
The story of what shipped, how the impact was measured, and the tradeoffs that were made.

Published: June 20, 2019
Search for just about any topic on Google, and you're presented with an instantly recognizable page of meaningful, relevant results. What you probably didn't realize is that this search results page is, under certain scenarios, served by a powerful piece of web technology called a service worker.
Rolling out service worker support for Google Search without negatively impacting the performance required dozens of engineers working across multiple teams. This is the story of what shipped, how performance was measured, and what tradeoffs were made.
Key reasons for exploring service workers
Adding a service worker to a web app, just like making any architectural change to your site, should be done with a clear set of goals in mind. For the Google Search team, there were a few key reasons why adding a service worker was worth exploring.
Limited search result caching
The Google Search team found that it's common for users to search for the same terms more than once within a short period of time. Rather than trigger a new backend request just to get what's likely to be the same results, the Search team wanted to take advantage of caching and fulfill those repeat requests locally.
The importance of freshness can't be discounted, and sometimes users search for the same terms repeatedly because it's an evolving topic, and they expect to see fresh results. Using a service worker allows the Search team to implement fine-grained logic to control the lifetime of locally cached search results, and achieve the exact balance of speed vs. freshness that they believe best serves users.
Meaningful offline experience
Additionally, the Google Search team wanted to provide a meaningful offline experience. When a user wants to find out about a topic, they want to go straight to the Google Search page and start searching, without worrying about an active Internet connection.
Without a service worker, visiting the Google search page while offline would just lead to the browser's standard network error page, and users would have to remember to come back and try again once their connection returned. With a service worker, it's possible to serve a custom offline HTML response, and allow users to enter their search query immediately.
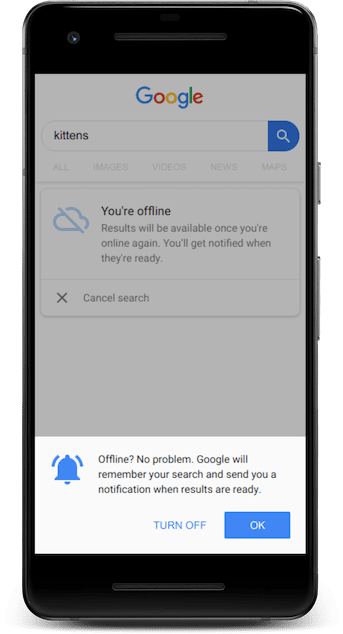
The results won't be available until there's an Internet connection, but the service worker allows the search to be deferred and sent to Google's servers as soon as the device goes back online using the background sync API.
Smarter JavaScript caching and serving
Another motivation was to optimize the caching and loading of the modularized JavaScript code that powers the various types of features on the search results page. There are a number of benefits offered by JavaScript bundling that make sense when there's no service worker involvement, so the Search team did not want to simply stop bundling entirely.
By using a service worker's ability to version and cache fine-grained chunks of JavaScript at runtime, the Search team suspected that they could reduce the amount of cache churn and ensure that JavaScript reused in the future can be cached efficiently. The logic inside of their service worker can analyze an outgoing HTTP request for a bundle that contains multiple JavaScript modules, and fulfill it by piecing together multiple, locally cached modules—effectively "unbundling" when possible. This saves user bandwidth, and improves overall responsiveness.
There are also performance benefits of using cached JavaScript served by a service worker: in Chrome, a parsed, byte code representation of that JavaScript is stored and reused, leading to less work that needs to be done at runtime in order to execute the JavaScript on the page.
Challenges and solutions
Here are a few of the hurdles that needed to be overcome in order to achieve the team's stated goals. While some of these challenges are specific to Google Search, many of them are applicable to a wide range of sites that might be considering a service worker deployment.
Problem: service worker overhead
The biggest challenge, and the one true blocker for launching a service worker on Google Search, was to ensure that it did not do anything that might increase user-perceived latency. Google Search takes performance very seriously, and in the past, has blocked launches of new functionality if it contributed even tens of milliseconds of additional latency for a given user population.
