
आधुनिक वेब ब्राउज़र के बारे में जानकारी


प्रस्तावना
WebKit और Gecko के इंटरनल ऑपरेशन के बारे में यह पूरी जानकारी, इज़रायल के डेवलपर ताली गार्सियल की रिसर्च का नतीजा है. कुछ सालों में, उन्होंने ब्राउज़र के इंटरनल के बारे में पब्लिश किए गए सभी डेटा की समीक्षा की. साथ ही, वेब ब्राउज़र के सोर्स कोड को पढ़ने में काफ़ी समय बिताया. उन्होंने लिखा:
वेब डेवलपर के तौर पर, ब्राउज़र के काम करने के तरीके के बारे में जानने से, आपको बेहतर फ़ैसले लेने में मदद मिलती है. साथ ही, डेवलपमेंट के सबसे सही तरीकों के पीछे की वजहों के बारे में भी पता चलता है. यह दस्तावेज़ काफ़ी लंबा है, लेकिन हमारा सुझाव है कि आप इसे ज़रूर पढ़ें. आपको बहुत खुशी होगी.
पॉल आयरिश, Chrome डेवलपर रिलेशनशिप
परिचय
वेब ब्राउज़र, सबसे ज़्यादा इस्तेमाल होने वाले सॉफ़्टवेयर हैं. इस प्राइमर में, मैंने बताया है कि ये सुविधाएं कैसे काम करती हैं. हम देखेंगे कि जब ब्राउज़र की स्क्रीन पर Google पेज दिखने तक, पता बार में google.com लिखा जाता है, तो क्या होता है.
हम इन ब्राउज़र के बारे में बात करेंगे
फ़िलहाल, डेस्कटॉप पर पांच मुख्य ब्राउज़र इस्तेमाल किए जाते हैं: Chrome, Internet Explorer, Firefox, Safari, और Opera. मोबाइल पर, मुख्य ब्राउज़र Android Browser, iPhone, Opera Mini और Opera Mobile, UC Browser, Nokia S40/S60 ब्राउज़र, और Chrome हैं. Opera ब्राउज़र को छोड़कर, ये सभी WebKit पर आधारित हैं. हम ओपन सोर्स ब्राउज़र Firefox और Chrome के साथ-साथ Safari (जो कुछ हद तक ओपन सोर्स है) के उदाहरण देंगे. StatCounter के आंकड़ों के मुताबिक (जून 2013 तक), दुनिया भर में डेस्कटॉप ब्राउज़र के इस्तेमाल में Chrome, Firefox, और Safari का योगदान करीब 71% है. मोबाइल पर, Android ब्राउज़र, iPhone, और Chrome का इस्तेमाल 54% तक होता है.
ब्राउज़र की मुख्य सुविधाएं
ब्राउज़र का मुख्य फ़ंक्शन, आपके चुने गए वेब संसाधन को दिखाना होता है. इसके लिए, वह सर्वर से अनुरोध करता है और उसे ब्राउज़र विंडो में दिखाता है. आम तौर पर, संसाधन एक एचटीएमएल दस्तावेज़ होता है. हालांकि, यह PDF, इमेज या किसी अन्य तरह का कॉन्टेंट भी हो सकता है. यूआरआई (यूनिफ़ॉर्म रिसॉर्स आइडेंटिफ़ायर) का इस्तेमाल करके, उपयोगकर्ता रिसॉर्स की जगह तय करता है.
एचटीएमएल और सीएसएस की खास बातों में बताया गया है कि ब्राउज़र, एचटीएमएल फ़ाइलों को कैसे समझता और दिखाता है. इन खास बातों को W3C (वर्ल्ड वाइड वेब कंसोर्टियम) संगठन मैनेज करता है. यह वेब के लिए स्टैंडर्ड तय करने वाला संगठन है. कई सालों तक ब्राउज़र, खास बातों के सिर्फ़ एक हिस्से का पालन करते थे और अपने एक्सटेंशन डेवलप करते थे. इससे वेब लेखकों को, अलग-अलग ब्राउज़र के साथ काम करने में गंभीर समस्याएं आ रही थीं. फ़िलहाल, ज़्यादातर ब्राउज़र इन खास बातों के मुताबिक काम करते हैं.
ब्राउज़र के यूज़र इंटरफ़ेस एक-दूसरे से काफ़ी मिलते-जुलते हैं. यूज़र इंटरफ़ेस के सामान्य एलिमेंट में ये शामिल हैं:
- यूआरआई डालने के लिए पता बार
- 'वापस जाएं' और 'आगे बढ़ें' बटन
- बुकमार्क करने के विकल्प
- मौजूदा दस्तावेज़ों को रीफ़्रेश करने या लोड होने से रोकने के लिए, रीफ़्रेश और रोकें बटन
- होम बटन, जो आपको होम पेज पर ले जाता है
हैरानी की बात यह है कि ब्राउज़र के यूज़र इंटरफ़ेस के बारे में किसी भी आधिकारिक स्पेसिफ़िकेशन में नहीं बताया गया है. यह सिर्फ़ सालों के अनुभव से बने अच्छे तरीकों और ब्राउज़र की एक-दूसरे की नकल करने से आता है. HTML5 स्पेसिफ़िकेशन में, ब्राउज़र में मौजूद होने वाले यूज़र इंटरफ़ेस (यूआई) एलिमेंट के बारे में नहीं बताया गया है. हालांकि, इसमें कुछ सामान्य एलिमेंट की सूची दी गई है. इनमें पता बार, स्टेटस बार, और टूल बार शामिल हैं. हालांकि, कुछ सुविधाएं किसी खास ब्राउज़र के लिए खास होती हैं. जैसे, Firefox का डाउनलोड मैनेजर.
हाई-लेवल इन्फ़्रास्ट्रक्चर
ब्राउज़र के मुख्य कॉम्पोनेंट ये हैं:
- यूज़र इंटरफ़ेस: इसमें पता बार, पीछे/आगे जाने का बटन, बुकमार्क करने वाला मेन्यू वगैरह शामिल है. अनुरोध किया गया पेज दिखाने वाली विंडो को छोड़कर, ब्राउज़र के डिसप्ले का हर हिस्सा.
- ब्राउज़र इंजन: यह यूज़र इंटरफ़ेस (यूआई) और रेंडरिंग इंजन के बीच की कार्रवाइयों को मैर्शल करता है.
- रेंडरिंग इंजन: अनुरोध किया गया कॉन्टेंट दिखाने के लिए ज़िम्मेदार. उदाहरण के लिए, अगर अनुरोध किया गया कॉन्टेंट एचटीएमएल है, तो रेंडरिंग इंजन एचटीएमएल और सीएसएस को पार्स करता है और पार्स किए गए कॉन्टेंट को स्क्रीन पर दिखाता है.
- नेटवर्किंग: एचटीटीपी अनुरोधों जैसे नेटवर्क कॉल के लिए, प्लैटफ़ॉर्म पर काम करने वाले इंटरफ़ेस के पीछे, अलग-अलग प्लैटफ़ॉर्म के लिए अलग-अलग तरीके इस्तेमाल किए जाते हैं.
- यूज़र इंटरफ़ेस (यूआई) बैकएंड: इसका इस्तेमाल, कॉम्बो बॉक्स और विंडो जैसे बुनियादी विजेट बनाने के लिए किया जाता है. यह बैकएंड, एक सामान्य इंटरफ़ेस दिखाता है, जो किसी खास प्लैटफ़ॉर्म के लिए नहीं है. इसके तहत, ऑपरेटिंग सिस्टम के यूज़र इंटरफ़ेस के तरीकों का इस्तेमाल किया जाता है.
- JavaScript इंटरप्रिटर. इसका इस्तेमाल, JavaScript कोड को पार्स और लागू करने के लिए किया जाता है.
- डेटा स्टोरेज. यह पर्सिस्टेंस लेयर है. ब्राउज़र को स्थानीय रूप से सभी तरह का डेटा सेव करना पड़ सकता है, जैसे कि कुकी. ब्राउज़र, localStorage, IndexedDB, WebSQL, और फ़ाइल सिस्टम जैसे स्टोरेज मेकेनिज्म के साथ भी काम करते हैं.
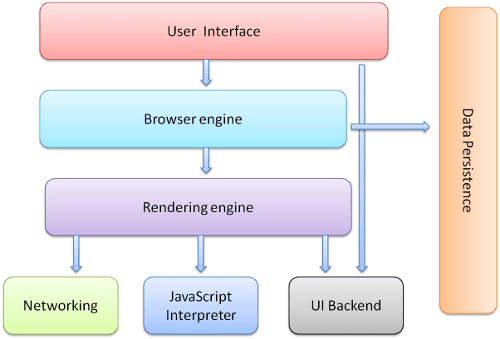
यह ध्यान रखना ज़रूरी है कि Chrome जैसे ब्राउज़र, रेंडरिंग इंजन के कई इंस्टेंस चलाते हैं: हर टैब के लिए एक. हर टैब, एक अलग प्रोसेस में चलता है.
रेंडरिंग इंजन
रेंडरिंग इंजन की ज़िम्मेदारी है… रेंडरिंग करना. इसका मतलब है कि अनुरोध किए गए कॉन्टेंट को ब्राउज़र की स्क्रीन पर दिखाना.
रेंडरिंग इंजन, डिफ़ॉल्ट रूप से एचटीएमएल और एक्सएमएल दस्तावेज़ और इमेज दिखा सकता है. यह प्लग-इन या एक्सटेंशन की मदद से, अन्य तरह का डेटा दिखा सकता है. उदाहरण के लिए, PDF व्यूअर प्लग-इन का इस्तेमाल करके PDF दस्तावेज़ दिखाना. हालांकि, इस चैप्टर में हम मुख्य इस्तेमाल के उदाहरण पर फ़ोकस करेंगे: सीएसएस का इस्तेमाल करके फ़ॉर्मैट की गई एचटीएमएल और इमेज दिखाना.
अलग-अलग ब्राउज़र, अलग-अलग रेंडरिंग इंजन का इस्तेमाल करते हैं: Internet Explorer, Trident का इस्तेमाल करता है, Firefox, Gecko का इस्तेमाल करता है, और Safari, WebKit का इस्तेमाल करता है. Chrome और Opera (15 वर्शन से), WebKit के फ़ॉर्क Blink का इस्तेमाल करते हैं.
WebKit एक ओपन सोर्स रेंडरिंग इंजन है. इसे Linux प्लैटफ़ॉर्म के लिए इंजन के तौर पर शुरू किया गया था. Apple ने इसे Mac और Windows के साथ काम करने के लिए बदलाव किया था.
मुख्य फ़्लो
रेंडरिंग इंजन, अनुरोध किए गए दस्तावेज़ का कॉन्टेंट, नेटवर्किंग लेयर से पाने लगेगा. आम तौर पर, यह 8 केबी के हिस्सों में किया जाएगा.
इसके बाद, रेंडरिंग इंजन का बुनियादी फ़्लो यह है:

रेंडरिंग इंजन, एचटीएमएल दस्तावेज़ को पार्स करना शुरू कर देगा और एलिमेंट को "कॉन्टेंट ट्री" नाम के ट्री में डीओएम नोड में बदल देगा. इंजन, बाहरी सीएसएस फ़ाइलों और स्टाइल एलिमेंट, दोनों में स्टाइल डेटा को पार्स करेगा. एचटीएमएल में विज़ुअल निर्देशों के साथ स्टाइल की जानकारी का इस्तेमाल, एक और ट्री बनाने के लिए किया जाएगा: रेंडर ट्री.
रेंडर ट्री में, रंग और डाइमेंशन जैसे विज़ुअल एट्रिब्यूट वाले रेक्टैंगल होते हैं. स्क्रीन पर दिखाए जाने के लिए, रेक्टैंगल सही क्रम में हों.
रेंडर ट्री बनने के बाद, उसे "लेआउट" की प्रोसेस से गुज़रना पड़ता है. इसका मतलब है कि हर नोड को स्क्रीन पर दिखने की सटीक जगह के निर्देशांक देना. अगला चरण पेंटिंग है - रेंडर ट्री को ट्रैवर्स किया जाएगा और यूज़र इंटरफ़ेस (यूआई) बैकएंड लेयर का इस्तेमाल करके हर नोड को पेंट किया जाएगा.
यह समझना ज़रूरी है कि यह प्रोसेस धीरे-धीरे पूरी होती है. बेहतर उपयोगकर्ता अनुभव के लिए, रेंडरिंग इंजन, कॉन्टेंट को स्क्रीन पर जल्द से जल्द दिखाने की कोशिश करेगा. यह रेंडर ट्री बनाने और लेआउट करने से पहले, पूरे एचटीएमएल के पार्स होने का इंतज़ार नहीं करेगा. कॉन्टेंट के कुछ हिस्सों को पार्स करके दिखाया जाएगा. साथ ही, नेटवर्क से आने वाले बाकी कॉन्टेंट के लिए भी यह प्रोसेस जारी रहेगी.
मुख्य फ़्लो के उदाहरण
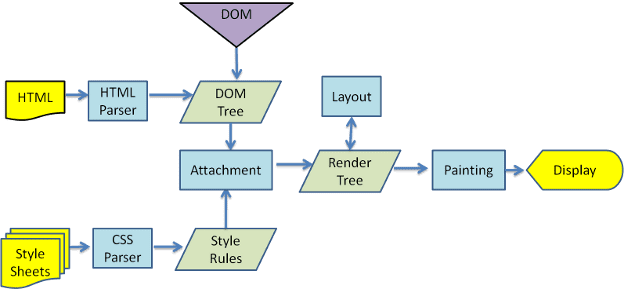
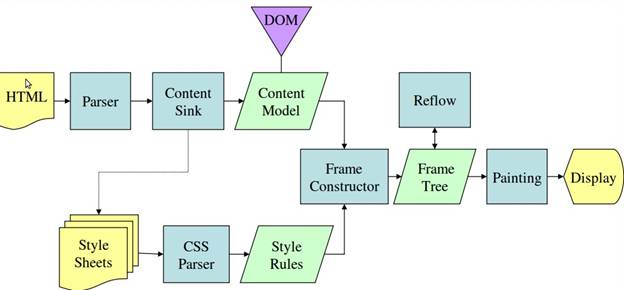
तीसरे और चौथे चित्र से पता चलता है कि WebKit और Gecko, थोड़ी अलग शब्दावली का इस्तेमाल करते हैं. हालांकि, फ़्लो एक जैसा ही है.
Gecko, विज़ुअल तौर पर फ़ॉर्मैट किए गए एलिमेंट के ट्री को "फ़्रेम ट्री" कहता है. हर एलिमेंट एक फ़्रेम होता है. WebKit, "रेंडर ट्री" शब्द का इस्तेमाल करता है. इसमें "रेंडर ऑब्जेक्ट" होते हैं. WebKit, एलिमेंट को प्लेस करने के लिए "लेआउट" शब्द का इस्तेमाल करता है, जबकि Gecko इसे "रीफ़्लो" कहता है. "अटैचमेंट", WebKit का वह शब्द है जिसका इस्तेमाल रेंडर ट्री बनाने के लिए, डीओएम नोड और विज़ुअल जानकारी को जोड़ने के लिए किया जाता है. एक छोटा सा गैर-समानार्थी अंतर यह है कि Gecko में एचटीएमएल और डीओएम ट्री के बीच एक अतिरिक्त लेयर होती है. इसे "कॉन्टेंट सिंक" कहा जाता है. यह डीओएम एलिमेंट बनाने वाली फ़ैक्ट्री है. हम फ़्लो के हर हिस्से के बारे में बात करेंगे:
पार्स करना - सामान्य जानकारी
पार्स करना, रेंडरिंग इंजन में एक बहुत अहम प्रोसेस है. इसलिए, हम इस बारे में थोड़ी ज़्यादा जानकारी देंगे. आइए, पार्स करने के बारे में थोड़ी जानकारी से शुरुआत करते हैं.
