
Les créateurs peuvent désormais modifier des contenus vidéo de haute qualité sur le Web avec Kapwing, grâce à des API puissantes (comme IndexedDB et WebCodecs) et à des outils de performances.

La consommation de vidéos en ligne a augmenté rapidement depuis le début de la pandémie. Les utilisateurs passent plus de temps à regarder des vidéos de haute qualité à l'infini sur des plates-formes telles que TikTok, Instagram et YouTube. Les créateurs et les propriétaires de petites entreprises du monde entier ont besoin d'outils rapides et faciles à utiliser pour créer des contenus vidéo.
Des entreprises comme Kapwing permettent de créer tous ces contenus vidéo directement sur le Web, à l'aide des dernières API et outils de performances performants.
À propos de Kapwing
Kapwing est un éditeur vidéo collaboratif basé sur le Web, conçu principalement pour les créateurs occasionnels tels que les streamers de jeux, les musiciens, les créateurs YouTube et les créateurs de mèmes. Il s'agit également d'une ressource de référence pour les propriétaires d'entreprises qui ont besoin d'un moyen simple de produire leurs propres contenus sur les réseaux sociaux, comme des annonces Facebook et Instagram.
Les utilisateurs découvrent Kapwing en effectuant une recherche pour une tâche spécifique, par exemple "comment couper une vidéo", "ajouter de la musique à ma vidéo" ou "redimensionner une vidéo". Ils peuvent effectuer ce qu'ils recherchent en un seul clic, sans avoir à accéder à une plate-forme de téléchargement d'applications et à télécharger une application. Le Web permet aux utilisateurs de rechercher précisément la tâche à laquelle ils ont besoin d'aide, puis de l'effectuer.
Après ce premier clic, les utilisateurs de Kapwing peuvent faire bien plus. Ils peuvent explorer des modèles sans frais, ajouter de nouvelles couches de vidéos libres de droits, insérer des sous-titres, transcrire des vidéos et importer de la musique de fond.
Comment Kapwing apporte la collaboration et l'édition en temps réel sur le Web
Bien que le Web présente des avantages uniques, il présente également des défis distincts. Kapwing doit assurer la lecture fluide et précise de projets complexes à plusieurs niveaux sur un large éventail d'appareils et de conditions réseau. Pour ce faire, nous utilisons diverses API Web pour atteindre nos objectifs de performances et de fonctionnalités.
IndexedDB
Le montage hautes performances nécessite que tous les contenus de nos utilisateurs soient hébergés sur le client, en évitant le réseau dans la mesure du possible. Contrairement à un service de streaming, où les utilisateurs accèdent généralement à un contenu une seule fois, nos clients réutilisent fréquemment leurs composants, des jours, voire des mois après leur importation.
IndexedDB nous permet de fournir un stockage persistant semblable à un système de fichiers à nos utilisateurs. Par conséquent, plus de 90% des requêtes multimédias de l'application sont traitées localement. L'intégration d'IndexedDB à notre système a été très simple.
Voici un code d'initialisation standard qui s'exécute lors du chargement de l'application:
import {DBSchema, openDB, deleteDB, IDBPDatabase} from 'idb';
let openIdb: Promise <IDBPDatabase<Schema>>;
const db =
(await openDB) <
Schema >
(
'kapwing',
version, {
upgrade(db, oldVersion) {
if (oldVersion >= 1) {
// assets store schema changed, need to recreate
db.deleteObjectStore('assets');
}
db.createObjectStore('assets', {
keyPath: 'mediaLibraryID'
});
},
async blocked() {
await deleteDB('kapwing');
},
async blocking() {
await deleteDB('kapwing');
},
}
);
Nous transmettons une version et définissons une fonction upgrade. Cette méthode est utilisée pour l'initialisation ou pour mettre à jour notre schéma si nécessaire. Nous transmettons des rappels de gestion des erreurs, blocked et blocking, qui nous ont semblé utiles pour éviter les problèmes des utilisateurs disposant de systèmes instables.
