

Das „L“ in Large Language Models (LLMs) steht zwar für „Large“ (groß), die Realität ist jedoch etwas differenzierter. Einige LLMs enthalten Billionen von Parametern, andere funktionieren effektiv mit weitaus weniger.
Sehen wir uns einige Praxisbeispiele und die praktischen Auswirkungen verschiedener Modellgrößen an.
LLM-Größen und -Größenklassen
Als Webentwickler denken wir bei der Größe einer Ressource in der Regel an die Downloadgröße. Die dokumentierte Größe eines Modells bezieht sich stattdessen auf die Anzahl der Parameter. Gemma 2B steht beispielsweise für Gemma mit 2 Milliarden Parametern.
LLMs können Hunderttausende, Millionen, Milliarden oder sogar Billionen von Parametern haben.
Größere LLMs haben mehr Parameter als ihre kleineren Pendants. So können sie komplexere Sprachbeziehungen erfassen und differenzierte Prompts verarbeiten. Außerdem werden sie oft mit größeren Datensätzen trainiert.
Sie haben vielleicht schon bemerkt, dass bestimmte Modellgrößen wie 2 Milliarden oder 7 Milliarden häufig vorkommen. Beispiele: Gemma 2B, Gemma 7B oder Mistral 7B. Die Modellgrößenklassen sind ungefähre Gruppierungen. Gemma 2B hat beispielsweise ungefähr zwei Milliarden Parameter, aber nicht genau.
Modellgrößenklassen bieten eine praktische Möglichkeit, die LLM-Leistung zu beurteilen. Sie können sich diese wie Gewichtsklassen im Boxen vorstellen: Modelle innerhalb derselben Größenklasse sind besser vergleichbar. Zwei 2B-Modelle sollten eine ähnliche Leistung bieten.
Allerdings kann ein kleineres Modell bei bestimmten Aufgaben dieselbe Leistung wie ein größeres Modell erzielen.

Die Modellgrößen der neuesten LLMs wie GPT-4 und Gemini Pro oder Ultra werden zwar nicht immer offengelegt, sie dürften aber Hunderte von Milliarden oder Trillionen von Parametern umfassen.

