
За кулисами современных веб-браузеров


Предисловие
Это подробное руководство по внутренним операциям WebKit и Gecko является результатом большого исследования, проведенного израильским разработчиком Тали Гарсиэль. В течение нескольких лет она просматривала все опубликованные данные о внутреннем устройстве браузера и потратила много времени на чтение исходного кода веб-браузера. Она написала:
Как веб-разработчик, изучение внутренних особенностей работы браузера поможет вам принимать более обоснованные решения и знать обоснование лучших практик разработки . Хотя это довольно объемный документ, мы рекомендуем вам потратить некоторое время на его изучение. Вы будете рады, что сделали это.
Пол Айриш, отдел по связям с разработчиками Chrome
Введение
Веб-браузеры являются наиболее широко используемым программным обеспечением. В этом руководстве я объясняю, как они работают за кулисами. Посмотрим, что произойдет, если вы наберете google.com в адресной строке, пока не увидите страницу Google на экране браузера.
Браузеры, о которых мы поговорим
Сегодня на настольных компьютерах используются пять основных браузеров: Chrome, Internet Explorer, Firefox, Safari и Opera. На мобильных устройствах основными браузерами являются Android Browser, iPhone, Opera Mini и Opera Mobile, UC Browser, браузеры Nokia S40/S60 и Chrome, все из которых, за исключением браузеров Opera, основаны на WebKit. Я приведу примеры из браузеров с открытым исходным кодом Firefox и Chrome, а также Safari (частично с открытым исходным кодом). Согласно статистике StatCounter (по состоянию на июнь 2013 г.), Chrome, Firefox и Safari составляют около 71% глобального использования браузеров для настольных компьютеров. На мобильных устройствах браузер Android, iPhone и Chrome составляют около 54% использования.
Основной функционал браузера
Основная функция браузера — представить выбранный вами веб-ресурс, запросив его с сервера и отобразив в окне браузера. Ресурс обычно представляет собой HTML-документ, но также может представлять собой PDF-файл, изображение или какой-либо другой тип контента. Местоположение ресурса указывается пользователем с помощью URI (унифицированного идентификатора ресурса).
То, как браузер интерпретирует и отображает файлы HTML, указано в спецификациях HTML и CSS. Эти спецификации поддерживаются организацией W3C (Консорциум World Wide Web), которая является организацией по стандартизации Интернета. В течение многих лет браузеры соответствовали лишь части спецификаций и разрабатывали собственные расширения. Это вызвало серьезные проблемы совместимости для веб-авторов. Сегодня большинство браузеров более или менее соответствуют спецификациям.
Пользовательские интерфейсы браузера имеют много общего друг с другом. Среди распространенных элементов пользовательского интерфейса можно выделить:
- Адресная строка для вставки URI
- Кнопки назад и вперед
- Параметры закладок
- Кнопки «Обновить» и «Стоп» для обновления или остановки загрузки текущих документов.
- Кнопка «Домой», которая приведет вас на домашнюю страницу.
Как ни странно, пользовательский интерфейс браузера не указан ни в одной формальной спецификации, он просто основан на передовых практиках, сформировавшихся за годы опыта, и на том, что браузеры имитируют друг друга. Спецификация HTML5 не определяет элементы пользовательского интерфейса, которые должен иметь браузер, но перечисляет некоторые общие элементы. Среди них адресная строка, строка состояния и панель инструментов. Конечно, есть функции, уникальные для конкретного браузера, такие как менеджер загрузок Firefox.
Инфраструктура высокого уровня
Основные компоненты браузера:
- Пользовательский интерфейс : включает в себя адресную строку, кнопку «Назад/Вперед», меню закладок и т. д. Все части экрана браузера, кроме окна, в котором вы видите запрошенную страницу.
- Механизм браузера : объединяет действия между пользовательским интерфейсом и механизмом рендеринга.
- Механизм рендеринга : отвечает за отображение запрошенного контента. Например, если запрошенное содержимое представляет собой HTML, механизм рендеринга анализирует HTML и CSS и отображает проанализированное содержимое на экране.
- Сеть : для сетевых вызовов, таких как HTTP-запросы, используются разные реализации для разных платформ за платформо-независимым интерфейсом.
- Серверная часть пользовательского интерфейса : используется для рисования основных виджетов, таких как поля со списком и окна. Этот бэкэнд предоставляет общий интерфейс, не зависящий от платформы. Под ним используются методы пользовательского интерфейса операционной системы.
- Интерпретатор JavaScript . Используется для анализа и выполнения кода JavaScript.
- Хранение данных . Это уровень персистентности. Браузеру может потребоваться сохранить все виды данных локально, например файлы cookie. Браузеры также поддерживают такие механизмы хранения, как localStorage, IndexedDB, WebSQL и FileSystem.
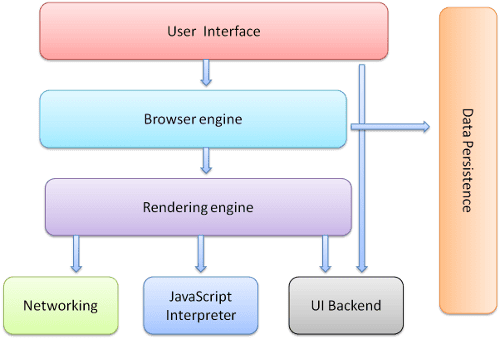
Важно отметить, что такие браузеры, как Chrome, запускают несколько экземпляров механизма рендеринга: по одному для каждой вкладки. Каждая вкладка выполняется в отдельном процессе.
Движки рендеринга
Ответственность движка рендеринга хорошо… Рендеринг, то есть отображение запрошенного содержимого на экране браузера.
По умолчанию механизм рендеринга может отображать документы и изображения HTML и XML. Он может отображать другие типы данных через плагины или расширения; например, отображение PDF-документов с помощью подключаемого модуля просмотра PDF-файлов. Однако в этой главе мы сосредоточимся на основном варианте использования: отображении HTML и изображений, отформатированных с помощью CSS.
В разных браузерах используются разные механизмы рендеринга: Internet Explorer использует Trident, Firefox использует Gecko, Safari использует WebKit. Chrome и Opera (начиная с версии 15) используют Blink, ответвление WebKit.
WebKit — это механизм рендеринга с открытым исходным кодом, который начинался как движок для платформы Linux и был модифицирован Apple для поддержки Mac и Windows.
Основной поток
Механизм рендеринга начнет получать содержимое запрошенного документа с сетевого уровня. Обычно это делается частями по 8 КБ.
После этого это основной поток работы движка рендеринга:

Механизм рендеринга начнет анализировать HTML-документ и преобразовывать элементы в узлы DOM в дереве, называемом «деревом контента». Движок будет анализировать данные стиля как во внешних файлах CSS, так и в элементах стиля. Информация о стиле вместе с визуальными инструкциями в HTML будет использоваться для создания другого дерева: дерева рендеринга .
Дерево рендеринга содержит прямоугольники с визуальными атрибутами, такими как цвет и размеры. Прямоугольники расположены в правильном порядке для отображения на экране.
После построения дерева рендеринга оно проходит процесс « макетирования ». Это означает предоставление каждому узлу точных координат того места, где он должен появиться на экране. Следующий этап — рисование — будет пройдено дерево рендеринга и каждый узел будет нарисован с использованием внутреннего слоя пользовательского интерфейса.
Важно понимать, что это постепенный процесс. Для лучшего взаимодействия с пользователем механизм рендеринга попытается отобразить содержимое на экране как можно скорее. Он не будет ждать, пока весь HTML будет проанализирован, прежде чем приступить к построению и компоновке дерева рендеринга. Части контента будут проанализированы и отображены, в то время как процесс продолжится с остальным контентом, который продолжает поступать из сети.
Примеры основного потока
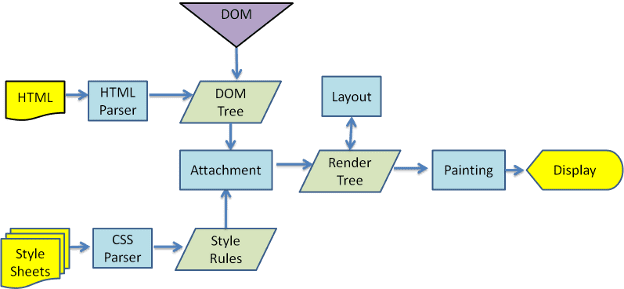
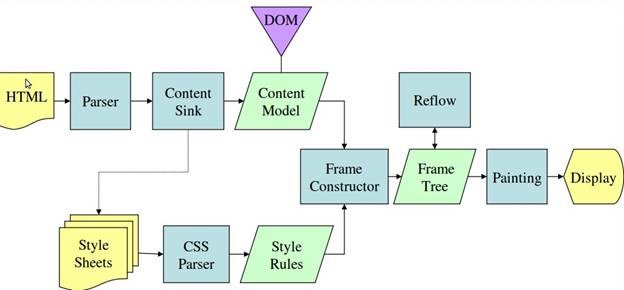
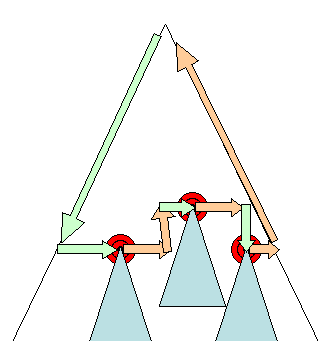
Из рисунков 3 и 4 видно, что хотя WebKit и Gecko используют несколько разную терминологию, последовательность действий в основном одинакова.
Gecko называет дерево визуально отформатированных элементов «деревом фреймов». Каждый элемент представляет собой рамку. WebKit использует термин «Дерево рендеринга» и состоит из «Объектов рендеринга». WebKit использует термин «макет» для размещения элементов, а Gecko называет его «перекомпоновка». «Присоединение» — это термин WebKit, обозначающий соединение узлов DOM и визуальной информации для создания дерева рендеринга. Небольшое несемантическое отличие состоит в том, что у Gecko есть дополнительный слой между HTML и деревом DOM. Он называется «приемником контента» и представляет собой фабрику по созданию элементов DOM. Мы поговорим о каждой части потока:
Синтаксический анализ – общий
Поскольку синтаксический анализ — очень важный процесс в движке рендеринга, мы углубимся в него. Начнем с небольшого введения в синтаксический анализ.
Анализ документа означает его преобразование в структуру, которую может использовать код. Результатом анализа обычно является дерево узлов, представляющих структуру документа. Это называется деревом разбора или синтаксическим деревом.
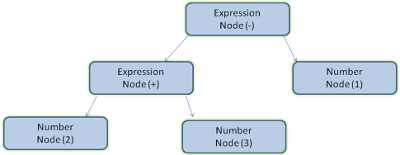
Например, анализ выражения 2 + 3 - 1 может вернуть такое дерево:
Грамматика
Синтаксический анализ основан на правилах синтаксиса, которым подчиняется документ: языке или формате, в котором он был написан. Каждый формат, который вы можете анализировать, должен иметь детерминированную грамматику, состоящую из словаря и правил синтаксиса. Это называется контекстно-свободной грамматикой . Человеческие языки не являются такими языками, и поэтому их нельзя анализировать с помощью традиционных методов синтаксического анализа.
Комбинация парсер-лексер
Синтаксический анализ можно разделить на два подпроцесса: лексический анализ и синтаксический анализ.
Лексический анализ — это процесс разбиения входных данных на токены. Токены — это словарь языка: набор действительных строительных блоков. В человеческом языке он будет состоять из всех слов, которые встречаются в словаре этого языка.
Синтаксический анализ – это применение правил синтаксиса языка.
Синтаксические анализаторы обычно делят работу между двумя компонентами: лексером (иногда называемым токенизатором), который отвечает за разбиение входных данных на действительные токены, и синтаксическим анализатором , который отвечает за построение дерева разбора путем анализа структуры документа в соответствии с правилами синтаксиса языка.
Лексер знает, как удалить ненужные символы, такие как пробелы и разрывы строк.
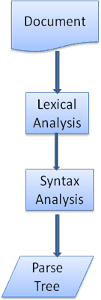
Процесс синтаксического анализа является итеративным. Синтаксический анализатор обычно запрашивает у лексера новый токен и пытается сопоставить его с одним из правил синтаксиса. Если правило соответствует, узел, соответствующий токену, будет добавлен в дерево разбора, и синтаксический анализатор запросит другой токен.
Если ни одно правило не соответствует, синтаксический анализатор сохранит токен внутри себя и будет продолжать запрашивать токены до тех пор, пока не будет найдено правило, соответствующее всем токенам, хранящимся внутри. Если правило не найдено, синтаксический анализатор выдаст исключение. Это означает, что документ недействителен и содержит синтаксические ошибки.
Перевод
Во многих случаях дерево разбора не является конечным продуктом. При переводе часто используется синтаксический анализ: преобразование входного документа в другой формат. Примером является компиляция. Компилятор, который компилирует исходный код в машинный код, сначала анализирует его в дерево разбора, а затем преобразует это дерево в документ машинного кода.
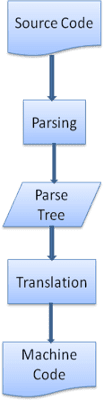
Пример парсинга
На рисунке 5 мы построили дерево разбора из математического выражения. Давайте попробуем определить простой математический язык и посмотрим на процесс анализа.
Синтаксис:
- Строительными блоками синтаксиса языка являются выражения, термины и операции.
- Наш язык может включать в себя любое количество выражений.
- Выражение определяется как «термин», за которым следует «операция», за которой следует еще один термин.
- Операция — это знак плюса или знак минуса.
- Термин — это целочисленный токен или выражение.
Давайте проанализируем ввод 2 + 3 - 1 .
Первая подстрока, соответствующая правилу, равна 2 : согласно правилу №5 это термин. Второе совпадение — 2 + 3 : это соответствует третьему правилу: за термином следует операция, за которой следует еще один термин. Следующее совпадение будет найдено только в конце ввода. 2 + 3 - 1 — это выражение, поскольку мы уже знаем, что 2 + 3 — это терм, поэтому у нас есть терм, за которым следует операция, за которой следует еще один терм. 2 + + не соответствует ни одному правилу и поэтому является недопустимым вводом.
Формальные определения словарного запаса и синтаксиса
Словарный запас обычно выражается регулярными выражениями .
Например, наш язык будет определен как:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Как видите, целые числа определяются регулярным выражением.
Синтаксис обычно определяется в формате BNF . Наш язык будет определен как:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Мы сказали, что язык может быть разобран обычными парсерами, если его грамматика является контекстно-свободной. Интуитивное определение контекстно-свободной грамматики — это грамматика, которая может быть полностью выражена в BNF. Формальное определение см. в статье Википедии «Контекстно-свободная грамматика».
Типы парсеров
Существует два типа парсеров: анализаторы сверху вниз и анализаторы снизу вверх. Интуитивное объяснение состоит в том, что анализаторы сверху вниз исследуют структуру синтаксиса высокого уровня и пытаются найти соответствие правилу. Анализаторы снизу вверх начинают с входных данных и постепенно преобразуют их в правила синтаксиса, начиная с правил низкого уровня до тех пор, пока не будут соблюдены правила высокого уровня.
Давайте посмотрим, как два типа парсеров будут анализировать наш пример.
Анализатор сверху вниз начнет с правила более высокого уровня: он определит 2 + 3 как выражение. Затем он идентифицирует 2 + 3 - 1 как выражение (процесс идентификации выражения развивается в соответствии с другими правилами, но отправной точкой является правило самого высокого уровня).
Синтаксический анализатор снизу вверх будет сканировать входные данные до тех пор, пока не будет найдено соответствие правилу. Затем он заменит соответствующий ввод правилом. Это будет продолжаться до конца ввода. Частично совпавшее выражение помещается в стек синтаксического анализатора.
Этот тип синтаксического анализатора снизу вверх называется анализатором сдвига-сокращения, поскольку ввод смещается вправо (представьте себе указатель, указывающий сначала на начало ввода и перемещающийся вправо) и постепенно сводится к синтаксическим правилам.
Автоматическое создание парсеров
Есть инструменты, которые могут генерировать парсер. Вы передаете им грамматику вашего языка — его словарный запас и правила синтаксиса — и они создают работающий парсер. Создание парсера требует глубокого понимания синтаксического анализа, а создать оптимизированный парсер вручную нелегко, поэтому генераторы парсеров могут быть очень полезны.
WebKit использует два хорошо известных генератора парсеров: Flex для создания лексера и Bison для создания парсера (вы можете столкнуться с ними под именами Lex и Yacc). Входные данные Flex — это файл, содержащий определения токенов регулярными выражениями. Входные данные Bison — это правила синтаксиса языка в формате BNF.
HTML-парсер
Задача анализатора HTML — преобразовать разметку HTML в дерево разбора.
HTML-грамматика
Словарь и синтаксис HTML определены в спецификациях, созданных организацией W3C.
Как мы видели во введении в синтаксический анализ, синтаксис грамматики может быть формально определен с использованием таких форматов, как BNF.
К сожалению, все традиционные темы парсера неприменимы к HTML (я поднял их не просто для развлечения — они будут использоваться при анализе CSS и JavaScript). HTML не может быть легко определен с помощью контекстно-свободной грамматики, которая необходима синтаксическим анализаторам.
Существует формальный формат определения HTML — DTD (Определение типа документа), но он не является контекстно-свободной грамматикой.
На первый взгляд это кажется странным; HTML довольно близок к XML. Существует множество доступных парсеров XML. Существует XML-вариант HTML — XHTML — так в чем же большая разница?
Разница в том, что подход HTML более «снисходителен»: он позволяет опускать определенные теги (которые затем добавляются неявно), а иногда и опускать начальные или конечные теги и т. д. В целом это «мягкий» синтаксис, в отличие от жесткого и требовательного синтаксиса XML.
Эта, казалось бы, маленькая деталь имеет огромное значение. С одной стороны, это основная причина популярности HTML: он прощает ваши ошибки и облегчает жизнь веб-автору. С другой стороны, это затрудняет написание формальной грамматики. Подводя итог, можно сказать, что HTML не может быть легко разобран обычными анализаторами, поскольку его грамматика не является контекстно-свободной. HTML не может быть проанализирован парсерами XML.
HTML-ОТД
Определение HTML находится в формате DTD. Этот формат используется для определения языков семейства SGML . Формат содержит определения всех разрешенных элементов, их атрибутов и иерархии. Как мы видели ранее, HTML DTD не формирует контекстно-свободную грамматику.
Существует несколько вариантов DTD. Строгий режим соответствует исключительно спецификациям, но другие режимы поддерживают разметку, использовавшуюся браузерами в прошлом. Целью является обратная совместимость со старым контентом. Текущий строгий DTD находится здесь: www.w3.org/TR/html4/strict.dtd .
ДОМ
Выходное дерево («дерево синтаксического анализа») представляет собой дерево элементов DOM и узлов атрибутов. DOM — это сокращение от объектной модели документа. Это объектное представление HTML-документа и интерфейс HTML-элементов с внешним миром, например JavaScript.
Корнем дерева является объект « Документ ».
DOM имеет почти однозначное отношение к разметке. Например:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Эта разметка будет преобразована в следующее дерево DOM:
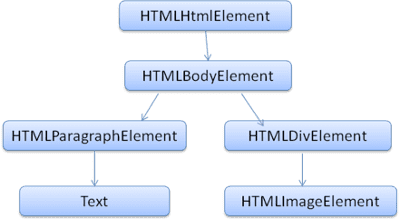
Как и HTML, DOM определяется организацией W3C. См. www.w3.org/DOM/DOMTR . Это общая спецификация для работы с документами. Конкретный модуль описывает определенные элементы HTML. Определения HTML можно найти здесь: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html .
Когда я говорю, что дерево содержит узлы DOM, я имею в виду, что дерево состоит из элементов, реализующих один из интерфейсов DOM. Браузеры используют конкретные реализации, у которых есть другие атрибуты, используемые браузером внутри.
Алгоритм парсинга
Как мы видели в предыдущих разделах, HTML нельзя анализировать с помощью обычных парсеров «сверху вниз» или «снизу вверх».
Причины:
- Прощающая природа языка.
- Тот факт, что браузеры имеют традиционную устойчивость к ошибкам для поддержки хорошо известных случаев недопустимого HTML.
- Процесс синтаксического анализа является реентерабельным. Для других языков источник не меняется во время синтаксического анализа, но в HTML динамический код (например, элементы сценария, содержащие вызовы
document.write()) может добавлять дополнительные токены, поэтому процесс синтаксического анализа фактически изменяет входные данные.
Не имея возможности использовать обычные методы анализа, браузеры создают собственные анализаторы для анализа HTML.
Алгоритм парсинга подробно описан спецификацией HTML5 . Алгоритм состоит из двух этапов: токенизации и построения дерева.
Токенизация — это лексический анализ, разбивающий входные данные на токены. Среди токенов HTML есть начальные теги, конечные теги, имена атрибутов и значения атрибутов.
Токенизатор распознает токен, передает его конструктору дерева и использует следующий символ для распознавания следующего токена и так далее до конца ввода.
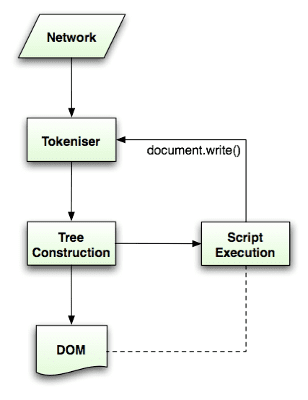
Алгоритм токенизации
Результатом работы алгоритма является HTML-токен. Алгоритм выражается в виде конечного автомата. Каждое состояние потребляет один или несколько символов входного потока и обновляет следующее состояние в соответствии с этими символами. На решение влияет текущее состояние токенизации и состояние построения дерева. Это означает, что один и тот же использованный символ будет давать разные результаты для правильного следующего состояния, в зависимости от текущего состояния. Алгоритм слишком сложен, чтобы его можно было полностью описать, поэтому давайте рассмотрим простой пример, который поможет нам понять принцип.
Базовый пример — токенизация следующего HTML:
<html>
<body>
Hello world
</body>
</html>
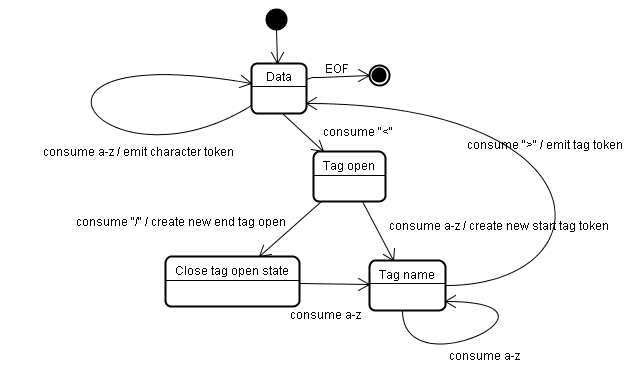
Исходное состояние — «Состояние данных». При обнаружении символа < состояние меняется на «Состояние тега открытое» . Использование символа az приводит к созданию «токена начального тега», состояние которого меняется на «состояние имени тега» . Мы остаемся в этом состоянии до тех пор, пока не будет использован символ > . Каждый символ добавляется к новому имени токена. В нашем случае созданный токен представляет собой html токен.
При достижении тега > генерируется текущий токен, и состояние меняется обратно на «Состояние данных» . Тег <body> будет обрабатываться теми же действиями. На данный момент теги html и body были созданы. Теперь мы вернулись в «Состояние данных» . Использование символа H в Hello world приведет к созданию и выдаче токена символа, это продолжается до тех пор, пока не будет достигнут < of </body> . Мы создадим токен персонажа для каждого персонажа Hello world .
Теперь мы вернулись в «состояние открытого тега» . Использование следующего ввода / приведет к созданию end tag token и переходу в «состояние имени тега» . Мы снова остаемся в этом состоянии, пока не достигнем > . Затем будет выпущен новый токен тега, и мы вернемся в «Состояние данных» . Ввод </html> будет обрабатываться так же, как и в предыдущем случае.
Алгоритм построения дерева
При создании парсера создается объект Document. На этапе построения дерева дерево DOM с Документом в корне будет изменено и к нему будут добавлены элементы. Каждый узел, созданный токенизатором, будет обработан конструктором дерева. Для каждого токена спецификация определяет, какой элемент DOM имеет к нему отношение и будет создан для этого токена. Элемент добавляется в дерево DOM, а также в стек открытых элементов. Этот стек используется для исправления несоответствий вложенности и незакрытых тегов. Алгоритм также описывается как конечный автомат. Состояния называются «режимами вставки».
