

While most AI features on the web rely on servers, client-side AI runs directly in the user's browser. This offers many benefits, including low latency, reduced server-side costs, no API key requirements, increased user privacy, and offline access. You can implement client-side AI that works across browsers with JavaScript libraries like TensorFlow.js, Transformers.js, and MediaPipe GenAI.
Client-side AI also introduces performance challenges: users have to download more files, and their browser has to work harder. To make it work well, consider:
- Your use case. Is client-side AI the right pick for your feature? Is your feature on a critical user journey, and if so, do you have a fallback?
- Good practices for model download and usage. Keep reading to learn more.
Before model download
Mind library and model size
To implement client-side AI you'll need a model and usually a library. When choosing the library, assess its size like you would any other tool.
Model size matters, too. What's considered large for an AI model depends. 5MB can be a useful rule of thumb: it's also the 75th percentile of the median web page size. A laxer number would be 10MB.
Here are some important considerations about model size:
- Many task-specific AI models can be really small. A model like BudouX, for accurate character breaking in Asian languages, is only 9.4KB GZipped. MediaPipe's language detection model is 315KB.
- Even vision models can be reasonably sized. The Handpose model and all related resources total 13.4MB. While this is much larger than most minified frontend packages, it's comparable to the median web page, which is 2.2MB (2.6MB on desktop).
- Gen AI models can exceed the recommended size for web resources. DistilBERT, which is considered either a very small LLM or a simple NLP model (opinions vary), weighs in at 67MB. Even small LLMs, such as Gemma 2B, can reach 1.3GB. This is over 100 times the size of the median web page.
You can assess the exact download size of the models you're planning to use with your browsers' developer tools.


Optimize model size
- Compare model quality and download sizes. A smaller model may have sufficient accuracy for your use case, while being much smaller. Fine tuning and model shrinking techniques exist to significantly reduce a model's size while maintaining sufficient accuracy.
- Pick specialized models when possible. Models that are tailored to a certain task tend to be smaller. For example, if you're looking to perform specific tasks like sentiment or toxicity analysis, use models specialized in these tasks rather than a generic LLM.
While all these models perform the same task, with varying accuracy, their sizes vary widely: from 3MB to 1.5GB.
Check if the model can run
Not all devices can run AI models. Even devices that have sufficient hardware specs may struggle, if other expensive processes are running or are started while the model is in use.
Until a solution is available, here's what you can do today:
- Check for WebGPU support. Several client-side AI libraries including Transformers.js version 3 and MediaPipe use WebGPU. At the moment, some of these libraries don't automatically fallback to Wasm if WebGPU isn't supported. You can mitigate that by enclosing your AI-related code within a WebGPU feature detection check, if you know that your client-side AI library needs WebGPU.
- Rule out underpowered devices. Use Navigator.hardwareConcurrency, Navigator.deviceMemory and the Compute Pressure API to estimate device capabilities and pressure. These APIs are not supported in all browsers and are intentionally imprecise to prevent fingerprinting, but they can still help rule out devices that seem very underpowered.
Signal large downloads
For large models, warn users before downloading. Desktop users are more likely
to be OK with large downloads than mobile users. To detect mobile devices, use
mobile
from the User-Agent Client Hints API (or the User-Agent string if UA-CH is
unsupported).
Limit large downloads
- Only download what's necessary. Especially if the model is large, download it only once there's reasonable certainty the AI features will be used. For example, if you have a type-ahead suggestion AI feature, only download when the user starts using typing features.
- Explicitly cache the model on the device using the Cache API, to avoid downloading it at every visit. Don't just rely on the implicit HTTP browser cache.
- Chunk the model download. fetch-in-chunks splits a large download into smaller chunks.
Model download and preparation
Don't block the user
Prioritize a smooth user experience: allow key features to function even if the AI model isn't fully loaded yet.