किसी दस्तावेज़ को पार्स करने का मतलब है, उसे ऐसे स्ट्रक्चर में बदलना जिसका इस्तेमाल कोड कर सके. आम तौर पर, पार्स करने का नतीजा नोड का एक ट्री होता है, जो दस्तावेज़ के स्ट्रक्चर को दिखाता है. इसे पार्स ट्री या सिंटैक्स ट्री कहा जाता है.
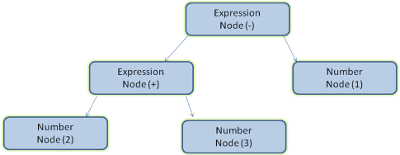
उदाहरण के लिए, एक्सप्रेशन 2 + 3 - 1 को पार्स करने पर, यह ट्री दिख सकता है:
व्याकरण
पार्सिंग, सिंटैक्स के उन नियमों पर आधारित होती है जिनका दस्तावेज़ पालन करता है: वह भाषा या फ़ॉर्मैट जिसमें उसे लिखा गया था. जिस भी फ़ॉर्मैट को पार्स किया जा सकता है उसमें व्याकरण का इस्तेमाल होना चाहिए. इसमें शब्दावली और सिंटैक्स के नियम शामिल होने चाहिए. इसे कॉन्टेक्स्ट फ़्री ग्रामर कहा जाता है. मानव भाषाएं ऐसी भाषाएं नहीं हैं. इसलिए, उन्हें पार्स करने के लिए, पार्स करने की पारंपरिक तकनीकों का इस्तेमाल नहीं किया जा सकता.
पार्सर - लेक्सर का कॉम्बिनेशन
पार्सिंग को दो उप-प्रोसेस में बांटा जा सकता है: लेक्सिकल विश्लेषण और सिंटैक्स विश्लेषण.
लेक्सिकल विश्लेषण, इनपुट को टोकन में बांटने की प्रोसेस है. टोकन, भाषा की शब्दावली होते हैं: मान्य बिल्डिंग ब्लॉक का कलेक्शन. सामान्य भाषा में, इसमें उस भाषा की डिक्शनरी में मौजूद सभी शब्द शामिल होंगे.
सिंटैक्स का विश्लेषण, भाषा के सिंटैक्स के नियमों को लागू करना है.
आम तौर पर, पार्स करने वाले टूल, काम को दो कॉम्पोनेंट में बांटते हैं: लेक्सर (इसे कभी-कभी टोकनेटर भी कहा जाता है), जो इनपुट को मान्य टोकन में बांटने के लिए ज़िम्मेदार होता है. दूसरा, पार्सर, जो भाषा के सिंटैक्स नियमों के हिसाब से दस्तावेज़ के स्ट्रक्चर का विश्लेषण करके, पार्स ट्री बनाता है.
लेक्सर, व्हाइट स्पेस और लाइन ब्रेक जैसे ग़ैर-ज़रूरी वर्णों को हटाने का तरीका जानता है.
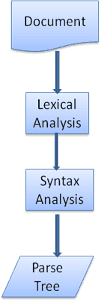
पार्स करने की प्रोसेस बार-बार इस्तेमाल होती है. आम तौर पर, पार्स करने वाला टूल, लेक्सर से नया टोकन मांगेगा और टोकन को सिंटैक्स के किसी नियम से मैच करने की कोशिश करेगा. अगर कोई नियम मैच होता है, तो पार्स ट्री में टोक़न से जुड़ा एक नोड जोड़ दिया जाएगा. इसके बाद, पार्स करने वाला टूल किसी दूसरे टोक़न के लिए कहेगा.
अगर कोई नियम मेल नहीं खाता है, तो पार्स करने वाला टूल, टोक़न को अंदरूनी रूप से सेव करेगा. साथ ही, तब तक टोक़न मांगता रहेगा, जब तक अंदरूनी रूप से सेव किए गए सभी टोक़न से मेल खाने वाला कोई नियम नहीं मिल जाता. अगर कोई नियम नहीं मिलता है, तो पार्स करने वाला टूल एक अपवाद दिखाएगा. इसका मतलब है कि दस्तावेज़ अमान्य था और उसमें सिंटैक्स से जुड़ी गड़बड़ियां थीं.
अनुवाद
कई मामलों में, पार्स ट्री ही फ़ाइनल प्रॉडक्ट नहीं होता. पार्सिंग का इस्तेमाल, अक्सर अनुवाद में किया जाता है: इनपुट दस्तावेज़ को किसी दूसरे फ़ॉर्मैट में बदलना. इसका एक उदाहरण है, कलेक्शन. सोर्स कोड को मशीन कोड में कंपाइल करने वाला कंपाइलर, पहले उसे पार्स ट्री में पार्स करता है. इसके बाद, ट्री को मशीन कोड दस्तावेज़ में बदल देता है.
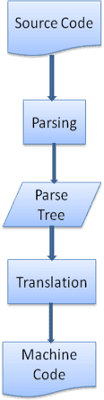
पार्स करने का उदाहरण
पांचवें चित्र में, हमने मैथमैटिकल एक्सप्रेशन से पार्स ट्री बनाया है. आइए, गणित की आसान भाषा को परिभाषित करने की कोशिश करते हैं और पार्स करने की प्रोसेस देखते हैं.
सिंटैक्स:
- भाषा के सिंटैक्स के बिल्डिंग ब्लॉक, एक्सप्रेशन, शब्द, और ऑपरेशन होते हैं.
- हमारी भाषा में जितने चाहें उतने एक्सप्रेशन शामिल किए जा सकते हैं.
- एक्सप्रेशन को "टर्म" के तौर पर परिभाषित किया जाता है. इसके बाद, "ऑपरेशन" और फिर एक और टर्म होता है
- ऑपरेशन, प्लस टोकन या माइनस टोकन होता है
- शब्द, इंटीजर टोकन या एक्सप्रेशन होता है
आइए, इनपुट 2 + 3 - 1 का विश्लेषण करते हैं.
किसी नियम से मैच करने वाली पहली सबस्ट्रिंग 2 है: नियम #5 के मुताबिक, यह एक शब्द है.
दूसरा मैच 2 + 3 है: यह तीसरे नियम से मेल खाता है: किसी शब्द के बाद कोई ऑपरेशन और उसके बाद कोई दूसरा शब्द.
अगला मैच सिर्फ़ इनपुट के आखिर में हिट होगा.
2 + 3 - 1 एक एक्सप्रेशन है, क्योंकि हम पहले से जानते हैं कि 2 + 3एक शब्द है. इसलिए, हमारे पास एक शब्द के बाद एक ऑपरेशन और उसके बाद एक और शब्द है.
2 + + किसी भी नियम से मैच नहीं करेगा. इसलिए, यह अमान्य इनपुट है.
शब्दावली और सिंटैक्स की औपचारिक परिभाषाएं
आम तौर पर, शब्दावली को रेगुलर एक्सप्रेशन से दिखाया जाता है.
उदाहरण के लिए, हमारी भाषा इस तरह से तय की जाएगी:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
जैसा कि आप देख सकते हैं, पूर्णांकों को रेगुलर एक्सप्रेशन से तय किया जाता है.
सिंटैक्स को आम तौर पर BNF नाम के फ़ॉर्मैट में तय किया जाता है. हमारी भाषा को इस तरह से परिभाषित किया जाएगा:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
हमने बताया था कि किसी भाषा को रेगुलर पार्सर से पार्स किया जा सकता है, बशर्ते उसका व्याकरण, कॉन्टेक्स्ट फ़्री ग्रामर हो. कॉन्टेक्स्ट फ़्री ग्रामर की आसान परिभाषा यह है कि यह एक ऐसा ग्रामर है जिसे पूरी तरह से बीएनएफ़ में दिखाया जा सकता है. इसकी औपचारिक परिभाषा के लिए, कॉन्टेक्स्ट-फ़्री ग्रामर के बारे में Wikipedia का लेख देखें
पार्सर के टाइप
पार्सर दो तरह के होते हैं: टॉप डाउन पार्सर और बॉटम अप पार्सर. आसान शब्दों में समझाने के लिए, यह कहा जा सकता है कि टॉप डाउन पार्सर, सिंटैक्स के हाई लेवल स्ट्रक्चर की जांच करते हैं और नियम से मैच होने वाले एलिमेंट ढूंढने की कोशिश करते हैं. बॉटम अप पार्सर, इनपुट से शुरू होते हैं और धीरे-धीरे इसे सिंटैक्स नियमों में बदल देते हैं. ये निचले लेवल के नियमों से शुरू होकर, उच्च लेवल के नियमों तक पहुंचते हैं.
आइए, देखें कि दो तरह के पार्स करने वाले टूल, हमारे उदाहरण को कैसे पार्स करेंगे.
टॉप-डाउन पार्सर, सबसे ऊपर के लेवल के नियम से शुरू होगा: यह 2 + 3 को एक्सप्रेशन के तौर पर पहचानेगा. इसके बाद, यह 2 + 3 - 1 को एक्सप्रेशन के तौर पर पहचानेगा. एक्सप्रेशन की पहचान करने की प्रोसेस, दूसरे नियमों से मैच करके आगे बढ़ती है. हालांकि, शुरुआती पॉइंट सबसे ऊंचे लेवल का नियम होता है.
बॉटम अप पार्सर, इनपुट को तब तक स्कैन करता रहेगा, जब तक किसी नियम से मेल नहीं खाता. इसके बाद, यह मेल खाने वाले इनपुट को नियम से बदल देगा. यह तब तक चलता रहेगा, जब तक इनपुट पूरा नहीं हो जाता. कुछ हद तक मैच होने वाला एक्सप्रेशन, पार्स करने वाले टूल के स्टैक पर रखा जाता है.
इस तरह के बॉटम अप पार्सर को शिफ़्ट-कम पार्सर कहा जाता है, क्योंकि इनपुट को दाईं ओर शिफ़्ट किया जाता है (एक पॉइंटर की कल्पना करें जो पहले इनपुट की शुरुआत पर होता है और दाईं ओर बढ़ता है). साथ ही, इसे सिंटैक्स नियमों में धीरे-धीरे कम किया जाता है.
पार्सर अपने-आप जनरेट होना
ऐसे टूल हैं जिनकी मदद से पार्सर जनरेट किया जा सकता है. आपको अपनी भाषा का व्याकरण - उसकी शब्दावली और सिंटैक्स के नियम - डालने होते हैं. इसके बाद, ये काम करने वाला पार्स करने वाला टूल जनरेट करते हैं. पार्सर बनाने के लिए, पार्सर के बारे में अच्छी तरह से जानना ज़रूरी है. साथ ही, मैन्युअल तरीके से ऑप्टिमाइज़ किया गया पार्सर बनाना आसान नहीं है. इसलिए, पार्सर जनरेटर का इस्तेमाल करना काफ़ी मददगार हो सकता है.
WebKit, दो जाने-माने पार्सर जनरेटर का इस्तेमाल करता है: लेक्सर बनाने के लिए Flex और पार्सर बनाने के लिए Bison. आपको ये Lex और Yacc के नाम से भी मिल सकते हैं. फ़्लेक्स इनपुट एक ऐसी फ़ाइल होती है जिसमें टोकन के रेगुलर एक्सप्रेशन की परिभाषाएं होती हैं. Bison का इनपुट, BNF फ़ॉर्मैट में भाषा के सिंटैक्स के नियम होते हैं.
एचटीएमएल पार्सर
एचटीएमएल पार्सर का काम, एचटीएमएल मार्कअप को पार्स ट्री में पार्स करना है.
एचटीएमएल व्याकरण
एचटीएमएल की शब्दावली और सिंटैक्स, W3C संगठन की बनाई गई खास बातों में बताया गया है.
जैसा कि हमने पार्सिंग के बारे में बताने वाले लेख में देखा है, व्याकरण के सिंटैक्स को BNF जैसे फ़ॉर्मैट का इस्तेमाल करके, औपचारिक तौर पर तय किया जा सकता है.
माफ़ करें, पार्सर के सभी सामान्य विषय एचटीएमएल पर लागू नहीं होते. मैंने इन्हें सिर्फ़ मनोरंजन के लिए नहीं बताया है - इनका इस्तेमाल सीएसएस और JavaScript को पार्स करने में किया जाएगा. एचटीएमएल को आसानी से उस कॉन्टेक्स्ट फ़्री ग्रामर से परिभाषित नहीं किया जा सकता जिसकी पार्स करने वालों को ज़रूरत होती है.
एचटीएमएल को तय करने के लिए एक फ़ॉर्मल फ़ॉर्मैट है - डीटीडी (दस्तावेज़ टाइप की परिभाषा) - लेकिन यह कॉन्टेक्स्ट फ़्री ग्रामर नहीं है.
पहली नज़र में यह अजीब लगता है, क्योंकि एचटीएमएल, एक्सएमएल से काफ़ी मिलता-जुलता है. एक्सएमएल पार्स करने वाले कई टूल उपलब्ध हैं. एचटीएमएल का एक एक्सएमएल वैरिएशन है - एक्सएचटीएमएल - तो इन दोनों में क्या फ़र्क़ है?
अंतर यह है कि एचटीएमएल का तरीका ज़्यादा "माफ़ करने वाला" है: इससे आपको कुछ टैग छोड़ने की अनुमति मिलती है (जिन्हें बाद में अपने-आप जोड़ दिया जाता है) या कभी-कभी शुरुआत या आखिर में मौजूद टैग छोड़ने की अनुमति मिलती है वगैरह. कुल मिलाकर, यह एक "सॉफ़्ट" सिंटैक्स है, जबकि एक्सएमएल का सिंटैक्स सख्त और ज़्यादा ज़रूरी है.
यह छोटी सी जानकारी काफ़ी मायने रखती है. एक तरफ़, एचटीएमएल इतना लोकप्रिय होने की मुख्य वजह यह है कि यह आपकी गलतियां माफ़ कर देता है और वेब लेखक के लिए काम को आसान बना देता है. दूसरी ओर, इससे फ़ॉर्मल व्याकरण लिखना मुश्किल हो जाता है. इसलिए, खास तौर पर यह बताना ज़रूरी है कि एचटीएमएल को पारंपरिक पार्स करने वाले टूल आसानी से पार्स नहीं कर सकते, क्योंकि इसका व्याकरण कॉन्टेक्स्ट फ़्री नहीं है. एक्सएमएल पार्सर, एचटीएमएल को पार्स नहीं कर सकते.
एचटीएमएल डीटीडी
एचटीएमएल डेफ़िनिशन, डीटीडी फ़ॉर्मैट में हो. इस फ़ॉर्मैट का इस्तेमाल, SGML फ़ैमिली की भाषाओं को तय करने के लिए किया जाता है. इस फ़ॉर्मैट में, इस्तेमाल किए जा सकने वाले सभी एलिमेंट, उनके एट्रिब्यूट, और हैरारकी की परिभाषाएं शामिल होती हैं. जैसा कि हमने पहले देखा था, एचटीएमएल डीटीडी, कॉन्टेक्स्ट-फ़्री ग्रामर नहीं बनाता.
