

บทนำ
Media Source Extensions (MSE)
ให้การควบคุมการบัฟเฟอร์และการเล่นที่ขยายออกไปสำหรับองค์ประกอบ <audio> และ <video> ของ HTML5 แม้ว่าเดิมทีจะพัฒนาขึ้นเพื่ออำนวยความสะดวกให้แก่เพลเยอร์วิดีโอที่ใช้การสตรีมที่ปรับเปลี่ยนได้แบบไดนามิกผ่าน HTTP (DASH)
แต่ด้านล่างนี้เราจะดูวิธีใช้กับเสียง โดยเฉพาะอย่างยิ่งสำหรับการเล่นแบบไม่ขาดตอน
คุณอาจเคยฟังอัลบั้มเพลงที่เพลงเล่นต่อเนื่องกันอย่างราบรื่น หรืออาจกำลังฟังอยู่ก็ได้ ศิลปินสร้างประสบการณ์การเล่นแบบไม่หยุดเหล่านี้ ทั้งในฐานะตัวเลือกทางศิลปะและผลงานจากแผ่นเสียงไวนิลและซีดีที่บันทึกเสียงเป็นสตรีมต่อเนื่องรายการเดียว อย่างไรก็ตาม ด้วยวิธีการทำงานของตัวแปลงสัญญาณเสียงสมัยใหม่ เช่น MP3 และ AAC ประสบการณ์ด้านเสียงที่ราบรื่น จึงมักหายไปในปัจจุบัน
เราจะอธิบายรายละเอียดของสาเหตุที่ด้านล่าง แต่ตอนนี้มาเริ่มด้วยการ สาธิตกันก่อน ด้านล่างนี้คือ 30 วินาทีแรกของภาพยนตร์สั้นยอดเยี่ยมเรื่อง Sintel ที่ตัดเป็นไฟล์ MP3 แยกกัน 5 ไฟล์และประกอบใหม่โดยใช้ MSE เส้นสีแดงแสดงถึงช่องว่างที่เกิดขึ้นระหว่าง การสร้าง (การเข้ารหัส) MP3 แต่ละไฟล์ คุณจะได้ยินเสียงขัดข้องที่จุดเหล่านี้
ยี้ ซึ่งเป็นประสบการณ์การใช้งานที่ไม่ดีนัก เราจึงต้องปรับปรุง หากใช้ไฟล์ MP3 เดียวกันในเดโมด้านบน เราจะใช้ MSE เพื่อลบช่องว่างที่น่ารำคาญเหล่านั้นได้ โดยใช้เวลาเพิ่มขึ้นเล็กน้อย เส้นสีเขียวในการสาธิตถัดไปแสดงตำแหน่งที่ระบบรวมไฟล์และนำช่องว่างออก ใน Chrome 38 ขึ้นไป การเล่นจะราบรื่น
การสร้างเนื้อหาแบบไม่มีช่องว่างทำได้หลายวิธี เพื่อวัตถุประสงค์ในการสาธิตนี้ เราจะมุ่งเน้นไปที่ประเภทไฟล์ที่ผู้ใช้ทั่วไป อาจมี ในกรณีที่ไฟล์แต่ละไฟล์ได้รับการเข้ารหัสแยกกันโดยไม่คำนึงถึงส่วนเสียงก่อนหน้าหรือหลังไฟล์นั้น
การตั้งค่าพื้นฐาน
ก่อนอื่น เรามาดูการตั้งค่าพื้นฐานของอินสแตนซ์ MediaSource กัน
Media Source Extensions ตามชื่อที่สื่อถึงเป็นเพียงส่วนขยายขององค์ประกอบสื่อที่มีอยู่ ด้านล่างนี้ เราจะกำหนด
Object URL