Давайте посмотрим на процесс построения дерева для примера входных данных:
<html>
<body>
Hello world
</body>
</html>
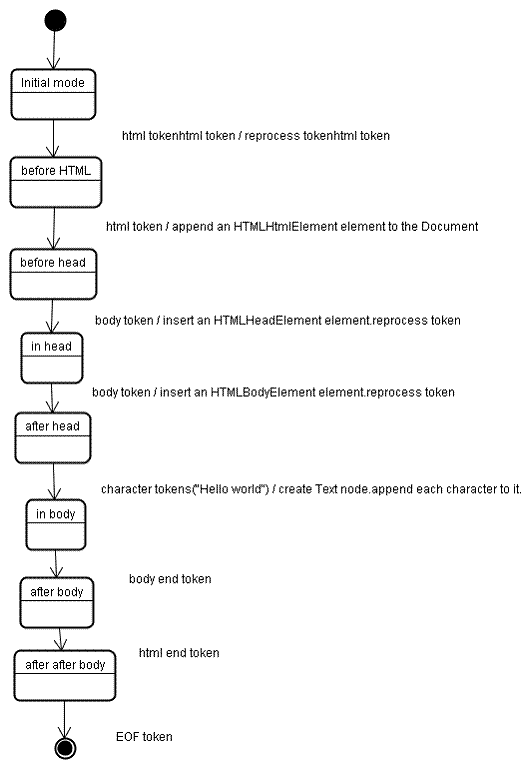
Входными данными для этапа построения дерева является последовательность токенов с этапа токенизации. Первый режим — «начальный режим» . Получение токена «html» приведет к переходу в режим «до HTML» и повторной обработке токена в этом режиме. Это приведет к созданию элемента HTMLHtmlElement, который будет добавлен к корневому объекту Document.
Состояние будет изменено на «до головы» . Затем принимается токен «тело». HTMLHeadElement будет создан неявно, хотя у нас нет токена «head», и он будет добавлен в дерево.
Теперь мы переходим в режим «в голове» , а затем в режим «после головы» . Токен тела повторно обрабатывается, создается и вставляется HTMLBodyElement, а режим переводится в «в теле» .
Символьные токены строки «Hello world» теперь получены. Первый вызовет создание и вставку узла «Текст», а остальные символы будут добавлены к этому узлу.
Получение токена завершения тела приведет к переходу в режим «после тела» . Теперь мы получим закрывающий тег html, который переведет нас в режим «после после тела» . Получение токена конца файла завершит синтаксический анализ.
Действия после завершения разбора
На этом этапе браузер пометит документ как интерактивный и начнет анализировать скрипты, находящиеся в «отложенном» режиме: те, которые должны быть выполнены после анализа документа. Состояние документа будет установлено на «завершено», и будет запущено событие «загрузка».
Полные алгоритмы токенизации и построения деревьев вы можете увидеть в спецификации HTML5 .
Устойчивость браузеров к ошибкам
Вы никогда не получите ошибку «Неверный синтаксис» на HTML-странице. Браузеры исправляют любой недопустимый контент и продолжают работу.
Возьмем, к примеру, этот HTML:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Я, наверное, нарушил около миллиона правил («mytag» не является стандартным тегом, неправильная вложенность элементов «p» и «div» и т. д.), но браузер по-прежнему показывает это правильно и не жалуется. Таким образом, большая часть кода парсера исправляет ошибки автора HTML.
Обработка ошибок в браузерах вполне единообразна, но, что удивительно, она не была частью спецификаций HTML. Подобно закладкам и кнопкам «Назад/Вперед», это просто то, что развивалось в браузерах на протяжении многих лет. Известны недопустимые конструкции HTML, повторяющиеся на многих сайтах, и браузеры пытаются исправить их способом, соответствующим другим браузерам.
Спецификация HTML5 определяет некоторые из этих требований. (WebKit прекрасно резюмирует это в комментарии в начале класса анализатора HTML.)
Анализатор анализирует токенизированные входные данные в документ, создавая дерево документа. Если документ правильно сформирован, его анализ не вызывает затруднений.
К сожалению, нам приходится обрабатывать множество HTML-документов, которые имеют неправильный формат, поэтому синтаксический анализатор должен быть терпим к ошибкам.
Мы должны позаботиться как минимум о следующих ошибках:
- Добавляемый элемент явно запрещен внутри некоторого внешнего тега. В этом случае нам следует закрыть все теги до того, который запрещает элемент, и добавить его позже.
- Нам не разрешено добавлять элемент напрямую. Возможно, человек, написавший документ, забыл какой-то тег между ними (или тег между ними не является обязательным). Это может произойти со следующими тегами: HTML HEAD BODY TBODY TR TD LI (я забыл какой-нибудь?).
- Мы хотим добавить блочный элемент внутри строчного элемента. Закройте все встроенные элементы до следующего более высокого элемента блока.
- Если это не помогает, закройте элементы, пока нам не будет разрешено добавить элемент, или игнорируйте тег.
Давайте посмотрим несколько примеров устойчивости к ошибкам WebKit:
</br> вместо <br>
Некоторые сайты используют </br> вместо <br> . Чтобы быть совместимым с IE и Firefox, WebKit обрабатывает это как <br> .
Код:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Обратите внимание, что обработка ошибок является внутренней: она не будет представлена пользователю.
Бродячий стол
Случайная таблица — это таблица внутри другой таблицы, но не внутри ячейки таблицы.
Например:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit изменит иерархию на две одноуровневые таблицы:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Код:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit использует стек для текущего содержимого элемента: он извлекает внутреннюю таблицу из стека внешней таблицы. Таблицы теперь будут одноуровневыми.
Вложенные элементы формы
Если пользователь помещает форму в другую форму, вторая форма игнорируется.
Код:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Слишком глубокая иерархия тегов
Комментарий говорит сам за себя.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Неправильно размещены конечные теги HTML или тела.
Опять же - комментарий говорит сам за себя.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Поэтому веб-авторы будьте осторожны - если вы не хотите, чтобы они использовались в качестве примера во фрагменте кода устойчивости к ошибкам WebKit, - пишите правильно сформированный HTML.
CSS-парсинг
Помните концепции синтаксического анализа во введении? В отличие от HTML, CSS является контекстно-свободной грамматикой и может анализироваться с использованием типов парсеров, описанных во введении. Фактически спецификация CSS определяет лексическую и синтаксическую грамматику CSS .
Давайте посмотрим несколько примеров:
Лексическая грамматика (словарь) определяется регулярными выражениями для каждого токена:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
«ident» — это сокращение от идентификатора, например, имени класса. «имя» — это идентификатор элемента (на который указывает «#»)
Синтаксическая грамматика описана в BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Объяснение:
Набор правил — это такая структура:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error и a.error являются селекторами. Часть внутри фигурных скобок содержит правила, применяемые этим набором правил. Эта структура формально определена в следующем определении:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Это означает, что набор правил представляет собой селектор или, возможно, несколько селекторов, разделенных запятой и пробелами (S означает пробел). Набор правил содержит фигурные скобки, а внутри них объявление или, при необходимости, несколько объявлений, разделенных точкой с запятой. «объявление» и «селектор» будут определены в следующих определениях BNF.
CSS-парсер WebKit
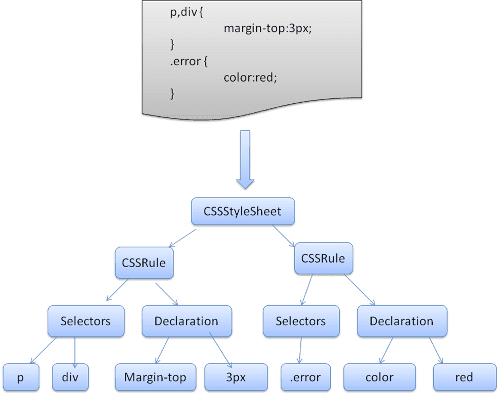
WebKit использует генераторы анализаторов Flex и Bison для автоматического создания анализаторов из файлов грамматики CSS. Как вы помните из введения в парсер, Bison создает синтаксический анализатор сдвига и сокращения снизу вверх. Firefox использует парсер сверху вниз, написанный вручную. В обоих случаях каждый файл CSS анализируется в объект StyleSheet. Каждый объект содержит правила CSS. Объекты правил CSS содержат объекты селектора и объявления, а также другие объекты, соответствующие грамматике CSS.
Порядок обработки скриптов и таблиц стилей
Скрипты
Модель сети синхронна. Авторы ожидают, что скрипты будут анализироваться и выполняться немедленно, когда парсер достигнет тега <script> . Анализ документа останавливается до тех пор, пока скрипт не будет выполнен. Если скрипт является внешним, то ресурс сначала необходимо получить из сети — это также делается синхронно, и синтаксический анализ останавливается до тех пор, пока ресурс не будет получен. Эта модель использовалась на протяжении многих лет и также указана в спецификациях HTML4 и 5. Авторы могут добавить в скрипт атрибут «defer», и в этом случае он не остановит синтаксический анализ документа и будет выполнен после анализа документа. В HTML5 добавлена возможность пометить сценарий как асинхронный, чтобы он анализировался и выполнялся в другом потоке.
Спекулятивный анализ
И WebKit, и Firefox выполняют такую оптимизацию. Во время выполнения скриптов другой поток анализирует остальную часть документа, выясняет, какие еще ресурсы необходимо загрузить из сети, и загружает их. Таким образом, ресурсы можно загружать в параллельные соединения, а общая скорость повышается. Примечание. Спекулятивный парсер анализирует только ссылки на внешние ресурсы, такие как внешние скрипты, таблицы стилей и изображения: он не изменяет дерево DOM — это остается на усмотрение основного парсера.
Таблицы стилей
С другой стороны, таблицы стилей имеют другую модель. Концептуально кажется, что, поскольку таблицы стилей не меняют дерево DOM, нет смысла ждать их и останавливать анализ документа. Однако существует проблема со сценариями, запрашивающими информацию о стиле на этапе анализа документа. Если стиль еще не загружен и не проанализирован, скрипт будет получать неверные ответы, и, видимо, это вызывает множество проблем. Кажется, это крайний случай, но он довольно распространен. Firefox блокирует все скрипты, если таблица стилей все еще загружается и анализируется. WebKit блокирует сценарии только тогда, когда они пытаются получить доступ к определенным свойствам стиля, на которые могут повлиять выгруженные таблицы стилей.
Построение дерева рендеринга
Пока строится дерево DOM, браузер создает другое дерево — дерево рендеринга. Это дерево состоит из визуальных элементов в том порядке, в котором они будут отображаться. Это визуальное представление документа. Назначение этого дерева — обеспечить возможность раскрашивания содержимого в правильном порядке.
Firefox называет элементы дерева рендеринга «фреймами». WebKit использует термин средство рендеринга или объект рендеринга.
Средство визуализации знает, как расположить и нарисовать себя и свои дочерние элементы.
Класс WebKit RenderObject, базовый класс средств рендеринга, имеет следующее определение:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Каждый рендерер представляет собой прямоугольную область, обычно соответствующую блоку CSS узла, как описано в спецификации CSS2. Он включает в себя геометрическую информацию, такую как ширина, высота и положение.
На тип блока влияет значение «display» атрибута стиля, соответствующего узлу (см. раздел « Вычисление стиля» ). Вот код WebKit для принятия решения о том, какой тип средства визуализации следует создать для узла DOM в соответствии с атрибутом display:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Также учитывается тип элемента: например, элементы управления формами и таблицы имеют специальные рамки.
В WebKit, если элемент хочет создать специальный рендерер, он переопределит метод createRenderer() . Средства визуализации указывают на объекты стиля, содержащие негеометрическую информацию.
Связь дерева рендеринга с деревом DOM
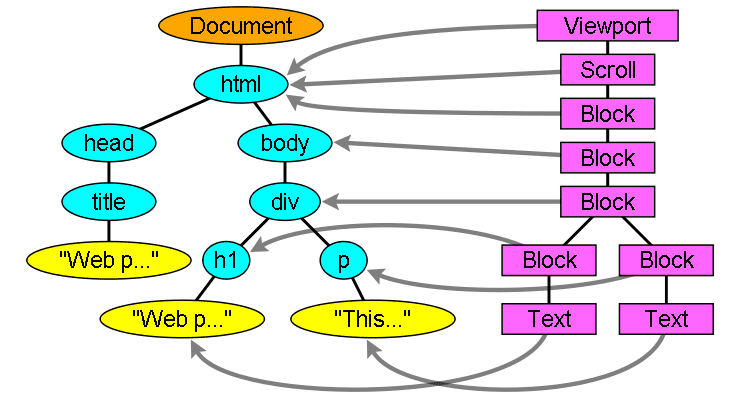
Средства визуализации соответствуют элементам DOM, но отношение не один к одному. Невизуальные элементы DOM не будут вставлены в дерево рендеринга. Примером может служить элемент «head». Также элементы, для которых было присвоено значение отображения «нет», не будут отображаться в дереве (тогда как элементы со «скрытой» видимостью появятся в дереве).
Существуют элементы DOM, которые соответствуют нескольким визуальным объектам. Обычно это элементы сложной структуры, которые невозможно описать одним прямоугольником. Например, элемент «Select» имеет три визуализатора: один для области отображения, один для раскрывающегося списка и один для кнопки. Кроме того, когда текст разбит на несколько строк, потому что ширина недостаточно для одной строки, новые линии будут добавлены в качестве дополнительных визуализаций.
Другим примером множественных рендеристов является разбитый HTML. Согласно спецификации CSS, встроенный элемент должен содержать либо блокировать только элементы, либо только встроенные элементы. В случае смешанного контента будут созданы анонимные визуализаторы блоков, чтобы обернуть встроенные элементы.
Некоторые рендеринг -объекты соответствуют узлу DOM, но не в том же месте в дереве. Поплавки и абсолютно позиционированные элементы вышли из потока, помещаются в другую часть дерева и нанесены на карту на реальную кадр. Рамка для заполнителей - это то, где они должны были быть.
Поток построения дерева
В Firefox презентация зарегистрирована как слушатель для обновлений DOM. Представление делегатов создает создание для FrameConstructor , а конструктор разрешает стиль (см. Вычисление стиля ) и создает кадр.
В Webkit процесс разрешения стиля и создания рендеринга называется «привязанностью». Каждый узел DOM имеет метод «прикрепления». Приложение является синхронным, вставка узла к дереву DOM вызывает новый метод «Прикрепления».
Обработка HTML и тегов тела приводит к созданию корня рендеринга. Объект render Render соответствует тому, что спецификация CSS вызывает содержащий блок: самый верхний блок, который содержит все остальные блоки. Его размеры - порт Viewport: размеры области отображения окна браузера. Firefox называет его ViewPortFrame , а Webkit называет его RenderView . Это объект рендеринга, на который указывает документ. Остальная часть дерева построена как вставка узлов DOM.
Смотрите спецификацию CSS2 на модели обработки .
Вычисление стиля
Создание дерева рендеринга требует расчета визуальных свойств каждого объекта рендеринга. Это делается путем расчета свойств стиля каждого элемента.
Стиль включает в себя листы стиля различных истоков, элементы встроенного стиля и визуальные свойства в HTML (например, свойство «BGColor»). Позднее переводится на соответствующие свойства стиля CSS.
Происхождение листов в стиле - это листы стиля по умолчанию браузера, листы стиля, предоставленные автором страницы и листами в стиле пользователя - это листы стилей, предоставленные пользователем браузера (браузеры позволяют вам определить ваши любимые стили.
Вычисление в стиле вызывает несколько трудностей:
- Данные стиля - очень большая конструкция, удерживая многочисленные свойства стиля, это может вызвать проблемы с памятью.
Поиск правил соответствия для каждого элемента может вызвать проблемы с производительностью, если они не оптимизированы. Переход всего списка правил для каждого элемента найти совпадения - это тяжелая задача. Селекторы могут иметь сложную структуру, которая может привести к тому, что процесс сопоставления начинается с, казалось бы, многообещающего пути, который оказался бесполезным, а другой путь должен быть опробован.
Например - этот комплексный селектор:
div div div div{ ... }Означает, что правила применяются к
<div>, кто является потомком 3 Div. Предположим, вы хотите проверить, применяется ли правило для данного элемента<div>. Вы выбираете определенный путь вверх по дереву для проверки. Возможно, вам придется пройти через узловое дерево, чтобы узнать, что есть только два DIV, и правило не применяется. Затем вам нужно попробовать другие пути на дереве.Применение правил включает в себя довольно сложные каскадные правила, которые определяют иерархию правил.
Посмотрим, как браузеры сталкиваются с этими проблемами:
Данные об обмене стиля
Узлы WebKit ссылки на стиль объектов (renderStyle). Эти объекты могут быть разделены узлами в некоторых условиях. Узлы - братья и сестры или двоюродные братья и:
- Элементы должны быть в одном и том же состоянии мыши (например, один не может быть в: парить, а другой - нет)
- Ни один элемент не должен иметь удостоверения личности
- Имена тегов должны соответствовать
- Атрибуты класса должны соответствовать
- Набор картированных атрибутов должен быть идентичным
- Состояния ссылки должны соответствовать
- Состояния фокуса должны соответствовать
- Ни на ни один элемент не должен зависеть от селекторов атрибутов, где затронуто определяется как какое -либо соответствие селектора, которое использует селектор атрибутов в любой позиции в селекторе вообще
- Не должно быть атрибута встроенного стиля на элементах
- Не должно быть никаких сестер, используемых вообще. Webcore просто бросает глобальный коммутатор, когда встречается любой селектор братьев и сестер, и отключает обмен стилем для всего документа, когда они присутствуют. Это включает в себя селектор + и селекторы, такие как: первый ребенок и: последний ребенок.
Firefox Rule Tree
У Firefox есть два дополнительных деревья для более легкого вычисления в стиле: дерево правил и контекстное дерево стиля. У Webkit также есть стильные объекты, но они не хранятся в дереве, подобном контекстному дереву стиля, только узел DOM указывает на его соответствующий стиль.
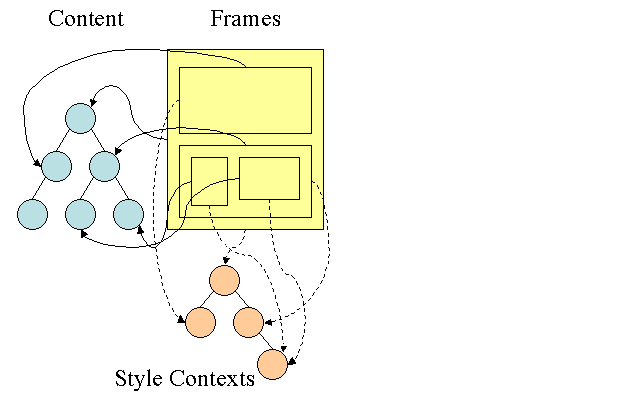
Контексты в стиле содержат конечные значения. Значения вычисляются путем применения всех правил сопоставления в правильном порядке и выполнения манипуляций, которые преобразуют их из логических в конкретные значения. Например, если логическое значение составляет процент от экрана, оно будет рассчитано и преобразовано в абсолютные единицы. Идея дерева правил действительно умна. Это позволяет делиться этими значениями между узлами, чтобы не вычислять их снова. Это также экономит пространство.
Все соответствующие правила хранятся в дереве. Нижние узлы на пути имеют более высокий приоритет. Дерево содержит все пути для совпадений правил, которые были найдены. Хранение правил сделано лениво. Дерево не рассчитывается в начале для каждого узла, но всякий раз, когда необходимо вычислять стиль узла, вычисленные пути добавляются в дерево.
Идея состоит в том, чтобы увидеть пути деревьев как слова в лексиконе. Допустим, мы уже вычислили это дерево правил:
Предположим, нам нужно соответствовать правилам для другого элемента в дереве содержания и выяснить, что соответствующие правила (в правильном порядке) являются BEI. У нас уже есть этот путь на дереве, потому что мы уже рассчитали путь, Абейл. Теперь у нас будет меньше работы.
Посмотрим, как дерево спасает нас работать.
Разделение на структуры
Контексты стиля разделены на структуры. Эти структуры содержат информацию о стиле для определенной категории, такой как граница или цвет. Все свойства в структуре либо унаследованы, либо унаследованы. Унаследованные свойства - это свойства, которые, если они не определены элементом, унаследованы от его родителя. Неконтролируемые свойства (называемые «сброшенными» свойствами) используют значения по умолчанию, если не определены.
Дерево помогает нам, кэшируя целые структуры (содержащие вычисленные конечные значения) в дереве. Идея состоит в том, что если нижний узел не предоставил определение для структуры, можно использовать кэшированную структуру в верхнем узле.
Вычисление контекстов стиля с использованием дерева правил
При вычислении контекста стиля для определенного элемента мы сначала вычисляем путь в дереве правил или используем существующий. Затем мы начинаем применять правила на пути, чтобы заполнить структуры в нашем контексте нашего нового стиля. Мы начинаем с нижнего узла пути - тот, который с самым высоким приоритетом (обычно самый специфический селектор) и перемещать дерево вверх до тех пор, пока наша структура не будет заполнена. Если в этом узле правила нет спецификации, то мы можем значительно оптимизировать - мы поднимаемся на дерево, пока не найдем узел, который полностью его указывает и указывают на него - это лучшая оптимизация - вся структура используется. Это сохраняет вычисление конечных значений и памяти.
Если мы найдем частичные определения, мы поднимаемся по дереву, пока структура не будет заполнена.
Если мы не нашли никаких определений для нашей структуры, то в случае, если структура является «унаследованным» типом, мы указываем на структуру нашего родителя в дереве контекста . В этом случае нам также удалось разделить структуры. Если это структура сброса, то будут использоваться значения по умолчанию.
Если наиболее конкретный узел действительно добавляет значения, то нам нужно сделать дополнительные вычисления для преобразования его в реальных значениях. Затем мы кэшируем результат в узле дерева, чтобы его можно было использовать детьми.
В случае, если у элемента есть брат или брат, который указывает на тот же узел дерева, тогда между ними можно разделить весь контекст стиля .
Давайте посмотрим на пример: предположим, что у нас есть этот HTML
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
И следующие правила:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Чтобы упростить вещи, скажем, нам нужно заполнить только две структуры: цветовая структура и маржинальная структура. Цветовая конструкция содержит только один элемент: цвет, который маржинальный конструкция содержит четыре стороны.
Полученное дерево правил будет выглядеть так (узлы отмечены именем узла: количество правила, на которое они указывают):
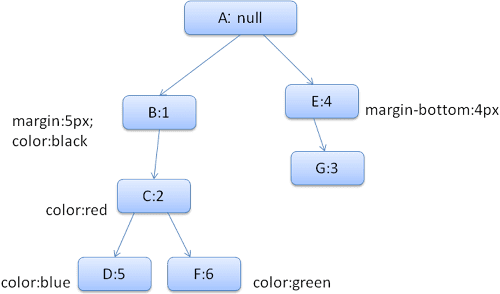
Дерево контекста будет выглядеть так (имя узла: Узел правила, на который они указывают):
Предположим, мы проанализируем HTML и добираемся до второго тега <div> . Нам нужно создать контекст стиля для этого узла и заполнить его стильные структуры.
Мы сопоставляем правила и обнаружим, что соответствующие правила для <div> - 1, 2 и 6. Это означает, что в дереве уже существует существующий путь, который может использовать наш элемент, и нам просто нужно добавить в него еще один узел для правила 6 (узел F в дереве правил).
Мы создадим контекст стиля и поместим его в контекстное дерево. Контекст нового стиля будет указывать на узел F в дереве правил.
Теперь нам нужно заполнить стильные структуры. Мы начнем с заполнения маржинальной структуры. Поскольку последний узел правила (F) не добавляет к маржинальной структуре, мы можем подняться на дерево, пока не найдем кэшированную структуру, рассчитанную в предыдущей вставке узла, и использовать его. Мы найдем его на узле B, который является самым верхним узлом, который указал правила маржи.
У нас есть определение для цветной структуры, поэтому мы не можем использовать кэшированную структуру. Поскольку в цвете есть один атрибут, нам не нужно подниматься по дереву, чтобы заполнить другие атрибуты. Мы рассмотрим конечное значение (преобразовать строку в RGB и т. Д.) и кэшируйте вычисленную структуру в этом узле.
Работа над вторым элементом <span> еще проще. Мы сопоставляем правила и пришли к выводу, что он указывает на правило G, как и в предыдущем промежутке. Поскольку у нас есть братья и сестры, которые указывают на один и тот же узел, мы можем поделиться всем контекстом стиля и просто указать на контекст предыдущего пролета.
Для структур, которые содержат правила, которые унаследованы от родителей, кэширование осуществляется на контекстном дереве (свойство цвета на самом деле унаследовано, но Firefox рассматривает его как сброс и кэширует его на дереве правил).
Например, если мы добавили правила для шрифтов в абзаце:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Тогда элемент абзаца, который является ребенком Div в контекстном дереве, мог бы разделить ту же структуру шрифта, что и его родитель. Это если правила шрифта не были указаны для абзаца.
В Webkit, у которого нет дерева правил, соответствующие объявления проходят четыре раза. Сначала применяются не важные свойства высокого приоритета (свойства, которые должны применяться в первую очередь, потому что другие зависят от них, таких как дисплей), а затем важный приоритет, а затем нормальный приоритет не имеет значения, а затем нормальный приоритет важных правил. Это означает, что свойства, которые появляются несколько раз, будут разрешены в соответствии с правильным каскадным порядком. Последние победы.
Таким образом, суммируйте: совместное использование объектов стиля (полностью или некоторые из них внутри них) решает проблемы 1 и 3. Дерево правил Firefox также помогает в применении свойств в правильном порядке.
