
Dietro le quinte dei browser web moderni


Prefazione
Questo prontuario completo sulle operazioni interne di WebKit e Gecko è il risultato di molte ricerche condotte dallo sviluppatore israeliano Tali Garsiel. Nel corso di alcuni anni, ha esaminato tutti i dati pubblicati sugli aspetti interni dei browser e ha trascorso molto tempo a leggere il codice sorgente dei browser web. Ha scritto:
In qualità di sviluppatore web, conoscere le operazioni interne dei browser ti aiuta a prendere decisioni migliori e a conoscere le giustificazioni alla base delle best practice di sviluppo. Sebbene si tratti di un documento piuttosto lungo, ti consigliamo di dedicarvi un po' di tempo. Sarai felice di averlo fatto.
Paul Irish, Chrome Developer Relations
Introduzione
I browser web sono il software più utilizzato. In questo articolo spiego come funzionano "dietro le quinte". Vedremo cosa succede quando digiti google.com
nella barra degli indirizzi finché non visualizzi la pagina di Google sullo schermo del browser.
Browser di cui parleremo
Attualmente esistono cinque browser principali utilizzati su computer: Chrome, Internet Explorer, Firefox, Safari e Opera. Sui dispositivi mobili, i browser principali sono Android Browser, iPhone, Opera Mini e Opera Mobile, UC Browser, i browser Nokia S40/S60 e Chrome, tutti basati su WebKit, ad eccezione dei browser Opera. Fornirò esempi dei browser open source Firefox e Chrome e di Safari (che è parzialmente open source). Secondo le statistiche di StatCounter (a giugno 2013), Chrome, Firefox e Safari rappresentano circa il 71% dell'utilizzo dei browser desktop a livello globale. Sui dispositivi mobili, il browser Android, iPhone e Chrome rappresentano circa il 54% dell'utilizzo.
La funzionalità principale del browser
La funzione principale di un browser è presentare la risorsa web scelta, richiedendola al server e mostrandola nella finestra del browser. La risorsa è in genere un documento HTML, ma può anche essere un PDF, un'immagine o un altro tipo di contenuti. La posizione della risorsa viene specificata dall'utente utilizzando un URI (Uniform Resource Identifier).
Il modo in cui il browser interpreta e mostra i file HTML è specificato nelle specifiche HTML e CSS. Queste specifiche sono gestite dall'organizzazione W3C (World Wide Web Consortium), che è l'organizzazione di standard per il web. Per anni i browser si sono conformati solo a una parte delle specifiche e hanno sviluppato le proprie estensioni. Ciò ha causato gravi problemi di compatibilità per gli autori web. Oggi la maggior parte dei browser è più o meno conforme alle specifiche.
Le interfacce utente dei browser hanno molto in comune tra loro. Tra gli elementi comuni dell'interfaccia utente sono inclusi:
- Barra degli indirizzi per l'inserimento di un URI
- Pulsanti Indietro e Avanti
- Opzioni di preferiti
- Pulsanti Aggiorna e Interrompi per aggiornare o interrompere il caricamento dei documenti correnti
- Pulsante Home che ti reindirizza alla home page
Stranamente, l'interfaccia utente del browser non è specificata in nessuna specifica formale, ma deriva da buone pratiche sviluppate nel corso di anni di esperienza e da browser che si imitano a vicenda. La specifica HTML5 non definisce gli elementi dell'interfaccia utente che un browser deve avere, ma elenca alcuni elementi comuni. Tra queste, la barra degli indirizzi, la barra di stato e la barra degli strumenti. Naturalmente, esistono funzionalità uniche per un browser specifico, come il gestore dei download di Firefox.
Infrastruttura di alto livello
I componenti principali del browser sono:
- Interfaccia utente: include la barra degli indirizzi, il pulsante Indietro/Avanti, il menu dei preferiti e così via. Ogni parte del browser, tranne la finestra in cui viene visualizzata la pagina richiesta.
- Il motore del browser: gestisce le azioni tra l'interfaccia utente e il motore di rendering.
- Il motore di rendering: responsabile della visualizzazione dei contenuti richiesti. Ad esempio, se i contenuti richiesti sono in HTML, il motore di rendering analizza HTML e CSS e mostra i contenuti analizzati sullo schermo.
- Networking: per le chiamate di rete, come le richieste HTTP, vengono utilizzate implementazioni diverse per piattaforme diverse dietro un'interfaccia indipendente dalla piattaforma.
- Backend dell'interfaccia utente: utilizzato per disegnare widget di base come caselle combinate e finestre. Questo backend espone un'interfaccia generica non specifica della piattaforma. Sotto utilizza i metodi dell'interfaccia utente del sistema operativo.
- Interprete JavaScript. Utilizzato per analizzare ed eseguire il codice JavaScript.
- Archiviazione dei dati. Si tratta di un livello di persistenza. Il browser potrebbe dover salvare localmente tutti i tipi di dati, ad esempio i cookie. I browser supportano anche meccanismi di archiviazione come localStorage, IndexedDB, WebSQL e FileSystem.
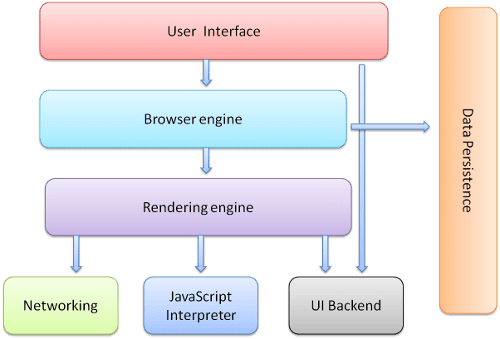
È importante notare che i browser come Chrome eseguono più istanze del motore di rendering: una per ogni scheda. Ogni scheda viene eseguita in un processo separato.
Motori di rendering
La responsabilità del motore di rendering è… il rendering, ovvero la visualizzazione dei contenuti richiesti sullo schermo del browser.
Per impostazione predefinita, il motore di rendering può visualizzare documenti e immagini HTML e XML. Può visualizzare altri tipi di dati tramite plug-in o estensioni, ad esempio la visualizzazione di documenti PDF utilizzando un plug-in per visualizzatori PDF. Tuttavia, in questo capitolo ci concentreremo sul caso d'uso principale: la visualizzazione di HTML e immagini formattate utilizzando CSS.
Browser diversi utilizzano motori di rendering diversi: Internet Explorer utilizza Trident, Firefox utilizza Gecko e Safari utilizza WebKit. Chrome e Opera (dalla versione 15) utilizzano Blink, un fork di WebKit.
WebKit è un motore di rendering open source nato come motore per la piattaforma Linux e modificato da Apple per supportare Mac e Windows.
Il flusso principale
Il motore di rendering inizierà a recuperare i contenuti del documento richiesto dal livello di rete. In genere, questo viene fatto in blocchi di 8 kB.
Di seguito è riportato il flusso di base del motore di rendering:

Il motore di rendering inizierà ad analizzare il documento HTML e a convertire gli elementi in nodi DOM in una struttura ad albero chiamata "albero dei contenuti". Il motore analizzerà i dati di stile, sia nei file CSS esterni sia negli elementi di stile. Le informazioni sugli stili, insieme alle istruzioni visive in HTML, verranno utilizzate per creare un'altra struttura ad albero: la struttura di rendering.
L'albero di rendering contiene rettangoli con attributi visivi come colore e dimensioni. I rettangoli sono nell'ordine giusto per essere visualizzati sullo schermo.
Dopo la costruzione dell'albero di rendering, viene eseguita una procedura di "layout". Ciò significa assegnare a ogni nodo le coordinate esatte in cui deve apparire sullo schermo. La fase successiva è la tinta: la struttura ad albero di rendering verrà attraversata e ogni nodo verrà dipinto utilizzando il livello di backend dell'interfaccia utente.
È importante capire che si tratta di un processo graduale. Per un'esperienza utente migliore, il motore di rendering cercherà di visualizzare i contenuti sullo schermo il prima possibile. Non attende che tutto il codice HTML venga analizzato prima di iniziare a creare e a eseguire il layout della struttura di rendering. Alcune parti dei contenuti verranno analizzate e visualizzate, mentre il processo continua con il resto dei contenuti che continuano ad arrivare dalla rete.
Esempi di flusso principale
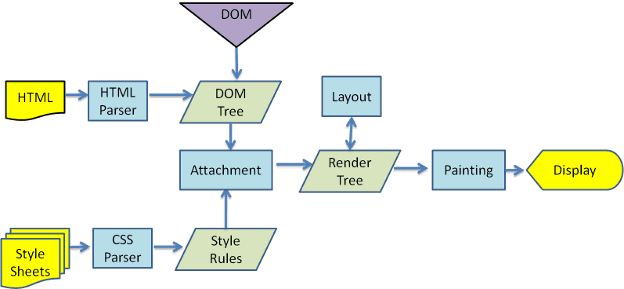
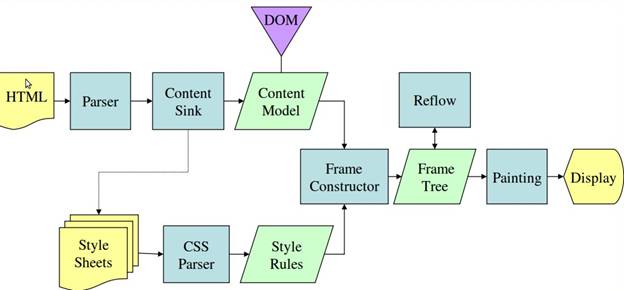
Dalle figure 3 e 4 puoi vedere che, sebbene WebKit e Gecko utilizzino una terminologia leggermente diversa, il flusso è sostanzialmente lo stesso.
