
Zwiększ skuteczność, korzystając z sieci dostarczania treści.

Sieci dostarczania treści (CDN) poprawiają wydajność witryny, wykorzystując rozproszoną sieć serwerów do dostarczania zasobów użytkownikom. Sieci CDN zmniejszają obciążenie serwera, więc obniżają koszty serwera i dobrze nadają się do obsługi gwałtownego wzrostu natężenia ruchu. W tym artykule omawiamy, jak działają sieci CDN, i zapewniają niezależne od platformy wskazówki dotyczące wyboru, konfigurowania i optymalizowania konfiguracji CDN.
Przegląd
Sieć dostarczania treści składa się z sieci serwerów zoptymalizowanych pod kątem szybkiego dostarczania treści użytkownikom. Sieci CDN są zapewne najbardziej znane z wyświetlania treści z pamięci podręcznej, ale mogą też usprawnić wyświetlanie treści, których nie można zapisać w pamięci podręcznej. Ogólnie rzecz biorąc, im więcej treści witryny wyświetli się przez sieć CDN, tym lepiej.
Ogólnie rzecz biorąc, korzyści związane z wydajnością sieci CDN wynikają z kilku zasad: serwery CDN znajdują się bliżej użytkowników niż serwery pierwotnego, więc mają krótszy czas przesyłania w obie strony (RTT). Optymalizacje sieci pozwalają sieci CDN na dostarczanie treści szybciej, niż gdyby treść została wczytana „bezpośrednio” z serwera pierwotnego. Po drugie, CDN eliminuje potrzebę przesyłania żądania do serwera pierwotnego.
Dostarczanie zasobów
Chociaż może się to wydawać nieintuicyjne, używanie sieci CDN do dostarczania zasobów (nawet tych, których nie można zapisać w pamięci podręcznej) zwykle trwa krócej niż „bezpośrednie” wczytywanie zasobu przez użytkownika z Twoich serwerów.
Gdy do dostarczania zasobów z punktu początkowego używana jest sieć CDN, nawiązane jest nowe połączenie między klientem a pobliskim serwerem CDN. Pozostała część ścieżki (czyli przesyłanie danych między serwerem CDN a punktem początkowym) odbywa się przez sieć CDN, która często obejmuje istniejące, trwałe połączenia z punktem początkowym. Zalety tego rozwiązania są dwukierunkowe: zakończenie nowego połączenia jak najbliżej użytkownika eliminuje niepotrzebne koszty jego konfigurowania (nawiązanie nowego połączenia jest kosztowne i wymaga wielu transferów w obie strony). Wstępnie przygotowane połączenie umożliwia natychmiastowe przesyłanie danych z maksymalną przepustowością.
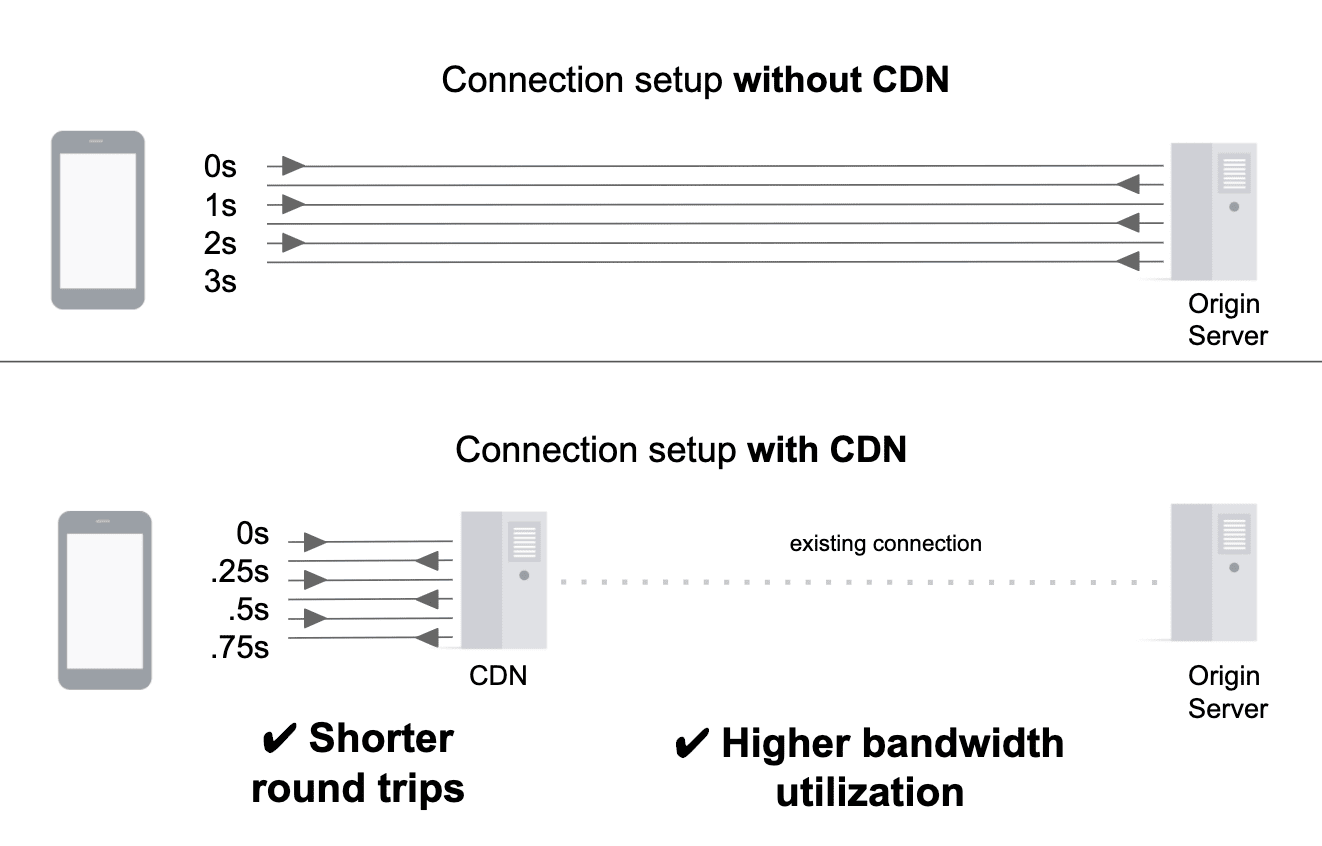
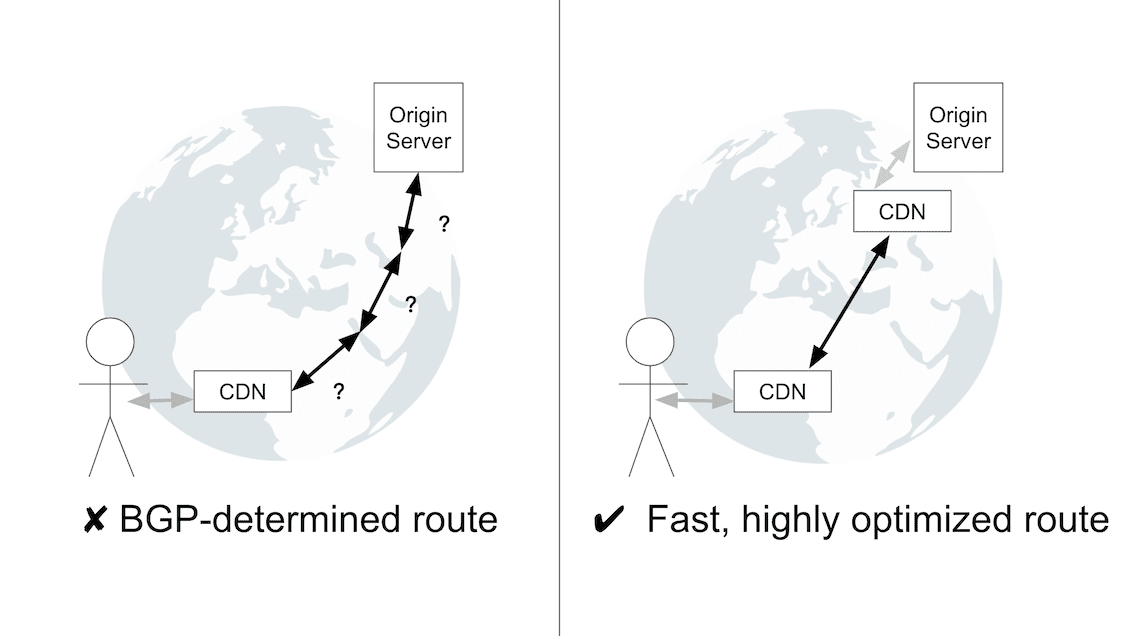
