
Agora os criadores de conteúdo podem editar conteúdo de vídeo de alta qualidade na Web com o Kapwing, graças a APIs poderosas (como IndexedDB e WebCodecs) e ferramentas de performance.

O consumo de vídeos on-line cresceu rapidamente desde o início da pandemia. As pessoas estão passando mais tempo consumindo vídeos infinitos de alta qualidade em plataformas como TikTok, Instagram e YouTube. Profissionais de criação e proprietários de pequenas empresas em todo o mundo precisam de ferramentas rápidas e fáceis de usar para criar conteúdo em vídeo.
Empresas como a Kapwing permitem criar todo esse conteúdo de vídeo na Web usando as APIs e ferramentas de performance mais recentes.
Sobre a Kapwing
O Kapwing é um editor de vídeo colaborativo baseado na Web projetado principalmente para criativos casuais, como streamers de jogos, músicos, criadores de conteúdo do YouTube e criadores de memes. Ele também é um recurso importante para proprietários de empresas que precisam de uma maneira fácil de produzir o próprio conteúdo para mídias sociais, como anúncios do Facebook e do Instagram.
As pessoas descobrem o Kapwing ao pesquisar uma tarefa específica, por exemplo,"como cortar um vídeo", "adicionar música ao meu vídeo" ou "redimensionar um vídeo". Elas podem fazer o que procuraram com apenas um clique, sem a fricção adicional de navegar até uma app store e fazer o download de um app. A Web facilita para as pessoas pesquisarem exatamente a tarefa que precisam de ajuda e depois fazerem isso.
Depois desse primeiro clique, os usuários do Kapwing podem fazer muito mais. Eles podem acessar modelos sem custo financeiro, adicionar novas camadas de vídeos de estoque, inserir legendas, transcrever vídeos e fazer upload de músicas de fundo.
Como o Kapwing traz edição e colaboração em tempo real para a Web
Embora a Web ofereça vantagens exclusivas, ela também apresenta desafios diferentes. O Kapwing precisa oferecer uma reprodução suave e precisa de projetos complexos com várias camadas em uma ampla variedade de dispositivos e condições de rede. Para isso, usamos várias APIs da Web para alcançar nossas metas de desempenho e recursos.
IndexedDB
A edição de alto desempenho exige que todo o conteúdo dos usuários esteja disponível no cliente, evitando a rede sempre que possível. Ao contrário de um serviço de streaming, em que os usuários geralmente acessam um conteúdo uma vez, nossos clientes reutilizam os recursos com frequência, dias e até meses após o upload.
O IndexedDB permite oferecer armazenamento semelhante a um sistema de arquivos aos usuários. O resultado é que mais de 90% das solicitações de mídia no app são atendidas localmente. A integração do IndexedDB ao nosso sistema foi muito simples.
Confira um código de inicialização de modelo que é executado ao carregar o app:
import {DBSchema, openDB, deleteDB, IDBPDatabase} from 'idb';
let openIdb: Promise <IDBPDatabase<Schema>>;
const db =
(await openDB) <
Schema >
(
'kapwing',
version, {
upgrade(db, oldVersion) {
if (oldVersion >= 1) {
// assets store schema changed, need to recreate
db.deleteObjectStore('assets');
}
db.createObjectStore('assets', {
keyPath: 'mediaLibraryID'
});
},
async blocked() {
await deleteDB('kapwing');
},
async blocking() {
await deleteDB('kapwing');
},
}
);
Transmitimos uma versão e definimos uma função upgrade. Ele é usado para
inicializar ou atualizar o esquema quando necessário. Transmitimos callbacks de tratamento de erros, blocked e blocking, que foram úteis para evitar problemas para usuários com sistemas instáveis.
