
เบื้องหลังการทำงานของเว็บเบราว์เซอร์สมัยใหม่


บทนำ
ข้อมูลเบื้องต้นที่ครอบคลุมนี้เกี่ยวกับการทำงานของ WebKit และ Gecko ภายในเป็นผลมาจากการวิจัยที่ Tali Garsiel นักพัฒนาซอฟต์แวร์ชาวอิสราเอลทําไว้ ในช่วงหลายปีที่ผ่านมา เธอได้ตรวจสอบข้อมูลที่เผยแพร่ทั้งหมดเกี่ยวกับส่วนภายในของเบราว์เซอร์และใช้เวลาอ่านซอร์สโค้ดของเว็บเบราว์เซอร์เป็นจำนวนมาก เธอเขียนว่า
ในฐานะนักพัฒนาเว็บ การเรียนรู้ข้อมูลภายในของการทำงานของเบราว์เซอร์จะช่วยคุณตัดสินใจได้ดียิ่งขึ้นและทราบเหตุผลเบื้องหลังแนวทางปฏิบัติแนะนำในการพัฒนา แม้ว่าเอกสารนี้จะค่อนข้างยาว แต่เราขอแนะนำให้คุณอ่านอย่างละเอียด แล้วคุณจะชอบ
Paul Irish จากทีมพัฒนาความสัมพันธ์กับนักพัฒนาซอฟต์แวร์ของ Chrome
บทนำ
เว็บเบราว์เซอร์เป็นซอฟต์แวร์ที่มีการใช้งานแพร่หลายที่สุด ในบทแนะนํานี้ เราจะอธิบายวิธีทํางานของเครื่องมือเหล่านี้ในเบื้องหลัง เราจะดูสิ่งที่เกิดขึ้นเมื่อคุณพิมพ์ google.com
ในแถบที่อยู่จนกว่าจะเห็นหน้า Google บนหน้าจอเบราว์เซอร์
เบราว์เซอร์ที่เราจะพูดถึง
ปัจจุบันมีเบราว์เซอร์หลัก 5 รายการที่ใช้ในเดสก์ท็อป ได้แก่ Chrome, Internet Explorer, Firefox, Safari และ Opera บนอุปกรณ์เคลื่อนที่ เบราว์เซอร์หลักๆ ได้แก่ เบราว์เซอร์ Android, iPhone, Opera Mini และ Opera Mobile, UC Browser, เบราว์เซอร์ Nokia S40/S60 และ Chrome ซึ่งทั้งหมดใช้ WebKit ยกเว้นเบราว์เซอร์ Opera เราจะยกตัวอย่างจากเบราว์เซอร์โอเพนซอร์สอย่าง Firefox และ Chrome รวมถึง Safari (ซึ่งเป็นโอเพนซอร์สบางส่วน) ตามสถิติ StatCounter (ข้อมูลเดือนมิถุนายน 2013) Chrome, Firefox และ Safari คิดเป็นสัดส่วนประมาณ 71% ของการใช้งานเบราว์เซอร์บนเดสก์ท็อปทั่วโลก บนอุปกรณ์เคลื่อนที่ เบราว์เซอร์ Android, iPhone และ Chrome คิดเป็นสัดส่วนการใช้งานประมาณ 54%
ฟังก์ชันหลักของเบราว์เซอร์
ฟังก์ชันหลักของเบราว์เซอร์คือแสดงทรัพยากรบนเว็บที่คุณเลือก โดยขอทรัพยากรจากเซิร์ฟเวอร์และแสดงในหน้าต่างเบราว์เซอร์ โดยปกติแล้ว ทรัพยากรจะเป็นเอกสาร HTML แต่อาจเป็น PDF, รูปภาพ หรือเนื้อหาประเภทอื่นๆ ก็ได้ ผู้ใช้ระบุตำแหน่งของทรัพยากรโดยใช้ URI (Uniform Resource Identifier)
วิธีที่เบราว์เซอร์ตีความและแสดงไฟล์ HTML จะระบุไว้ในข้อกำหนดของ HTML และ CSS ข้อกำหนดเหล่านี้ได้รับการดูแลโดยองค์กร W3C (World Wide Web Consortium) ซึ่งเป็นองค์กรมาตรฐานสำหรับเว็บ เป็นเวลาหลายปีที่เบราว์เซอร์ปฏิบัติตามข้อกำหนดเพียงบางส่วนและสร้างส่วนขยายของตนเอง ซึ่งทำให้เกิดปัญหาความเข้ากันได้อย่างร้ายแรงสำหรับผู้เขียนเว็บ ปัจจุบันเบราว์เซอร์ส่วนใหญ่เป็นไปตามข้อกำหนดนี้ไม่มากก็น้อย
อินเทอร์เฟซผู้ใช้ของเบราว์เซอร์มีความคล้ายคลึงกันมาก องค์ประกอบอินเทอร์เฟซผู้ใช้ที่พบบ่อย ได้แก่
- แถบที่อยู่สําหรับแทรก URI
- ปุ่มย้อนกลับและไปข้างหน้า
- ตัวเลือกบุ๊กมาร์ก
- ปุ่มรีเฟรชและหยุดสำหรับรีเฟรชหรือหยุดการโหลดเอกสารปัจจุบัน
- ปุ่มหน้าแรกที่นําคุณไปยังหน้าแรก
น่าแปลกที่อินเทอร์เฟซผู้ใช้ของเบราว์เซอร์ไม่ได้ระบุไว้ในข้อกำหนดอย่างเป็นทางการใดๆ แต่มาจากแนวทางปฏิบัติแนะนำที่พัฒนาขึ้นจากประสบการณ์หลายปีและเบราว์เซอร์ที่เลียนแบบกัน ข้อกำหนด HTML5 ไม่ได้กำหนดองค์ประกอบ UI ที่เบราว์เซอร์ต้องมี แต่ระบุองค์ประกอบทั่วไปบางรายการ ซึ่งรวมถึงแถบที่อยู่ แถบสถานะ และแถบเครื่องมือ แต่ก็มีฟีเจอร์เฉพาะสำหรับบางเบราว์เซอร์ เช่น เครื่องมือจัดการการดาวน์โหลดของ Firefox
โครงสร้างพื้นฐานระดับสูง
คอมโพเนนต์หลักของเบราว์เซอร์มีดังนี้
- อินเทอร์เฟซผู้ใช้: ซึ่งรวมถึงแถบที่อยู่ ปุ่มย้อนกลับ/ไปข้างหน้า เมนูบุ๊กมาร์ก ฯลฯ การแสดงผลทุกส่วนของเบราว์เซอร์ ยกเว้นหน้าต่างที่คุณเห็นหน้าที่ขอ
- เครื่องมือของเบราว์เซอร์: จัดระเบียบการดำเนินการระหว่าง UI กับเครื่องมือแสดงผล
- เครื่องมือแสดงผล: รับผิดชอบในการแสดงเนื้อหาที่ขอ ตัวอย่างเช่น หากเนื้อหาที่ขอเป็น HTML เครื่องมือแสดงผลจะแยกวิเคราะห์ HTML และ CSS และแสดงเนื้อหาที่แยกวิเคราะห์บนหน้าจอ
- การทํางานของเครือข่าย: สําหรับการเรียกใช้เครือข่าย เช่น คําขอ HTTP โดยใช้การติดตั้งใช้งานที่แตกต่างกันสําหรับแพลตฟอร์มต่างๆ ที่อยู่เบื้องหลังอินเทอร์เฟซที่ไม่ขึ้นอยู่กับแพลตฟอร์ม
- แบ็กเอนด์ UI: ใช้สำหรับวาดวิดเจ็ตพื้นฐาน เช่น ช่องตัวเลือกแบบเลื่อนลงและหน้าต่าง แบ็กเอนด์นี้จะแสดงอินเทอร์เฟซทั่วไปที่ไม่ใช่แพลตฟอร์มที่เฉพาะเจาะจง ด้านล่างจะใช้เมธอดอินเทอร์เฟซผู้ใช้ของระบบปฏิบัติการ
- โปรแกรมตีความ JavaScript ใช้เพื่อแยกวิเคราะห์และเรียกใช้โค้ด JavaScript
- พื้นที่เก็บข้อมูล นี่คือเลเยอร์การคงข้อมูล เบราว์เซอร์อาจต้องบันทึกข้อมูลทุกประเภทไว้ในเครื่อง เช่น คุกกี้ นอกจากนี้ เบราว์เซอร์ยังรองรับกลไกพื้นที่เก็บข้อมูล เช่น localStorage, IndexedDB, WebSQL และ FileSystem
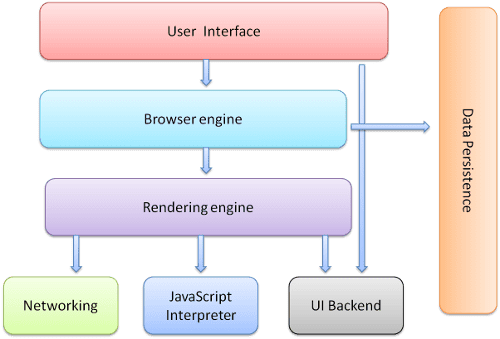
โปรดทราบว่าเบราว์เซอร์อย่าง Chrome จะเรียกใช้อินสแตนซ์ของเครื่องมือแสดงผลหลายรายการ โดยแต่ละแท็บจะมี 1 อินสแตนซ์ แต่ละแท็บจะทำงานในกระบวนการแยกกัน
เครื่องมือแสดงผล
หน้าที่ของเครื่องมือแสดงผลคือการแสดงผล นั่นคือการแสดงเนื้อหาที่ขอบนหน้าจอเบราว์เซอร์
โดยค่าเริ่มต้น เครื่องมือแสดงผลจะแสดงเอกสาร HTML และ XML รวมถึงรูปภาพได้ โดยสามารถแสดงข้อมูลประเภทอื่นๆ ผ่านปลั๊กอินหรือส่วนขยาย เช่น การแสดงเอกสาร PDF โดยใช้ปลั๊กอินโปรแกรมดู PDF อย่างไรก็ตาม ในบทนี้เราจะมุ่งเน้นที่กรณีการใช้งานหลักๆ ซึ่งก็คือการแสดง HTML และรูปภาพที่จัดรูปแบบโดยใช้ CSS
เบราว์เซอร์แต่ละประเภทใช้เครื่องมือแสดงผลที่แตกต่างกัน เช่น Internet Explorer ใช้ Trident, Firefox ใช้ Gecko และ Safari ใช้ WebKit Chrome และ Opera (ตั้งแต่เวอร์ชัน 15) ใช้ Blink ซึ่งเป็นเว็บเบราว์เซอร์ที่แยกมาจาก WebKit
WebKit เป็นเครื่องมือแสดงผลแบบโอเพนซอร์สที่เริ่มต้นจากเครื่องมือสำหรับแพลตฟอร์ม Linux และ Apple นำมาแก้ไขให้รองรับ Mac และ Windows
ขั้นตอนหลัก
เครื่องมือแสดงผลจะเริ่มรับเนื้อหาของเอกสารที่ขอจากเลเยอร์การทํางานของเครือข่าย ซึ่งโดยปกติจะดำเนินการเป็นกลุ่มขนาด 8KB
หลังจากนั้น ขั้นตอนพื้นฐานของเครื่องมือแสดงผลมีดังนี้

เครื่องมือแสดงผลจะเริ่มแยกวิเคราะห์เอกสาร HTML และแปลงองค์ประกอบเป็นโหนด DOM ในต้นไม้ที่เรียกว่า "ต้นไม้เนื้อหา" เครื่องมือนี้จะแยกวิเคราะห์ข้อมูลสไตล์ทั้งในไฟล์ CSS ภายนอกและองค์ประกอบสไตล์ ระบบจะใช้ข้อมูลการจัดรูปแบบพร้อมกับวิธีการแสดงภาพใน HTML เพื่อสร้างต้นไม้อีกต้นหนึ่งที่เรียกว่าต้นไม้แสดงผล
ต้นไม้เรนเดอร์ประกอบด้วยสี่เหลี่ยมผืนผ้าที่มีแอตทริบิวต์ภาพ เช่น สีและมิติข้อมูล สี่เหลี่ยมผืนผ้าอยู่ในลําดับที่ถูกต้องที่จะแสดงบนหน้าจอ
หลังจากสร้างต้นไม้เรนเดอร์แล้ว ระบบจะเข้าสู่กระบวนการ "เลย์เอาต์" ซึ่งหมายความว่าให้พิกัดที่แน่นอนแก่แต่ละโหนดซึ่งควรปรากฏบนหน้าจอ ระยะถัดไปคือการวาด - ระบบจะเรียกใช้เรนเดอร์ทรีและวาดแต่ละโหนดโดยใช้เลเยอร์แบ็กเอนด์ UI
โปรดทราบว่าการดำเนินการนี้จะเป็นไปอย่างค่อยเป็นค่อยไป เครื่องมือแสดงผลจะพยายามแสดงเนื้อหาบนหน้าจอโดยเร็วที่สุดเพื่อให้ผู้ใช้ได้รับประสบการณ์การใช้งานที่ดียิ่งขึ้น โดยจะไม่รอจนกว่าระบบจะแยกวิเคราะห์ HTML ทั้งหมดก่อนเริ่มสร้างและวางเลย์เอาต์ของต้นไม้แสดงผล ระบบจะแยกวิเคราะห์และแสดงเนื้อหาบางส่วน ขณะที่ดำเนินการกับเนื้อหาที่เหลือที่มาจากเครือข่ายต่อไป
ตัวอย่างโฟลว์หลัก
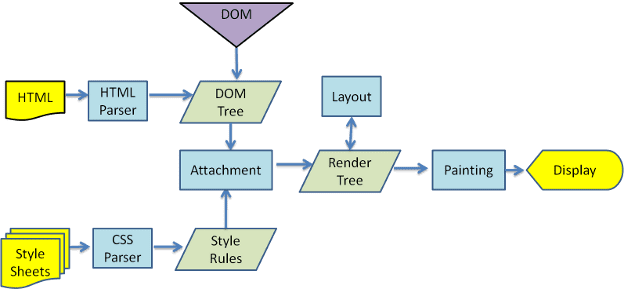
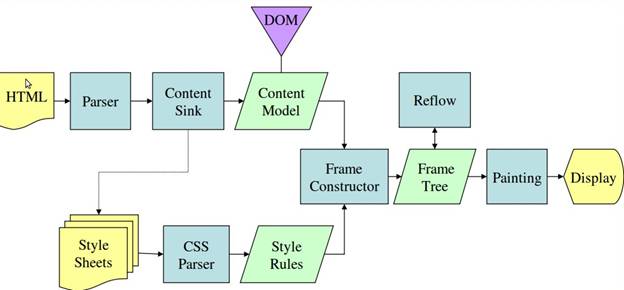
จากรูปที่ 3 และ 4 คุณจะเห็นได้ว่าแม้ว่า WebKit และ Gecko จะใช้คำศัพท์ที่แตกต่างกันเล็กน้อย แต่โดยพื้นฐานแล้วขั้นตอนจะเหมือนกัน
Gecko เรียกต้นไม้ขององค์ประกอบที่มีการจัดรูปแบบเป็นภาพว่า "ต้นไม้เฟรม" แต่ละองค์ประกอบคือเฟรม WebKit ใช้คำว่า "Render Tree" ซึ่งประกอบด้วย "Render Object" WebKit ใช้คำว่า "เลย์เอาต์" สำหรับการวางองค์ประกอบ ส่วน Gecko เรียกว่า "การจัดเรียงใหม่" "ไฟล์แนบ" เป็นคําที่ WebKit ใช้เรียกการเชื่อมต่อโหนด DOM กับข้อมูลภาพเพื่อสร้างต้นไม้การแสดงผล ความแตกต่างที่ไม่เกี่ยวข้องกับความหมายเล็กน้อยคือ Gecko มีเลเยอร์เพิ่มเติมระหว่าง HTML กับ DOM องค์ประกอบนี้เรียกว่า "ซิงค์เนื้อหา" และเป็นโรงงานสำหรับสร้างองค์ประกอบ DOM เราจะพูดถึงแต่ละส่วนของขั้นตอนดังนี้
การแยกวิเคราะห์ - ทั่วไป
เนื่องจากการแยกวิเคราะห์เป็นกระบวนการที่สำคัญมากในเครื่องมือแสดงผล เราจึงจะเจาะลึกเรื่องนี้กันสักหน่อย มาเริ่มกันด้วยการแนะนําสั้นๆ เกี่ยวกับการแยกวิเคราะห์