Niektóre sieci CDN są w tym jeszcze lepsze, ponieważ kierują ruch do punktu początkowego przez kilka serwerów CDN rozproszonych w internecie. Połączenia między serwerami CDN są przeprowadzane na niezawodnych i wysoce zoptymalizowanych trasach, a nie przez trasy określone przez protokół BGP. Chociaż BGP jest defacto protokołu routingu internetu, decyzje dotyczące routingu nie zawsze skłaniają do zorientowania się na wydajność. W związku z tym trasy określone przez BGP będą prawdopodobnie mniej wydajne niż dostrojone trasy między serwerami CDN.
Zapisywanie w pamięci podręcznej
Buforowanie zasobów na serwerach CDN eliminuje potrzebę przesyłania żądań do punktu początkowego, by zostało zrealizowane. W rezultacie zasób jest dostarczany szybciej, co zmniejsza również obciążenie serwera pierwotnego.
Dodawanie zasobów do pamięci podręcznej
Najczęściej stosowaną metodą zapełniania pamięci podręcznych CDN jest używanie w miarę potrzeb zasobów CDN. Nazywamy to „pobieraniem źródła”. Przy pierwszym żądaniu konkretnego zasobu z pamięci podręcznej CDN CDN wysyła żądanie do serwera pierwotnego i zapisuje odpowiedź w pamięci podręcznej. Dzięki temu zawartość pamięci podręcznej rośnie wraz z upływem czasu, w miarę jak są żądane dodatkowe zasoby, które nie znajdują się w pamięci podręcznej.
Usuwanie zasobów z pamięci podręcznej
Sieci CDN używają usuwania pamięci podręcznej do okresowego usuwania z pamięci podręcznej niezbyt przydatnych zasobów. Oprócz tego właściciele witryn mogą użyć trwałego usuwania zasobów, aby je usunąć.
Usuwanie z pamięci podręcznej
Pamięć podręczna ma ograniczoną pojemność. Gdy pamięć podręczna zbliża się do limitu, robi się miejsce na nowe zasoby, usuwając te, z których ostatnio nie korzystano lub które zajmują dużo miejsca. Ten proces jest nazywany usuwaniem pamięci podręcznej. Usunięcie zasobu z jednej pamięci podręcznej nie musi oznaczać, że został on wykluczony ze wszystkich pamięci podręcznych w sieci CDN.
Czyszczenie
Trwałe usuwanie (nazywane też „unieważnieniem pamięci podręcznej”) to mechanizm usuwania zasobu z pamięci podręcznej sieci CDN bez konieczności czekania na jego wygaśnięcie lub usunięcie. Zwykle jest on wykonywany za pomocą interfejsu API. Trwałe usuwanie jest kluczowe w sytuacjach, gdy treść musi zostać wycofana (na przykład w celu poprawienia literówek, błędów dotyczących cen lub nieprawidłowych artykułów z wiadomościami). Ponadto może odgrywać kluczową rolę w strategii buforowania treści witryny.