Enfin, notez notre définition d'une clé primaire keyPath. Dans notre cas, il s'agit d'un ID unique que nous appelons mediaLibraryID. Lorsqu'un utilisateur ajoute un contenu multimédia à notre système, que ce soit via notre outil d'importation ou une extension tierce, nous l'ajoutons à notre bibliothèque multimédia à l'aide du code suivant:
export async function addAsset(mediaLibraryID: string, file: File) {
return runWithAssetMutex(mediaLibraryID, async () => {
const assetAlreadyInStore = await (await openIdb).get(
'assets',
mediaLibraryID
);
if (assetAlreadyInStore) return;
const idbVideo: IdbVideo = {
file,
mediaLibraryID,
};
await (await openIdb).add('assets', idbVideo);
});
}
runWithAssetMutex est notre propre fonction définie en interne qui sérialise l'accès à IndexedDB. Cela est nécessaire pour toutes les opérations de type lecture-modification-écriture, car l'API IndexedDB est asynchrone.
Voyons maintenant comment accéder aux fichiers. Voici notre fonction getAsset:
export async function getAsset(
mediaLibraryID: string,
source: LayerSource | null | undefined,
location: string
): Promise<IdbAsset | undefined> {
let asset: IdbAsset | undefined;
const { idbCache } = window;
const assetInCache = idbCache[mediaLibraryID];
if (assetInCache && assetInCache.status === 'complete') {
asset = assetInCache.asset;
} else if (assetInCache && assetInCache.status === 'pending') {
asset = await new Promise((res) => {
assetInCache.subscribers.push(res);
});
} else {
idbCache[mediaLibraryID] = { subscribers: [], status: 'pending' };
asset = (await openIdb).get('assets', mediaLibraryID);
idbCache[mediaLibraryID].asset = asset;
idbCache[mediaLibraryID].subscribers.forEach((res: any) => {
res(asset);
});
delete (idbCache[mediaLibraryID] as any).subscribers;
if (asset) {
idbCache[mediaLibraryID].status = 'complete';
} else {
idbCache[mediaLibraryID].status = 'failed';
}
}
return asset;
}
Nous disposons de notre propre structure de données, idbCache, qui permet de réduire les accès IndexedDB. Bien que IndexedDB soit rapide, l'accès à la mémoire locale est encore plus rapide. Nous vous recommandons cette approche tant que vous gérez la taille du cache.
Le tableau subscribers, qui permet d'empêcher l'accès simultané à IndexedDB, serait autrement courant lors du chargement.
API Web Audio
La visualisation audio est extrêmement importante pour le montage vidéo. Pour comprendre pourquoi, regardez une capture d'écran de l'éditeur:
