
得益于强大的 API(例如 IndexedDB 和 WebCodecs)和性能工具,创作者现在可以使用 Kapwing 编辑网络上的高品质视频内容。

自疫情开始以来,在线视频消费快速增长。 人们越来越多地在 TikTok、Instagram 和 YouTube 等平台上观看无尽的高画质视频。世界各地的创意人员和小企业主都需要快捷易用的工具来制作视频内容。
Kapwing 等公司利用强大的 API 和性能工具等最新产品,可以直接在网络上创作这类视频内容。
Kapwing 简介
Kapwing 是一款基于网络的协作式视频编辑器,主要面向游戏直播者、音乐人、YouTube 创作者和表情包达人等休闲广告素材。如果企业主需要一种简单的方式来制作自己的社交内容(例如 Facebook 和 Instagram 广告),也可以使用此资料。
用户通过搜索特定任务(例如“如何剪辑视频”“向我的视频中添加音乐”或“调整视频大小”)就能发现 Kapwing。用户只需点击一下即可执行所搜索的内容,无需转到应用商店和下载应用,因此更加顺畅。用户可以借助 Web 轻松准确地搜索自己需要帮助的任务,然后执行相应操作。
首次点击之后,Kapwing 用户可以执行更多操作。他们可以探索免费的模板、添加新的免费图库视频、插入字幕、转录视频以及上传背景音乐。
Kapwing 如何将实时编辑与协作带入网络
虽然网络具有独特的优势,但也存在一些独特的挑战。Kapwing 需要能够在各种设备和网络条件下流畅准确地播放复杂的多层项目。为了实现这一点,我们使用各种 Web API 来实现性能和功能目标。
IndexedDB
高性能编辑要求所有用户的内容都存在于客户端上,并尽可能避开网络。与在线播放服务(用户通常访问一段内容一次)不同,我们的客户会在上传后的几天甚至几个月内频繁地重复使用他们的资源。
借助 IndexedDB,我们能够为用户提供类似文件系统的永久性存储空间。结果就是,应用中超过 90% 的媒体请求都是在本地执行的。将 IndexedDB 集成到我们的系统中非常简单。
以下是一些在应用加载时运行的样板初始化代码:
import {DBSchema, openDB, deleteDB, IDBPDatabase} from 'idb';
let openIdb: Promise <IDBPDatabase<Schema>>;
const db =
(await openDB) <
Schema >
(
'kapwing',
version, {
upgrade(db, oldVersion) {
if (oldVersion >= 1) {
// assets store schema changed, need to recreate
db.deleteObjectStore('assets');
}
db.createObjectStore('assets', {
keyPath: 'mediaLibraryID'
});
},
async blocked() {
await deleteDB('kapwing');
},
async blocking() {
await deleteDB('kapwing');
},
}
);
我们传递一个版本并定义一个 upgrade 函数。这用于进行初始化或在必要时更新架构。我们会传递错误处理回调 blocked 和 blocking。我们发现它们有助于防止系统不稳定的用户出现问题。
最后,请注意主键 keyPath 的定义。在我们的示例中,这是唯一 ID,我们称之为 mediaLibraryID。当用户通过上传器或第三方扩展程序向我们的系统添加媒体内容时,我们会使用以下代码将相应媒体内容添加到媒体库中:
export async function addAsset(mediaLibraryID: string, file: File) {
return runWithAssetMutex(mediaLibraryID, async () => {
const assetAlreadyInStore = await (await openIdb).get(
'assets',
mediaLibraryID
);
if (assetAlreadyInStore) return;
const idbVideo: IdbVideo = {
file,
mediaLibraryID,
};
await (await openIdb).add('assets', idbVideo);
});
}
runWithAssetMutex 是我们自己的内部定义的函数,用于序列化 IndexedDB 访问。任何读取-修改-写入类型的操作都需要满足此要求,因为 IndexedDB API 是异步的。
现在,我们来看看如何访问文件。以下是我们的 getAsset 函数:
export async function getAsset(