Gecko chiama l'albero degli elementi formattati visivamente "albero di frame". Ogni elemento è un frame. WebKit utilizza il termine "struttura di rendering" ed è costituito da "oggetti di rendering". WebKit utilizza il termine "layout" per il posizionamento degli elementi, mentre Gecko lo chiama "Reflow". "Allegato" è il termine di WebKit per indicare il collegamento di nodi DOM e informazioni visive per creare la struttura di rendering. Una differenza non semantica minore è che Gecko ha un livello aggiuntivo tra l'HTML e la struttura DOM. Si chiama "content sink" ed è una factory per la creazione di elementi DOM. Parleremo di ogni parte del flusso:
Analisi - generale
Poiché l'analisi è un processo molto importante all'interno dell'engine di rendering, lo esamineremo un po' più a fondo. Iniziamo con una breve introduzione all'analisi.
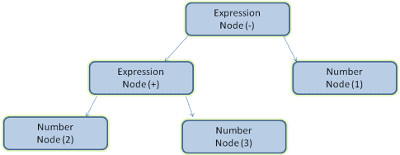
L'analisi di un documento significa tradurlo in una struttura che il codice può utilizzare. Il risultato dell'analisi sintattica è in genere un albero di nodi che rappresenta la struttura del documento. Questa è chiamata albero di analisi o albero sintattico.
Ad esempio, l'analisi dell'espressione 2 + 3 - 1 potrebbe restituire questo albero:
Grammatica
L'analisi si basa sulle regole di sintassi a cui il documento è conforme: la lingua o il formato in cui è stato scritto. Ogni formato che puoi analizzare deve avere una grammatica deterministica composta da regole di vocabolario e sintassi. Si tratta di una grammatica libera dal contesto. Le lingue umane non sono lingue di questo tipo e quindi non possono essere analizzate con tecniche di analisi convenzionali.
Combinazione di parser e analizzatori lessicali
L'analisi sintattica può essere suddivisa in due sottoprocessi: analisi lessicale e analisi sintattica.
L'analisi lessicale è il processo di suddivisione dell'input in token. I token sono il vocabolario della lingua: la raccolta di elementi di base validi. In linguaggio umano, sarà costituito da tutte le parole presenti nel dizionario della lingua in questione.
L'analisi della sintassi consiste nell'applicazione delle regole di sintassi del linguaggio.
I parser di solito suddividono il lavoro in due componenti: il lexer (a volte chiamato tokenizer) che si occupa di suddividere l'input in token validi e il parser che si occupa di costruire l'albero di analisi analizzando la struttura del documento in base alle regole di sintassi del linguaggio.
Il lexer sa come rimuovere i caratteri irrilevanti come gli spazi e le interruzioni di riga.
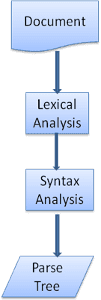
Il processo di analisi è iterativo. In genere, il parser chiede al lexer un nuovo token e tenta di associarlo a una delle regole di sintassi. Se viene trovata una corrispondenza con una regola, alla struttura ad albero di analisi viene aggiunto un nodo corrispondente al token e il parser richiederà un altro token.
Se nessuna regola corrisponde, l'analizzatore memorizza il token internamente e continua a chiedere token finché non viene trovata una regola che corrisponda a tutti i token memorizzati internamente. Se non viene trovata alcuna regola, l'interprete genera un'eccezione. Ciò significa che il documento non era valido e conteneva errori di sintassi.
Traduzione
In molti casi l'albero di analisi non è il prodotto finale. L'analisi viene spesso utilizzata nella traduzione: trasforma il documento di input in un altro formato. Un esempio è la compilazione. Il compilatore che compila il codice sorgente in codice macchina lo analizza innanzitutto in un albero di analisi e poi lo traduce in un documento di codice macchina.
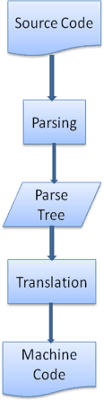
Esempio di analisi
Nella figura 5 abbiamo creato un albero di analisi da un'espressione matematica. Proviamo a definire un semplice linguaggio matematico e a vedere il processo di analisi.
Sintassi:
- I componenti di base della sintassi del linguaggio sono espressioni, termini e operazioni.
- Il nostro linguaggio può includere un numero qualsiasi di espressioni.
- Un'espressione è definita come un "termine" seguito da un'"operazione" seguita da un altro termine
- Un'operazione è un token più o un token meno
- Un termine è un token intero o un'espressione
Analizziamo l'input 2 + 3 - 1.
La prima sottostringa che corrisponde a una regola è 2: secondo la regola 5 è un termine.
La seconda corrispondenza è 2 + 3: corrisponde alla terza regola: un termine seguito da un'operazione seguito da un altro termine.
La corrispondenza successiva verrà trovata solo alla fine dell'input.
2 + 3 - 1 è un'espressione perché sappiamo già che 2 + 3 è un termine, quindi abbiamo un termine seguito da un'operazione seguita da un altro termine.
2 + + non corrisponde a nessuna regola ed è quindi un input non valido.
Definizioni formali per vocabolario e sintassi
Il vocabolario viene solitamente espresso tramite espressioni regolari.
Ad esempio, il nostro linguaggio sarà definito come:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Come puoi vedere, gli interi sono definiti da un'espressione regolare.
La sintassi è in genere definita in un formato chiamato BNF. Il nostro linguaggio sarà definito come:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Abbiamo detto che un linguaggio può essere analizzato da parser regolari se la sua grammatica è una grammatica senza contesto. Una definizione intuitiva di una grammatica senza contesto è una grammatica che può essere interamente espressa in BNF. Per una definizione formale, consulta l'articolo di Wikipedia sulla grammatica libera dal contesto
Tipi di analizzatori
Esistono due tipi di analizzatori: dall'alto verso il basso e dal basso verso l'alto. Una spiegazione intuitiva è che gli analizzatori dall'alto verso il basso esaminano la struttura di alto livello della sintassi e cercano una corrispondenza con una regola. I parser dal basso verso l'alto partono dall'input e lo trasformano gradualmente nelle regole di sintassi, dalle regole di basso livello fino a quelle di alto livello.
Vediamo come i due tipi di analizzatori analizzeranno il nostro esempio.
L'analizzatore dall'alto verso il basso inizierà dalla regola di livello superiore: identificherà 2 + 3 come un'espressione. Identifica quindi 2 + 3 - 1 come espressione (il processo di identificazione dell'espressione si evolve, corrispondendo alle altre regole, ma il punto di partenza è la regola di livello più alto).
L'analizzatore dal basso verso l'alto eseguirà la scansione dell'input fino a quando non viene trovata una regola corrispondente. Sostituirà quindi l'input corrispondente con la regola. L'operazione continuerà fino alla fine dell'input. L'espressione con corrispondenza parziale viene inserita nello stack dell'analizzatore.
Questo tipo di parser dal basso verso l'alto è chiamato parser di scorrimento e riduzione, perché l'input viene spostato verso destra (immagina un cursore che punta prima all'inizio dell'input e si sposta verso destra) e viene gradualmente ridotto a regole di sintassi.
Generazione automatica di analizzatori
Esistono strumenti che possono generare un parser. Fornisci la grammatica della tua lingua, ovvero il vocabolario e le regole di sintassi, e il programma genera un parser funzionante. La creazione di un parser richiede una conoscenza approfondita dell'analisi sintattica e non è facile creare un parser ottimizzato manualmente, quindi i generatori di parser possono essere molto utili.
WebKit utilizza due generatori di parser ben noti: Flex per creare un analizzatore lessicale e Bison per creare un parser (potresti trovarli con i nomi Lex e Yacc). L'input Flex è un file contenente le definizioni delle espressioni regolari dei token. L'input di Bison sono le regole di sintassi del linguaggio in formato BNF.
Parser HTML
Il compito del parser HTML è analizzare il markup HTML in un albero di analisi.
Grammatica HTML
Il vocabolario e la sintassi dell'HTML sono definiti nelle specifiche create dall'organizzazione W3C.
Come abbiamo visto nell'introduzione all'analisi, la sintassi della grammatica può essere definita formalmente utilizzando formati come BNF.
Purtroppo tutti gli argomenti relativi ai parser convenzionali non si applicano all'HTML (non li ho menzionati solo per divertimento: verranno utilizzati per l'analisi CSS e JavaScript). L'HTML non può essere facilmente definito da una grammatica senza contesto necessaria per i parser.
Esiste un formato formale per definire l'HTML, il DTD (Document Type Definition), ma non è una grammatica senza contesto.
A prima vista può sembrare strano, perché l'HTML è piuttosto simile al XML. Esistono molti analizzatori XML disponibili. Esiste una variante XML dell'HTML, XHTML, quindi qual è la grande differenza?
La differenza è che l'approccio HTML è più "tollerante": ti consente di omettere determinati tag (che vengono poi aggiunti implicitamente) o, a volte, i tag di inizio o di fine e così via. Nel complesso, si tratta di una sintassi "morbida", rispetto alla sintassi rigida e impegnativa di XML.
Questo dettaglio apparentemente piccolo fa una grande differenza. Da un lato, questo è il motivo principale per cui l'HTML è così popolare: perdona i tuoi errori e semplifica la vita all'autore web. D'altra parte, rende difficile scrivere una grammatica formale. Per riepilogare, l'HTML non può essere analizzato facilmente dai parser convenzionali, poiché la sua grammatica non è priva di contesto. L'HTML non può essere analizzato dagli analizzatori sintattici XML.
DTD HTML
La definizione HTML è in formato DTD. Questo formato viene utilizzato per definire i linguaggi della famiglia SGML. Il formato contiene le definizioni di tutti gli elementi consentiti, dei relativi attributi e della gerarchia. Come abbiamo visto in precedenza, il DTD HTML non forma una grammatica senza contesto.