Jeśli sieć CDN obsługuje niemal natychmiastowe trwałe usuwanie, można jej użyć do zarządzania przechowywaniem w pamięci podręcznej zawartości dynamicznej: buforuj zawartość dynamiczną przy użyciu długiego czasu TTL, a następnie trwale usuwaj zasób po każdej aktualizacji. W ten sposób można zmaksymalizować czas przechowywania zasobu dynamicznego w pamięci podręcznej, mimo że nie wiadomo z wyprzedzeniem, kiedy zasób się zmieni. Technika ta jest czasami nazywana „buforowaniem, na które się nie zgadzasz”.
Trwałe usuwanie plików jest zwykle używane w połączeniu z pojęciem nazywanym „tagami pamięci podręcznej” lub „zastępczymi kluczami pamięci podręcznej”. Ten mechanizm umożliwia właścicielom witryn powiązanie jednego lub kilku dodatkowych identyfikatorów (czasem nazywanych „tagami”) z zasobami zapisanymi w pamięci podręcznej. Tych tagów można potem użyć do przeprowadzenia bardzo szczegółowego trwałego usuwania. Możesz na przykład dodać tag „stopka” do wszystkich zasobów (np.
/about,/blog), które zawierają stopkę witryny. Po zaktualizowaniu stopki poproś sieć CDN o trwałe usunięcie wszystkich zasobów powiązanych z tagiem „footer”.
Zasoby możliwe do buforowania
To, czy i w jaki sposób zasób powinien być buforowany, zależy od tego, czy jest on publiczny, czy prywatny, statyczny czy dynamiczny.
Zasoby prywatne i publiczne
Zasoby prywatne
Zasoby prywatne zawierają dane przeznaczone dla pojedynczego użytkownika, dlatego nie powinny być buforowane przez CDN. Zasoby prywatne są oznaczone nagłówkiem
Cache-Control: private.Zasoby publiczne
Zasoby publiczne nie zawierają informacji dotyczących użytkownika, dlatego można je buforować przez CDN. Zasób może zostać uznany za buforowany przez CDN, jeśli nie ma nagłówka
Cache-Control: no-storelubCache-Control: private. Czas, przez jaki zasób publiczny może być przechowywany w pamięci podręcznej, zależy od tego, jak często zasób się zmienia.
Zawartość dynamiczna i statyczna
Treści dynamiczne
Treści dynamiczne to takie, które często się zmieniają. Przykładem treści tego typu są odpowiedź interfejsu API i strona główna sklepu. Jednak częste zmiany w treściach nie muszą oznaczać, że nie będą one przechowywane w pamięci podręcznej. W okresach dużego natężenia ruchu przechowywanie tych odpowiedzi w pamięci podręcznej przez bardzo krótki czas (np. 5 sekund) może znacznie zmniejszyć obciążenie serwera pierwotnego przy minimalnym wpływie na częstotliwość aktualizacji danych.
Treść statyczna
Treści statyczne zmieniają się rzadko (lub w przeszłości). Zwykle tego typu są obrazy, filmy i biblioteki z różnymi wersjami treści. Ponieważ treści statyczne nie ulegają zmianie, powinny być przechowywane w pamięci podręcznej z zachowaniem długiego czasu życia danych (TTL), np. 6 miesięcy lub 1 roku.
Wybieranie sieci CDN
Wybierając sieć CDN, należy zazwyczaj brać pod uwagę wydajność. Wybierając sieć CDN, należy jednak wziąć pod uwagę inne funkcje dostępne w sieci CDN (np. funkcje zabezpieczeń i analityki), a także ceny, pomoc i wprowadzenie.
Wydajność
Ogólnie rzecz biorąc, strategię wydajności sieci CDN można traktować jako kompromis między minimalizacją czasu oczekiwania a maksymalizacją współczynnika trafień w pamięci podręcznej. Sieci CDN z wieloma punktami obecności mogą skrócić czas oczekiwania, ale mogą wykazywać niższy współczynnik trafień w pamięci podręcznej z powodu rozdzielania ruchu między większą liczbę pamięci podręcznych. I odwrotnie, sieci CDN z mniejszą liczbą punktów dostępu mogą znajdować się w dalszej odległości od użytkowników, ale mogą osiągnąć wyższy współczynnik trafień w pamięci podręcznej.
Z tego powodu niektóre sieci CDN stosują wielopoziomowe podejście do buforowania: punkty POP znajdujące się blisko użytkowników (nazywane też „pamięcią podręczną brzegowej”) są uzupełniane o centralne punkty wirtualne o wyższym współczynniku trafień w pamięci podręcznej. Gdy pamięć podręczna na brzegu nie może znaleźć zasobu, szuka centralnego punktu dostępu dla tego zasobu. To podejście wiąże się z nieco dłuższym czasem oczekiwania, co zwiększa prawdopodobieństwo, że zasób może być udostępniany z pamięci podręcznej CDN, choć niekoniecznie z tymczasowego przechowywania danych na serwerach brzegowych.
Komercja między minimalizacją czasu oczekiwania a maksymalizacją współczynnika trafień w pamięci podręcznej jest szerokim zakresem. Żadne konkretne podejście nie jest uniwersalnie lepsze. Jednak w zależności od charakteru witryny i jej użytkowników może się okazać, że jedno z nich zapewnia znacznie większą skuteczność od drugiego.
Warto też pamiętać, że skuteczność sieci CDN może się znacznie różnić w zależności od położenia geograficznego, pory dnia, a nawet bieżących wydarzeń. Choć zawsze dobrze jest samodzielnie sprawdzić skuteczność sieci CDN, dokładna prognoza jej skuteczności może być trudna.