When the team started collecting performance data during their earliest experiments, it became obvious that there would be a problem. The HTML returned in response to navigation requests for the search result page is dynamic, and varies greatly depending on logic that needs to run on Search's web servers. There's currently no way for the service worker to replicate this logic and return cached HTML immediately—the best it could do is to pass along navigation requests to the backend web servers, which necessitates a network request.
Without a service worker, this network request happens immediately upon user
navigation. When a service worker is registered, it always needs to be started
up and given a chance to execute its
fetch event handlers,
even when there's no chance those fetch handlers will do anything other than go
to the network. The amount of time that it takes to start up and run the service
worker code is pure overhead added on top of every navigation:

This puts the service worker implementation at too much of a latency disadvantage to justify any other benefits. Additionally, the team found that, based on measuring service worker boot times on real-world devices, there was a wide distribution of startup times, with some low-end mobile devices taking almost as much time to start up the service worker as it might take to make the network request for the results page's HTML.
Solution: use navigation preload
The single, most crucial feature that allowed the Google Search team to move ahead with their service worker launch is navigation preload. Using navigation preload is a key performance win for any service worker that needs to use a response from the network to satisfy navigation requests. It provides a hint to the browser to start making the navigation request immediately, at the same time as the service worker starts up:

As long as the amount of time it takes for the service worker to start up is less than the amount of time it takes to get a response back from the network, there shouldn't be any latency overhead introduced by the service worker.
The Search team also needed to avoid using a service worker on low-end mobile devices where the service worker boot time could exceed the navigation request. Since there's no hard-and-fast rule for what constitutes a "low-end" device, they came up with the heuristic of checking the total RAM installed on the device. Anything less than 2 gigabytes of memory fell into their low-end device category, where service worker startup time would be unacceptable.
Available storage space is another consideration, since the full set of
resources to be cached for future use can run to several megabytes. The
navigator.storage interface
allows the Google Search page to figure out in advance whether their attempts to
cache data run the risk of failing due to storage quota failures.
This left the Search team with multiple pieces of criteria that they could use to determine whether or not to use a service worker: if a user comes to the Google Search page using a browser that supports navigation preload, and has at least 2 gigabytes of RAM, and enough free storage space, then a service worker is registered. Browsers or devices that don't meet that criteria won't end up with a service worker, but they'll still see the same Google Search experience as they always have.
One side benefit of this selective registration is the ability to ship a smaller, more efficient service worker. Targeting fairly modern browsers to run the service worker code eliminates the overhead of transpilation and polyfills for older browsers. This ended up cutting out around 8 kilobytes of uncompressed JavaScript code from the total size of the service worker's implementation.
Problem: service worker scopes
Once the Search team ran enough latency experiments and were confident that using navigation preload offered them a viable, latency-neutral path for using a service worker, some practical issues started moving to the forefront. One of those issues has to do with service worker's scoping rules. A service worker's scope determines which pages it can potentially take control of.
Scoping works based on the URL path prefix. For domains that host a single
web app, this isn't an issue, as you'd normally just use a service worker with
the maximal scope of /, which could take control of any page under the domain.
But Google Search's URL structure is a little more complicated.
If the service worker were given the maximal scope of /, it would end up being
able to take control of any page hosted under www.google.com (or the regional
equivalent), and there are URLs under that domain that have nothing to do with
Google Search. A more reasonable, restrictive scope would be /search, which at
least would eliminate URLs completely unrelated to search results.
Unfortunately, even that /search URL path is shared amongst different flavor
of Google Search results, with URL query parameters determining which specific
type of search result is shown. Some of those flavors use completely different
codebases than the traditional web search result page. For example, Image Search
and Shopping Search are both served under the /search URL path with different
query parameters, but neither of those interfaces were ready to ship their own
service worker experience (yet).
Solution: create a dispatch and routing framework
While there are some proposals that allow for something more powerful than URL path prefixes to determine service worker scopes, the Google Search team was stuck deploying a service worker that did nothing for a subset of pages it controlled.
