
現代網路瀏覽器的幕後


前言
這份 WebKit 和 Gecko 內部運作方式的完整入門指南,是以色列開發人員 Tali Garsiel 進行大量研究後的成果。在過去幾年,她查看了所有已發布的瀏覽器內部資料,並花費大量時間閱讀網路瀏覽器原始碼。她寫道:
身為網頁開發人員,瞭解瀏覽器作業的內部運作方式有助於做出更明智的決策,並瞭解開發最佳做法的背後原因。雖然這份文件相當冗長,但我們建議您花點時間深入瞭解。絕對值得您花時間進行這項作業。
Chrome 開發人員關係團隊成員 Paul Irish
簡介
網頁瀏覽器是最廣泛使用的軟體。在本教學課程中,我將說明這些功能的幕後運作方式。我們會在您在網址列中輸入 google.com 後,直到瀏覽器畫面顯示 Google 頁面為止,觀察這項操作的結果。
我們將討論的瀏覽器
目前電腦上有五款主要瀏覽器:Chrome、Internet Explorer、Firefox、Safari 和 Opera。在行動裝置上,主要的瀏覽器包括 Android 瀏覽器、iPhone、Opera Mini 和 Opera Mobile、UC 瀏覽器、Nokia S40/S60 瀏覽器和 Chrome,其中除了 Opera 瀏覽器外,其他都是以 WebKit 為基礎。我將以 Firefox、Chrome 和 Safari (部分為開源) 為例說明。根據 StatCounter 統計資料 (截至 2013 年 6 月),Chrome、Firefox 和 Safari 約佔全球桌上型瀏覽器使用率的 71%。在行動裝置上,Android 瀏覽器、iPhone 和 Chrome 約占 54% 的使用量。
瀏覽器的主要功能
瀏覽器的主要功能是從伺服器要求您選擇的網頁資源,並在瀏覽器視窗中顯示。資源通常是 HTML 文件,但也可能是 PDF、圖片或其他類型的內容。使用者會使用 URI (統一資源識別項) 指定資源的位置。
瀏覽器解讀及顯示 HTML 檔案的方式,已在 HTML 和 CSS 規格中指定。這些規格由 W3C (全球資訊網協會) 機構維護,該機構是網路標準機構。多年以來,瀏覽器只遵循部分規格,並自行開發擴充功能。這會導致網頁作者發生嚴重的相容性問題。目前大多數瀏覽器或多或少都符合規格。
瀏覽器使用者介面有很多共同點。常見的使用者介面元素包括:
- 用於插入 URI 的網址列
- 返回和前進按鈕
- 書籤選項
- 用於重新整理或停止載入目前文件的「重新整理」和「停止」按鈕
- 可前往首頁的主畫面按鈕
奇怪的是,瀏覽器的使用者介面並未在任何正式規格中指定,而是來自多年經驗和瀏覽器互相模仿的良好做法。HTML5 規格並未定義瀏覽器必須具備的 UI 元素,但列出了一些常見元素。其中包括網址列、狀態列和工具列。當然,有些功能是特定瀏覽器獨有的,例如 Firefox 的下載管理工具。
高階基礎架構
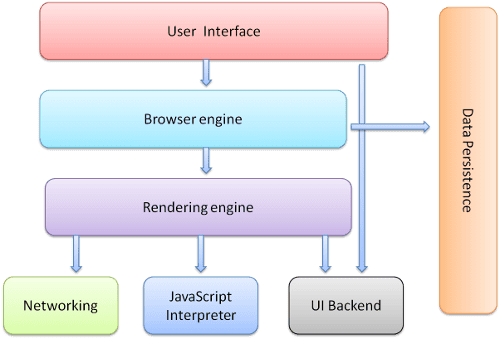
瀏覽器的主要元件如下:
- 使用者介面:包括網址列、前/後按鈕、書籤選單等,瀏覽器顯示畫面中的每個部分,除了您看到要求的網頁的視窗。