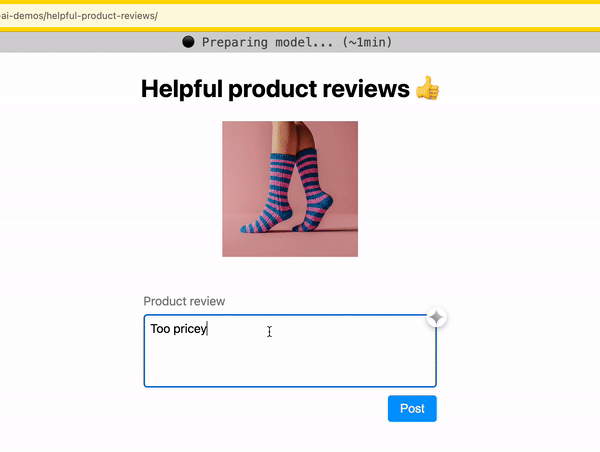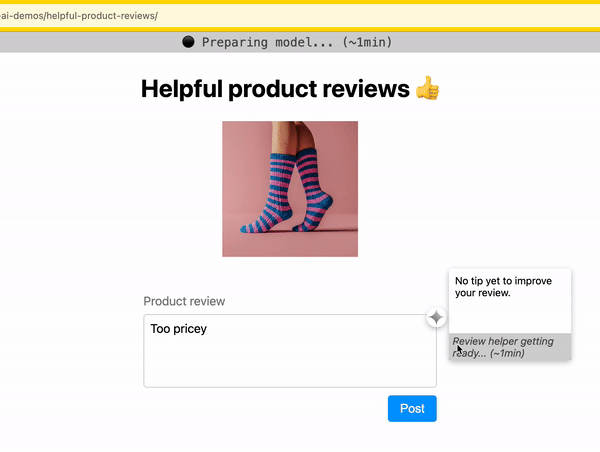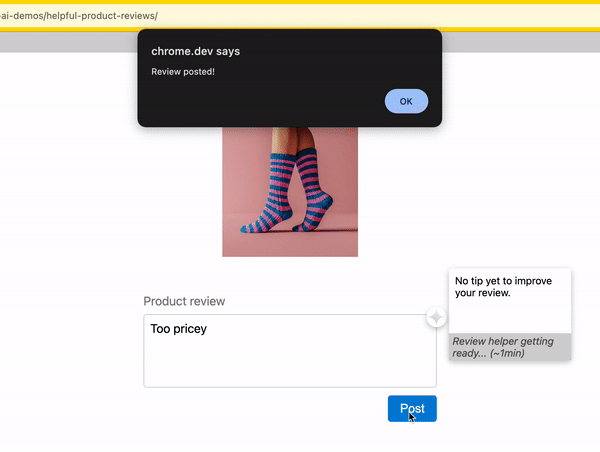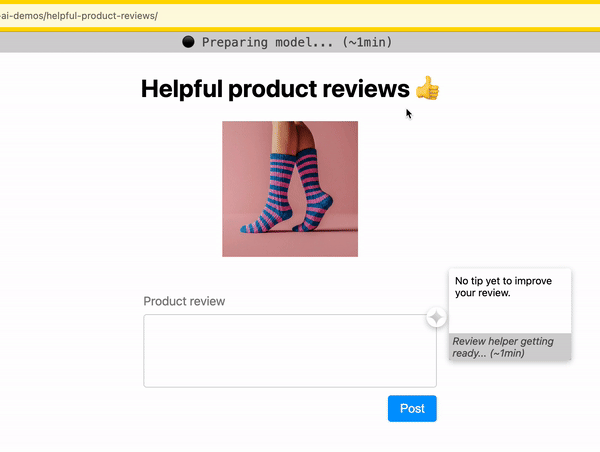
Indicate progress
As you download the model, indicate progress completed and time remaining.
- If model downloads are handled by your client-side AI library, use the download progress status to display it to the user. If this feature isn't available, consider opening an issue to request it (or contribute it!).