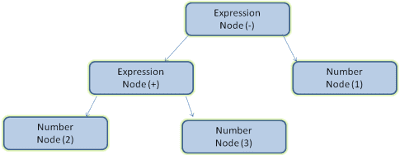
การแยกวิเคราะห์เอกสารหมายถึงการแปลเอกสารเป็นโครงสร้างที่โค้ดใช้ได้ ผลลัพธ์ของการแยกวิเคราะห์มักจะเป็นต้นไม้ของโหนดที่แสดงถึงโครงสร้างของเอกสาร ซึ่งเรียกว่าต้นไม้พาสคําหรือต้นไม้ไวยากรณ์
เช่น การแยกวิเคราะห์นิพจน์ 2 + 3 - 1 อาจแสดงผลเป็นต้นไม้นี้
ไวยากรณ์
การแยกวิเคราะห์จะอิงตามกฎไวยากรณ์ที่เอกสารปฏิบัติตาม ซึ่งก็คือภาษาหรือรูปแบบที่เขียน รูปแบบทั้งหมดที่คุณแยกวิเคราะห์ได้ต้องมีไวยากรณ์แบบกำหนดได้ ซึ่งประกอบด้วยคําศัพท์และกฎไวยากรณ์ ภาษาดังกล่าวเรียกว่าไวยากรณ์แบบไม่ขึ้นกับบริบท ภาษามนุษย์ไม่ใช่ภาษาดังกล่าว จึงไม่สามารถแยกวิเคราะห์ด้วยเทคนิคการแยกวิเคราะห์แบบดั้งเดิมได้
โปรแกรมแยกวิเคราะห์ - โปรแกรมแยกวิเคราะห์ข้อความ
การวิเคราะห์เชิงข้อความแบ่งออกเป็น 2 กระบวนการย่อย ได้แก่ การวิเคราะห์เชิงคําศัพท์และการวิเคราะห์ไวยากรณ์
การวิเคราะห์เชิงคำศัพท์คือกระบวนการแบ่งอินพุตออกเป็นโทเค็น โทเค็นคือคําศัพท์ของภาษา ซึ่งเป็นคอลเล็กชันองค์ประกอบพื้นฐานที่ถูกต้อง ในรูปแบบที่มนุษย์อ่านได้ พจนานุกรมจะประกอบด้วยคำทั้งหมดที่ปรากฏในพจนานุกรมของภาษานั้น
การวิเคราะห์ไวยากรณ์คือการใช้กฎไวยากรณ์ของภาษา
โดยปกติแล้ว โปรแกรมแยกวิเคราะห์จะแบ่งงานระหว่างคอมโพเนนต์ 2 รายการ ได้แก่ โปรแกรมแยกคำ (บางครั้งเรียกว่าโปรแกรมแยกชุดอักขระ) ซึ่งมีหน้าที่แบ่งอินพุตออกเป็นโทเค็นที่ถูกต้อง และโปรแกรมแยกวิเคราะห์ซึ่งมีหน้าที่สร้างต้นไม้แยกวิเคราะห์โดยการวิเคราะห์โครงสร้างเอกสารตามกฎไวยากรณ์ของภาษา
โปรแกรมแยกวิเคราะห์จะรู้วิธีตัดอักขระที่ไม่เกี่ยวข้อง เช่น เว้นวรรคและการขึ้นบรรทัดใหม่
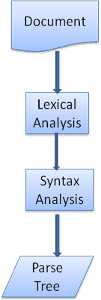
กระบวนการแยกวิเคราะห์เป็นกระบวนการที่ต้องทำซ้ำ โดยปกติแล้ว โปรแกรมแยกวิเคราะห์จะขอโทเค็นใหม่จากโปรแกรมแยกวิเคราะห์ข้อความ และพยายามจับคู่โทเค็นกับกฎไวยากรณ์ข้อใดข้อหนึ่ง หากพบกฎที่ตรงกัน ระบบจะเพิ่มโหนดที่สอดคล้องกับโทเค็นนั้นลงในต้นไม้การแยกวิเคราะห์ และโปรแกรมแยกวิเคราะห์จะขอโทเค็นอื่น
หากไม่มีกฎที่ตรงกัน โปรแกรมแยกวิเคราะห์จะจัดเก็บโทเค็นไว้ในที่เก็บข้อมูลภายใน และขอโทเค็นต่อไปจนกว่าจะพบกฎที่ตรงกับโทเค็นที่จัดเก็บไว้ในที่เก็บข้อมูลภายในทั้งหมด หากไม่พบกฎใดๆ โปรแกรมแยกวิเคราะห์จะแสดงข้อยกเว้น ซึ่งหมายความว่าเอกสารไม่ถูกต้องและมีข้อผิดพลาดทางไวยากรณ์
การแปล
ในหลายกรณี ต้นไม้พาสเซนด์ไม่ใช่ผลิตภัณฑ์ขั้นสุดท้าย การวิเคราะห์ข้อมูลมักใช้ในการแปลภาษา โดยเปลี่ยนรูปแบบเอกสารอินพุตเป็นรูปแบบอื่น เช่น การคอมไพล์ คอมไพเลอร์ที่คอมไพล์ซอร์สโค้ดเป็นรหัสเครื่องจะแยกวิเคราะห์ซอร์สโค้ดเป็นต้นไม้การแยกวิเคราะห์ก่อน จากนั้นจึงแปลต้นไม้เป็นเอกสารรหัสเครื่อง
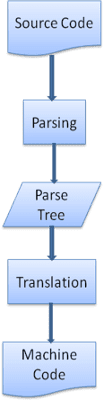
ตัวอย่างการแยกวิเคราะห์
ในรูปที่ 5 เราได้สร้างต้นไม้พาร์สจากนิพจน์ทางคณิตศาสตร์ ลองกำหนดภาษาทางคณิตศาสตร์แบบง่ายและดูกระบวนการแยกวิเคราะห์กัน
ไวยากรณ์:
- องค์ประกอบพื้นฐานของไวยากรณ์ภาษาคือนิพจน์ เงื่อนไข และการดำเนินการ
- ภาษาของเรามีนิพจน์ได้กี่รายการก็ได้
- นิพจน์หมายถึง "คํา" ตามด้วย "การดำเนินการ" ตามด้วยคําอื่น
- การดำเนินการคือโทเค็นบวกหรือโทเค็นลบ
- เทอมคือโทเค็นจำนวนเต็มหรือนิพจน์
มาวิเคราะห์อินพุต 2 + 3 - 1 กัน
สตริงย่อยแรกที่ตรงกับกฎคือ 2: กฎ #5 ระบุว่าเป็นคํา
การจับคู่ที่ 2 คือ 2 + 3: การจับคู่นี้ตรงกับกฎข้อที่ 3 ซึ่งเป็นคําตามด้วยการดำเนินการตามด้วยคําอื่น
การจับคู่ครั้งถัดไปจะเกิดขึ้นเมื่อสิ้นสุดอินพุตเท่านั้น
2 + 3 - 1 เป็นนิพจน์เนื่องจากเราทราบอยู่แล้วว่า 2 + 3 เป็นคํา เราจึงมีคําตามด้วยการดำเนินการตามด้วยคําอื่น
2 + + จะไม่ตรงกับกฎใดๆ และจึงเป็นอินพุตที่ไม่ถูกต้อง
คําจํากัดความอย่างเป็นทางการสําหรับคําศัพท์และไวยากรณ์
โดยปกติแล้วคําศัพท์จะแสดงด้วยนิพจน์ทั่วไป
ตัวอย่างเช่น ภาษาของเราจะกำหนดเป็น
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
ดังที่คุณเห็น จํานวนเต็มจะกําหนดโดยนิพจน์ทั่วไป
โดยปกติไวยากรณ์จะกำหนดในรูปแบบที่เรียกว่า BNF ภาษาของเราจะกำหนดดังนี้
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
เราได้บอกว่าภาษาหนึ่งๆ สามารถแยกวิเคราะห์ได้โดยโปรแกรมแยกวิเคราะห์ทั่วไปหากไวยากรณ์ของภาษานั้นเป็นไวยากรณ์แบบไม่มีบริบท คำจำกัดความที่เข้าใจง่ายของไวยากรณ์แบบไม่มีบริบทคือไวยากรณ์ที่แสดงเป็น BNF ได้ทั้งหมด ดูคำจำกัดความอย่างเป็นทางการได้ที่บทความเกี่ยวกับไวยากรณ์แบบไม่ขึ้นกับบริบทของ Wikipedia
ประเภทของโปรแกรมแยกวิเคราะห์
โปรแกรมแยกวิเคราะห์มี 2 ประเภท ได้แก่ โปรแกรมแยกวิเคราะห์จากบนลงล่างและโปรแกรมแยกวิเคราะห์จากล่างขึ้นบน คำอธิบายที่เข้าใจง่ายคือ โปรแกรมแยกวิเคราะห์จากบนลงล่างจะตรวจสอบโครงสร้างระดับสูงของไวยากรณ์และพยายามค้นหากฎที่ตรงกัน ตัวแยกวิเคราะห์จากล่างขึ้นบนจะเริ่มต้นด้วยอินพุตและค่อยๆ เปลี่ยนอินพุตเป็นกฎไวยากรณ์ โดยเริ่มจากกฎระดับล่างจนกว่าจะพบกฎระดับสูง
มาดูกันว่าโปรแกรมแยกวิเคราะห์ 2 ประเภทจะแยกวิเคราะห์ตัวอย่างของเราอย่างไร
โปรแกรมแยกวิเคราะห์จากบนลงล่างจะเริ่มต้นจากกฎระดับที่สูงขึ้น โดยจะระบุ 2 + 3 เป็นนิพจน์ จากนั้นจะระบุ 2 + 3 - 1 เป็นนิพจน์ (กระบวนการระบุนิพจน์จะพัฒนาไปเรื่อยๆ เพื่อจับคู่กับกฎอื่นๆ แต่จุดเริ่มต้นคือกฎระดับสูงสุด)
ตัวแยกวิเคราะห์จากล่างขึ้นบนจะสแกนอินพุตจนกว่าจะพบกฎที่ตรงกัน จากนั้นระบบจะแทนที่อินพุตที่ตรงกันด้วยกฎ ซึ่งจะดำเนินไปจนกว่าจะสิ้นสุดอินพุต ระบบจะวางนิพจน์ที่ตรงกันบางส่วนไว้ในกองของโปรแกรมแยกวิเคราะห์
โปรแกรมวิเคราะห์แบบจากล่างขึ้นบนประเภทนี้เรียกว่าโปรแกรมวิเคราะห์แบบเลื่อนและลด เนื่องจากระบบจะเลื่อนอินพุตไปทางขวา (ลองนึกภาพเคอร์เซอร์ที่ชี้ไปที่จุดเริ่มต้นของอินพุตก่อนแล้วเลื่อนไปทางขวา) และค่อย ๆ ลดให้เป็นกฎไวยากรณ์
การสร้างโปรแกรมแยกวิเคราะห์โดยอัตโนมัติ
มีเครื่องมือที่สามารถสร้างโปรแกรมแยกวิเคราะห์ได้ คุณจะป้อนไวยากรณ์ของภาษา เช่น คําศัพท์และกฎไวยากรณ์ แล้วเครื่องมือจะสร้างโปรแกรมแยกวิเคราะห์ที่ใช้งานได้ การสร้างโปรแกรมแยกวิเคราะห์ต้องใช้ความเข้าใจเชิงลึกเกี่ยวกับการแยกวิเคราะห์ และการสร้างโปรแกรมแยกวิเคราะห์ที่เพิ่มประสิทธิภาพด้วยตนเองนั้นไม่ใช่เรื่องง่าย เครื่องมือสร้างโปรแกรมแยกวิเคราะห์จึงมีประโยชน์อย่างยิ่ง
WebKit ใช้เครื่องมือสร้างโปรแกรมแยกวิเคราะห์ที่รู้จักกันดี 2 รายการ ได้แก่ Flex สำหรับการสร้างโปรแกรมแยกวิเคราะห์ข้อความ และ Bison สำหรับการสร้างโปรแกรมแยกวิเคราะห์ (คุณอาจเห็นเครื่องมือเหล่านี้ในชื่อ Lex และ Yacc) อินพุต Flex คือไฟล์ที่มีคำจำกัดความนิพจน์ทั่วไปของโทเค็น อินพุตของ Bison คือกฎไวยากรณ์ภาษาในรูปแบบ BNF
โปรแกรมแยกวิเคราะห์ HTML
หน้าที่ของโปรแกรมแยกวิเคราะห์ HTML คือแยกวิเคราะห์มาร์กอัป HTML เป็นโครงสร้างการแยกวิเคราะห์
ไวยากรณ์ HTML
คําศัพท์และไวยากรณ์ของ HTML ได้รับการกําหนดไว้ในข้อกําหนดที่องค์กร W3C สร้างขึ้น
ดังที่เราได้เห็นในบทนำเกี่ยวกับการแยกวิเคราะห์ ไวยากรณ์ของไวยากรณ์สามารถกำหนดอย่างเป็นทางการได้โดยใช้รูปแบบอย่าง BNF
ขออภัย หัวข้อเกี่ยวกับโปรแกรมแยกวิเคราะห์แบบดั้งเดิมทั้งหมดใช้ไม่ได้กับ HTML (เราไม่ได้พูดถึงหัวข้อเหล่านี้เพื่อสนุกๆ เท่านั้น แต่หัวข้อเหล่านี้จะใช้ในการแยกวิเคราะห์ CSS และ JavaScript) HTML ไม่สามารถกำหนดได้ง่ายด้วยไวยากรณ์แบบไม่มีบริบทที่โปรแกรมแยกวิเคราะห์ต้องการ
รูปแบบอย่างเป็นทางการสำหรับการกำหนด HTML คือ DTD (Document Type Definition) แต่ไม่ใช่ไวยากรณ์แบบไม่มีบริบท
การดำเนินการนี้อาจดูแปลกๆ ในตอนแรก เนื่องจาก HTML ค่อนข้างคล้ายกับ XML เครื่องมือแยกวิเคราะห์ XML มีมากมาย XHTML เป็นรูปแบบ XML ของ HTML แล้วความแตกต่างที่สำคัญคืออะไร
ความแตกต่างคือแนวทาง HTML "ให้อภัย" มากกว่า ซึ่งช่วยให้คุณละเว้นแท็กบางรายการได้ (ซึ่งระบบจะเพิ่มให้โดยปริยาย) หรือบางครั้งอาจละเว้นแท็กเปิดหรือแท็กปิด และอื่นๆ โดยรวมแล้ว ไวยากรณ์นี้ "ยืดหยุ่น" เมื่อเทียบกับไวยากรณ์ที่เข้มงวดและซับซ้อนของ XML
รายละเอียดเล็กๆ น้อยๆ นี้สร้างความแตกต่างได้เป็นอย่างมาก ในทางหนึ่ง นี่เป็นเหตุผลหลักที่ทำให้ HTML ได้รับความนิยมอย่างมาก เนื่องจากให้อภัยความผิดพลาดของคุณและช่วยให้ผู้เขียนเว็บทำงานได้ง่าย ในทางกลับกัน รูปแบบนี้ทำให้เขียนไวยากรณ์แบบเป็นทางการได้ยาก สรุปคือ โปรแกรมแยกวิเคราะห์แบบดั้งเดิมแยกวิเคราะห์ HTML ได้ไม่ง่ายนัก เนื่องจากไวยากรณ์ของ HTML ไม่ได้เป็นแบบไม่ขึ้นกับบริบท โปรแกรมแยกวิเคราะห์ XML แยกวิเคราะห์ HTML ไม่ได้