Wpływ na największe wyrenderowanie treści (LCP)
Jak wspomnieliśmy w tym artykule, głównym celem sieci CDN jest zmniejszenie opóźnień przez dystrybucję zasobów na serwerach znajdujących się bliżej użytkowników. Dlatego główną zaletą sieci CDN jest to, że zwiększa ona wydajność wczytywania. W szczególności możesz znacznie poprawić czas do pierwszego bajtu (TTFB) zasobu, wprowadzając CDN do architektury serwera po stronie serwera.
Chociaż TTFB nie jest wskaźnikiem wydajności skupionym na użytkownikach, to jest ważnym wskaźnikiem przy diagnozowaniu problemów z największym wyrenderowaniem treści (LCP), czyli wartością ukierunkowaną na użytkowników.
Sieci CDN są szczególnie skuteczne w poprawie LCP, ponieważ mogą usprawnić przesyłanie dokumentów (przez zmniejszenie TTFB w konfiguracji połączenia i przechowywaniu dokumentu w pamięci podręcznej) oraz w usprawnianiu dostarczania wszystkich zasobów statycznych niezbędnych do renderowania elementu LCP.
Dodatkowe funkcje
Oprócz podstawowej oferty sieci CDN sieci CDN mają zwykle dostęp do wielu różnych funkcji. Najczęściej oferowane funkcje to: równoważenie obciążenia, optymalizacja obrazu, strumieniowe przesyłanie filmów, przetwarzanie brzegowe i usługi zabezpieczające.
Jak skonfigurować sieć CDN
Idealnym rozwiązaniem jest korzystanie z sieci CDN do wyświetlania reklam w całej witrynie. Ogólnie rzecz biorąc, proces konfiguracji składa się z rejestracji u dostawcy CDN, a potem aktualizacji rekordu DNS CNAME, tak aby wskazywał dostawcę CDN. Na przykład rekord CNAME domeny www.example.com może wskazywać adres example.my-cdn.com. W wyniku tej zmiany DNS ruch do Twojej witryny będzie kierowany przez sieć CDN.
Jeśli nie możesz używać sieci CDN do obsługi wszystkich zasobów, możesz skonfigurować ją tak, aby obsługiwała tylko podzbiór zasobów, np. tylko zasoby statyczne. Możesz to zrobić, tworząc oddzielny rekord CNAME, który będzie używany tylko na potrzeby zasobów, które powinny być obsługiwane przez CDN. Możesz na przykład utworzyć rekord CNAME static.example.com wskazujący na example.my-cdn.com. Konieczne będzie też przepisanie adresów URL zasobów obsługiwanych przez sieć CDN, tak aby wskazywały utworzoną przez Ciebie subdomenę static.example.com.
Mimo że Twoja sieć CDN będzie na tym etapie skonfigurowana, prawdopodobnie zacznie działać nieefektywnie. W kolejnych 2 sekcjach tego artykułu dowiesz się, jak w pełni wykorzystać możliwości sieci CDN, zwiększając współczynnik trafień w pamięci podręcznej i włączając funkcje związane z wydajnością.
Poprawa współczynnika trafień w pamięci podręcznej
Skuteczna konfiguracja CDN będzie obsługiwać jak najwięcej zasobów z pamięci podręcznej. Wartość ta jest zwykle mierzona przez współczynnik trafień w pamięci podręcznej (CHR). Współczynnik trafień w pamięci podręcznej to liczba trafień w pamięci podręcznej podzielona przez liczbę wszystkich żądań w danym przedziale czasu.
Świeżo zainicjowana pamięć podręczna będzie miała wskaźnik CHR równy 0, ale wzrasta on, gdy pamięć podręczna jest zapełniana zasobami. CHR na poziomie 90% to dobry cel dla większości witryn. Twój dostawca CDN powinien dostarczyć Ci analizy i raporty dotyczące CHR.
Podczas optymalizowania CHR wszystkie zasoby, które można zapisać w pamięci podręcznej, są przechowywane w pamięci podręcznej i przechowywane w pamięci podręcznej przez odpowiedni czas. To prosta ocena, którą powinny przeprowadzać wszystkie witryny.
Kolejnym poziomem optymalizacji CHR jest takie dostosowanie ustawień CDN, by logiczne odpowiedzi serwera nie były przechowywane w pamięci podręcznej oddzielnie. Ten błąd występuje często z powodu wpływu na buforowanie takich czynników jak parametry zapytań, pliki cookie i nagłówki żądań.
Wstępny audyt
Większość sieci CDN zapewnia analizę pamięci podręcznej. Narzędzia takie jak WebPageTest i Lighthouse mogą też służyć do szybkiego sprawdzania, czy wszystkie zasoby statyczne strony są przechowywane w pamięci podręcznej przez odpowiedni czas. Można to osiągnąć, sprawdzając nagłówki pamięci podręcznej HTTP każdego zasobu. Buforowanie zasobu przy użyciu maksymalnego odpowiedniego czasu życia (TTL) pozwala uniknąć niepotrzebnego pobierania źródła w przyszłości i tym samym zwiększyć CHR.
Aby zasób mógł być buforowany przez CDN, należy zazwyczaj ustawić co najmniej jeden z tych nagłówków:
Cache-Control: max-age=Cache-Control: s-maxage=Expires
Nie wpływa to też na to, czy i w jaki sposób zasób jest buforowany przez CDN, ale warto też ustawić dyrektywę Cache-Control: immutable.Cache-Control: immutable wskazuje, że zasób „nie będzie aktualizowany przez cały okres jego aktualności”. W rezultacie przeglądarka nie weryfikuje ponownie zasobu przy udostępnianiu go z pamięci podręcznej przeglądarki, co eliminuje niepotrzebne żądania serwera. Ta dyrektywa jest obsługiwana tylko przez Firefoksa i Safari – nie jest ona obsługiwana przez przeglądarki oparte na Chromium. Ten problem śledzi obsługę wersji Cache-Control: immutable przez Chromium. Oznaczenie tego problemu gwiazdką może zachęcić nas do pomocy technicznej dla tej funkcji.