Манипулирование правилами для легкого матча
Есть несколько источников для правил стиля:
- Правила CSS, либо в листах внешнего стиля, либо по элементам стиля.
css p {color: blue} - Атрибуты встроенного стиля, такие как
html <p style="color: blue" /> - Визуальные атрибуты HTML (которые отображаются с соответствующими правилами стиля)
html <p bgcolor="blue" />Последние два легко сопоставлены с элементом, поскольку ему принадлежат атрибуты стиля, а атрибуты HTML могут быть сопоставлены с использованием элемента в качестве ключа.
Как отмечалось ранее в выпуске № 2, сопоставление правил CSS может быть сложнее. Чтобы решить сложность, правилами манипулируют для более легкого доступа.
По словам селектора, после анализа листа стиля правила добавляются к одной из нескольких карт хеш -карт. Есть карты по идентификатору, по имени класса, по имени тега и общей картой для всего, что не вписывается в эти категории. Если селектор является идентификатором, правило будет добавлено к карте ID, если это класс, оно будет добавлено в карту класса и т. Д.
Это манипуляция значительно облегчает соответствие правилам. В каждом объявлении не нужно смотреть: мы можем извлечь соответствующие правила для элемента с карт. Эта оптимизация устраняет 95+% правил, так что они не должны даже рассматриваться в процессе сопоставления (4.1).
Давайте посмотрим, например, следующие правила стиля:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
Первое правило будет вставлено в карту класса. Второй в карту ID и третий в карту тегов.
Для следующего фрагмента HTML;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Сначала мы попытаемся найти правила для элемента P. Карта класса будет содержать ключ «ошибки», под которой находится правило для «P.Error». Элемент DIV будет иметь соответствующие правила на карте ID (ключ - ID) и карта тегов. Таким образом, единственная оставшаяся работа - выяснить, какое из правил, которые были извлечены ключи, действительно совпадает.
Например, если правило для Div было:
table div {margin: 5px}
Он по -прежнему будет извлечен из карты тегов, потому что ключ - самый правый селектор, но он не будет соответствовать нашему элементу DIV, у которого нет табличного предка.
И Webkit, и Firefox делают это манипуляции.
Каскадный заказ в стиле
Объект стиля обладает свойствами, соответствующими каждому визуальному атрибуту (все атрибуты CSS, но более общие). Если свойство не определено ни одним из соответствующих правил, то некоторые свойства могут быть унаследованы объектом стиля родительского элемента. Другие свойства имеют значения по умолчанию.
Проблема начинается, когда существует более одного определения - вот входит каскадный приказ, чтобы решить проблему.
Объявление о свойстве стиля может появиться в нескольких листах стиля, а несколько раз в листе стиля. Это означает, что порядок применения правил очень важен. Это называется «каскадным» порядком. Согласно спецификации CSS2, каскадный заказ (от низкого до высокого):
- Декларации браузера
- Обычные объявления пользователя
- Автор нормальные объявления
- Автор важных деклараций
- Пользовательские важные объявления
Объявления браузера наименее важны, и пользователь переопределяет автора только в том случае, если объявление было отмечено как важное. Объявления с тем же порядком будут отсортированы по специфичности , а затем указанный порядок. Визуальные атрибуты HTML переводятся на соответствующие объявления CSS. Они рассматриваются как правила автора с низким приоритетом.
Специфичность
Специфика селектора определяется спецификацией CSS2 следующим образом:
- Считайте 1, если объявление оно является атрибутом «стиля», а не правилом с селектором, 0 в противном случае (= a)
- Подсчитайте количество атрибутов идентификатора в селекторе (= B)
- Подсчитайте количество других атрибутов и псевдо-классов в селекторе (= C)
- Подсчитайте количество имен элементов и псевдо-элементов в селекторе (= D)
Соглашение четырех чисел ABCD (в численной системе с большой базой) дает специфичность.
Номерная база, которую вы должны использовать, определяется самым высоким количеством, которое у вас есть в одной из категорий.
Например, если a = 14 вы можете использовать шестнадцатеричную базу. В маловероятном случае, когда a = 17 вам понадобится база с 17 цифр. Более поздняя ситуация может произойти с таким селектором, как это: HTML Body Div P ... (17 метров в вашем селекторе ... маловероятно).
Несколько примеров:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Сортировка правил
После того, как правила соответствуют, они отсортированы в соответствии с каскадными правилами. Webkit использует Bubble Sort для небольших списков и сортировки слияния для больших. Webkit реализует сортировку, переопределив > оператора для правил:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Постепенный процесс
Webkit использует флаг, который отмечает, если были загружены все листы в стиле верхнего уровня (включая @imports). Если стиль не полностью загружен при прикреплении, используются держатели места, и он отмечается в документе, и они будут пересматриваться после загрузки листов стиля.
Макет
Когда визуализатор создается и добавляется к дереву, он не имеет позиции и размера. Расчет этих значений называется макетом или рефтовом.
HTML использует модель макета на основе потока, что означает, что большую часть времени можно вычислить геометрию за один проход. Позднее элементы «в потоке» обычно не влияют на геометрию элементов, которые ранее «в потоке», поэтому макет может пройтись слева направо, сверху вниз через документ. Существуют исключения: например, таблицы HTML могут потребовать более одного прохода.
Система координат относительно корневой кадры. Используются верхние и левые координаты.
Макет - это рекурсивный процесс. Он начинается с корневого рендеринга, который соответствует элементу <html> документа HTML. Макет продолжается рекурсивно через какую -то или всю иерархию кадров, вычисляя геометрическую информацию для каждого визуализатора, который требует этого.
Положение корневого рендеринга составляет 0,0, а его размеры - это видоупика - видимая часть окна браузера.
У всех визуализаторов есть метод «макета» или «рефтова», каждый визуализатор вызывает метод макета своих детей, которые нуждаются в макете.
Грязная бит -система
Чтобы не делать полную макет для каждого небольшого изменения, браузеры используют систему «грязного бита». Оран, который изменяется или добавлен сам и его детей как «грязный»: нуждается в макете.
Есть два флага: «грязные», а «дети грязные», что означает, что, хотя сам рендерер может быть в порядке, у него есть по крайней мере один ребенок, которому нужна макет.
Глобальный и постепенный макет
Макет может быть вызван во всем дерева рендеринга - это «глобальный» макет. Это может произойти в результате:
- Глобальное изменение в стиле, которое влияет на всех рендеристов, например, изменение размера шрифта.
- В результате изменения размера экрана
Макет может быть постепенным, будут выложены только грязные визуализаторы (это может нанести некоторый ущерб, который потребует дополнительных макетов).
Инкрементная компоновка запускается (асинхронно), когда визуализаторы грязные. Например, когда новые визуализаторы добавляются к дереву рендеринга после того, как дополнительный контент поступил из сети и был добавлен в дерево DOM.
Асинхронная и синхронная макет
Инкрементальный макет выполняется асинхронно. Очерки Firefox «Команды рефтова» для инкрементных макетов и планировщик запускают пакетное выполнение этих команд. У Webkit также есть таймер, который выполняет инкрементную макет - дерево пересекается, а «грязные» визуализаторы определяются.
Сценарии, запрашивающие информацию о стиле, такие как «Offsetheight», могут синхронизировать инкрементальный макет.
Глобальный макет обычно запускается синхронно.
Иногда макет запускается как обратный вызов после начального макета, потому что некоторые атрибуты, такие как положение прокрутки.
Оптимизации
Когда макет запускается «изменением размера» или изменением позиции рендеринга (а не размера), размеры рендеров взяты из кеша и не пересчитываются…
В некоторых случаях модифицируется только субполовое дерево, а макет не начинается с корня. Это может произойти в тех случаях, когда изменение является локальным и не влияет на его окружение - например, текст, вставленные в текстовые поля (в противном случае каждый клавиш будет вызывать макет, начиная с корня).
Процесс макета
Макет обычно имеет следующий шаблон:
- Родительский рендер определяет свою собственную ширину.
- Родитель рассказывает о детях и:
- Поместите дочерний визуализатор (устанавливает его x и y).
- При необходимости вызывает на вызов ребенка - они грязные или мы находимся в глобальной планировке или по какой -то другой причине - которая вычисляет высоту ребенка.
- Родитель использует накапливающие высоты детей и высоты краев и прокладки, чтобы установить свою собственную высоту - это будет использоваться родительским родителем.
- Устанавливает свой грязный бит на ложь.
Firefox использует объект «состояния» (nshtmlreflowstate) в качестве параметра для макета (называется «рефтоу»). Среди прочих государство включает в себя ширину родителей.
Выходной сигнал Firefox Mayout представляет собой объект «метрики» (nshtmlreflowmetrics). Он будет содержать рендеринг вычисленной высоты.
Расчет ширины
Ширина рендеринга рассчитывается с использованием ширины контейнеровочного блока, свойства стиля рендеринга «ширина», поля и границы.
Например, ширина следующего div:
<div style="width: 30%"/>
Будет рассчитываться Webkit как следующее (Class Renderbox Method Calcdath):
- Ширина контейнера - это максимум доступных контейнеров, и 0. Доступная Whidth в этом случае - это контент -прогиба, которая рассчитывается как:
clientWidth() - paddingLeft() - paddingRight()
Клиентская Whidth и ClientHeight представляют интерьер объекта, за исключением границы и прокрутки.
Ширина элементов - это атрибут стиля «ширины». Он будет рассчитывать как абсолютное значение путем вычисления процента ширины контейнера.
Горизонтальные границы и падения теперь добавлены.
До сих пор это был расчет «предпочтительной ширины». Теперь будет рассчитана минимальная и максимальная ширина.
Если предпочтительная ширина больше максимальной ширины, используется максимальная ширина. Если это меньше минимальной ширины (наименьшая нерушимая единица), то используется минимальная ширина.
Значения кэшируются в случае необходимости макета, но ширина не меняется.
Разрыв линии
Когда визуализатор в середине макета решает, что он должен сломаться, рендерер останавливает и распространяет родителя макета, что его нужно сломать. Родитель создает дополнительные визуализаторы и вызывает макет на них.
Рисование
На стадии рисования дерево рендеринга переселяется, а метод рендеринга «Paint ()» вызывается для отображения контента на экране. Живопись использует компонент инфраструктуры пользовательского интерфейса.
Глобальный и постепенный
Как и макет, живопись также может быть глобальной - все дерево окрашено - или постепенно. В постепенной живописи некоторые из рендеристов меняются таким образом, что не влияет на все дерево. Измененный рендерер недействительный свой прямоугольник на экране. Это заставляет ОС видеть ее как «грязную область» и генерирует событие «краски». ОС делает это умно и объединяет несколько регионов в одну. В Chrome это сложнее, потому что рендерер находится в другом процессе, чем в основном процессе. Chrome в некоторой степени имитирует поведение ОС. Презентация слушает эти события и делегирует сообщение в корне рендеринга. Дерево переселяется до тех пор, пока не будет достигнут соответствующий визуализатор. Он перекрасит себя (и обычно его детей).
Порядок картины
CSS2 определяет порядок процесса живописи . На самом деле это порядок, в котором элементы находятся в контексте укладки . Этот порядок влияет на живопись, так как стеки окрашены сзади на спереди. Порядок укладки блок -рендерера:
- цвет фона
- Фоновое изображение
- граница
- дети
- контур
Список дисплея Firefox
Firefox проходит через дерево рендеринга и строит список дисплеев для окрашенного прямоугольного. Он содержит визуализаторы, имеющие отношение к прямоугольному, в правильном порядке рисования (фоны рендеристов, затем граничат с т. Д.).
Таким образом, дерево нужно пройти только один раз для перекрашивания, а не несколько раз - рисовать все фоны, затем все изображения, затем все границы и т. Д.
Firefox оптимизирует процесс, не добавляя элементы, которые будут скрыты, как элементы, полностью под другими непрозрачными элементами.
Webkit прямоугольное хранилище
Перед перекрашением Webkit сохраняет старый прямоугольник как растровый карту. Затем он рисует только дельту между новыми и старыми прямоугольниками.
Динамические изменения
Браузеры пытаются выполнить минимальные возможные действия в ответ на изменение. Таким образом, изменения в цвете элемента вызовут только перекрашение элемента. Изменения в позиции элемента приведут к выводу макета и перекрашивания элемента, его детей и, возможно, братьев и сестер. Добавление узла DOM приведет к перекрашению макета и перекрашивания узла. Основные изменения, такие как увеличение размера шрифта элемента «HTML», приведут к недействительности кэша, реле и перекраске всего дерева.
Нити двигателя рендеринга
Двигатель рендеринга однооболочный. Почти все, кроме сетевых операций, происходит в одном потоке. В Firefox и Safari это главная нить браузера. В Chrome это основной поток процесса TAB.
Сетевые операции могут быть выполнены несколькими параллельными потоками. Количество параллельных соединений ограничено (обычно 2 - 6 соединений).
Петля мероприятия
Основная поток браузера - это цикл событий. Это бесконечный цикл, который поддерживает процесс. Он ждет событий (например, макет и краски) и обрабатывает их. Это код Firefox для основного цикла событий:
while (!mExiting)
NS_ProcessNextEvent(thread);
Визуальная модель CSS2
Холст
Согласно спецификации CSS2 , термин Canvas описывает «пространство, где визуализируется структура форматирования»: где браузер рисует содержание.
Холст бесконечен для каждого измерения пространства, но браузеры выбирают начальную ширину, основанную на размерах видового порта.
Согласно www.w3.org/tr/css2/zindex.html , холст является прозрачным, если он содержится в другом, и дается определенный браузер, определенный цвет, если это не так.
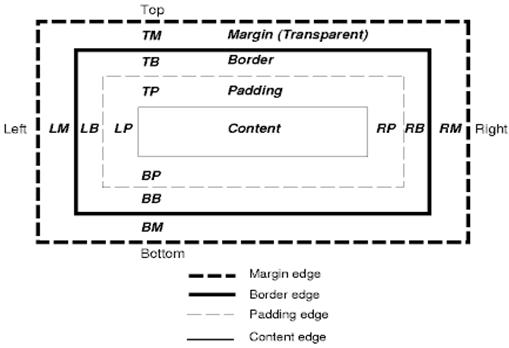
CSS Box Model
Модель коробки CSS описывает прямоугольные коробки, которые генерируются для элементов в дереве документов и выложены в соответствии с моделью визуального форматирования.
Каждая коробка имеет область содержания (например, текст, изображение и т. Д.) И дополнительные окружающие прокладки, границы и поля.
Каждый узел генерирует 0… N таких коробок.
Все элементы имеют свойство «отображения», которое определяет тип коробки, который будет сгенерирован.
Примеры:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
По умолчанию встроенный, но лист в стиле браузера может установить другие значения по умолчанию. Например: дисплей по умолчанию для элемента "div" - это блок.
Вы можете найти пример листа стиля по умолчанию здесь: www.w3.org/tr/css2/sample.html .
Схема позиционирования
Есть три схемы:
- Нормальный: объект расположен в соответствии с его местом в документе. Это означает, что его место в дереве рендеринга похоже на его место в дереве DOM и выложено в соответствии с типом и размерами коробки
- Float: объект сначала выложен как нормальный поток, затем перемещается как можно дальше влево или вправо, насколько это возможно
- Абсолют: объект помещается в дерево рендеринга в другом месте, чем в дереве DOM
Схема позиционирования устанавливается свойством «позиции» и атрибутом «float».
- статический и относительный вызван нормальный поток
- Абсолютное и фиксированное вызывает абсолютное позиционирование
В статическом позиционировании позиция не определено, и используется позиционирование по умолчанию. В других схемах автор указывает позицию: вверху, внизу, слева, справа.
То, как выложенная коробка, определяется:
- Тип коробки
- Размеры коробки
- Схема позиционирования
- Внешняя информация, такая как размер изображения и размер экрана
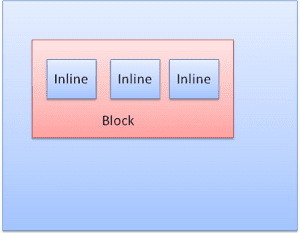
Типы коробок
Блок -коробка: образует блок - имеет свой собственный прямоугольник в окне браузера.

Встроенная коробка: не имеет своего собственного блока, но находится внутри блока.
Блоки отформатированы вертикально один за другой. Встроенные отформатированы горизонтально.
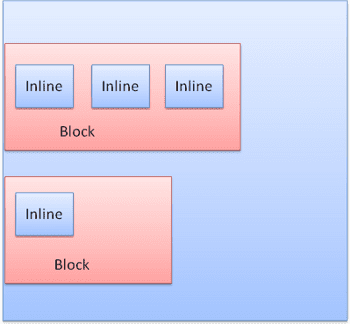
Встроенные ящики помещают внутри линии или «линейные коробки». Линии, по крайней мере, такие же высокие, как самая высокая коробка, но могут быть выше, когда коробки выровнены «базовый уровень», что означает, что нижняя часть элемента выровнена в точке другой коробки, кроме нижнего. Если ширины контейнера недостаточно, встроенные встроены на несколько строк. Обычно это то, что происходит в абзаце.
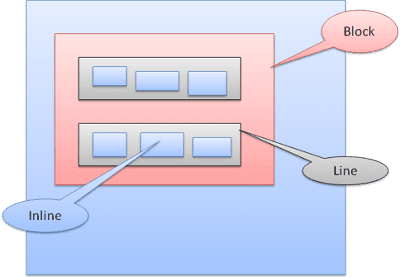
Позиционирование
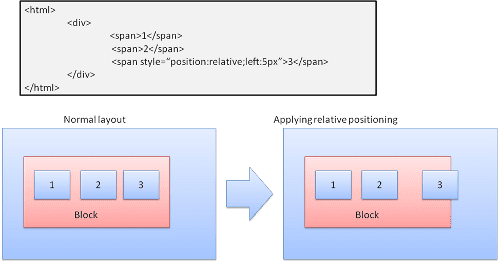
Родственник
Относительное позиционирование - расположено как обычно, а затем перемещено необходимой дельтой.
Поплавки
Ящик с поплавкой смещена влево или справа от линии. Интересная особенность заключается в том, что другие коробки текут вокруг него. HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Будет выглядеть как:

Абсолютный и фиксированный
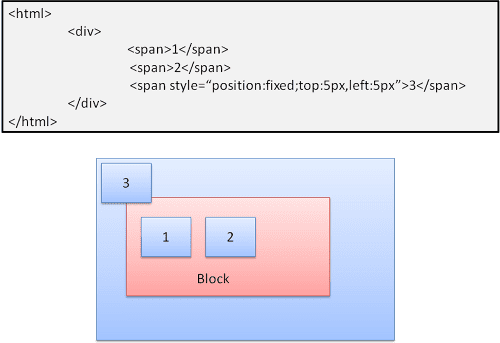
Макет определяется точно так же, независимо от нормального потока. Элемент не участвует в нормальном потоке. Размеры относительно контейнера. В фиксированном контейнере является товар для просмотра.
Многослойное представление
Это указывает свойство z-Index CSS. Он представляет третье измерение коробки: его положение вдоль «оси z».
Ящики разделены на стеки (называемые контекстами укладки). В каждом стеке обратные элементы будут нарисованы первыми, а прямые элементы сверху, ближе к пользователю. В случае перекрытия ведущий элемент будет скрывать прежний элемент.
Стеки заказаны в соответствии с свойством Z-Index. Ящики со свойством "z-Index" образуют локальный стек. В Viewport есть внешний стек.
Пример:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Результатом будет следующее:

Хотя Red Div предшествует зеленому в наценке и был бы нарисован ранее в обычном потоке, свойство Z-Index выше, поэтому оно более вперед в стеке, удерживаемой корневым ящиком.
Ресурсы
Архитектура браузера
- Гросскурт, Алан. Справочная архитектура для веб -браузеров (PDF)
- Гупта, Винет. Как работают браузеры - часть 1 - Архитектура
Разбор
- Aho, Sethi, Ullman, компиляторы: принципы, методы и инструменты (он же «Книга дракона»), Аддисон-Уэсли, 1986
- Рик Джеллифф. Смелые и красивые: два новых черновика для HTML 5.
Firefox
- Л. Дэвид Барон, более быстрые HTML и CSS: внутренние внутренние продукты для разработчиков.
- Л. Дэвид Барон, более быстрые HTML и CSS: внутренние внутренние продукты для разработчиков веб -разработчиков (видео Google Tech Talk Video)
- Л. Дэвид Барон, двигатель макета Mozilla
- Л. Дэвид Барон, Документация системы в стиле Mozilla
- Крис Уотерсон, Заметки на HTML -реасы
- Крис Уотерсон, обзор геккона
- Александр Ларссон, Жизнь HTML HTTP -запроса
Webkit
- Дэвид Хаятт, реализация CSS (часть 1)
- Дэвид Хаятт, обзор веб -корра
- Дэвид Хаятт, рендеринг веб -корра
- Дэвид Хаятт, проблема FOUC
Спецификации W3C
Браузеры строят инструкции
Переводы
Эта страница была переведена на японский, дважды:
- Как работают браузеры - за кулисами современных веб -браузеров (JA) @ Kosei
- ブラウザってどうやって動いてるの? (モダン ブラウザシーンの裏側 ブラウザシーンの裏側 by @ikike443 и @kiyoto01.
Вы можете просмотреть внешние переводы корейского и турецкого .
Спасибо всем!
,За кулисами современных веб -браузеров
Предисловие
Этот комплексный учебник по внутренним операциям Webkit и Gecko является результатом многих исследований, проведенных израильским разработчиком Тали Гарсиэлем. В течение нескольких лет она рассмотрела все опубликованные данные о внутренних интернатах браузера и потратила много времени на чтение исходного кода веб -браузера. Она написала:
Как веб -разработчик, изучение внутренних пунктов операций браузера помогает вам принимать лучшие решения и узнать о себе, лежащих в основе лучших практик развития . While this is a rather lengthy document, we recommend you spend some time digging in. You'll be glad you did.
Paul Irish, Chrome Developer Relations
Введение
Web browsers are the most widely used software. In this primer, I explain how they work behind the scenes. We will see what happens when you type google.com in the address bar until you see the Google page on the browser screen.
Browsers we'll talk about
There are five major browsers used on desktop today: Chrome, Internet Explorer, Firefox, Safari and Opera. On mobile, the main browsers are Android Browser, iPhone, Opera Mini and Opera Mobile, UC Browser, the Nokia S40/S60 browsers and Chrome, all of which, except for the Opera browsers, are based on WebKit. I will give examples from the open source browsers Firefox and Chrome, and Safari (which is partly open source). According to StatCounter statistics (as of June 2013) Chrome, Firefox and Safari make up around 71% of global desktop browser usage. On mobile, Android Browser, iPhone and Chrome constitute around 54% of usage.
The browser's main functionality
The main function of a browser is to present the web resource you choose, by requesting it from the server and displaying it in the browser window. The resource is usually an HTML document, but may also be a PDF, image, or some other type of content. The location of the resource is specified by the user using a URI (Uniform Resource Identifier).
The way the browser interprets and displays HTML files is specified in the HTML and CSS specifications. These specifications are maintained by the W3C (World Wide Web Consortium) organization, which is the standards organization for the web. For years browsers conformed to only a part of the specifications and developed their own extensions. That caused serious compatibility issues for web authors. Today most of the browsers more or less conform to the specifications.
Browser user interfaces have a lot in common with each other. Among the common user interface elements are:
- Address bar for inserting a URI
- Back and forward buttons
- Bookmarking options
- Refresh and stop buttons for refreshing or stopping the loading of current documents
- Home button that takes you to your home page
Strangely enough, the browser's user interface is not specified in any formal specification, it just comes from good practices shaped over years of experience and by browsers imitating each other. The HTML5 specification doesn't define UI elements a browser must have, but lists some common elements. Among those are the address bar, status bar and tool bar. There are, of course, features unique to a specific browser like Firefox's downloads manager.
High-level infrastructure
The browser's main components are:
- The user interface : this includes the address bar, back/forward button, bookmarking menu, etc. Every part of the browser display except the window where you see the requested page.
- The browser engine : marshals actions between the UI and the rendering engine.
- The rendering engine : responsible for displaying requested content. For example if the requested content is HTML, the rendering engine parses HTML and CSS, and displays the parsed content on the screen.
- Networking : for network calls such as HTTP requests, using different implementations for different platform behind a platform-independent interface.
- UI backend : used for drawing basic widgets like combo boxes and windows. This backend exposes a generic interface that is not platform specific. Underneath it uses operating system user interface methods.
- JavaScript interpreter . Used to parse and execute JavaScript code.
- Data storage . This is a persistence layer. The browser may need to save all sorts of data locally, such as cookies. Browsers also support storage mechanisms such as localStorage, IndexedDB, WebSQL and FileSystem.
It is important to note that browsers such as Chrome run multiple instances of the rendering engine: one for each tab. Each tab runs in a separate process.
Rendering engines
The responsibility of the rendering engine is well… Rendering, that is display of the requested contents on the browser screen.
By default the rendering engine can display HTML and XML documents and images. It can display other types of data via plug-ins or extension; for example, displaying PDF documents using a PDF viewer plug-in. However, in this chapter we will focus on the main use case: displaying HTML and images that are formatted using CSS.