डीटीडी के कुछ वैरिएंट हैं. स्ट्रिक्ट मोड, सिर्फ़ खास बातों के मुताबिक काम करता है. हालांकि, दूसरे मोड में ब्राउज़र के पहले इस्तेमाल किए गए मार्कअप के लिए सहायता होती है. इसका मकसद, पुराने वीडियो के साथ काम करना है. सख्त DTD का मौजूदा वर्शन यहां दिया गया है: www.w3.org/TR/html4/strict.dtd
डीओएम
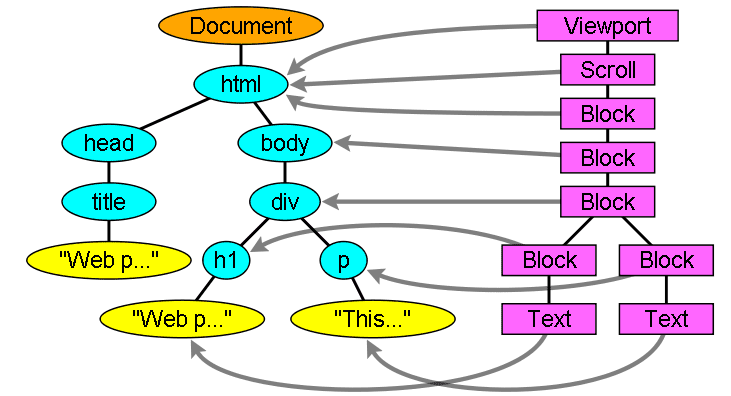
आउटपुट ट्री ("पार्स ट्री"), डीओएम एलिमेंट और एट्रिब्यूट नोड का ट्री होता है. डीओएम, डॉक्यूमेंट ऑब्जेक्ट मॉडल का छोटा नाम है. यह एचटीएमएल दस्तावेज़ का ऑब्जेक्ट प्रज़ेंटेशन और JavaScript जैसे बाहरी दुनिया के लिए एचटीएमएल एलिमेंट का इंटरफ़ेस है.
ट्री का रूट, "दस्तावेज़" ऑब्जेक्ट होता है.
डीओएम का मार्कअप से एक-एक का संबंध होता है. उदाहरण के लिए:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
इस मार्कअप को इस डीओएम ट्री में बदल दिया जाएगा:
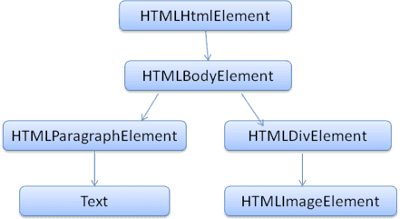
एचटीएमएल की तरह, डीओएम को भी W3C संगठन तय करता है. www.w3.org/DOM/DOMTR देखें. यह दस्तावेज़ों में बदलाव करने के लिए सामान्य तौर पर इस्तेमाल होने वाली जानकारी है. किसी खास मॉड्यूल में, एचटीएमएल के खास एलिमेंट के बारे में बताया जाता है. एचटीएमएल की परिभाषाएं यहां देखी जा सकती हैं: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
जब हम कहते हैं कि ट्री में डीओएम नोड होते हैं, तो हमारा मतलब है कि ट्री को ऐसे एलिमेंट से बनाया जाता है जो डीओएम इंटरफ़ेस में से किसी एक को लागू करते हैं. ब्राउज़र, ऐसे लागू किए गए एट्रिब्यूट का इस्तेमाल करते हैं जिनमें ब्राउज़र के अंदर इस्तेमाल किए जाने वाले अन्य एट्रिब्यूट होते हैं.
पार्स करने का एल्गोरिदम
जैसा कि हमने पिछले सेक्शन में देखा था, एचटीएमएल को टॉप डाउन या बॉटम अप पार्सर का इस्तेमाल करके पार्स नहीं किया जा सकता.
इसकी वजहें ये हैं:
- भाषा में गड़बड़ियों को माफ़ करने की सुविधा.
- ब्राउज़र में गड़बड़ी को सहन करने की सुविधा होती है, ताकि अमान्य एचटीएमएल के आम तौर पर होने वाले मामलों को ठीक किया जा सके.
- पार्स करने की प्रोसेस को फिर से शुरू किया जा सकता है. दूसरी भाषाओं के लिए, पार्स करने के दौरान सोर्स में कोई बदलाव नहीं होता. हालांकि, एचटीएमएल में डाइनैमिक कोड (जैसे,
document.write()कॉल वाले स्क्रिप्ट एलिमेंट) अतिरिक्त टोकन जोड़ सकते हैं. इसलिए, पार्स करने की प्रोसेस में, इनपुट में बदलाव होता है.
सामान्य पार्सिंग तकनीकों का इस्तेमाल न कर पाने की वजह से, ब्राउज़र एचटीएमएल को पार्स करने के लिए कस्टम पार्सर बनाते हैं.
पार्सिंग एल्गोरिदम के बारे में ज़्यादा जानकारी, HTML5 स्पेसिफ़िकेशन में दी गई है. एल्गोरिदम में दो चरण होते हैं: टोकनाइज़ेशन और ट्री का निर्माण.
टोकनाइज़ेशन, लेक्सिकल विश्लेषण है. इसमें इनपुट को टोकन में पार्स किया जाता है. एचटीएमएल टोकन में, स्टार्ट टैग, एंड टैग, एट्रिब्यूट के नाम, और एट्रिब्यूट की वैल्यू शामिल हैं.
टोकेनर, टोकन की पहचान करता है और उसे ट्री कन्स्ट्रक्टर को देता है. साथ ही, अगले टोकन की पहचान करने के लिए अगले वर्ण का इस्तेमाल करता है. यह प्रक्रिया, इनपुट के आखिर तक चलती रहती है.
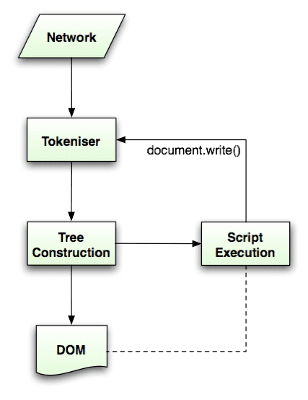
टोकनाइज़ेशन एल्गोरिदम
एल्गोरिदम का आउटपुट एक एचटीएमएल टोकन होता है. एल्गोरिदम को स्टेट मशीन के तौर पर दिखाया जाता है. हर स्टेटस, इनपुट स्ट्रीम के एक या उससे ज़्यादा वर्णों का इस्तेमाल करता है और उन वर्णों के हिसाब से अगला स्टेटस अपडेट करता है. यह फ़ैसला, टोकनाइज़ेशन की मौजूदा स्थिति और ट्री बनाने की स्थिति से तय होता है. इसका मतलब है कि मौजूदा स्थिति के आधार पर, इस्तेमाल किए गए एक ही वर्ण से अगली सही स्थिति के लिए अलग-अलग नतीजे मिलेंगे. एल्गोरिदम को पूरी तरह से समझाना बहुत मुश्किल है. इसलिए, एक आसान उदाहरण देखें, जिससे हमें सिद्धांत को समझने में मदद मिलेगी.
बुनियादी उदाहरण - इस एचटीएमएल को टोकन में बदलना:
<html>
<body>
Hello world
</body>
</html>
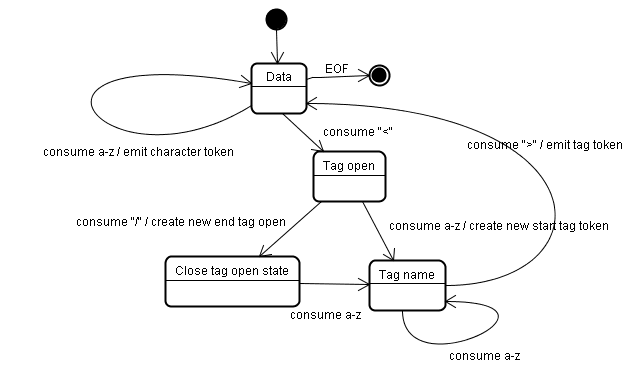
शुरुआती स्थिति, "डेटा स्टेटस" होती है.
< वर्ण मिलने पर, स्टेटस को "टैग खुला है" में बदल दिया जाता है.
a-z वर्ण का इस्तेमाल करने पर, "स्टार्ट टैग टोकन" बन जाता है. साथ ही, स्टेटस "टैग के नाम की स्थिति" में बदल जाता है.
हम इस स्थिति में तब तक बने रहते हैं, जब तक > वर्ण का इस्तेमाल नहीं हो जाता. हर वर्ण, नए टोकन के नाम में जोड़ दिया जाता है. हमारे मामले में, बनाया गया टोकन एक html टोकन है.
> टैग तक पहुंचने पर, मौजूदा टोकन उत्सर्जित किया जाता है और स्टेटस वापस "डेटा स्टेटस" में बदल जाता है.
<body> टैग को भी इसी तरह से प्रोसेस किया जाएगा.
अब तक html और body टैग उत्सर्जित किए गए थे. अब हम "डेटा की स्थिति" पर वापस आ गए हैं.
Hello world के H वर्ण का इस्तेमाल करने पर, एक वर्ण टोकन बनेगा और उसे भेजा जाएगा. ऐसा तब तक होता रहेगा, जब तक </body> के < तक नहीं पहुंचा जाता. हम Hello world के हर वर्ण के लिए एक वर्ण टोकन उत्सर्जित करेंगे.
अब हम "टैग के खुले होने की स्थिति" पर वापस आ गए हैं.
अगले इनपुट / का इस्तेमाल करने पर, एक end tag token बन जाएगा और "टैग के नाम की स्थिति" पर ले जाया जाएगा. हम फिर से इस स्थिति में तब तक बने रहते हैं, जब तक कि हम > तक नहीं पहुंच जाते.इसके बाद, नया टैग टोकन उत्सर्जित किया जाएगा और हम "डेटा स्टेटस" पर वापस चले जाएंगे.
</html> इनपुट को पिछले मामले की तरह ही माना जाएगा.
ट्री स्ट्रक्चर बनाने का एल्गोरिदम
पार्स करने वाला टूल बनाने पर, दस्तावेज़ ऑब्जेक्ट बन जाता है. ट्री बनाने के दौरान, रूट में दस्तावेज़ वाले डीओएम ट्री में बदलाव किया जाएगा और उसमें एलिमेंट जोड़े जाएंगे. tokenizer से उत्सर्जित हर नोड को ट्री कन्स्ट्रक्टर प्रोसेस करेगा. हर टोकन के लिए, स्पेसिफ़िकेशन से यह तय होता है कि कौनसा DOM एलिमेंट उसके लिए काम का है और इस टोकन के लिए बनाया जाएगा. एलिमेंट को DOM ट्री में जोड़ा जाता है. साथ ही, ओपन एलिमेंट के स्टैक में भी जोड़ा जाता है. इस स्टैक का इस्तेमाल, नेस्टिंग मैच न होने और बंद नहीं किए गए टैग को ठीक करने के लिए किया जाता है. एल्गोरिदम को स्टेट मशीन भी कहा जाता है. इन स्थितियों को "शामिल करने के मोड" कहा जाता है.
आइए, उदाहरण के तौर पर दिए गए इनपुट के लिए, ट्री स्ट्रक्चर बनाने की प्रोसेस देखें:
<html>
<body>
Hello world
</body>
</html>
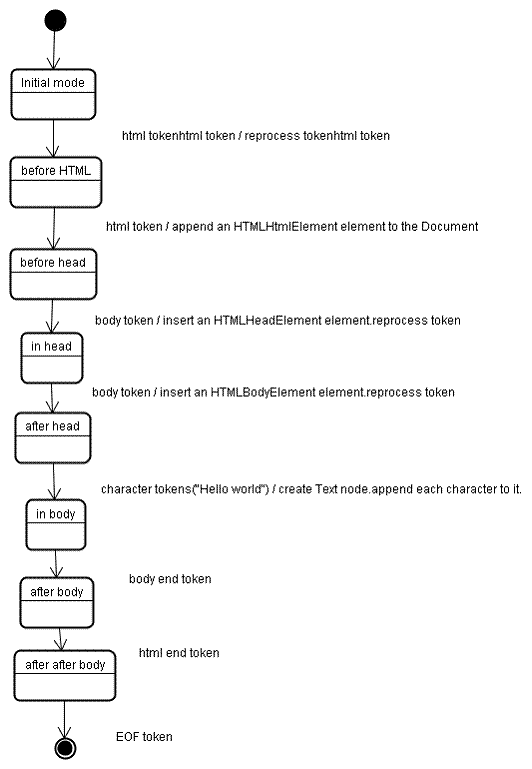
ट्री बनाने के चरण में, टोकन बनाने के चरण से मिले टोकन का क्रम इनपुट के तौर पर इस्तेमाल किया जाता है. पहला मोड, "शुरुआती मोड" है. "html" टोकन मिलने पर, "html से पहले" मोड पर स्विच हो जाएगा और उस मोड में टोकन को फिर से प्रोसेस किया जाएगा. इससे HTMLHtmlElement एलिमेंट बन जाएगा, जिसे रूट दस्तावेज़ ऑब्जेक्ट में जोड़ दिया जाएगा.
स्टेटस बदलकर "before head" हो जाएगा. इसके बाद, "body" टोकन मिलता है. हमारे पास "head" टोकन न होने पर भी, HTMLHeadElement अपने-आप बन जाएगा और उसे ट्री में जोड़ दिया जाएगा.
अब हम "सिर के अंदर" मोड पर जाते हैं और फिर "सिर के बाद" मोड पर जाते हैं. बॉडी टोकन को फिर से प्रोसेस किया जाता है, एक HTMLBodyElement बनाया और डाला जाता है. साथ ही, मोड को "बॉडी में" पर ट्रांसफ़र किया जाता है.
"Hello world" स्ट्रिंग के वर्ण टोकन अब मिल गए हैं. पहले विकल्प की मदद से, "टेक्स्ट" नोड बनाया और डाला जाएगा. साथ ही, दूसरे वर्ण उस नोड में जोड़ दिए जाएंगे.
बॉडी एंड टोकन मिलने पर, "बॉडी के बाद" मोड पर ट्रांसफ़र हो जाएगा. अब हमें एचटीएमएल का आखिरी टैग मिलेगा, जो हमें "body के बाद" मोड पर ले जाएगा. फ़ाइल के आखिर में मौजूद टोकन मिलने पर, पार्सिंग की प्रोसेस खत्म हो जाएगी.
पार्स करने के बाद की जाने वाली कार्रवाइयां
इस चरण में, ब्राउज़र दस्तावेज़ को इंटरैक्टिव के तौर पर मार्क करेगा और "देर से" मोड में मौजूद स्क्रिप्ट को पार्स करना शुरू कर देगा. ये ऐसी स्क्रिप्ट होती हैं जिन्हें दस्तावेज़ को पार्स करने के बाद ही लागू किया जाना चाहिए. इसके बाद, दस्तावेज़ की स्थिति "पूरा हुआ" पर सेट हो जाएगी और "लोड" इवेंट ट्रिगर हो जाएगा.
HTML5 स्पेसिफ़िकेशन में, टोकन बनाने और ट्री बनाने के लिए पूरे एल्गोरिदम देखे जा सकते हैं.
ब्राउज़र में गड़बड़ी की सीमा
आपको एचटीएमएल पेज पर कभी भी "अमान्य सिंटैक्स" गड़बड़ी नहीं दिखती. ब्राउज़र, अमान्य कॉन्टेंट को ठीक कर देते हैं और आगे बढ़ जाते हैं.