- If you handle model downloads in your own code, you can fetch the model in
chunks using a library, such as
fetch-in-chunks,
and display download progress to the user.
- For more advice, refer to Best practices for animated progress indicators and Designing for long waits and interruptions.
Handle network interruptions gracefully
Model downloads can take different amounts of time, depending on their size. Consider how to handle network interruptions if the user goes offline. When possible, inform the user of a broken connection, and continue the download when the connection is restored.
Flaky connectivity is another reason to download in chunks.
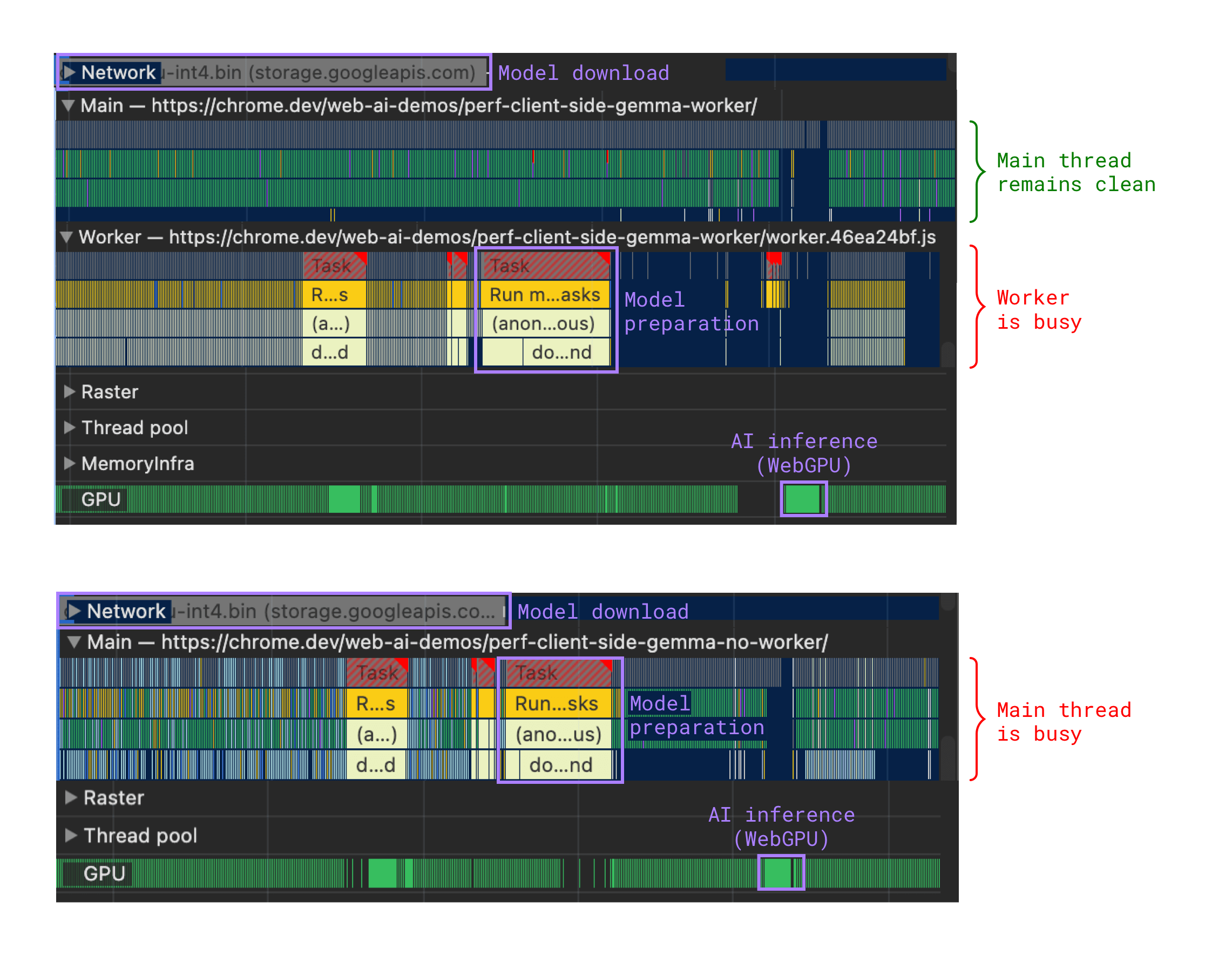
Offload expensive tasks to a web worker
Expensive tasks, for example model preparation steps after download, can block your main thread, causing a jittery user experience. Moving these tasks over to a web worker helps.