Different browsers use different rendering engines: Internet Explorer uses Trident, Firefox uses Gecko, Safari uses WebKit. Chrome and Opera (from version 15) use Blink, a fork of WebKit.
WebKit is an open source rendering engine which started as an engine for the Linux platform and was modified by Apple to support Mac and Windows.
The main flow
The rendering engine will start getting the contents of the requested document from the networking layer. This will usually be done in 8kB chunks.
After that, this is the basic flow of the rendering engine:
The rendering engine will start parsing the HTML document and convert elements to DOM nodes in a tree called the "content tree". The engine will parse the style data, both in external CSS files and in style elements. Styling information together with visual instructions in the HTML will be used to create another tree: the render tree .
The render tree contains rectangles with visual attributes like color and dimensions. The rectangles are in the right order to be displayed on the screen.
After the construction of the render tree it goes through a " layout " process. This means giving each node the exact coordinates where it should appear on the screen. The next stage is painting - the render tree will be traversed and each node will be painted using the UI backend layer.
It's important to understand that this is a gradual process. For better user experience, the rendering engine will try to display contents on the screen as soon as possible. It won't wait until all HTML is parsed before starting to build and layout the render tree. Parts of the content will be parsed and displayed, while the process continues with the rest of the contents that keeps coming from the network.
Main flow examples
From figures 3 and 4 you can see that although WebKit and Gecko use slightly different terminology, the flow is basically the same.
Gecko calls the tree of visually formatted elements a "Frame tree". Each element is a frame. WebKit uses the term "Render Tree" and it consists of "Render Objects". WebKit uses the term "layout" for the placing of elements, while Gecko calls it "Reflow". "Attachment" is WebKit's term for connecting DOM nodes and visual information to create the render tree. A minor non-semantic difference is that Gecko has an extra layer between the HTML and the DOM tree. It is called the "content sink" and is a factory for making DOM elements. We will talk about each part of the flow:
Parsing - general
Since parsing is a very significant process within the rendering engine, we will go into it a little more deeply. Let's begin with a little introduction about parsing.
Parsing a document means translating it to a structure the code can use. The result of parsing is usually a tree of nodes that represent the structure of the document. This is called a parse tree or a syntax tree.
For example, parsing the expression 2 + 3 - 1 could return this tree:
Грамматика
Parsing is based on the syntax rules the document obeys: the language or format it was written in. Every format you can parse must have deterministic grammar consisting of vocabulary and syntax rules. It is called a context free grammar . Human languages are not such languages and therefore cannot be parsed with conventional parsing techniques.
Parser - Lexer combination
Parsing can be separated into two sub processes: lexical analysis and syntax analysis.
Lexical analysis is the process of breaking the input into tokens. Tokens are the language vocabulary: the collection of valid building blocks. In human language it will consist of all the words that appear in the dictionary for that language.
Syntax analysis is the applying of the language syntax rules.
Parsers usually divide the work between two components: the lexer (sometimes called tokenizer) that is responsible for breaking the input into valid tokens, and the parser that is responsible for constructing the parse tree by analyzing the document structure according to the language syntax rules.
The lexer knows how to strip irrelevant characters like white spaces and line breaks.
The parsing process is iterative. The parser will usually ask the lexer for a new token and try to match the token with one of the syntax rules. If a rule is matched, a node corresponding to the token will be added to the parse tree and the parser will ask for another token.
If no rule matches, the parser will store the token internally, and keep asking for tokens until a rule matching all the internally stored tokens is found. If no rule is found then the parser will raise an exception. This means the document was not valid and contained syntax errors.
Перевод
In many cases the parse tree is not the final product. Parsing is often used in translation: transforming the input document to another format. An example is compilation. The compiler that compiles source code into machine code first parses it into a parse tree and then translates the tree into a machine code document.
Parsing example
In figure 5 we built a parse tree from a mathematical expression. Let's try to define a simple mathematical language and see the parse process.
Синтаксис:
- The language syntax building blocks are expressions, terms and operations.
- Our language can include any number of expressions.
- An expression is defined as a "term" followed by an "operation" followed by another term
- An operation is a plus token or a minus token
- A term is an integer token or an expression
Let's analyze the input 2 + 3 - 1 .
The first substring that matches a rule is 2 : according to rule #5 it is a term. The second match is 2 + 3 : this matches the third rule: a term followed by an operation followed by another term. The next match will only be hit at the end of the input. 2 + 3 - 1 is an expression because we already know that 2 + 3 is a term, so we have a term followed by an operation followed by another term. 2 + + won't match any rule and therefore is an invalid input.
Formal definitions for vocabulary and syntax
Vocabulary is usually expressed by regular expressions .
For example our language will be defined as:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
As you see, integers are defined by a regular expression.
Syntax is usually defined in a format called BNF . Our language will be defined as:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
We said that a language can be parsed by regular parsers if its grammar is a context free grammar. An intuitive definition of a context free grammar is a grammar that can be entirely expressed in BNF. For a formal definition see Wikipedia's article on Context-free grammar
Types of parsers
There are two types of parsers: top down parsers and bottom up parsers. An intuitive explanation is that top down parsers examine the high level structure of the syntax and try to find a rule match. Bottom up parsers start with the input and gradually transform it into the syntax rules, starting from the low level rules until high level rules are met.
Let's see how the two types of parsers will parse our example.
The top down parser will start from the higher level rule: it will identify 2 + 3 as an expression. It will then identify 2 + 3 - 1 as an expression (the process of identifying the expression evolves, matching the other rules, but the start point is the highest level rule).
The bottom up parser will scan the input until a rule is matched. It will then replace the matching input with the rule. This will go on until the end of the input. The partly matched expression is placed on the parser's stack.
This type of bottom up parser is called a shift-reduce parser, because the input is shifted to the right (imagine a pointer pointing first at the input start and moving to the right) and is gradually reduced to syntax rules.
Generating parsers automatically
There are tools that can generate a parser. You feed them the grammar of your language - its vocabulary and syntax rules - and they generate a working parser. Creating a parser requires a deep understanding of parsing and it's not easy to create an optimized parser by hand, so parser generators can be very useful.
WebKit uses two well known parser generators: Flex for creating a lexer and Bison for creating a parser (you might run into them with the names Lex and Yacc). Flex input is a file containing regular expression definitions of the tokens. Bison's input is the language syntax rules in BNF format.
HTML Parser
The job of the HTML parser is to parse the HTML markup into a parse tree.
HTML grammar
The vocabulary and syntax of HTML are defined in specifications created by the W3C organization.
As we have seen in the parsing introduction, grammar syntax can be defined formally using formats like BNF.
Unfortunately all the conventional parser topics don't apply to HTML (I didn't bring them up just for fun - they will be used in parsing CSS and JavaScript). HTML cannot easily be defined by a context free grammar that parsers need.
There is a formal format for defining HTML - DTD (Document Type Definition) - but it is not a context free grammar.
This appears strange at first sight; HTML is rather close to XML. There are lots of available XML parsers. There is an XML variation of HTML - XHTML - so what's the big difference?
The difference is that the HTML approach is more "forgiving": it lets you omit certain tags (which are then added implicitly), or sometimes omit start or end tags, and so on. On the whole it's a "soft" syntax, as opposed to XML's stiff and demanding syntax.
This seemingly small detail makes a world of a difference. On one hand this is the main reason why HTML is so popular: it forgives your mistakes and makes life easy for the web author. On the other hand, it makes it difficult to write a formal grammar. So to summarize, HTML cannot be parsed easily by conventional parsers, since its grammar is not context free. HTML cannot be parsed by XML parsers.
HTML DTD
HTML definition is in a DTD format. This format is used to define languages of the SGML family. The format contains definitions for all allowed elements, their attributes and hierarchy. As we saw earlier, the HTML DTD doesn't form a context free grammar.
There are a few variations of the DTD. The strict mode conforms solely to the specifications but other modes contain support for markup used by browsers in the past. The purpose is backwards compatibility with older content. The current strict DTD is here: www.w3.org/TR/html4/strict.dtd
ДОМ
The output tree (the "parse tree") is a tree of DOM element and attribute nodes. DOM is short for Document Object Model. It is the object presentation of the HTML document and the interface of HTML elements to the outside world like JavaScript.
The root of the tree is the " Document " object.
The DOM has an almost one-to-one relation to the markup. Например:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
This markup would be translated to the following DOM tree:
Like HTML, DOM is specified by the W3C organization. See www.w3.org/DOM/DOMTR . It is a generic specification for manipulating documents. A specific module describes HTML specific elements. The HTML definitions can be found here: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html .
When I say the tree contains DOM nodes, I mean the tree is constructed of elements that implement one of the DOM interfaces. Browsers use concrete implementations that have other attributes used by the browser internally.
The parsing algorithm
As we saw in the previous sections, HTML cannot be parsed using the regular top down or bottom up parsers.
The reasons are:
- The forgiving nature of the language.
- The fact that browsers have traditional error tolerance to support well known cases of invalid HTML.
- The parsing process is reentrant. For other languages, the source doesn't change during parsing, but in HTML, dynamic code (such as script elements containing
document.write()calls) can add extra tokens, so the parsing process actually modifies the input.
Unable to use the regular parsing techniques, browsers create custom parsers for parsing HTML.
The parsing algorithm is described in detail by the HTML5 specification . The algorithm consists of two stages: tokenization and tree construction.
Tokenization is the lexical analysis, parsing the input into tokens. Among HTML tokens are start tags, end tags, attribute names and attribute values.
The tokenizer recognizes the token, gives it to the tree constructor, and consumes the next character for recognizing the next token, and so on until the end of the input.
The tokenization algorithm
The algorithm's output is an HTML token. The algorithm is expressed as a state machine. Each state consumes one or more characters of the input stream and updates the next state according to those characters. The decision is influenced by the current tokenization state and by the tree construction state. This means the same consumed character will yield different results for the correct next state, depending on the current state. The algorithm is too complex to describe fully, so let's see a simple example that will help us understand the principle.
Basic example - tokenizing the following HTML:
<html>
<body>
Hello world
</body>
</html>
The initial state is the "Data state". When the < character is encountered, the state is changed to "Tag open state" . Consuming an az character causes creation of a "Start tag token", the state is changed to "Tag name state" . We stay in this state until the > character is consumed. Each character is appended to the new token name. In our case the created token is an html token.
When the > tag is reached, the current token is emitted and the state changes back to the "Data state" . The <body> tag will be treated by the same steps. So far the html and body tags were emitted. We are now back at the "Data state" . Consuming the H character of Hello world will cause creation and emitting of a character token, this goes on until the < of </body> is reached. We will emit a character token for each character of Hello world .
We are now back at the "Tag open state" . Consuming the next input / will cause creation of an end tag token and a move to the "Tag name state" . Again we stay in this state until we reach > .Then the new tag token will be emitted and we go back to the "Data state" . The </html> input will be treated like the previous case.
Tree construction algorithm
When the parser is created the Document object is created. During the tree construction stage the DOM tree with the Document in its root will be modified and elements will be added to it. Each node emitted by the tokenizer will be processed by the tree constructor. For each token the specification defines which DOM element is relevant to it and will be created for this token. The element is added to the DOM tree, and also the stack of open elements. This stack is used to correct nesting mismatches and unclosed tags. The algorithm is also described as a state machine. The states are called "insertion modes".
Let's see the tree construction process for the example input:
<html>
<body>
Hello world
</body>
</html>
The input to the tree construction stage is a sequence of tokens from the tokenization stage. The first mode is the "initial mode" . Receiving the "html" token will cause a move to the "before html" mode and a reprocessing of the token in that mode. This will cause creation of the HTMLHtmlElement element, which will be appended to the root Document object.
The state will be changed to "before head" . The "body" token is then received. An HTMLHeadElement will be created implicitly although we don't have a "head" token and it will be added to the tree.
We now move to the "in head" mode and then to "after head" . The body token is reprocessed, an HTMLBodyElement is created and inserted and the mode is transferred to "in body" .
The character tokens of the "Hello world" string are now received. The first one will cause creation and insertion of a "Text" node and the other characters will be appended to that node.
The receiving of the body end token will cause a transfer to "after body" mode. We will now receive the html end tag which will move us to "after after body" mode. Receiving the end of file token will end the parsing.
Actions when the parsing is finished
At this stage the browser will mark the document as interactive and start parsing scripts that are in "deferred" mode: those that should be executed after the document is parsed. The document state will be then set to "complete" and a "load" event will be fired.
You can see the full algorithms for tokenization and tree construction in the HTML5 specification .
Browsers' error tolerance
You never get an "Invalid Syntax" error on an HTML page. Browsers fix any invalid content and go on.
Take this HTML for example:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
I must have violated about a million rules ("mytag" is not a standard tag, wrong nesting of the "p" and "div" elements and more) but the browser still shows it correctly and doesn't complain. So a lot of the parser code is fixing the HTML author mistakes.
Error handling is quite consistent in browsers, but amazingly enough it hasn't been part of HTML specifications. Like bookmarking and back/forward buttons it's just something that developed in browsers over the years. There are known invalid HTML constructs repeated on many sites, and the browsers try to fix them in a way conformant with other browsers.
The HTML5 specification does define some of these requirements. (WebKit summarizes this nicely in the comment at the beginning of the HTML parser class.)
The parser parses tokenized input into the document, building up the document tree. If the document is well-formed, parsing it is straightforward.
Unfortunately, we have to handle many HTML documents that are not well-formed, so the parser has to be tolerant about errors.
We have to take care of at least the following error conditions:
- The element being added is explicitly forbidden inside some outer tag. In this case we should close all tags up to the one which forbids the element, and add it afterwards.
- We are not allowed to add the element directly. It could be that the person writing the document forgot some tag in between (or that the tag in between is optional). This could be the case with the following tags: HTML HEAD BODY TBODY TR TD LI (did I forget any?).
- We want to add a block element inside an inline element. Close all inline elements up to the next higher block element.
- If this doesn't help, close elements until we are allowed to add the element - or ignore the tag.
Let's see some WebKit error tolerance examples:
</br> instead of <br>
Some sites use </br> instead of <br> . In order to be compatible with IE and Firefox, WebKit treats this like <br> .
Код:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Note that the error handling is internal: it won't be presented to the user.
A stray table
A stray table is a table inside another table, but not inside a table cell.
Например:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit will change the hierarchy to two sibling tables:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Код:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit uses a stack for the current element contents: it will pop the inner table out of the outer table stack. The tables will now be siblings.
Nested form elements
In case the user puts a form inside another form, the second form is ignored.
Код:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
A too deep tag hierarchy
The comment speaks for itself.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Misplaced html or body end tags
Again - the comment speaks for itself.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
So web authors beware - unless you want to appear as an example in a WebKit error tolerance code snippet - write well formed HTML.
CSS parsing
Remember the parsing concepts in the introduction? Well, unlike HTML, CSS is a context free grammar and can be parsed using the types of parsers described in the introduction. In fact the CSS specification defines CSS lexical and syntax grammar .
Let's see some examples:
The lexical grammar (vocabulary) is defined by regular expressions for each token:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" is short for identifier, like a class name. "name" is an element id (that is referred by "#" )
The syntax grammar is described in BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Объяснение:
A ruleset is this structure:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error and a.error are selectors. The part inside the curly braces contains the rules that are applied by this ruleset. This structure is defined formally in this definition:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
This means a ruleset is a selector or optionally a number of selectors separated by a comma and spaces (S stands for white space). A ruleset contains curly braces and inside them a declaration or optionally a number of declarations separated by a semicolon. "declaration" and "selector" will be defined in the following BNF definitions.
WebKit CSS parser
WebKit uses Flex and Bison parser generators to create parsers automatically from the CSS grammar files. As you recall from the parser introduction, Bison creates a bottom up shift-reduce parser. Firefox uses a top down parser written manually. In both cases each CSS file is parsed into a StyleSheet object. Each object contains CSS rules. The CSS rule objects contain selector and declaration objects and other objects corresponding to CSS grammar.
Processing order for scripts and style sheets
Scripts
The model of the web is synchronous. Authors expect scripts to be parsed and executed immediately when the parser reaches a <script> tag. The parsing of the document halts until the script has been executed. If the script is external then the resource must first be fetched from the network - this is also done synchronously, and parsing halts until the resource is fetched. This was the model for many years and is also specified in HTML4 and 5 specifications. Authors can add the "defer" attribute to a script, in which case it won't halt document parsing and will execute after the document is parsed. HTML5 adds an option to mark the script as asynchronous so it will be parsed and executed by a different thread.
Speculative parsing
Both WebKit and Firefox do this optimization. While executing scripts, another thread parses the rest of the document and finds out what other resources need to be loaded from the network and loads them. In this way, resources can be loaded on parallel connections and overall speed is improved. Note: the speculative parser only parses references to external resources like external scripts, style sheets and images: it doesn't modify the DOM tree - that is left to the main parser.
Style sheets
Style sheets on the other hand have a different model. Conceptually it seems that since style sheets don't change the DOM tree, there is no reason to wait for them and stop the document parsing. There is an issue, though, of scripts asking for style information during the document parsing stage. If the style is not loaded and parsed yet, the script will get wrong answers and apparently this caused lots of problems. It seems to be an edge case but is quite common. Firefox blocks all scripts when there is a style sheet that is still being loaded and parsed. WebKit blocks scripts only when they try to access certain style properties that may be affected by unloaded style sheets.
Render tree construction
While the DOM tree is being constructed, the browser constructs another tree, the render tree. This tree is of visual elements in the order in which they will be displayed. It is the visual representation of the document. The purpose of this tree is to enable painting the contents in their correct order.
Firefox calls the elements in the render tree "frames". WebKit uses the term renderer or render object.
A renderer knows how to lay out and paint itself and its children.
WebKit's RenderObject class, the base class of the renderers, has the following definition:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Each renderer represents a rectangular area usually corresponding to a node's CSS box, as described by the CSS2 spec. It includes geometric information like width, height and position.
The box type is affected by the "display" value of the style attribute that is relevant to the node (see the style computation section). Here is WebKit code for deciding what type of renderer should be created for a DOM node, according to the display attribute:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
The element type is also considered: for example, form controls and tables have special frames.
In WebKit if an element wants to create a special renderer, it will override the createRenderer() method. The renderers point to style objects that contains non geometric information.
The render tree relation to the DOM tree
The renderers correspond to DOM elements, but the relation is not one to one. Non-visual DOM elements won't be inserted in the render tree. An example is the "head" element. Also elements whose display value was assigned to "none" won't appear in the tree (whereas elements with "hidden" visibility will appear in the tree).
There are DOM elements which correspond to several visual objects. These are usually elements with complex structure that cannot be described by a single rectangle. For example, the "select" element has three renderers: one for the display area, one for the drop down list box and one for the button. Also when text is broken into multiple lines because the width is not sufficient for one line, the new lines will be added as extra renderers.
Another example of multiple renderers is broken HTML. According to the CSS spec an inline element must contain either only block elements or only inline elements. In the case of mixed content, anonymous block renderers will be created to wrap the inline elements.
Some render objects correspond to a DOM node but not in the same place in the tree. Floats and absolutely positioned elements are out of flow, placed in a different part of the tree, and mapped to the real frame. A placeholder frame is where they should have been.
The flow of constructing the tree
In Firefox, the presentation is registered as a listener for DOM updates. The presentation delegates frame creation to the FrameConstructor and the constructor resolves style (see style computation ) and creates a frame.
In WebKit the process of resolving the style and creating a renderer is called "attachment". Every DOM node has an "attach" method. Attachment is synchronous, node insertion to the DOM tree calls the new node "attach" method.
Processing the html and body tags results in the construction of the render tree root. The root render object corresponds to what the CSS spec calls the containing block: the top most block that contains all other blocks. Its dimensions are the viewport: the browser window display area dimensions. Firefox calls it ViewPortFrame and WebKit calls it RenderView . This is the render object that the document points to. The rest of the tree is constructed as a DOM nodes insertion.
See the CSS2 spec on the processing model .
Style computation
Building the render tree requires calculating the visual properties of each render object. This is done by calculating the style properties of each element.
The style includes style sheets of various origins, inline style elements and visual properties in the HTML (like the "bgcolor" property).The later is translated to matching CSS style properties.
The origins of style sheets are the browser's default style sheets, the style sheets provided by the page author and user style sheets - these are style sheets provided by the browser user (browsers let you define your favorite styles. In Firefox, for instance, this is done by placing a style sheet in the "Firefox Profile" folder).
Style computation brings up a few difficulties:
- Style data is a very large construct, holding the numerous style properties, this can cause memory problems.
Finding the matching rules for each element can cause performance issues if it's not optimized. Traversing the entire rule list for each element to find matches is a heavy task. Selectors can have complex structure that can cause the matching process to start on a seemingly promising path that is proven to be futile and another path has to be tried.
For example - this compound selector:
div div div div{ ... }Means the rules apply to a
<div>who is the descendant of 3 divs. Suppose you want to check if the rule applies for a given<div>element. You choose a certain path up the tree for checking. You may need to traverse the node tree up just to find out there are only two divs and the rule does not apply. You then need to try other paths in the tree.Applying the rules involves quite complex cascade rules that define the hierarchy of the rules.
Let's see how the browsers face these issues:
Sharing style data
WebKit nodes references style objects (RenderStyle). These objects can be shared by nodes in some conditions. The nodes are siblings or cousins and:
- The elements must be in the same mouse state (eg, one can't be in :hover while the other isn't)
- Neither element should have an id
- The tag names should match
- The class attributes should match
- The set of mapped attributes must be identical
- The link states must match
- The focus states must match
- Neither element should be affected by attribute selectors, where affected is defined as having any selector match that uses an attribute selector in any position within the selector at all
- There must be no inline style attribute on the elements
- There must be no sibling selectors in use at all. WebCore simply throws a global switch when any sibling selector is encountered and disables style sharing for the entire document when they are present. This includes the + selector and selectors like :first-child and :last-child.
Firefox rule tree
Firefox has two extra trees for easier style computation: the rule tree and style context tree. WebKit also has style objects but they are not stored in a tree like the style context tree, only the DOM node points to its relevant style.
The style contexts contain end values. The values are computed by applying all the matching rules in the correct order and performing manipulations that transform them from logical to concrete values. For example, if the logical value is a percentage of the screen it will be calculated and transformed to absolute units. The rule tree idea is really clever. It enables sharing these values between nodes to avoid computing them again. This also saves space.
All the matched rules are stored in a tree. The bottom nodes in a path have higher priority. The tree contains all the paths for rule matches that were found. Storing the rules is done lazily. The tree isn't calculated at the beginning for every node, but whenever a node style needs to be computed the computed paths are added to the tree.
The idea is to see the tree paths as words in a lexicon. Lets say we already computed this rule tree:
Suppose we need to match rules for another element in the content tree, and find out the matched rules (in the correct order) are BEI. We already have this path in the tree because we already computed path ABEIL. We will now have less work to do.
Let's see how the tree saves us work.
Division into structs
The style contexts are divided into structs. Those structs contain style information for a certain category like border or color. All the properties in a struct are either inherited or non inherited. Inherited properties are properties that unless defined by the element, are inherited from its parent. Non inherited properties (called "reset" properties) use default values if not defined.
The tree helps us by caching entire structs (containing the computed end values) in the tree. The idea is that if the bottom node didn't supply a definition for a struct, a cached struct in an upper node can be used.
Computing the style contexts using the rule tree
When computing the style context for a certain element, we first compute a path in the rule tree or use an existing one. We then begin to apply the rules in the path to fill the structs in our new style context. We start at the bottom node of the path - the one with the highest precedence (usually the most specific selector) and traverse the tree up until our struct is full. If there is no specification for the struct in that rule node, then we can greatly optimize - we go up the tree until we find a node that specifies it fully and point to it - that's the best optimization - the entire struct is shared. This saves computation of end values and memory.
If we find partial definitions we go up the tree until the struct is filled.
If we didn't find any definitions for our struct then, in case the struct is an "inherited" type, we point to the struct of our parent in the context tree . In this case we also succeeded in sharing structs. If it's a reset struct then default values will be used.
If the most specific node does add values then we need to do some extra calculations for transforming it to actual values. We then cache the result in the tree node so it can be used by children.
In case an element has a sibling or a brother that points to the same tree node then the entire style context can be shared between them.
Lets see an example: Suppose we have this HTML
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
And the following rules:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
To simplify things let's say we need to fill out only two structs: the color struct and the margin struct. The color struct contains only one member: the color The margin struct contains the four sides.
The resulting rule tree will look like this (the nodes are marked with the node name: the number of the rule they point at):
The context tree will look like this (node name: rule node they point to):
Suppose we parse the HTML and get to the second <div> tag. We need to create a style context for this node and fill its style structs.
We will match the rules and discover that the matching rules for the <div> are 1, 2 and 6. This means there is already an existing path in the tree that our element can use and we just need to add another node to it for rule 6 (node F in the rule tree).
We will create a style context and put it in the context tree. The new style context will point to node F in the rule tree.
We now need to fill the style structs. We will begin by filling out the margin struct. Since the last rule node (F) doesn't add to the margin struct, we can go up the tree until we find a cached struct computed in a previous node insertion and use it. We will find it on node B, which is the uppermost node that specified margin rules.