उदाहरण के लिए, यह एचटीएमएल:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
मैंने करीब एक लाख नियमों का उल्लंघन किया है ("mytag" स्टैंडर्ड टैग नहीं है, "p" और "div" एलिमेंट का गलत नेस्टिंग वगैरह), लेकिन ब्राउज़र अब भी इसे सही तरीके से दिखाता है और कोई शिकायत नहीं करता. इसलिए, पार्सर कोड का ज़्यादातर हिस्सा, एचटीएमएल लेखक की गलतियां ठीक कर रहा है.
ब्राउज़र में गड़बड़ी को मैनेज करने का तरीका काफ़ी हद तक एक जैसा होता है. हालांकि, हैरानी की बात है कि यह एचटीएमएल के स्पेसिफ़िकेशन का हिस्सा नहीं है. यह सुविधा, ब्राउज़र में पिछले कुछ सालों में विकसित हुई है. यह सुविधा, बुकमार्क करने और पीछे/आगे जाने के बटन की तरह ही है. कई साइटों पर, अमान्य एचटीएमएल कॉन्स्ट्रक्ट बार-बार इस्तेमाल किए जाते हैं. ब्राउज़र, उन्हें दूसरे ब्राउज़र के मुताबिक ठीक करने की कोशिश करते हैं.
HTML5 स्पेसिफ़िकेशन में इनमें से कुछ ज़रूरी शर्तों के बारे में बताया गया है. (WebKit, एचटीएमएल पार्स करने वाली क्लास की शुरुआत में मौजूद टिप्पणी में इस बारे में अच्छी तरह से बताता है.)
पार्सर, दस्तावेज़ में टोकन किए गए इनपुट को पार्स करता है और दस्तावेज़ ट्री बनाता है. अगर दस्तावेज़ सही तरीके से बनाया गया है, तो उसे पार्स करना आसान होता है.
माफ़ करें, हमें ऐसे कई एचटीएमएल दस्तावेज़ हैं जो सही तरीके से नहीं बनाए गए हैं. इसलिए, पार्स करने वाले टूल को गड़बड़ियों को स्वीकार करना होगा.
हमें गड़बड़ी की कम से कम इन स्थितियों का ध्यान रखना होगा:
- जो एलिमेंट जोड़ा जा रहा है उसे किसी बाहरी टैग के अंदर इस्तेमाल करने की अनुमति नहीं है. इस मामले में, हमें उस टैग तक सभी टैग बंद कर देने चाहिए जो एलिमेंट को अनुमति नहीं देता. इसके बाद, उस टैग को जोड़ें.
- हमारे पास एलिमेंट को सीधे जोड़ने की अनुमति नहीं है. ऐसा हो सकता है कि दस्तावेज़ लिखने वाले व्यक्ति ने बीच में कोई टैग इस्तेमाल करना न भूल हो या बीच में इस्तेमाल किया जाने वाला टैग ज़रूरी न हो. यह इन टैग के साथ हो सकता है: एचटीएमएल हेड बॉडी टीबीडी टीआर टीडी एलआई (क्या मैंने कोई टैग छूटा है?).
- हमें इनलाइन एलिमेंट में ब्लॉक एलिमेंट जोड़ना है. अगले ब्लॉक एलिमेंट तक सभी इनलाइन एलिमेंट बंद करें.
- अगर इससे मदद नहीं मिलती है, तो तब तक एलिमेंट बंद रखें, जब तक हमें एलिमेंट जोड़ने की अनुमति नहीं मिल जाती. इसके अलावा, टैग को अनदेखा भी किया जा सकता है.
आइए, WebKit के गड़बड़ी को सहन करने की सुविधा के कुछ उदाहरण देखें:
<br> के बजाय </br>
कुछ साइटें <br> के बजाय </br> का इस्तेमाल करती हैं. IE और Firefox के साथ काम करने के लिए, WebKit इसे <br> की तरह इस्तेमाल करता है.
कोड:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
ध्यान दें कि गड़बड़ी को मैनेज करने की प्रोसेस इंटरनल है: यह उपयोगकर्ता को नहीं दिखाई जाएगी.
कोई ऐसी टेबल जो किसी कैटगरी में नहीं है
अलग-थलग टेबल, किसी टेबल सेल के बजाय किसी दूसरी टेबल में मौजूद टेबल होती है.
उदाहरण के लिए:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit, हैरारकी को दो सिबलिंग टेबल में बदल देगा:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
कोड:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit, मौजूदा एलिमेंट के कॉन्टेंट के लिए स्टैक का इस्तेमाल करता है: यह आंतरिक टेबल को बाहरी टेबल स्टैक से बाहर पॉप कर देगा. अब ये टेबल, एक-दूसरे से जुड़ी होंगी.
नेस्ट किए गए फ़ॉर्म एलिमेंट
अगर उपयोगकर्ता किसी फ़ॉर्म में कोई दूसरा फ़ॉर्म डालता है, तो दूसरे फ़ॉर्म को अनदेखा कर दिया जाता है.
कोड:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
टैग की हैरारकी बहुत गहरी है
टिप्पणी से ही साफ़ तौर पर पता चलता है कि दर्शक इस बारे में क्या सोचते हैं.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
एचटीएमएल या मुख्य हिस्से के आखिर में मौजूद टैग गलत जगह पर हैं
फिर से - टिप्पणी से ही साफ़ तौर पर पता चलता है कि दर्शक किस तरह की कॉन्टेंट पसंद करते हैं.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
इसलिए, वेब लेखकों को सावधान रहना चाहिए. अगर आपको WebKit के गड़बड़ी को सहन करने वाले कोड स्निपेट में उदाहरण के तौर पर नहीं दिखना है, तो सही तरीके से एचटीएमएल लिखें.
सीएसएस पार्सिंग
क्या आपको शुरुआत में दिए गए पार्सिंग के कॉन्सेप्ट याद हैं? एचटीएमएल के उलट, सीएसएस एक कॉन्टेक्स्ट-फ़्री ग्रामर है. इसे शुरुआत में बताए गए पार्सर का इस्तेमाल करके पार्स किया जा सकता है. असल में, सीएसएस स्पेसिफ़िकेशन में सीएसएस लेक्सिकल और सिंटैक्स ग्रामर के बारे में बताया गया है.
आइए, कुछ उदाहरण देखते हैं:
हर टोकन के लिए, रेगुलर एक्सप्रेशन से लेक्सिकल ग्रामर (शब्दावली) तय की जाती है:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident", आइडेंटिफ़ायर का छोटा रूप है, जैसे कि क्लास का नाम. "name" एक एलिमेंट आईडी है, जिसे "#" से रेफ़र किया जाता है
सिंटैक्स ग्रामर के बारे में BNF में बताया गया है.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
व्याख्या:
नियमों का सेट इस स्ट्रक्चर में होता है:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error और a.error सिलेक्टर हैं. कर्ली ब्रैकेट के अंदर मौजूद हिस्से में वे नियम होते हैं जो इस नियमों के सेट के हिसाब से लागू होते हैं.
इस स्ट्रक्चर की जानकारी, इस परिभाषा में दी गई है:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
इसका मतलब है कि नियमों का सेट एक सिलेक्टर है या वैकल्पिक रूप से, कॉमा और स्पेस से अलग किए गए कई सिलेक्टर हैं. S का मतलब खाली जगह है. नियमों के सेट में कर्ली ब्रैकेट होते हैं. इनमें एक एलान या कई एलान होते हैं. ये एलान, सेमीकोलन से अलग किए जाते हैं. "एलान" और "सिलेक्टर" की परिभाषा, नीचे दी गई बीएनएफ़ परिभाषाओं में दी गई है.
WebKit CSS पार्स करने वाला टूल
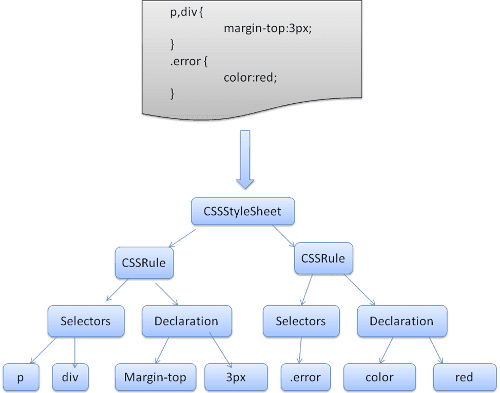
WebKit, CSS व्याकरण फ़ाइलों से अपने-आप पार्स करने वाले टूल बनाने के लिए, Flex और Bison पार्सर जनरेटर का इस्तेमाल करता है. जैसा कि आपको पार्स करने वाले टूल के बारे में जानकारी देने वाले लेख में बताया गया था, Bison एक बॉटम अप शिफ़्ट-रीड्यूस पार्स करने वाला टूल बनाता है. Firefox, मैन्युअल तरीके से लिखे गए टॉप डाउन पार्सर का इस्तेमाल करता है. दोनों ही मामलों में, हर CSS फ़ाइल को स्टाइलशीट ऑब्जेक्ट में पार्स किया जाता है. हर ऑब्जेक्ट में सीएसएस नियम होते हैं. सीएसएस नियम ऑब्जेक्ट में, सिलेक्टर और डिक्लेरेशन ऑब्जेक्ट के साथ-साथ सीएसएस व्याकरण से जुड़े अन्य ऑब्जेक्ट शामिल होते हैं.
स्क्रिप्ट और स्टाइल शीट के लिए प्रोसेसिंग का क्रम
स्क्रिप्ट
वेब का मॉडल सिंक्रोनस है. लेखकों को उम्मीद होती है कि पार्स करने वाला टूल, <script> टैग पर पहुंचते ही स्क्रिप्ट को पार्स करके तुरंत लागू कर देगा.
स्क्रिप्ट लागू होने तक, दस्तावेज़ को पार्स करने की प्रोसेस रुक जाती है.
अगर स्क्रिप्ट बाहरी है, तो संसाधन को पहले नेटवर्क से फ़ेच करना होगा - यह भी सिंक्रोनस तरीके से किया जाता है. साथ ही, संसाधन फ़ेच होने तक पार्सिंग रुक जाती है.
यह कई सालों तक मॉडल था और इसे HTML4 और 5 के स्पेसिफ़िकेशन में भी बताया गया है.
लेखक, स्क्रिप्ट में "defer" एट्रिब्यूट जोड़ सकते हैं. ऐसा करने पर, दस्तावेज़ को पार्स करने की प्रोसेस रुक नहींेगी और स्क्रिप्ट, दस्तावेज़ को पार्स करने के बाद ही चलेगी. HTML5 में, स्क्रिप्ट को असाइनोक्रोनस के तौर पर मार्क करने का विकल्प जोड़ा गया है, ताकि उसे किसी दूसरी थ्रेड से पार्स और लागू किया जा सके.
अनुमान के आधार पर पार्स करना
WebKit और Firefox, दोनों ही यह ऑप्टिमाइज़ेशन करते हैं. स्क्रिप्ट को लागू करते समय, एक और थ्रेड बाकी दस्तावेज़ को पार्स करता है. साथ ही, यह पता लगाता है कि नेटवर्क से कौनसे अन्य रिसॉर्स लोड करने हैं और उन्हें लोड करता है. इस तरह, संसाधनों को पैरलल कनेक्शन पर लोड किया जा सकता है और कुल स्पीड बेहतर हो जाती है. ध्यान दें: स्पेक्टुलेटिव पार्सर सिर्फ़ बाहरी स्क्रिप्ट, स्टाइल शीट, और इमेज जैसे बाहरी रिसॉर्स के रेफ़रंस को पार्स करता है. यह डीओएम ट्री में बदलाव नहीं करता. यह काम मुख्य पार्सर करता है.
स्टाइलशीट
दूसरी ओर, स्टाइल शीट का मॉडल अलग होता है. कॉन्सेप्ट के हिसाब से, ऐसा लगता है कि स्टाइल शीट, डीओएम ट्री में बदलाव नहीं करती हैं. इसलिए, उनके इंतज़ार करने और दस्तावेज़ को पार्स करने की प्रोसेस को रोकने की कोई वजह नहीं है. हालांकि, दस्तावेज़ को पार्स करने के दौरान, स्टाइल की जानकारी मांगने वाली स्क्रिप्ट में एक समस्या है. अगर स्टाइल अभी तक लोड और पार्स नहीं हुई है, तो स्क्रिप्ट को गलत जवाब मिलेंगे. इससे कई समस्याएं हो सकती हैं. ऐसा लगता है कि यह एक असाधारण मामला है, लेकिन यह काफ़ी आम है. अगर कोई स्टाइल शीट अभी भी लोड और पार्स की जा रही है, तो Firefox सभी स्क्रिप्ट को ब्लॉक कर देता है. WebKit, स्क्रिप्ट को सिर्फ़ तब ब्लॉक करता है, जब वे कुछ ऐसी स्टाइल प्रॉपर्टी को ऐक्सेस करने की कोशिश करती हैं जिन पर अनलोड की गई स्टाइल शीट का असर पड़ सकता है.
रेंडर ट्री कंस्ट्रक्शन
डीओएम ट्री बनने के दौरान, ब्राउज़र एक और ट्री बनाता है, जिसे रेंडर ट्री कहा जाता है. यह विज़ुअल एलिमेंट का ट्री है, जो उसी क्रम में दिखेगा जिस क्रम में उन्हें दिखाया जाएगा. यह दस्तावेज़ का विज़ुअल वर्शन होता है. इस ट्री का मकसद, कॉन्टेंट को उनके सही क्रम में दिखाना है.
Firefox, रेंडर ट्री में मौजूद एलिमेंट को "फ़्रेम" कहता है. WebKit, रेंडरर या रेंडर ऑब्जेक्ट शब्द का इस्तेमाल करता है.
रेंडरर को खुद को और अपने बच्चों को लेआउट करने और पेंट करने का तरीका पता होता है.
WebKit की RenderObject क्लास, रेंडरर की बुनियादी क्लास है. इसकी परिभाषा इस तरह है:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
हर रेंडरर, आम तौर पर किसी नोड के सीएसएस बॉक्स से जुड़े आयताकार एरिया को दिखाता है, जैसा कि सीएसएस2 स्पेसिफ़िकेशन में बताया गया है. इसमें चौड़ाई, ऊंचाई, और पोज़िशन जैसी ज्यामितीय जानकारी शामिल होती है.
बॉक्स टाइप पर, स्टाइल एट्रिब्यूट की "डिसप्ले" वैल्यू का असर पड़ता है. यह वैल्यू, नोड के हिसाब से तय होती है. स्टाइल का हिसाब लगाना सेक्शन देखें. यहां WebKit कोड दिया गया है. इससे यह तय किया जा सकता है कि डिसप्ले एट्रिब्यूट के हिसाब से, किसी DOM नोड के लिए किस तरह का रेंडरर बनाया जाना चाहिए:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
एलिमेंट के टाइप पर भी ध्यान दिया जाता है: उदाहरण के लिए, फ़ॉर्म कंट्रोल और टेबल में खास फ़्रेम होते हैं.
अगर WebKit में कोई एलिमेंट कोई खास रेंडरर बनाना चाहता है, तो वह createRenderer() तरीके को बदल देगा.
रेंडरर, स्टाइल ऑब्जेक्ट पर पॉइंट करते हैं जिनमें ज्यामितीय जानकारी नहीं होती.