Esistono alcune varianti del DTD. La modalità rigorosa è conforme solo alle specifiche, ma le altre modalità supportano il markup utilizzato dai browser in passato. Lo scopo è la compatibilità con le versioni precedenti dei contenuti. L'attuale DTD rigoroso è disponibile qui: www.w3.org/TR/html4/strict.dtd
DOM
L'albero di output ("albero di analisi") è un albero di elementi DOM e nodi di attributi. DOM è l'acronimo di Document Object Model. È la presentazione dell'oggetto del documento HTML e l'interfaccia degli elementi HTML con l'esterno, come JavaScript.
La radice dell'albero è l'oggetto "Document".
Il DOM ha una relazione quasi uno a uno con il markup. Ad esempio:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Questo markup verrà tradotto nella seguente struttura DOM:
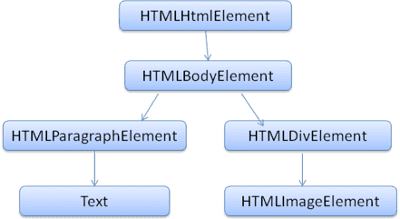
Come HTML, il DOM è specificato dall'organizzazione W3C. Consulta www.w3.org/DOM/DOMTR. Si tratta di una specifica generica per la manipolazione dei documenti. Un modulo specifico descrive elementi HTML specifici. Le definizioni HTML sono disponibili qui: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Quando dico che l'albero contiene nodi DOM, intendo che l'albero è costituito da elementi che implementano una delle interfacce DOM. I browser utilizzano implementazioni concrete che hanno altri attributi utilizzati internamente dal browser.
L'algoritmo di analisi
Come abbiamo visto nelle sezioni precedenti, l'HTML non può essere analizzato utilizzando i normali analizzatori dall'alto verso il basso o dal basso verso l'alto.
I motivi sono:
- La natura permissiva del linguaggio.
- Il fatto che i browser abbiano una tolleranza agli errori tradizionale per supportare casi ben noti di HTML non valido.
- Il processo di analisi è ricorsivo. Per altri linguaggi, il codice sorgente non cambia durante l'analisi, ma in HTML il codice dinamico (ad esempio gli elementi di script contenenti chiamate
document.write()) può aggiungere token aggiuntivi, pertanto il processo di analisi modifica effettivamente l'input.
Poiché non possono utilizzare le tecniche di analisi standard, i browser creano analizzatori personalizzati per l'analisi dell'HTML.
L'algoritmo di analisi è descritto in dettaglio dalla specifica HTML5. L'algoritmo è costituito da due fasi: tokenizzazione e costruzione dell'albero.
La tokenizzazione è l'analisi lessicale, che analizza l'input in token. Tra i token HTML sono inclusi i tag di inizio, i tag di fine, i nomi degli attributi e i valori degli attributi.
Lo tokenizer riconosce il token, lo passa al costruttore dell'albero e utilizza il carattere successivo per riconoscere il token successivo e così via fino alla fine dell'input.
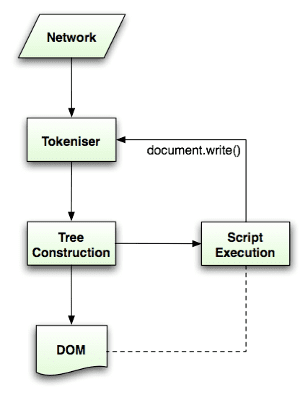
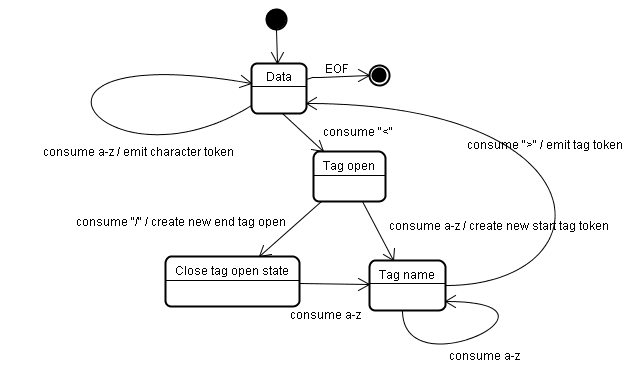
L'algoritmo di tokenizzazione
L'output dell'algoritmo è un token HTML. L'algoritmo è espresso come una macchina a stati. Ogni stato consuma uno o più caratteri dello stream di input e aggiorna lo stato successivo in base a questi caratteri. La decisione è influenzata dallo stato attuale della tokenizzazione e dallo stato della costruzione dell'albero. Ciò significa che lo stesso carattere consumato produrrà risultati diversi per lo stato successivo corretto, a seconda dello stato corrente. L'algoritmo è troppo complesso da descrivere in modo esaustivo, quindi vediamo un semplice esempio che ci aiuti a comprendere il principio.
Esempio di base: tokenizzazione del seguente codice HTML:
<html>
<body>
Hello world
</body>
</html>
Lo stato iniziale è "Stato dei dati".
Quando viene rilevato il carattere <, lo stato viene modificato in "Stato tag aperto".
L'utilizzo di un carattere a-z comporta la creazione di un "token tag inizio" e lo stato viene modificato in "Stato nome tag".
Rimarremo in questo stato finché il carattere > non verrà consumato. Ogni carattere viene aggiunto al nome del nuovo token. Nel nostro caso, il token creato è un token html.
Quando viene raggiunto il tag >, viene emesso il token corrente e lo stato torna a "Stato dei dati".
Il tag <body> verrà trattato con gli stessi passaggi.
Finora sono stati emessi i tag html e body. Siamo tornati a "Stato dei dati".
L'utilizzo del carattere H di Hello world comporterà la creazione e l'emissione di un token carattere, che continuerà fino al raggiungimento del < di </body>. Emetteremo un token carattere per ogni carattere di Hello world.
Ora torniamo a "Stato tag aperto".
L'utilizzo dell'input successivo / comporterà la creazione di un end tag token e il passaggio allo "stato Nome tag". Anche in questo caso, rimaniamo in questo stato fino a quando non raggiungiamo >.A questo punto, verrà emesso il nuovo token del tag e torneremo a "Stato dei dati".
L'input </html> verrà trattato come nel caso precedente.
Algoritmo di costruzione dell'albero
Quando viene creato il parser, viene creato l'oggetto Document. Durante la fase di costruzione dell'albero, l'albero DOM con il documento nella radice verrà modificato e verranno aggiunti elementi. Ogni nodo emesso dal tokenizzatore verrà elaborato dal costruttore dell'albero. Per ogni token, la specifica definisce quale elemento DOM è pertinente e verrà creato per questo token. L'elemento viene aggiunto alla struttura DOM e alla serie di elementi aperti. Questo stack viene utilizzato per correggere le mancate corrispondenze di nidificazione e i tag non chiusi. L'algoritmo è descritto anche come macchina a stati. Questi stati sono chiamati "modalità di inserimento".
Vediamo la procedura di costruzione dell'albero per l'input di esempio:
<html>
<body>
Hello world
</body>
</html>
L'input della fase di costruzione dell'albero è una sequenza di token della fase di tokenizzazione. La prima modalità è la "modalità iniziale". La ricezione del token "html" comporterà il passaggio alla modalità "prima di html" e il nuovo trattamento del token in quella modalità. Verrà creato l'elemento HTMLHtmlElement, che verrà aggiunto all'oggetto Document principale.
Lo stato verrà modificato in "before head". Viene quindi ricevuto il token "body". Verrà creato un elemento HTMLHeadElement in modo implicito, anche se non abbiamo un token "head ", e verrà aggiunto all'albero.
Ora passiamo alla modalità "in testa" e poi a "dopo la testa". Il token del corpo viene rielaborato, viene creato e inserito un elemento HTMLBody e la modalità viene trasferita a "in body".
I token di caratteri della stringa "Hello world" vengono ora ricevuti. Il primo comporterà la creazione e l'inserimento di un nodo "Testo" e gli altri caratteri verranno aggiunti a quel nodo.
La ricezione del token di fine del corpo causerà il trasferimento alla modalità "dopo il corpo". Ora riceveremo il tag di chiusura HTML che ci porterà alla modalità "dopo il body". La ricezione del token di fine file termina l'analisi.
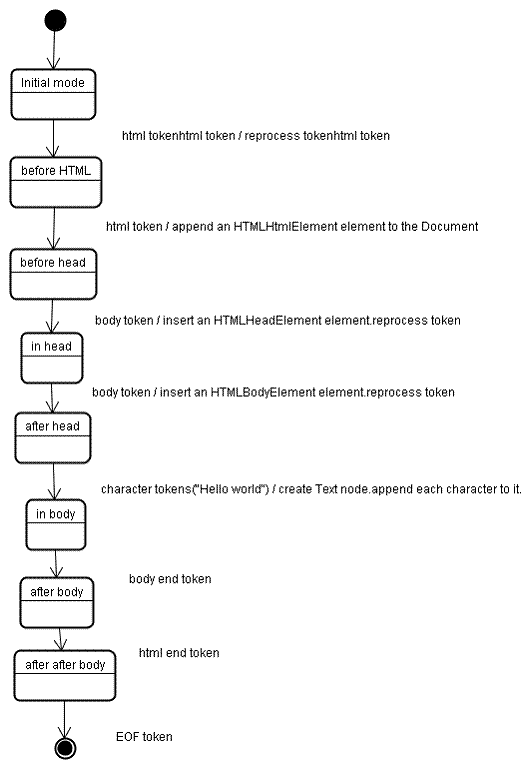
Azioni al termine dell'analisi
A questo punto, il browser contrassegna il documento come interattivo e inizia ad analizzare gli script in modalità "differita": quelli che devono essere eseguiti dopo l'analisi del documento. Lo stato del documento verrà impostato su "complete" e verrà attivato un evento "load".
Puoi consultare gli algoritmi completi per la tokenizzazione e la costruzione dell'albero nella specifica HTML5.
Tolleranza di errore dei browser
Non viene mai visualizzato un errore "Sintassi non valida" in una pagina HTML. I browser correggono i contenuti non validi e continuano.