We do have a definition for the color struct, so we can't use a cached struct. Since color has one attribute we don't need to go up the tree to fill other attributes. We will compute the end value (convert string to RGB etc) and cache the computed struct on this node.
The work on the second <span> element is even easier. We will match the rules and come to the conclusion that it points to rule G, like the previous span. Since we have siblings that point to the same node, we can share the entire style context and just point to the context of the previous span.
For structs that contain rules that are inherited from the parent, caching is done on the context tree (the color property is actually inherited, but Firefox treats it as reset and caches it on the rule tree).
For example, if we added rules for fonts in a paragraph:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Then the paragraph element, which is a child of the div in the context tree, could have shared the same font struct as his parent. This is if no font rules were specified for the paragraph.
In WebKit, who does not have a rule tree, the matched declarations are traversed four times. First non-important high priority properties are applied (properties that should be applied first because others depend on them, such as display), then high priority important, then normal priority non-important, then normal priority important rules. This means that properties that appear multiple times will be resolved according to the correct cascade order. The last wins.
So to summarize: sharing the style objects (entirely or some of the structs inside them) solves issues 1 and 3. The Firefox rule tree also helps in applying the properties in the correct order.
Manipulating the rules for an easy match
There are several sources for style rules:
- CSS rules, either in external style sheets or in style elements.
css p {color: blue} - Inline style attributes like
html <p style="color: blue" /> - HTML visual attributes (which are mapped to relevant style rules)
html <p bgcolor="blue" />The last two are easily matched to the element since he owns the style attributes and HTML attributes can be mapped using the element as the key.
As noted previously in issue #2, the CSS rule matching can be trickier. To solve the difficulty, the rules are manipulated for easier access.
After parsing the style sheet, the rules are added to one of several hash maps, according to the selector. There are maps by id, by class name, by tag name and a general map for anything that doesn't fit into those categories. If the selector is an id, the rule will be added to the id map, if it's a class it will be added to the class map etc.
This manipulation makes it much easier to match rules. There is no need to look in every declaration: we can extract the relevant rules for an element from the maps. This optimization eliminates 95+% of the rules, so that they need not even be considered during the matching process(4.1).
Let's see for example the following style rules:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
The first rule will be inserted into the class map. The second into the id map and the third into the tag map.
For the following HTML fragment;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
We will first try to find rules for the p element. The class map will contain an "error" key under which the rule for "p.error" is found. The div element will have relevant rules in the id map (the key is the id) and the tag map. So the only work left is finding out which of the rules that were extracted by the keys really match.
For example if the rule for the div was:
table div {margin: 5px}
It will still be extracted from the tag map, because the key is the rightmost selector, but it wouldn't match our div element, who does not have a table ancestor.
Both WebKit and Firefox do this manipulation.
Style sheet cascade order
The style object has properties corresponding to every visual attribute (all CSS attributes but more generic). If the property is not defined by any of the matched rules, then some properties can be inherited by the parent element style object. Other properties have default values.
The problem begins when there is more than one definition - here comes the cascade order to solve the issue.
A declaration for a style property can appear in several style sheets, and several times inside a style sheet. This means the order of applying the rules is very important. This is called the "cascade" order. According to CSS2 spec, the cascade order is (from low to high):
- Browser declarations
- User normal declarations
- Author normal declarations
- Author important declarations
- User important declarations
The browser declarations are least important and the user overrides the author only if the declaration was marked as important. Declarations with the same order will be sorted by specificity and then the order they are specified. The HTML visual attributes are translated to matching CSS declarations . They are treated as author rules with low priority.
Specificity
The selector specificity is defined by the CSS2 specification as follows:
- count 1 if the declaration it is from is a 'style' attribute rather than a rule with a selector, 0 otherwise (= a)
- count the number of ID attributes in the selector (= b)
- count the number of other attributes and pseudo-classes in the selector (= c)
- count the number of element names and pseudo-elements in the selector (= d)
Concatenating the four numbers abcd (in a number system with a large base) gives the specificity.
The number base you need to use is defined by the highest count you have in one of the categories.
For example, if a=14 you can use hexadecimal base. In the unlikely case where a=17 you will need a 17 digits number base. The later situation can happen with a selector like this: html body div div p… (17 tags in your selector… not very likely).
Несколько примеров:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Sorting the rules
After the rules are matched, they are sorted according to the cascade rules. WebKit uses bubble sort for small lists and merge sort for big ones. WebKit implements sorting by overriding the > operator for the rules:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Gradual process
WebKit uses a flag that marks if all top level style sheets (including @imports) have been loaded. If the style is not fully loaded when attaching, place holders are used and it is marked in the document, and they will be recalculated once the style sheets were loaded.
Макет
When the renderer is created and added to the tree, it does not have a position and size. Calculating these values is called layout or reflow.
HTML uses a flow based layout model, meaning that most of the time it is possible to compute the geometry in a single pass. Elements later "in the flow" typically don't affect the geometry of elements that are earlier "in the flow", so layout can proceed left-to-right, top-to-bottom through the document. There are exceptions: for example, HTML tables may require more than one pass.
The coordinate system is relative to the root frame. Top and left coordinates are used.
Layout is a recursive process. It begins at the root renderer, which corresponds to the <html> element of the HTML document. Layout continues recursively through some or all of the frame hierarchy, computing geometric information for each renderer that requires it.
The position of the root renderer is 0,0 and its dimensions are the viewport - the visible part of the browser window.
All renderers have a "layout" or "reflow" method, each renderer invokes the layout method of its children that need layout.
Dirty bit system
In order not to do a full layout for every small change, browsers use a "dirty bit" system. A renderer that is changed or added marks itself and its children as "dirty": needing layout.
There are two flags: "dirty", and "children are dirty" which means that although the renderer itself may be OK, it has at least one child that needs a layout.
Global and incremental layout
Layout can be triggered on the entire render tree - this is "global" layout. This can happen as a result of:
- A global style change that affects all renderers, like a font size change.
- As a result of a screen being resized
Layout can be incremental, only the dirty renderers will be laid out (this can cause some damage which will require extra layouts).
Incremental layout is triggered (asynchronously) when renderers are dirty. For example when new renderers are appended to the render tree after extra content came from the network and was added to the DOM tree.
Asynchronous and Synchronous layout
Incremental layout is done asynchronously. Firefox queues "reflow commands" for incremental layouts and a scheduler triggers batch execution of these commands. WebKit also has a timer that executes an incremental layout - the tree is traversed and "dirty" renderers are layout out.
Scripts asking for style information, like "offsetHeight" can trigger incremental layout synchronously.
Global layout will usually be triggered synchronously.
Sometimes layout is triggered as a callback after an initial layout because some attributes, like the scrolling position changed.
Оптимизации
When a layout is triggered by a "resize" or a change in the renderer position(and not size), the renders sizes are taken from a cache and not recalculated…
In some cases only a sub tree is modified and layout does not start from the root. This can happen in cases where the change is local and does not affect its surroundings - like text inserted into text fields (otherwise every keystroke would trigger a layout starting from the root).
The layout process
The layout usually has the following pattern:
- Parent renderer determines its own width.
- Parent goes over children and:
- Place the child renderer (sets its x and y).
- Calls child layout if needed - they are dirty or we are in a global layout, or for some other reason - which calculates the child's height.
- Parent uses children's accumulative heights and the heights of margins and padding to set its own height - this will be used by the parent renderer's parent.
- Sets its dirty bit to false.
Firefox uses a "state" object(nsHTMLReflowState) as a parameter to layout (termed "reflow"). Among others the state includes the parents width.
The output of the Firefox layout is a "metrics" object(nsHTMLReflowMetrics). It will contain the renderer computed height.
Width calculation
The renderer's width is calculated using the container block's width, the renderer's style "width" property, the margins and borders.
For example the width of the following div:
<div style="width: 30%"/>
Would be calculated by WebKit as the following(class RenderBox method calcWidth):
- The container width is the maximum of the containers availableWidth and 0. The availableWidth in this case is the contentWidth which is calculated as:
clientWidth() - paddingLeft() - paddingRight()
clientWidth and clientHeight represent the interior of an object excluding border and scrollbar.
The elements width is the "width" style attribute. It will be calculated as an absolute value by computing the percentage of the container width.
The horizontal borders and paddings are now added.
So far this was the calculation of the "preferred width". Now the minimum and maximum widths will be calculated.
If the preferred width is greater than the maximum width, the maximum width is used. If it is less than the minimum width (the smallest unbreakable unit) then the minimum width is used.
The values are cached in case a layout is needed, but the width does not change.
Line Breaking
When a renderer in the middle of a layout decides that it needs to break, the renderer stops and propagates to the layout's parent that it needs to be broken. The parent creates the extra renderers and calls layout on them.
Рисование
In the painting stage, the render tree is traversed and the renderer's "paint()" method is called to display content on the screen. Painting uses the UI infrastructure component.
Global and incremental
Like layout, painting can also be global - the entire tree is painted - or incremental. In incremental painting, some of the renderers change in a way that does not affect the entire tree. The changed renderer invalidates its rectangle on the screen. This causes the OS to see it as a "dirty region" and generate a "paint" event. The OS does it cleverly and coalesces several regions into one. In Chrome it is more complicated because the renderer is in a different process then the main process. Chrome simulates the OS behavior to some extent. The presentation listens to these events and delegates the message to the render root. The tree is traversed until the relevant renderer is reached. It will repaint itself (and usually its children).
The painting order
CSS2 defines the order of the painting process . This is actually the order in which the elements are stacked in the stacking contexts . This order affects painting since the stacks are painted from back to front. The stacking order of a block renderer is:
- цвет фона
- background image
- граница
- дети
- контур
Firefox display list
Firefox goes over the render tree and builds a display list for the painted rectangular. It contains the renderers relevant for the rectangular, in the right painting order (backgrounds of the renderers, then borders etc).
That way the tree needs to be traversed only once for a repaint instead of several times - painting all backgrounds, then all images, then all borders etc.
Firefox optimizes the process by not adding elements that will be hidden, like elements completely beneath other opaque elements.
WebKit rectangle storage
Before repainting, WebKit saves the old rectangle as a bitmap. It then paints only the delta between the new and old rectangles.
Dynamic changes
The browsers try to do the minimal possible actions in response to a change. So changes to an element's color will cause only repaint of the element. Changes to the element position will cause layout and repaint of the element, its children and possibly siblings. Adding a DOM node will cause layout and repaint of the node. Major changes, like increasing font size of the "html" element, will cause invalidation of caches, relayout and repaint of the entire tree.
The rendering engine's threads
The rendering engine is single threaded. Almost everything, except network operations, happens in a single thread. In Firefox and Safari this is the main thread of the browser. In Chrome it's the tab process main thread.
Network operations can be performed by several parallel threads. The number of parallel connections is limited (usually 2 - 6 connections).
Event loop
The browser main thread is an event loop. It's an infinite loop that keeps the process alive. It waits for events (like layout and paint events) and processes them. This is Firefox code for the main event loop:
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 visual model
The canvas
According to the CSS2 specification , the term canvas describes "the space where the formatting structure is rendered": where the browser paints the content.
The canvas is infinite for each dimension of the space but browsers choose an initial width based on the dimensions of the viewport.
According to www.w3.org/TR/CSS2/zindex.html , the canvas is transparent if contained within another, and given a browser defined color if it is not.
CSS Box model
The CSS box model describes the rectangular boxes that are generated for elements in the document tree and laid out according to the visual formatting model.
Each box has a content area (eg text, an image, etc.) and optional surrounding padding, border, and margin areas.
Each node generates 0…n such boxes.
All elements have a "display" property that determines the type of box that will be generated.
Примеры:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
The default is inline but the browser style sheet may set other defaults. For example: the default display for the "div" element is block.
You can find a default style sheet example here: www.w3.org/TR/CSS2/sample.html .
Positioning scheme
There are three schemes:
- Normal: the object is positioned according to its place in the document. This means its place in the render tree is like its place in the DOM tree and laid out according to its box type and dimensions
- Float: the object is first laid out like normal flow, then moved as far left or right as possible
- Absolute: the object is put in the render tree in a different place than in the DOM tree
The positioning scheme is set by the "position" property and the "float" attribute.
- static and relative cause a normal flow
- absolute and fixed cause absolute positioning
In static positioning no position is defined and the default positioning is used. In the other schemes, the author specifies the position: top, bottom, left, right.
The way the box is laid out is determined by:
- Box type
- Box dimensions
- Positioning scheme
- External information such as image size and the size of the screen
Box types
Block box: forms a block - has its own rectangle in the browser window.
Inline box: does not have its own block, but is inside a containing block.
Blocks are formatted vertically one after the other. Inlines are formatted horizontally.
Inline boxes are put inside lines or "line boxes". The lines are at least as tall as the tallest box but can be taller, when the boxes are aligned "baseline" - meaning the bottom part of an element is aligned at a point of another box other then the bottom. If the container width is not enough, the inlines will be put on several lines. This is usually what happens in a paragraph.
Positioning
Родственник
Relative positioning - positioned like usual and then moved by the required delta.
Floats
A float box is shifted to the left or right of a line. The interesting feature is that the other boxes flow around it. The HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Will look like:
Absolute and fixed
The layout is defined exactly regardless of the normal flow. The element does not participate in the normal flow. The dimensions are relative to the container. In fixed, the container is the viewport.
Layered representation
This is specified by the z-index CSS property. It represents the third dimension of the box: its position along the "z axis".
The boxes are divided into stacks (called stacking contexts). In each stack the back elements will be painted first and the forward elements on top, closer to the user. In case of overlap the foremost element will hide the former element.
The stacks are ordered according to the z-index property. Boxes with "z-index" property form a local stack. The viewport has the outer stack.
Пример:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
The result will be this:
Although the red div precedes the green one in the markup, and would have been painted before in the regular flow, the z-index property is higher, so it is more forward in the stack held by the root box.
Ресурсы
Browser architecture
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf)
- Gupta, Vineet. How Browsers Work - Part 1 - Architecture
Разбор
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: two new drafts for HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron, Mozilla's Layout Engine
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, Gecko Overview
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, WebCore Rendering
- David Hyatt, The FOUC Problem
W3C Specifications
Browsers build instructions
Переводы
This page has been translated into Japanese, twice:
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) by @ kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側by @ikeike443 and @kiyoto01 .
You can view the externally hosted translations of Korean and Turkish .
Спасибо всем!
,Behind the scenes of modern web browsers
Предисловие
This comprehensive primer on the internal operations of WebKit and Gecko is the result of much research done by Israeli developer Tali Garsiel. Over a few years, she reviewed all the published data about browser internals and spent a lot of time reading web browser source code. She wrote:
As a web developer, learning the internals of browser operations helps you make better decisions and know the justifications behind development best practices . While this is a rather lengthy document, we recommend you spend some time digging in. You'll be glad you did.
Paul Irish, Chrome Developer Relations
Введение
Web browsers are the most widely used software. In this primer, I explain how they work behind the scenes. We will see what happens when you type google.com in the address bar until you see the Google page on the browser screen.
Browsers we'll talk about
There are five major browsers used on desktop today: Chrome, Internet Explorer, Firefox, Safari and Opera. On mobile, the main browsers are Android Browser, iPhone, Opera Mini and Opera Mobile, UC Browser, the Nokia S40/S60 browsers and Chrome, all of which, except for the Opera browsers, are based on WebKit. I will give examples from the open source browsers Firefox and Chrome, and Safari (which is partly open source). According to StatCounter statistics (as of June 2013) Chrome, Firefox and Safari make up around 71% of global desktop browser usage. On mobile, Android Browser, iPhone and Chrome constitute around 54% of usage.
The browser's main functionality
The main function of a browser is to present the web resource you choose, by requesting it from the server and displaying it in the browser window. The resource is usually an HTML document, but may also be a PDF, image, or some other type of content. The location of the resource is specified by the user using a URI (Uniform Resource Identifier).
The way the browser interprets and displays HTML files is specified in the HTML and CSS specifications. These specifications are maintained by the W3C (World Wide Web Consortium) organization, which is the standards organization for the web. For years browsers conformed to only a part of the specifications and developed their own extensions. That caused serious compatibility issues for web authors. Today most of the browsers more or less conform to the specifications.
Browser user interfaces have a lot in common with each other. Among the common user interface elements are:
- Address bar for inserting a URI
- Back and forward buttons
- Bookmarking options
- Refresh and stop buttons for refreshing or stopping the loading of current documents
- Home button that takes you to your home page
Strangely enough, the browser's user interface is not specified in any formal specification, it just comes from good practices shaped over years of experience and by browsers imitating each other. The HTML5 specification doesn't define UI elements a browser must have, but lists some common elements. Among those are the address bar, status bar and tool bar. There are, of course, features unique to a specific browser like Firefox's downloads manager.
High-level infrastructure
The browser's main components are:
- The user interface : this includes the address bar, back/forward button, bookmarking menu, etc. Every part of the browser display except the window where you see the requested page.
- The browser engine : marshals actions between the UI and the rendering engine.
- The rendering engine : responsible for displaying requested content. For example if the requested content is HTML, the rendering engine parses HTML and CSS, and displays the parsed content on the screen.
- Networking : for network calls such as HTTP requests, using different implementations for different platform behind a platform-independent interface.
- UI backend : used for drawing basic widgets like combo boxes and windows. This backend exposes a generic interface that is not platform specific. Underneath it uses operating system user interface methods.
- JavaScript interpreter . Used to parse and execute JavaScript code.
- Data storage . This is a persistence layer. The browser may need to save all sorts of data locally, such as cookies. Browsers also support storage mechanisms such as localStorage, IndexedDB, WebSQL and FileSystem.
It is important to note that browsers such as Chrome run multiple instances of the rendering engine: one for each tab. Each tab runs in a separate process.
Rendering engines
The responsibility of the rendering engine is well… Rendering, that is display of the requested contents on the browser screen.
By default the rendering engine can display HTML and XML documents and images. It can display other types of data via plug-ins or extension; for example, displaying PDF documents using a PDF viewer plug-in. However, in this chapter we will focus on the main use case: displaying HTML and images that are formatted using CSS.
Different browsers use different rendering engines: Internet Explorer uses Trident, Firefox uses Gecko, Safari uses WebKit. Chrome and Opera (from version 15) use Blink, a fork of WebKit.
WebKit is an open source rendering engine which started as an engine for the Linux platform and was modified by Apple to support Mac and Windows.
The main flow
The rendering engine will start getting the contents of the requested document from the networking layer. This will usually be done in 8kB chunks.
After that, this is the basic flow of the rendering engine:
The rendering engine will start parsing the HTML document and convert elements to DOM nodes in a tree called the "content tree". The engine will parse the style data, both in external CSS files and in style elements. Styling information together with visual instructions in the HTML will be used to create another tree: the render tree .
The render tree contains rectangles with visual attributes like color and dimensions. The rectangles are in the right order to be displayed on the screen.
After the construction of the render tree it goes through a " layout " process. This means giving each node the exact coordinates where it should appear on the screen. The next stage is painting - the render tree will be traversed and each node will be painted using the UI backend layer.
It's important to understand that this is a gradual process. For better user experience, the rendering engine will try to display contents on the screen as soon as possible. It won't wait until all HTML is parsed before starting to build and layout the render tree. Parts of the content will be parsed and displayed, while the process continues with the rest of the contents that keeps coming from the network.
Main flow examples
From figures 3 and 4 you can see that although WebKit and Gecko use slightly different terminology, the flow is basically the same.
Gecko calls the tree of visually formatted elements a "Frame tree". Each element is a frame. WebKit uses the term "Render Tree" and it consists of "Render Objects". WebKit uses the term "layout" for the placing of elements, while Gecko calls it "Reflow". "Attachment" is WebKit's term for connecting DOM nodes and visual information to create the render tree. A minor non-semantic difference is that Gecko has an extra layer between the HTML and the DOM tree. It is called the "content sink" and is a factory for making DOM elements. We will talk about each part of the flow:
Parsing - general
Since parsing is a very significant process within the rendering engine, we will go into it a little more deeply. Let's begin with a little introduction about parsing.
Parsing a document means translating it to a structure the code can use. The result of parsing is usually a tree of nodes that represent the structure of the document. This is called a parse tree or a syntax tree.
For example, parsing the expression 2 + 3 - 1 could return this tree:
Грамматика
Parsing is based on the syntax rules the document obeys: the language or format it was written in. Every format you can parse must have deterministic grammar consisting of vocabulary and syntax rules. It is called a context free grammar . Human languages are not such languages and therefore cannot be parsed with conventional parsing techniques.
Parser - Lexer combination
Parsing can be separated into two sub processes: lexical analysis and syntax analysis.
Lexical analysis is the process of breaking the input into tokens. Tokens are the language vocabulary: the collection of valid building blocks. In human language it will consist of all the words that appear in the dictionary for that language.
Syntax analysis is the applying of the language syntax rules.
Parsers usually divide the work between two components: the lexer (sometimes called tokenizer) that is responsible for breaking the input into valid tokens, and the parser that is responsible for constructing the parse tree by analyzing the document structure according to the language syntax rules.
The lexer knows how to strip irrelevant characters like white spaces and line breaks.
The parsing process is iterative. The parser will usually ask the lexer for a new token and try to match the token with one of the syntax rules. If a rule is matched, a node corresponding to the token will be added to the parse tree and the parser will ask for another token.
If no rule matches, the parser will store the token internally, and keep asking for tokens until a rule matching all the internally stored tokens is found. If no rule is found then the parser will raise an exception. This means the document was not valid and contained syntax errors.
Перевод
In many cases the parse tree is not the final product. Parsing is often used in translation: transforming the input document to another format. An example is compilation. The compiler that compiles source code into machine code first parses it into a parse tree and then translates the tree into a machine code document.
Parsing example
In figure 5 we built a parse tree from a mathematical expression. Let's try to define a simple mathematical language and see the parse process.
Синтаксис:
- The language syntax building blocks are expressions, terms and operations.
- Our language can include any number of expressions.
- An expression is defined as a "term" followed by an "operation" followed by another term
- An operation is a plus token or a minus token
- A term is an integer token or an expression
Let's analyze the input 2 + 3 - 1 .
The first substring that matches a rule is 2 : according to rule #5 it is a term. The second match is 2 + 3 : this matches the third rule: a term followed by an operation followed by another term. The next match will only be hit at the end of the input. 2 + 3 - 1 is an expression because we already know that 2 + 3 is a term, so we have a term followed by an operation followed by another term. 2 + + won't match any rule and therefore is an invalid input.
Formal definitions for vocabulary and syntax
Vocabulary is usually expressed by regular expressions .
For example our language will be defined as:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
As you see, integers are defined by a regular expression.
Syntax is usually defined in a format called BNF . Our language will be defined as:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
We said that a language can be parsed by regular parsers if its grammar is a context free grammar. An intuitive definition of a context free grammar is a grammar that can be entirely expressed in BNF. For a formal definition see Wikipedia's article on Context-free grammar
Types of parsers
There are two types of parsers: top down parsers and bottom up parsers. An intuitive explanation is that top down parsers examine the high level structure of the syntax and try to find a rule match. Bottom up parsers start with the input and gradually transform it into the syntax rules, starting from the low level rules until high level rules are met.
Let's see how the two types of parsers will parse our example.
The top down parser will start from the higher level rule: it will identify 2 + 3 as an expression. It will then identify 2 + 3 - 1 as an expression (the process of identifying the expression evolves, matching the other rules, but the start point is the highest level rule).
The bottom up parser will scan the input until a rule is matched. It will then replace the matching input with the rule. This will go on until the end of the input. The partly matched expression is placed on the parser's stack.
This type of bottom up parser is called a shift-reduce parser, because the input is shifted to the right (imagine a pointer pointing first at the input start and moving to the right) and is gradually reduced to syntax rules.
Generating parsers automatically
There are tools that can generate a parser. You feed them the grammar of your language - its vocabulary and syntax rules - and they generate a working parser. Creating a parser requires a deep understanding of parsing and it's not easy to create an optimized parser by hand, so parser generators can be very useful.
WebKit uses two well known parser generators: Flex for creating a lexer and Bison for creating a parser (you might run into them with the names Lex and Yacc). Flex input is a file containing regular expression definitions of the tokens. Bison's input is the language syntax rules in BNF format.
HTML Parser
The job of the HTML parser is to parse the HTML markup into a parse tree.
HTML grammar
The vocabulary and syntax of HTML are defined in specifications created by the W3C organization.
As we have seen in the parsing introduction, grammar syntax can be defined formally using formats like BNF.
Unfortunately all the conventional parser topics don't apply to HTML (I didn't bring them up just for fun - they will be used in parsing CSS and JavaScript). HTML cannot easily be defined by a context free grammar that parsers need.
There is a formal format for defining HTML - DTD (Document Type Definition) - but it is not a context free grammar.
This appears strange at first sight; HTML is rather close to XML. There are lots of available XML parsers. There is an XML variation of HTML - XHTML - so what's the big difference?
The difference is that the HTML approach is more "forgiving": it lets you omit certain tags (which are then added implicitly), or sometimes omit start or end tags, and so on. On the whole it's a "soft" syntax, as opposed to XML's stiff and demanding syntax.