Por fim, observe nossa definição de uma chave primária keyPath. No nosso caso, esse é um
ID exclusivo chamado mediaLibraryID. Quando um usuário adiciona um conteúdo ao nosso sistema, seja pelo nosso uploader ou por uma extensão de terceiros, adicionamos o conteúdo
à nossa biblioteca com o seguinte código:
export async function addAsset(mediaLibraryID: string, file: File) {
return runWithAssetMutex(mediaLibraryID, async () => {
const assetAlreadyInStore = await (await openIdb).get(
'assets',
mediaLibraryID
);
if (assetAlreadyInStore) return;
const idbVideo: IdbVideo = {
file,
mediaLibraryID,
};
await (await openIdb).add('assets', idbVideo);
});
}
runWithAssetMutex é a nossa própria função definida internamente que serializa
o acesso ao IndexedDB. Isso é necessário para qualquer operação do tipo leitura-modificação-gravação,
já que a API IndexedDB é assíncrona.
Agora vamos conferir como acessar arquivos. Confira abaixo nossa função getAsset:
export async function getAsset(
mediaLibraryID: string,
source: LayerSource | null | undefined,
location: string
): Promise<IdbAsset | undefined> {
let asset: IdbAsset | undefined;
const { idbCache } = window;
const assetInCache = idbCache[mediaLibraryID];
if (assetInCache && assetInCache.status === 'complete') {
asset = assetInCache.asset;
} else if (assetInCache && assetInCache.status === 'pending') {
asset = await new Promise((res) => {
assetInCache.subscribers.push(res);
});
} else {
idbCache[mediaLibraryID] = { subscribers: [], status: 'pending' };
asset = (await openIdb).get('assets', mediaLibraryID);
idbCache[mediaLibraryID].asset = asset;
idbCache[mediaLibraryID].subscribers.forEach((res: any) => {
res(asset);
});
delete (idbCache[mediaLibraryID] as any).subscribers;
if (asset) {
idbCache[mediaLibraryID].status = 'complete';
} else {
idbCache[mediaLibraryID].status = 'failed';
}
}
return asset;
}
Temos nossa própria estrutura de dados, idbCache, que é usada para minimizar os acessos
do IndexedDB. Embora o IndexedDB seja rápido, o acesso à memória local é mais rápido. Recomendamos
essa abordagem desde que você gerencie o tamanho do cache.
A matriz subscribers, que é usada para impedir o acesso simultâneo ao
IndexedDB, seria comum no carregamento.
API Web Audio
