

Introduction
Les extensions Media Source Extensions (MSE)
offrent une mise en mémoire tampon étendue et un contrôle de la lecture pour les éléments HTML5 <audio> et
<video> éléments. Bien qu'elles aient été initialement développées pour faciliter
les lecteurs vidéo basés sur le streaming adaptatif dynamique sur HTTP (DASH)
, nous verrons ci-dessous comment elles peuvent être utilisées pour l'audio, en particulier pour
la lecture sans interruption.
Vous avez probablement déjà écouté un album de musique dont les chansons s'enchaînaient sans interruption. Vous en écoutez peut-être même un en ce moment. Les artistes créent ces expériences de lecture sans interruption à la fois comme choix artistique et comme artefact des disques vinyles et des CD, où l'audio était écrit comme un flux continu. Malheureusement, en raison du fonctionnement des codecs audio modernes tels que MP3 et AAC, cette expérience auditive fluide est souvent perdue aujourd'hui.
Nous allons voir pourquoi ci-dessous, mais commençons par une démonstration. Vous trouverez ci-dessous les 30 premières secondes de l'excellent film Sintel, découpées en cinq fichiers MP3 distincts et réassemblées à l'aide de MSE. Les lignes rouges indiquent les interruptions introduites lors de la création (encodage) de chaque MP3. Vous entendrez des problèmes à ces points.
Beurk ! Ce n'est pas une expérience idéale. Nous pouvons faire mieux. Avec un peu plus de travail, en utilisant exactement les mêmes fichiers MP3 que dans la démo ci-dessus, nous pouvons utiliser MSE pour supprimer ces interruptions gênantes. Les lignes vertes de la démo suivante indiquent où les fichiers ont été joints et les interruptions supprimées. Sur Chrome 38 et versions ultérieures, la lecture sera fluide.
Il existe différentes façons de créer du contenu sans interruption. Pour les besoins de cette démo, nous nous concentrerons sur le type de fichiers qu'un utilisateur normal peut avoir. Chaque fichier a été encodé séparément, sans tenir compte des segments audio avant ou après.
Configuration de base
Tout d'abord, revenons en arrière et abordons la configuration de base d'une instance MediaSource.
Comme leur nom l'indique, les extensions Media Source Extensions ne sont que des extensions des éléments multimédias existants. Ci-dessous, nous attribuons une
Object URL,
représentant notre instance MediaSource, à l'attribut source d'un élément audio
, comme vous le feriez pour une URL standard.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
Une fois l'objet MediaSource connecté, il effectue une initialisation
et déclenche un événement sourceopen. Nous pouvons alors créer un
SourceBuffer. Dans l
'exemple ci-dessus, nous créons un audio/mpeg, qui est capable d'analyser et de
décoder nos segments MP3. Plusieurs
autres types sont disponibles.
Formes d'onde anomales
Nous reviendrons au code dans un instant, mais examinons maintenant de plus près le fichier que nous venons d'ajouter, en particulier à la fin. Vous trouverez ci-dessous un graphique des 3 000 derniers échantillons, moyennés sur les deux canaux de la piste sintel_0.mp3. Chaque pixel de la ligne rouge est un
échantillon à virgule flottante
compris entre [-1.0, 1.0].

Pourquoi tous ces échantillons zéro (silencieux) ? Ils sont en fait dus à des artefacts de compression introduits lors de l'encodage. Presque tous les encodeurs introduisent un type de remplissage. Dans ce cas, LAME a ajouté exactement 576 échantillons de remplissage à la fin du fichier.
En plus du remplissage à la fin, un remplissage a également été ajouté au début de chaque fichier. Si nous examinons la piste sintel_1.mp3, nous verrons 576 autres échantillons de remplissage au début. La quantité
de remplissage varie en fonction de l'encodeur et du contenu, mais nous connaissons les valeurs exactes en fonction des
metadata inclus dans chaque fichier.
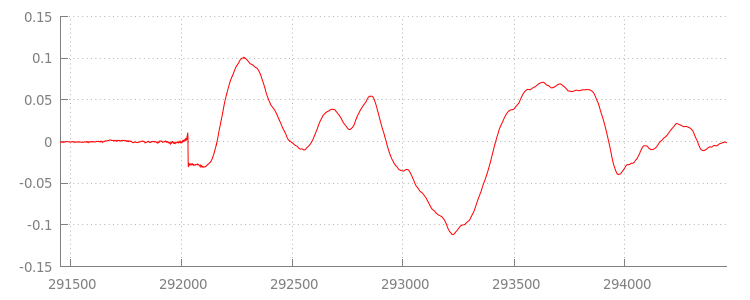
Les sections de silence au début et à la fin de chaque fichier sont à l'origine des problèmes entre les segments de la démo précédente. Pour obtenir une lecture sans interruption, nous devons supprimer ces sections de silence. Heureusement, cela est facile à faire avec MediaSource. Ci-dessous, nous allons modifier notre onAudioLoaded() méthode pour utiliser une
fenêtre d'ajout et un décalage
d'horodatage afin de supprimer ce silence.