This seemingly small detail makes a world of a difference. On one hand this is the main reason why HTML is so popular: it forgives your mistakes and makes life easy for the web author. On the other hand, it makes it difficult to write a formal grammar. So to summarize, HTML cannot be parsed easily by conventional parsers, since its grammar is not context free. HTML cannot be parsed by XML parsers.
HTML DTD
HTML definition is in a DTD format. This format is used to define languages of the SGML family. The format contains definitions for all allowed elements, their attributes and hierarchy. As we saw earlier, the HTML DTD doesn't form a context free grammar.
There are a few variations of the DTD. The strict mode conforms solely to the specifications but other modes contain support for markup used by browsers in the past. The purpose is backwards compatibility with older content. The current strict DTD is here: www.w3.org/TR/html4/strict.dtd
ДОМ
The output tree (the "parse tree") is a tree of DOM element and attribute nodes. DOM is short for Document Object Model. It is the object presentation of the HTML document and the interface of HTML elements to the outside world like JavaScript.
The root of the tree is the " Document " object.
The DOM has an almost one-to-one relation to the markup. Например:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
This markup would be translated to the following DOM tree:
Like HTML, DOM is specified by the W3C organization. See www.w3.org/DOM/DOMTR . It is a generic specification for manipulating documents. A specific module describes HTML specific elements. The HTML definitions can be found here: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html .
When I say the tree contains DOM nodes, I mean the tree is constructed of elements that implement one of the DOM interfaces. Browsers use concrete implementations that have other attributes used by the browser internally.
The parsing algorithm
As we saw in the previous sections, HTML cannot be parsed using the regular top down or bottom up parsers.
The reasons are:
- The forgiving nature of the language.
- The fact that browsers have traditional error tolerance to support well known cases of invalid HTML.
- The parsing process is reentrant. For other languages, the source doesn't change during parsing, but in HTML, dynamic code (such as script elements containing
document.write()calls) can add extra tokens, so the parsing process actually modifies the input.
Unable to use the regular parsing techniques, browsers create custom parsers for parsing HTML.
The parsing algorithm is described in detail by the HTML5 specification . The algorithm consists of two stages: tokenization and tree construction.
Tokenization is the lexical analysis, parsing the input into tokens. Among HTML tokens are start tags, end tags, attribute names and attribute values.
The tokenizer recognizes the token, gives it to the tree constructor, and consumes the next character for recognizing the next token, and so on until the end of the input.
The tokenization algorithm
The algorithm's output is an HTML token. The algorithm is expressed as a state machine. Each state consumes one or more characters of the input stream and updates the next state according to those characters. The decision is influenced by the current tokenization state and by the tree construction state. This means the same consumed character will yield different results for the correct next state, depending on the current state. The algorithm is too complex to describe fully, so let's see a simple example that will help us understand the principle.
Basic example - tokenizing the following HTML:
<html>
<body>
Hello world
</body>
</html>
The initial state is the "Data state". When the < character is encountered, the state is changed to "Tag open state" . Consuming an az character causes creation of a "Start tag token", the state is changed to "Tag name state" . We stay in this state until the > character is consumed. Each character is appended to the new token name. In our case the created token is an html token.
When the > tag is reached, the current token is emitted and the state changes back to the "Data state" . The <body> tag will be treated by the same steps. So far the html and body tags were emitted. We are now back at the "Data state" . Consuming the H character of Hello world will cause creation and emitting of a character token, this goes on until the < of </body> is reached. We will emit a character token for each character of Hello world .
We are now back at the "Tag open state" . Consuming the next input / will cause creation of an end tag token and a move to the "Tag name state" . Again we stay in this state until we reach > .Then the new tag token will be emitted and we go back to the "Data state" . The </html> input will be treated like the previous case.
Tree construction algorithm
When the parser is created the Document object is created. During the tree construction stage the DOM tree with the Document in its root will be modified and elements will be added to it. Each node emitted by the tokenizer will be processed by the tree constructor. For each token the specification defines which DOM element is relevant to it and will be created for this token. The element is added to the DOM tree, and also the stack of open elements. This stack is used to correct nesting mismatches and unclosed tags. The algorithm is also described as a state machine. The states are called "insertion modes".
Let's see the tree construction process for the example input:
<html>
<body>
Hello world
</body>
</html>
The input to the tree construction stage is a sequence of tokens from the tokenization stage. The first mode is the "initial mode" . Receiving the "html" token will cause a move to the "before html" mode and a reprocessing of the token in that mode. This will cause creation of the HTMLHtmlElement element, which will be appended to the root Document object.
The state will be changed to "before head" . The "body" token is then received. An HTMLHeadElement will be created implicitly although we don't have a "head" token and it will be added to the tree.
We now move to the "in head" mode and then to "after head" . The body token is reprocessed, an HTMLBodyElement is created and inserted and the mode is transferred to "in body" .
The character tokens of the "Hello world" string are now received. The first one will cause creation and insertion of a "Text" node and the other characters will be appended to that node.
The receiving of the body end token will cause a transfer to "after body" mode. We will now receive the html end tag which will move us to "after after body" mode. Receiving the end of file token will end the parsing.
Actions when the parsing is finished
At this stage the browser will mark the document as interactive and start parsing scripts that are in "deferred" mode: those that should be executed after the document is parsed. The document state will be then set to "complete" and a "load" event will be fired.
You can see the full algorithms for tokenization and tree construction in the HTML5 specification .
Browsers' error tolerance
You never get an "Invalid Syntax" error on an HTML page. Browsers fix any invalid content and go on.
Take this HTML for example:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
I must have violated about a million rules ("mytag" is not a standard tag, wrong nesting of the "p" and "div" elements and more) but the browser still shows it correctly and doesn't complain. So a lot of the parser code is fixing the HTML author mistakes.
Error handling is quite consistent in browsers, but amazingly enough it hasn't been part of HTML specifications. Like bookmarking and back/forward buttons it's just something that developed in browsers over the years. There are known invalid HTML constructs repeated on many sites, and the browsers try to fix them in a way conformant with other browsers.
The HTML5 specification does define some of these requirements. (WebKit summarizes this nicely in the comment at the beginning of the HTML parser class.)
The parser parses tokenized input into the document, building up the document tree. If the document is well-formed, parsing it is straightforward.
Unfortunately, we have to handle many HTML documents that are not well-formed, so the parser has to be tolerant about errors.
We have to take care of at least the following error conditions:
- The element being added is explicitly forbidden inside some outer tag. In this case we should close all tags up to the one which forbids the element, and add it afterwards.
- We are not allowed to add the element directly. It could be that the person writing the document forgot some tag in between (or that the tag in between is optional). This could be the case with the following tags: HTML HEAD BODY TBODY TR TD LI (did I forget any?).
- We want to add a block element inside an inline element. Close all inline elements up to the next higher block element.
- If this doesn't help, close elements until we are allowed to add the element - or ignore the tag.
Let's see some WebKit error tolerance examples:
</br> instead of <br>
Some sites use </br> instead of <br> . In order to be compatible with IE and Firefox, WebKit treats this like <br> .
Код:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Note that the error handling is internal: it won't be presented to the user.
A stray table
A stray table is a table inside another table, but not inside a table cell.
Например:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit will change the hierarchy to two sibling tables:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Код:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit uses a stack for the current element contents: it will pop the inner table out of the outer table stack. The tables will now be siblings.
Nested form elements
In case the user puts a form inside another form, the second form is ignored.
Код:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
A too deep tag hierarchy
The comment speaks for itself.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Misplaced html or body end tags
Again - the comment speaks for itself.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
So web authors beware - unless you want to appear as an example in a WebKit error tolerance code snippet - write well formed HTML.
CSS parsing
Remember the parsing concepts in the introduction? Well, unlike HTML, CSS is a context free grammar and can be parsed using the types of parsers described in the introduction. In fact the CSS specification defines CSS lexical and syntax grammar .
Let's see some examples:
The lexical grammar (vocabulary) is defined by regular expressions for each token:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" is short for identifier, like a class name. "name" is an element id (that is referred by "#" )
The syntax grammar is described in BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Объяснение:
A ruleset is this structure:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error and a.error are selectors. The part inside the curly braces contains the rules that are applied by this ruleset. This structure is defined formally in this definition:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
This means a ruleset is a selector or optionally a number of selectors separated by a comma and spaces (S stands for white space). A ruleset contains curly braces and inside them a declaration or optionally a number of declarations separated by a semicolon. "declaration" and "selector" will be defined in the following BNF definitions.
WebKit CSS parser
WebKit uses Flex and Bison parser generators to create parsers automatically from the CSS grammar files. As you recall from the parser introduction, Bison creates a bottom up shift-reduce parser. Firefox uses a top down parser written manually. In both cases each CSS file is parsed into a StyleSheet object. Each object contains CSS rules. The CSS rule objects contain selector and declaration objects and other objects corresponding to CSS grammar.
Processing order for scripts and style sheets
Scripts
The model of the web is synchronous. Authors expect scripts to be parsed and executed immediately when the parser reaches a <script> tag. The parsing of the document halts until the script has been executed. If the script is external then the resource must first be fetched from the network - this is also done synchronously, and parsing halts until the resource is fetched. This was the model for many years and is also specified in HTML4 and 5 specifications. Authors can add the "defer" attribute to a script, in which case it won't halt document parsing and will execute after the document is parsed. HTML5 adds an option to mark the script as asynchronous so it will be parsed and executed by a different thread.
Speculative parsing
Both WebKit and Firefox do this optimization. While executing scripts, another thread parses the rest of the document and finds out what other resources need to be loaded from the network and loads them. In this way, resources can be loaded on parallel connections and overall speed is improved. Note: the speculative parser only parses references to external resources like external scripts, style sheets and images: it doesn't modify the DOM tree - that is left to the main parser.
Style sheets
Style sheets on the other hand have a different model. Conceptually it seems that since style sheets don't change the DOM tree, there is no reason to wait for them and stop the document parsing. There is an issue, though, of scripts asking for style information during the document parsing stage. If the style is not loaded and parsed yet, the script will get wrong answers and apparently this caused lots of problems. It seems to be an edge case but is quite common. Firefox blocks all scripts when there is a style sheet that is still being loaded and parsed. WebKit blocks scripts only when they try to access certain style properties that may be affected by unloaded style sheets.
Render tree construction
While the DOM tree is being constructed, the browser constructs another tree, the render tree. This tree is of visual elements in the order in which they will be displayed. It is the visual representation of the document. The purpose of this tree is to enable painting the contents in their correct order.
Firefox calls the elements in the render tree "frames". WebKit uses the term renderer or render object.
A renderer knows how to lay out and paint itself and its children.
WebKit's RenderObject class, the base class of the renderers, has the following definition:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Each renderer represents a rectangular area usually corresponding to a node's CSS box, as described by the CSS2 spec. It includes geometric information like width, height and position.
The box type is affected by the "display" value of the style attribute that is relevant to the node (see the style computation section). Here is WebKit code for deciding what type of renderer should be created for a DOM node, according to the display attribute:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
The element type is also considered: for example, form controls and tables have special frames.
In WebKit if an element wants to create a special renderer, it will override the createRenderer() method. The renderers point to style objects that contains non geometric information.
The render tree relation to the DOM tree
The renderers correspond to DOM elements, but the relation is not one to one. Non-visual DOM elements won't be inserted in the render tree. An example is the "head" element. Also elements whose display value was assigned to "none" won't appear in the tree (whereas elements with "hidden" visibility will appear in the tree).
There are DOM elements which correspond to several visual objects. These are usually elements with complex structure that cannot be described by a single rectangle. For example, the "select" element has three renderers: one for the display area, one for the drop down list box and one for the button. Also when text is broken into multiple lines because the width is not sufficient for one line, the new lines will be added as extra renderers.
Another example of multiple renderers is broken HTML. According to the CSS spec an inline element must contain either only block elements or only inline elements. In the case of mixed content, anonymous block renderers will be created to wrap the inline elements.
Some render objects correspond to a DOM node but not in the same place in the tree. Floats and absolutely positioned elements are out of flow, placed in a different part of the tree, and mapped to the real frame. A placeholder frame is where they should have been.
The flow of constructing the tree
In Firefox, the presentation is registered as a listener for DOM updates. The presentation delegates frame creation to the FrameConstructor and the constructor resolves style (see style computation ) and creates a frame.
In WebKit the process of resolving the style and creating a renderer is called "attachment". Every DOM node has an "attach" method. Attachment is synchronous, node insertion to the DOM tree calls the new node "attach" method.
Processing the html and body tags results in the construction of the render tree root. The root render object corresponds to what the CSS spec calls the containing block: the top most block that contains all other blocks. Its dimensions are the viewport: the browser window display area dimensions. Firefox calls it ViewPortFrame and WebKit calls it RenderView . This is the render object that the document points to. The rest of the tree is constructed as a DOM nodes insertion.
See the CSS2 spec on the processing model .
Style computation
Building the render tree requires calculating the visual properties of each render object. This is done by calculating the style properties of each element.
The style includes style sheets of various origins, inline style elements and visual properties in the HTML (like the "bgcolor" property).The later is translated to matching CSS style properties.
The origins of style sheets are the browser's default style sheets, the style sheets provided by the page author and user style sheets - these are style sheets provided by the browser user (browsers let you define your favorite styles. In Firefox, for instance, this is done by placing a style sheet in the "Firefox Profile" folder).
Style computation brings up a few difficulties:
- Style data is a very large construct, holding the numerous style properties, this can cause memory problems.
Finding the matching rules for each element can cause performance issues if it's not optimized. Traversing the entire rule list for each element to find matches is a heavy task. Selectors can have complex structure that can cause the matching process to start on a seemingly promising path that is proven to be futile and another path has to be tried.
For example - this compound selector:
div div div div{ ... }Means the rules apply to a
<div>who is the descendant of 3 divs. Suppose you want to check if the rule applies for a given<div>element. You choose a certain path up the tree for checking. You may need to traverse the node tree up just to find out there are only two divs and the rule does not apply. You then need to try other paths in the tree.Applying the rules involves quite complex cascade rules that define the hierarchy of the rules.
Let's see how the browsers face these issues:
Sharing style data
WebKit nodes references style objects (RenderStyle). These objects can be shared by nodes in some conditions. The nodes are siblings or cousins and:
- The elements must be in the same mouse state (eg, one can't be in :hover while the other isn't)
- Neither element should have an id
- The tag names should match
- The class attributes should match
- The set of mapped attributes must be identical
- The link states must match
- The focus states must match
- Neither element should be affected by attribute selectors, where affected is defined as having any selector match that uses an attribute selector in any position within the selector at all
- There must be no inline style attribute on the elements
- There must be no sibling selectors in use at all. WebCore simply throws a global switch when any sibling selector is encountered and disables style sharing for the entire document when they are present. This includes the + selector and selectors like :first-child and :last-child.
Firefox rule tree
Firefox has two extra trees for easier style computation: the rule tree and style context tree. WebKit also has style objects but they are not stored in a tree like the style context tree, only the DOM node points to its relevant style.
The style contexts contain end values. The values are computed by applying all the matching rules in the correct order and performing manipulations that transform them from logical to concrete values. For example, if the logical value is a percentage of the screen it will be calculated and transformed to absolute units. The rule tree idea is really clever. It enables sharing these values between nodes to avoid computing them again. This also saves space.
All the matched rules are stored in a tree. The bottom nodes in a path have higher priority. The tree contains all the paths for rule matches that were found. Storing the rules is done lazily. The tree isn't calculated at the beginning for every node, but whenever a node style needs to be computed the computed paths are added to the tree.
The idea is to see the tree paths as words in a lexicon. Lets say we already computed this rule tree:
Suppose we need to match rules for another element in the content tree, and find out the matched rules (in the correct order) are BEI. We already have this path in the tree because we already computed path ABEIL. We will now have less work to do.
Let's see how the tree saves us work.
Division into structs
The style contexts are divided into structs. Those structs contain style information for a certain category like border or color. All the properties in a struct are either inherited or non inherited. Inherited properties are properties that unless defined by the element, are inherited from its parent. Non inherited properties (called "reset" properties) use default values if not defined.
The tree helps us by caching entire structs (containing the computed end values) in the tree. The idea is that if the bottom node didn't supply a definition for a struct, a cached struct in an upper node can be used.
Computing the style contexts using the rule tree
When computing the style context for a certain element, we first compute a path in the rule tree or use an existing one. We then begin to apply the rules in the path to fill the structs in our new style context. We start at the bottom node of the path - the one with the highest precedence (usually the most specific selector) and traverse the tree up until our struct is full. If there is no specification for the struct in that rule node, then we can greatly optimize - we go up the tree until we find a node that specifies it fully and point to it - that's the best optimization - the entire struct is shared. This saves computation of end values and memory.
If we find partial definitions we go up the tree until the struct is filled.
If we didn't find any definitions for our struct then, in case the struct is an "inherited" type, we point to the struct of our parent in the context tree . In this case we also succeeded in sharing structs. If it's a reset struct then default values will be used.
If the most specific node does add values then we need to do some extra calculations for transforming it to actual values. We then cache the result in the tree node so it can be used by children.
In case an element has a sibling or a brother that points to the same tree node then the entire style context can be shared between them.
Lets see an example: Suppose we have this HTML
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
And the following rules:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
To simplify things let's say we need to fill out only two structs: the color struct and the margin struct. The color struct contains only one member: the color The margin struct contains the four sides.
The resulting rule tree will look like this (the nodes are marked with the node name: the number of the rule they point at):
The context tree will look like this (node name: rule node they point to):
Suppose we parse the HTML and get to the second <div> tag. We need to create a style context for this node and fill its style structs.
We will match the rules and discover that the matching rules for the <div> are 1, 2 and 6. This means there is already an existing path in the tree that our element can use and we just need to add another node to it for rule 6 (node F in the rule tree).
We will create a style context and put it in the context tree. The new style context will point to node F in the rule tree.
We now need to fill the style structs. We will begin by filling out the margin struct. Since the last rule node (F) doesn't add to the margin struct, we can go up the tree until we find a cached struct computed in a previous node insertion and use it. We will find it on node B, which is the uppermost node that specified margin rules.
We do have a definition for the color struct, so we can't use a cached struct. Since color has one attribute we don't need to go up the tree to fill other attributes. We will compute the end value (convert string to RGB etc) and cache the computed struct on this node.
The work on the second <span> element is even easier. We will match the rules and come to the conclusion that it points to rule G, like the previous span. Since we have siblings that point to the same node, we can share the entire style context and just point to the context of the previous span.
For structs that contain rules that are inherited from the parent, caching is done on the context tree (the color property is actually inherited, but Firefox treats it as reset and caches it on the rule tree).
For example, if we added rules for fonts in a paragraph:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Then the paragraph element, which is a child of the div in the context tree, could have shared the same font struct as his parent. This is if no font rules were specified for the paragraph.
In WebKit, who does not have a rule tree, the matched declarations are traversed four times. First non-important high priority properties are applied (properties that should be applied first because others depend on them, such as display), then high priority important, then normal priority non-important, then normal priority important rules. This means that properties that appear multiple times will be resolved according to the correct cascade order. The last wins.
So to summarize: sharing the style objects (entirely or some of the structs inside them) solves issues 1 and 3. The Firefox rule tree also helps in applying the properties in the correct order.
Manipulating the rules for an easy match
There are several sources for style rules:
- CSS rules, either in external style sheets or in style elements.
css p {color: blue} - Inline style attributes like
html <p style="color: blue" /> - HTML visual attributes (which are mapped to relevant style rules)
html <p bgcolor="blue" />The last two are easily matched to the element since he owns the style attributes and HTML attributes can be mapped using the element as the key.
As noted previously in issue #2, the CSS rule matching can be trickier. To solve the difficulty, the rules are manipulated for easier access.
After parsing the style sheet, the rules are added to one of several hash maps, according to the selector. There are maps by id, by class name, by tag name and a general map for anything that doesn't fit into those categories. If the selector is an id, the rule will be added to the id map, if it's a class it will be added to the class map etc.
This manipulation makes it much easier to match rules. There is no need to look in every declaration: we can extract the relevant rules for an element from the maps. This optimization eliminates 95+% of the rules, so that they need not even be considered during the matching process(4.1).
Let's see for example the following style rules:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
The first rule will be inserted into the class map. The second into the id map and the third into the tag map.
For the following HTML fragment;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
We will first try to find rules for the p element. The class map will contain an "error" key under which the rule for "p.error" is found. The div element will have relevant rules in the id map (the key is the id) and the tag map. So the only work left is finding out which of the rules that were extracted by the keys really match.
For example if the rule for the div was:
table div {margin: 5px}
It will still be extracted from the tag map, because the key is the rightmost selector, but it wouldn't match our div element, who does not have a table ancestor.
Both WebKit and Firefox do this manipulation.
Style sheet cascade order
The style object has properties corresponding to every visual attribute (all CSS attributes but more generic). If the property is not defined by any of the matched rules, then some properties can be inherited by the parent element style object. Other properties have default values.
The problem begins when there is more than one definition - here comes the cascade order to solve the issue.
A declaration for a style property can appear in several style sheets, and several times inside a style sheet. This means the order of applying the rules is very important. This is called the "cascade" order. According to CSS2 spec, the cascade order is (from low to high):
- Browser declarations
- User normal declarations
- Author normal declarations
- Author important declarations
- User important declarations
The browser declarations are least important and the user overrides the author only if the declaration was marked as important. Declarations with the same order will be sorted by specificity and then the order they are specified. The HTML visual attributes are translated to matching CSS declarations . They are treated as author rules with low priority.
Specificity
The selector specificity is defined by the CSS2 specification as follows:
- count 1 if the declaration it is from is a 'style' attribute rather than a rule with a selector, 0 otherwise (= a)
- count the number of ID attributes in the selector (= b)
- count the number of other attributes and pseudo-classes in the selector (= c)
- count the number of element names and pseudo-elements in the selector (= d)
Concatenating the four numbers abcd (in a number system with a large base) gives the specificity.
The number base you need to use is defined by the highest count you have in one of the categories.
For example, if a=14 you can use hexadecimal base. In the unlikely case where a=17 you will need a 17 digits number base. The later situation can happen with a selector like this: html body div div p… (17 tags in your selector… not very likely).
Несколько примеров:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Sorting the rules
After the rules are matched, they are sorted according to the cascade rules. WebKit uses bubble sort for small lists and merge sort for big ones. WebKit implements sorting by overriding the > operator for the rules:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Gradual process
WebKit uses a flag that marks if all top level style sheets (including @imports) have been loaded. If the style is not fully loaded when attaching, place holders are used and it is marked in the document, and they will be recalculated once the style sheets were loaded.
Макет
When the renderer is created and added to the tree, it does not have a position and size. Calculating these values is called layout or reflow.
HTML uses a flow based layout model, meaning that most of the time it is possible to compute the geometry in a single pass. Elements later "in the flow" typically don't affect the geometry of elements that are earlier "in the flow", so layout can proceed left-to-right, top-to-bottom through the document. There are exceptions: for example, HTML tables may require more than one pass.
The coordinate system is relative to the root frame. Top and left coordinates are used.
Layout is a recursive process. It begins at the root renderer, which corresponds to the <html> element of the HTML document. Layout continues recursively through some or all of the frame hierarchy, computing geometric information for each renderer that requires it.
The position of the root renderer is 0,0 and its dimensions are the viewport - the visible part of the browser window.
All renderers have a "layout" or "reflow" method, each renderer invokes the layout method of its children that need layout.
Dirty bit system
In order not to do a full layout for every small change, browsers use a "dirty bit" system. A renderer that is changed or added marks itself and its children as "dirty": needing layout.
There are two flags: "dirty", and "children are dirty" which means that although the renderer itself may be OK, it has at least one child that needs a layout.
Global and incremental layout
Layout can be triggered on the entire render tree - this is "global" layout. This can happen as a result of:
- A global style change that affects all renderers, like a font size change.
- As a result of a screen being resized
Layout can be incremental, only the dirty renderers will be laid out (this can cause some damage which will require extra layouts).
Incremental layout is triggered (asynchronously) when renderers are dirty. For example when new renderers are appended to the render tree after extra content came from the network and was added to the DOM tree.
Asynchronous and Synchronous layout
Incremental layout is done asynchronously. Firefox queues "reflow commands" for incremental layouts and a scheduler triggers batch execution of these commands. WebKit also has a timer that executes an incremental layout - the tree is traversed and "dirty" renderers are layout out.
Scripts asking for style information, like "offsetHeight" can trigger incremental layout synchronously.
Global layout will usually be triggered synchronously.
Sometimes layout is triggered as a callback after an initial layout because some attributes, like the scrolling position changed.
Оптимизации
When a layout is triggered by a "resize" or a change in the renderer position(and not size), the renders sizes are taken from a cache and not recalculated…
In some cases only a sub tree is modified and layout does not start from the root. This can happen in cases where the change is local and does not affect its surroundings - like text inserted into text fields (otherwise every keystroke would trigger a layout starting from the root).
The layout process
The layout usually has the following pattern:
- Parent renderer determines its own width.
- Parent goes over children and:
- Place the child renderer (sets its x and y).
- Calls child layout if needed - they are dirty or we are in a global layout, or for some other reason - which calculates the child's height.