Prendi ad esempio questo codice HTML:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Devo aver violato circa un milione di regole ("mytag" non è un tag standard, nidificazione errata degli elementi "p" e "div" e altro ancora), ma il browser lo mostra comunque correttamente e non segnala errori. Pertanto, gran parte del codice del parser serve a correggere gli errori dell'autore HTML.
La gestione degli errori è abbastanza coerente nei browser, ma sorprendentemente non fa parte delle specifiche HTML. Come i preferiti e i pulsanti Indietro/Avanti, è semplicemente una funzionalità sviluppata nei browser nel corso degli anni. Esistono strutture HTML non valide note ripetute su molti siti e i browser cercano di correggerle in modo conforme agli altri browser.
La specifica HTML5 definisce alcuni di questi requisiti. WebKit lo riassume bene nel commento all'inizio della classe dell'analizzatore HTML.
Il parser analizza l'input tokenizzato nel documento, creando l'albero del documento. Se il documento è ben formato, l'analisi è semplice.
Purtroppo, dobbiamo gestire molti documenti HTML non ben formattati, quindi lo scanner deve essere tollerante nei confronti degli errori.
Dobbiamo occuparci di almeno le seguenti condizioni di errore:
- L'elemento aggiunto è vietato in modo esplicito all'interno di alcuni tag esterni. In questo caso dobbiamo chiudere tutti i tag fino a quello che vieta l'elemento e aggiungerlo in un secondo momento.
- Non è consentito aggiungere l'elemento direttamente. È possibile che la persona che ha scritto il documento abbia dimenticato qualche tag intermedio (o che il tag intermedio sia facoltativo). Potrebbe essere il caso dei seguenti tag: HTML HEAD BODY TBODY TR TD LI (ne ho dimenticato qualcuno?).
- Vogliamo aggiungere un elemento di blocco all'interno di un elemento in linea. Chiudi tutti gli elementi in linea fino all'elemento di blocco successivo di livello superiore.
- Se il problema persiste, chiudi gli elementi finché non ci sarà consentito aggiungerlo o ignora il tag.
Ecco alcuni esempi di tolleranza degli errori di WebKit:
</br> anziché <br>
Alcuni siti utilizzano </br> anziché <br>. Per essere compatibile con IE e Firefox, WebKit lo tratta come <br>.
Il codice:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Tieni presente che la gestione degli errori è interna: non verrà presentata all'utente.
Una tabella fuori posto
Una tabella esterna è una tabella all'interno di un'altra tabella, ma non all'interno di una cella di tabella.
Ad esempio:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit cambierà la gerarchia in due tabelle sorelle:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Il codice:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit utilizza una pila per i contenuti dell'elemento corrente: estrae la tabella interna dalla pila di tabelle esterne. Le tabelle saranno ora sorelle.
Elementi di modulo nidificati
Se l'utente inserisce un modulo in un altro modulo, il secondo modulo viene ignorato.
Il codice:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Una gerarchia di tag troppo profonda
Il commento parla da solo.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Tag di chiusura html o body fuori posto
Ancora una volta, il commento parla da solo.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Quindi, autori web, attenzione: a meno che non vogliate comparire come esempio in uno snippet di codice di tolleranza degli errori di WebKit, scrivete HTML ben formato.
Analisi CSS
Ricordi i concetti di analisi sintattica nell'introduzione? A differenza dell'HTML, il CSS è una grammatica senza contesto e può essere analizzato utilizzando i tipi di analizzatori descritti nell'introduzione. Infatti, la specifica CSS definisce la grammatica lessicale e sintattica del CSS.
Vediamo alcuni esempi:
La grammatica lessicale (vocabolario) è definita da espressioni regolari per ogni token:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" è l'abbreviazione di identificatore, ad esempio il nome di una classe. "name" è un ID elemento (a cui si fa riferimento con "#")
La grammatica della sintassi è descritta in BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Spiegazione:
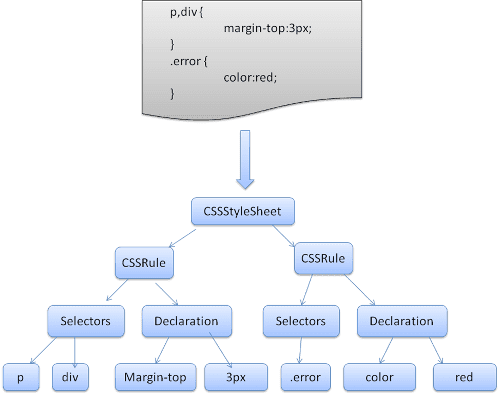
Un insieme di regole ha la seguente struttura:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error e a.error sono selettori. La parte all'interno delle parentesi graffe contiene le regole applicate da questo insieme di regole.
Questa struttura è definita formalmente in questa definizione:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Ciò significa che un insieme di regole è un selettore o, facoltativamente, un numero di selettori separati da una virgola e spazi (S indica uno spazio). Un insieme di regole contiene parentesi graffe e al loro interno una dichiarazione o, facoltativamente, un numero di dichiarazioni separate da un punto e virgola. "declaration" e "selector" verranno definiti nelle seguenti definizioni BNF.
Analizza CSS di WebKit
WebKit utilizza i generatori di parser Flex e Bison per creare automaticamente i parser dai file di grammatica CSS. Come ricordi dall'introduzione al parser, Bison crea un parser shift-reduce dal basso verso l'alto. Firefox utilizza un parser dall'alto verso il basso scritto manualmente. In entrambi i casi, ogni file CSS viene analizzato in un oggetto StyleSheet. Ogni oggetto contiene regole CSS. Gli oggetti regola CSS contengono oggetti selettore e dichiarazione e altri oggetti corrispondenti alla grammatica CSS.
Ordine di elaborazione di script e fogli di stile
Script
Il modello del web è sincrono. Gli autori si aspettano che gli script vengano analizzati ed eseguiti immediatamente quando il parser raggiunge un tag <script>.
L'analisi del documento viene interrotta fino all'esecuzione dello script.
Se lo script è esterno, la risorsa deve prima essere recuperata dalla rete. Questa operazione viene eseguita anche in modo sincrono e l'analisi viene interrotta fino al recupero della risorsa.
Questo è stato il modello per molti anni ed è specificato anche nelle specifiche HTML4 e 5.
Gli autori possono aggiungere l'attributo "defer" a uno script, in questo caso l'analisi del documento non verrà interrotta e lo script verrà eseguito dopo l'analisi. HTML5 aggiunge un'opzione per contrassegnare lo script come asincrono, in modo che venga analizzato ed eseguito da un thread diverso.
Analisi speculativa
Sia WebKit che Firefox eseguono questa ottimizzazione. Durante l'esecuzione degli script, un altro thread analizza il resto del documento e scopre quali altre risorse devono essere caricate dalla rete e le carica. In questo modo, le risorse possono essere caricate su connessioni parallele e la velocità complessiva viene migliorata. Nota: l'interprete speculativo analizza solo i riferimenti a risorse esterne come script, fogli di stile e immagini esterni: non modifica la struttura DOM, che viene lasciata all'interprete principale.
Fogli di stile
I fogli di stile, invece, hanno un modello diverso. A livello concettuale, sembra che, poiché i fogli di stile non modificano la struttura DOM, non ci sia motivo di attendere e interrompere l'analisi del documento. Tuttavia, si verifica un problema con gli script che richiedono informazioni sugli stili durante la fase di analisi del documento. Se lo stile non è ancora stato caricato e analizzato, lo script riceverà risposte sbagliate e, a quanto pare, questo ha causato molti problemi. Sembra un caso limite, ma è abbastanza comune. Firefox blocca tutti gli script quando è presente un foglio di stile che è ancora in fase di caricamento e analisi. WebKit blocca gli script solo quando tentano di accedere a determinate proprietà di stile che potrebbero essere interessate dagli stili non caricati.
Costruzione dell'albero di rendering
Durante la costruzione dell'albero DOM, il browser ne crea un altro, l'albero di rendering. Questo albero contiene gli elementi visivi nell'ordine in cui verranno visualizzati. È la rappresentazione visiva del documento. Lo scopo di questa struttura ad albero è consentire la visualizzazione dei contenuti nell'ordine corretto.
Firefox chiama gli elementi dell'albero di rendering "frame". WebKit utilizza il termine visualizzatore o oggetto di rendering.
Un renderer sa come eseguire il layout e dipingere se stesso e i suoi elementi secondari.
La classe RenderObject di WebKit, la classe di base dei renderer, ha la seguente definizione:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Ogni visualizzatore rappresenta un'area rettangolare che in genere corrisponde al riquadro CSS di un nodo, come descritto dalla specifica CSS2. Include informazioni geometriche come larghezza, altezza e posizione.
Il tipo di riquadro è influenzato dal valore "display" dell'attributo style pertinente al nodo (vedi la sezione Calcolo dello stile). Ecco il codice WebKit per decidere quale tipo di visualizzatore deve essere creato per un nodo DOM, in base all'attributo display:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Viene preso in considerazione anche il tipo di elemento: ad esempio, i controlli modulo e le tabelle hanno riquadri speciali.
In WebKit, se un elemento vuole creare un renderer speciale, sostituirà il metodo createRenderer().
I visualizzatori rimandano a oggetti di stile che contengono informazioni non geometriche.