Bardziej szczegółowe informacje o buforowaniu HTTP znajdziesz w artykule Zapobieganie niepotrzebnym żądaniom sieciowym dzięki pamięci podręcznej HTTP.
Dostrajanie
Niewielkim uproszczonym wyjaśnieniem, jak działają pamięci podręczne CDN, jest to, że adres URL zasobu służy do buforowania i pobierania zasobu z pamięci podręcznej. W praktyce jest to w dużej mierze prawda, ale jest ona nieco skomplikowana ze względu na wpływ takich czynników jak nagłówki żądań i parametry zapytań. W związku z tym przepisywanie adresów URL żądań jest ważną techniką zarówno dla maksymalizacji CHR, jak i zapewnienia wyświetlania użytkownikom właściwych treści. Prawidłowo skonfigurowana instancja CDN zachowuje równowagę między zbyt szczegółowym buforowaniem (co zaszkodzi CHR) a niewystarczającym buforowaniem (co skutkuje udostępnianiem użytkownikom nieprawidłowych odpowiedzi).
Parametry zapytania
Domyślnie sieci CDN uwzględniają parametry zapytania podczas buforowania zasobu. Jednak niewielkie modyfikacje obsługi parametrów zapytań mogą mieć znaczny wpływ na CHR. Na przykład:
Niepotrzebne parametry zapytania
Domyślnie sieć CDN będzie przechowywać w pamięci podręcznej oddzielnie
example.com/blogiexample.com/blog?referral_id=2zjk, mimo że prawdopodobnie są to te same zasoby bazowe. Można to naprawić, dostosowując konfigurację sieci CDN w taki sposób, aby ignorowała parametr zapytaniareferral\_id.Kolejność parametrów zapytania
CDN będzie zapisywać
example.com/blog?id=123&query=dogsw pamięci podręcznej niezależnie odexample.com/blog?query=dogs&id=123. W przypadku większości witryn kolejność parametrów zapytań nie ma znaczenia, więc skonfigurowanie sieci CDN pod kątem sortowania parametrów zapytania (to znormalizowanie adresu URL używanego do buforowania odpowiedzi serwera) zwiększy CHR.
Zmieniaj
Nagłówek odpowiedzi Vary informuje pamięć podręczną, że odpowiedź serwera odpowiadająca konkretnemu adresowi URL może się różnić w zależności od nagłówków ustawionych w żądaniu (na przykład od nagłówków żądania Accept-Language lub Accept-Encoding). W efekcie instruuje sieć CDN, aby osobno buforowała te odpowiedzi. Nagłówek Vary nie jest powszechnie obsługiwany przez sieci CDN i może w innym przypadku spowodować, że zasób z pamięci podręcznej nie będzie wyświetlany z pamięci podręcznej.
Nagłówek Vary może być przydatnym narzędziem, ale jego nieprawidłowe użycie szkodzi CHR. Ponadto, jeśli używasz Vary, normalizacja nagłówków żądań pomoże ulepszyć CHR. Na przykład bez normalizacji nagłówki żądań Accept-Language: en-US i Accept-Language: en-US,en;q=0.9 spowodowałoby powstanie 2 osobnych wpisów w pamięci podręcznej, mimo że ich zawartość byłaby prawdopodobnie identyczna.
Ciastka
Pliki cookie są ustawiane w żądaniach przez nagłówek Cookie. Są ustawiane w odpowiedziach za pomocą nagłówka Set-Cookie. Należy unikać niepotrzebnego użycia nagłówka Set-Cookie, ponieważ pamięci podręczne zwykle nie buforują odpowiedzi serwera zawierających ten nagłówek.
Funkcje wydajności
W tej sekcji omawiamy funkcje związane ze skutecznością, które są zwykle oferowane przez sieci CDN w ramach podstawowej oferty usług. Wiele witryn zapomina o włączeniu tych funkcji, co powoduje utratę łatwej w tym celu korzyści.
Kompresja
Wszystkie odpowiedzi tekstowe powinny być skompresowane za pomocą programu gzip lub Brotli. Jeśli masz wybór, wybierz Brotli zamiast gzip. Brotli to nowszy algorytm kompresji, który w porównaniu z gzipem może uzyskać wyższe współczynniki kompresji.
Istnieją 2 typy obsługi CDN w zakresie kompresji Brotli: „Brotli z punktu początkowego” i „automatyczna kompresja Brotli”.
Pochodzenie Brotli
Wskaźnik typu Brotli z punktu początkowego ma miejsce, gdy sieć CDN obsługuje zasoby, które zostały skompresowane przez źródło Brotli. Chociaż może się wydawać, że to funkcja, którą od razu powinna obsługiwać wszystkie sieci CDN, wymaga ona, by sieć CDN mogła buforować wiele wersji (czyli skompresowanych w formacie gzip i Brotli) zasobu odpowiadającego danemu URL-owi.
Automatyczna kompresja Brotli
Automatyczna kompresja Brotli polega na tym, że zasoby są skompresowane przez CDN. Sieci CDN mogą kompresować zasoby możliwe do buforowania i niebuforowane.
Przy pierwszym żądaniu zasobu jest on udostępniany z użyciem „wystarczająco dobrej” kompresji, na przykład Brotli-5. Ten typ kompresji ma zastosowanie zarówno do zasobów, które można zapisać w pamięci podręcznej, jak i tych, których nie można przechowywać w pamięci podręcznej.
Tymczasem, jeśli zasób można buforować, CDN będzie go skompresować na bardziej wydajnym, ale znacznie wolniejszym poziomie kompresji, na przykład Brotli-11. Gdy kompresja się zakończy, bardziej skompresowana wersja będzie przechowywana w pamięci podręcznej i używana w kolejnych żądaniach.