- Parent uses children's accumulative heights and the heights of margins and padding to set its own height - this will be used by the parent renderer's parent.
- Sets its dirty bit to false.
Firefox uses a "state" object(nsHTMLReflowState) as a parameter to layout (termed "reflow"). Among others the state includes the parents width.
The output of the Firefox layout is a "metrics" object(nsHTMLReflowMetrics). It will contain the renderer computed height.
Width calculation
The renderer's width is calculated using the container block's width, the renderer's style "width" property, the margins and borders.
For example the width of the following div:
<div style="width: 30%"/>
Would be calculated by WebKit as the following(class RenderBox method calcWidth):
- The container width is the maximum of the containers availableWidth and 0. The availableWidth in this case is the contentWidth which is calculated as:
clientWidth() - paddingLeft() - paddingRight()
clientWidth and clientHeight represent the interior of an object excluding border and scrollbar.
The elements width is the "width" style attribute. It will be calculated as an absolute value by computing the percentage of the container width.
The horizontal borders and paddings are now added.
So far this was the calculation of the "preferred width". Now the minimum and maximum widths will be calculated.
If the preferred width is greater than the maximum width, the maximum width is used. If it is less than the minimum width (the smallest unbreakable unit) then the minimum width is used.
The values are cached in case a layout is needed, but the width does not change.
Line Breaking
When a renderer in the middle of a layout decides that it needs to break, the renderer stops and propagates to the layout's parent that it needs to be broken. The parent creates the extra renderers and calls layout on them.
Рисование
In the painting stage, the render tree is traversed and the renderer's "paint()" method is called to display content on the screen. Painting uses the UI infrastructure component.
Global and incremental
Like layout, painting can also be global - the entire tree is painted - or incremental. In incremental painting, some of the renderers change in a way that does not affect the entire tree. The changed renderer invalidates its rectangle on the screen. This causes the OS to see it as a "dirty region" and generate a "paint" event. The OS does it cleverly and coalesces several regions into one. In Chrome it is more complicated because the renderer is in a different process then the main process. Chrome simulates the OS behavior to some extent. The presentation listens to these events and delegates the message to the render root. The tree is traversed until the relevant renderer is reached. It will repaint itself (and usually its children).
The painting order
CSS2 defines the order of the painting process . This is actually the order in which the elements are stacked in the stacking contexts . This order affects painting since the stacks are painted from back to front. The stacking order of a block renderer is:
- цвет фона
- background image
- граница
- дети
- контур
Firefox display list
Firefox goes over the render tree and builds a display list for the painted rectangular. It contains the renderers relevant for the rectangular, in the right painting order (backgrounds of the renderers, then borders etc).
That way the tree needs to be traversed only once for a repaint instead of several times - painting all backgrounds, then all images, then all borders etc.
Firefox optimizes the process by not adding elements that will be hidden, like elements completely beneath other opaque elements.
WebKit rectangle storage
Before repainting, WebKit saves the old rectangle as a bitmap. It then paints only the delta between the new and old rectangles.
Dynamic changes
The browsers try to do the minimal possible actions in response to a change. So changes to an element's color will cause only repaint of the element. Changes to the element position will cause layout and repaint of the element, its children and possibly siblings. Adding a DOM node will cause layout and repaint of the node. Major changes, like increasing font size of the "html" element, will cause invalidation of caches, relayout and repaint of the entire tree.
The rendering engine's threads
The rendering engine is single threaded. Almost everything, except network operations, happens in a single thread. In Firefox and Safari this is the main thread of the browser. In Chrome it's the tab process main thread.
Network operations can be performed by several parallel threads. The number of parallel connections is limited (usually 2 - 6 connections).
Event loop
The browser main thread is an event loop. It's an infinite loop that keeps the process alive. It waits for events (like layout and paint events) and processes them. This is Firefox code for the main event loop:
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 visual model
The canvas
According to the CSS2 specification , the term canvas describes "the space where the formatting structure is rendered": where the browser paints the content.
The canvas is infinite for each dimension of the space but browsers choose an initial width based on the dimensions of the viewport.
According to www.w3.org/TR/CSS2/zindex.html , the canvas is transparent if contained within another, and given a browser defined color if it is not.
CSS Box model
The CSS box model describes the rectangular boxes that are generated for elements in the document tree and laid out according to the visual formatting model.
Each box has a content area (eg text, an image, etc.) and optional surrounding padding, border, and margin areas.
Each node generates 0…n such boxes.
All elements have a "display" property that determines the type of box that will be generated.
Примеры:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
The default is inline but the browser style sheet may set other defaults. For example: the default display for the "div" element is block.
You can find a default style sheet example here: www.w3.org/TR/CSS2/sample.html .
Positioning scheme
There are three schemes:
- Normal: the object is positioned according to its place in the document. This means its place in the render tree is like its place in the DOM tree and laid out according to its box type and dimensions
- Float: the object is first laid out like normal flow, then moved as far left or right as possible
- Absolute: the object is put in the render tree in a different place than in the DOM tree
The positioning scheme is set by the "position" property and the "float" attribute.
- static and relative cause a normal flow
- absolute and fixed cause absolute positioning
In static positioning no position is defined and the default positioning is used. In the other schemes, the author specifies the position: top, bottom, left, right.
The way the box is laid out is determined by:
- Box type
- Box dimensions
- Positioning scheme
- External information such as image size and the size of the screen
Box types
Block box: forms a block - has its own rectangle in the browser window.
Inline box: does not have its own block, but is inside a containing block.
Blocks are formatted vertically one after the other. Inlines are formatted horizontally.
Inline boxes are put inside lines or "line boxes". The lines are at least as tall as the tallest box but can be taller, when the boxes are aligned "baseline" - meaning the bottom part of an element is aligned at a point of another box other then the bottom. If the container width is not enough, the inlines will be put on several lines. This is usually what happens in a paragraph.
Positioning
Родственник
Relative positioning - positioned like usual and then moved by the required delta.
Floats
A float box is shifted to the left or right of a line. The interesting feature is that the other boxes flow around it. The HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Will look like:
Absolute and fixed
The layout is defined exactly regardless of the normal flow. The element does not participate in the normal flow. The dimensions are relative to the container. In fixed, the container is the viewport.
Layered representation
This is specified by the z-index CSS property. It represents the third dimension of the box: its position along the "z axis".
The boxes are divided into stacks (called stacking contexts). In each stack the back elements will be painted first and the forward elements on top, closer to the user. In case of overlap the foremost element will hide the former element.
The stacks are ordered according to the z-index property. Boxes with "z-index" property form a local stack. The viewport has the outer stack.
Пример:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
The result will be this:
Although the red div precedes the green one in the markup, and would have been painted before in the regular flow, the z-index property is higher, so it is more forward in the stack held by the root box.
Ресурсы
Browser architecture
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf)
- Gupta, Vineet. How Browsers Work - Part 1 - Architecture
Разбор
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: two new drafts for HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron, Mozilla's Layout Engine
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, Gecko Overview
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, WebCore Rendering
- David Hyatt, The FOUC Problem
W3C Specifications
Browsers build instructions
Переводы
This page has been translated into Japanese, twice:
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) by @ kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側by @ikeike443 and @kiyoto01 .
You can view the externally hosted translations of Korean and Turkish .
Спасибо всем!
,Behind the scenes of modern web browsers
Предисловие
This comprehensive primer on the internal operations of WebKit and Gecko is the result of much research done by Israeli developer Tali Garsiel. Over a few years, she reviewed all the published data about browser internals and spent a lot of time reading web browser source code. She wrote:
As a web developer, learning the internals of browser operations helps you make better decisions and know the justifications behind development best practices . While this is a rather lengthy document, we recommend you spend some time digging in. You'll be glad you did.
Paul Irish, Chrome Developer Relations
Введение
Web browsers are the most widely used software. In this primer, I explain how they work behind the scenes. We will see what happens when you type google.com in the address bar until you see the Google page on the browser screen.
Browsers we'll talk about
There are five major browsers used on desktop today: Chrome, Internet Explorer, Firefox, Safari and Opera. On mobile, the main browsers are Android Browser, iPhone, Opera Mini and Opera Mobile, UC Browser, the Nokia S40/S60 browsers and Chrome, all of which, except for the Opera browsers, are based on WebKit. I will give examples from the open source browsers Firefox and Chrome, and Safari (which is partly open source). According to StatCounter statistics (as of June 2013) Chrome, Firefox and Safari make up around 71% of global desktop browser usage. On mobile, Android Browser, iPhone and Chrome constitute around 54% of usage.
The browser's main functionality
The main function of a browser is to present the web resource you choose, by requesting it from the server and displaying it in the browser window. The resource is usually an HTML document, but may also be a PDF, image, or some other type of content. The location of the resource is specified by the user using a URI (Uniform Resource Identifier).
The way the browser interprets and displays HTML files is specified in the HTML and CSS specifications. These specifications are maintained by the W3C (World Wide Web Consortium) organization, which is the standards organization for the web. For years browsers conformed to only a part of the specifications and developed their own extensions. That caused serious compatibility issues for web authors. Today most of the browsers more or less conform to the specifications.
Browser user interfaces have a lot in common with each other. Among the common user interface elements are:
- Address bar for inserting a URI
- Back and forward buttons
- Bookmarking options
- Refresh and stop buttons for refreshing or stopping the loading of current documents
- Home button that takes you to your home page
Strangely enough, the browser's user interface is not specified in any formal specification, it just comes from good practices shaped over years of experience and by browsers imitating each other. The HTML5 specification doesn't define UI elements a browser must have, but lists some common elements. Among those are the address bar, status bar and tool bar. There are, of course, features unique to a specific browser like Firefox's downloads manager.
High-level infrastructure
The browser's main components are:
- The user interface : this includes the address bar, back/forward button, bookmarking menu, etc. Every part of the browser display except the window where you see the requested page.
- The browser engine : marshals actions between the UI and the rendering engine.
- The rendering engine : responsible for displaying requested content. For example if the requested content is HTML, the rendering engine parses HTML and CSS, and displays the parsed content on the screen.
- Networking : for network calls such as HTTP requests, using different implementations for different platform behind a platform-independent interface.
- UI backend : used for drawing basic widgets like combo boxes and windows. This backend exposes a generic interface that is not platform specific. Underneath it uses operating system user interface methods.
- JavaScript interpreter . Used to parse and execute JavaScript code.
- Data storage . This is a persistence layer. The browser may need to save all sorts of data locally, such as cookies. Browsers also support storage mechanisms such as localStorage, IndexedDB, WebSQL and FileSystem.
It is important to note that browsers such as Chrome run multiple instances of the rendering engine: one for each tab. Each tab runs in a separate process.
Rendering engines
The responsibility of the rendering engine is well… Rendering, that is display of the requested contents on the browser screen.
By default the rendering engine can display HTML and XML documents and images. It can display other types of data via plug-ins or extension; for example, displaying PDF documents using a PDF viewer plug-in. However, in this chapter we will focus on the main use case: displaying HTML and images that are formatted using CSS.
Different browsers use different rendering engines: Internet Explorer uses Trident, Firefox uses Gecko, Safari uses WebKit. Chrome and Opera (from version 15) use Blink, a fork of WebKit.
WebKit is an open source rendering engine which started as an engine for the Linux platform and was modified by Apple to support Mac and Windows.
The main flow
The rendering engine will start getting the contents of the requested document from the networking layer. This will usually be done in 8kB chunks.
After that, this is the basic flow of the rendering engine:
The rendering engine will start parsing the HTML document and convert elements to DOM nodes in a tree called the "content tree". The engine will parse the style data, both in external CSS files and in style elements. Styling information together with visual instructions in the HTML will be used to create another tree: the render tree .
The render tree contains rectangles with visual attributes like color and dimensions. The rectangles are in the right order to be displayed on the screen.
After the construction of the render tree it goes through a " layout " process. This means giving each node the exact coordinates where it should appear on the screen. The next stage is painting - the render tree will be traversed and each node will be painted using the UI backend layer.
It's important to understand that this is a gradual process. For better user experience, the rendering engine will try to display contents on the screen as soon as possible. It won't wait until all HTML is parsed before starting to build and layout the render tree. Parts of the content will be parsed and displayed, while the process continues with the rest of the contents that keeps coming from the network.
Main flow examples
From figures 3 and 4 you can see that although WebKit and Gecko use slightly different terminology, the flow is basically the same.
Gecko calls the tree of visually formatted elements a "Frame tree". Each element is a frame. WebKit uses the term "Render Tree" and it consists of "Render Objects". WebKit uses the term "layout" for the placing of elements, while Gecko calls it "Reflow". "Attachment" is WebKit's term for connecting DOM nodes and visual information to create the render tree. A minor non-semantic difference is that Gecko has an extra layer between the HTML and the DOM tree. It is called the "content sink" and is a factory for making DOM elements. We will talk about each part of the flow:
Parsing - general
Since parsing is a very significant process within the rendering engine, we will go into it a little more deeply. Let's begin with a little introduction about parsing.
Parsing a document means translating it to a structure the code can use. The result of parsing is usually a tree of nodes that represent the structure of the document. This is called a parse tree or a syntax tree.
For example, parsing the expression 2 + 3 - 1 could return this tree:
Грамматика
Parsing is based on the syntax rules the document obeys: the language or format it was written in. Every format you can parse must have deterministic grammar consisting of vocabulary and syntax rules. It is called a context free grammar . Human languages are not such languages and therefore cannot be parsed with conventional parsing techniques.
Parser - Lexer combination
Parsing can be separated into two sub processes: lexical analysis and syntax analysis.
Lexical analysis is the process of breaking the input into tokens. Tokens are the language vocabulary: the collection of valid building blocks. In human language it will consist of all the words that appear in the dictionary for that language.
Syntax analysis is the applying of the language syntax rules.
Parsers usually divide the work between two components: the lexer (sometimes called tokenizer) that is responsible for breaking the input into valid tokens, and the parser that is responsible for constructing the parse tree by analyzing the document structure according to the language syntax rules.
The lexer knows how to strip irrelevant characters like white spaces and line breaks.
The parsing process is iterative. The parser will usually ask the lexer for a new token and try to match the token with one of the syntax rules. If a rule is matched, a node corresponding to the token will be added to the parse tree and the parser will ask for another token.
If no rule matches, the parser will store the token internally, and keep asking for tokens until a rule matching all the internally stored tokens is found. If no rule is found then the parser will raise an exception. This means the document was not valid and contained syntax errors.
Перевод
In many cases the parse tree is not the final product. Parsing is often used in translation: transforming the input document to another format. An example is compilation. The compiler that compiles source code into machine code first parses it into a parse tree and then translates the tree into a machine code document.
Parsing example
In figure 5 we built a parse tree from a mathematical expression. Let's try to define a simple mathematical language and see the parse process.
Синтаксис:
- The language syntax building blocks are expressions, terms and operations.
- Our language can include any number of expressions.
- An expression is defined as a "term" followed by an "operation" followed by another term
- An operation is a plus token or a minus token
- A term is an integer token or an expression
Let's analyze the input 2 + 3 - 1 .
The first substring that matches a rule is 2 : according to rule #5 it is a term. The second match is 2 + 3 : this matches the third rule: a term followed by an operation followed by another term. The next match will only be hit at the end of the input. 2 + 3 - 1 is an expression because we already know that 2 + 3 is a term, so we have a term followed by an operation followed by another term. 2 + + won't match any rule and therefore is an invalid input.
Formal definitions for vocabulary and syntax
Vocabulary is usually expressed by regular expressions .
For example our language will be defined as:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
As you see, integers are defined by a regular expression.
Syntax is usually defined in a format called BNF . Our language will be defined as:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
We said that a language can be parsed by regular parsers if its grammar is a context free grammar. An intuitive definition of a context free grammar is a grammar that can be entirely expressed in BNF. For a formal definition see Wikipedia's article on Context-free grammar
Types of parsers
There are two types of parsers: top down parsers and bottom up parsers. An intuitive explanation is that top down parsers examine the high level structure of the syntax and try to find a rule match. Bottom up parsers start with the input and gradually transform it into the syntax rules, starting from the low level rules until high level rules are met.
Let's see how the two types of parsers will parse our example.
The top down parser will start from the higher level rule: it will identify 2 + 3 as an expression. It will then identify 2 + 3 - 1 as an expression (the process of identifying the expression evolves, matching the other rules, but the start point is the highest level rule).
The bottom up parser will scan the input until a rule is matched. It will then replace the matching input with the rule. This will go on until the end of the input. The partly matched expression is placed on the parser's stack.
This type of bottom up parser is called a shift-reduce parser, because the input is shifted to the right (imagine a pointer pointing first at the input start and moving to the right) and is gradually reduced to syntax rules.
Generating parsers automatically
There are tools that can generate a parser. You feed them the grammar of your language - its vocabulary and syntax rules - and they generate a working parser. Creating a parser requires a deep understanding of parsing and it's not easy to create an optimized parser by hand, so parser generators can be very useful.
WebKit uses two well known parser generators: Flex for creating a lexer and Bison for creating a parser (you might run into them with the names Lex and Yacc). Flex input is a file containing regular expression definitions of the tokens. Bison's input is the language syntax rules in BNF format.
HTML Parser
The job of the HTML parser is to parse the HTML markup into a parse tree.
HTML grammar
The vocabulary and syntax of HTML are defined in specifications created by the W3C organization.
As we have seen in the parsing introduction, grammar syntax can be defined formally using formats like BNF.
Unfortunately all the conventional parser topics don't apply to HTML (I didn't bring them up just for fun - they will be used in parsing CSS and JavaScript). HTML cannot easily be defined by a context free grammar that parsers need.
There is a formal format for defining HTML - DTD (Document Type Definition) - but it is not a context free grammar.
This appears strange at first sight; HTML is rather close to XML. There are lots of available XML parsers. There is an XML variation of HTML - XHTML - so what's the big difference?
The difference is that the HTML approach is more "forgiving": it lets you omit certain tags (which are then added implicitly), or sometimes omit start or end tags, and so on. On the whole it's a "soft" syntax, as opposed to XML's stiff and demanding syntax.
This seemingly small detail makes a world of a difference. On one hand this is the main reason why HTML is so popular: it forgives your mistakes and makes life easy for the web author. On the other hand, it makes it difficult to write a formal grammar. So to summarize, HTML cannot be parsed easily by conventional parsers, since its grammar is not context free. HTML cannot be parsed by XML parsers.
HTML DTD
HTML definition is in a DTD format. This format is used to define languages of the SGML family. The format contains definitions for all allowed elements, their attributes and hierarchy. As we saw earlier, the HTML DTD doesn't form a context free grammar.
There are a few variations of the DTD. The strict mode conforms solely to the specifications but other modes contain support for markup used by browsers in the past. The purpose is backwards compatibility with older content. The current strict DTD is here: www.w3.org/TR/html4/strict.dtd
ДОМ
The output tree (the "parse tree") is a tree of DOM element and attribute nodes. DOM is short for Document Object Model. It is the object presentation of the HTML document and the interface of HTML elements to the outside world like JavaScript.
The root of the tree is the " Document " object.
The DOM has an almost one-to-one relation to the markup. Например:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
This markup would be translated to the following DOM tree:
Like HTML, DOM is specified by the W3C organization. See www.w3.org/DOM/DOMTR . It is a generic specification for manipulating documents. A specific module describes HTML specific elements. The HTML definitions can be found here: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html .
When I say the tree contains DOM nodes, I mean the tree is constructed of elements that implement one of the DOM interfaces. Browsers use concrete implementations that have other attributes used by the browser internally.
The parsing algorithm
As we saw in the previous sections, HTML cannot be parsed using the regular top down or bottom up parsers.
The reasons are:
- The forgiving nature of the language.
- The fact that browsers have traditional error tolerance to support well known cases of invalid HTML.
- The parsing process is reentrant. For other languages, the source doesn't change during parsing, but in HTML, dynamic code (such as script elements containing
document.write()calls) can add extra tokens, so the parsing process actually modifies the input.
Unable to use the regular parsing techniques, browsers create custom parsers for parsing HTML.
The parsing algorithm is described in detail by the HTML5 specification . The algorithm consists of two stages: tokenization and tree construction.
Tokenization is the lexical analysis, parsing the input into tokens. Among HTML tokens are start tags, end tags, attribute names and attribute values.
The tokenizer recognizes the token, gives it to the tree constructor, and consumes the next character for recognizing the next token, and so on until the end of the input.
The tokenization algorithm
The algorithm's output is an HTML token. The algorithm is expressed as a state machine. Each state consumes one or more characters of the input stream and updates the next state according to those characters. The decision is influenced by the current tokenization state and by the tree construction state. This means the same consumed character will yield different results for the correct next state, depending on the current state. The algorithm is too complex to describe fully, so let's see a simple example that will help us understand the principle.
Basic example - tokenizing the following HTML:
<html>
<body>
Hello world
</body>
</html>
The initial state is the "Data state". When the < character is encountered, the state is changed to "Tag open state" . Consuming an az character causes creation of a "Start tag token", the state is changed to "Tag name state" . We stay in this state until the > character is consumed. Each character is appended to the new token name. In our case the created token is an html token.
When the > tag is reached, the current token is emitted and the state changes back to the "Data state" . The <body> tag will be treated by the same steps. So far the html and body tags were emitted. We are now back at the "Data state" . Consuming the H character of Hello world will cause creation and emitting of a character token, this goes on until the < of </body> is reached. We will emit a character token for each character of Hello world .
We are now back at the "Tag open state" . Consuming the next input / will cause creation of an end tag token and a move to the "Tag name state" . Again we stay in this state until we reach > .Then the new tag token will be emitted and we go back to the "Data state" . The </html> input will be treated like the previous case.
Tree construction algorithm
When the parser is created the Document object is created. During the tree construction stage the DOM tree with the Document in its root will be modified and elements will be added to it. Each node emitted by the tokenizer will be processed by the tree constructor. For each token the specification defines which DOM element is relevant to it and will be created for this token. The element is added to the DOM tree, and also the stack of open elements. This stack is used to correct nesting mismatches and unclosed tags. The algorithm is also described as a state machine. The states are called "insertion modes".
Let's see the tree construction process for the example input:
<html>
<body>
Hello world
</body>
</html>
The input to the tree construction stage is a sequence of tokens from the tokenization stage. The first mode is the "initial mode" . Receiving the "html" token will cause a move to the "before html" mode and a reprocessing of the token in that mode. This will cause creation of the HTMLHtmlElement element, which will be appended to the root Document object.
The state will be changed to "before head" . The "body" token is then received. An HTMLHeadElement will be created implicitly although we don't have a "head" token and it will be added to the tree.
We now move to the "in head" mode and then to "after head" . The body token is reprocessed, an HTMLBodyElement is created and inserted and the mode is transferred to "in body" .
The character tokens of the "Hello world" string are now received. The first one will cause creation and insertion of a "Text" node and the other characters will be appended to that node.
The receiving of the body end token will cause a transfer to "after body" mode. We will now receive the html end tag which will move us to "after after body" mode. Receiving the end of file token will end the parsing.
Actions when the parsing is finished
At this stage the browser will mark the document as interactive and start parsing scripts that are in "deferred" mode: those that should be executed after the document is parsed. The document state will be then set to "complete" and a "load" event will be fired.
You can see the full algorithms for tokenization and tree construction in the HTML5 specification .
Browsers' error tolerance
You never get an "Invalid Syntax" error on an HTML page. Browsers fix any invalid content and go on.
Take this HTML for example:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
I must have violated about a million rules ("mytag" is not a standard tag, wrong nesting of the "p" and "div" elements and more) but the browser still shows it correctly and doesn't complain. So a lot of the parser code is fixing the HTML author mistakes.
Error handling is quite consistent in browsers, but amazingly enough it hasn't been part of HTML specifications. Like bookmarking and back/forward buttons it's just something that developed in browsers over the years. There are known invalid HTML constructs repeated on many sites, and the browsers try to fix them in a way conformant with other browsers.
The HTML5 specification does define some of these requirements. (WebKit summarizes this nicely in the comment at the beginning of the HTML parser class.)
The parser parses tokenized input into the document, building up the document tree. If the document is well-formed, parsing it is straightforward.
Unfortunately, we have to handle many HTML documents that are not well-formed, so the parser has to be tolerant about errors.
We have to take care of at least the following error conditions:
- The element being added is explicitly forbidden inside some outer tag. In this case we should close all tags up to the one which forbids the element, and add it afterwards.
- We are not allowed to add the element directly. It could be that the person writing the document forgot some tag in between (or that the tag in between is optional). This could be the case with the following tags: HTML HEAD BODY TBODY TR TD LI (did I forget any?).
- We want to add a block element inside an inline element. Close all inline elements up to the next higher block element.
- If this doesn't help, close elements until we are allowed to add the element - or ignore the tag.
Let's see some WebKit error tolerance examples:
</br> instead of <br>
Some sites use </br> instead of <br> . In order to be compatible with IE and Firefox, WebKit treats this like <br> .
Код:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Note that the error handling is internal: it won't be presented to the user.
A stray table
A stray table is a table inside another table, but not inside a table cell.
Например:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit will change the hierarchy to two sibling tables:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Код:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit uses a stack for the current element contents: it will pop the inner table out of the outer table stack. The tables will now be siblings.