DTD ของ HTML
คําจํากัดความ HTML อยู่ในรูปแบบ DTD รูปแบบนี้ใช้เพื่อกำหนดภาษาของตระกูล SGML รูปแบบนี้มีคำจำกัดความขององค์ประกอบที่อนุญาตทั้งหมด แอตทริบิวต์ และลําดับชั้น ดังที่เราได้ดูกันก่อนหน้านี้ DTD ของ HTML ไม่ได้เป็นไวยากรณ์แบบไม่มีบริบท
DTD มีรูปแบบต่างๆ อยู่ 2-3 รูปแบบ โหมดที่เข้มงวดจะเป็นไปตามข้อกำหนดเท่านั้น แต่โหมดอื่นๆ จะรองรับมาร์กอัปที่เบราว์เซอร์ใช้มาก่อนหน้านี้ โดยมีวัตถุประสงค์เพื่อใช้งานร่วมกับเนื้อหาเก่าได้ DTD แบบเข้มงวดปัจจุบันมีดังนี้ www.w3.org/TR/html4/strict.dtd
DOM
ต้นไม้เอาต์พุต ("ต้นไม้การแยกวิเคราะห์") คือต้นไม้ขององค์ประกอบ DOM และโหนดแอตทริบิวต์ DOM ย่อมาจาก Document Object Model นั่นคือการแสดงออบเจ็กต์ของเอกสาร HTML และอินเทอร์เฟซขององค์ประกอบ HTML ไปยังโลกภายนอก เช่น JavaScript
รูทของต้นไม้คือออบเจ็กต์ "Document"
DOM เกือบจะสัมพันธ์กับมาร์กอัปแบบ 1:1 เช่น
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
มาร์กอัปนี้จะแปลเป็นต้นไม้ DOM ดังต่อไปนี้
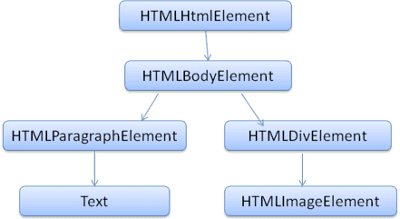
DOM ได้รับการระบุโดยองค์กร W3C เช่นเดียวกับ HTML โปรดดูที่ www.w3.org/DOM/DOMTR ซึ่งเป็นข้อกำหนดทั่วไปสำหรับการจัดการเอกสาร โมดูลที่เฉพาะเจาะจงจะอธิบายองค์ประกอบ HTML ที่เฉพาะเจาะจง ดูคำจำกัดความ HTML ได้ที่นี่ www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html
เมื่อเราบอกว่าต้นไม้มีโหนด DOM หมายความว่าต้นไม้สร้างขึ้นจากองค์ประกอบที่ใช้อินเทอร์เฟซ DOM อย่างใดอย่างหนึ่ง เบราว์เซอร์ใช้การใช้งานที่แน่ชัดซึ่งมีแอตทริบิวต์อื่นๆ ที่เบราว์เซอร์ใช้ภายใน
อัลกอริทึมการแยกวิเคราะห์
ดังที่เราได้เห็นในส่วนก่อนหน้านี้ ไม่สามารถแยกวิเคราะห์ HTML โดยใช้โปรแกรมแยกวิเคราะห์แบบจากบนลงล่างหรือจากล่างขึ้นบนตามปกติ
เหตุผลมีดังนี้
- ลักษณะที่ยอมรับของภาษา
- การที่เบราว์เซอร์มีความอดทนต่อข้อผิดพลาดแบบดั้งเดิมเพื่อรองรับกรณีที่ทราบกันดีว่า HTML ไม่ถูกต้อง
- กระบวนการแยกวิเคราะห์เป็นแบบเข้าซ้ำได้ สำหรับภาษาอื่นๆ แหล่งที่มาจะไม่เปลี่ยนแปลงระหว่างการแยกวิเคราะห์ แต่สำหรับ HTML โค้ดแบบไดนามิก (เช่น องค์ประกอบสคริปต์ที่มีการเรียก
document.write()) สามารถเพิ่มโทเค็นเพิ่มเติมได้ ดังนั้นกระบวนการแยกวิเคราะห์จะแก้ไขอินพุต
เมื่อใช้เทคนิคการแยกวิเคราะห์ปกติไม่ได้ เบราว์เซอร์จะสร้างโปรแกรมแยกวิเคราะห์ที่กำหนดเองเพื่อแยกวิเคราะห์ HTML
อัลกอริทึมการแยกวิเคราะห์มีคำอธิบายโดยละเอียดในข้อกำหนด HTML5 อัลกอริทึมนี้ประกอบด้วย 2 ระยะ ได้แก่ การจัดทําโทเค็นและการสร้างต้นไม้
การจัดทําโทเค็นคือการวิเคราะห์เชิงคําศัพท์ ซึ่งจะแยกวิเคราะห์อินพุตออกเป็นโทเค็น โทเค็น HTML ประกอบด้วยแท็กเริ่มต้น แท็กปิด ชื่อแอตทริบิวต์ และค่าแอตทริบิวต์
ตัวแยกวิเคราะห์จะจดจําโทเค็น ส่งไปยังตัวสร้างต้นไม้ และใช้อักขระถัดไปเพื่อจดจําโทเค็นถัดไป และทําเช่นนี้ไปเรื่อยๆ จนกว่าจะถึงจุดสิ้นสุดของอินพุต
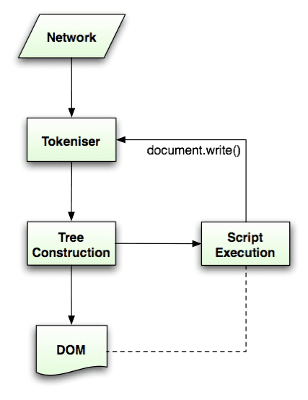
อัลกอริทึมการแปลงข้อมูลเป็นโทเค็น
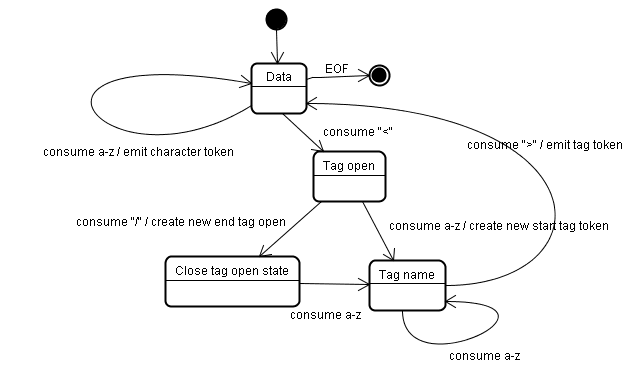
เอาต์พุตของอัลกอริทึมคือโทเค็น HTML อัลกอริทึมแสดงเป็นสถานะการทำงานของเครื่อง แต่ละสถานะจะใช้อักขระอย่างน้อย 1 ตัวในสตรีมอินพุตและอัปเดตสถานะถัดไปตามอักขระเหล่านั้น การตัดสินใจนี้ขึ้นอยู่กับสถานะการแยกออกเป็นโทเค็นปัจจุบันและสถานะการสร้างต้นไม้ ซึ่งหมายความว่าอักขระเดียวกันที่บริโภคจะให้ผลลัพธ์ที่แตกต่างกันสำหรับสถานะที่ถูกต้องถัดไป ทั้งนี้ขึ้นอยู่กับสถานะปัจจุบัน อัลกอริทึมนี้ซับซ้อนเกินกว่าที่จะอธิบายได้ทั้งหมด เรามาดูตัวอย่างง่ายๆ ที่ช่วยให้เราเข้าใจหลักการกัน
ตัวอย่างพื้นฐาน - การจัดทําโทเค็นของ HTML ต่อไปนี้
<html>
<body>
Hello world
</body>
</html>
สถานะเริ่มต้นคือ "สถานะข้อมูล"
เมื่อพบอักขระ < ระบบจะเปลี่ยนสถานะเป็น "สถานะเปิดแท็ก"
การใช้อักขระ a-z จะทําให้เกิดการสร้าง "โทเค็นแท็กเริ่มต้น" และเปลี่ยนสถานะเป็น "สถานะชื่อแท็ก"
เราจะอยู่ในสถานะนี้จนกว่าอักขระ > จะถูกใช้ ระบบจะเพิ่มอักขระแต่ละตัวต่อท้ายชื่อโทเค็นใหม่ ในกรณีของเรา โทเค็นที่สร้างคือโทเค็น html
เมื่อถึงแท็ก > ระบบจะส่งโทเค็นปัจจุบันและสถานะจะเปลี่ยนกลับไปเป็น"สถานะข้อมูล"
ระบบจะดำเนินการกับแท็ก <body> ด้วยขั้นตอนเดียวกัน
จนถึงตอนนี้ ระบบได้ส่งแท็ก html และ body ตอนนี้เรากลับมาที่"สถานะข้อมูล"
การใช้อักขระ H ของ Hello world จะทำให้เกิดการสร้างและส่งโทเค็นอักขระ ซึ่งจะดำเนินต่อไปจนกว่าจะถึง < ของ </body> เราจะแสดงโทเค็นอักขระสำหรับอักขระแต่ละตัวของ Hello world
ตอนนี้เรากลับมาที่"สถานะเปิดแท็ก"
การใช้อินพุต / รายการถัดไปจะทําให้เกิดการสร้าง end tag token และย้ายไปยัง"สถานะชื่อแท็ก" เราจะอยู่ในสถานะนี้จนกว่าจะถึง > จากนั้นระบบจะส่งโทเค็นแท็กใหม่และเราจะกลับไปที่"สถานะข้อมูล"
ระบบจะถือว่าอินพุต </html> เหมือนกับเคสก่อนหน้า
อัลกอริทึมการสร้างต้นไม้
เมื่อสร้างโปรแกรมแยกวิเคราะห์ ระบบจะสร้างออบเจ็กต์เอกสาร ในระหว่างการสร้างต้นไม้ ต้นไม้ DOM ที่มีเอกสารเป็นรูทจะได้รับการแก้ไขและเพิ่มองค์ประกอบเข้าไป โหนดแต่ละโหนดที่ตัวแยกวิเคราะห์สร้างจะได้รับการประมวลผลโดยตัวสร้างต้นไม้ สเปคจะกำหนดว่าองค์ประกอบ DOM ใดเกี่ยวข้องกับโทเค็นแต่ละรายการและจะสร้างโทเค็นนี้ ระบบจะเพิ่มองค์ประกอบลงในต้นไม้ DOM และกององค์ประกอบที่เปิดอยู่ สแต็กนี้ใช้เพื่อแก้ไขการซ้อนที่ไม่ตรงกันและแท็กที่ปิดไม่สนิท อัลกอริทึมนี้ยังอธิบายว่าเป็นสถานะการทำงานของเครื่องจักรด้วย สถานะเหล่านี้เรียกว่า "โหมดการแทรก"
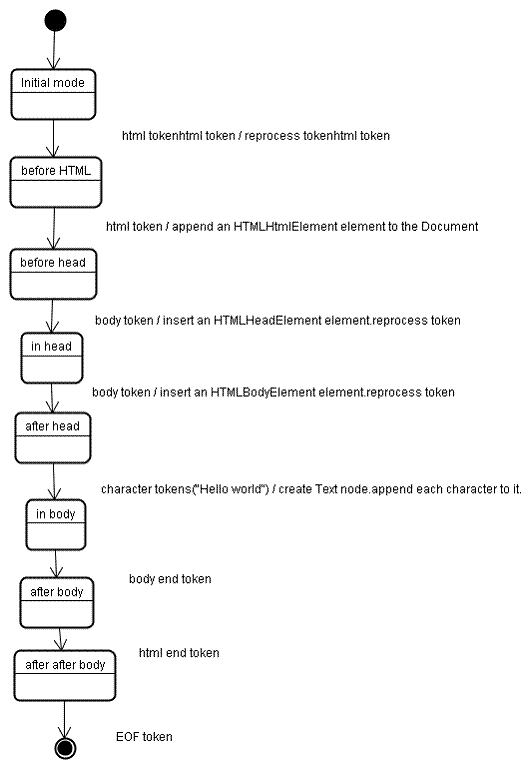
มาดูขั้นตอนการสร้างต้นไม้สำหรับอินพุตตัวอย่างกัน
<html>
<body>
Hello world
</body>
</html>
อินพุตสำหรับระยะการสร้างต้นไม้คือลําดับโทเค็นจากระยะการแยกวิเคราะห์ โหมดแรกคือ"โหมดเริ่มต้น" การรับโทเค็น "html" จะทําให้ระบบย้ายไปยังโหมด "ก่อน html" และประมวลผลโทเค็นอีกครั้งในโหมดนั้น ซึ่งจะทําให้เกิดการสร้างองค์ประกอบ HTMLHtmlElement ซึ่งจะต่อท้ายออบเจ็กต์เอกสารรูท
สถานะจะเปลี่ยนเป็น "before head" จากนั้นระบบจะรับโทเค็น "body" ระบบจะสร้าง HTMLHeadElement โดยนัยแม้ว่าจะไม่มีโทเค็น "head" และระบบจะเพิ่มลงในต้นไม้
ตอนนี้เราจะไปที่โหมด "in head" แล้วไปที่ "after head" ระบบจะประมวลผลโทเค็นเนื้อหาอีกครั้ง สร้างและแทรก HTMLBodyElement และโอนโหมดเป็น "in body"
ตอนนี้ได้รับโทเค็นอักขระของสตริง "Hello world" แล้ว อักขระแรกจะทําให้เกิดการสร้างและแทรกโหนด "ข้อความ" และระบบจะต่ออักขระอื่นๆ ต่อท้ายโหนดนั้น
การรับโทเค็นสิ้นสุดของเนื้อหาจะทำให้เกิดการโอนไปยังโหมด "หลังเนื้อหา" ตอนนี้เราจะได้รับการสิ้นสุดแท็ก HTML ซึ่งจะนําเราไปยังโหมด "after after body" การรับโทเค็นสิ้นสุดไฟล์จะเป็นการสิ้นสุดการแยกวิเคราะห์
การดำเนินการเมื่อแยกวิเคราะห์เสร็จแล้ว
ในขั้นตอนนี้ เบราว์เซอร์จะทําเครื่องหมายเอกสารเป็นแบบอินเทอร์แอกทีฟและเริ่มแยกวิเคราะห์สคริปต์ที่อยู่ในโหมด "เลื่อนเวลา" ซึ่งก็คือสคริปต์ที่ควรเรียกใช้หลังจากแยกวิเคราะห์เอกสารแล้ว จากนั้นระบบจะตั้งค่าสถานะเอกสารเป็น "เสร็จสมบูรณ์" และระบบจะเรียกเหตุการณ์ "โหลด"
คุณดูอัลกอริทึมทั้งหมดสำหรับการแยกออกเป็นโทเค็นและการสร้างต้นไม้ได้ในข้อกำหนด HTML5
ความคลาดเคลื่อนของข้อผิดพลาดของเบราว์เซอร์
คุณจะไม่พบข้อผิดพลาด "ไวยากรณ์ไม่ถูกต้อง" ในหน้า HTML เบราว์เซอร์จะแก้ไขเนื้อหาที่ไม่ถูกต้องและดำเนินการต่อ
มาดูตัวอย่าง HTML นี้กัน
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
ฉันละเมิดกฎประมาณ 1 ล้านข้อ ("mytag" ไม่ใช่แท็กมาตรฐาน การฝังองค์ประกอบ "p" และ "div" ไม่ถูกต้อง และอื่นๆ) แต่เบราว์เซอร์ยังคงแสดงอย่างถูกต้องและไม่แสดงข้อร้องเรียน ดังนั้นโค้ดแยกวิเคราะห์จำนวนมากจึงแก้ไขข้อผิดพลาดของผู้เขียน HTML
การจัดการข้อผิดพลาดค่อนข้างสอดคล้องกันในเบราว์เซอร์ แต่น่าแปลกใจที่ไม่ได้เป็นส่วนหนึ่งของข้อกำหนด HTML เช่นเดียวกับการบุ๊กมาร์กและปุ่มย้อนกลับ/ไปข้างหน้า ฟีเจอร์นี้เป็นสิ่งที่พัฒนาขึ้นในเบราว์เซอร์ในช่วงหลายปีที่ผ่านมา มีโครงสร้าง HTML ที่ไม่ถูกต้องซึ่งทราบอยู่แล้วปรากฏซ้ำในหลายเว็บไซต์ และเบราว์เซอร์พยายามแก้ไขโครงสร้างดังกล่าวในลักษณะที่สอดคล้องกับเบราว์เซอร์อื่นๆ