To work around this, the Google Search team built up a bespoke dispatch and routing framework that could be configured to check for criteria like the query parameters of the client page, and use those to determine which specific code path to go down. Rather than hardcoding rules, the system was built to be flexible and allow teams that share the URL space, like Image Search and Shopping Search, to drop in their own service worker logic down the line, if they decide to implement it.
Problem: personalized results and metrics
Users can sign in to Google Search using their Google Accounts, and their search results experience may be customized based on their particular account data. Logged in users are identified by specific browser cookies, which is a venerable and widely-supported standard.
One downside of using browser cookies, though, is that they are not exposed inside of a service worker, and there is no way of automatically examining their values and ensuring that they have not changed due to a user logging out or switching accounts. (There is effort underway to bring cookie access to service workers, but as of this writing, the approach is experimental and is not widely supported.)
A mismatch between the service worker's view of the current logged in user and the actual user logged in to the Google Search web interface could lead to incorrectly personalized search results or misattributed metrics and logging. Any of those failure scenarios would be a serious issue for the Google Search team.
Solution: send cookies using postMessage
Rather than wait for experimental APIs to launch and provide direct access to
the browser's cookies inside of a service worker, the Google Search team went
with a stop-gap solution: whenever a page controlled by the service worker is
loaded, the page reads the relevant cookies and uses
postMessage()
to send them to the service worker.
The service worker then checks the current cookie value against the value that it expects, and if there's a mismatch, it takes steps to purge any user-specific data from its storage, and reloads the search results page without any incorrect personalization.
The specific steps that the service worker takes to reset things to a baseline are particular to Google Search's requirements, but the same general approach may be useful to other developers who deal with personalized data keyed off of browsers cookies.
Problem: experiments and dynamism
As mentioned, the Google Search team relies heavily on running experiments in production, and testing the effects of new code and features in the real world before turning them on by default. This can be a bit of a challenge with a static service worker that relies heavily on cached data, since opting users in and out of experiments often requires communication with the backend server.
Solution: dynamically generated service worker script
The solution that the team went with was to use a dynamically generated service worker script, customized by the web server for each individual user, instead of a single, static service worker script that gets generated ahead of time. Information about experiments that might affect the service worker's behavior or network requests in general are included directly in this customized service worker scripts. Changing the sets of active experiences for a user is done via a combination of traditional techniques, like browser cookies, as well as serving updated code in the registered service worker URL.
Using a dynamically generated service worker script also makes it easier to provide an escape hatch in the unlikely event that a service worker implementation has a fatal bug that needs to be avoided. The dynamic server worker response could be a no-op implementation, effectively disabling the service worker for some or all of the current users.
Problem: coordinating updates
One of the toughest challenges facing any real-world service worker deployment is to devise a reasonable tradeoff between avoiding the network in favor of the cache, while at the same time, ensuring that existing users get critical updates and changes soon after they're deployed to production. The right balance depends on a lot of factors:
- Whether your web app is a long-lived single page app that a user keeps open indefinitely, without navigating to new pages.
- What the deployment cadence is for updates to your backend web server.
- Whether the average user would tolerate using a slightly out-of-date version of your web app, or whether freshness is the top priority.
While experimenting with service workers, the Google Search team made sure to keep the experiments running across a number of scheduled backend updates, to ensure that the metrics and user experience would more closely match what return users would end up seeing in the real-world.
Solution: balance freshness and cache-utilization
After testing a number of different configuration options, the Google Search team found that the following setup provided the right balance between freshness and cache-utilization.
The service worker script URL is served with the
Cache-Control: private, max-age=1500 (1500 seconds, or 25 minutes) response
header, and is
registered with updateViaCache set to 'all'
to ensure that the header is honored. The Google Search web backend is, as you
might imagine, a large, globally distributed set of servers that requires as
close to 100% uptime as possible. Deploying a change that would affect the
service worker script's contents is done in a rolling fashion.
If a user hits a backend that has been updated, and then quickly navigates to another page which hits a backend that hasn't yet received the updated service worker, they'd end up flip-flopping between versions multiple times. Therefore, telling the browser to only bother checking for an updated script if 25 minutes has passed since the last check does not have a significant downside. The upside of opting-in to this behavior is cutting down significantly on the traffic received by the endpoint that dynamically generates the service worker script.