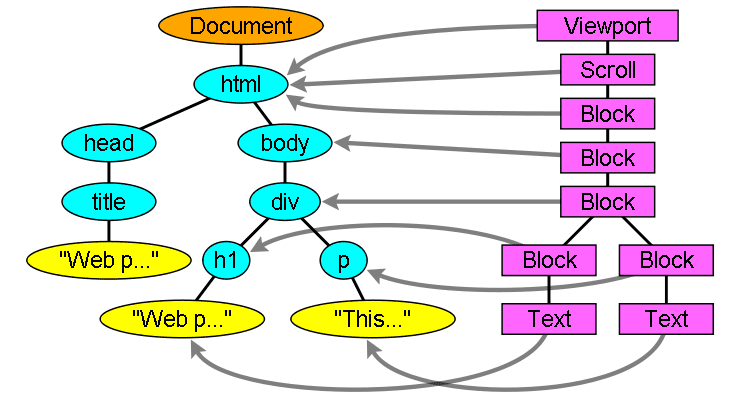
La relazione dell'albero di rendering con l'albero DOM
I visualizzatori corrispondono agli elementi DOM, ma la relazione non è uno a uno. Gli elementi DOM non visivi non verranno inseriti nell'albero di rendering. Un esempio è l'elemento "head". Inoltre, gli elementi a cui è stato assegnato il valore di visualizzazione "none" non verranno visualizzati nell'albero (mentre gli elementi con visibilità "hidden" verranno visualizzati nell'albero).
Esistono elementi DOM che corrispondono a più oggetti visivi. Di solito si tratta di elementi con una struttura complessa che non può essere descritta da un singolo rettangolo. Ad esempio, l'elemento "select" ha tre visualizzatori: uno per l'area di visualizzazione, uno per la casella dell'elenco a discesa e uno per il pulsante. Inoltre, quando il testo è suddiviso in più righe perché la larghezza non è sufficiente per una riga, le nuove righe verranno aggiunte come visualizzatori aggiuntivi.
Un altro esempio di più visualizzatori è il codice HTML non valido. Secondo le specifiche CSS, un elemento in linea deve contenere solo elementi in blocco o solo elementi in linea. Nel caso di contenuti misti, verranno creati visualizzatori di blocchi anonimi per avvolgere gli elementi in linea.
Alcuni oggetti di rendering corrispondono a un nodo DOM, ma non nella stessa posizione della struttura ad albero. Gli elementi in primo piano e con posizionamento assoluto sono fuori dal flusso, posizionati in una parte diversa dell'albero e mappati al frame reale. Al loro posto è presente un frame segnaposto.
Il flusso di costruzione dell'albero
In Firefox, la presentazione è registrata come ascoltatore per gli aggiornamenti del DOM.
La presentazione delega la creazione del frame a FrameConstructor e il costruttore risolve lo stile (vedi Calcolo dello stile) e crea un frame.
In WebKit, il processo di risoluzione dello stile e creazione di un visualizzatore è chiamato "attachment". Ogni nodo DOM ha un metodo "attach". L'attacco è sincrono, l'inserimento del nodo nella struttura DOM chiama il metodo "attach" del nuovo nodo.
L'elaborazione dei tag html e body comporta la costruzione della radice della struttura ad albero del rendering.
L'oggetto di rendering principale corrisponde a quello che la specifica CSS chiama blocco contenitore: il blocco più alto che contiene tutti gli altri blocchi. Le sue dimensioni sono l'area visibile: le dimensioni dell'area di visualizzazione della finestra del browser.
Firefox lo chiama ViewPortFrame e WebKit RenderView.
Si tratta dell'oggetto di rendering a cui fa riferimento il documento.
Il resto dell'albero viene costruito come inserimento di nodi DOM.
Consulta le specifiche CSS2 sul modello di elaborazione.
Calcolo dello stile
La creazione dell'albero di rendering richiede il calcolo delle proprietà visive di ogni oggetto di rendering. Questo viene fatto calcolando le proprietà di stile di ogni elemento.
Lo stile include fogli di stile di varie origini, elementi di stile incorporati e proprietà visive in HTML (come la proprietà "bgcolor").Quest'ultima viene tradotta in proprietà di stile CSS corrispondenti.
Le origini degli stili sono gli stili predefiniti del browser, gli stili forniti dall'autore della pagina e gli stili utente, ovvero quelli forniti dall'utente del browser (i browser ti consentono di definire i tuoi stili preferiti. In Firefox, ad esempio, questo viene fatto inserendo un foglio di stile nella cartella "Profilo di Firefox".
Il calcolo dello stile presenta alcune difficoltà:
- I dati di stile sono un costrutto molto grande che contiene le numerose proprietà di stile e possono causare problemi di memoria.
La ricerca delle regole di corrispondenza per ogni elemento può causare problemi di prestazioni se non è ottimizzata. Esaminare l'intero elenco di regole per ogni elemento per trovare le corrispondenze è un'operazione complessa. I selettori possono avere una struttura complessa che può causare l'avvio della procedura di corrispondenza su un percorso apparentemente promettente che si rivela inutile e deve essere provato un altro percorso.
Ad esempio, questo selettore composto:
div div div div{ ... }Significa che le regole si applicano a un
<div>che è il discendente di tre div. Supponiamo che tu voglia verificare se la regola si applica a un determinato elemento<div>. Scegli un determinato percorso nell'albero da controllare. Potresti dover risalire la struttura ad albero dei nodi per scoprire che ci sono solo due div e che la regola non si applica. Devi quindi provare altri percorsi nell'albero.L'applicazione delle regole prevede regole di cascata piuttosto complesse che definiscono la gerarchia delle regole.
Vediamo come i browser affrontano questi problemi:
Condivisione dei dati sugli stili
I nodi WebKit fanno riferimento a oggetti di stile (RenderStyle). Questi oggetti possono essere condivisi dai nodi in alcune condizioni. I nodi sono fratelli o cugini e:
- Gli elementi devono trovarsi nello stesso stato del mouse (ad es. uno non può essere in :hover mentre l'altro no)
- Nessuno dei due elementi deve avere un ID
- I nomi dei tag devono corrispondere
- Gli attributi della classe devono corrispondere
- L'insieme di attributi mappati deve essere identico
- Gli stati del collegamento devono corrispondere
- Gli stati di messa a fuoco devono corrispondere
- Nessuno degli elementi deve essere interessato dai selettori degli attributi, dove per interessato si intende la presenza di una corrispondenza del selettore che utilizza un selettore degli attributi in qualsiasi posizione all'interno del selettore
- Non deve essere presente alcun attributo di stile in linea negli elementi
- Non devono essere utilizzati selettori fratelli. WebCore lancia semplicemente un'opzione globale quando viene rilevato un selettore fratello e disattiva la condivisione degli stili per l'intero documento se sono presenti. Sono inclusi il selettore + e selettori come :first-child e :last-child.
Albero delle regole di Firefox
Firefox ha due alberi aggiuntivi per semplificare il calcolo degli stili: l'albero delle regole e l'albero del contesto dello stile. WebKit ha anche oggetti di stile, ma non sono memorizzati in una struttura ad albero come l'albero del contesto dello stile, solo il nodo DOM fa riferimento allo stile pertinente.
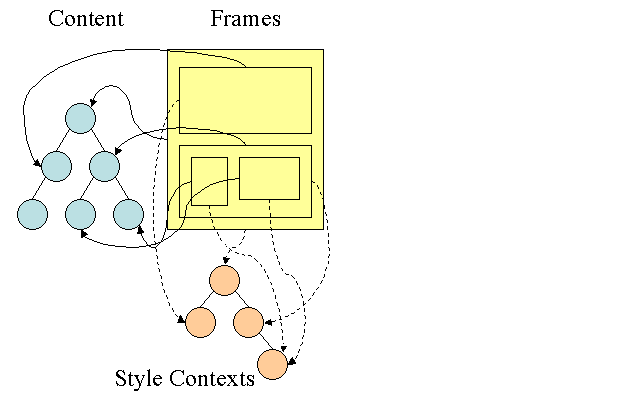
I contesti di stile contengono valori finali. I valori vengono calcolati applicando tutte le regole di corrispondenza nell'ordine corretto ed eseguendo manipolazioni che li trasformano da valori logici a valori concreti. Ad esempio, se il valore logico è una percentuale della schermata, verrà calcolato e trasformato in unità di misura absolute. L'idea dell'albero delle regole è davvero intelligente. Consente di condividere questi valori tra i nodi per evitare di doverli calcolare di nuovo. In questo modo risparmi anche spazio.
Tutte le regole corrispondenti vengono memorizzate in una struttura ad albero. I nodi inferiori di un percorso hanno una priorità più alta. L'albero contiene tutti i percorsi per le corrispondenze delle regole trovate. La memorizzazione delle regole viene eseguita in modo lazy. L'albero non viene calcolato all'inizio per ogni nodo, ma ogni volta che è necessario calcolare lo stile di un nodo, i percorsi calcolati vengono aggiunti all'albero.
L'idea è vedere i percorsi dell'albero come parole in un lessico. Supponiamo di aver già calcolato questo albero di regole:
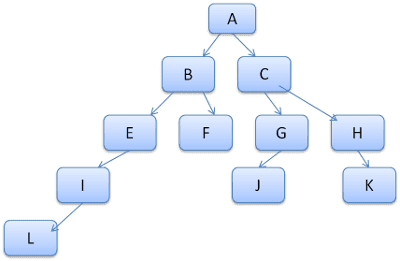
Supponiamo di dover associare regole per un altro elemento nell'albero dei contenuti e di scoprire che le regole associate (nell'ordine corretto) sono B-E-I. Questo percorso è già presente nell'albero perché abbiamo già calcolato il percorso A-B-E-I-L. Ora avremo meno lavoro da fare.
Vediamo come l'albero ci fa risparmiare lavoro.
Suddivisione in struct
I contesti di stile sono suddivisi in struct. Queste strutture contengono informazioni sullo stile per una determinata categoria, come bordo o colore. Tutte le proprietà di una struct sono ereditate o non ereditate. Le proprietà ereditate sono proprietà che, se non definite dall'elemento, vengono ereditate dall'elemento principale. Le proprietà non ereditate (chiamate proprietà "reset") utilizzano i valori predefiniti se non sono definiti.
L'albero ci aiuta memorizzando nella cache intere strutture (contenenti i valori finali calcolati). L'idea è che se il nodo inferiore non ha fornito una definizione per una struttura, è possibile utilizzare una struttura memorizzata nella cache in un nodo superiore.