Exemple de code
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Une forme d'onde fluide
Voyons ce que notre nouveau code a accompli en examinant à nouveau la forme d'onde après avoir appliqué nos fenêtres d'ajout. Vous pouvez voir ci-dessous que la section silencieuse à la fin de sintel_0.mp3 (en rouge) et la section silencieuse au début de sintel_1.mp3 (en bleu) ont été supprimées, ce qui nous laisse une transition fluide entre les segments.
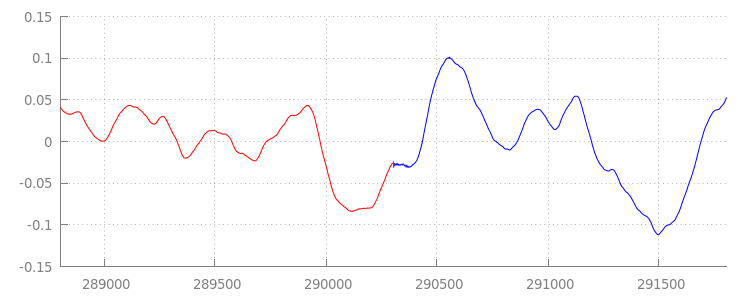
Conclusion
Nous avons ainsi assemblé les cinq segments de manière fluide en un seul et avons terminé notre démo. Avant de partir, vous avez peut-être remarqué que notre méthode onAudioLoaded() ne tient pas compte des conteneurs ni des codecs.
Cela signifie que toutes ces techniques fonctionneront quel que soit le type de conteneur ou de codec. Vous pouvez rejouer la démo d'origine au format MP4 fragmenté compatible DASH au lieu de MP3.
Pour en savoir plus, consultez les annexes ci-dessous pour en savoir plus sur la création de contenu sans interruption et l'analyse des métadonnées. Vous pouvez également explorer
gapless.js pour examiner de plus près
le code qui alimente cette démo.
Merci de votre attention,
Annexe A : Créer du contenu sans interruption
Il peut être difficile de créer du contenu sans interruption. Nous allons voir ci-dessous comment créer le média Sintel utilisé dans cette démo. Pour commencer, vous aurez besoin d'une copie de la bande-son FLAC sans perte pour Sintel. Pour la postérité, le SHA1 est inclus ci-dessous. Pour les outils, vous aurez besoin de FFmpeg, MP4Box, LAME et d'une installation OSX avec afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Tout d'abord, nous allons diviser les 31,5 premières secondes de la piste 1-Snow_Fight.flac. Nous voulons également ajouter un fondu de 2,5 secondes à partir de 28 secondes pour éviter tout clic une fois la lecture terminée. À l'aide de la ligne de commande FFmpeg ci-dessous, nous pouvons tout faire et placer les résultats dans sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Ensuite, nous allons diviser le fichier en cinq fichiers d'onde de 6,5 secondes chacun.Il est plus facile d'utiliser une onde, car presque tous les encodeurs prennent en charge son ingestion. Encore une fois, nous pouvons le faire précisément avec FFmpeg, après quoi nous aurons : sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav et sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
Ensuite, créons les fichiers MP3. LAME propose plusieurs options pour créer du contenu sans interruption. Si vous contrôlez le contenu, vous pouvez envisager d'utiliser --nogap avec un encodage par lot de tous les fichiers pour éviter tout remplissage entre les segments.
Toutefois, pour les besoins de cette démo, nous voulons ce remplissage. Nous allons donc utiliser un encodage VBR standard de haute qualité des fichiers d'onde.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
C'est tout ce qui est nécessaire pour créer les fichiers MP3. Passons maintenant à la création des fichiers MP4 fragmentés. Nous allons suivre les instructions d'Apple pour créer des médias masterisés pour iTunes . Ci-dessous, nous allons convertir les fichiers d'onde en fichiers CAF intermédiaires, conformément aux instructions, avant de les encoder au format AAC dans un conteneur MP4 à l'aide des paramètres recommandés.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Nous disposons maintenant de plusieurs fichiers M4A que nous devons
fragmenter
de manière appropriée avant de pouvoir les utiliser avec
MediaSource. Pour nos besoins, nous allons utiliser une taille de fragment d'une seconde. MP4Box écrira chaque MP4 fragmenté sous la forme sintel_#_dashinit.mp4, ainsi qu'un fichier manifeste MPEG-DASH (sintel_#_dash.mpd) qui peut être supprimé.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
Et voilà ! Nous disposons maintenant de fichiers MP4 et MP3 fragmentés avec les métadonnées correctes nécessaires à la lecture sans interruption. Consultez l'annexe B pour en savoir plus sur l'apparence de ces métadonnées.