Nicht bei allen Modellen ist die Anzahl der Parameter im Namen angegeben. Einige Modelle haben eine Versionsnummer. Gemini 1.5 Pro bezieht sich beispielsweise auf die Version 1.5 des Modells (nach Version 1).
LLM oder nicht?
Wann ist ein Modell zu klein, um als LLM zu gelten? Die Definition von LLM kann in der KI- und ML-Community etwas fließend sein.
Einige betrachten nur die größten Modelle mit Milliarden von Parametern als echte LLMs, während kleinere Modelle wie DistilBERT als einfache NLP-Modelle betrachtet werden. Andere schließen kleinere, aber dennoch leistungsstarke Modelle in die Definition von LLM ein, z. B. DistilBERT.
Kleinere LLMs für Anwendungsfälle auf dem Gerät
Größere LLMs erfordern viel Speicherplatz und Rechenleistung für die Inferenz. Sie müssen auf speziellen leistungsstarken Servern mit spezieller Hardware (z. B. TPUs) ausgeführt werden.
Als Webentwickler interessiert uns unter anderem, ob ein Modell klein genug ist, um auf das Gerät eines Nutzers heruntergeladen und dort ausgeführt zu werden.
Das ist aber eine schwierige Frage. Derzeit gibt es keine einfache Möglichkeit, herauszufinden, ob ein Modell auf den meisten Mittelklasse-Geräten ausgeführt werden kann. Das hat mehrere Gründe:
- Die Gerätefunktionen variieren stark je nach Arbeitsspeicher, GPU-/CPU-Spezifikationen und mehr. Ein Low-End-Android-Smartphone und ein NVIDIA® RTX-Laptop unterscheiden sich stark. Möglicherweise haben Sie einige Datenpunkte dazu, welche Geräte Ihre Nutzer haben. Wir haben noch keine Definition für ein Referenzgerät, das für den Zugriff auf das Web verwendet wird.
- Ein Modell oder das Framework, in dem es ausgeführt wird, kann für die Ausführung auf bestimmter Hardware optimiert sein.
- Es gibt keine programmatische Möglichkeit, festzustellen, ob ein bestimmter LLM auf ein bestimmtes Gerät heruntergeladen und dort ausgeführt werden kann. Die Downloadkapazität eines Geräts hängt unter anderem davon ab, wie viel VRAM auf der GPU vorhanden ist.
Wir haben jedoch einige empirische Erkenntnisse: Heute können einige Modelle mit einigen Millionen bis hin zu einigen Milliarden Parametern im Browser auf Geräten für den Massenmarkt ausgeführt werden.
Beispiel:
- Gemma 2B mit der MediaPipe LLM Inference API (auch für Geräte geeignet, die nur eine CPU haben) Jetzt ausprobieren.
- DistilBERT mit Transformers.js
Dieses Feld ist noch in der Entwicklungsphase. Die Branche wird sich weiterentwickeln:
- Mit den Innovationen von WebAssembly und WebGPU wird WebGPU-Unterstützung in immer mehr Bibliotheken, neuen Bibliotheken und Optimierungen eingeführt. Auf den Geräten der Nutzer können dann immer effizienter LLMs verschiedener Größen ausgeführt werden.
- Durch neue Schrumpftechniken werden kleinere, leistungsstarke LLMs immer häufiger eingesetzt.
Hinweise für kleinere LLMs
Bei der Arbeit mit kleineren LLMs sollten Sie immer die Leistung und die Downloadgröße berücksichtigen.
Leistung
Die Leistung eines Modells hängt stark von Ihrem Anwendungsfall ab. Ein kleineres LLM, das auf Ihren Anwendungsfall abgestimmt ist, kann eine bessere Leistung als ein größeres generisches LLM erzielen.
Innerhalb derselben Modellfamilie sind kleinere LLMs jedoch weniger leistungsfähig als ihre größeren Pendants. Für denselben Anwendungsfall müssen Sie bei Verwendung eines kleineren LLM in der Regel mehr schnelle Engineering-Arbeit leisten.
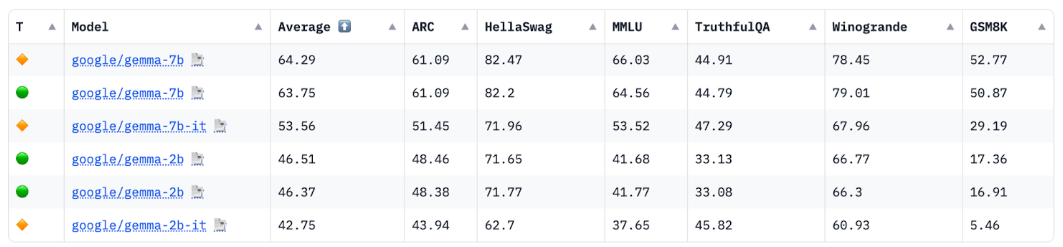
Quelle: HuggingFace Open LLM Leaderboard, April 2024
Downloadgröße
Mehr Parameter bedeuten eine größere Downloadgröße. Dies wirkt sich auch darauf aus, ob ein Modell, auch wenn es als klein eingestuft wird, für On-Device-Anwendungsfälle vernünftig heruntergeladen werden kann.
Es gibt zwar Methoden, mit denen die Downloadgröße eines Modells anhand der Anzahl der Parameter berechnet werden kann, dies kann jedoch komplex sein.
Anfang 2024 werden die Downloadgrößen von Modellen selten dokumentiert. Daher empfehlen wir dir, die Downloadgröße für Anwendungsfälle auf dem Gerät und im Browser empirisch zu ermitteln. Dazu kannst du den Bereich Netzwerk in den Chrome-Entwicklertools oder andere Browser-Entwicklertools verwenden.

Gemma wird mit der MediaPipe LLM Inference API verwendet. DistilBERT wird mit Transformers.js verwendet.
Techniken zum Schrumpfen von Modellen
Es gibt mehrere Möglichkeiten, den Speicherbedarf eines Modells erheblich zu reduzieren:
- LoRA (Low-Rank Adaptation): Eine Methode zur Feinabstimmung, bei der die vorab trainierten Gewichte eingefroren werden. Weitere Informationen zu LoRA
- Auslaßen: Weniger wichtige Gewichte aus dem Modell entfernen, um die Größe zu reduzieren.
- Quantisierung: Verringerung der Genauigkeit von Gewichten von Gleitkommazahlen (z. B. 32 Bit) auf niedrigere Bitdarstellungen (z. B. 8 Bit).
- Wissensdestillation: Ein kleineres Modell wird so trainiert, dass es das Verhalten eines größeren, vortrainierten Modells nachahmt.
- Parameterfreigabe: Dieselben Gewichte für mehrere Teile des Modells verwenden, um die Gesamtzahl der eindeutigen Parameter zu reduzieren.