A visualização de áudio é extremamente importante para a edição de vídeo. Para entender por que, confira uma captura de tela do editor:
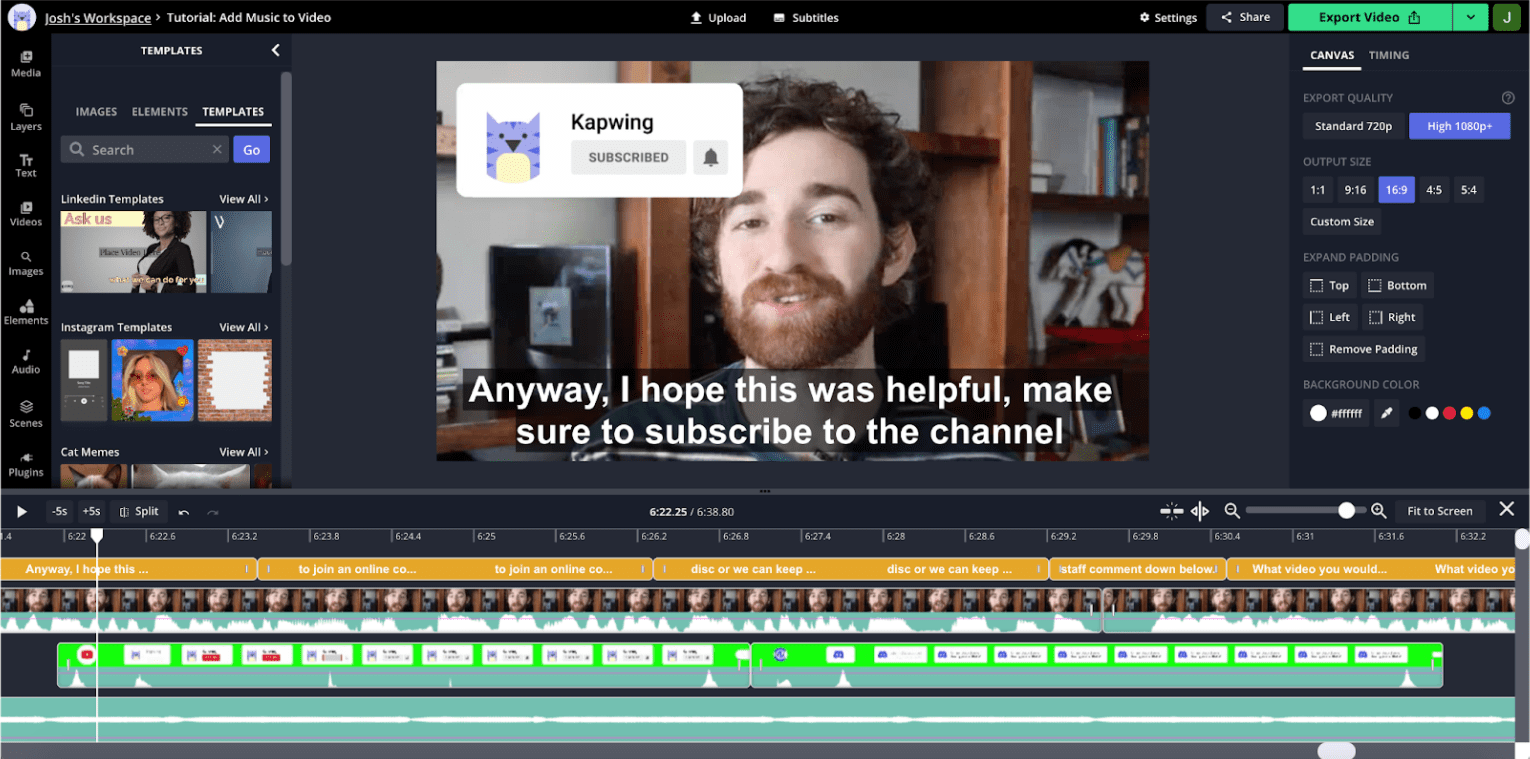
Este é um vídeo no estilo do YouTube, que é comum no nosso app. O usuário não se move muito ao longo do clipe, então as miniaturas visuais das linhas do tempo não são tão úteis para navegar entre as seções. Por outro lado, a forma de onda de áudio mostra picos e vales, com os vales normalmente correspondendo ao tempo morto na gravação. Se você aumentar o zoom na linha do tempo, vai ver informações de áudio mais detalhadas com vales correspondentes a interrupções e pausas.
Nossa pesquisa de usuário mostra que os criadores de conteúdo geralmente são guiados por essas formas de onda ao dividir o conteúdo. A API Web Audio permite apresentar essas informações com eficiência e atualizar rapidamente em um zoom ou pan da linha do tempo.
O snippet abaixo demonstra como fazer isso:
const getDownsampledBuffer = (idbAsset: IdbAsset) =>
decodeMutex.runExclusive(
async (): Promise<Float32Array> => {
const arrayBuffer = await idbAsset.file.arrayBuffer();
const audioContext = new AudioContext();
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
const offline = new OfflineAudioContext(
audioBuffer.numberOfChannels,
audioBuffer.duration * MIN_BROWSER_SUPPORTED_SAMPLE_RATE,
MIN_BROWSER_SUPPORTED_SAMPLE_RATE
);
const downsampleSource = offline.createBufferSource();
downsampleSource.buffer = audioBuffer;
downsampleSource.start(0);
downsampleSource.connect(offline.destination);
const downsampledBuffer22K = await offline.startRendering();
const downsampledBuffer22KData = downsampledBuffer22K.getChannelData(0);
const downsampledBuffer = new Float32Array(
Math.floor(
downsampledBuffer22KData.length / POST_BROWSER_SAMPLE_INTERVAL
)
);
for (
let i = 0, j = 0;
i < downsampledBuffer22KData.length;
i += POST_BROWSER_SAMPLE_INTERVAL, j += 1
) {
let sum = 0;
for (let k = 0; k < POST_BROWSER_SAMPLE_INTERVAL; k += 1) {
sum += Math.abs(downsampledBuffer22KData[i + k]);
}
const avg = sum / POST_BROWSER_SAMPLE_INTERVAL;
downsampledBuffer[j] = avg;
}
return downsampledBuffer;
}
);
Transmitimos a esse auxiliar o recurso armazenado no IndexedDB. Após a conclusão, vamos atualizar o recurso no IndexedDB e no nosso próprio cache.