ข้อกำหนด HTML5 ระบุข้อกำหนดเหล่านี้บางส่วนไว้ (WebKit สรุปข้อมูลนี้ไว้อย่างละเอียดในความคิดเห็นตอนต้นของคลาสโปรแกรมแยกวิเคราะห์ HTML)
โปรแกรมแยกวิเคราะห์จะแยกวิเคราะห์อินพุตที่แบ่งออกเป็นโทเค็นลงในเอกสารเพื่อสร้างต้นไม้เอกสาร หากเอกสารมีรูปแบบถูกต้อง การแยกวิเคราะห์ก็จะง่ายดาย
ขออภัย เราต้องจัดการกับเอกสาร HTML จำนวนมากที่มีรูปแบบไม่ถูกต้อง ดังนั้นโปรแกรมแยกวิเคราะห์จึงต้องยอมรับข้อผิดพลาดได้
เราต้องจัดการกับเงื่อนไขข้อผิดพลาดต่อไปนี้เป็นอย่างน้อย
- องค์ประกอบที่เพิ่มอยู่ภายในแท็กภายนอกบางรายการไม่ได้รับอนุญาตอย่างชัดแจ้ง ในกรณีนี้ เราควรปิดแท็กทั้งหมดจนถึงแท็กที่ห้ามองค์ประกอบนั้น แล้วเพิ่มแท็กนั้นในภายหลัง
- เราไม่ได้รับอนุญาตให้เพิ่มองค์ประกอบดังกล่าวโดยตรง อาจเป็นเพราะผู้เขียนเอกสารลืมแท็กบางรายการไว้ (หรือแท็กนั้นๆ ไม่จำเป็นต้องใส่ก็ได้) กรณีนี้อาจเกิดขึ้นกับแท็ก HTML HEAD BODY TBODY TR TD LI (หรือมีแท็กอื่นที่ฉันลืมไปไหม)
- เราต้องการเพิ่มองค์ประกอบบล็อกภายในองค์ประกอบในบรรทัด ปิดองค์ประกอบในบรรทัดทั้งหมดจนถึงองค์ประกอบบล็อกที่สูงกว่ารายการถัดไป
- หากวิธีนี้ไม่ได้ผล ให้ปิดองค์ประกอบจนกว่าเราจะได้รับอนุญาตให้เพิ่มองค์ประกอบ หรือละเว้นแท็ก
มาดูตัวอย่างการยอมรับข้อผิดพลาดของ WebKit กัน
</br> จากราคาเต็ม <br>
บางเว็บไซต์ใช้ </br> แทน <br> WebKit จะถือว่าค่านี้เหมือนกับ <br> เพื่อให้เข้ากันได้กับ IE และ Firefox
โค้ด
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
โปรดทราบว่าการจัดการข้อผิดพลาดเป็นการดำเนินการภายใน ซึ่งจะไม่แสดงต่อผู้ใช้
ตารางที่หลุดออกมา
ตารางที่หลุดออกมาคือตารางที่อยู่ภายในตารางอื่น แต่ไม่ได้อยู่ในเซลล์ของตาราง
เช่น
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit จะเปลี่ยนลําดับชั้นเป็นตารางพี่น้อง 2 ตาราง ดังนี้
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
โค้ด
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit ใช้กองสำหรับเนื้อหาองค์ประกอบปัจจุบัน ซึ่งจะแสดงตารางด้านในออกมาจากกองตารางด้านนอก ตอนนี้ตารางจะเป็นตารางพี่น้องกัน
องค์ประกอบแบบฟอร์มที่ซ้อนกัน
ในกรณีที่ผู้ใช้ใส่แบบฟอร์มไว้ในอีกแบบฟอร์มหนึ่ง ระบบจะไม่สนใจแบบฟอร์มที่ 2
โค้ด
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
ลําดับชั้นแท็กลึกเกินไป
ความคิดเห็นนี้ชัดเจนอยู่แล้ว
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
แท็ก HTML หรือแท็กปิดของเนื้อหาอยู่ผิดตำแหน่ง
อีกครั้ง ความคิดเห็นก็บอกทุกอย่างแล้ว
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
ดังนั้น ผู้เขียนเว็บควรเขียน HTML ให้มีรูปแบบถูกต้อง เว้นแต่ว่าคุณต้องการปรากฏเป็นตัวอย่างในข้อมูลโค้ดความยืดหยุ่นของข้อผิดพลาด WebKit
การแยกวิเคราะห์ CSS
จำแนวคิดการแยกวิเคราะห์ในส่วนข้อมูลเบื้องต้นได้ไหม CSS เป็นไวยากรณ์แบบไม่มีบริบทและสามารถแยกวิเคราะห์ได้โดยใช้ประเภทของโปรแกรมแยกวิเคราะห์ที่อธิบายไว้ในบทนำ ซึ่งแตกต่างจาก HTML อันที่จริงแล้ว ข้อกำหนด CSS จะกำหนดไวยากรณ์และคำศัพท์ของ CSS
มาดูตัวอย่างกัน
ไวยากรณ์เชิงคําศัพท์ (คําศัพท์) กำหนดโดยนิพจน์ทั่วไปสําหรับโทเค็นแต่ละรายการ ดังนี้
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" ย่อมาจากตัวระบุ เช่น ชื่อคลาส "name" คือรหัสองค์ประกอบ (ที่อ้างอิงโดย "#")
ไวยากรณ์ของรูปแบบคำสั่งมีอธิบายอยู่ใน BNF
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
คำอธิบาย:
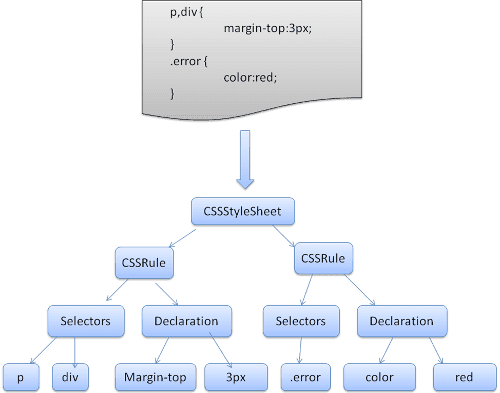
กฎชุดหนึ่งมีโครงสร้างดังนี้
div.error, a.error {
color:red;
font-weight:bold;
}
div.error และ a.error คือตัวเลือก ส่วนที่อยู่ภายในวงเล็บปีกกามีกฎที่ใช้โดยชุดกฎนี้
โครงสร้างนี้ได้รับการกําหนดอย่างเป็นทางการในคําจํากัดความนี้
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
ซึ่งหมายความว่าชุดกฎคือตัวเลือกหรือตัวเลือกหลายรายการที่คั่นด้วยคอมมาและเว้นวรรค (S หมายถึงเว้นวรรค) ชุดกฎประกอบด้วยวงเล็บปีกกาและภายในวงเล็บปีกกาจะมีการประกาศหรือประกาศหลายรายการที่คั่นด้วยเครื่องหมายเซมิโคลอน (ไม่บังคับ) "declaration" และ "selector" จะได้รับการกําหนดไว้ในคําจํากัดความ BNF ต่อไปนี้
โปรแกรมแยกวิเคราะห์ CSS ของ WebKit
WebKit ใช้เครื่องมือสร้างโปรแกรมแยกวิเคราะห์ Flex และ Bison เพื่อสร้างโปรแกรมแยกวิเคราะห์จากไฟล์ไวยากรณ์ CSS โดยอัตโนมัติ ดังที่คุณทราบจากข้อมูลเบื้องต้นเกี่ยวกับโปรแกรมแยกวิเคราะห์ Bison จะสร้างโปรแกรมแยกวิเคราะห์แบบเลื่อนลดจากล่างขึ้นบน Firefox ใช้โปรแกรมแยกวิเคราะห์จากบนลงล่างที่เขียนขึ้นด้วยตนเอง ไม่ว่าจะในกรณีใด ระบบจะแยกวิเคราะห์ไฟล์ CSS แต่ละไฟล์ให้เป็นออบเจ็กต์ StyleSheet แต่ละออบเจ็กต์มีกฎ CSS ออบเจ็กต์กฎ CSS ประกอบด้วยออบเจ็กต์ตัวเลือกและการประกาศ รวมถึงออบเจ็กต์อื่นๆ ที่สอดคล้องกับไวยากรณ์ CSS
ลำดับการประมวลผลสคริปต์และสไตล์ชีต
สคริปต์
โมเดลของเว็บเป็นแบบซิงค์ ผู้เขียนคาดหวังว่าสคริปต์จะได้รับการแยกวิเคราะห์และดำเนินการทันทีเมื่อโปรแกรมแยกวิเคราะห์ถึงแท็ก <script>
การแยกวิเคราะห์เอกสารจะหยุดลงจนกว่าสคริปต์จะทำงาน
หากสคริปต์อยู่ภายนอก ระบบจะต้องดึงข้อมูลทรัพยากรจากเครือข่ายก่อน ซึ่งการดำเนินการนี้จะดำเนินการแบบซิงค์กัน และการแยกวิเคราะห์จะหยุดจนกว่าระบบจะดึงข้อมูลทรัพยากร
รูปแบบนี้เป็นรูปแบบที่ใช้มาหลายปีและระบุไว้ในข้อกำหนด HTML4 และ 5 ด้วย
ผู้เขียนสามารถเพิ่มแอตทริบิวต์ "defer" ลงในสคริปต์ได้ ซึ่งในกรณีนี้ สคริปต์จะไม่หยุดการแยกวิเคราะห์เอกสารและจะดำเนินการหลังจากแยกวิเคราะห์เอกสารแล้ว HTML5 เพิ่มตัวเลือกในการทําเครื่องหมายสคริปต์เป็นแบบไม่พร้อมกันเพื่อให้แยกวิเคราะห์และดำเนินการโดยเธรดอื่น
การแยกวิเคราะห์แบบคาดเดา
ทั้ง WebKit และ Firefox ทำการเพิ่มประสิทธิภาพนี้ ขณะเรียกใช้สคริปต์ เทรดอื่นจะแยกวิเคราะห์ส่วนที่เหลือของเอกสาร และค้นหาทรัพยากรอื่นๆ ที่ต้องโหลดจากเครือข่ายและโหลดทรัพยากรเหล่านั้น วิธีนี้ช่วยให้โหลดทรัพยากรในการเชื่อมต่อแบบขนานได้และความเร็วโดยรวมจะดีขึ้น หมายเหตุ: โปรแกรมแยกวิเคราะห์แบบคาดการณ์จะแยกวิเคราะห์เฉพาะการอ้างอิงทรัพยากรภายนอก เช่น สคริปต์ภายนอก สไตล์ชีต และรูปภาพ แต่จะไม่ได้แก้ไขต้นไม้ DOM ซึ่งจะปล่อยให้โปรแกรมแยกวิเคราะห์หลักดำเนินการ
สไตล์ชีต
ส่วนชีตสไตล์จะมีรูปแบบที่แตกต่างออกไป แนวคิดนี้ดูเหมือนว่าเนื่องจากสไตล์ชีตไม่ได้เปลี่ยนต้นไม้ DOM จึงไม่มีเหตุผลที่ต้องรอและหยุดการแยกวิเคราะห์เอกสาร แต่สคริปต์จะขอข้อมูลสไตล์ระหว่างขั้นตอนการแยกวิเคราะห์เอกสาร หากยังไม่ได้โหลดและแยกวิเคราะห์สไตล์ สคริปต์จะได้รับคำตอบที่ไม่ถูกต้อง และดูเหมือนว่านี่จะทำให้เกิดปัญหามากมาย ดูเหมือนว่าจะเป็นกรณีที่เกิดขึ้นไม่บ่อยนัก แต่พบได้บ่อย Firefox จะบล็อกสคริปต์ทั้งหมดเมื่อมีสไตล์ชีตที่ยังคงโหลดและแยกวิเคราะห์อยู่ WebKit จะบล็อกสคริปต์เฉพาะเมื่อพยายามเข้าถึงพร็อพเพอร์ตี้สไตล์บางอย่างที่อาจได้รับผลกระทบจากสไตล์ชีตที่ไม่ได้โหลด
การสร้างต้นไม้ในการแสดงผล
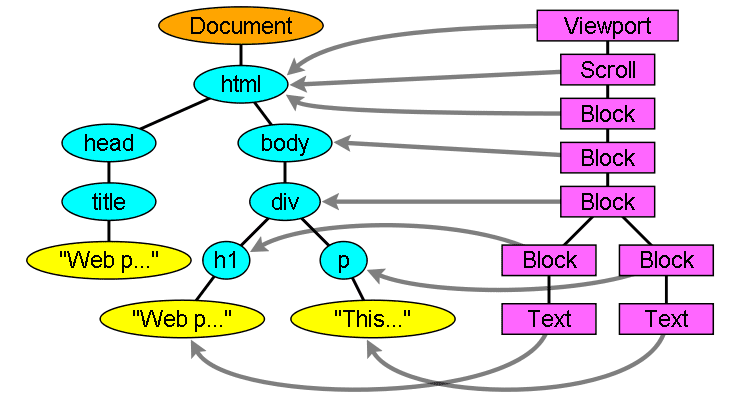
ขณะสร้าง DOM Tree เบราว์เซอร์จะสร้างอีก Tree หนึ่ง ซึ่งเป็น Render Tree ต้นไม้นี้แสดงองค์ประกอบภาพตามลำดับที่จะแสดง ซึ่งเป็นการแสดงภาพเอกสาร วัตถุประสงค์ของต้นไม้นี้คือการช่วยให้วาดเนื้อหาตามลําดับที่ถูกต้องได้
Firefox เรียกองค์ประกอบในต้นไม้เรนเดอร์ว่า "เฟรม" WebKit ใช้คำว่าโปรแกรมแสดงผลหรือออบเจ็กต์การแสดงผล
โปรแกรมแสดงผลจะรู้วิธีวางเลย์เอาต์และวาดภาพตัวเองและองค์ประกอบย่อย
คลาส RenderObject ของ WebKit ซึ่งเป็นคลาสพื้นฐานของโปรแกรมแสดงผลมีคำจำกัดความดังนี้
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
โปรแกรมแสดงผลแต่ละรายการแสดงพื้นที่สี่เหลี่ยมผืนผ้าซึ่งมักจะสอดคล้องกับกล่อง CSS ของโหนดตามที่ข้อกำหนด CSS2 อธิบายไว้ โดยจะมีข้อมูลเชิงเรขาคณิต เช่น ความกว้าง ความสูง และตำแหน่ง
ประเภทกล่องจะได้รับผลกระทบจากค่า "display" ของแอตทริบิวต์สไตล์ที่เกี่ยวข้องกับโหนด (ดูส่วนการคํานวณสไตล์) ต่อไปนี้คือโค้ด WebKit สำหรับการตัดสินใจว่าควรสร้างโปรแกรมแสดงผลประเภทใดสำหรับโหนด DOM ตามแอตทริบิวต์ display
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
ระบบจะพิจารณาประเภทองค์ประกอบด้วย เช่น ตัวควบคุมแบบฟอร์มและตารางจะมีเฟรมพิเศษ