Find a demo and full implementation based on a web worker:
During inference
Once the model is downloaded and ready, you can run inference. Inference can be computationally expensive.
Move inference to a web worker
If inference occurs through WebGL, WebGPU or WebNN, it relies on the GPU. This means it occurs in a separate process that doesn't block the UI.
But for CPU-based implementations (such as Wasm, which can be a fallback for WebGPU, if WebGPU is unsupported), moving inference to a web worker keeps your page responsive—just like during model preparation.
Your implementation may be simpler if all your AI-related code (model fetch, model preparation, inference) lives in the same place. So, you may choose a web worker, whether or not the GPU is in use.
Handle errors
Even though you've checked that the model should run on the device, the user may start another process that extensively consumes resources later on. To mitigate this:
- Handle inference errors. Enclose inference in
try/catchblocks, and handle corresponding runtime errors. - Handle WebGPU errors, both unexpected and GPUDevice.lost, which occurs when the GPU is actually reset because the device struggles.
Indicate inference status
If inference takes more time than what would feel immediate, signal to the user that the model is thinking. Use animations to ease the wait and ensure the user that the application is working as intended.
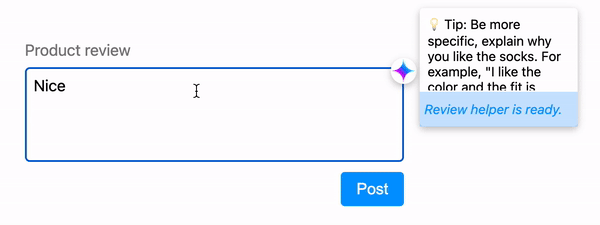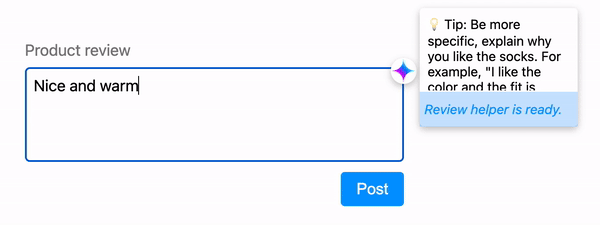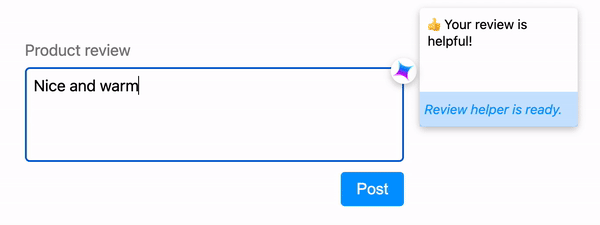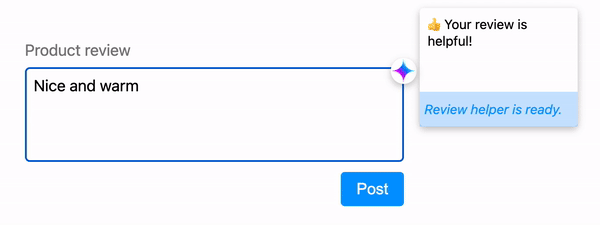
Make inference cancellable
Allow the user to refine their query on the fly, without the system wasting resources generating a response the user will never see.