Coletamos dados sobre o audioBuffer com o construtor AudioContext,
mas, como não renderizamos para o hardware do dispositivo, usamos o
OfflineAudioContext para renderizar para um ArrayBuffer, onde armazenaremos
dados de amplitude.
A API retorna dados com uma taxa de amostragem muito maior do que o necessário para uma visualização eficaz. Por isso, reduzimos manualmente a amostragem para 200 Hz, o que achamos suficiente para formas de onda úteis e visualmente atraentes.
WebCodecs
Em alguns vídeos, as miniaturas das faixas são mais úteis para a navegação na linha do tempo do que as formas de onda. No entanto, a geração de miniaturas consome mais recursos do que a geração de formas de onda.
Não podemos armazenar em cache todas as miniaturas possíveis no carregamento. Portanto, a decodificação rápida na panorâmica/zoom da linha do tempo é essencial para um aplicativo responsivo e com bom desempenho. O gargalo para conseguir uma exibição de frames suave é a decodificação de frames, que até recentemente fazíamos usando um player de vídeo HTML5. O desempenho dessa abordagem não era confiável e, muitas vezes, a capacidade de resposta do app era prejudicada durante a renderização de frames.
Recentemente, migramos para os WebCodecs, que podem ser usados em workers da Web. Isso vai melhorar nossa capacidade de desenhar miniaturas para grandes quantidades de camadas sem afetar a performance da linha de execução principal. Enquanto a implementação do worker da Web ainda está em andamento, apresentamos abaixo um esboço da nossa implementação de linha de execução principal atual.
Um arquivo de vídeo contém vários streams: vídeo, áudio, legendas e assim por diante, que são "muxados" juntos. Para usar o WebCodecs, primeiro precisamos ter um fluxo de vídeo desmuxado. Demuximos mp4s com a biblioteca mp4box, conforme mostrado aqui:
async function create(demuxer: any) {
demuxer.file = (await MP4Box).createFile();
demuxer.file.onReady = (info: any) => {
demuxer.info = info;
demuxer._info_resolver(info);
};
demuxer.loadMetadata();
}
const loadMetadata = async () => {
let offset = 0;
const asset = await getAsset(this.mediaLibraryId, null, this.url);
const maxFetchOffset = asset?.file.size || 0;
const end = offset + FETCH_SIZE;
const response = await fetch(this.url, {
headers: { range: `bytes=${offset}-${end}` },
});
const reader = response.body.getReader();
let done, value;
while (!done) {
({ done, value } = await reader.read());
if (done) {
this.file.flush();
break;
}
const buf: ArrayBufferLike & { fileStart?: number } = value.buffer;
buf.fileStart = offset;
offset = this.file.appendBuffer(buf);
}
};
Este snippet se refere a uma classe demuxer, que usamos para encapsular a
interface para MP4Box. Acesse o recurso novamente pelo IndexedDB. Esses
segmentos não são necessariamente armazenados na ordem de bytes, e o método appendBuffer
retorna o deslocamento do próximo bloco.