ใน WebKit หากองค์ประกอบต้องการสร้างโปรแกรมแสดงผลพิเศษ ระบบจะลบล้างเมธอด createRenderer()
โปรแกรมแสดงผลจะชี้ไปยังออบเจ็กต์สไตล์ที่มีข้อมูลไม่ใช่เรขาคณิต
ความสัมพันธ์ของต้นไม้แสดงผลกับต้นไม้ DOM
โปรแกรมแสดงผลจะสอดคล้องกับองค์ประกอบ DOM แต่ความสัมพันธ์นั้นไม่ใช่แบบ 1:1 ระบบจะไม่แทรกองค์ประกอบ DOM ที่ไม่มีการแสดงผลในต้นไม้การแสดงผล เช่น องค์ประกอบ "head" นอกจากนี้ องค์ประกอบที่มีการกำหนดค่าการแสดงผลเป็น "ไม่มี" จะไม่ปรากฏในแผนภูมิ (ในขณะที่องค์ประกอบที่มีระดับการแชร์ "ซ่อน" จะปรากฏในแผนภูมิ)
มีองค์ประกอบ DOM ที่สอดคล้องกับออบเจ็กต์ภาพหลายรายการ โดยทั่วไปแล้ว องค์ประกอบเหล่านี้มีโครงสร้างที่ซับซ้อนซึ่งอธิบายด้วยสี่เหลี่ยมผืนผ้ารูปเดียวไม่ได้ เช่น องค์ประกอบ "select" มีโปรแกรมแสดงผล 3 รายการ ได้แก่ รายการสำหรับพื้นที่แสดงผล รายการสำหรับช่องรายการแบบเลื่อนลง และรายการสำหรับปุ่ม นอกจากนี้ เมื่อข้อความแบ่งออกเป็นหลายบรรทัดเนื่องจากความกว้างไม่เพียงพอสำหรับ 1 บรรทัด ระบบจะเพิ่มบรรทัดใหม่เป็นโปรแกรมแสดงผลเพิ่มเติม
อีกตัวอย่างหนึ่งของโปรแกรมแสดงผลหลายรายการคือ HTML ที่ไม่ถูกต้อง ตามข้อกำหนดของ CSS องค์ประกอบในบรรทัดต้องมีองค์ประกอบบล็อกเท่านั้นหรือองค์ประกอบในบรรทัดเท่านั้น ในกรณีที่มีเนื้อหาแบบผสม ระบบจะสร้างโปรแกรมแสดงผลบล็อกที่ไม่ระบุชื่อเพื่อตัดองค์ประกอบในบรรทัด
ออบเจ็กต์การแสดงผลบางรายการสอดคล้องกับโหนด DOM แต่ไม่ได้อยู่ในตําแหน่งเดียวกันในต้นไม้ องค์ประกอบที่ลอยอยู่และองค์ประกอบที่วางตำแหน่งแบบสัมบูรณ์จะอยู่นอกลำดับการวาง วางไว้ในส่วนอื่นของต้นไม้ และแมปกับเฟรมจริง เฟรมตัวยึดตําแหน่งควรอยู่ตรงที่ควรจะอยู่
ขั้นตอนการสร้างแผนภูมิ
ใน Firefox ระบบจะลงทะเบียนงานนำเสนอเป็นผู้ฟังการอัปเดต DOM
การแสดงผลจะมอบสิทธิ์การสร้างเฟรมให้กับ FrameConstructor และตัวสร้างจะแก้ไขสไตล์ (ดูการคํานวณสไตล์) และสร้างเฟรม
ใน WebKit กระบวนการแก้ไขสไตล์และสร้างโปรแกรมแสดงผลเรียกว่า "ไฟล์แนบ" โหนด DOM ทุกโหนดมีเมธอด "attach" การแนบเป็นแบบซิงค์ โดยการแทรกโหนดลงในต้นไม้ DOM จะเรียกใช้เมธอด "แนบ" ของโหนดใหม่
การประมวลผลแท็ก HTML และแท็กเนื้อหาจะส่งผลให้มีการสร้างรูทของต้นไม้แสดงผล
ออบเจ็กต์การแสดงผลรูทสอดคล้องกับสิ่งที่ข้อกำหนด CSS เรียกว่าบล็อกที่บรรจุ ซึ่งก็คือบล็อกบนสุดที่มีบล็อกอื่นๆ ทั้งหมด มิติข้อมูลขององค์ประกอบนี้คือวิวพอร์ต ซึ่งเป็นมิติข้อมูลของพื้นที่แสดงผลของหน้าต่างเบราว์เซอร์
Firefox เรียกสิ่งนี้ว่า ViewPortFrame และ WebKit เรียกสิ่งนี้ว่า RenderView
นี่คือออบเจ็กต์การแสดงผลที่เอกสารชี้ถึง
ส่วนที่เหลือของต้นไม้จะสร้างขึ้นโดยการแทรกโหนด DOM
ดูข้อกำหนด CSS2 เกี่ยวกับรูปแบบการประมวลผล
การคํานวณรูปแบบ
การสร้างต้นไม้เรนเดอร์ต้องคํานวณพร็อพเพอร์ตี้ภาพของแต่ละออบเจ็กต์เรนเดอร์ ซึ่งทำได้โดยการคำนวณพร็อพเพอร์ตี้สไตล์ขององค์ประกอบแต่ละรายการ
สไตล์นี้ประกอบด้วยสไตล์ชีตจากแหล่งที่มาต่างๆ องค์ประกอบสไตล์แทรกในบรรทัด และพร็อพเพอร์ตี้ภาพใน HTML (เช่น พร็อพเพอร์ตี้ "bgcolor") ซึ่งระบบจะแปลเป็นพร็อพเพอร์ตี้สไตล์ CSS ที่ตรงกัน
ต้นกำเนิดของสไตล์ชีตคือสไตล์ชีตเริ่มต้นของเบราว์เซอร์ สไตล์ชีตที่ผู้เขียนหน้าเว็บระบุ และสไตล์ชีตของผู้ใช้ ซึ่งเป็นสไตล์ชีตที่ผู้ใช้เบราว์เซอร์ระบุ (เบราว์เซอร์ให้คุณกำหนดสไตล์ที่ชอบได้ เช่น ใน Firefox การดำเนินการนี้จะทำได้โดยการวางสไตล์ชีตในโฟลเดอร์ "โปรไฟล์ Firefox")
การคํานวณสไตล์ก่อให้เกิดปัญหาบางอย่าง ดังนี้
- ข้อมูลสไตล์เป็นโครงสร้างขนาดใหญ่มากซึ่งมีพร็อพเพอร์ตี้สไตล์จํานวนมาก ซึ่งอาจทำให้เกิดปัญหาเกี่ยวกับหน่วยความจําได้
การค้นหากฎที่ตรงกันสำหรับองค์ประกอบแต่ละรายการอาจทำให้เกิดปัญหาด้านประสิทธิภาพหากไม่ได้รับการเพิ่มประสิทธิภาพ การเรียกดูรายการกฎทั้งหมดสำหรับองค์ประกอบแต่ละรายการเพื่อหารายการที่ตรงกันนั้นเป็นงานที่หนักมาก ตัวเลือกอาจมีโครงสร้างที่ซับซ้อนซึ่งอาจทําให้กระบวนการจับคู่เริ่มต้นในเส้นทางที่ดูเหมือนจะเป็นไปได้แต่กลับพิสูจน์แล้วว่าไร้ประโยชน์และต้องลองเส้นทางอื่น
เช่น ตัวเลือกแบบผสมนี้
div div div div{ ... }หมายความว่ากฎมีผลกับ
<div>ซึ่งเป็นรายการที่สืบทอดมาจาก div 3 รายการ สมมติว่าคุณต้องการตรวจสอบว่ากฎมีผลกับองค์ประกอบ<div>หนึ่งๆ หรือไม่ คุณเลือกเส้นทางที่แน่นอนในลําดับชั้นเพื่อตรวจสอบ คุณอาจต้องไปยังส่วนต่างๆ ของต้นไม้โหนดเพื่อดูว่ามี Div เพียง 2 รายการและกฎไม่มีผล จากนั้นคุณต้องลองใช้เส้นทางอื่นๆ ในแผนภูมิการใช้กฎเกี่ยวข้องกับกฎ Cascade ที่ซับซ้อนพอสมควรซึ่งกําหนดลําดับชั้นของกฎ
มาดูกันว่าเบราว์เซอร์ต่างๆ จัดการกับปัญหาเหล่านี้อย่างไร
การแชร์ข้อมูลสไตล์
โหนด WebKit จะอ้างอิงออบเจ็กต์สไตล์ (RenderStyle) โหนดสามารถแชร์ออบเจ็กต์เหล่านี้ได้ในบางเงื่อนไข โหนดเป็นพี่น้องหรือญาติ และ
- องค์ประกอบต้องอยู่ในสถานะเมาส์เดียวกัน (เช่น องค์ประกอบหนึ่งต้องไม่อยู่ในสถานะ :hover ขณะที่อีกองค์ประกอบหนึ่งไม่ได้อยู่ในสถานะดังกล่าว)
- องค์ประกอบทั้ง 2 รายการไม่ควรมีรหัส
- ชื่อแท็กควรตรงกัน
- แอตทริบิวต์คลาสควรตรงกัน
- ชุดแอตทริบิวต์ที่แมปต้องเหมือนกัน
- สถานะลิงก์ต้องตรงกัน
- สถานะโฟกัสต้องตรงกัน
- องค์ประกอบทั้ง 2 รายการไม่ควรได้รับผลกระทบจากตัวเลือกแอตทริบิวต์ โดยที่ "ได้รับผลกระทบ" หมายถึงมีตัวเลือกที่ตรงกันซึ่งใช้ตัวเลือกแอตทริบิวต์ในตําแหน่งใดก็ตามภายในตัวเลือก
- องค์ประกอบต้องไม่มีแอตทริบิวต์รูปแบบในบรรทัด
- ต้องไม่มีการใช้ตัวเลือกพี่น้องเลย WebCore จะเปิดสวิตช์ส่วนกลางเมื่อพบตัวเลือกพี่น้องและปิดใช้การแชร์สไตล์สำหรับทั้งเอกสารเมื่อมีตัวเลือกดังกล่าว ซึ่งรวมถึงตัวเลือก + และตัวเลือกต่างๆ เช่น :first-child และ :last-child
ต้นไม้กฎของ Firefox
Firefox มีต้นไม้พิเศษอีก 2 ต้นเพื่อให้การคํานวณสไตล์ง่ายขึ้น ได้แก่ ต้นไม้กฎและต้นไม้บริบทสไตล์ WebKit ยังมีออบเจ็กต์สไตล์ด้วย แต่ไม่ได้จัดเก็บไว้ในต้นไม้เหมือนต้นไม้บริบทสไตล์ มีเพียงโหนด DOM ที่ชี้ไปยังสไตล์ที่เกี่ยวข้องเท่านั้น
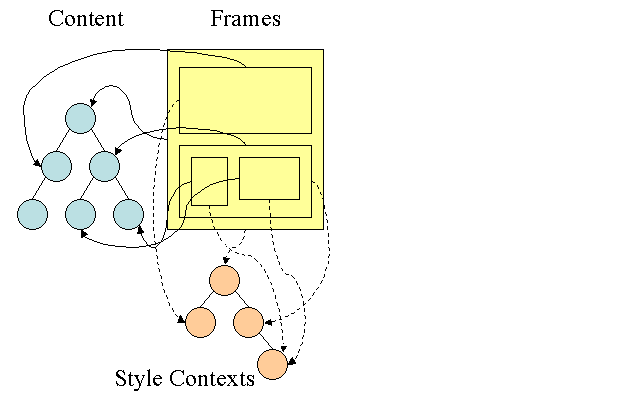
บริบทสไตล์มีค่าสิ้นสุด ระบบจะคํานวณค่าโดยใช้กฎการจับคู่ทั้งหมดตามลําดับที่ถูกต้อง และดําเนินการต่างๆ ที่เปลี่ยนค่าจากตรรกะเป็นค่าที่เป็นรูปธรรม เช่น หากค่าตรรกะเป็นเปอร์เซ็นต์ของหน้าจอ ระบบจะคํานวณและเปลี่ยนค่าเป็นหน่วยสัมบูรณ์ แนวคิดแผนภูมิกฎนั้นฉลาดมาก ซึ่งช่วยให้แชร์ค่าเหล่านี้ระหว่างโหนดเพื่อหลีกเลี่ยงการคํานวณอีกครั้งได้ ซึ่งจะช่วยประหยัดพื้นที่ด้วย
ระบบจะจัดเก็บกฎที่ตรงกันทั้งหมดไว้ในต้นไม้ โหนดด้านล่างในเส้นทางจะมีลําดับความสําคัญสูงกว่า แผนภาพมีเส้นทางทั้งหมดสำหรับการจับคู่กฎที่พบ ระบบจะจัดเก็บกฎแบบล่าช้า ระบบจะไม่คำนวณต้นไม้สำหรับโหนดทุกโหนดตั้งแต่ต้น แต่ทุกครั้งที่จำเป็นต้องคำนวณสไตล์โหนด ระบบจะเพิ่มเส้นทางที่คำนวณแล้วลงในต้นไม้
แนวคิดคือดูเส้นทางต้นไม้เป็นคำในคลังคำ สมมติว่าเราคํานวณต้นไม้กฎนี้แล้ว
สมมติว่าเราต้องจับคู่กฎสําหรับองค์ประกอบอื่นในลําดับชั้นเนื้อหา และพบว่ากฎที่ตรงกัน (ตามลําดับที่ถูกต้อง) คือ B-E-I เรามีเส้นทางนี้ในแผนผังอยู่แล้วเนื่องจากได้คํานวณเส้นทาง A-B-E-I-L แล้ว ซึ่งจะทำให้เราทำงานน้อยลง
มาดูกันว่าต้นไม้ช่วยเราประหยัดงานได้อย่างไร
การแบ่งออกเป็นโครงสร้าง
บริบทสไตล์จะแบ่งออกเป็นสตรัคเจอร์ โครงสร้างเหล่านั้นมีข้อมูลสไตล์สำหรับบางหมวดหมู่ เช่น เส้นขอบหรือสี พร็อพเพอร์ตี้ทั้งหมดในสตรูคเจอร์จะรับค่ามาหรือไม่รับค่ามา พร็อพเพอร์ตี้ที่รับค่าเดิมคือพร็อพเพอร์ตี้ที่รับค่ามาจากองค์ประกอบหลัก เว้นแต่ว่าองค์ประกอบจะกําหนดไว้ พร็อพเพอร์ตี้ที่ไม่ใช่แบบรับค่ามา (เรียกว่าพร็อพเพอร์ตี้ "รีเซ็ต") จะใช้ค่าเริ่มต้นหากไม่ได้กําหนด
ต้นไม้ช่วยเราด้วยการแคชทั้งโครงสร้าง (ซึ่งมีค่าสุดท้ายที่คำนวณแล้ว) ในต้นไม้ แนวคิดคือหากโหนดด้านล่างไม่ได้ระบุคําจํากัดความของโครงสร้าง ระบบจะใช้โครงสร้างที่แคชไว้ในโหนดด้านบนได้
การคํานวณบริบทสไตล์โดยใช้ต้นไม้กฎ
เมื่อคํานวณบริบทสไตล์สําหรับองค์ประกอบหนึ่งๆ เราจะคํานวณเส้นทางในลําดับชั้นกฎหรือใช้เส้นทางที่มีอยู่ก่อน จากนั้นเราจะเริ่มใช้กฎในเส้นทางเพื่อกรอกข้อมูลโครงสร้างในบริบทรูปแบบใหม่ เราจะเริ่มจากโหนดด้านล่างของเส้นทาง ซึ่งเป็นโหนดที่มีลําดับความสําคัญสูงสุด (โดยปกติคือตัวเลือกที่เฉพาะเจาะจงที่สุด) และเดินผ่านลําดับชั้นขึ้นจนกว่าโครงสร้างจะเต็ม หากไม่มีข้อกําหนดสําหรับโครงสร้างในโหนดกฎนั้น เราจะเพิ่มประสิทธิภาพได้อย่างมาก โดยเราจะขึ้นไปยังระดับบนสุดของต้นไม้จนกว่าจะพบโหนดที่ระบุโครงสร้างอย่างสมบูรณ์และชี้ไปยังโหนดนั้น ซึ่งเป็นการเพิ่มประสิทธิภาพที่ดีที่สุด เนื่องจากมีการแชร์ทั้งโครงสร้าง ซึ่งจะช่วยประหยัดการคำนวณค่าสุดท้ายและหน่วยความจำ