Sprawdzone metody kompresji
Witryny, które chcą zmaksymalizować wydajność, powinny zastosować kompresję Brotli zarówno na serwerze pierwotnym, jak i w sieci CDN. Kompresja Brotli w punkcie początkowym minimalizuje rozmiar transferu zasobów, których nie można obsłużyć z pamięci podręcznej. Aby zapobiec opóźnieniom w żądaniach obsługi, źródło powinno skompresować zasoby dynamiczne przy użyciu dość zachowawczego poziomu kompresji, np. Brotli-4; zasoby statyczne można kompresować przy użyciu Brotli-11. Jeśli źródło nie obsługuje formatu Brotli, do skompresowania zasobów dynamicznych można użyć programu gzip-6, a do skompresowania zasobów statycznych – programu gzip-9.
TLS 1.3
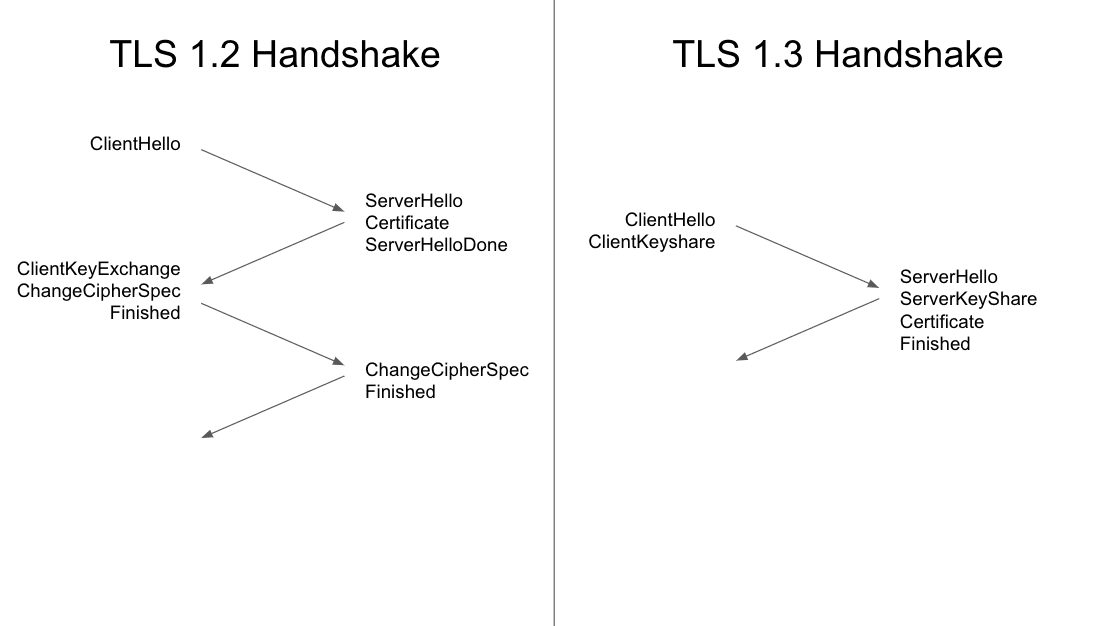
TLS 1.3 to najnowsza wersja protokołu TLS (Transport Layer Security), protokołu kryptograficznego wykorzystywanego w HTTPS. TLS 1.3 zapewnia większą prywatność i lepszą wydajność niż TLS 1.2.
TLS 1.3 skraca uzgadnianie połączenia TLS z dwóch cykli wymiany danych do jednej. W przypadku połączeń korzystających z HTTP/1 lub HTTP/2 skrócenie uzgadniania połączenia TLS do jednej sesji w obie strony skutecznie skraca czas konfiguracji połączenia o 33%.
HTTP/2 i HTTP/3
Zarówno HTTP/2, jak i HTTP/3 zapewniają większą wydajność niż HTTP/1. HTTP/3 ma większe potencjalne korzyści związane z wydajnością. Protokół HTTP/3 nie został jeszcze w pełni ustandaryzowany, ale gdy to nastąpi, będzie powszechnie obsługiwany.
HTTP/2
Jeśli w Twojej sieci CDN nie włączono jeszcze domyślnego protokołu HTTP/2, zastanów się nad włączeniem go. HTTP/2 zapewnia wiele korzyści w wydajności w porównaniu z HTTP/1 i jest obsługiwany przez wszystkie popularne przeglądarki. Funkcje wydajności HTTP/2 obejmują multipleksowanie, nadawanie priorytetów strumieniowi i kompresję nagłówków.
multipleks
Multipleks to prawdopodobnie najważniejsza funkcja HTTP/2. Multipleksowanie umożliwia pojedynczym połączeniu TCP obsługę wielu par żądanie–odpowiedź jednocześnie. Pozwala to wyeliminować konieczność niepotrzebnej konfiguracji połączeń – w związku z tym, że liczba otwartych połączeń, które przeglądarka może otworzyć w danym momencie, jest ograniczona, oznacza to również, że przeglądarka może teraz równolegle żądać większej ilości zasobów strony. Multipleksowanie teoretycznie eliminuje konieczność stosowania optymalizacji HTTP/1, takich jak konkatenacja czy arkusze sprite. W praktyce techniki te pozostaną jednak istotne, ponieważ większe pliki kompresują się lepiej.
Określanie priorytetów transmisji
Multipleks umożliwia obsługę wielu równoczesnych strumieni. Nadawanie priorytetów to interfejs do przekazywania względnego priorytetu każdego z nich. Dzięki temu serwer może najpierw wysłać najważniejsze zasoby, nawet jeśli nie zostały wysłane najpierw.