Additionally, an ETag header is set on the service worker script's HTTP response, ensuring that when an update check is made after 25 minutes has passed, the server can respond efficiently with an HTTP 304 response if there haven't been any updates to the service worker deployed in the interim.
While some interactions within the Google Search web app use single page
app-style navigations (i.e. via the
History API),
for the most part, Google Search is a traditional web app that uses "real"
navigations. This comes into play when the team decided that it would be
effective to use two options that accelerate the service worker update
lifecycle:
clients.claim()
and
skipWaiting().
Clicking around Google Search's interface generally ends up navigating to new
HTML documents. Calling skipWaiting ensures that an updated service worker
gets a chance to handle those new navigation requests immediately after
installation. Similarly, calling clients.claim() means that the updated
service worker gets a chance to start controlling any open Google Search pages
that are uncontrolled, following service worker activation.
The approach that Google Search went with isn't necessarily a solution that
works for everyone—it was the result of carefully A/B testing various
combinations of serving options until they found what worked best for them.
Developers whose backend infrastructure allow them to deploy updates more
quickly might prefer that the browser check for an updated service worker script
as frequently as possible, by
always ignoring the HTTP cache.
If you're building a single page app that users will might keep open for a long
period of time, using skipWaiting() is probably not the right choice for
you—you
risk running into cache inconsistencies
if you allow the new service worker to activate while there are long-lived
clients.
Key Takeaways
By default, service workers aren't performance neutral
Adding a service worker to your web app means inserting an additional piece of JavaScript that needs to be loaded and executed before your web app gets responses to its requests. If those responses end up coming from a local cache rather than from the network, then the overhead of running the service worker is usually negligible in comparison to the performance win from going cache-first. But if you know that your service worker always has to consult the network when handling navigation requests, using navigation preload is a crucial performance win.
Service workers are (still!) a progressive enhancement
The service worker support story is much brighter today than it was even a year ago. All modern browsers now feature at least some support for service workers, but unfortunately, there are some advanced service worker features—like background sync and navigation preload—that aren't rolled out universally. Feature checking for the specific subset of features that you know you need, and only registering a service worker when those are present, is still a reasonable approach to take.
Similarly, if you've run experiments in the wild, and know that low-end devices end up performing poorly with the additional overhead of a service worker, you can abstain from registering a service worker in those scenarios as well.
You should continue to treat service workers as a progressive enhancement that gets added to a web app when all the prerequisites are met and the service worker adds something positive to user experience and overall loading performance.
Measure everything
The only way you can figure out whether shipping a service worker has had a positive or negative impact on your users' experiences is to experiment and measure the results.
The specifics of setting up meaningful measurements depends on what analytics provider you're using, and how you normally conduct experiments in your deployment setup. One approach, using Google Analytics to collect metrics, is detailed in this case study based on the experience using service workers in the Google I/O web app.
Non-goals
While many in the web development community associate service workers with Progressive Web Apps, building a "Google Search PWA" was not an initial goal of the team. The Google Search web app doesn't provide metadata in a web app manifest, nor does it encourage users to go through the Add to Home Screen flow. The Search team is satisfied with users coming to their web app with the classic entry points for Google Search.
Rather than trying to turn the Google Search web experience into the equivalent of what you'd expect from an installed application, the focus on the initial release was to progressively enhance the existing web site.
Acknowledgements
Thanks to the entire Google Search web development team for their work on the service worker implementation, and for sharing the background material that went into writing this. Particular thanks goes to Philippe Golle, Rajesh Jagannathan, R. Samuel Klatchko, Andy Martone, Leonardo Peña, Rachel Shearer, Greg Terrono, and Clay Woolam.
Update (Oct. 2021): Since this article was originally published, the Google Search team has reevaluated the benefits and tradeoffs of their current service worker architecture. The service worker described above is being retired. As the Google Search web infrastructure evolves, the team may revisit their service worker design.