डीओएम ट्री से रेंडर ट्री का संबंध
रेंडरर, डीओएम एलिमेंट से जुड़े होते हैं, लेकिन उनका संबंध एक-एक से नहीं होता. ऐसे डीओएम एलिमेंट जो विज़ुअल नहीं हैं उन्हें रेंडर ट्री में नहीं डाला जाएगा. उदाहरण के लिए, "head" एलिमेंट. साथ ही, जिन एलिमेंट की डिसप्ले वैल्यू "कोई नहीं" पर सेट की गई है वे ट्री में नहीं दिखेंगे. हालांकि, "छिपा हुआ" विज़िबिलिटी वाले एलिमेंट ट्री में दिखेंगे.
ऐसे डीओएम एलिमेंट होते हैं जो कई विज़ुअल ऑब्जेक्ट से जुड़े होते हैं. आम तौर पर, ये ऐसे एलिमेंट होते हैं जिनका स्ट्रक्चर जटिल होता है और जिन्हें एक ही रेक्टैंगल से नहीं दिखाया जा सकता. उदाहरण के लिए, "select" एलिमेंट में तीन रेंडरर होते हैं: एक डिसप्ले एरिया के लिए, एक ड्रॉप-डाउन सूची बॉक्स के लिए, और एक बटन के लिए. साथ ही, जब टेक्स्ट को एक लाइन के लिए ज़रूरत के मुताबिक चौड़ाई न मिलने की वजह से कई लाइनों में बांटा जाता है, तो नई लाइनों को अतिरिक्त रेंडरर के तौर पर जोड़ा जाएगा.
एक से ज़्यादा रेंडरर का एक और उदाहरण, गलत एचटीएमएल है. सीएसएस स्पेसिफ़िकेशन के मुताबिक, इनलाइन एलिमेंट में सिर्फ़ ब्लॉक एलिमेंट या सिर्फ़ इनलाइन एलिमेंट होने चाहिए. अलग-अलग तरह के कॉन्टेंट के मामले में, इनलाइन एलिमेंट को रैप करने के लिए, पहचान छिपाकर ब्लॉक रेंडर करने वाले टूल बनाए जाएंगे.
कुछ रेंडर ऑब्जेक्ट, किसी DOM नोड से जुड़े होते हैं, लेकिन वे ट्री में एक ही जगह पर नहीं होते. फ़्लोट और एब्सोल्यूट तौर पर पोज़िशन किए गए एलिमेंट, फ़्लो से बाहर होते हैं. इन्हें ट्री के किसी दूसरे हिस्से में रखा जाता है और रीयल फ़्रेम पर मैप किया जाता है. प्लेसहोल्डर फ़्रेम उस जगह पर होना चाहिए जहां उन्हें होना चाहिए.
ट्री स्ट्रक्चर बनाने का तरीका
Firefox में, प्रज़ेंटेशन को डीओएम अपडेट के लिए लिसनर के तौर पर रजिस्टर किया जाता है.
प्रज़ेंटेशन, फ़्रेम बनाने की ज़िम्मेदारी FrameConstructor को दे देता है. इसके बाद, कन्स्ट्रक्टर स्टाइल को हल करता है (स्टाइल कैलकुलेशन देखें) और फ़्रेम बनाता है.
WebKit में, स्टाइल को हल करने और रेंडरर बनाने की प्रोसेस को "अटैचमेंट" कहा जाता है. हर DOM नोड में "अटैच" मेथड होता है. अटैचमेंट सिंक्रोनस होता है. डीओएम ट्री में नोड डालने पर, नए नोड के "अटैच" तरीके को कॉल किया जाता है.
एचटीएमएल और बॉडी टैग को प्रोसेस करने से, रेंडर ट्री का रूट बनता है.
रूट रेंडर ऑब्जेक्ट, सीएसएस स्पेसिफ़िकेशन में मौजूद कॉन्टेंट ब्लॉक से मेल खाता है: यह सबसे ऊपर मौजूद ब्लॉक होता है, जिसमें सभी अन्य ब्लॉक होते हैं. इसके डाइमेंशन, व्यूपोर्ट होते हैं: ब्राउज़र विंडो के डिसप्ले एरिया के डाइमेंशन.
Firefox इसे ViewPortFrame और WebKit इसे RenderView कहता है.
यह वह रेंडर ऑब्जेक्ट है जिस पर दस्तावेज़ ले जाता है.
बाकी ट्री को डीओएम नोड के इंसर्शन के तौर पर बनाया जाता है.
प्रोसेसिंग मॉडल पर CSS2 स्पेसिफ़िकेशन देखें.
स्टाइल कैलकुलेट करना
रेंडर ट्री बनाने के लिए, हर रेंडर ऑब्जेक्ट की विज़ुअल प्रॉपर्टी का हिसाब लगाना ज़रूरी है. ऐसा करने के लिए, हर एलिमेंट की स्टाइल प्रॉपर्टी का हिसाब लगाया जाता है.
स्टाइल में, एचटीएमएल में अलग-अलग सोर्स की स्टाइल शीट, इनलाइन स्टाइल एलिमेंट, और विज़ुअल प्रॉपर्टी (जैसे, "bgcolor" प्रॉपर्टी) शामिल होती हैं. बाद वाली प्रॉपर्टी को मैच करने वाली सीएसएस स्टाइल प्रॉपर्टी में बदल दिया जाता है.
स्टाइल शीट की शुरुआत, ब्राउज़र की डिफ़ॉल्ट स्टाइल शीट, पेज के लेखक की दी गई स्टाइल शीट, और उपयोगकर्ता की स्टाइल शीट से होती है. ये स्टाइल शीट, ब्राउज़र के उपयोगकर्ता से मिलती हैं. ब्राउज़र की मदद से, अपनी पसंदीदा स्टाइल तय की जा सकती हैं. उदाहरण के लिए, Firefox में ऐसा करने के लिए, "Firefox प्रोफ़ाइल" फ़ोल्डर में स्टाइल शीट डाली जाती है.
स्टाइल का हिसाब लगाने में कुछ समस्याएं आती हैं:
- स्टाइल डेटा बहुत बड़ा होता है. इसमें कई स्टाइल प्रॉपर्टी होती हैं. इसकी वजह से, मेमोरी से जुड़ी समस्याएं हो सकती हैं.
अगर हर एलिमेंट के लिए मैच करने वाले नियम ढूंढे जाते हैं, तो परफ़ॉर्मेंस से जुड़ी समस्याएं हो सकती हैं. ऐसा तब होता है, जब एलिमेंट को ऑप्टिमाइज़ नहीं किया गया हो. मैच ढूंढने के लिए, हर एलिमेंट के लिए नियमों की पूरी सूची को देखना एक मुश्किल काम है. चुनने वाले टूल का स्ट्रक्चर जटिल हो सकता है. इसकी वजह से, मैच करने की प्रोसेस किसी ऐसे पाथ पर शुरू हो सकती है जो काम का नहीं होता. ऐसे में, आपको किसी दूसरे पाथ को आज़माना पड़ता है.
उदाहरण के लिए - यह कंपाउंड सिलेक्टर:
div div div div{ ... }इसका मतलब है कि ये नियम उस
<div>पर लागू होते हैं जो तीन डिव के वंशज है. मान लें कि आपको यह देखना है कि यह नियम किसी दिए गए<div>एलिमेंट पर लागू होता है या नहीं. जांच करने के लिए, ट्री में कोई खास पाथ चुना जाता है. आपको नोड ट्री को ऊपर तक ट्रैवर्स करना पड़ सकता है, ताकि यह पता चल सके कि सिर्फ़ दो डिव हैं और नियम लागू नहीं होता. इसके बाद, आपको ट्री में मौजूद अन्य पाथ आज़माने होंगे.नियमों को लागू करने के लिए, कैस्केड नियमों का इस्तेमाल किया जाता है. ये नियम, नियमों की हैरारकी तय करते हैं.
आइए, देखें कि ब्राउज़र को इन समस्याओं का सामना कैसे करना पड़ता है:
स्टाइल का डेटा शेयर करना
WebKit नोड, स्टाइल ऑब्जेक्ट (RenderStyle) का रेफ़रंस देते हैं. कुछ मामलों में, ये ऑब्जेक्ट नोड के ज़रिए शेयर किए जा सकते हैं. नोड, भाई-बहन या चचेरे भाई-बहन हैं और:
- एलिमेंट, माउस की एक ही स्थिति में होने चाहिए. उदाहरण के लिए, एक एलिमेंट :hover में हो सकता है, जबकि दूसरा एलिमेंट ऐसा न हो
- दोनों एलिमेंट में कोई आईडी नहीं होना चाहिए
- टैग के नाम मेल खाने चाहिए
- क्लास एट्रिब्यूट मेल खाने चाहिए
- मैप किए गए एट्रिब्यूट का सेट एक जैसा होना चाहिए
- लिंक की स्थितियां मेल खानी चाहिए
- फ़ोकस की स्थितियां मेल खानी चाहिए
- किसी भी एलिमेंट पर एट्रिब्यूट सिलेक्टर का असर नहीं पड़ना चाहिए. असर पड़ने का मतलब है कि कोई भी सिलेक्टर मैच, सिलेक्टर में किसी भी पोज़िशन में एट्रिब्यूट सिलेक्टर का इस्तेमाल करता है
- एलिमेंट में इनलाइन स्टाइल एट्रिब्यूट नहीं होना चाहिए
- सिबलिंग सिलेक्टर का इस्तेमाल नहीं किया जाना चाहिए. जब कोई सिबलिंग सिलेक्टर मिलता है, तो WebCore सिर्फ़ एक ग्लोबल स्विच करता है. साथ ही, सिबलिंग सिलेक्टर मौजूद होने पर, पूरे दस्तावेज़ के लिए स्टाइल शेयर करने की सुविधा बंद कर देता है. इसमें + सिलेक्टर और :first-child और :last-child जैसे सिलेक्टर शामिल हैं.
Firefox का नियम ट्री
स्टाइल का हिसाब आसानी से लगाने के लिए, Firefox में दो अतिरिक्त ट्री होते हैं: नियम ट्री और स्टाइल कॉन्टेक्स्ट ट्री. WebKit में भी स्टाइल ऑब्जेक्ट होते हैं, लेकिन उन्हें स्टाइल कॉन्टेक्स्ट ट्री की तरह ट्री में सेव नहीं किया जाता. सिर्फ़ डीओएम नोड, अपनी काम की स्टाइल पर ले जाता है.
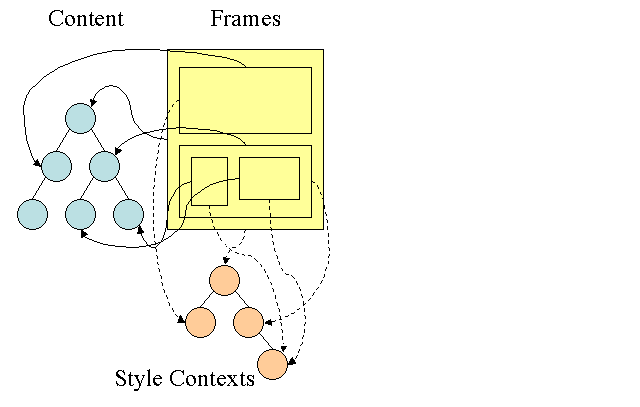
स्टाइल कॉन्टेक्स्ट में आखिरी वैल्यू होती हैं. वैल्यू का हिसाब लगाने के लिए, मैच करने वाले सभी नियमों को सही क्रम में लागू किया जाता है. साथ ही, उनमें बदलाव करके उन्हें लॉजिकल से कॉन्क्रीट वैल्यू में बदला जाता है. उदाहरण के लिए, अगर लॉजिकल वैल्यू स्क्रीन का प्रतिशत है, तो उसका हिसाब लगाया जाएगा और उसे पूरी यूनिट में बदल दिया जाएगा. नियम ट्री का आइडिया वाकई बहुत अच्छा है. यह इन वैल्यू को नोड के बीच शेयर करने की सुविधा देता है, ताकि उन्हें फिर से कैलकुलेट न करना पड़े. इससे स्टोरेज भी बचता है.
मैच होने वाले सभी नियम, ट्री में सेव किए जाते हैं. पाथ में सबसे नीचे मौजूद नोड की प्राथमिकता सबसे ज़्यादा होती है. इस ट्री में, नियम से मैच होने वाले सभी पाथ शामिल होते हैं. नियमों को स्टोर करने की प्रोसेस धीमी होती है. शुरुआत में हर नोड के लिए ट्री का हिसाब नहीं लगाया जाता. हालांकि, जब भी किसी नोड स्टाइल का हिसाब लगाना होता है, तो कैलकुलेट किए गए पाथ को ट्री में जोड़ दिया जाता है.
इसका मकसद, ट्री पाथ को शब्दकोश में शब्दों के तौर पर देखना है. मान लें कि हमने इस नियम के ट्री को पहले ही कैलकुलेट कर लिया है:
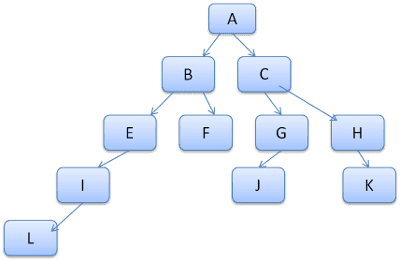
मान लें कि हमें कॉन्टेंट ट्री में किसी दूसरे एलिमेंट के लिए नियमों को मैच करना है और हमें पता चलता है कि मैच किए गए नियम (सही क्रम में) B-E-I हैं. हमारे पास ट्री में यह पाथ पहले से मौजूद है, क्योंकि हमने पहले ही पाथ A-B-E-I-L का हिसाब लगा लिया है. अब हमें कम काम करना होगा.
आइए, देखते हैं कि ट्री डेटा स्ट्रक्चर से हमें कितना काम बचा.
स्ट्रक्चर में बांटना
स्टाइल कॉन्टेक्स्ट को स्ट्रक्चर में बांटा गया है. उन स्ट्रक्चर में, बॉर्डर या रंग जैसी किसी कैटगरी के लिए स्टाइल की जानकारी होती है. किसी स्ट्रक्चर में मौजूद सभी प्रॉपर्टी, इनहेरिट की गई होती हैं या नहीं की गई होती हैं. इनहेरिट की गई प्रॉपर्टी वे प्रॉपर्टी होती हैं जिन्हें एलिमेंट में तय नहीं किया जाता. ये प्रॉपर्टी, पैरंट से इनहेरिट की जाती हैं. इनहेरिट नहीं की गई प्रॉपर्टी (जिन्हें "रीसेट" प्रॉपर्टी कहा जाता है) में कोई वैल्यू तय न होने पर, डिफ़ॉल्ट वैल्यू का इस्तेमाल किया जाता है.
ट्री में पूरे स्ट्रक्चर (इसमें एंड वैल्यू शामिल होती हैं) को कैश मेमोरी में सेव करके, ट्री से हमें मदद मिलती है. इसका मतलब है कि अगर सबसे नीचे वाले नोड में किसी स्ट्रक्चर की परिभाषा नहीं दी गई है, तो ऊपर वाले नोड में कैश मेमोरी में सेव किए गए स्ट्रक्चर का इस्तेमाल किया जा सकता है.