Przeglądarka określa priorytety strumienia za pomocą drzewa zależności i jest to po prostu deklaracja preferencji: co oznacza, że serwer nie jest zobowiązany do spełniania (lub nawet uwzględnienia) priorytetów określonych przez przeglądarkę. Określanie priorytetów strumienia jest skuteczniejsze, gdy większa część witryny jest wyświetlana przez sieć CDN.
Implementacje CDN związane z określaniem priorytetów zasobów HTTP/2 bardzo się różnią. Aby dowiedzieć się, czy Twoja sieć CDN w pełni i prawidłowo obsługuje nadawanie priorytetów zasobów HTTP/2, przeczytaj artykuł Czy HTTP/2 jest już szybki?.
Chociaż zmiana instancji CDN na HTTP/2 polega w większości na odwróceniu przełącznika, ważne jest dokładne przetestowanie tej zmiany przed jej włączeniem w środowisku produkcyjnym. W przypadku nagłówków żądań i odpowiedzi HTTP/1 i HTTP/2 stosują te same konwencje, ale przy ich przestrzeganiu protokół HTTP/2 nie daje dużo swobody. W związku z tym po włączeniu protokołu HTTP/2 praktyki niezgodne ze specyfikacją, takie jak używanie znaków spoza zestawu ASCII lub wielkich liter w nagłówkach, mogą powodować błędy. W takim przypadku próby pobrania zasobu przez przeglądarkę zakończą się niepowodzeniem. Nieudana próba pobrania będzie widoczna na karcie „Sieć” w Narzędziach deweloperskich. Dodatkowo w konsoli wyświetli się komunikat o błędzie „ERR_HTTP2_PROTOCOL_ERROR”.
HTTP/3
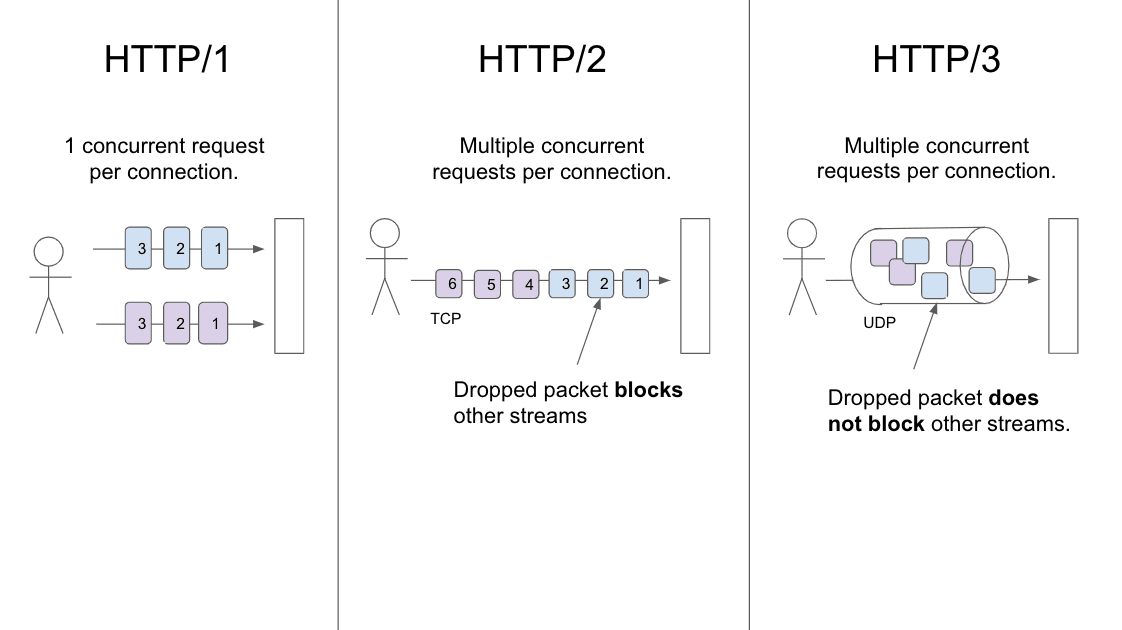
HTTP/3 jest następcą protokołu HTTP/2. Od września 2020 r. wszystkie najpopularniejsze przeglądarki oferują eksperymentalną obsługę HTTP/3, a niektóre sieci CDN obsługują tę funkcję. Wydajność to główna zaleta protokołu HTTP/3 w porównaniu z HTTP/2. Konkretnie HTTP/3 eliminuje blokowanie nagłówka na poziomie połączenia i skraca czas konfiguracji połączenia.
Eliminacja blokowania reklam głównych
W protokole HTTP/2 wprowadzono multipleksowanie, funkcję, która umożliwia używanie pojedynczego połączenia do przesyłania wielu strumieni danych jednocześnie. Jednak w przypadku HTTP/2 pojedynczy utracony pakiet blokuje wszystkie strumienie w połączeniu (zjawisko znane jako blokowanie nagłówka wiersza). W przypadku HTTP/3 utracony pakiet blokuje tylko jeden strumień. To ulepszenie wynika głównie z używania protokołu HTTP/3 przy użyciu protokołu UDP (HTTP/3 używa protokołu UDP przez QUIC), a nie TCP. Dzięki temu protokół HTTP/3 jest szczególnie przydatny przy przesyłaniu danych w przeciążonych lub stratnych sieciach.
Krótszy czas konfiguracji połączenia
HTTP/3 korzysta z protokołu TLS 1.3, dzięki czemu ma zalety związane z wydajnością: nawiązanie nowego połączenia wymaga tylko jednej odpowiedzi w obie strony, a wznowienie istniejącego połączenia nie wymaga przesyłania w obie strony.