หากพบคําจํากัดความบางส่วน เราจะขึ้นไปยังลําดับชั้นด้านบนจนกว่าโครงสร้างจะสมบูรณ์
หากไม่พบคําจํากัดความของโครงสร้าง ในกรณีที่โครงสร้างเป็นประเภท "รับช่วงมา" เราจะชี้ไปยังโครงสร้างของรายการหลักในต้นไม้บริบท ในกรณีนี้ เราแชร์โครงสร้างข้อมูลได้สําเร็จด้วย หากเป็นรีเซ็ตสตรัคเจอร์ ระบบจะใช้ค่าเริ่มต้น
หากโหนดที่เฉพาะเจาะจงที่สุดเพิ่มค่า เราจะต้องทําการคํานวณเพิ่มเติมเพื่อเปลี่ยนค่านั้นให้เป็นค่าจริง จากนั้นเราจะแคชผลลัพธ์ไว้ในโหนดต้นไม้เพื่อให้บุตรหลานใช้งาน
ในกรณีที่องค์ประกอบมีพี่น้องหรือองค์ประกอบที่ชี้ไปยังโหนดต้นไม้เดียวกัน องค์ประกอบเหล่านั้นจะแชร์บริบทสไตล์ทั้งหมดได้
มาดูตัวอย่างกัน สมมติว่าเรามี HTML นี้
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
และกฎต่อไปนี้
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
เพื่อความง่าย เราจะสมมติว่าต้องกรอก Struct เพียง 2 รายการเท่านั้น ได้แก่ Struct สีและ Struct ระยะขอบ โครงสร้างสีมีสมาชิกเพียง 1 คนเท่านั้น ได้แก่ สี ส่วนโครงสร้างระยะขอบมี 4 ด้าน
แผนภูมิกฎที่ได้จะมีลักษณะดังนี้ (โหนดจะมีเครื่องหมายชื่อโหนด ซึ่งเป็นหมายเลขของกฎที่โหนดชี้ถึง)
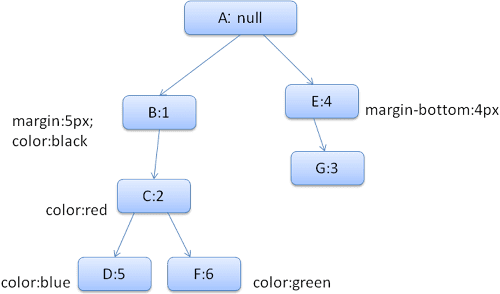
ต้นไม้บริบทจะมีลักษณะดังนี้ (ชื่อโหนด: โหนดกฎที่ชี้ถึง)
สมมติว่าเราแยกวิเคราะห์ HTML และไปถึงแท็ก <div> แท็กที่ 2 เราต้องสร้างบริบทสไตล์สําหรับโหนดนี้และกรอกข้อมูลโครงสร้างสไตล์
เราจะจับคู่กฎและพบว่ากฎที่ตรงกันสำหรับ <div> คือ 1, 2 และ 6
ซึ่งหมายความว่ามีเส้นทางในต้นไม้อยู่แล้วที่องค์ประกอบของเราใช้ได้ และเราเพียงแค่ต้องเพิ่มโหนดอื่นลงในต้นไม้สำหรับกฎ 6 (โหนด F ในต้นไม้กฎ)
เราจะสร้างบริบทสไตล์และวางไว้ในต้นไม้บริบท บริบทสไตล์ใหม่จะชี้ไปยังโหนด F ในลําดับชั้นกฎ
ตอนนี้เราต้องกรอกข้อมูลในโครงสร้างสไตล์ เราจะเริ่มด้วยการกรอกข้อมูลโครงสร้างส่วนต่าง เนื่องจากโหนดกฎสุดท้าย (F) ไม่ได้เพิ่มลงในโครงสร้างส่วนต่าง เราจะขึ้นไปยังด้านบนของต้นไม้ได้จนกว่าจะพบโครงสร้างที่แคชไว้ซึ่งคํานวณจากการแทรกโหนดก่อนหน้า แล้วนำไปใช้ เราจะพบกฎนี้ที่โหนด B ซึ่งเป็นโหนดบนสุดที่ระบุกฎส่วนต่างกำไร
เรามีคําจํากัดความของโครงสร้างสี จึงใช้โครงสร้างที่แคชไว้ไม่ได้ เนื่องจากสีมีแอตทริบิวต์เดียว เราจึงไม่ต้องขึ้นไปยังระดับบนสุดของต้นไม้เพื่อกรอกแอตทริบิวต์อื่นๆ เราจะคํานวณค่าสุดท้าย (แปลงสตริงเป็น RGB ฯลฯ) และแคชสตรูคเจอร์ที่คำนวณแล้วในโหนดนี้
การทำงานกับองค์ประกอบ <span> รายการที่ 2 จะง่ายยิ่งขึ้น เราจะจับคู่กฎและสรุปได้ว่า URL ชี้ไปยังกฎ G เช่นเดียวกับช่วงก่อนหน้า
เนื่องจากเรามีรายการพี่น้องที่ชี้ไปยังโหนดเดียวกัน เราจึงแชร์บริบทสไตล์ทั้งหมดและชี้ไปยังบริบทของสเปนก่อนหน้าได้
สําหรับโครงสร้างที่มีกฎที่รับค่ามาจากรายการหลัก ระบบจะแคชในต้นไม้บริบท (จริง ๆ แล้วระบบจะรับค่าพร็อพเพอร์ตี้สี แต่ Firefox จะถือว่าค่านี้เป็นค่ารีเซ็ตและแคชไว้ในต้นไม้กฎ)
ตัวอย่างเช่น หากเราเพิ่มกฎสำหรับแบบอักษรในย่อหน้า
p {font-family: Verdana; font size: 10px; font-weight: bold}
จากนั้นองค์ประกอบย่อหน้าซึ่งเป็นองค์ประกอบย่อยของ div ในต้นไม้บริบทอาจใช้โครงสร้างแบบอักษรเดียวกับองค์ประกอบหลัก กรณีนี้เกิดขึ้นเมื่อไม่ได้ระบุกฎแบบอักษรสำหรับย่อหน้า
ใน WebKit ซึ่งไม่มีต้นไม้กฎ ระบบจะเรียกใช้ประกาศที่ตรงกัน 4 ครั้ง ระบบจะใช้พร็อพเพอร์ตี้ที่มีลำดับความสำคัญสูงแต่ไม่สำคัญก่อน (พร็อพเพอร์ตี้ที่ควรใช้ก่อนเนื่องจากพร็อพเพอร์ตี้อื่นๆ ต้องใช้พร็อพเพอร์ตี้นี้ เช่น การแสดงผล) ตามด้วยพร็อพเพอร์ตี้ที่มีลำดับความสำคัญสูงแต่สำคัญ ตามด้วยพร็อพเพอร์ตี้ที่มีลำดับความสำคัญปกติแต่ไม่สำคัญ และตามด้วยพร็อพเพอร์ตี้ที่มีลำดับความสำคัญปกติแต่สำคัญ ซึ่งหมายความว่าพร็อพเพอร์ตี้ที่ปรากฏหลายครั้งจะได้รับการแก้ไขตามลําดับตามลำดับขั้นที่ถูกต้อง ชัยชนะครั้งล่าสุด
กล่าวโดยสรุป การแชร์ออบเจ็กต์สไตล์ (ทั้งออบเจ็กต์หรือบางโครงสร้างภายใน) ช่วยแก้ปัญหาที่ 1 และ 3 ได้ แผนภูมิกฎของ Firefox ยังช่วยในการใช้พร็อพเพอร์ตี้ตามลําดับที่ถูกต้องด้วย
การปรับกฎเพื่อให้จับคู่ได้ง่าย
กฎสไตล์มีแหล่งที่มาหลายแห่ง ดังนี้
- กฎ CSS ในสไตล์ชีตภายนอกหรือในองค์ประกอบสไตล์
css p {color: blue} - แอตทริบิวต์รูปแบบแทรกในบรรทัด เช่น
html <p style="color: blue" /> - แอตทริบิวต์ภาพ HTML (ซึ่งแมปกับกฎสไตล์ที่เกี่ยวข้อง)
html <p bgcolor="blue" />2 รายการสุดท้ายจับคู่กับองค์ประกอบได้ง่ายเนื่องจากเป็นเจ้าของแอตทริบิวต์สไตล์และแอตทริบิวต์ HTML สามารถแมปโดยใช้องค์ประกอบเป็นคีย์
ดังที่ได้กล่าวไว้ก่อนหน้านี้ในข้อ 2 การจับคู่กฎ CSS อาจทำได้ยากกว่า กฎต่างๆ จึงได้รับการปรับเปลี่ยนเพื่อให้เข้าถึงได้ง่ายขึ้น
หลังจากแยกวิเคราะห์สไตล์ชีตแล้ว ระบบจะเพิ่มกฎลงในแฮชแมปรายการใดรายการหนึ่งตามตัวเลือก โดยจะมีแผนที่ตามรหัส ตามชื่อชั้นเรียน ตามชื่อแท็ก และแผนที่ทั่วไปสำหรับรายการที่ไม่ตรงกับหมวดหมู่เหล่านั้น หากตัวเลือกเป็นรหัส ระบบจะเพิ่มกฎลงในแผนที่รหัส หากเป็นคลาส ระบบจะเพิ่มลงในแผนที่คลาส เป็นต้น
การจัดการนี้ช่วยให้จับคู่กฎได้ง่ายขึ้นมาก คุณไม่จำเป็นต้องดูการประกาศทั้งหมด เนื่องจากเราดึงกฎที่เกี่ยวข้องกับองค์ประกอบออกจากแผนที่ได้ การเพิ่มประสิทธิภาพนี้จะนํากฎออกได้มากกว่า 95% จึงไม่ต้องพิจารณากฎเหล่านั้นในระหว่างกระบวนการจับคู่(4.1)
มาดูตัวอย่างกฎสไตล์ต่อไปนี้
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
ระบบจะแทรกกฎแรกลงในแผนที่ชั้นเรียน รายการที่ 2 ไปยังแผนที่รหัส และรายการที่ 3 ไปยังแผนที่แท็ก
สําหรับข้อมูลโค้ด HTML ต่อไปนี้
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
เราจะลองหากฎสําหรับองค์ประกอบ p ก่อน แมปคลาสจะมีคีย์ "error" ซึ่งจะพบกฎสําหรับ "p.error" องค์ประกอบ div จะมีกฎที่เกี่ยวข้องในการแมปรหัส (คีย์คือรหัส) และการแมปแท็ก ดังนั้น สิ่งที่ต้องทำที่เหลือคือดูว่ากฎใดที่ดึงมาจากคีย์ตรงกันจริงๆ
เช่น หากกฎสําหรับ div คือ
table div {margin: 5px}
ระบบจะยังคงดึงข้อมูลนี้มาจากแผนที่แท็ก เนื่องจากคีย์คือตัวเลือกด้านขวาสุด แต่จะจับคู่กับองค์ประกอบ div ไม่ได้เนื่องจากไม่มีบรรพบุรุษที่เป็นตาราง
ทั้ง WebKit และ Firefox ดำเนินการนี้
ลําดับ Cascading Style Sheet
ออบเจ็กต์สไตล์มีพร็อพเพอร์ตี้ที่สอดคล้องกับแอตทริบิวต์ภาพทุกรายการ (แอตทริบิวต์ CSS ทั้งหมดแต่เป็นแบบทั่วไปมากกว่า) หากไม่มีกฎใดที่ตรงกันซึ่งกำหนดพร็อพเพอร์ตี้ไว้ ออบเจ็กต์สไตล์ขององค์ประกอบหลักจะรับค่าพร็อพเพอร์ตี้บางรายการได้ พร็อพเพอร์ตี้อื่นๆ จะมีค่าเริ่มต้น
ปัญหาจะเริ่มขึ้นเมื่อมีคําจํากัดความมากกว่า 1 รายการ ลำดับตามลําดับจึงเข้ามาแก้ปัญหา
การประกาศสำหรับพร็อพเพอร์ตี้สไตล์อาจปรากฏในหลายสไตล์ชีต และปรากฏหลายครั้งในสไตล์ชีต ซึ่งหมายความว่าลําดับการใช้กฎนั้นสําคัญมาก ซึ่งเรียกว่าลําดับ "ตามลําดับชั้น" ตามข้อกำหนด CSS2 ลำดับการแสดงผลตามลำดับชั้นคือ (จากต่ำไปสูง)
- การประกาศของเบราว์เซอร์
- การประกาศปกติของผู้ใช้
- การประกาศปกติของผู้แต่ง
- ประกาศที่สำคัญของผู้เขียน
- การประกาศที่สําคัญสําหรับผู้ใช้
การประกาศของเบราว์เซอร์มีความสำคัญน้อยที่สุด และผู้ใช้จะลบล้างผู้เขียนได้ก็ต่อเมื่อมีการทําเครื่องหมายการประกาศว่าสำคัญเท่านั้น ระบบจะจัดเรียงประกาศที่มีลําดับเดียวกันตามความเฉพาะเจาะจง แล้วจัดเรียงตามลําดับที่ระบุ ระบบจะแปลแอตทริบิวต์ภาพ HTML เป็นประกาศ CSS ที่ตรงกัน ระบบจะถือว่ากฎเหล่านี้เป็นกฎของผู้แต่งที่มีลําดับความสําคัญต่ำ
ลักษณะเฉพาะ
ข้อกำหนด CSS2 กำหนดความเฉพาะเจาะจงของตัวเลือกไว้ดังนี้
- นับ 1 หากประกาศนั้นมาจากแอตทริบิวต์ "style" ไม่ใช่กฎที่มีตัวเลือก มิเช่นนั้นให้นับเป็น 0 (= a)
- นับจํานวนแอตทริบิวต์รหัสในตัวเลือก (= b)
- นับจํานวนแอตทริบิวต์และคลาสจำลองอื่นๆ ในตัวเลือก (= c)
- นับจํานวนชื่อองค์ประกอบและองค์ประกอบจำลองในตัวเลือก (= d)
การต่อตัวเลข 4 ตัว a-b-c-d (ในระบบตัวเลขที่มีฐานขนาดใหญ่) จะให้ความเป็นเฉพาะเจาะจง
ระบบจะกำหนดฐานตัวเลขที่คุณต้องใช้ตามจำนวนสูงสุดที่คุณมีในหมวดหมู่ใดหมวดหมู่หนึ่ง