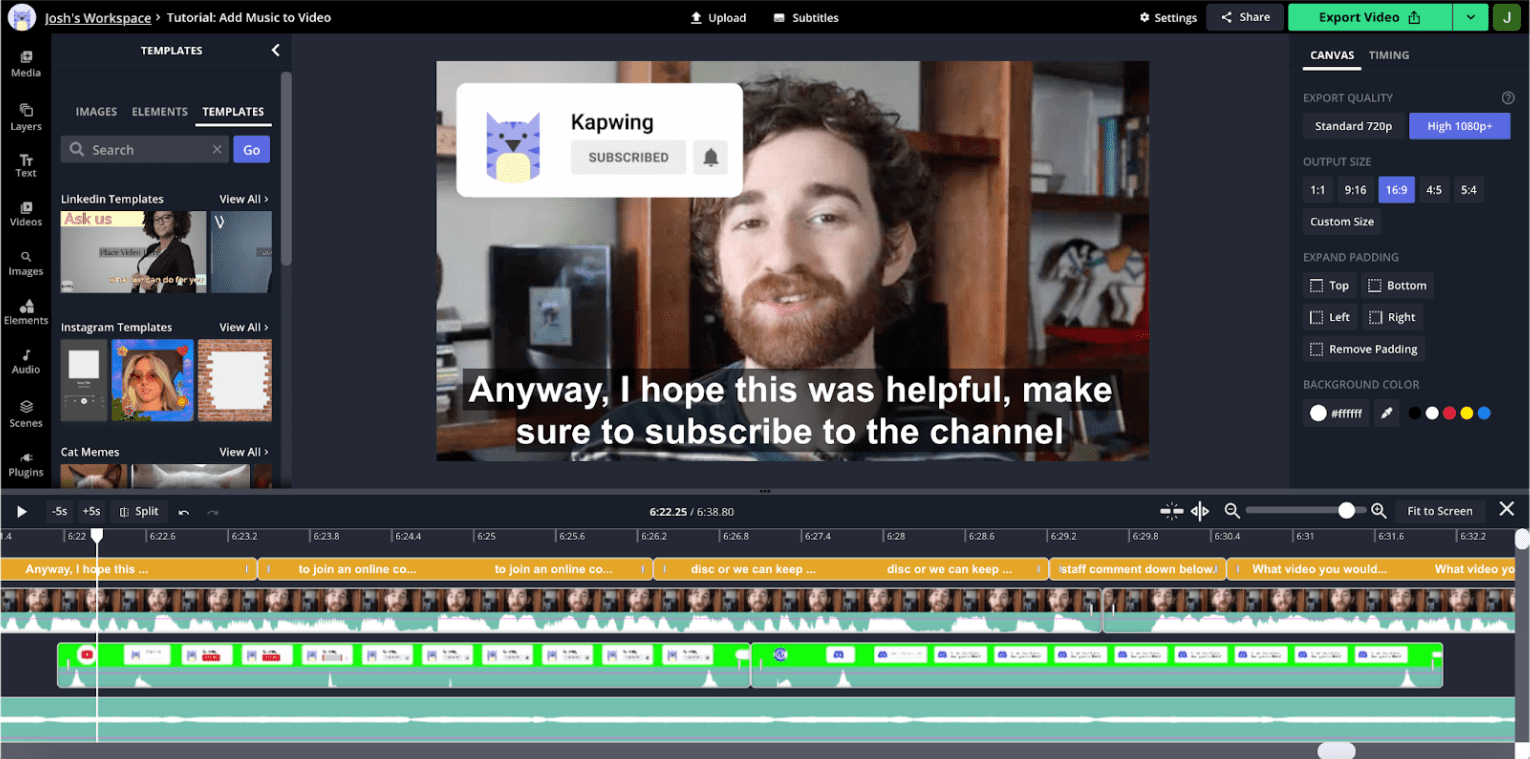
Il s'agit d'une vidéo de style YouTube, ce qui est courant dans notre application. L'utilisateur ne bouge pas beaucoup tout au long du clip. Par conséquent, les miniatures visuelles des chronologies ne sont pas aussi utiles pour naviguer entre les sections. En revanche, la forme d'onde audio affiche des pics et des creux, les creux correspondant généralement à des temps morts dans l'enregistrement. Si vous faites un zoom avant sur la timeline, vous verrez des informations audio plus précises, avec des creux correspondant aux à-coups et aux pauses.
Nos recherches sur l'expérience utilisateur montrent que les créateurs sont souvent guidés par ces formes d'onde lorsqu'ils assemblent leurs contenus. L'API Web Audio nous permet de présenter ces informations de manière performante et de les mettre à jour rapidement en cas de zoom ou de panoramique sur la timeline.
L'extrait de code ci-dessous montre comment procéder:
const getDownsampledBuffer = (idbAsset: IdbAsset) =>
decodeMutex.runExclusive(
async (): Promise<Float32Array> => {
const arrayBuffer = await idbAsset.file.arrayBuffer();
const audioContext = new AudioContext();
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
const offline = new OfflineAudioContext(
audioBuffer.numberOfChannels,
audioBuffer.duration * MIN_BROWSER_SUPPORTED_SAMPLE_RATE,
MIN_BROWSER_SUPPORTED_SAMPLE_RATE
);
const downsampleSource = offline.createBufferSource();
downsampleSource.buffer = audioBuffer;
downsampleSource.start(0);
downsampleSource.connect(offline.destination);
const downsampledBuffer22K = await offline.startRendering();
const downsampledBuffer22KData = downsampledBuffer22K.getChannelData(0);
const downsampledBuffer = new Float32Array(
Math.floor(
downsampledBuffer22KData.length / POST_BROWSER_SAMPLE_INTERVAL
)
);
for (
let i = 0, j = 0;
i < downsampledBuffer22KData.length;
i += POST_BROWSER_SAMPLE_INTERVAL, j += 1
) {
let sum = 0;
for (let k = 0; k < POST_BROWSER_SAMPLE_INTERVAL; k += 1) {
sum += Math.abs(downsampledBuffer22KData[i + k]);
}
const avg = sum / POST_BROWSER_SAMPLE_INTERVAL;
downsampledBuffer[j] = avg;
}
return downsampledBuffer;
}
);
Nous transmettons à cet assistant l'élément stocké dans IndexedDB. Une fois l'opération terminée, nous mettrons à jour l'élément dans IndexedDB ainsi que notre propre cache.