Calcolo dei contesti di stile utilizzando la struttura ad albero delle regole
Quando calcoliamo il contesto di stile per un determinato elemento, calcoliamo prima un percorso nella struttura ad albero delle regole o ne utilizziamo uno esistente. Poi iniziamo ad applicare le regole nel percorso per compilare le strutture nel nuovo contesto di stile. Partiamo dal nodo inferiore del percorso, quello con la precedenza più alta (di solito il selettore più specifico) e risaliamo l'albero fino a quando la nostra struttura non è completa. Se non è presente alcuna specifica per la struttura nel nodo della regola, possiamo ottimizzare notevolmente: saliamo nell'albero fino a trovare un nodo che la specifichi completamente e lo indichiamo. Questa è l'ottimizzazione migliore: l'intera struttura è condivisa. In questo modo, si risparmiano memoria e calcoli dei valori finali.
Se troviamo definizioni parziali, saliamo nell'albero fino a quando la struttura non è completa.
Se non abbiamo trovato definizioni per la nostra struttura, nel caso in cui la struttura sia di tipo "ereditato ", facciamo riferimento alla struttura del nostro elemento principale nell'albero del contesto. In questo caso siamo riusciti anche a condividere le strutture. Se si tratta di una struttura di reimpostazione, verranno utilizzati i valori predefiniti.
Se il nodo più specifico aggiunge valori, dobbiamo eseguire alcuni calcoli aggiuntivi per trasformarli in valori effettivi. Memorizziamo quindi il risultato nel nodo dell'albero in modo che possa essere utilizzato dai bambini.
Se un elemento ha un fratello o una sorella che punta allo stesso nodo dell'albero, l'intero contesto di stile può essere condiviso tra loro.
Vediamo un esempio: Supponiamo di avere questo codice HTML
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
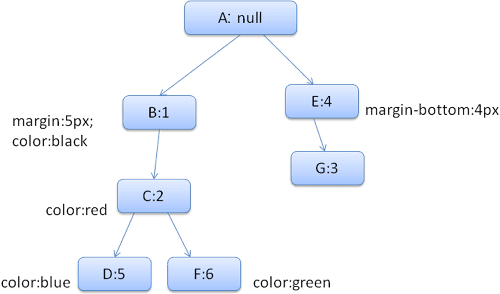
E le seguenti regole:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Per semplificare, supponiamo di dover compilare solo due struct: la struct di colore e la struct di margine. Lo struct color contiene un solo membro: il colore Lo struct margin contiene i quattro lati.
L'albero delle regole risultante sarà simile a questo (i nodi sono contrassegnati dal nome del nodo: il numero della regola a cui fanno riferimento):
L'albero del contesto sarà simile al seguente (nome del nodo: nodo regola a cui rimanda):
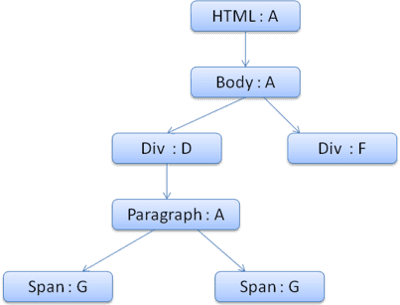
Supponiamo di analizzare il codice HTML e di arrivare al secondo tag <div>. Dobbiamo creare un contesto di stile per questo nodo e compilare le relative strutture di stile.
Le regole corrispondenti per <div> sono 1, 2 e 6.
Ciò significa che nella struttura esiste già un percorso che il nostro elemento può utilizzare e che dobbiamo solo aggiungere un altro nodo per la regola 6 (nodo F nella struttura della regola).
Creeremo un contesto di stile e lo inseriremo nella struttura ad albero del contesto. Il nuovo contesto dello stile punterà al nodo F nella struttura ad albero delle regole.
Ora dobbiamo compilare le strutture di stile. Inizieremo compilando la struttura del margine. Poiché l'ultimo nodo regola (F) non aggiunge nulla alla struttura del margine, possiamo risalire nella struttura ad albero fino a trovare una struttura memorizzata nella cache calcolata in un'inserzione di nodo precedente e utilizzarla. Lo troveremo nel nodo B, che è il nodo più alto che ha specificato le regole di margine.
Abbiamo una definizione per lo struct di colore, quindi non possiamo utilizzare uno struct memorizzato nella cache. Poiché il colore ha un attributo, non è necessario risalire nella struttura ad albero per compilare altri attributi. Calcoleremo il valore finale (converti stringa in RGB e così via) e memorizzeremo nella cache la struttura calcolata in questo nodo.
Il lavoro sul secondo elemento <span> è ancora più semplice. Le regole verranno associate e arriveremo alla conclusione che rimanda alla regola G, come lo spazio precedente.
Poiché abbiamo elementi fratelli che rimandano allo stesso nodo, possiamo condividere l'intero contesto dello stile e fare riferimento solo al contesto dell'elemento precedente.
Per le strutture che contengono regole ereditate dall'elemento principale, la memorizzazione nella cache viene eseguita sulla struttura ad albero del contesto (la proprietà color viene effettivamente ereditata, ma Firefox la tratta come reimpostata e la memorizza nella cache nella struttura ad albero delle regole).
Ad esempio, se aggiungiamo regole per i caratteri in un paragrafo:
p {font-family: Verdana; font size: 10px; font-weight: bold}
L'elemento paragrafo, che è un elemento secondario del div nell'albero del contesto, potrebbe aver condiviso la stessa struttura del carattere del suo elemento principale. Questo accade se non sono state specificate regole di carattere per il paragrafo.
In WebKit, che non ha un'albero di regole, le dichiarazioni con corrispondenze vengono attraversate quattro volte. Vengono applicate prima le proprietà non importanti con priorità elevata (proprietà che devono essere applicate per prime perché altre dipendono da esse, ad esempio la visualizzazione), poi le proprietà importanti con priorità elevata, poi le proprietà non importanti con priorità normale e infine le regole importanti con priorità normale. Ciò significa che le proprietà che appaiono più volte verranno risolte in base all'ordine di cascata corretto. Vince l'ultima.
Per riassumere: la condivisione degli oggetti di stile (completamente o alcune delle strutture al loro interno) risolve i problemi 1 e 3. La struttura ad albero delle regole di Firefox aiuta anche ad applicare le proprietà nell'ordine corretto.
Manipolare le regole per una facile corrispondenza
Esistono diverse origini per le regole di stile:
- Regole CSS in fogli di stile esterni o in elementi di stile.
css p {color: blue} - Attributi di stile in linea come
html <p style="color: blue" /> - Attributi visivi HTML (che vengono mappati alle regole di stile pertinenti)
html <p bgcolor="blue" />Gli ultimi due possono essere facilmente associati all'elemento poiché sono di sua proprietà e gli attributi HTML possono essere mappati utilizzando l'elemento come chiave.
Come indicato in precedenza nel problema 2, la corrispondenza delle regole CSS può essere più complessa. Per risolvere il problema, le regole vengono manipolate per facilitare l'accesso.
Dopo l'analisi del foglio di stile, le regole vengono aggiunte a una delle diverse mappe hash, in base al selettore. Esistono mappe per ID, per nome della classe, per nome del tag e una mappa generale per tutto ciò che non rientra in queste categorie. Se il selettore è un ID, la regola verrà aggiunta alla mappa degli ID, se è una classe verrà aggiunta alla mappa delle classi e così via.
Questa manipolazione semplifica notevolmente l'associazione delle regole. Non è necessario esaminare ogni dichiarazione: possiamo estrarre le regole pertinenti per un elemento dalle mappe. Questa ottimizzazione elimina oltre il 95% delle regole, in modo che non debbano nemmeno essere prese in considerazione durante la procedura di corrispondenza(4.1).
Vediamo ad esempio le seguenti regole di stile:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
La prima regola verrà inserita nella mappa delle classi. Il secondo nella mappa ID e il terzo nella mappa dei tag.
Per il seguente frammento HTML:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Per prima cosa proveremo a trovare regole per l'elemento p. La mappa di classi conterrà una chiave "errore" in cui viene trovata la regola per "p.error". L'elemento div avrà regole pertinenti nella mappa ID (la chiave è l'ID) e nella mappa dei tag. Pertanto, l'unica operazione rimasta è scoprire quali delle regole estratte dalle chiavi corrispondono effettivamente.
Ad esempio, se la regola per il div fosse:
table div {margin: 5px}
Verrà comunque estratto dalla mappa dei tag, perché la chiave è il selettore più a destra, ma non corrisponde all'elemento div, che non ha un'antecedente tabella.
Sia WebKit che Firefox eseguono questa manipolazione.
Ordine di applicazione dei fogli di stile
L'oggetto style ha proprietà corrispondenti a ogni attributo visivo (tutti gli attributi CSS, ma più generici). Se la proprietà non è definita da nessuna delle regole corrispondenti, alcune proprietà possono essere ereditate dall'oggetto stile dell'elemento principale. Altre proprietà hanno valori predefiniti.
Il problema si verifica quando sono presenti più definizioni. Ecco l'ordine di applicazione in cascata per risolvere il problema.
Una dichiarazione per una proprietà di stile può apparire in più fogli di stile e più volte all'interno di un foglio di stile. Ciò significa che l'ordine di applicazione delle regole è molto importante. Questo è chiamato ordine "a cascata". Secondo la specifica CSS2, l'ordine di applicazione è (dal più basso al più alto):
- Dichiarazioni del browser
- Dichiarazioni normali utente
- Dichiarazioni normali dell'autore
- Autorizzare dichiarazioni importanti
- Dichiarazioni importanti per l'utente
Le dichiarazioni del browser sono le meno importanti e l'utente sostituisce l'autore solo se la dichiarazione è contrassegnata come importante. Le dichiarazioni con lo stesso ordine verranno ordinate in base alla specificità e poi all'ordine in cui sono specificate. Gli attributi visivi HTML vengono tradotti in dichiarazioni CSS corrispondenti . Vengono trattate come regole dell'autore con priorità bassa.