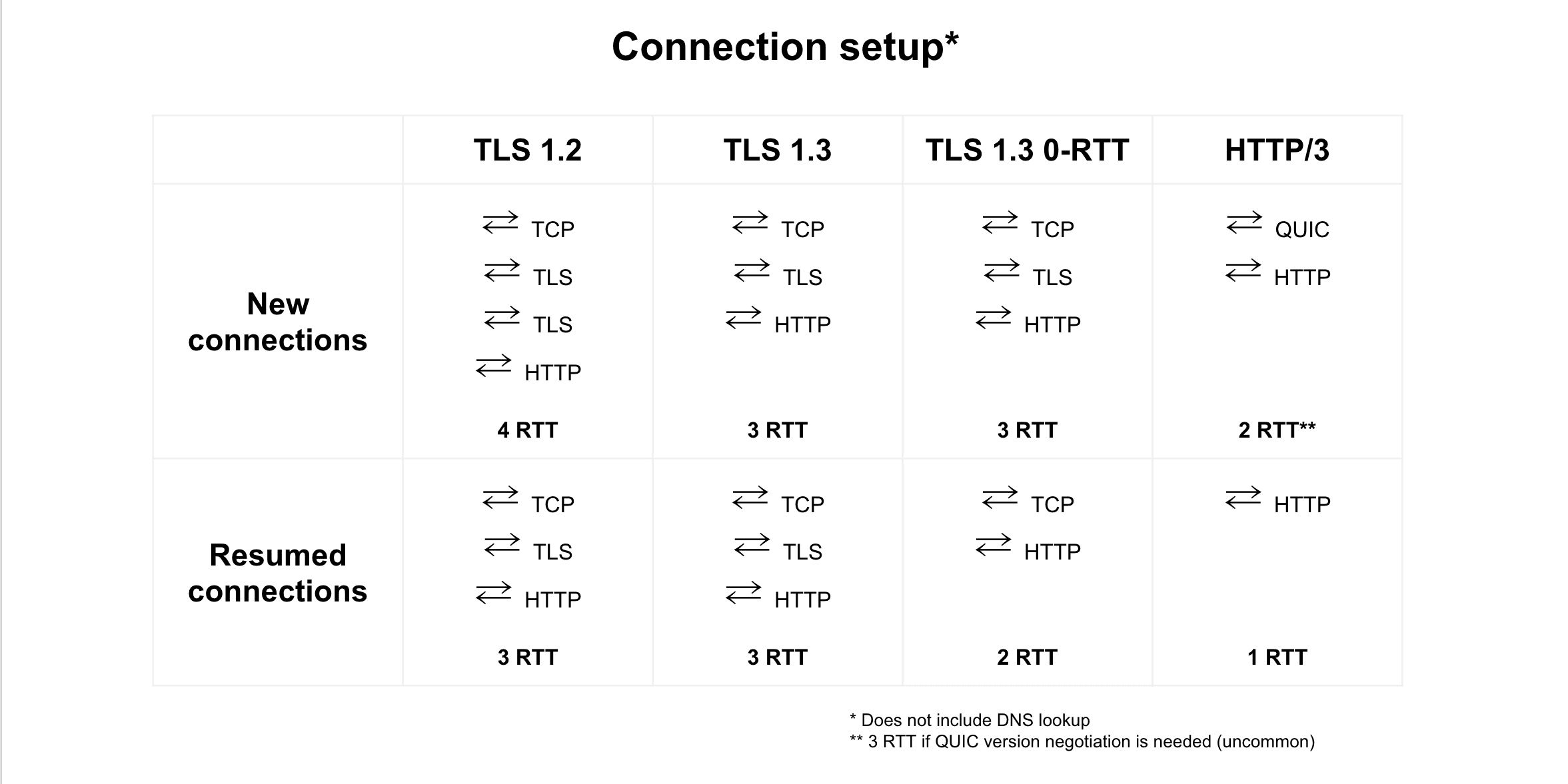
HTTP/3 ma największy wpływ na użytkowników korzystających z połączeń o niskiej jakości. Nie tylko dlatego, że protokół HTTP/3 obsługuje utratę pakietów lepiej niż jego poprzednicy, ale też bezwzględna oszczędność czasu wynikająca z konfiguracji połączenia 0-RTT lub 1-RTT będzie większa w przypadku sieci o dużych opóźnieniach.
Optymalizacja obrazu
Usługi optymalizacji obrazu CDN koncentrują się zwykle na optymalizacji obrazu, który można zastosować automatycznie, aby zmniejszyć rozmiar przesyłanych obrazów. Dotyczy to na przykład usuwania danych EXIF, stosowania kompresji bezstratnej czy konwertowania obrazów do nowszych formatów plików (np. WebP). Obrazy stanowią ok. 50% bajtów przesyłanych na stronę, dlatego zoptymalizowanie ich może znacznie zmniejszyć rozmiar strony.
Minifikacja
Zmniejszanie usuwa niepotrzebne znaki z JavaScriptu, CSS i HTML. Lepiej jest przeprowadzać minifikację na serwerze pierwotnym zamiast w sieci CDN. Właściciele witryn mają więcej informacji o kodzie do zmniejszenia, więc często mogą stosować bardziej agresywne techniki minifikacji niż te stosowane w sieciach CDN. Jeśli jednak zmniejszanie kodu w punkcie początkowym nie jest możliwe, dobrą alternatywą jest minifikacja przy użyciu sieci CDN.
Podsumowanie
- Korzystaj z sieci CDN: sieci CDN szybko dostarczają zasoby, zmniejszają obciążenie serwera pierwotnego i pomagają radzić sobie ze wzrostem natężenia ruchu.
- Jak najbardziej agresywnie buforuj treść: zarówno treści statyczne, jak i dynamiczne mogą i powinny być przechowywane w pamięci podręcznej, chociaż na różne czasy. Od czasu do czasu sprawdzaj, czy treść buforowana jest w swojej witrynie optymalnie.
- Włącz funkcje wydajności CDN: funkcje takie jak Brotli, TLS 1.3, HTTP/2 i HTTP/3 dodatkowo zwiększają wydajność.