mediaLibraryID: string,
source: LayerSource | null | undefined,
location: string
): Promise<IdbAsset | undefined> {
let asset: IdbAsset | undefined;
const { idbCache } = window;
const assetInCache = idbCache[mediaLibraryID];
if (assetInCache && assetInCache.status === 'complete') {
asset = assetInCache.asset;
} else if (assetInCache && assetInCache.status === 'pending') {
asset = await new Promise((res) => {
assetInCache.subscribers.push(res);
});
} else {
idbCache[mediaLibraryID] = { subscribers: [], status: 'pending' };
asset = (await openIdb).get('assets', mediaLibraryID);
idbCache[mediaLibraryID].asset = asset;
idbCache[mediaLibraryID].subscribers.forEach((res: any) => {
res(asset);
});
delete (idbCache[mediaLibraryID] as any).subscribers;
if (asset) {
idbCache[mediaLibraryID].status = 'complete';
} else {
idbCache[mediaLibraryID].status = 'failed';
}
}
return asset;
}
我们有自己的数据结构 idbCache,用于最大限度地减少 IndexedDB 访问。虽然 IndexedDB 速度很快,但访问本地内存的速度会更快。我们建议您使用此方法,前提是您可以管理缓存的大小。
subscribers 数组用于防止同时访问 IndexedDB,否则在加载时会很常见。
Web Audio API
音频的可视化对于视频编辑至关重要。如需了解原因,请查看编辑器中的屏幕截图:
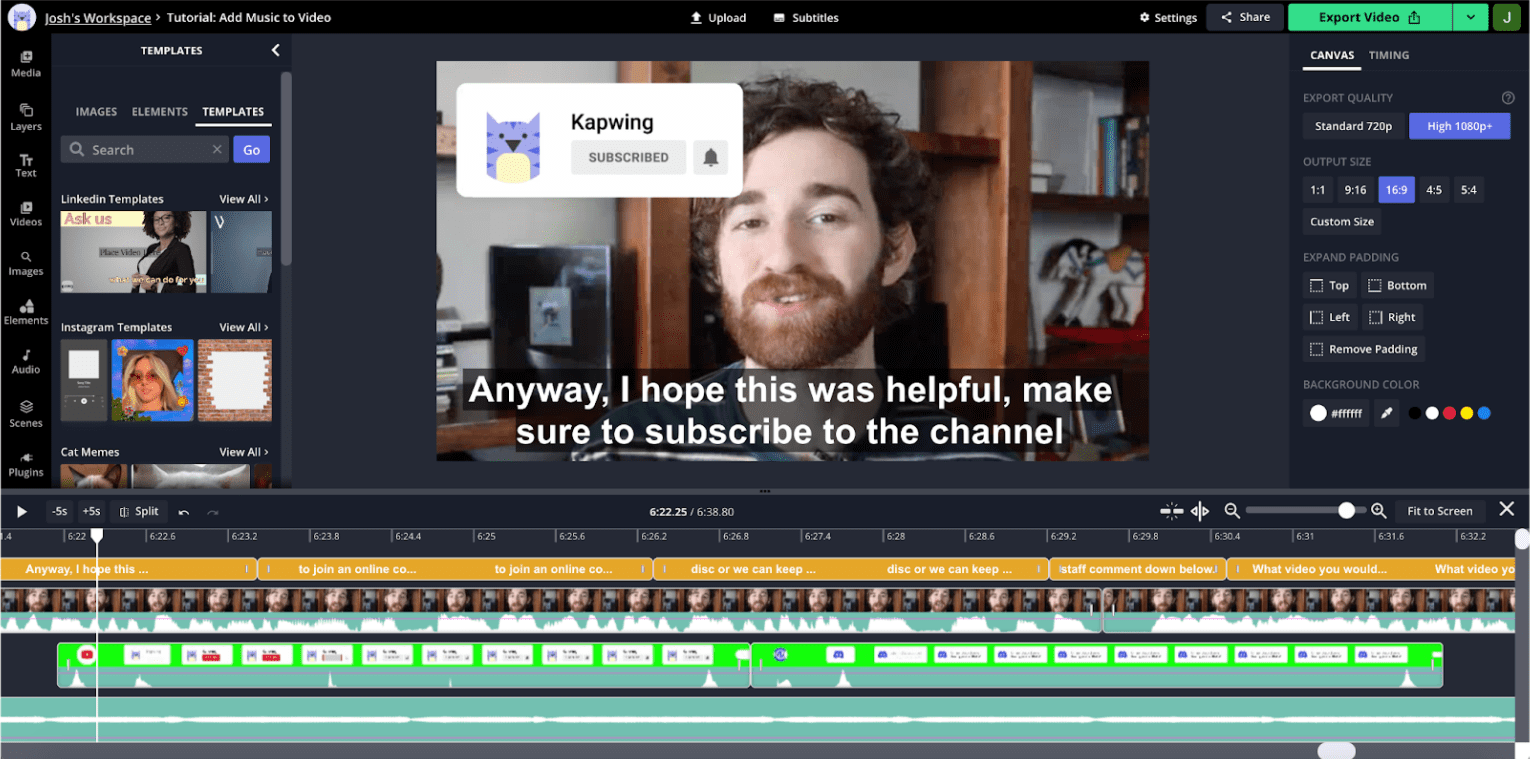
这是一个 YouTube 样式的视频,这在我们的应用中很常见。用户在整个视频剪辑中不会进行太多移动,因此时间轴的可视缩略图对于在各部分之间导航不太有用。另一方面,音频波形会显示峰值和谷值,谷值通常对应于录音中的停止时间。如果放大时间轴,您会看到更精细的音频信息,以及与卡顿和暂停对应的谷值。
我们的用户研究表明,创作者在拼接内容时通常会受到这些波形的引导。借助 Web Audio API,我们能够高效地呈现这些信息,并在时间轴的缩放或平移时快速更新。
以下代码段演示了如何实现此操作:
const getDownsampledBuffer = (idbAsset: IdbAsset) =>
decodeMutex.runExclusive(
async (): Promise<Float32Array> => {
const arrayBuffer = await idbAsset.file.arrayBuffer();
const audioContext = new AudioContext();
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
const offline = new OfflineAudioContext(
audioBuffer.numberOfChannels,
audioBuffer.duration * MIN_BROWSER_SUPPORTED_SAMPLE_RATE,
MIN_BROWSER_SUPPORTED_SAMPLE_RATE
);
const downsampleSource = offline.createBufferSource();
downsampleSource.buffer = audioBuffer;
downsampleSource.start(0);
downsampleSource.connect(offline.destination);
const downsampledBuffer22K = await offline.startRendering();
const downsampledBuffer22KData = downsampledBuffer22K.getChannelData(0);