เช่น หาก a=14 คุณจะใช้ฐานสิบหกได้ ในกรณีที่ a=17 ซึ่งเกิดขึ้นไม่บ่อยนัก คุณจะต้องมีฐานตัวเลข 17 หลัก สถานการณ์หลังอาจเกิดขึ้นกับตัวเลือกเช่นนี้ html body div div p… (แท็ก 17 รายการในตัวเลือก… ไม่น่าจะเกิดขึ้น)
ตัวอย่างมีดังต่อไปนี้
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
การจัดเรียงกฎ
หลังจากจับคู่กฎแล้ว ระบบจะจัดเรียงกฎตามกฎการแสดงผลตามลำดับขั้น
WebKit ใช้การเรียงลำดับแบบบับเบิลสำหรับรายการขนาดเล็กและการเรียงลำดับแบบผสานสำหรับรายการขนาดใหญ่
WebKit ใช้การจัดเรียงโดยการลบล้างโอเปอเรเตอร์ > สำหรับกฎต่อไปนี้
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
กระบวนการที่ค่อยเป็นค่อยไป
WebKit ใช้ Flag ที่ทําเครื่องหมายว่าโหลดสไตลชีตระดับบนสุดทั้งหมด (รวมถึง @imports) แล้วหรือยัง หากโหลดสไตล์ไม่เสร็จสมบูรณ์เมื่อแนบ ระบบจะใช้ตัวยึดตําแหน่งและทำเครื่องหมายในเอกสาร และระบบจะคํานวณใหม่เมื่อโหลดสไตล์ชีต
เลย์เอาต์
เมื่อสร้างและเพิ่มโปรแกรมแสดงผลลงในต้นไม้แล้ว โปรแกรมแสดงผลจะไม่มีตําแหน่งและขนาด การคำนวณค่าเหล่านี้เรียกว่าเลย์เอาต์หรือการเรียงใหม่
HTML ใช้รูปแบบเลย์เอาต์ตามลำดับ ซึ่งหมายความว่าส่วนใหญ่จะคำนวณเรขาคณิตได้ในรอบเดียว โดยทั่วไปแล้ว องค์ประกอบ "ในลำดับถัดไป" จะไม่ส่งผลต่อเรขาคณิตขององค์ประกอบ "ในลำดับก่อนหน้า" เพื่อให้เลย์เอาต์ดำเนินจากซ้ายไปขวา จากบนลงล่างผ่านทั้งเอกสาร แต่มีข้อยกเว้น เช่น ตาราง HTML อาจต้องมีการเรียกใช้มากกว่า 1 ครั้ง
ระบบพิกัดจะสัมพันธ์กับเฟรมรูท ระบบจะใช้พิกัดด้านบนและซ้าย
เลย์เอาต์เป็นกระบวนการที่ต้องทำซ้ำ โดยเริ่มต้นที่โปรแกรมแสดงผลรูท ซึ่งสอดคล้องกับองค์ประกอบ <html> ของเอกสาร HTML เลย์เอาต์จะแสดงซ้ำตามลําดับชั้นเฟรมบางส่วนหรือทั้งหมดต่อไป โดยคํานวณข้อมูลเชิงเรขาคณิตสําหรับโปรแกรมแสดงผลแต่ละรายการที่จําเป็น
ตำแหน่งของโปรแกรมแสดงผลรูทคือ 0,0 และขนาดคือวิวพอร์ต ซึ่งเป็นส่วนที่มองเห็นได้ของหน้าต่างเบราว์เซอร์
โปรแกรมแสดงผลทั้งหมดมีเมธอด "layout" หรือ "reflow" โดยแต่ละโปรแกรมแสดงผลจะเรียกใช้เมธอด layout ขององค์ประกอบย่อยที่จำเป็นต้องจัดวาง
ระบบบิตที่สกปรก
เบราว์เซอร์ใช้ระบบ "Dirty Bit" เพื่อไม่ให้ต้องจัดวางเลย์เอาต์ใหม่ทั้งหมดสำหรับการเปลี่ยนแปลงเล็กๆ น้อยๆ โปรแกรมแสดงผลที่มีการเปลี่ยนแปลงหรือเพิ่มเข้ามาจะทําเครื่องหมายตัวเองและรายการย่อยว่า "ไม่ถูกต้อง" ซึ่งหมายความว่าต้องจัดวาง
โดยมี Flag 2 รายการ ได้แก่ "dirty" และ "children are dirty" ซึ่งหมายความว่าแม้ว่าโปรแกรมแสดงผลเองอาจทำงานได้ปกติ แต่ก็มีองค์ประกอบย่อยอย่างน้อย 1 รายการที่ต้องจัดวาง
เลย์เอาต์ส่วนกลางและแบบเพิ่ม
เลย์เอาต์สามารถทริกเกอร์ได้ในทั้งต้นไม้เรนเดอร์ ซึ่งเป็นเลย์เอาต์ "ส่วนกลาง" ปัญหานี้อาจเกิดขึ้นจากสาเหตุต่อไปนี้
- การเปลี่ยนแปลงสไตล์ส่วนกลางที่ส่งผลต่อโปรแกรมแสดงผลทั้งหมด เช่น การเปลี่ยนแปลงขนาดแบบอักษร
- เป็นผลมาจากการการปรับขนาดหน้าจอ
เลย์เอาต์สามารถเพิ่มได้ โดยจะมีการจัดวางเฉพาะโปรแกรมแสดงผลที่เปลี่ยนแปลง (ซึ่งอาจทำให้เกิดความเสียหายบางอย่างซึ่งต้องใช้เลย์เอาต์เพิ่มเติม)
เลย์เอาต์ที่เพิ่มขึ้นจะทริกเกอร์ (แบบอะซิงโครนัส) เมื่อโปรแกรมแสดงผลไม่ถูกต้อง เช่น เมื่อมีการต่อท้ายโปรแกรมแสดงผลใหม่ลงในต้นไม้แสดงผลหลังจากที่เนื้อหาเพิ่มเติมมาจากเครือข่ายและเพิ่มลงในต้นไม้ DOM
เลย์เอาต์แบบอะซิงโครนัสและแบบซิงโครนัส
เลย์เอาต์ที่เพิ่มขึ้นจะทำงานแบบไม่พร้อมกัน Firefox จะจัดคิว "คำสั่งการจัดเรียงใหม่" สำหรับเลย์เอาต์ที่เพิ่มขึ้น และตัวจัดเวลาจะทริกเกอร์การดำเนินการคำสั่งเหล่านี้เป็นกลุ่ม WebKit ยังมีตัวจับเวลาที่เรียกใช้เลย์เอาต์แบบเพิ่มทีละน้อยด้วย โดยจะเรียกใช้ผ่านต้นไม้และแสดงเลย์เอาต์ของโปรแกรมแสดงผลที่ "ไม่ถูกต้อง"
สคริปต์ที่ขอข้อมูลสไตล์ เช่น "offsetHeight" อาจทริกเกอร์เลย์เอาต์ที่เพิ่มขึ้นแบบซิงค์กันได้
โดยปกติแล้วเลย์เอาต์ส่วนกลางจะทริกเกอร์พร้อมกัน
บางครั้งเลย์เอาต์จะทริกเกอร์เป็นคอลแบ็กหลังจากเลย์เอาต์เริ่มต้น เนื่องจากแอตทริบิวต์บางอย่าง เช่น ตำแหน่งการเลื่อนมีการเปลี่ยนแปลง
การเพิ่มประสิทธิภาพ
เมื่อเลย์เอาต์ทริกเกอร์โดย "การปรับขนาด" หรือการเปลี่ยนแปลงตำแหน่งโปรแกรมแสดงผล(ไม่ใช่ขนาด) ระบบจะนำขนาดการแสดงผลมาจากแคชและจะไม่คำนวณใหม่…
ในบางกรณี ระบบจะแก้ไขเฉพาะต้นไม้ย่อยและเลย์เอาต์ไม่ได้เริ่มต้นจากรูท กรณีนี้อาจเกิดขึ้นเมื่อการเปลี่ยนแปลงเกิดขึ้นภายในและไม่ส่งผลต่อองค์ประกอบรอบข้าง เช่น ข้อความที่แทรกลงในช่องข้อความ (ไม่เช่นนั้นการกดแป้นพิมพ์แต่ละครั้งจะทริกเกอร์เลย์เอาต์ที่เริ่มต้นจากรูท)
กระบวนการจัดวาง
โดยปกติแล้วเลย์เอาต์จะมีรูปแบบดังต่อไปนี้
- โปรแกรมแสดงผลหลักจะกําหนดความกว้างของตนเอง
- ผู้ปกครองดูแลบุตรหลานและดำเนินการต่อไปนี้
- วางโปรแกรมแสดงผลย่อย (ตั้งค่า x และ y)
- เรียกใช้เลย์เอาต์ย่อย หากจำเป็น - เลย์เอาต์ไม่ถูกต้องหรือเราอยู่ในเลย์เอาต์ส่วนกลาง หรือเหตุผลอื่นๆ ซึ่งจะคำนวณความสูงของรายการย่อย
- องค์ประกอบหลักใช้ความสูงสะสมขององค์ประกอบย่อยและความสูงของระยะขอบและระยะห่างเพื่อกำหนดความสูงของตนเอง ซึ่งองค์ประกอบหลักของโปรแกรมแสดงผลหลักจะใช้ค่านี้
- ตั้งค่าบิต "มีการแก้ไข" เป็น "เท็จ"
Firefox ใช้ออบเจ็กต์ "state" (nsHTMLReflowState) เป็นพารามิเตอร์ในการจัดวาง (เรียกว่า "การจัดเรียงใหม่") สถานะอื่นๆ ประกอบด้วยความกว้างขององค์ประกอบหลัก
เอาต์พุตของเลย์เอาต์ Firefox คือออบเจ็กต์ "เมตริก" (nsHTMLReflowMetrics) ซึ่งจะมีความสูงที่คำนวณโดยโปรแกรมแสดงผล
การคำนวณความกว้าง
ระบบจะคํานวณความกว้างของโปรแกรมแสดงผลโดยใช้ความกว้างของบล็อกคอนเทนเนอร์ พร็อพเพอร์ตี้ "width" ของสไตล์โปรแกรมแสดงผล ระยะขอบ และเส้นขอบ
เช่น ความกว้างของ div ต่อไปนี้
<div style="width: 30%"/>
WebKit จะคํานวณค่านี้ดังนี้(เมธอด calcWidth ของคลาส RenderBox)
- ความกว้างของคอนเทนเนอร์คือค่าสูงสุดระหว่าง availableWidth ของคอนเทนเนอร์กับ 0 ในกรณีนี้ availableWidth คือ contentWidth ซึ่งคำนวณดังนี้
clientWidth() - paddingLeft() - paddingRight()
clientWidth และ clientHeight แสดงถึงส่วนภายในของออบเจ็กต์ ซึ่งไม่รวมขอบและแถบเลื่อน
ความกว้างขององค์ประกอบคือแอตทริบิวต์สไตล์ "width" ระบบจะคํานวณเป็นค่าสัมบูรณ์โดยคํานวณเปอร์เซ็นต์ของความกว้างของคอนเทนเนอร์
ระบบจะเพิ่มเส้นขอบแนวนอนและระยะห่างจากขอบแล้ว
จนถึงตอนนี้นี่คือการคำนวณ "ความกว้างที่ต้องการ" ระบบจะคำนวณความกว้างขั้นต่ำและสูงสุด
หากความกว้างที่ต้องการมากกว่าความกว้างสูงสุด ระบบจะใช้ความกว้างสูงสุด หากน้อยกว่าความกว้างขั้นต่ำ (หน่วยที่เล็กที่สุดซึ่งแบ่งไม่ได้) ระบบจะใช้ความกว้างขั้นต่ำ
ระบบจะแคชค่าไว้ในกรณีที่ต้องใช้เลย์เอาต์ แต่ความกว้างจะไม่เปลี่ยนแปลง
การขึ้นบรรทัดใหม่
เมื่อโปรแกรมแสดงผลที่อยู่ตรงกลางของเลย์เอาต์ตัดสินใจว่าต้องแบ่งบรรทัด โปรแกรมแสดงผลจะหยุดและส่งต่อไปยังรายการหลักของเลย์เอาต์ว่าต้องแบ่งบรรทัด รายการหลักจะสร้างโปรแกรมแสดงผลเพิ่มเติมและเรียกใช้เลย์เอาต์ในรายการเหล่านั้น
การวาดภาพ
ในขั้นตอนการวาดภาพ ระบบจะเรียกใช้เมธอด "paint()" ของโปรแกรมแสดงผลเพื่อแสดงเนื้อหาบนหน้าจอ การวาดภาพใช้คอมโพเนนต์โครงสร้างพื้นฐาน UI
ทั้งหมดและเพิ่มขึ้น
เช่นเดียวกับเลย์เอาต์ การวาดภาพอาจเป็นแบบส่วนกลางได้เช่นกัน (ทั้งต้นไม้ได้รับการวาดภาพ) หรือแบบเพิ่ม ในการแสดงภาพแบบเพิ่มทีละส่วน โปรแกรมแสดงผลบางรายการจะเปลี่ยนแปลงในลักษณะที่ไม่ส่งผลต่อทั้งต้นไม้ โปรแกรมแสดงผลที่เปลี่ยนแปลงจะทำให้สี่เหลี่ยมผืนผ้าบนหน้าจอใช้งานไม่ได้ ซึ่งทำให้ระบบปฏิบัติการเห็นว่าเป็น "พื้นที่ที่เปลี่ยนแปลง" และสร้างเหตุการณ์ "การวาด" ระบบปฏิบัติการจะดำเนินการอย่างชาญฉลาดและรวมหลายภูมิภาคเข้าด้วยกัน ใน Chrome การดำเนินการจะซับซ้อนกว่าเนื่องจากโปรแกรมแสดงผลอยู่ในกระบวนการอื่นนอกเหนือจากกระบวนการหลัก Chrome จะจำลองลักษณะการทํางานของระบบปฏิบัติการในระดับหนึ่ง งานนำเสนอจะคอยฟังเหตุการณ์เหล่านี้และมอบหมายข้อความไปยังรูทการแสดงผล ระบบจะไปยังส่วนต่างๆ ของต้นไม้จนกว่าจะพบโปรแกรมแสดงผลที่เกี่ยวข้อง โดยจะวาดภาพตัวเองใหม่ (และมักจะวาดภาพองค์ประกอบย่อยด้วย)
คำสั่งซื้อภาพวาด
CSS2 กําหนดลําดับของกระบวนการวาด ซึ่งก็คือลําดับที่ซ้อนองค์ประกอบในบริบทการซ้อน ลําดับนี้มีผลกับการเพ้นท์เนื่องจากกองจะได้รับการเพ้นท์จากด้านหลังไปด้านหน้า ลําดับการซ้อนของโปรแกรมแสดงผลบล็อกมีดังนี้