ซึ่งแสดงถึงอินสแตนซ์ MediaSource ให้กับแอตทริบิวต์แหล่งที่มาขององค์ประกอบเสียง
เช่นเดียวกับที่คุณตั้งค่า URL มาตรฐาน
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
เมื่อเชื่อมต่อออบเจ็กต์ MediaSource แล้ว ออบเจ็กต์จะทำการเริ่มต้นบางอย่าง
และจะทริกเกอร์เหตุการณ์ sourceopen ในที่สุด ซึ่งในจุดนี้เราจะสร้าง
SourceBuffer ได้ ใน
ตัวอย่างข้างต้น เรากำลังสร้าง audio/mpeg ซึ่งสามารถแยกวิเคราะห์และ
ถอดรหัสกลุ่ม MP3 ของเราได้ และยังมีประเภทอื่นๆ อีกหลายประเภท
ให้ใช้งาน
รูปแบบคลื่นที่ผิดปกติ
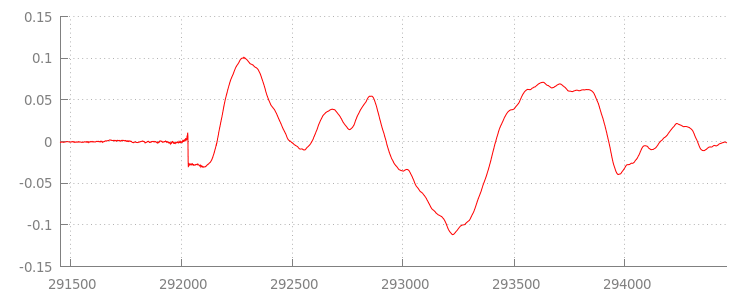
เราจะกลับมาดูโค้ดในอีกสักครู่ แต่ตอนนี้มาดูไฟล์ที่เราเพิ่งต่อท้ายกันอย่างละเอียด โดยเฉพาะส่วนท้ายของไฟล์ ด้านล่างนี้คือกราฟของ
ตัวอย่าง 3, 000 รายการล่าสุดที่หาค่าเฉลี่ยจากทั้ง 2 ช่องทางจาก
sintel_0.mp3
แทร็ก แต่ละพิกเซลบนเส้นสีแดงคือตัวอย่างจุดลอยตัว
ในช่วง [-1.0, 1.0]

ทำไมถึงมีตัวอย่างที่ไม่มีเสียง (เงียบ) เยอะขนาดนี้ แต่จริงๆ แล้วเกิดจากอาร์ติแฟกต์การบีบอัด ที่เกิดขึ้นระหว่างการเข้ารหัส โดยตัวเข้ารหัสเกือบทุกตัวจะมีการเพิ่ม การเพิ่มแพดดิ้งบางประเภท ในกรณีนี้ LAME เพิ่มตัวอย่างการเพิ่มพื้นที่ว่าง 576 รายการที่ส่วนท้ายของไฟล์
นอกจากระยะขอบที่ส่วนท้ายแล้ว ไฟล์แต่ละไฟล์ยังมีระยะขอบที่เพิ่มที่
จุดเริ่มต้นด้วย หากเราดูที่
sintel_1.mp3
แทร็ก เราจะเห็นตัวอย่างการเพิ่มแพดดิ้งอีก 576 รายการที่ด้านหน้า ปริมาณ
การเพิ่มพื้นที่ว่างจะแตกต่างกันไปตามตัวเข้ารหัสและเนื้อหา แต่เราทราบค่าที่แน่นอนโดยอิงตาม
metadata ที่รวมอยู่ในแต่ละไฟล์
ส่วนที่ไม่มีเสียงที่จุดเริ่มต้นและจุดสิ้นสุดของแต่ละไฟล์เป็นสาเหตุที่ทำให้เกิดข้อบกพร่องระหว่างกลุ่มในเดโมก่อนหน้า หากต้องการให้เล่นเพลงแบบไม่ขาดตอน
เราต้องนำช่วงที่เงียบเหล่านี้ออก โชคดีที่ทำได้ง่ายๆ ด้วย
MediaSource ด้านล่างนี้ เราจะแก้ไขonAudioLoaded()วิธีของเราเพื่อใช้หน้าต่างต่อท้ายและออฟเซ็ตการประทับเวลาเพื่อลบช่วงเงียบนี้
โค้ดตัวอย่าง