नियम ट्री का इस्तेमाल करके स्टाइल कॉन्टेक्स्ट कैलकुलेट करना
किसी खास एलिमेंट के स्टाइल कॉन्टेक्स्ट का हिसाब लगाते समय, हम पहले नियम के ट्री में कोई पाथ तय करते हैं या किसी मौजूदा पाथ का इस्तेमाल करते हैं. इसके बाद, हम नए स्टाइल के संदर्भ में स्ट्रक्चर भरने के लिए, पाथ में नियम लागू करना शुरू करते हैं. हम पाथ के सबसे नीचे मौजूद नोड से शुरू करते हैं. यह नोड सबसे ज़्यादा प्राथमिकता वाला होता है. आम तौर पर, यह सबसे खास सिलेक्टर होता है. इसके बाद, हम ट्री को तब तक ट्रैवर्स करते हैं, जब तक हमारा स्ट्रक्चर पूरा नहीं हो जाता. अगर उस नियम वाले नोड में स्ट्रक्चर के बारे में कोई जानकारी नहीं है, तो हम उसे बेहतर तरीके से ऑप्टिमाइज़ कर सकते हैं. इसके लिए, हम ट्री में ऊपर तक जाते हैं, जब तक हमें कोई ऐसा नोड नहीं मिल जाता जो पूरी जानकारी देता हो और उस पर ले जाता हो. यह सबसे अच्छा ऑप्टिमाइज़ेशन है. इसमें पूरा स्ट्रक्चर शेयर किया जाता है. इससे आखिरी वैल्यू और मेमोरी का हिसाब लगाने में बचत होती है.
अगर हमें कुछ जानकारी मिलती है, तो हम ट्री में ऊपर की ओर तब तक जाते हैं, जब तक कि स्ट्रक्चर पूरा नहीं हो जाता.
अगर हमें अपने स्ट्रक्चर के लिए कोई परिभाषा नहीं मिली, तो अगर स्ट्रक्चर "इनहेरिट किया गया" टाइप का है, तो हम कॉन्टेक्स्ट ट्री में अपने पैरंट के स्ट्रक्चर पर ले जाते हैं. इस मामले में, हमने स्ट्रक्चर भी शेयर किए. अगर यह रीसेट स्ट्रक्चर है, तो डिफ़ॉल्ट वैल्यू का इस्तेमाल किया जाएगा.
अगर सबसे खास नोड में वैल्यू जोड़ी जाती हैं, तो हमें इसे असल वैल्यू में बदलने के लिए कुछ और गणनाएं करनी होंगी. इसके बाद, हम नतीजे को ट्री नोड में कैश मेमोरी में सेव कर देते हैं, ताकि बच्चे इसका इस्तेमाल कर सकें.
अगर किसी एलिमेंट का कोई भाई या बहन है, जो एक ही ट्री नोड पर ले जाता है, तो पूरा स्टाइल कॉन्टेक्स्ट उनके बीच शेयर किया जा सकता है.
आइए, एक उदाहरण देखें: मान लें कि हमारे पास यह एचटीएमएल है
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
साथ ही, इन नियमों का पालन करना चाहिए:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
इसे आसान बनाने के लिए, मान लें कि हमें सिर्फ़ दो स्ट्रक्चर भरने हैं: कलर स्ट्रक्चर और मार्जिन स्ट्रक्चर. कलर स्ट्रक्चर में सिर्फ़ एक एलिमेंट होता है: कलर मार्जिन स्ट्रक्चर में चार साइड होते हैं.
इससे मिलने वाला नियम ट्री कुछ ऐसा दिखेगा (नोड को नोड के नाम से मार्क किया जाता है: वे नियम की संख्या पर ले जाते हैं):
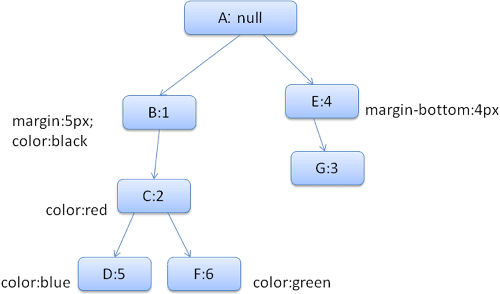
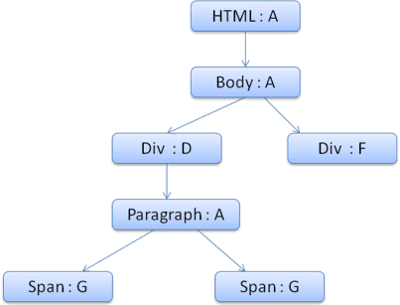
कॉन्टेक्स्ट ट्री कुछ ऐसा दिखेगा (नोड का नाम: वह नियम नोड जिस पर वे पॉइंट करते हैं):
मान लें कि हमने एचटीएमएल को पार्स किया और हमें दूसरा <div> टैग मिला. हमें इस नोड के लिए स्टाइल कॉन्टेक्स्ट बनाना होगा और उसके स्टाइल स्ट्रक्चर भरने होंगे.
हम नियमों को मैच करेंगे और पता लगाएंगे कि <div> के लिए, मैच करने वाले नियम 1, 2, और 6 हैं.
इसका मतलब है कि ट्री में पहले से ही एक मौजूदा पाथ है जिसका इस्तेमाल हमारा एलिमेंट कर सकता है. साथ ही, हमें नियम 6 (नियम ट्री में नोड F) के लिए, उसमें एक और नोड जोड़ना होगा.
हम एक स्टाइल कॉन्टेक्स्ट बनाएंगे और उसे कॉन्टेक्स्ट ट्री में डालेंगे. नई स्टाइल का कॉन्टेक्स्ट, नियम ट्री में मौजूद नोड F पर ले जाएगा.
अब हमें स्टाइल स्ट्रक्चर भरने होंगे. हम मार्जिन स्ट्रक्चर भरकर शुरुआत करेंगे. आखिरी नियम नोड (F), मार्जिन स्ट्रक्चर में नहीं जोड़ता है. इसलिए, हम ट्री में तब तक ऊपर जा सकते हैं, जब तक हमें पिछले नोड के इंसर्शन में कैश मेमोरी में सेव किया गया स्ट्रक्चर न मिल जाए और उसका इस्तेमाल न कर लिया जाए. हमें यह नोड B पर मिलेगा, जो मार्जिन के नियमों को तय करने वाला सबसे ऊपर वाला नोड है.
हमारे पास कलर स्ट्रक्चर की परिभाषा है, इसलिए हम कैश मेमोरी में सेव किए गए स्ट्रक्चर का इस्तेमाल नहीं कर सकते. रंग में एक एट्रिब्यूट है, इसलिए हमें दूसरे एट्रिब्यूट भरने के लिए, ट्री में ऊपर जाने की ज़रूरत नहीं है. हम आखिरी वैल्यू का हिसाब लगाएंगे (स्ट्रिंग को RGB वगैरह में बदलेंगे) और इस नोड पर कैलकुलेट किए गए स्ट्रक्चर को कैश मेमोरी में सेव कर देंगे.
दूसरे <span> एलिमेंट पर काम करना और भी आसान है. हम नियमों से मैच करेंगे और इस नतीजे पर पहुंचेंगे कि यह पिछले स्पैन की तरह ही नियम G पर ले जाता है.
हमारे पास एक ही नोड पर ले जाने वाले सिबलिंग हैं. इसलिए, हम स्टाइल का पूरा कॉन्टेक्स्ट शेयर कर सकते हैं और सिर्फ़ पिछले स्पैन के कॉन्टेक्स्ट पर ले जा सकते हैं.
जिन स्ट्रक्चर में पैरंट से इनहेरिट किए गए नियम होते हैं उनके लिए, कॉन्टेक्स्ट ट्री पर कैश मेमोरी में सेव किया जाता है. रंग प्रॉपर्टी को असल में इनहेरिट किया जाता है, लेकिन Firefox इसे रीसेट के तौर पर इस्तेमाल करता है और इसे नियम ट्री पर कैश मेमोरी में सेव करता है.
उदाहरण के लिए, अगर हमने किसी पैराग्राफ़ में फ़ॉन्ट के लिए नियम जोड़े हैं, तो:
p {font-family: Verdana; font size: 10px; font-weight: bold}
इसके बाद, पैराग्राफ एलिमेंट, जो कॉन्टेक्स्ट ट्री में div का चाइल्ड है, उसी फ़ॉन्ट स्ट्रक्चर को शेयर कर सकता था जो उसके पैरंट का था. ऐसा तब होता है, जब पैराग्राफ़ के लिए कोई फ़ॉन्ट नियम तय न किया गया हो.
WebKit में, मैच होने वाले एलान को चार बार ट्रैवर्स किया जाता है. हालांकि, इसमें कोई नियम ट्री नहीं होता. सबसे पहले, ज़्यादा प्राथमिकता वाली ऐसी प्रॉपर्टी लागू की जाती हैं जो ज़रूरी नहीं हैं. इन प्रॉपर्टी को पहले लागू किया जाना चाहिए, क्योंकि डिसप्ले जैसी अन्य प्रॉपर्टी इन पर निर्भर करती हैं. इसके बाद, ज़्यादा प्राथमिकता वाली ज़रूरी प्रॉपर्टी, सामान्य प्राथमिकता वाली ज़रूरी प्रॉपर्टी, सामान्य प्राथमिकता वाली ऐसी प्रॉपर्टी लागू की जाती हैं जो ज़रूरी नहीं हैं, और फिर सामान्य प्राथमिकता वाली ज़रूरी नियम लागू किए जाते हैं. इसका मतलब है कि एक से ज़्यादा बार दिखने वाली प्रॉपर्टी को सही कैस्केड क्रम के हिसाब से हल किया जाएगा. आखिरी में बचे खिलाड़ी को जीत मिलती है.
खास जानकारी: स्टाइल ऑब्जेक्ट (पूरी तरह या उनमें मौजूद कुछ स्ट्रक्चर) शेयर करने से, पहली और तीसरी समस्या हल हो जाती है. Firefox के नियम ट्री की मदद से, प्रॉपर्टी को सही क्रम में लागू करने में भी मदद मिलती है.
आसानी से मैच पाने के लिए नियमों में हेर-फेर करना
स्टाइल से जुड़े नियमों के कई सोर्स हैं:
- सीएसएस के नियम, जो बाहरी स्टाइल शीट या स्टाइल एलिमेंट में मौजूद हों.
css p {color: blue} - इनलाइन स्टाइल एट्रिब्यूट, जैसे कि
html <p style="color: blue" /> - एचटीएमएल विज़ुअल एट्रिब्यूट (जो काम के स्टाइल नियमों से मैप किए जाते हैं)
html <p bgcolor="blue" />आखिरी दो एट्रिब्यूट, एलिमेंट से आसानी से मैच हो जाते हैं, क्योंकि स्टाइल एट्रिब्यूट का मालिकाना हक एलिमेंट के पास होता है. साथ ही, एलिमेंट को पासकोड के तौर पर इस्तेमाल करके, एचटीएमएल एट्रिब्यूट को मैप किया जा सकता है.
जैसा कि समस्या #2 में पहले बताया गया था, सीएसएस नियम को मैच करना मुश्किल हो सकता है. इस समस्या को हल करने के लिए, नियमों में बदलाव किया गया है, ताकि उन्हें आसानी से ऐक्सेस किया जा सके.
स्टाइल शीट को पार्स करने के बाद, नियमों को सिलेक्टर के हिसाब से कई हैश मैप में से किसी एक में जोड़ दिया जाता है. आईडी, क्लास के नाम, टैग के नाम के हिसाब से मैप होते हैं. साथ ही, उन सभी चीज़ों के लिए एक सामान्य मैप होता है जो इन कैटगरी में नहीं आती हैं. अगर सिलेक्टर कोई आईडी है, तो नियम को आईडी मैप में जोड़ दिया जाएगा. अगर यह कोई क्लास है, तो इसे क्लास मैप में जोड़ दिया जाएगा.
डेटा में बदलाव करने से, नियमों को मैच करना काफ़ी आसान हो जाता है. हर एलान को देखने की ज़रूरत नहीं है: हम मैप से किसी एलिमेंट के लिए काम के नियम निकाल सकते हैं. इस ऑप्टिमाइज़ेशन से 95% से ज़्यादा नियम हट जाते हैं. इसलिए, मैचिंग की प्रोसेस(4.1) के दौरान, इन नियमों को ध्यान में रखने की ज़रूरत नहीं होती.
उदाहरण के लिए, स्टाइल के इन नियमों को देखें:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
पहला नियम, क्लास मैप में डाल दिया जाएगा. दूसरा आईडी मैप में और तीसरा टैग मैप में.
नीचे दिए गए एचटीएमएल फ़्रैगमेंट के लिए;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
हम सबसे पहले p एलिमेंट के लिए नियम ढूंढने की कोशिश करेंगे. क्लास मैप में एक "error" कुंजी होगी, जिसके तहत "p.error" का नियम मिलेगा. div एलिमेंट के लिए, आईडी मैप (आईडी ही कुंजी है) और टैग मैप में काम के नियम होंगे. इसलिए, अब सिर्फ़ यह पता लगाना बाकी है कि कीवर्ड से निकाले गए कौनसे नियम असल में मैच करते हैं.
उदाहरण के लिए, अगर div के लिए नियम यह था:
table div {margin: 5px}
इसे अब भी टैग मैप से निकाला जाएगा, क्योंकि कुंजी सबसे दाईं ओर मौजूद सिलेक्टर है. हालांकि, यह हमारे div एलिमेंट से मेल नहीं खाएगा, क्योंकि उसके पास टेबल का कोई पैरंट एलिमेंट नहीं है.
WebKit और Firefox, दोनों में यह बदलाव होता है.
स्टाइल शीट का कैस्केड क्रम
स्टाइल ऑब्जेक्ट में हर विज़ुअल एट्रिब्यूट (सभी सीएसएस एट्रिब्यूट, लेकिन ज़्यादा सामान्य) से जुड़ी प्रॉपर्टी होती हैं. अगर प्रॉपर्टी को मैच होने वाले किसी भी नियम से तय नहीं किया गया है, तो पैरंट एलिमेंट स्टाइल ऑब्जेक्ट से कुछ प्रॉपर्टी इनहेरिट की जा सकती हैं. अन्य प्रॉपर्टी की डिफ़ॉल्ट वैल्यू होती हैं.
समस्या तब शुरू होती है, जब एक से ज़्यादा परिभाषाएं होती हैं - समस्या को हल करने के लिए, यहां कैस्केड ऑर्डर का इस्तेमाल किया जाता है.
स्टाइल प्रॉपर्टी का एलान, कई स्टाइल शीट में और स्टाइल शीट में कई बार दिख सकता है. इसका मतलब है कि नियमों को लागू करने का क्रम बहुत अहम है. इसे "कैस्केड" ऑर्डर कहा जाता है. CSS2 स्पेसिफ़िकेशन के मुताबिक, कैस्केड का क्रम (कम से ज़्यादा) इस तरह से है:
- ब्राउज़र के एलान
- उपयोगकर्ता के सामान्य एलान
- लेखक के सामान्य एलान
- ज़रूरी एलान करना
- उपयोगकर्ता के लिए ज़रूरी एलान
ब्राउज़र के एलान सबसे कम अहम होते हैं. उपयोगकर्ता, एलान को सिर्फ़ तब बदलता है, जब उसे 'अहम' के तौर पर मार्क किया गया हो. एक ही क्रम में दिए गए एलान, खास जानकारी के हिसाब से क्रम से लगाए जाएंगे. इसके बाद, उन्हें दिए गए क्रम के हिसाब से लगाया जाएगा. एचटीएमएल विज़ुअल एट्रिब्यूट को मैच करने वाले सीएसएस एलान में बदल दिया जाता है . इन्हें कम प्राथमिकता वाले लेखक के नियमों के तौर पर माना जाता है.