Specificità
La specificità del selettore è definita dalla specifica CSS2 come segue:
- conteggia 1 se la dichiarazione proviene da un attributo "style" anziché da una regola con un selettore, altrimenti 0 (= a)
- conteggia il numero di attributi ID nel selettore (= b)
- conteggia il numero di altri attributi e pseudoclassi nel selettore (= c)
- conteggia il numero di nomi di elementi e pseudo-elementi nel selettore (= d)
La concatenazione dei quattro numeri a-b-c-d (in un sistema di numerazione con una base grande) fornisce la specificità.
La base di numeri da utilizzare è definita dal conteggio più alto presente in una delle categorie.
Ad esempio, se a=14 puoi utilizzare la base esadecimale. Nell'improbabile caso in cui a=17, avrai bisogno di una base di numeri di 17 cifre. La seconda situazione può verificarsi con un selettore come questo: html body div div p… (17 tag nel selettore… non molto probabile).
Ecco alcuni esempi:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Ordinamento delle regole
Dopo la corrispondenza, le regole vengono ordinate in base alle regole di applicazione in cascata.
WebKit utilizza la selezione a bolle per gli elenchi di piccole dimensioni e la selezione per unione per quelli di grandi dimensioni.
WebKit implementa l'ordinamento sostituendo l'operatore > per le regole:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Procedura graduale
WebKit utilizza un flag che indica se sono stati caricati tutti gli stili di primo livello (inclusi @import). Se lo stile non è completamente caricato al momento dell'attacco, vengono utilizzati dei segnaposto e lo stile viene contrassegnato nel documento. Questi verranno ricalcolati una volta caricati gli stili.
Layout
Quando il visualizzatore viene creato e aggiunto all'albero, non ha una posizione e dimensioni. Il calcolo di questi valori è chiamato layout o reflow.
HTML utilizza un modello di layout basato sul flusso, il che significa che la maggior parte delle volte è possibile calcolare la geometria in un unico passaggio. Gli elementi "più avanti nel flusso" in genere non influiscono sulla geometria degli elementi "più indietro nel flusso ", quindi il layout può procedere da sinistra a destra e dall'alto verso il basso nel documento. Esistono delle eccezioni: ad esempio, le tabelle HTML potrebbero richiedere più di un passaggio.
Il sistema di coordinate è relativo al frame principale. Vengono utilizzate le coordinate in alto e a sinistra.
Il layout è un processo ricorsivo. Inizia dal renderer principale, che corrisponde all'elemento <html> del documento HTML. Il layout continua in modo ricorsivo attraverso una parte o tutta la gerarchia del frame, calcolando le informazioni geometriche per ogni visualizzatore che lo richiede.
La posizione del renderer principale è 0,0 e le sue dimensioni corrispondono al viewport, ovvero la parte visibile della finestra del browser.
Tutti i renderer hanno un metodo "layout" o "reflow", ogni renderer invoca il metodo di layout dei suoi elementi figlio che richiedono il layout.
Sistema di bit sporchi
Per non eseguire un layout completo per ogni piccola modifica, i browser utilizzano un sistema di "dirty bit". Un renderer modificato o aggiunto contrassegna se stesso e i suoi elementi secondari come "sporchi": necessitano di un layout.
Esistono due flag: "dirty" e "children are dirty", il che significa che, anche se il renderer stesso potrebbe essere OK, ha almeno un elemento secondario che richiede un layout.
Layout globale e incrementale
Il layout può essere attivato nell'intera struttura ad albero di rendering: si tratta del layout "globale". Ciò può accadere a causa di:
- Una modifica dello stile globale che interessa tutti i renderer, ad esempio una modifica delle dimensioni dei caratteri.
- A seguito del ridimensionamento di una schermata
Il layout può essere incrementale, verranno disposti solo i renderer sporchi (questo può causare alcuni danni che richiederanno layout aggiuntivi).
Il layout incrementale viene attivato (in modo asincrono) quando i renderer non sono aggiornati. Ad esempio, quando nuovi visualizzatori vengono aggiunti alla struttura di rendering dopo che i contenuti aggiuntivi sono stati inviati dalla rete e aggiunti alla struttura DOM.
Layout asincrono e sincrono
Il layout incrementale viene eseguito in modo asincrono. Firefox mette in coda i "comandi di riflusso" per i layout incrementali e un programmatore attiva l'esecuzione collettiva di questi comandi. WebKit dispone anche di un timer che esegue un layout incrementale: l'albero viene attraversato e i renderer "sporchi" vengono sottoposti a layout.
Gli script che richiedono informazioni sugli stili, come "offsetHeight", possono attivare il layout incrementale in modo sincrono.
In genere, il layout globale viene attivato in modo sincrono.
A volte il layout viene attivato come callback dopo un layout iniziale perché alcuni attributi, come la posizione di scorrimento, sono cambiati.
Ottimizzazioni
Quando un layout viene attivato da un "ridimensionamento" o da una modifica della posizione del renderer(e non delle dimensioni), le dimensioni dei rendering vengono prese da una cache e non vengono ricalcolate…
In alcuni casi viene modificato solo un sottoalbero e il layout non inizia dalla radice. Ciò può accadere nei casi in cui la modifica sia locale e non influisca sull'ambiente circostante, ad esempio il testo inserito nei campi di testo (in caso contrario, ogni pressione di tasto attiverebbe un layout a partire dalla radice).
La procedura di layout
In genere il layout ha il seguente pattern:
- Il renderer principale determina la propria larghezza.
- Il genitore controlla i figli e:
- Posiziona il renderer secondario (imposta x e y).
- Se necessario, chiama il layout secondario (se non è pulito, se siamo in un layout globale o per qualche altro motivo) che calcola l'altezza del layout secondario.
- Il componente principale utilizza le altezze cumulative dei componenti secondari e le altezze di margini e spaziatura interna per impostare la propria altezza, che verrà utilizzata dal componente principale del visualizzatore principale.
- Imposta il bit dirty su false.
Firefox utilizza un oggetto "state" (nsHTMLReflowState) come parametro per il layout (chiamato "riflussi"). Tra gli altri, lo stato include la larghezza dei genitori.
L'output del layout di Firefox è un oggetto "metriche" (nsHTMLReflowMetrics). Conterrà l'altezza calcolata dal renderer.
Calcolo della larghezza
La larghezza del visualizzatore viene calcolata utilizzando la larghezza del blocco del contenitore, la proprietà "width" dello stile del visualizzatore, i margini e i bordi.
Ad esempio, la larghezza del seguente div:
<div style="width: 30%"/>
Verrà calcolato da WebKit come segue(metodo calcWidth della classe RenderBox):
- La larghezza del contenitore è la massima tra la larghezza disponibile dei contenitori e 0. In questo caso, availableWidth è la larghezza del contenuto, calcolata come segue:
clientWidth() - paddingLeft() - paddingRight()
clientWidth e clientHeight rappresentano l'interno di un oggetto esclusi il bordo e la barra di scorrimento.
La larghezza degli elementi è l'attributo dello stile "width". Verrà calcolato come valore assoluto mediante il calcolo della percentuale della larghezza del contenitore.
I bordi e i margini orizzontali sono stati aggiunti.
Finora abbiamo calcolato la "larghezza preferita". Ora verranno calcolate le larghezze minime e massime.
Se la larghezza preferita è maggiore di quella massima, viene utilizzata la larghezza massima. Se è inferiore alla larghezza minima (l'unità più piccola non frazionabile), viene utilizzata la larghezza minima.
I valori vengono memorizzati nella cache nel caso in cui sia necessario un layout, ma la larghezza non cambia.
Interruzioni di riga
Quando un visualizzatore nel mezzo di un layout decide di interrompersi, si arresta e comunica all'elemento principale del layout che deve essere interrotto. Il componente principale crea i renderer aggiuntivi e chiama il layout su di essi.
Pittura
Nella fase di pittura, l'albero di rendering viene attraversato e viene chiamato il metodo "paint()" del renderer per visualizzare i contenuti sullo schermo. La pittura utilizza il componente dell'infrastruttura dell'interfaccia utente.
Globali e incrementali
Come il layout, anche la pittura può essere globale (l'intero albero viene dipinto) o incrementale. Nella pittura incrementale, alcuni dei renderer cambiano in modo da non influire sull'intero albero. Il renderer modificato invalida il suo rettangolo sullo schermo. Di conseguenza, il sistema operativo la vede come una "regione non aggiornata" e genera un evento "paint". Il sistema operativo lo fa in modo intelligente e unisce più regioni in una sola. In Chrome è più complicato perché il motore di rendering si trova in un processo diverso da quello principale. Chrome simula il comportamento del sistema operativo in una certa misura. La presentazione ascolta questi eventi e delega il messaggio alla radice di rendering. L'albero viene attraversato fino a quando non viene raggiunto il visualizzatore pertinente. Si ridipingerà (e di solito anche i suoi elementi secondari).
L'ordine di pittura
CSS2 definisce l'ordine del processo di disegno. In realtà, si tratta dell'ordine in cui gli elementi vengono impilati nei contesti di impilaggio. Questo ordine influisce sulla verniciatura, poiché le serie vengono verniciate dal retro verso l'anteriore. L'ordine di sovrapposizione di un visualizzatore di blocchi è:
- colore sfondo
- Immagine di sfondo
- border
- bambini
- struttura
Elenco di visualizzazione di Firefox
Firefox esamina l'albero di rendering e crea un elenco di visualizzazione per il rettangolo dipinto. Contiene i renderer pertinenti per il rettangolo, nell'ordine di applicazione corretto (sfondi dei renderer, bordi e così via).
In questo modo, l'albero deve essere attraversato una sola volta per una nuova colorazione anziché più volte: dipingere tutti gli sfondi, poi tutte le immagini, poi tutti i bordi e così via.
