuidos a nivel mundial que requiere un tiempo de actividad lo más cercano posible al 100%. La implementación de un cambio que afectaría el contenido de la secuencia de comandos del trabajador de servicio se realiza de forma continua.
Si un usuario accede a un backend que se actualizó y, luego, navega rápidamente a otra página que accede a un backend que aún no recibió el trabajador de servicio actualizado, terminará cambiando entre versiones varias veces. Por lo tanto, decirle al navegador que solo se moleste en buscar una secuencia de comandos actualizada si transcurrieron 25 minutos desde la última verificación no tiene una desventaja significativa. La ventaja de habilitar este comportamiento es reducir significativamente el tráfico que recibe el extremo que genera de forma dinámica la secuencia de comandos del trabajador de servicio.
Además, se establece un encabezado ETag en la respuesta HTTP de la secuencia de comandos del trabajador de servicio, lo que garantiza que, cuando se realice una verificación de actualización después de que hayan transcurrido 25 minutos, el servidor pueda responder de manera eficiente con una respuesta HTTP 304 si no hubo actualizaciones del trabajador de servicio implementado en el ínterin.
Si bien algunas interacciones dentro de la app web de la Búsqueda de Google usan navegaciones de tipo app de una sola página (es decir, a través de la History API), en su mayoría, la Búsqueda de Google es una app web tradicional que usa navegaciones "reales". Esto entra en juego cuando el equipo decidió que sería eficaz usar dos opciones que aceleran el ciclo de vida de actualización del trabajador de servicio: clients.claim() y skipWaiting().
Hacer clic en la interfaz de la Búsqueda de Google suele terminar en la navegación a documentos HTML nuevos. Llamar a skipWaiting garantiza que un trabajador de servicio actualizado tenga la oportunidad de controlar esas solicitudes de navegación nuevas inmediatamente después de la instalación. De manera similar, llamar a clients.claim() significa que el trabajador de servicio actualizado tiene la oportunidad de comenzar a controlar las páginas abiertas de la Búsqueda de Google que no están controladas después de la activación del trabajador de servicio.
El enfoque que adoptó la Búsqueda de Google no es necesariamente una solución que funcione para todos; fue el resultado de pruebas A/B cuidadosas de varias combinaciones de opciones de publicación hasta que encontraron lo que funcionaba mejor para ellos.
Los desarrolladores cuya infraestructura de backend les permite implementar actualizaciones con mayor rapidez pueden preferir que el navegador compruebe si hay una secuencia de comandos de trabajador de servicio actualizada con la mayor frecuencia posible, siempre ignorando la caché HTTP.
Si estás compilando una app de una sola página que los usuarios podrían mantener abierta durante un período prolongado, es probable que usar skipWaiting() no sea la opción correcta para ti. Corres el riesgo de encontrar inconsistencias en la caché si permites que el nuevo trabajador de servicio se active mientras hay clientes de larga duración.
Conclusiones principales
De forma predeterminada, los trabajadores del servicio no son neutrales en cuanto al rendimiento.
Agregar un trabajador de servicio a tu app web implica insertar un fragmento adicional de JavaScript que se debe cargar y ejecutar antes de que la app web obtenga respuestas a sus solicitudes. Si esas respuestas provienen de una caché local en lugar de la red, la sobrecarga de ejecutar el trabajador de servicio suele ser despreciable en comparación con la mejora del rendimiento que se obtiene cuando se prioriza la caché. Sin embargo, si sabes que tu trabajador de servicio siempre tiene que consultar la red cuando controla las solicitudes de navegación, usar la carga previa de navegación es una mejora de rendimiento fundamental.
Los trabajadores de servicio siguen siendo una mejora progresiva
La historia de compatibilidad con los trabajadores de servicio es mucho más prometedora hoy que hace un año. Todos los navegadores modernos ahora cuentan con al menos cierta compatibilidad con los service workers, pero, lamentablemente, hay algunas funciones avanzadas de service workers, como la sincronización en segundo plano y la carga previa de navegación, que no se lanzaron de forma universal. La verificación de funciones para el subconjunto específico de funciones que sabes que necesitas y solo registrar un trabajador de servicio cuando estén presentes sigue siendo un enfoque razonable.
Del mismo modo, si ejecutaste experimentos en el entorno real y sabes que los dispositivos de gama baja terminan teniendo un rendimiento bajo con la sobrecarga adicional de un trabajador de servicio, también puedes abstenerte de registrar un trabajador de servicio en esas situaciones.
Debes seguir tratando a los trabajadores de servicio como una mejora progresiva que se agrega a una app web cuando se cumplen todos los requisitos previos y el trabajador de servicio agrega algo positivo a la experiencia del usuario y al rendimiento general de la carga.
Medir todo
La única manera de saber si el envío de un trabajador de servicio tuvo un impacto positivo o negativo en las experiencias de tus usuarios es experimentar y medir los resultados.
Los detalles para configurar mediciones significativas dependen del proveedor de estadísticas que uses y de cómo realices los experimentos en la configuración de tu implementación. En este caso de éxito, se detalla un enfoque que utiliza Google Analytics para recopilar métricas en función de la experiencia con los trabajadores del servicio en la app web de Google I/O.
No son objetivos
Si bien muchos miembros de la comunidad de desarrollo web asocian los service workers con las apps web progresivas, la creación de una "AWP de Búsqueda de Google" no era un objetivo inicial del equipo. Actualmente, la app web de la Búsqueda de Google no proporciona metadatos a través de un manifiesto de app web ni anima a los usuarios a seguir el flujo Agregar a la pantalla principal. Actualmente, el equipo de Búsqueda está conforme con que los usuarios lleguen a su app web a través de los puntos de entrada tradicionales de la Búsqueda de Google.
En lugar de intentar convertir la experiencia web de la Búsqueda de Google en el equivalente de lo que esperarías de una aplicación instalada, el objetivo del lanzamiento inicial era mejorar progresivamente el sitio web existente.
Agradecimientos
Gracias a todo el equipo de desarrollo web de la Búsqueda de Google por su trabajo en la implementación del servicio de trabajador y por compartir el material de referencia que se usó para escribir este artículo. Agradecemos especialmente a Philippe Golle, Rajesh Jagannathan y R. Samuel Klatchko, Andy Martone, Leonardo Peña, Rachel Shearer, Greg Terrono y Clay Woolam.
Actualización (octubre de 2021): Desde que se publicó este artículo originalmente, el equipo de la Búsqueda de Google volvió a evaluar los beneficios y las compensaciones de su arquitectura actual de trabajadores del servicio. Se retirará el trabajador de servicio descrito anteriormente. A medida que evoluciona la infraestructura web de la Búsqueda de Google, el equipo puede volver a revisar el diseño de su servicio trabajador.