खासियत
CSS2 स्पेसिफ़िकेशन में, सिलेक्टर की खास जानकारी इस तरह दी गई है:
- अगर यह एट्रिब्यूट, सिलेक्टर वाले नियम के बजाय 'स्टाइल' एट्रिब्यूट से है, तो 1 की गिनती करें. अगर ऐसा नहीं है, तो 0 की गिनती करें (= a)
- सिलेक्टर में आईडी एट्रिब्यूट की संख्या गिनें (= b)
- सिलेक्टर (= c) में मौजूद अन्य एट्रिब्यूट और स्यूडो-क्लास की संख्या की गिनती करना
- सिलेक्टर में एलिमेंट के नाम और स्यूडो-एलिमेंट की संख्या की गिनती करें (= d)
बड़े बेस वाले नंबर सिस्टम में, चार संख्याओं a-b-c-d को जोड़ने से, संख्या की सटीक जानकारी मिलती है.
आपको जिस नंबर बेस का इस्तेमाल करना है वह किसी एक कैटगरी में मौजूद सबसे ज़्यादा संख्या से तय होता है.
उदाहरण के लिए, अगर a=14 है, तो हेक्साडेसिमल बेस का इस्तेमाल किया जा सकता है. अगर a=17 है, तो आपको 17 अंकों का अंक आधार चाहिए. बाद की स्थिति, इस तरह के सिलेक्टर के साथ हो सकती है: html body div div p… (आपके सिलेक्टर में 17 टैग… बहुत संभावना नहीं है).
कुछ उदाहरण:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
नियमों को क्रम से लगाना
नियमों के मैच होने के बाद, उन्हें कैस्केड नियमों के हिसाब से क्रम से लगाया जाता है.
WebKit, छोटी सूचियों के लिए बबल सॉर्ट और बड़ी सूचियों के लिए मर्ज सॉर्ट का इस्तेमाल करता है.
WebKit, नियमों के लिए > ऑपरेटर को बदलकर, क्रम से लगाने की सुविधा लागू करता है:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
धीरे-धीरे होने वाली प्रोसेस
WebKit, एक फ़्लैग का इस्तेमाल करता है. इससे यह पता चलता है कि सभी टॉप लेवल स्टाइल शीट (इनमें @imports भी शामिल हैं) लोड हो गई हैं या नहीं. अगर अटैच करते समय स्टाइल पूरी तरह से लोड नहीं होती है, तो प्लेसहोल्डर का इस्तेमाल किया जाता है और उसे दस्तावेज़ में मार्क किया जाता है. साथ ही, स्टाइल शीट लोड होने के बाद, उनका फिर से हिसाब लगाया जाएगा.
लेआउट
रेंडरर बनाने और उसे ट्री में जोड़ने पर, उसकी कोई पोज़िशन और साइज़ नहीं होती. इन वैल्यू का हिसाब लगाने को लेआउट या रीफ़्लो कहा जाता है.
एचटीएमएल, फ़्लो पर आधारित लेआउट मॉडल का इस्तेमाल करता है. इसका मतलब है कि ज़्यादातर समय में, ज्यामिति का हिसाब एक ही पास में लगाया जा सकता है. आम तौर पर, "फ़्लो" में बाद में जोड़े गए एलिमेंट का असर, "फ़्लो" में पहले से मौजूद एलिमेंट की ज्यामिति पर नहीं पड़ता. इसलिए, दस्तावेज़ में लेआउट, बाईं से दाईं ओर, ऊपर से नीचे की ओर बढ़ सकता है. हालांकि, कुछ मामलों में ऐसा नहीं होता: उदाहरण के लिए, एचटीएमएल टेबल के लिए एक से ज़्यादा पास की ज़रूरत पड़ सकती है.
निर्देशांक सिस्टम, रूट फ़्रेम के हिसाब से होता है. टॉप और लेफ़्ट निर्देशांक का इस्तेमाल किया जाता है.
लेआउट एक बार-बार इस्तेमाल होने वाली प्रोसेस है. यह रूट रेंडरर से शुरू होता है, जो एचटीएमएल दस्तावेज़ के <html> एलिमेंट से जुड़ा होता है. लेआउट, फ़्रेम की कुछ या सभी हैरारकी में बार-बार रेक्यूर्सिव तरीके से काम करता रहता है. साथ ही, हर उस रेंडरर के लिए ज्यामितीय जानकारी का हिसाब लगाता है जिसे इसकी ज़रूरत होती है.
रूट रेंडरर की पोज़िशन 0,0 होती है और इसके डाइमेंशन व्यूपोर्ट होते हैं. व्यूपोर्ट, ब्राउज़र विंडो का दिखने वाला हिस्सा होता है.
सभी रेंडरर में "लेआउट" या "रीफ़्लो" का तरीका होता है. हर रेंडरर, अपने उन बच्चों के लेआउट तरीके को लागू करता है जिन्हें लेआउट की ज़रूरत होती है.
डर्टी बिट सिस्टम
हर छोटे बदलाव के लिए पूरा लेआउट न बदलने के लिए, ब्राउज़र "डर्टी बिट" सिस्टम का इस्तेमाल करते हैं. बदला गया या जोड़ा गया रेंडरर, अपने और अपने चाइल्ड एलिमेंट को "बदला गया" के तौर पर मार्क करता है: इसका मतलब है कि उन्हें लेआउट की ज़रूरत है.
दो फ़्लैग हैं: "dirty" और "children are dirty". इसका मतलब है कि रेंडरर ठीक हो सकता है, लेकिन इसमें कम से कम एक चाइल्ड एलिमेंट है जिसे लेआउट की ज़रूरत है.
ग्लोबल और इंक्रीमेंटल लेआउट
लेआउट को पूरे रेंडर ट्री पर ट्रिगर किया जा सकता है - यह "ग्लोबल" लेआउट है. ऐसा इन वजहों से हो सकता है:
- स्टाइल में ऐसा बदलाव जो सभी रेंडरर पर असर डालता है. जैसे, फ़ॉन्ट साइज़ में बदलाव.
- स्क्रीन का साइज़ बदलने की वजह से
लेआउट में बदलाव किया जा सकता है. इसमें सिर्फ़ ऐसे रेंडरर लेआउट किए जाएंगे जिनमें बदलाव किया गया है. इससे कुछ नुकसान हो सकता है, जिसके लिए अतिरिक्त लेआउट की ज़रूरत होगी.
रेंडरर में बदलाव होने पर, इंक्रीमेंटल लेआउट को सिंक किए बिना ट्रिगर किया जाता है. उदाहरण के लिए, जब नेटवर्क से अतिरिक्त कॉन्टेंट मिलने और उसे डीओएम ट्री में जोड़ने के बाद, रेंडर ट्री में नए रेंडरर जोड़े जाते हैं.
एसिंक्रोनस और सिंक्रोनस लेआउट
इंक्रीमेंटल लेआउट, एसिंक्रोनस तरीके से किया जाता है. Firefox, इंक्रीमेंटल लेआउट के लिए "फिर से फ़्लो करने के निर्देश" को लाइन में लगाता है. साथ ही, शेड्यूलर इन निर्देशों को एक साथ लागू करता है. WebKit में एक टाइमर भी होता है, जो इंक्रीमेंटल लेआउट को लागू करता है - ट्री को ट्रैवर्स किया जाता है और "गंदा" रेंडरर लेआउट आउट होते हैं.
"offsetHeight" जैसी स्टाइल की जानकारी मांगने वाली स्क्रिप्ट, इंक्रीमेंटल लेआउट को सिंक करके ट्रिगर कर सकती हैं.
आम तौर पर, ग्लोबल लेआउट सिंक्रोनस तरीके से ट्रिगर होगा.
कभी-कभी शुरुआती लेआउट के बाद, लेआउट को कॉलबैक के तौर पर ट्रिगर किया जाता है. ऐसा इसलिए होता है, क्योंकि स्क्रोलिंग पोज़िशन जैसे कुछ एट्रिब्यूट में बदलाव होता है.
अनुकूलन
जब किसी लेआउट को "साइज़ बदलने" या रेंडरर की पोज़िशन में बदलाव(साइज़ में नहीं) से ट्रिगर किया जाता है, तो रेंडर के साइज़ को कैश मेमोरी से लिया जाता है और फिर से कैलकुलेट नहीं किया जाता…
कुछ मामलों में, सिर्फ़ किसी सब-ट्री में बदलाव किया जाता है और लेआउट रूट से शुरू नहीं होता. ऐसा तब हो सकता है, जब बदलाव स्थानीय हो और उसके आस-पास के हिस्सों पर इसका असर न पड़ता हो. जैसे, टेक्स्ट फ़ील्ड में डाला गया टेक्स्ट. ऐसा न होने पर, हर कीस्ट्रोक से रूट से शुरू होने वाला लेआउट ट्रिगर होगा.
लेआउट की प्रोसेस
आम तौर पर, लेआउट का पैटर्न इस तरह का होता है:
- पैरंट रेंडरर अपनी चौड़ाई खुद तय करता है.
- माता-पिता, बच्चों के बारे में बताते हैं और:
- चाइल्ड रेंडरर को रखें (इसका x और y सेट करता है).
- अगर ज़रूरी हो, तो चाइल्ड लेआउट को कॉल करता है - वे गलत हैं या हम ग्लोबल लेआउट में हैं या किसी और वजह से - जो चाइल्ड की ऊंचाई का हिसाब लगाता है.
- पैरंट, अपनी ऊंचाई सेट करने के लिए, चाइल्ड की कुल ऊंचाई और मार्जिन और पैडिंग की ऊंचाई का इस्तेमाल करता है. इसका इस्तेमाल, पैरंट रेंडरर के पैरंट करेंगे.
- अपने 'गंदा है' बिट को 'गलत है' पर सेट करता है.
Firefox, लेआउट के लिए पैरामीटर के तौर पर "स्टेटस" ऑब्जेक्ट (nsHTMLReflowState) का इस्तेमाल करता है. इसे "रीफ़्लो" कहा जाता है. अन्य चीज़ों के अलावा, इस स्टेटस में पैरंट की चौड़ाई शामिल होती है.
Firefox लेआउट का आउटपुट, "मेट्रिक" ऑब्जेक्ट(nsHTMLReflowMetrics) होता है. इसमें रेंडरर की गिनती की गई ऊंचाई शामिल होगी.
चौड़ाई का हिसाब लगाना
रेंडरर की चौड़ाई का हिसाब, कंटेनर ब्लॉक की चौड़ाई, रेंडरर की स्टाइल "चौड़ाई" प्रॉपर्टी, मार्जिन, और बॉर्डर का इस्तेमाल करके लगाया जाता है.
उदाहरण के लिए, इस div की चौड़ाई:
<div style="width: 30%"/>
WebKit, इसकी गिनती इस तरह से करेगा(क्लास RenderBox का तरीका calcWidth):
- कंटेनर की चौड़ाई, कंटेनर की उपलब्ध चौड़ाई और 0 में से सबसे बड़ी वैल्यू होती है. इस मामले में, availableWidth, contentWidth होती है. इसका हिसाब इस तरह से लगाया जाता है:
clientWidth() - paddingLeft() - paddingRight()
clientWidth और clientHeight, बॉर्डर और स्क्रोलबार को छोड़कर किसी ऑब्जेक्ट के अंदरूनी हिस्से को दिखाते हैं.
एलिमेंट की चौड़ाई, "width" स्टाइल एट्रिब्यूट है. इसका हिसाब, कंटेनर की चौड़ाई के प्रतिशत का हिसाब लगाकर, पूरी वैल्यू के तौर पर लगाया जाएगा.
हॉरिज़ॉन्टल बॉर्डर और पैडिंग अब जोड़ दी गई हैं.
अब तक, "पसंदीदा चौड़ाई" का हिसाब इस तरह लगाया जाता था. अब कम से कम और ज़्यादा से ज़्यादा चौड़ाई का हिसाब लगाया जाएगा.
अगर पसंदीदा चौड़ाई, ज़्यादा से ज़्यादा चौड़ाई से ज़्यादा है, तो ज़्यादा से ज़्यादा चौड़ाई का इस्तेमाल किया जाता है. अगर यह कम से कम चौड़ाई (बिना टूटी हुई सबसे छोटी यूनिट) से कम है, तो कम से कम चौड़ाई का इस्तेमाल किया जाता है.
अगर किसी लेआउट की ज़रूरत पड़ती है, तो वैल्यू को कैश मेमोरी में सेव किया जाता है. हालांकि, चौड़ाई में कोई बदलाव नहीं होता.
लाइन ब्रेक
जब किसी लेआउट के बीच में कोई रेंडरर यह तय करता है कि उसे ब्रेक करने की ज़रूरत है, तो रेंडरर रुक जाता है और लेआउट के पैरंट को यह सूचना भेजता है कि उसे ब्रेक करने की ज़रूरत है. पैरंट, अतिरिक्त रेंडरर बनाता है और उन पर लेआउट को कॉल करता है.
पेंटिंग
पेंटिंग के चरण में, रेंडर ट्री को ट्रैवर्स किया जाता है और स्क्रीन पर कॉन्टेंट दिखाने के लिए, रेंडरर के "paint()" तरीके को कॉल किया जाता है. पेंटिंग, यूज़र इंटरफ़ेस (यूआई) इन्फ़्रास्ट्रक्चर कॉम्पोनेंट का इस्तेमाल करती है.
ग्लोबल और इंक्रीमेंटल
लेआउट की तरह, पेंटिंग भी ग्लोबल हो सकती है - पूरा ट्री पेंट किया जाता है - या इंक्रीमेंटल. इंक्रीमेंटल पेंटिंग में, कुछ रेंडरर इस तरह बदलते हैं कि पूरे ट्री पर असर न पड़े. बदला गया रेंडरर, स्क्रीन पर अपने रेक्टैंगल को अमान्य कर देता है. इससे ओएस इसे "गंदा क्षेत्र" के तौर पर देखता है और "पेंट" इवेंट जनरेट करता है. ओएस यह काम चालाकी से करता है और कई इलाकों को एक में मिला देता है. Chrome में यह प्रोसेस ज़्यादा मुश्किल है, क्योंकि रेंडरर मुख्य प्रोसेस से अलग प्रोसेस में होता है. Chrome, कुछ हद तक ओएस के व्यवहार को सिम्युलेट करता है. प्रज़ेंटेशन इन इवेंट को सुनता है और मैसेज को रेंडर रूट को भेजता है. जब तक काम का रेंडरर नहीं मिल जाता, तब तक ट्री को ट्रैवर्स किया जाता है. यह अपने-आप और आम तौर पर अपने बच्चों को फिर से रंग देगा.
पेंटिंग का क्रम
CSS2, पेंटिंग की प्रोसेस के क्रम को तय करता है. यह असल में वह क्रम है जिसमें स्टैकिंग कॉन्टेक्स्ट में एलिमेंट स्टैक किए जाते हैं. इस क्रम से पेंट करने पर, स्टैक को पीछे से आगे की ओर पेंट किया जाता है. ब्लॉक रेंडरर का स्टैकिंग क्रम यह है:
- बैकग्राउंड का रंग
- बैकग्राउंड इमेज
- बॉर्डर
- बच्चे
- बाह्यरेखा
Firefox की डिसप्ले सूची
Firefox, रेंडर ट्री पर जाता है और पेंट किए गए रेक्टैंगल के लिए एक डिसप्ले सूची बनाता है. इसमें रेक्टैंगल के लिए काम के रेंडरर, सही क्रम में होते हैं. जैसे, रेंडरर के बैकग्राउंड, फिर बॉर्डर वगैरह.