Veja como decodificamos um frame de vídeo:
const getFrameFromVideoDecoder = async (demuxer: any): Promise<any> => {
let desiredSampleIndex = demuxer.getFrameIndexForTimestamp(this.frameTime);
let timestampToMatch: number;
let decodedSample: VideoFrame | null = null;
const outputCallback = (frame: VideoFrame) => {
if (frame.timestamp === timestampToMatch) decodedSample = frame;
else frame.close();
};
const decoder = new VideoDecoder({
output: outputCallback,
});
const {
codec,
codecWidth,
codecHeight,
description,
} = demuxer.getDecoderConfigurationInfo();
decoder.configure({ codec, codecWidth, codecHeight, description });
/* begin demuxer interface */
const preceedingKeyFrameIndex = demuxer.getPreceedingKeyFrameIndex(
desiredSampleIndex
);
const trak_id = demuxer.trak_id
const trak = demuxer.moov.traks.find((trak: any) => trak.tkhd.track_id === trak_id);
const data = await demuxer.getFrameDataRange(
preceedingKeyFrameIndex,
desiredSampleIndex
);
/* end demuxer interface */
for (let i = preceedingKeyFrameIndex; i <= desiredSampleIndex; i += 1) {
const sample = trak.samples[i];
const sampleData = data.readNBytes(
sample.offset,
sample.size
);
const sampleType = sample.is_sync ? 'key' : 'delta';
const encodedFrame = new EncodedVideoChunk({
sampleType,
timestamp: sample.cts,
duration: sample.duration,
samapleData,
});
if (i === desiredSampleIndex)
timestampToMatch = encodedFrame.timestamp;
decoder.decodeEncodedFrame(encodedFrame, i);
}
await decoder.flush();
return { type: 'value', value: decodedSample };
};
A estrutura do demuxer é bastante complexa e está fora do escopo deste
artigo. Ele armazena cada frame em uma matriz intitulada samples. Usamos o demuxer
para encontrar o frame-chave anterior mais próximo do carimbo de data/hora desejado, onde precisamos iniciar a decodificação do vídeo.
Os vídeos são compostos por frames completos, conhecidos como chave ou i-frames, e frames delta muito menores, geralmente chamados de p-frames ou b-frames. A decodificação precisa sempre começar em um frame-chave.
O aplicativo decodifica os frames da seguinte maneira:
- Instância do decodificador com um callback de frame de saída.
- Configurar o decodificador para o codec e a resolução de entrada específicos.
- Criação de um
encodedVideoChunkusando dados do demuxer. - Chamando o método
decodeEncodedFrame.
Fazemos isso até chegarmos ao frame com o carimbo de data/hora desejado.
A seguir
Definimos a escala no front-end como a capacidade de manter a reprodução precisa e eficiente à medida que os projetos ficam maiores e mais complexos. Uma maneira de aumentar a performance é montar o menor número possível de vídeos de uma vez. No entanto, ao fazer isso, corremos o risco de ter transições lentas e irregulares. Embora tenhamos desenvolvido sistemas internos para armazenar em cache os componentes de vídeo para reutilização, há limitações quanto ao controle que as tags de vídeo HTML5 podem oferecer.
No futuro, vamos tentar reproduzir todos os arquivos de mídia usando o WebCodecs. Isso pode nos permitir ser muito precisos sobre quais dados armazenamos em buffer, o que deve ajudar a dimensionar a performance.
Também podemos fazer um trabalho melhor de transferência de grandes computações do trackpad para workers da Web e ser mais inteligentes sobre a pré-busca de arquivos e a pré-geração de frames. Vemos grandes oportunidades para otimizar o desempenho geral do aplicativo e estender a funcionalidade com ferramentas como o WebGL.
Queremos continuar investindo no TensorFlow.js, que usamos atualmente para remoção inteligente de plano de fundo. Planejamos usar o TensorFlow.js para outras tarefas sofisticadas, como detecção de objetos, extração de recursos, transferência de estilo e assim por diante.
Estamos felizes em continuar desenvolvendo nosso produto com desempenho e funcionalidade nativos em uma Web aberta e sem custo financeiro.