Nous recueillons des données sur le audioBuffer avec le constructeur AudioContext, mais comme nous n'effectuons pas de rendu sur le matériel de l'appareil, nous utilisons le OfflineAudioContext pour effectuer un rendu sur un ArrayBuffer dans lequel nous stockerons les données d'amplitude.
L'API elle-même renvoie des données à un taux d'échantillonnage beaucoup plus élevé que nécessaire pour une visualisation efficace. C'est pourquoi nous avons réduit manuellement la fréquence d'échantillonnage à 200 Hz, ce qui nous a semblé suffisant pour obtenir des formes d'onde utiles et visuellement attrayantes.
WebCodecs
Pour certaines vidéos, les miniatures des pistes sont plus utiles pour la navigation dans la timeline que les formes d'onde. Toutefois, la génération de miniatures est plus gourmande en ressources que la génération de formes d'onde.
Nous ne pouvons pas mettre en cache toutes les miniatures potentielles au chargement. Par conséquent, un décodage rapide lors du panoramique/zoom de la timeline est essentiel pour une application performante et réactive. Le goulot d'étranglement pour obtenir un dessin de frame fluide est le décodage des frames, que nous effectuions jusqu'à récemment à l'aide d'un lecteur vidéo HTML5. Les performances de cette approche n'étaient pas fiables, et nous avons souvent constaté une dégradation de la réactivité de l'application lors du rendu des frames.
Nous avons récemment migré vers WebCodecs, qui peut être utilisé dans les web workers. Cela devrait améliorer notre capacité à dessiner des miniatures pour de grandes quantités de calques sans affecter les performances du thread principal. Bien que l'implémentation du thread de travail Web soit toujours en cours, nous vous présentons ci-dessous un aperçu de notre implémentation du thread principal existant.
Un fichier vidéo contient plusieurs flux: vidéo, audio, sous-titres, etc., qui sont "multiplexés". Pour utiliser WebCodecs, nous devons d'abord disposer d'un flux vidéo démultiplexé. Nous démultiplexons les fichiers MP4 avec la bibliothèque mp4box, comme indiqué ci-dessous:
async function create(demuxer: any) {
demuxer.file = (await MP4Box).createFile();
demuxer.file.onReady = (info: any) => {
demuxer.info = info;
demuxer._info_resolver(info);
};
demuxer.loadMetadata();
}
const loadMetadata = async () => {
let offset = 0;
const asset = await getAsset(this.mediaLibraryId, null, this.url);
const maxFetchOffset = asset?.file.size || 0;
const end = offset + FETCH_SIZE;
const response = await fetch(this.url, {
headers: { range: `bytes=${offset}-${end}` },
});
const reader = response.body.getReader();
let done, value;
while (!done) {
({ done, value } = await reader.read());
if (done) {
this.file.flush();
break;
}
const buf: ArrayBufferLike & { fileStart?: number } = value.buffer;
buf.fileStart = offset;
offset = this.file.appendBuffer(buf);
}
};
Cet extrait fait référence à une classe demuxer, que nous utilisons pour encapsuler l'interface dans MP4Box. Nous accédons à nouveau à l'asset à partir d'IndexedDB. Ces segments ne sont pas nécessairement stockés dans l'ordre des octets, et la méthode appendBuffer renvoie le décalage du segment suivant.