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
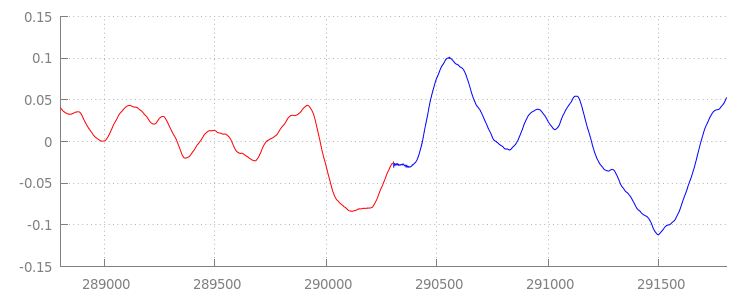
รูปแบบคลื่นที่ราบรื่น
มาดูกันว่าโค้ดใหม่ของเราทำอะไรได้บ้างโดยดู
รูปคลื่นอีกครั้งหลังจากที่เราใช้หน้าต่างต่อท้าย ด้านล่างนี้ คุณจะเห็นว่าส่วนที่ไม่มีเสียงที่ตอนท้ายของ
sintel_0.mp3
(สีแดง) และส่วนที่ไม่มีเสียงที่ตอนต้นของ
sintel_1.mp3
(สีน้ำเงิน) ถูกนำออกแล้ว ทำให้เรามีช่วงเปลี่ยนผ่านที่ราบรื่นระหว่าง
กลุ่ม
บทสรุป
ด้วยเหตุนี้ เราจึงได้รวมทั้ง 5 ส่วนเข้าด้วยกันอย่างราบรื่นและ
ได้มาถึงช่วงท้ายของการสาธิตแล้ว ก่อนจากกัน คุณอาจสังเกตเห็นว่าonAudioLoaded()วิธีการของเราไม่ได้พิจารณาคอนเทนเนอร์หรือตัวแปลงรหัส
ซึ่งหมายความว่าเทคนิคทั้งหมดนี้จะใช้ได้ไม่ว่าจะเป็นคอนเทนเนอร์หรือ
ประเภทตัวแปลงรหัสใดก็ตาม ด้านล่างนี้คุณสามารถเล่นการสาธิตต้นฉบับของ MP4 แบบแยกส่วนที่พร้อมสำหรับ DASH
แทนที่จะเป็น MP3
หากต้องการทราบข้อมูลเพิ่มเติม โปรดดูภาคผนวกด้านล่างเพื่อดูรายละเอียดเพิ่มเติมเกี่ยวกับ
การสร้างเนื้อหาแบบไร้ช่องว่างและการแยกวิเคราะห์ข้อมูลเมตา นอกจากนี้ คุณยังสำรวจ
gapless.js เพื่อดูรายละเอียดเพิ่มเติมเกี่ยวกับ
โค้ดที่ขับเคลื่อนการสาธิตนี้ได้ด้วย
ขอขอบคุณที่อ่าน
ภาคผนวก ก: การสร้างเนื้อหาที่ไม่มีช่องว่าง
การสร้างเนื้อหาแบบไม่มีช่องว่างอาจเป็นเรื่องยาก ด้านล่างนี้เราจะอธิบายขั้นตอนการสร้างสื่อ Sintel ที่ใช้ใน การสาธิตนี้ ในการเริ่มต้น คุณจะต้องมีสำเนาซาวด์แทร็ก FLAC แบบไม่สูญเสียรายละเอียดของ Sintel และเราได้ใส่ SHA1 ไว้ด้านล่างเพื่อเป็นข้อมูลอ้างอิง สำหรับเครื่องมือ คุณจะต้องมี FFmpeg, MP4Box, LAME และการติดตั้ง OSX ที่มี afconvert
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
ก่อนอื่น เราจะแยกแทร็ก 1-Snow_Fight.flac ออกเป็น 31.5 วินาทีแรก นอกจากนี้ เรายังต้องการเพิ่มการจางหาย 2.5 วินาทีโดยเริ่มที่วินาทีที่ 28 เพื่อหลีกเลี่ยงการคลิกเมื่อการเล่นสิ้นสุดลง การใช้บรรทัดคำสั่ง FFmpeg ด้านล่างจะช่วยให้เรา