इस तरह, ट्री को फिर से रंगने के लिए, कई बार के बजाय सिर्फ़ एक बार ट्रैवर्स करना पड़ता है. जैसे, सभी बैकग्राउंड, फिर सभी इमेज, फिर सभी बॉर्डर वगैरह को पेंट करना.
Firefox, छिपे हुए एलिमेंट को जोड़कर प्रोसेस को ऑप्टिमाइज़ नहीं करता. जैसे, पूरी तरह से धुंधले एलिमेंट के नीचे मौजूद एलिमेंट.
WebKit रेक्टैंगल स्टोरेज
फिर से रंग भरने से पहले, WebKit पुराने रेक्टैंगल को बिटमैप के तौर पर सेव करता है. इसके बाद, यह नए और पुराने आयतों के बीच सिर्फ़ डेल्टा को पेंट करता है.
डाइनैमिक बदलाव
ब्राउज़र, किसी बदलाव के जवाब में कम से कम कार्रवाइयां करने की कोशिश करते हैं. इसलिए, किसी एलिमेंट के रंग में बदलाव करने पर, सिर्फ़ एलिमेंट को फिर से रंगा जाएगा. एलिमेंट की पोज़िशन में बदलाव करने से, एलिमेंट, उसके चाइल्ड एलिमेंट, और शायद उसके भाई-बहनों का लेआउट बदल जाएगा और उन्हें फिर से रंग दिया जाएगा. डीओएम नोड जोड़ने से, नोड का लेआउट और फिर से रंग भरना होगा. "html" एलिमेंट के फ़ॉन्ट साइज़ को बढ़ाने जैसे बड़े बदलावों की वजह से, कैश मेमोरी अमान्य हो जाएगी. साथ ही, पूरे ट्री का लेआउट फिर से बन जाएगा और उसे फिर से पेंट किया जाएगा.
रेंडरिंग इंजन के थ्रेड
रेंडरिंग इंजन सिंगल थ्रेड वाला है. नेटवर्क ऑपरेशन को छोड़कर, ज़्यादातर काम एक ही थ्रेड में होते हैं. Firefox और Safari में यह ब्राउज़र की मुख्य थ्रेड होती है. Chrome में, यह टैब प्रोसेस की मुख्य थ्रेड होती है.
नेटवर्क ऑपरेशन, कई पैरलल थ्रेड की मदद से किए जा सकते हैं. एक साथ कनेक्ट किए जा सकने वाले डिवाइसों की संख्या सीमित होती है. आम तौर पर, एक साथ दो से छह डिवाइस कनेक्ट किए जा सकते हैं.
इवेंट लूप
ब्राउज़र की मुख्य थ्रेड एक इवेंट लूप होती है. यह एक ऐसा अनलिमिटेड लूप है जो प्रोसेस को चालू रखता है. यह लेआउट और पेंट इवेंट जैसे इवेंट के लिए इंतज़ार करता है और उन्हें प्रोसेस करता है. मुख्य इवेंट लूप के लिए Firefox कोड:
while (!mExiting)
NS_ProcessNextEvent(thread);
सीएसएस2 विज़ुअल मॉडल
कैनवस
CSS2 स्पेसिफ़िकेशन के मुताबिक, कैनवस शब्द से "वह जगह होती है जहां फ़ॉर्मैटिंग स्ट्रक्चर रेंडर किया जाता है": जहां ब्राउज़र कॉन्टेंट को पेंट करता है.
स्पेस के हर डाइमेंशन के लिए कैनवस अनलिमिटेड होता है. हालांकि, ब्राउज़र व्यूपोर्ट के डाइमेंशन के आधार पर शुरुआती चौड़ाई चुनते हैं.
www.w3.org/TR/CSS2/zindex.html के मुताबिक, अगर कैनवस किसी दूसरे कैनवस में शामिल है, तो वह पारदर्शी होता है. अगर ऐसा नहीं है, तो उसे ब्राउज़र से तय किया गया रंग दिया जाता है.
सीएसएस बॉक्स मॉडल
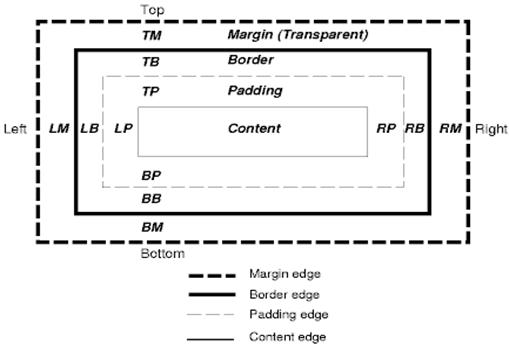
सीएसएस बॉक्स मॉडल, दस्तावेज़ ट्री में एलिमेंट के लिए जनरेट किए गए आयताकार बॉक्स के बारे में बताता है. साथ ही, विज़ुअल फ़ॉर्मैटिंग मॉडल के हिसाब से इन बॉक्स को व्यवस्थित करता है.
हर बॉक्स में एक कॉन्टेंट एरिया (जैसे, टेक्स्ट, इमेज वगैरह) होता है. साथ ही, बॉक्स के चारों ओर पैडिंग, बॉर्डर, और मार्जिन एरिया भी हो सकते हैं. हालांकि, ये ज़रूरी नहीं हैं.
हर नोड, 0 से लेकर n तक ऐसे बॉक्स जनरेट करता है.
सभी एलिमेंट में "display" प्रॉपर्टी होती है. इससे यह तय होता है कि किस तरह का बॉक्स जनरेट किया जाएगा.
उदाहरण:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
डिफ़ॉल्ट रूप से, इनलाइन का इस्तेमाल किया जाता है. हालांकि, ब्राउज़र स्टाइल शीट में अन्य डिफ़ॉल्ट सेट किए जा सकते हैं. उदाहरण के लिए: "div" एलिमेंट के लिए डिफ़ॉल्ट डिसप्ले, ब्लॉक है.
डिफ़ॉल्ट स्टाइल शीट का उदाहरण यहां देखा जा सकता है: www.w3.org/TR/CSS2/sample.html.
पोज़िशनिंग स्कीम
इसके लिए तीन स्कीम उपलब्ध हैं:
- सामान्य: ऑब्जेक्ट को दस्तावेज़ में उसकी जगह के हिसाब से पोज़िशन किया जाता है. इसका मतलब है कि रेंडर ट्री में इसकी जगह, डीओएम ट्री में इसकी जगह जैसी ही है. साथ ही, इसे बॉक्स टाइप और डाइमेंशन के हिसाब से व्यवस्थित किया जाता है
- फ़्लोट: ऑब्जेक्ट को पहले सामान्य फ़्लो की तरह सेट किया जाता है. इसके बाद, उसे बाईं या दाईं ओर जितना हो सके उतना ले जाया जाता है
- एब्सोल्यूट: ऑब्जेक्ट को रेंडर ट्री में, डीओएम ट्री से अलग जगह पर रखा जाता है
पोज़िशनिंग स्कीम, "position" प्रॉपर्टी और "float" एट्रिब्यूट से सेट होता है.
- स्टैटिक और रिलेटिव से सामान्य फ़्लो होता है
- एब्सोल्यूट और फ़िक्स्ड एब्सोल्यूट पोज़िशनिंग
स्टैटिक पोज़िशनिंग में, कोई पोज़िशन तय नहीं की जाती और डिफ़ॉल्ट पोज़िशनिंग का इस्तेमाल किया जाता है. अन्य स्कीम में, लेखक पोज़िशन तय करता है: ऊपर, नीचे, बाईं, दाईं.
बॉक्स के लेआउट का फ़ैसला इन बातों के आधार पर लिया जाता है:
- बॉक्स का टाइप
- बॉक्स के डाइमेंशन
- पोज़िशनिंग स्कीम
- बाहरी जानकारी, जैसे कि इमेज का साइज़ और स्क्रीन का साइज़
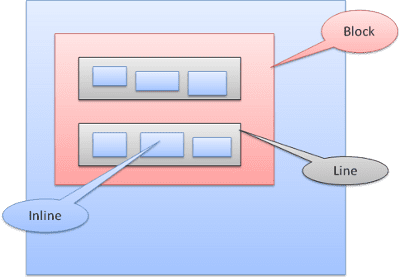
बॉक्स के टाइप
ब्लॉक बॉक्स: यह एक ब्लॉक बनाता है. ब्राउज़र विंडो में इसका एक रेक्टैंगल होता है.

इनलाइन बॉक्स: इसका अपना ब्लॉक नहीं होता, लेकिन यह किसी ब्लॉक में होता है.
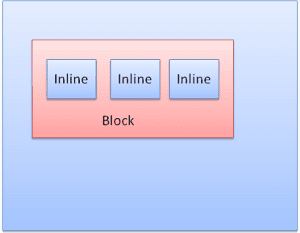
ब्लॉक को एक के बाद एक, वर्टिकल तौर पर फ़ॉर्मैट किया जाता है. इनलाइन को हॉरिज़ॉन्टल तौर पर फ़ॉर्मैट किया जाता है.
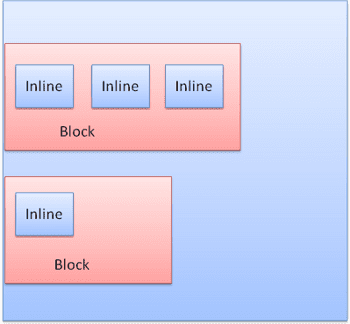
इनलाइन बॉक्स, लाइनों या "लाइन बॉक्स" के अंदर डाले जाते हैं. लाइनें कम से कम सबसे ऊंचे बॉक्स के बराबर ऊंची होती हैं. हालांकि, जब बॉक्स "बेसलाइन" के साथ अलाइन किए जाते हैं, तो लाइनें ज़्यादा ऊंची हो सकती हैं. इसका मतलब है कि किसी एलिमेंट का निचला हिस्सा, बॉक्स के निचले हिस्से के बजाय किसी दूसरे हिस्से के साथ अलाइन होता है. अगर कंटेनर की चौड़ाई काफ़ी नहीं है, तो इनलाइन को कई लाइनों में डाला जाएगा. आम तौर पर, पैराग्राफ़ में ऐसा होता है.
स्टिकर दिखने की जगह
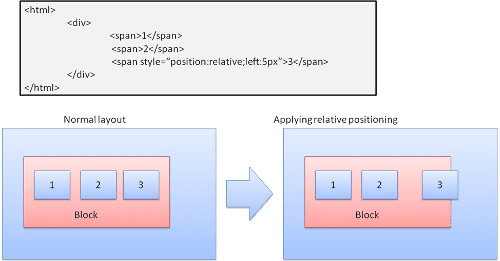
संबंधी
रिलेटिव पोज़िशनिंग - सामान्य तौर पर पोज़िशन की जाती है और फिर ज़रूरत के हिसाब से डेल्टा में बदलाव किया जाता है.
फ़्लोट
फ़्लोट बॉक्स को लाइन की बाईं या दाईं ओर ले जाया जाता है. इसकी दिलचस्प बात यह है कि दूसरे बॉक्स इसके चारों ओर घूमते हैं. एचटीएमएल:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
यह इस तरह दिखेगा:

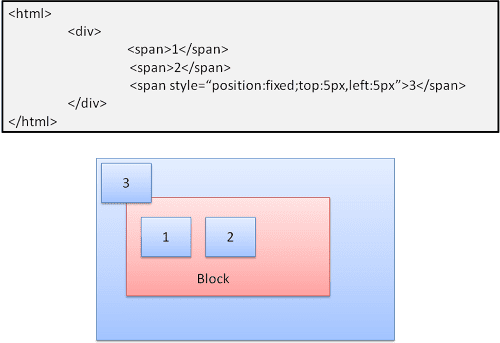
एब्सोलूट और फ़िक्स्ड
सामान्य फ़्लो के बावजूद, लेआउट को सही तरीके से तय किया जाता है. एलिमेंट, सामान्य फ़्लो में शामिल नहीं होता. डाइमेंशन, कंटेनर के हिसाब से होते हैं. फ़िक्स्ड में, कंटेनर व्यूपोर्ट होता है.
लेयर के हिसाब से दिखाना
यह z-index सीएसएस प्रॉपर्टी से तय होता है. यह बॉक्स के तीसरे डाइमेंशन को दिखाता है: "z ऐक्सिस" के साथ उसकी स्थिति.
बॉक्स को स्टैक में बांटा जाता है. इन्हें स्टैकिंग कॉन्टेक्स्ट कहा जाता है. हर स्टैक में, सबसे पहले पीछे के एलिमेंट पेंट किए जाएंगे. इसके बाद, सबसे ऊपर उपयोगकर्ता के करीब, आगे के एलिमेंट पेंट किए जाएंगे. ओवरलैप होने पर, सबसे आगे मौजूद एलिमेंट, पिछले एलिमेंट को छिपा देगा.
स्टैक को z-index प्रॉपर्टी के हिसाब से क्रम में लगाया जाता है. "z-index" प्रॉपर्टी वाले बॉक्स, एक स्थानीय स्टैक बनाते हैं. व्यूपोर्ट में आउटर स्टैक होता है.
उदाहरण:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
इसका नतीजा यह होगा:

हालांकि, मार्कअप में लाल डायव ग्रीन डायव से पहले आता है और सामान्य फ़्लो में पहले पेंट किया गया होगा, लेकिन z-इंडेक्स प्रॉपर्टी ज़्यादा है. इसलिए, यह रूट बॉक्स के स्टैक में आगे है.
संसाधन
ब्राउज़र का आर्किटेक्चर
- ग्रॉस्कुर्थ, एलन. वेब ब्राउज़र के लिए रेफ़रंस आर्किटेक्चर (pdf)
- गुप्ता, विनीत. ब्राउज़र कैसे काम करते हैं - पहला भाग - आर्किटेक्चर
पार्स करना
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986
- रिक जेलिफ़. The Bold and the Beautiful: HTML 5 के लिए दो नए ड्राफ़्ट.
Firefox
- एल॰ डेविड बैरन, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- एल॰ डेविड बैरन, बेहतर एचटीएमएल और सीएसएस: वेब डेवलपर के लिए लेआउट इंजन के इंटरनल (Google टेक टॉक वीडियो)
- एल॰ डेविड बैरन, Mozilla का लेआउट इंजन
- एल॰ डेविड बैरन, Mozilla स्टाइल सिस्टम दस्तावेज़
- क्रिस वॉटरसन, एचटीएमएल रीफ़्लो के बारे में जानकारी
- क्रिस वॉटरसन, Gecko की खास जानकारी
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- डेविड हाइफ़र्ट, सीएसएस लागू करना(पहला भाग)
- डेविड हाइफ़र्ट, WebCore के बारे में खास जानकारी
- डेविड हयात, WebCore रेंडरिंग
- डेविड हाइफ़र्ट, एफ़ओयूसी की समस्या
W3C के स्पेसिफ़िकेशन
ब्राउज़र बनाने के निर्देश
अनुवाद
इस पेज का दो बार जापानी में अनुवाद किया गया है:
- ब्राउज़र कैसे काम करते हैं - आधुनिक वेब ब्राउज़र के काम करने का तरीका (ja) @kosei की ओर से
- ब्राउज़र कैसे काम करता है?(モダンWEBブラウザシーンの裏側 @ikeike443 और @kiyoto01 की ओर से.
कोरियन और तुर्किश भाषा में, बाहरी होस्ट किए गए अनुवाद देखे जा सकते हैं.
सभी को धन्यवाद!