Voici comment nous décodons un frame vidéo:
const getFrameFromVideoDecoder = async (demuxer: any): Promise<any> => {
let desiredSampleIndex = demuxer.getFrameIndexForTimestamp(this.frameTime);
let timestampToMatch: number;
let decodedSample: VideoFrame | null = null;
const outputCallback = (frame: VideoFrame) => {
if (frame.timestamp === timestampToMatch) decodedSample = frame;
else frame.close();
};
const decoder = new VideoDecoder({
output: outputCallback,
});
const {
codec,
codecWidth,
codecHeight,
description,
} = demuxer.getDecoderConfigurationInfo();
decoder.configure({ codec, codecWidth, codecHeight, description });
/* begin demuxer interface */
const preceedingKeyFrameIndex = demuxer.getPreceedingKeyFrameIndex(
desiredSampleIndex
);
const trak_id = demuxer.trak_id
const trak = demuxer.moov.traks.find((trak: any) => trak.tkhd.track_id === trak_id);
const data = await demuxer.getFrameDataRange(
preceedingKeyFrameIndex,
desiredSampleIndex
);
/* end demuxer interface */
for (let i = preceedingKeyFrameIndex; i <= desiredSampleIndex; i += 1) {
const sample = trak.samples[i];
const sampleData = data.readNBytes(
sample.offset,
sample.size
);
const sampleType = sample.is_sync ? 'key' : 'delta';
const encodedFrame = new EncodedVideoChunk({
sampleType,
timestamp: sample.cts,
duration: sample.duration,
samapleData,
});
if (i === desiredSampleIndex)
timestampToMatch = encodedFrame.timestamp;
decoder.decodeEncodedFrame(encodedFrame, i);
}
await decoder.flush();
return { type: 'value', value: decodedSample };
};
La structure du démultiplexeur est assez complexe et dépasse le cadre de cet article. Il stocke chaque frame dans un tableau intitulé samples. Nous utilisons le démultiplexeur pour trouver le frame clé précédent le plus proche du code temporel souhaité, à partir duquel nous devons commencer le décodage vidéo.
Les vidéos sont composées de trames complètes, appelées trames clés ou trames I, ainsi que de trames delta beaucoup plus petites, souvent appelées trames P ou trames B. Le décodage doit toujours commencer à un frame clé.
L'application décode les images en procédant comme suit:
- Instanciation du décodeur avec un rappel de sortie de frame.
- Configurer le décodeur pour le codec et la résolution d'entrée spécifiques
- Création d'un
encodedVideoChunkà l'aide des données du démultiplexeur. - En appelant la méthode
decodeEncodedFrame.
Nous répétons cette opération jusqu'à ce que nous atteignions le frame avec le code temporel souhaité.
Étape suivante
Nous définissons l'échelle sur notre interface avant comme la capacité à maintenir une lecture précise et performante à mesure que les projets deviennent plus volumineux et plus complexes. Une façon d'améliorer les performances consiste à monter le moins de vidéos possible à la fois. Toutefois, nous risquons alors de ralentir et de hacher les transitions. Bien que nous ayons développé des systèmes internes pour mettre en cache les composants vidéo à des fins de réutilisation, le contrôle que les balises vidéo HTML5 peuvent fournir est limité.
À l'avenir, nous tenterons peut-être de lire tous les contenus multimédias à l'aide de WebCodecs. Cela pourrait nous permettre d'être très précis sur les données que nous mettons en mémoire tampon, ce qui devrait aider à faire évoluer les performances.
Nous pouvons également mieux décharger les grands calculs du pavé tactile sur les workers Web, et nous pouvons être plus intelligents en préchargeant les fichiers et en prégénérant les frames. Nous voyons de grandes opportunités d'optimiser les performances globales de nos applications et d'étendre les fonctionnalités avec des outils tels que WebGL.
Nous souhaitons poursuivre nos investissements dans TensorFlow.js, que nous utilisons actuellement pour supprimer intelligemment l'arrière-plan. Nous prévoyons d'exploiter TensorFlow.js pour d'autres tâches sophistiquées telles que la détection d'objets, l'extraction de caractéristiques, le transfert de style, etc.
Nous sommes ravis de continuer à développer notre produit avec des performances et des fonctionnalités semblables à celles des applications natives sur un Web sans frais et ouvert.