const downsampledBuffer = new Float32Array(
Math.floor(
downsampledBuffer22KData.length / POST_BROWSER_SAMPLE_INTERVAL
)
);
for (
let i = 0, j = 0;
i < downsampledBuffer22KData.length;
i += POST_BROWSER_SAMPLE_INTERVAL, j += 1
) {
let sum = 0;
for (let k = 0; k < POST_BROWSER_SAMPLE_INTERVAL; k += 1) {
sum += Math.abs(downsampledBuffer22KData[i + k]);
}
const avg = sum / POST_BROWSER_SAMPLE_INTERVAL;
downsampledBuffer[j] = avg;
}
return downsampledBuffer;
}
);
我们向该帮助程序传递存储在 IndexedDB 中的资源。完成后,我们将更新 IndexedDB 中的资源以及我们自己的缓存。
我们使用 AudioContext 构造函数收集有关 audioBuffer 的数据,但由于我们不会渲染到设备硬件,因此我们使用 OfflineAudioContext 渲染到 ArrayBuffer,并在其中存储振幅数据。
API 本身以远高于有效可视化所需的采样率返回数据。因此,我们手动将采样率降至 200 Hz,我们发现这足以生成具有视觉吸引力的实用波形。
WebCodecs
对于某些视频,轨道缩略图比波形更有助于进行时间轴导航。但是,生成缩略图比生成波形需要耗费更多资源。
我们无法在加载时缓存所有可能的缩略图,因此,对时间轴平移/缩放进行快速解码对于应用性能出色且响应迅速的应用至关重要。实现流畅帧绘制的瓶颈是解码帧,直到最近我们使用 HTML5 视频播放器进行帧解码。这种方法的性能并不可靠,并且在帧渲染期间,我们经常会发现应用响应能力下降。
最近,我们已迁移至可在 Web 工作器中使用的 WebCodecs。这应该会增强我们为大量图层绘制缩略图的能力,而不会影响主线程性能。在 Web 工作器实现过程中,我们将在下面概述现有的主线程实现。
视频文件包含多个流:视频、音频和字幕等流通过多路复用。如需使用 WebCodecs,我们首先需要一个多路分配视频流。我们使用 mp4box 库对 mp4 进行多路分配,如下所示:
async function create(demuxer: any) {
demuxer.file = (await MP4Box).createFile();
demuxer.file.onReady = (info: any) => {
demuxer.info = info;
demuxer._info_resolver(info);
};
demuxer.loadMetadata();
}
const loadMetadata = async () => {
let offset = 0;
const asset = await getAsset(this.mediaLibraryId, null, this.url);
const maxFetchOffset = asset?.file.size || 0;
const end = offset + FETCH_SIZE;
const response = await fetch(this.url, {
headers: { range: `bytes=${offset}-${end}` },
});
const reader = response.body.getReader();
let done, value;
while (!done) {
({ done, value } = await reader.read());
if (done) {
this.file.flush();
break;
}
const buf: ArrayBufferLike & { fileStart?: number } = value.buffer;
buf.fileStart = offset;
offset = this.file.appendBuffer(buf);
}
};
此代码段引用了一个 demuxer 类,我们使用该类将接口封装到 MP4Box 中。我们再次从 IndexedDB 访问该资源。这些区段不一定按字节顺序存储,并且 appendBuffer 方法会返回下一个区块的偏移量。
下面介绍了我们对视频帧进行解码的方式:
const getFrameFromVideoDecoder = async (demuxer: any): Promise<any> => {