ทำทั้งหมดนี้และใส่ผลลัพธ์ใน sintel.flac ได้
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
จากนั้นเราจะแยกไฟล์เป็นไฟล์ wave
5 ไฟล์ ไฟล์ละ 6.5 วินาที โดยใช้ wave ได้ง่ายที่สุดเนื่องจากตัวเข้ารหัสเกือบทุกตัว
รองรับการส่งผ่านข้อมูล เราสามารถทำสิ่งนี้ได้อย่างแม่นยำด้วย FFmpeg หลังจากนั้นเราจะได้ sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav และ sintel_4.wav
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
จากนั้นมาสร้างไฟล์ MP3 กัน LAME มีตัวเลือกหลายอย่างสำหรับการสร้างเนื้อหาแบบเล่นต่อเนื่อง
หากคุณควบคุมเนื้อหาได้ คุณอาจพิจารณาใช้ --nogap
พร้อมการเข้ารหัสแบบกลุ่มของไฟล์ทั้งหมดเพื่อหลีกเลี่ยงการเพิ่มพื้นที่ว่างระหว่างกลุ่มทั้งหมด
แต่เพื่อวัตถุประสงค์ของการสาธิตนี้ เราต้องการระยะขอบดังกล่าว จึงจะใช้การเข้ารหัส VBR คุณภาพสูงมาตรฐานของไฟล์ Wave
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
เพียงเท่านี้ก็สร้างไฟล์ MP3 ได้แล้ว ตอนนี้เรามาดู การสร้างไฟล์ MP4 แบบแยกส่วนกัน เราจะทำตามคำแนะนำของ Apple ในการ สร้างสื่อที่ มาสเตอร์สำหรับ iTunes ด้านล่างนี้ เราจะแปลงไฟล์ Wave เป็นไฟล์ CAF ระดับกลางตาม วิธีการ ก่อนที่จะเข้ารหัสเป็น AAC ในคอนเทนเนอร์ MP4 โดยใช้พารามิเตอร์ที่แนะนำ
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
ตอนนี้เรามีไฟล์ M4A หลายไฟล์ซึ่งเราต้องแยก
อย่างเหมาะสมก่อนจึงจะใช้กับ
MediaSource ได้ สำหรับวัตถุประสงค์ของเรา เราจะใช้ขนาดของ Fragment เป็น 1 วินาที MP4Box
จะเขียน MP4 ที่แยกส่วนแต่ละรายการเป็น sintel_#_dashinit.mp4 พร้อมกับ
ไฟล์ Manifest MPEG-DASH (sintel_#_dash.mpd) ซึ่งทิ้งได้
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
เท่านี้ก็เรียบร้อย ตอนนี้เรามีไฟล์ MP4 และ MP3 ที่แยกส่วนพร้อมข้อมูลเมตาที่ถูกต้อง ซึ่งจำเป็นสำหรับการเล่นแบบไม่ขาดตอนแล้ว ดูรายละเอียดเพิ่มเติมเกี่ยวกับลักษณะของข้อมูลเมตาดังกล่าวได้ที่ภาคผนวก ข.