Firefox ottimizza il processo non aggiungendo elementi che verranno nascosti, ad esempio quelli completamente sotto altri elementi opachi.
Spazio di archiviazione dei rettangoli WebKit
Prima di ridipingere, WebKit salva il vecchio rettangolo come bitmap. Quindi, viene visualizzato solo il delta tra il nuovo e il vecchio rettangolo.
Modifiche dinamiche
I browser cercano di eseguire le azioni minime possibili in risposta a una modifica. Pertanto, le modifiche al colore di un elemento ne causeranno solo la nuova colorazione. Le modifiche alla posizione dell'elemento ne causano il layout e la nuova colorazione, nonché di quelli secondari e, eventualmente, di quelli fratelli. L'aggiunta di un nodo DOM comporterà il layout e la nuova colorazione del nodo. Modifiche importanti, come l'aumento delle dimensioni dei caratteri dell'elemento "html", causeranno l'invalidazione delle cache, il nuovo layout e la nuova colorazione dell'intera struttura ad albero.
I thread del motore di rendering
Il motore di rendering è a thread singolo. Quasi tutto, tranne le operazioni di rete, avviene in un unico thread. In Firefox e Safari si tratta del thread principale del browser. In Chrome è il thread principale del processo della scheda.
Le operazioni di rete possono essere eseguite da più thread paralleli. Il numero di connessioni parallele è limitato (di solito 2-6 connessioni).
Loop di eventi
Il thread principale del browser è un loop di eventi. Si tratta di un loop infinito che mantiene attivo il processo. Attende gli eventi (ad esempio gli eventi di layout e di disegno) ed li elabora. Questo è il codice di Firefox per il loop di eventi principale:
while (!mExiting)
NS_ProcessNextEvent(thread);
Modello visivo CSS2
La tela
Secondo la specifica CSS2, il termine canvas descrive "lo spazio in cui viene visualizzata la struttura di formattazione": dove il browser dipinge i contenuti.
La tela è infinita per ogni dimensione dello spazio, ma i browser scelgono una larghezza iniziale in base alle dimensioni dell'area visibile.
Secondo la pagina www.w3.org/TR/CSS2/zindex.html, la tela è trasparente se contenuta in un'altra e, in caso contrario, viene assegnato un colore definito dal browser.
Modello a casella CSS
Il modello di riquadro CSS descrive le caselle rettangolari generate per gli elementi nell'albero del documento e disposte in base al modello di formattazione visiva.
Ogni riquadro ha un'area dei contenuti (ad es. testo, immagine e così via) e aree di spaziatura interna, bordi e margini facoltativi.
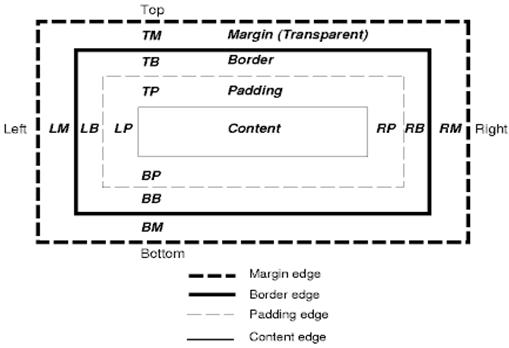
Ogni nodo genera 0…n caselle di questo tipo.
Tutti gli elementi hanno una proprietà "display" che determina il tipo di casella che verrà generata.
Esempi:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
Il valore predefinito è in linea, ma il foglio di stile del browser potrebbe impostare altri valori predefiniti. Ad esempio, la visualizzazione predefinita per l'elemento "div" è block.
Puoi trovare un esempio di foglio di stile predefinito qui: www.w3.org/TR/CSS2/sample.html.
Schema di posizionamento
Esistono tre schemi:
- Normale: l'oggetto viene posizionato in base alla sua posizione nel documento. Ciò significa che la sua posizione nella struttura di rendering è simile alla sua posizione nella struttura DOM e viene disposta in base al tipo e alle dimensioni della casella
- Flusso: l'oggetto viene prima disposto come per il flusso normale, quindi spostato il più possibile verso sinistra o verso destra
- Assoluto: l'oggetto viene inserito nell'albero di rendering in una posizione diversa rispetto all'albero DOM
Lo schema di posizionamento viene impostato dalla proprietà "position" e dall'attributo "float".
- statici e relativi causano un flusso normale
- absolute e fixed causano il posizionamento assoluto
Nel posizionamento statico non è definita alcuna posizione e viene utilizzato il posizionamento predefinito. Negli altri schemi, l'autore specifica la posizione: in alto, in basso, a sinistra, a destra.
La disposizione della casella è determinata da:
- Tipo di casella
- Dimensioni della confezione
- Schema di posizionamento
- Informazioni esterne, come le dimensioni delle immagini e dello schermo
Tipi di caselle
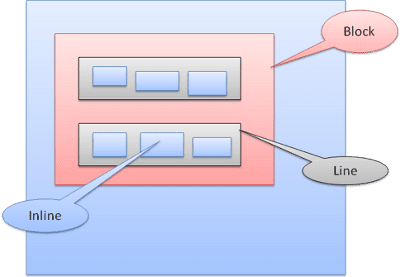
Casella di blocco: forma un blocco e ha un proprio rettangolo nella finestra del browser.

Riquadro in linea: non ha un proprio blocco, ma si trova all'interno di un blocco contenitore.
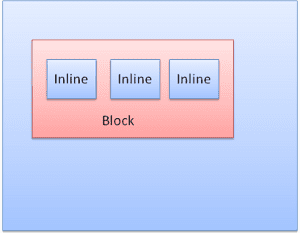
I blocchi vengono formattati verticalmente uno dopo l'altro. Le intestazioni in linea sono formattate orizzontalmente.
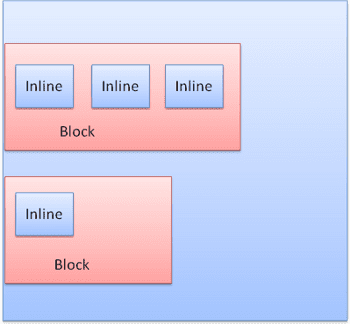
Le caselle in linea vengono inserite all'interno di linee o "caselle di riga". Le linee sono alte almeno quanto la casella più alta, ma possono essere più alte quando le caselle sono allineate "alla linea di base", ovvero la parte inferiore di un elemento è allineata a un punto di un'altra casella diverso dal basso. Se la larghezza del contenitore non è sufficiente, gli elementi in linea verranno inseriti su più righe. Di solito è quello che accade in un paragrafo.
Presentazione
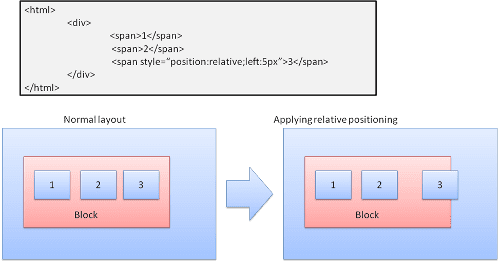
Relativo
Posizionamento relativo: posizionato come di consueto e poi spostato in base al delta richiesto.
Float
Una casella mobile viene spostata verso sinistra o destra rispetto a una riga. La caratteristica interessante è che le altre caselle si adattano al suo interno. Il codice HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Sarà simile al seguente:

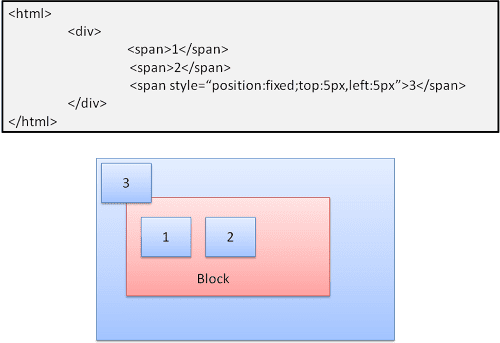
Assoluti e fissi
Il layout è definito esattamente indipendentemente dal flusso normale. L'elemento non partecipa al normale flusso. Le dimensioni sono relative al contenitore. In modalità fissa, il contenitore è l'area visibile.
Rappresentazione a più livelli
Questo valore è specificato dalla proprietà CSS z-index. Rappresenta la terza dimensione della casella: la sua posizione lungo l'"asse z".
Le caselle sono suddivise in serie (chiamate contesti di accodamento). In ogni pila, gli elementi posteriori verranno visualizzati per primi e quelli anteriori in alto, più vicini all'utente. In caso di sovrapposizione, l'elemento più in primo piano nasconderà l'elemento precedente.
Le serie sono ordinate in base alla proprietà z-index. Le caselle con la proprietà "z-index" formano una serie locale. L'area visibile contiene la serie di elementi esterni.
Esempio:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Il risultato sarà il seguente:

Sebbene il div rosso preceda quello verde nel markup e sarebbe stato visualizzato prima nel flusso normale, la proprietà z-index è più alta, quindi è più avanti nella serie detenuta dalla casella principale.
Risorse
Architettura del browser
- Grosskurth, Alan. Un'architettura di riferimento per i browser web (pdf)
- Gupta, Vineet. Come funzionano i browser - Parte 1 - Architettura
Analisi
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (noto anche come "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. Beautiful and the Bold: due nuove bozze per HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- L. David Baron, HTML e CSS più veloci: aspetti interni dell'engine di layout per sviluppatori web (video di Google Tech Talk)
- L. David Baron, Layout Engine di Mozilla
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Note su HTML Reflow
- Chris Waterson, Panoramica di Gecko
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, Rendering WebCore
- David Hyatt, The FOUC Problem
Specifiche W3C
Istruzioni di compilazione dei browser
Traduzioni
Questa pagina è stata tradotta in giapponese due volte:
- Come funzionano i browser: dietro le quinte dei browser web moderni (ja) di @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 di @ikeike443 e @kiyoto01.
Puoi visualizzare le traduzioni ospitate esternamente in coreano e turco.
Grazie a tutti.