Annexe B : Analyser les métadonnées sans interruption
Tout comme la création de contenu sans interruption, l'analyse des métadonnées sans interruption peut être délicate, car il n'existe pas de méthode de stockage standard. Nous allons voir ci-dessous comment les deux encodeurs les plus courants, LAME et iTunes, stockent leurs métadonnées sans interruption. Commençons par configurer quelques méthodes d'assistance et un aperçu de la méthode ParseGaplessData() utilisée ci-dessus.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Nous allons d'abord aborder le format de métadonnées iTunes d'Apple, car il est le plus facile à analyser et à expliquer. Dans les fichiers MP3 et M4A, iTunes (et afconvert) écrivent une courte section en ASCII comme suit :
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Ceci est écrit dans un tag ID3 dans le conteneur MP3 et dans un atome de métadonnées dans le conteneur MP4. Pour nos besoins, nous pouvons ignorer le premier jeton 0000000. Les trois jetons suivants sont le remplissage avant, le remplissage de fin et le nombre total d'échantillons sans remplissage. En divisant chacun d'eux par la fréquence d'échantillonnage de l'audio, nous obtenons la durée de chacun.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
À l'inverse, la plupart des encodeurs MP3 Open Source stockent les métadonnées sans interruption dans un en-tête Xing spécial placé dans une trame MPEG silencieuse (il est silencieux, de sorte que les décodeurs qui ne comprennent pas l'en-tête Xing ne feront que lire le silence). Malheureusement, ce tag n'est pas toujours présent et comporte un certain nombre de champs facultatifs. Pour les besoins de cette démo, nous contrôlons le média, mais en pratique, des vérifications de sensibilité supplémentaires seront nécessaires pour savoir quand les métadonnées sans interruption sont réellement disponibles.
Nous allons d'abord analyser le nombre total d'échantillons. Par souci de simplicité, nous allons le lire à partir de
l'en-tête Xing, mais il pourrait être construit à partir de l'en-tête audio MPEG normal
normal.
Les en-têtes Xing peuvent être marqués par un tag Xing ou Info. Exactement 4 octets après ce tag, il existe 32 bits représentant le nombre total de trames dans le fichier. En multipliant cette valeur par le nombre d'échantillons par trame, nous obtenons le nombre total d'échantillons dans le fichier.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Maintenant que nous avons le nombre total d'échantillons, nous pouvons passer à la lecture du nombre d'échantillons de remplissage. Selon votre encodeur, cela peut être écrit sous un tag LAME ou Lavf imbriqué dans l'en-tête Xing. Exactement 17 octets après cet en-tête, il existe 3 octets représentant respectivement le remplissage avant et le remplissage de fin en 12 bits.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Nous disposons ainsi d'une fonction complète pour analyser la grande majorité du contenu sans interruption. Les cas extrêmes sont nombreux. Il est donc recommandé de faire preuve de prudence avant d'utiliser un code similaire en production.
Annexe C : À propos de la récupération de mémoire
La mémoire appartenant aux instances SourceBuffer est activement
récupérée
en fonction du type de contenu, des limites spécifiques à la plate-forme et de la position de lecture
actuelle. Dans Chrome, la mémoire est d'abord récupérée à partir des tampons déjà lus.
Toutefois, si l'utilisation de la mémoire dépasse les limites spécifiques à la plate-forme, elle sera supprimée des tampons non lus.
Lorsque la lecture atteint une interruption dans la chronologie en raison de la mémoire récupérée, elle peut être défectueuse si l'interruption est suffisamment petite ou s'arrêter complètement si l'interruption est trop importante. Aucune de ces expériences n'est idéale pour l'utilisateur. Il est donc important d'éviter d'ajouter trop de données à la fois et de supprimer manuellement les plages de la chronologie multimédia qui ne sont plus nécessaires.
Les plages peuvent être supprimées à l'aide de la
remove()
méthode sur chaque SourceBuffer, qui prend une plage [start, end] en secondes.
Comme appendBuffer(), chaque remove() déclenche un événement updateend une fois terminé. Aucune autre suppression ni aucun autre ajout ne doivent être émis tant que l'événement n'est pas déclenché.
Sur Chrome pour ordinateur, vous pouvez conserver environ 12 mégaoctets de contenu audio et 150 mégaoctets de contenu vidéo en mémoire à la fois. Vous ne devez pas vous fier à ces valeurs sur tous les navigateurs ou plates-formes. Par exemple, elles ne sont certainement pas représentatives des appareils mobiles.
La récupération de mémoire n'a d'impact que sur les données ajoutées à SourceBuffers. Il n'y a aucune limite à la quantité de données que vous pouvez mettre en mémoire tampon dans les variables JavaScript. Vous pouvez également ajouter à nouveau les mêmes données au même emplacement si nécessaire.