ภาคผนวก ข: การแยกวิเคราะห์ข้อมูลเมตาแบบไม่มีช่องว่าง
การแยกวิเคราะห์ข้อมูลเมตาแบบไม่มีช่องว่างอาจทำได้ยากเช่นเดียวกับการสร้างเนื้อหาแบบไม่มีช่องว่าง เนื่องจากไม่มีวิธีการจัดเก็บมาตรฐาน ด้านล่างนี้เราจะอธิบายวิธีที่ตัวเข้ารหัส 2 ตัวที่พบบ่อยที่สุดอย่าง LAME และ iTunes จัดเก็บข้อมูลเมตาแบบเล่นต่อเนื่อง มาเริ่มด้วยการ
ตั้งค่าเมธอดตัวช่วยและโครงร่างสำหรับ ParseGaplessData() ที่ใช้
ด้านบนกัน
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
เราจะพูดถึงรูปแบบข้อมูลเมตาของ iTunes ของ Apple ก่อนเนื่องจากเป็นรูปแบบที่แยกวิเคราะห์ และอธิบายได้ง่ายที่สุด ในไฟล์ MP3 และ M4A นั้น iTunes (และ afconvert) จะเขียนส่วนสั้นๆ ใน ASCII ดังนี้
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
โดยจะเขียนไว้ภายในแท็ก ID3 ในคอนเทนเนอร์ MP3 และภายในอะตอมข้อมูลเมตา
ในคอนเทนเนอร์ MP4 สำหรับจุดประสงค์ของเรา เราสามารถละเว้นโทเค็นแรก
0000000ได้ โทเค็น 3 รายการถัดไปคือการเว้นวรรคด้านหน้า การเว้นวรรคด้านท้าย และ
จำนวนตัวอย่างที่ไม่ใช่การเว้นวรรครวม การนำแต่ละค่านี้ไปหารด้วยอัตราการสุ่มตัวอย่างของ
เสียงจะทำให้เราทราบระยะเวลาของแต่ละค่า
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
ในทางกลับกัน ตัวเข้ารหัส MP3 แบบโอเพนซอร์สส่วนใหญ่จะจัดเก็บข้อมูลเมตาแบบเล่นต่อเนื่อง ไว้ภายในส่วนหัว Xing พิเศษ ซึ่งวางอยู่ภายในเฟรม MPEG ที่ไม่มีเสียง (ไม่มีเสียงเพื่อให้ตัวถอดรหัสที่ไม่ เข้าใจส่วนหัว Xing เล่นเสียงเงียบ) แต่แท็กนี้ไม่ได้ มีอยู่เสมอและมีฟิลด์ที่ไม่บังคับหลายรายการ เพื่อวัตถุประสงค์ของ การสาธิตนี้ เราควบคุมสื่อได้ แต่ในทางปฏิบัติจะต้องมีการตรวจสอบความละเอียดอ่อนเพิ่มเติม เพื่อดูว่าข้อมูลเมตาแบบไม่มีช่องว่างพร้อมใช้งานจริงเมื่อใด
ก่อนอื่นเราจะแยกวิเคราะห์จำนวนตัวอย่างทั้งหมด เพื่อความสะดวก เราจะอ่านข้อมูลนี้จาก
ส่วนหัวของ Xing แต่คุณอาจสร้างข้อมูลนี้จาก
ส่วนหัวของเสียง MPEG ปกติก็ได้
ส่วนหัวของ Xing สามารถทำเครื่องหมายด้วยแท็ก Xing หรือ Info หลังจากแท็กนี้ไป 4 ไบต์
จะมี 32 บิตที่แสดงจำนวนเฟรมทั้งหมดใน
ไฟล์ การคูณค่านี้ด้วยจำนวนตัวอย่างต่อเฟรมจะทำให้เราทราบ
จำนวนตัวอย่างทั้งหมดในไฟล์
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