Nested form elements
In case the user puts a form inside another form, the second form is ignored.
Код:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
A too deep tag hierarchy
The comment speaks for itself.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Misplaced html or body end tags
Again - the comment speaks for itself.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
So web authors beware - unless you want to appear as an example in a WebKit error tolerance code snippet - write well formed HTML.
CSS parsing
Remember the parsing concepts in the introduction? Well, unlike HTML, CSS is a context free grammar and can be parsed using the types of parsers described in the introduction. In fact the CSS specification defines CSS lexical and syntax grammar .
Let's see some examples:
The lexical grammar (vocabulary) is defined by regular expressions for each token:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" is short for identifier, like a class name. "name" is an element id (that is referred by "#" )
The syntax grammar is described in BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Объяснение:
A ruleset is this structure:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error and a.error are selectors. The part inside the curly braces contains the rules that are applied by this ruleset. This structure is defined formally in this definition:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
This means a ruleset is a selector or optionally a number of selectors separated by a comma and spaces (S stands for white space). A ruleset contains curly braces and inside them a declaration or optionally a number of declarations separated by a semicolon. "declaration" and "selector" will be defined in the following BNF definitions.
WebKit CSS parser
WebKit uses Flex and Bison parser generators to create parsers automatically from the CSS grammar files. As you recall from the parser introduction, Bison creates a bottom up shift-reduce parser. Firefox uses a top down parser written manually. In both cases each CSS file is parsed into a StyleSheet object. Each object contains CSS rules. The CSS rule objects contain selector and declaration objects and other objects corresponding to CSS grammar.
Processing order for scripts and style sheets
Scripts
The model of the web is synchronous. Authors expect scripts to be parsed and executed immediately when the parser reaches a <script> tag. The parsing of the document halts until the script has been executed. If the script is external then the resource must first be fetched from the network - this is also done synchronously, and parsing halts until the resource is fetched. This was the model for many years and is also specified in HTML4 and 5 specifications. Authors can add the "defer" attribute to a script, in which case it won't halt document parsing and will execute after the document is parsed. HTML5 adds an option to mark the script as asynchronous so it will be parsed and executed by a different thread.
Speculative parsing
Both WebKit and Firefox do this optimization. While executing scripts, another thread parses the rest of the document and finds out what other resources need to be loaded from the network and loads them. In this way, resources can be loaded on parallel connections and overall speed is improved. Note: the speculative parser only parses references to external resources like external scripts, style sheets and images: it doesn't modify the DOM tree - that is left to the main parser.
Style sheets
Style sheets on the other hand have a different model. Conceptually it seems that since style sheets don't change the DOM tree, there is no reason to wait for them and stop the document parsing. There is an issue, though, of scripts asking for style information during the document parsing stage. If the style is not loaded and parsed yet, the script will get wrong answers and apparently this caused lots of problems. It seems to be an edge case but is quite common. Firefox blocks all scripts when there is a style sheet that is still being loaded and parsed. WebKit blocks scripts only when they try to access certain style properties that may be affected by unloaded style sheets.
Render tree construction
While the DOM tree is being constructed, the browser constructs another tree, the render tree. This tree is of visual elements in the order in which they will be displayed. It is the visual representation of the document. The purpose of this tree is to enable painting the contents in their correct order.
Firefox calls the elements in the render tree "frames". WebKit uses the term renderer or render object.
A renderer knows how to lay out and paint itself and its children.
WebKit's RenderObject class, the base class of the renderers, has the following definition:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Each renderer represents a rectangular area usually corresponding to a node's CSS box, as described by the CSS2 spec. It includes geometric information like width, height and position.
The box type is affected by the "display" value of the style attribute that is relevant to the node (see the style computation section). Here is WebKit code for deciding what type of renderer should be created for a DOM node, according to the display attribute:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
The element type is also considered: for example, form controls and tables have special frames.
In WebKit if an element wants to create a special renderer, it will override the createRenderer() method. The renderers point to style objects that contains non geometric information.
The render tree relation to the DOM tree
The renderers correspond to DOM elements, but the relation is not one to one. Non-visual DOM elements won't be inserted in the render tree. An example is the "head" element. Also elements whose display value was assigned to "none" won't appear in the tree (whereas elements with "hidden" visibility will appear in the tree).
There are DOM elements which correspond to several visual objects. These are usually elements with complex structure that cannot be described by a single rectangle. For example, the "select" element has three renderers: one for the display area, one for the drop down list box and one for the button. Also when text is broken into multiple lines because the width is not sufficient for one line, the new lines will be added as extra renderers.
Another example of multiple renderers is broken HTML. According to the CSS spec an inline element must contain either only block elements or only inline elements. In the case of mixed content, anonymous block renderers will be created to wrap the inline elements.
Some render objects correspond to a DOM node but not in the same place in the tree. Floats and absolutely positioned elements are out of flow, placed in a different part of the tree, and mapped to the real frame. A placeholder frame is where they should have been.
The flow of constructing the tree
In Firefox, the presentation is registered as a listener for DOM updates. The presentation delegates frame creation to the FrameConstructor and the constructor resolves style (see style computation ) and creates a frame.
In WebKit the process of resolving the style and creating a renderer is called "attachment". Every DOM node has an "attach" method. Attachment is synchronous, node insertion to the DOM tree calls the new node "attach" method.
Processing the html and body tags results in the construction of the render tree root. The root render object corresponds to what the CSS spec calls the containing block: the top most block that contains all other blocks. Its dimensions are the viewport: the browser window display area dimensions. Firefox calls it ViewPortFrame and WebKit calls it RenderView . This is the render object that the document points to. The rest of the tree is constructed as a DOM nodes insertion.
See the CSS2 spec on the processing model .
Style computation
Building the render tree requires calculating the visual properties of each render object. This is done by calculating the style properties of each element.
The style includes style sheets of various origins, inline style elements and visual properties in the HTML (like the "bgcolor" property).The later is translated to matching CSS style properties.
The origins of style sheets are the browser's default style sheets, the style sheets provided by the page author and user style sheets - these are style sheets provided by the browser user (browsers let you define your favorite styles. In Firefox, for instance, this is done by placing a style sheet in the "Firefox Profile" folder).
Style computation brings up a few difficulties:
- Style data is a very large construct, holding the numerous style properties, this can cause memory problems.
Finding the matching rules for each element can cause performance issues if it's not optimized. Traversing the entire rule list for each element to find matches is a heavy task. Selectors can have complex structure that can cause the matching process to start on a seemingly promising path that is proven to be futile and another path has to be tried.
For example - this compound selector:
div div div div{ ... }Means the rules apply to a
<div>who is the descendant of 3 divs. Suppose you want to check if the rule applies for a given<div>element. You choose a certain path up the tree for checking. You may need to traverse the node tree up just to find out there are only two divs and the rule does not apply. You then need to try other paths in the tree.Applying the rules involves quite complex cascade rules that define the hierarchy of the rules.
Let's see how the browsers face these issues:
Sharing style data
WebKit nodes references style objects (RenderStyle). These objects can be shared by nodes in some conditions. The nodes are siblings or cousins and:
- The elements must be in the same mouse state (eg, one can't be in :hover while the other isn't)
- Neither element should have an id
- The tag names should match
- The class attributes should match
- The set of mapped attributes must be identical
- The link states must match
- The focus states must match
- Neither element should be affected by attribute selectors, where affected is defined as having any selector match that uses an attribute selector in any position within the selector at all
- There must be no inline style attribute on the elements
- There must be no sibling selectors in use at all. WebCore simply throws a global switch when any sibling selector is encountered and disables style sharing for the entire document when they are present. This includes the + selector and selectors like :first-child and :last-child.
Firefox rule tree
Firefox has two extra trees for easier style computation: the rule tree and style context tree. WebKit also has style objects but they are not stored in a tree like the style context tree, only the DOM node points to its relevant style.
The style contexts contain end values. The values are computed by applying all the matching rules in the correct order and performing manipulations that transform them from logical to concrete values. For example, if the logical value is a percentage of the screen it will be calculated and transformed to absolute units. The rule tree idea is really clever. It enables sharing these values between nodes to avoid computing them again. This also saves space.
All the matched rules are stored in a tree. The bottom nodes in a path have higher priority. The tree contains all the paths for rule matches that were found. Storing the rules is done lazily. The tree isn't calculated at the beginning for every node, but whenever a node style needs to be computed the computed paths are added to the tree.
The idea is to see the tree paths as words in a lexicon. Lets say we already computed this rule tree:
Suppose we need to match rules for another element in the content tree, and find out the matched rules (in the correct order) are BEI. We already have this path in the tree because we already computed path ABEIL. We will now have less work to do.
Let's see how the tree saves us work.
Division into structs
The style contexts are divided into structs. Those structs contain style information for a certain category like border or color. All the properties in a struct are either inherited or non inherited. Inherited properties are properties that unless defined by the element, are inherited from its parent. Non inherited properties (called "reset" properties) use default values if not defined.
The tree helps us by caching entire structs (containing the computed end values) in the tree. The idea is that if the bottom node didn't supply a definition for a struct, a cached struct in an upper node can be used.
Computing the style contexts using the rule tree
When computing the style context for a certain element, we first compute a path in the rule tree or use an existing one. We then begin to apply the rules in the path to fill the structs in our new style context. We start at the bottom node of the path - the one with the highest precedence (usually the most specific selector) and traverse the tree up until our struct is full. If there is no specification for the struct in that rule node, then we can greatly optimize - we go up the tree until we find a node that specifies it fully and point to it - that's the best optimization - the entire struct is shared. This saves computation of end values and memory.
If we find partial definitions we go up the tree until the struct is filled.
If we didn't find any definitions for our struct then, in case the struct is an "inherited" type, we point to the struct of our parent in the context tree . In this case we also succeeded in sharing structs. If it's a reset struct then default values will be used.
If the most specific node does add values then we need to do some extra calculations for transforming it to actual values. We then cache the result in the tree node so it can be used by children.
In case an element has a sibling or a brother that points to the same tree node then the entire style context can be shared between them.
Lets see an example: Suppose we have this HTML
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
And the following rules:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
To simplify things let's say we need to fill out only two structs: the color struct and the margin struct. The color struct contains only one member: the color The margin struct contains the four sides.
The resulting rule tree will look like this (the nodes are marked with the node name: the number of the rule they point at):
The context tree will look like this (node name: rule node they point to):
Suppose we parse the HTML and get to the second <div> tag. We need to create a style context for this node and fill its style structs.
We will match the rules and discover that the matching rules for the <div> are 1, 2 and 6. This means there is already an existing path in the tree that our element can use and we just need to add another node to it for rule 6 (node F in the rule tree).
We will create a style context and put it in the context tree. The new style context will point to node F in the rule tree.
We now need to fill the style structs. We will begin by filling out the margin struct. Since the last rule node (F) doesn't add to the margin struct, we can go up the tree until we find a cached struct computed in a previous node insertion and use it. We will find it on node B, which is the uppermost node that specified margin rules.
We do have a definition for the color struct, so we can't use a cached struct. Since color has one attribute we don't need to go up the tree to fill other attributes. We will compute the end value (convert string to RGB etc) and cache the computed struct on this node.
The work on the second <span> element is even easier. We will match the rules and come to the conclusion that it points to rule G, like the previous span. Since we have siblings that point to the same node, we can share the entire style context and just point to the context of the previous span.
For structs that contain rules that are inherited from the parent, caching is done on the context tree (the color property is actually inherited, but Firefox treats it as reset and caches it on the rule tree).
For example, if we added rules for fonts in a paragraph:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Then the paragraph element, which is a child of the div in the context tree, could have shared the same font struct as his parent. This is if no font rules were specified for the paragraph.
In WebKit, who does not have a rule tree, the matched declarations are traversed four times. First non-important high priority properties are applied (properties that should be applied first because others depend on them, such as display), then high priority important, then normal priority non-important, then normal priority important rules. This means that properties that appear multiple times will be resolved according to the correct cascade order. The last wins.
So to summarize: sharing the style objects (entirely or some of the structs inside them) solves issues 1 and 3. The Firefox rule tree also helps in applying the properties in the correct order.
Manipulating the rules for an easy match
There are several sources for style rules:
- CSS rules, either in external style sheets or in style elements.
css p {color: blue} - Inline style attributes like
html <p style="color: blue" /> - HTML visual attributes (which are mapped to relevant style rules)
html <p bgcolor="blue" />The last two are easily matched to the element since he owns the style attributes and HTML attributes can be mapped using the element as the key.
As noted previously in issue #2, the CSS rule matching can be trickier. To solve the difficulty, the rules are manipulated for easier access.
After parsing the style sheet, the rules are added to one of several hash maps, according to the selector. There are maps by id, by class name, by tag name and a general map for anything that doesn't fit into those categories. If the selector is an id, the rule will be added to the id map, if it's a class it will be added to the class map etc.
This manipulation makes it much easier to match rules. There is no need to look in every declaration: we can extract the relevant rules for an element from the maps. This optimization eliminates 95+% of the rules, so that they need not even be considered during the matching process(4.1).
Let's see for example the following style rules:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
The first rule will be inserted into the class map. The second into the id map and the third into the tag map.
For the following HTML fragment;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
We will first try to find rules for the p element. The class map will contain an "error" key under which the rule for "p.error" is found. The div element will have relevant rules in the id map (the key is the id) and the tag map. So the only work left is finding out which of the rules that were extracted by the keys really match.
For example if the rule for the div was:
table div {margin: 5px}
It will still be extracted from the tag map, because the key is the rightmost selector, but it wouldn't match our div element, who does not have a table ancestor.
Both WebKit and Firefox do this manipulation.
Style sheet cascade order
The style object has properties corresponding to every visual attribute (all CSS attributes but more generic). If the property is not defined by any of the matched rules, then some properties can be inherited by the parent element style object. Other properties have default values.
The problem begins when there is more than one definition - here comes the cascade order to solve the issue.
A declaration for a style property can appear in several style sheets, and several times inside a style sheet. This means the order of applying the rules is very important. This is called the "cascade" order. According to CSS2 spec, the cascade order is (from low to high):
- Browser declarations
- User normal declarations
- Author normal declarations
- Author important declarations
- User important declarations
The browser declarations are least important and the user overrides the author only if the declaration was marked as important. Declarations with the same order will be sorted by specificity and then the order they are specified. The HTML visual attributes are translated to matching CSS declarations . They are treated as author rules with low priority.
Specificity
The selector specificity is defined by the CSS2 specification as follows:
- count 1 if the declaration it is from is a 'style' attribute rather than a rule with a selector, 0 otherwise (= a)
- count the number of ID attributes in the selector (= b)
- count the number of other attributes and pseudo-classes in the selector (= c)
- count the number of element names and pseudo-elements in the selector (= d)
Concatenating the four numbers abcd (in a number system with a large base) gives the specificity.
The number base you need to use is defined by the highest count you have in one of the categories.
For example, if a=14 you can use hexadecimal base. In the unlikely case where a=17 you will need a 17 digits number base. The later situation can happen with a selector like this: html body div div p… (17 tags in your selector… not very likely).
Несколько примеров:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Sorting the rules
After the rules are matched, they are sorted according to the cascade rules. WebKit uses bubble sort for small lists and merge sort for big ones. WebKit implements sorting by overriding the > operator for the rules:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Gradual process
WebKit uses a flag that marks if all top level style sheets (including @imports) have been loaded. If the style is not fully loaded when attaching, place holders are used and it is marked in the document, and they will be recalculated once the style sheets were loaded.
Макет
When the renderer is created and added to the tree, it does not have a position and size. Calculating these values is called layout or reflow.
HTML uses a flow based layout model, meaning that most of the time it is possible to compute the geometry in a single pass. Elements later "in the flow" typically don't affect the geometry of elements that are earlier "in the flow", so layout can proceed left-to-right, top-to-bottom through the document. There are exceptions: for example, HTML tables may require more than one pass.
The coordinate system is relative to the root frame. Top and left coordinates are used.
Layout is a recursive process. It begins at the root renderer, which corresponds to the <html> element of the HTML document. Layout continues recursively through some or all of the frame hierarchy, computing geometric information for each renderer that requires it.
The position of the root renderer is 0,0 and its dimensions are the viewport - the visible part of the browser window.
All renderers have a "layout" or "reflow" method, each renderer invokes the layout method of its children that need layout.
Dirty bit system
In order not to do a full layout for every small change, browsers use a "dirty bit" system. A renderer that is changed or added marks itself and its children as "dirty": needing layout.
There are two flags: "dirty", and "children are dirty" which means that although the renderer itself may be OK, it has at least one child that needs a layout.
Global and incremental layout
Layout can be triggered on the entire render tree - this is "global" layout. This can happen as a result of:
- A global style change that affects all renderers, like a font size change.
- As a result of a screen being resized
Layout can be incremental, only the dirty renderers will be laid out (this can cause some damage which will require extra layouts).
Incremental layout is triggered (asynchronously) when renderers are dirty. For example when new renderers are appended to the render tree after extra content came from the network and was added to the DOM tree.
Asynchronous and Synchronous layout
Incremental layout is done asynchronously. Firefox queues "reflow commands" for incremental layouts and a scheduler triggers batch execution of these commands. WebKit also has a timer that executes an incremental layout - the tree is traversed and "dirty" renderers are layout out.
Scripts asking for style information, like "offsetHeight" can trigger incremental layout synchronously.
Global layout will usually be triggered synchronously.
Sometimes layout is triggered as a callback after an initial layout because some attributes, like the scrolling position changed.
Оптимизации
When a layout is triggered by a "resize" or a change in the renderer position(and not size), the renders sizes are taken from a cache and not recalculated…
In some cases only a sub tree is modified and layout does not start from the root. This can happen in cases where the change is local and does not affect its surroundings - like text inserted into text fields (otherwise every keystroke would trigger a layout starting from the root).
The layout process
The layout usually has the following pattern:
- Parent renderer determines its own width.
- Parent goes over children and:
- Place the child renderer (sets its x and y).
- Calls child layout if needed - they are dirty or we are in a global layout, or for some other reason - which calculates the child's height.
- Parent uses children's accumulative heights and the heights of margins and padding to set its own height - this will be used by the parent renderer's parent.
- Sets its dirty bit to false.
Firefox uses a "state" object(nsHTMLReflowState) as a parameter to layout (termed "reflow"). Among others the state includes the parents width.
The output of the Firefox layout is a "metrics" object(nsHTMLReflowMetrics). It will contain the renderer computed height.
Width calculation
The renderer's width is calculated using the container block's width, the renderer's style "width" property, the margins and borders.
For example the width of the following div:
<div style="width: 30%"/>
Would be calculated by WebKit as the following(class RenderBox method calcWidth):
- The container width is the maximum of the containers availableWidth and 0. The availableWidth in this case is the contentWidth which is calculated as:
clientWidth() - paddingLeft() - paddingRight()
clientWidth and clientHeight represent the interior of an object excluding border and scrollbar.
The elements width is the "width" style attribute. It will be calculated as an absolute value by computing the percentage of the container width.
The horizontal borders and paddings are now added.
So far this was the calculation of the "preferred width". Now the minimum and maximum widths will be calculated.
If the preferred width is greater than the maximum width, the maximum width is used. If it is less than the minimum width (the smallest unbreakable unit) then the minimum width is used.
The values are cached in case a layout is needed, but the width does not change.
Line Breaking
When a renderer in the middle of a layout decides that it needs to break, the renderer stops and propagates to the layout's parent that it needs to be broken. The parent creates the extra renderers and calls layout on them.
Рисование
In the painting stage, the render tree is traversed and the renderer's "paint()" method is called to display content on the screen. Painting uses the UI infrastructure component.
Global and incremental
Like layout, painting can also be global - the entire tree is painted - or incremental. In incremental painting, some of the renderers change in a way that does not affect the entire tree. The changed renderer invalidates its rectangle on the screen. This causes the OS to see it as a "dirty region" and generate a "paint" event. The OS does it cleverly and coalesces several regions into one. In Chrome it is more complicated because the renderer is in a different process then the main process. Chrome simulates the OS behavior to some extent. The presentation listens to these events and delegates the message to the render root. The tree is traversed until the relevant renderer is reached. It will repaint itself (and usually its children).
The painting order
CSS2 defines the order of the painting process . This is actually the order in which the elements are stacked in the stacking contexts . This order affects painting since the stacks are painted from back to front. The stacking order of a block renderer is:
- цвет фона
- background image
- граница
- дети
- контур
Firefox display list
Firefox goes over the render tree and builds a display list for the painted rectangular. It contains the renderers relevant for the rectangular, in the right painting order (backgrounds of the renderers, then borders etc).
That way the tree needs to be traversed only once for a repaint instead of several times - painting all backgrounds, then all images, then all borders etc.
Firefox optimizes the process by not adding elements that will be hidden, like elements completely beneath other opaque elements.
WebKit rectangle storage
Before repainting, WebKit saves the old rectangle as a bitmap. It then paints only the delta between the new and old rectangles.
Dynamic changes
The browsers try to do the minimal possible actions in response to a change. So changes to an element's color will cause only repaint of the element. Changes to the element position will cause layout and repaint of the element, its children and possibly siblings. Adding a DOM node will cause layout and repaint of the node. Major changes, like increasing font size of the "html" element, will cause invalidation of caches, relayout and repaint of the entire tree.
The rendering engine's threads
The rendering engine is single threaded. Almost everything, except network operations, happens in a single thread. In Firefox and Safari this is the main thread of the browser. In Chrome it's the tab process main thread.
Network operations can be performed by several parallel threads. The number of parallel connections is limited (usually 2 - 6 connections).
Event loop
The browser main thread is an event loop. It's an infinite loop that keeps the process alive. It waits for events (like layout and paint events) and processes them. This is Firefox code for the main event loop:
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 visual model
The canvas
According to the CSS2 specification , the term canvas describes "the space where the formatting structure is rendered": where the browser paints the content.
The canvas is infinite for each dimension of the space but browsers choose an initial width based on the dimensions of the viewport.
According to www.w3.org/TR/CSS2/zindex.html , the canvas is transparent if contained within another, and given a browser defined color if it is not.
CSS Box model
The CSS box model describes the rectangular boxes that are generated for elements in the document tree and laid out according to the visual formatting model.
Each box has a content area (eg text, an image, etc.) and optional surrounding padding, border, and margin areas.
Each node generates 0…n such boxes.
All elements have a "display" property that determines the type of box that will be generated.
Примеры:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
The default is inline but the browser style sheet may set other defaults. For example: the default display for the "div" element is block.
You can find a default style sheet example here: www.w3.org/TR/CSS2/sample.html .
Positioning scheme
There are three schemes:
- Normal: the object is positioned according to its place in the document. This means its place in the render tree is like its place in the DOM tree and laid out according to its box type and dimensions
- Float: the object is first laid out like normal flow, then moved as far left or right as possible
- Absolute: the object is put in the render tree in a different place than in the DOM tree
The positioning scheme is set by the "position" property and the "float" attribute.
- static and relative cause a normal flow
- absolute and fixed cause absolute positioning
In static positioning no position is defined and the default positioning is used. In the other schemes, the author specifies the position: top, bottom, left, right.
The way the box is laid out is determined by:
- Box type
- Box dimensions
- Positioning scheme
- External information such as image size and the size of the screen
Box types
Block box: forms a block - has its own rectangle in the browser window.
Inline box: does not have its own block, but is inside a containing block.
Blocks are formatted vertically one after the other. Inlines are formatted horizontally.
Inline boxes are put inside lines or "line boxes". The lines are at least as tall as the tallest box but can be taller, when the boxes are aligned "baseline" - meaning the bottom part of an element is aligned at a point of another box other then the bottom. If the container width is not enough, the inlines will be put on several lines. This is usually what happens in a paragraph.
Positioning
Родственник
Relative positioning - positioned like usual and then moved by the required delta.
Floats
A float box is shifted to the left or right of a line. The interesting feature is that the other boxes flow around it. The HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Will look like:
Absolute and fixed
The layout is defined exactly regardless of the normal flow. The element does not participate in the normal flow. The dimensions are relative to the container. In fixed, the container is the viewport.
Layered representation
This is specified by the z-index CSS property. It represents the third dimension of the box: its position along the "z axis".
The boxes are divided into stacks (called stacking contexts). In each stack the back elements will be painted first and the forward elements on top, closer to the user. In case of overlap the foremost element will hide the former element.
The stacks are ordered according to the z-index property. Boxes with "z-index" property form a local stack. The viewport has the outer stack.
Пример:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
The result will be this:
Although the red div precedes the green one in the markup, and would have been painted before in the regular flow, the z-index property is higher, so it is more forward in the stack held by the root box.
Ресурсы
Browser architecture
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf)
- Gupta, Vineet. How Browsers Work - Part 1 - Architecture
Разбор
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: two new drafts for HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron, Mozilla's Layout Engine
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, Gecko Overview
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, WebCore Rendering
- David Hyatt, The FOUC Problem
W3C Specifications
Browsers build instructions
Переводы
This page has been translated into Japanese, twice:
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) by @ kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側by @ikeike443 and @kiyoto01 .
You can view the externally hosted translations of Korean and Turkish .
Спасибо всем!