let desiredSampleIndex = demuxer.getFrameIndexForTimestamp(this.frameTime);
let timestampToMatch: number;
let decodedSample: VideoFrame | null = null;
const outputCallback = (frame: VideoFrame) => {
if (frame.timestamp === timestampToMatch) decodedSample = frame;
else frame.close();
};
const decoder = new VideoDecoder({
output: outputCallback,
});
const {
codec,
codecWidth,
codecHeight,
description,
} = demuxer.getDecoderConfigurationInfo();
decoder.configure({ codec, codecWidth, codecHeight, description });
/* begin demuxer interface */
const preceedingKeyFrameIndex = demuxer.getPreceedingKeyFrameIndex(
desiredSampleIndex
);
const trak_id = demuxer.trak_id
const trak = demuxer.moov.traks.find((trak: any) => trak.tkhd.track_id === trak_id);
const data = await demuxer.getFrameDataRange(
preceedingKeyFrameIndex,
desiredSampleIndex
);
/* end demuxer interface */
for (let i = preceedingKeyFrameIndex; i <= desiredSampleIndex; i += 1) {
const sample = trak.samples[i];
const sampleData = data.readNBytes(
sample.offset,
sample.size
);
const sampleType = sample.is_sync ? 'key' : 'delta';
const encodedFrame = new EncodedVideoChunk({
sampleType,
timestamp: sample.cts,
duration: sample.duration,
samapleData,
});
if (i === desiredSampleIndex)
timestampToMatch = encodedFrame.timestamp;
decoder.decodeEncodedFrame(encodedFrame, i);
}
await decoder.flush();
return { type: 'value', value: decodedSample };
};
分路器的结构非常复杂,不在本文的讨论范围内。它会将每个帧存储在名为 samples 的数组中。我们使用分路器查找最接近所需时间戳的上一个关键帧,我们必须在该时间戳处开始进行视频解码。
视频由全帧(称为关键帧或 i-frame)和更小的增量帧(通常称为 p 帧或 b 帧)组成。解码必须始终从某个关键帧开始。
该应用通过以下方式对帧进行解码:
- 使用帧输出回调实例化解码器。
- 针对特定编解码器和输入分辨率配置解码器。
- 使用分路器中的数据创建
encodedVideoChunk。 - 调用
decodeEncodedFrame方法。
我们一直这样做,直到到达具有所需时间戳的帧。
后续操作
我们将前端的规模定义为随着项目规模越来越大、项目越来越复杂,我们能够保持精确且高性能的播放。扩缩性能的一种方法是一次装载尽可能少的视频,但是,这样做可能会导致过渡速度缓慢和连贯。虽然我们开发了内部系统来缓存视频组件以供重复使用,但在 HTML5 视频代码能够提供的控制机制方面存在一些限制。
将来,我们可能会尝试使用 WebCodecs 播放所有媒体。这样,我们就可以非常精确地确定缓冲哪些数据,从而帮助提升性能。
我们还可以更好地将大型触控板计算工作分流给Web 工作器,并且在预取文件和预生成帧方面可以变得更加智能。我们发现,有机会优化整体应用性能并使用 WebGL 等工具扩展功能。
我们希望继续投资 TensorFlow.js,它目前用于智能背景移除。我们计划将 TensorFlow.js 用于其他复杂任务,例如对象检测、特征提取、风格迁移等。
最终,我们很高兴能够在免费且开放的 Web 上继续打造具有原生态性能和功能的产品。