ตอนนี้เรามีจำนวนตัวอย่างทั้งหมดแล้ว เราจึงสามารถอ่านจำนวนตัวอย่างการเพิ่มแพดดิ้งได้ ซึ่งอาจเขียนไว้ภายใต้แท็ก LAME หรือ Lavf ที่ซ้อนอยู่ในส่วนหัว Xing ทั้งนี้ขึ้นอยู่กับตัวเข้ารหัส หลังจากส่วนหัวนี้ มี 3 ไบต์ที่แสดงถึงการเว้นวรรคหน้าและท้ายในแต่ละ 12 บิต ตามลำดับ
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
ด้วยเหตุนี้ เราจึงมีฟังก์ชันที่สมบูรณ์สำหรับการแยกวิเคราะห์เนื้อหาส่วนใหญ่ที่ไม่มีช่องว่าง อย่างไรก็ตาม กรณีข้อยกเว้นก็มีอยู่มากมาย ดังนั้นเราขอแนะนำให้คุณใช้ความระมัดระวังก่อน ใช้โค้ดที่คล้ายกันในเวอร์ชันที่ใช้งานจริง
ภาคผนวก ค.: เกี่ยวกับการเก็บขยะ
ระบบจะล้างหน่วยความจำของอินสแตนซ์ SourceBuffer อย่างต่อเนื่อง
ตามประเภทเนื้อหา ขีดจำกัดเฉพาะแพลตฟอร์ม และตำแหน่งการเล่นปัจจุบัน
ใน Chrome ระบบจะเรียกคืนหน่วยความจำจากบัฟเฟอร์ที่เล่นแล้วก่อน
อย่างไรก็ตาม หากการใช้งานหน่วยความจำเกินขีดจำกัดเฉพาะของแพลตฟอร์ม ระบบจะนำหน่วยความจำออกจากบัฟเฟอร์ที่ยังไม่ได้เล่น
เมื่อการเล่นถึงช่องว่างในไทม์ไลน์เนื่องจากหน่วยความจำที่เรียกคืนมา การเล่นอาจ ขัดข้องหากช่องว่างมีขนาดเล็กพอ หรือหยุดชะงักโดยสมบูรณ์หากช่องว่างมีขนาดใหญ่เกินไป ทั้ง 2 อย่างนี้ไม่ใช่วิธีที่ให้ประสบการณ์การใช้งานที่ดี ดังนั้นคุณจึงควรหลีกเลี่ยงการต่อท้ายข้อมูลมากเกินไปในคราวเดียว และนำช่วงออกจากไทม์ไลน์สื่อด้วยตนเองเมื่อไม่จำเป็นอีกต่อไป
คุณสามารถนำช่วงออกได้โดยใช้เมธอด
remove()
ในแต่ละSourceBuffer ซึ่งจะใช้ช่วง[start, end]เป็นวินาที
คล้ายกับ appendBuffer() โดยแต่ละ remove() จะทริกเกอร์เหตุการณ์ updateend 1 ครั้ง
เมื่อเสร็จสมบูรณ์ ไม่ควรออกการนำออกหรือการเพิ่มอื่นๆ จนกว่าเหตุการณ์จะ
ทริกเกอร์
ใน Chrome บนเดสก์ท็อป คุณสามารถเก็บเนื้อหาเสียงประมาณ 12 เมกะไบต์และเนื้อหาวิดีโอ 150 เมกะไบต์ไว้ในหน่วยความจำได้พร้อมกัน คุณไม่ควรใช้ค่าเหล่านี้ในเบราว์เซอร์หรือแพลตฟอร์มต่างๆ เช่น ค่าเหล่านี้ไม่ใช่ตัวแทนของอุปกรณ์เคลื่อนที่อย่างแน่นอน
ระบบจัดการหน่วยความจำที่ไม่ใช้แล้วจะส่งผลต่อข้อมูลที่เพิ่มลงใน SourceBuffers เท่านั้น โดยไม่มีข้อจำกัดเกี่ยวกับปริมาณข้อมูลที่คุณสามารถเก็บไว้ในตัวแปร JavaScript คุณยัง
ต่อท้ายข้อมูลเดียวกันในตำแหน่งเดิมได้หากจำเป็น