- สีพื้นหลัง
- ภาพพื้นหลัง
- border
- เด็ก
- outline
รายการที่แสดงของ Firefox
Firefox จะตรวจสอบต้นไม้เรนเดอร์และสร้างรายการการแสดงผลสำหรับสี่เหลี่ยมผืนผ้าที่วาด ซึ่งมีโปรแกรมแสดงผลที่เกี่ยวข้องกับสี่เหลี่ยมผืนผ้าในลําดับการวาดที่ถูกต้อง (พื้นหลังของโปรแกรมแสดงผล ตามด้วยเส้นขอบ ฯลฯ)
วิธีนี้จะทำให้ต้องวนผ่านต้นไม้เพียงครั้งเดียวสำหรับการวาดภาพใหม่แทนที่จะวนหลายครั้ง เช่น การวาดพื้นหลังทั้งหมด ตามด้วยภาพทั้งหมด ตามด้วยเส้นขอบทั้งหมด เป็นต้น
Firefox จะเพิ่มประสิทธิภาพกระบวนการนี้โดยไม่เพิ่มองค์ประกอบที่จะซ่อนอยู่ เช่น องค์ประกอบที่อยู่ใต้องค์ประกอบทึบแสงอื่นๆ โดยสมบูรณ์
ที่เก็บข้อมูลสี่เหลี่ยมผืนผ้า WebKit
WebKit จะบันทึกสี่เหลี่ยมผืนผ้าเก่าเป็นบิตแมปก่อนที่จะวาดใหม่ จากนั้นจะวาดเฉพาะส่วนต่างระหว่างสี่เหลี่ยมผืนผ้าใหม่และสี่เหลี่ยมผืนผ้าเก่า
การเปลี่ยนแปลงแบบไดนามิก
เบราว์เซอร์จะพยายามดำเนินการน้อยที่สุดเพื่อตอบสนองต่อการเปลี่ยนแปลง ดังนั้น การเปลี่ยนแปลงสีขององค์ประกอบจะทําให้องค์ประกอบนั้นวาดภาพใหม่เท่านั้น การเปลี่ยนแปลงตำแหน่งองค์ประกอบจะทำให้เลย์เอาต์และองค์ประกอบย่อยขององค์ประกอบนั้นๆ รวมถึงองค์ประกอบอื่นๆ ในลําดับชั้นเดียวกันต้องวาดใหม่ การเพิ่มโหนด DOM จะทําให้เลย์เอาต์และภาพโหนดนั้นวาดใหม่ การเปลี่ยนแปลงที่สำคัญ เช่น การเพิ่มขนาดแบบอักษรขององค์ประกอบ "html" จะทําให้แคชใช้งานไม่ได้ การจัดวางใหม่ และการวาดภาพทั้งต้นไม้อีกครั้ง
เทรดของเครื่องมือแสดงผล
เครื่องมือแสดงผลเป็นแบบเธรดเดียว เกือบทุกอย่างจะเกิดขึ้นในชุดข้อความเดียว ยกเว้นการดำเนินการของเครือข่าย ใน Firefox และ Safari เทรดนี้จะเป็นเทรดหลักของเบราว์เซอร์ ใน Chrome จะเป็นเธรดหลักของกระบวนการแท็บ
การดำเนินการกับเครือข่ายจะดำเนินการโดยเธรดหลายรายการที่ทำงานพร้อมกันได้ จำนวนการเชื่อมต่อแบบขนานมีขีดจํากัด (โดยปกติคือ 2-6 การเชื่อมต่อ)
ลูปเหตุการณ์
เทรดหลักของเบราว์เซอร์คือลูปเหตุการณ์ การดำเนินการนี้จะวนซ้ำไปเรื่อยๆ โดยจะรอเหตุการณ์ (เช่น เหตุการณ์เลย์เอาต์และการวาดภาพ) และประมวลผลเหตุการณ์เหล่านั้น นี่คือโค้ด Firefox สําหรับลูปเหตุการณ์หลัก
while (!mExiting)
NS_ProcessNextEvent(thread);
รูปแบบภาพ CSS2
แคนวาส
ตามข้อกำหนด CSS2 คำว่า Canvas หมายถึง "พื้นที่ที่แสดงผลโครงสร้างการจัดรูปแบบ" ซึ่งเป็นตำแหน่งที่เบราว์เซอร์วาดเนื้อหา
พื้นที่ทำงานจะมีขนาดไม่จำกัดสำหรับมิติข้อมูลแต่ละรายการของพื้นที่ แต่เบราว์เซอร์จะเลือกความกว้างเริ่มต้นตามขนาดของวิวพอร์ต
ตาม www.w3.org/TR/CSS2/zindex.html ระบุว่า Canvas จะโปร่งใสหากอยู่ภายใน Canvas อื่น และจะมีสีที่เบราว์เซอร์กำหนดหากไม่ใช่
รูปแบบกล่อง CSS
รูปแบบกล่อง CSS อธิบายถึงกล่องสี่เหลี่ยมผืนผ้าที่สร้างขึ้นสำหรับองค์ประกอบในลําดับชั้นเอกสารและวางตามรูปแบบการจัดรูปแบบภาพ
กล่องแต่ละกล่องมีพื้นที่เนื้อหา (เช่น ข้อความ รูปภาพ ฯลฯ) และพื้นที่ระยะห่างจากขอบ เส้นขอบ และขอบโดยรอบ (ไม่บังคับ)
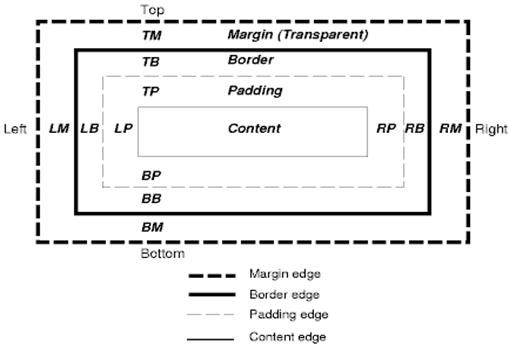
แต่ละโหนดจะสร้างกล่องดังกล่าว 0…n กล่อง
องค์ประกอบทั้งหมดมีพร็อพเพอร์ตี้ "display" ที่กำหนดประเภทของกล่องที่จะสร้างขึ้น
ตัวอย่าง
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
ค่าเริ่มต้นคือ "ในบรรทัด" แต่ชีตสไตล์ของเบราว์เซอร์อาจตั้งค่าเริ่มต้นอื่นๆ เช่น การแสดงผลเริ่มต้นสำหรับองค์ประกอบ "div" คือบล็อก
ดูตัวอย่างสไตล์ชีตเริ่มต้นได้ที่นี่ www.w3.org/TR/CSS2/sample.html
รูปแบบการอธิบายหัวข้อต่างๆ แก่ลูกค้า
โดยรูปแบบมีด้วยกัน 3 รูปแบบ ดังนี้
- ปกติ: ระบบจะจัดวางออบเจ็กต์ตามตำแหน่งในเอกสาร ซึ่งหมายความว่าตําแหน่งในต้นไม้แสดงผลจะเหมือนกับตําแหน่งในต้นไม้ DOM และวางตามประเภทและขนาดของกล่อง
- ลอย: ระบบจะวางวัตถุตามลำดับปกติก่อน จากนั้นจะย้ายไปทางซ้ายหรือขวาให้มากที่สุด
- Absolute: วางออบเจ็กต์ไว้ในแผนผังการแสดงผลในตำแหน่งอื่นที่ไม่ใช่ในแผนผัง DOM
รูปแบบการจัดวางจะกำหนดโดยพร็อพเพอร์ตี้ "position" และแอตทริบิวต์ "float"
- คงที่และสัมพัทธ์ทำให้เกิดลำดับปกติ
- absolute และ fixed ทําให้เกิดการกําหนดตําแหน่งแบบสัมบูรณ์
ในตำแหน่งแบบคงที่ ระบบจะไม่กำหนดตำแหน่งใดๆ และใช้ตำแหน่งเริ่มต้น ในรูปแบบอื่นๆ ผู้เขียนจะระบุตำแหน่ง เช่น บน ล่าง ซ้าย ขวา
การวางกล่องจะขึ้นอยู่กับปัจจัยต่อไปนี้
- ประเภทกล่อง
- ขนาดกล่อง
- รูปแบบการอธิบายหัวข้อต่างๆ แก่ลูกค้า
- ข้อมูลภายนอก เช่น ขนาดรูปภาพและขนาดหน้าจอ
ประเภทของ Box
กล่องบล็อก: สร้างบล็อก - มีสี่เหลี่ยมผืนผ้าของตัวเองในหน้าต่างเบราว์เซอร์

กล่องในบรรทัด: ไม่มีบล็อกของตัวเอง แต่อยู่ภายในบล็อกที่รองรับ
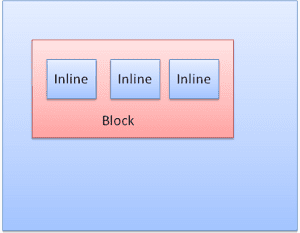
บล็อกจะได้รับการจัดรูปแบบตามแนวตั้งทีละรายการ ข้อความย่อยจะได้รับการจัดรูปแบบในแนวนอน
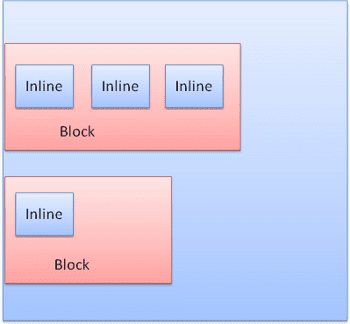
ช่องในบรรทัดจะวางไว้ภายในบรรทัดหรือ "กล่องบรรทัด" เส้นมีความสูงอย่างน้อยเท่ากับช่องที่สูงที่สุด แต่อาจสูงกว่าได้เมื่อช่องต่างๆ ได้รับการจัดแนว "เส้นฐาน" ซึ่งหมายความว่าส่วนล่างขององค์ประกอบจะจัดแนวที่จุดของช่องอื่นที่ไม่ใช่ด้านล่าง หากความกว้างของคอนเทนเนอร์ไม่เพียงพอ ระบบจะใส่บรรทัดย่อยในหลายบรรทัด ซึ่งมักเกิดขึ้นในย่อหน้า
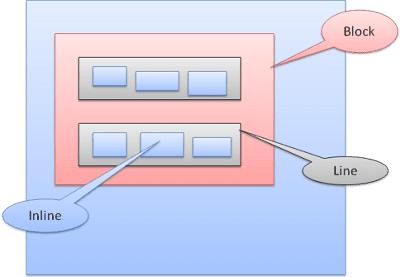
การอธิบายหัวข้อต่างๆ แก่ลูกค้า
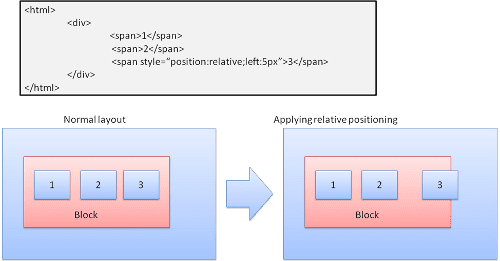
ญาติ
การวางตำแหน่งแบบสัมพัทธ์ - วางตำแหน่งตามปกติแล้วเลื่อนตามค่าเดลต้าที่ต้องการ
แบบลอย
กล่องลอยจะเลื่อนไปทางซ้ายหรือขวาของบรรทัด ฟีเจอร์ที่น่าสนใจคือกล่องอื่นๆ จะไหลไปรอบๆ HTML
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
มีลักษณะดังนี้

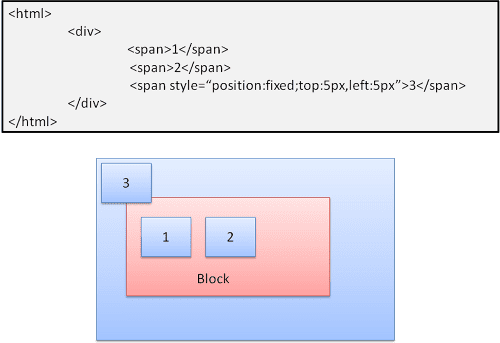
สัมบูรณ์และคงที่
เลย์เอาต์จะกําหนดไว้อย่างละเอียดโดยไม่คำนึงถึงขั้นตอนปกติ องค์ประกอบไม่ได้อยู่ในขั้นตอนปกติ มิติข้อมูลจะสัมพันธ์กับคอนเทนเนอร์ ในแบบคงที่ คอนเทนเนอร์จะเป็นวิวพอร์ต
การนําเสนอแบบเลเยอร์
ซึ่งระบุโดยพร็อพเพอร์ตี้ CSS ของ z-index ซึ่งแสดงถึงมิติข้อมูลที่สามของกล่อง ได้แก่ ตําแหน่งตาม "แกน z"
กล่องจะแบ่งออกเป็นกอง (เรียกว่าบริบทการซ้อน) ในแต่ละกอง องค์ประกอบที่อยู่ด้านหลังจะแสดงก่อน ส่วนองค์ประกอบที่อยู่ด้านหน้าจะแสดงที่ด้านบน ซึ่งอยู่ใกล้กับผู้ใช้มากกว่า ในกรณีที่ซ้อนทับกัน องค์ประกอบที่อยู่ด้านหน้าสุดจะซ่อนองค์ประกอบก่อนหน้า
ระบบจะจัดเรียงกองตามพร็อพเพอร์ตี้ z-index กล่องที่มีแอตทริบิวต์ "z-index" จะสร้างกองซ้อนในพื้นที่ วิวพอร์ตมีสแต็กด้านนอก
ตัวอย่าง
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
ผลลัพธ์ที่ได้จะเป็นดังนี้

แม้ว่า div สีแดงจะมาก่อน div สีเขียวในมาร์กอัป และควรจะแสดงก่อนในโฟลว์ปกติ แต่พร็อพเพอร์ตี้ z-index สูงกว่า จึงอยู่ข้างหน้าในกองที่เก็บโดยกล่องรูท
แหล่งข้อมูล
สถาปัตยกรรมเบราว์เซอร์
- Grosskurth, Alan. สถาปัตยกรรมอ้างอิงสำหรับเว็บเบราว์เซอร์ (pdf)
- Gupta, Vineet วิธีการทำงานของเบราว์เซอร์ - ส่วนที่ 1 - สถาปัตยกรรม
การแยกวิเคราะห์
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (หรือที่เรียกว่า "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe The Bold and the Beautiful: ร่างใหม่ 2 ฉบับสำหรับ HTML 5
Firefox
- L. David Baron, HTML และ CSS ที่เร็วขึ้น: ข้อมูลภายในของเครื่องมือวางเลย์เอาต์สำหรับนักพัฒนาเว็บ
- L. David Baron, HTML และ CSS ที่เร็วขึ้น: ข้อมูลภายในของเครื่องมือวางเลย์เอาต์สำหรับนักพัฒนาเว็บ (วิดีโอการพูดคุยเรื่องเทคโนโลยีของ Google)
- L. David Baron จากโปรแกรมจัดวางของ Mozilla
- L. David Baron จากเอกสารประกอบเกี่ยวกับระบบสไตล์ของ Mozilla
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, ภาพรวมของ Gecko
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, การใช้ CSS(ส่วนที่ 1)
- David Hyatt, ภาพรวมของ WebCore
- David Hyatt จาก WebCore Rendering
- David Hyatt, The FOUC Problem
ข้อกำหนดของ W3C
วิธีการบิลด์เบราว์เซอร์
คำแปล
หน้านี้ได้รับการแปลเป็นภาษาญี่ปุ่น 2 ครั้ง ดังนี้
- วิธีการทํางานของเบราว์เซอร์ - เบื้องหลังของเว็บเบราว์เซอร์สมัยใหม่ (ญี่ปุ่น) โดย @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 โดย @ikeike443 และ @kiyoto01
คุณสามารถดูคำแปลภาษาเกาหลีและตุรกีที่โฮสต์ภายนอกได้
ขอขอบคุณทุกคน