- 瀏覽器引擎:在 UI 和轉譯引擎之間進行配對動作。
- 轉譯引擎:負責顯示要求的內容。舉例來說,如果要求的內容是 HTML,轉譯引擎會剖析 HTML 和 CSS,並在畫面上顯示剖析的內容。
- 網路:針對 HTTP 要求等網路呼叫,在平台無關介面後方使用不同平台的不同實作。
- UI 後端:用於繪製基本小工具,例如組合方塊和視窗。此後端會公開非特定平台的一般介面。底下則使用作業系統使用者介面方法。
- JavaScript 解譯器。用於剖析及執行 JavaScript 程式碼。
- 資料儲存。這是持久層。瀏覽器可能需要在本機儲存各種資料,例如 Cookie。瀏覽器也支援 localStorage、IndexedDB、WebSQL 和 FileSystem 等儲存機制。
請注意,Chrome 等瀏覽器會執行多個轉譯引擎執行個體,每個分頁一個。每個分頁都會在獨立的程序中執行。
轉譯引擎
轉譯引擎的職責是...轉譯,也就是在瀏覽器畫面上顯示要求的內容。
根據預設,轉譯引擎可顯示 HTML 和 XML 文件和圖片。它可以透過外掛程式或擴充功能顯示其他類型的資料,例如使用 PDF 檢視器外掛程式顯示 PDF 文件。不過,本章將著重於主要用途:使用 CSS 格式化 HTML 和圖片。
不同的瀏覽器會使用不同的轉譯引擎:Internet Explorer 使用 Trident、Firefox 使用 Gecko、Safari 使用 WebKit。Chrome 和 Opera (15 版起) 使用 Blink,這是 WebKit 的分支版本。
WebKit 是開放原始碼轉譯引擎,最初是 Linux 平台的引擎,後來經過 Apple 修改,可支援 Mac 和 Windows。
主要流程
轉譯引擎會開始從網路層取得要求文件的內容。這通常會以 8 kB 的區塊完成。
之後,轉譯引擎的基本流程如下:

轉譯引擎會開始剖析 HTML 文件,並將元素轉換為「內容樹狀結構」樹狀結構中的 DOM 節點。引擎會剖析外部 CSS 檔案和樣式元素中的樣式資料。樣式資訊和 HTML 中的視覺指示會用來建立另一個樹狀結構:轉譯樹狀結構。
轉譯樹狀結構包含矩形,其中包含顏色和尺寸等視覺屬性。矩形會以正確的順序顯示在畫面上。
算繪樹狀結構建構完成後,系統會進行「版面配置」程序。也就是說,您必須為每個節點提供在畫面上顯示的確切座標。接下來是繪製階段,系統會遍歷轉譯樹狀結構,並使用 UI 後端層繪製每個節點。
請務必瞭解,這項作業是漸進式的。為了提供更好的使用者體驗,算繪引擎會盡快嘗試在螢幕上顯示內容。不會等到所有 HTML 都剖析完畢,才開始建構及安排轉譯樹狀結構。系統會剖析並顯示部分內容,同時繼續處理網路持續傳送的其他內容。
主要流程範例
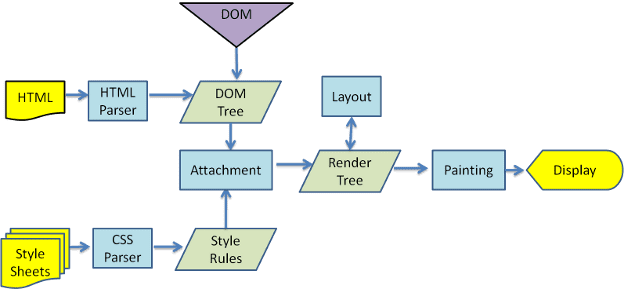
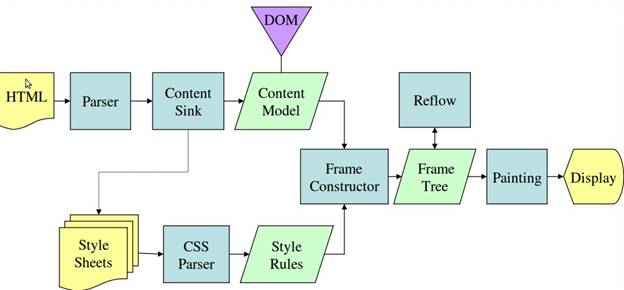
從圖 3 和 4 可知,雖然 WebKit 和 Gecko 使用的術語略有不同,但流程基本上相同。
Gecko 將視覺格式化元素的樹狀結構稱為「影格樹狀結構」。每個元素都是一個影格。WebKit 使用「轉譯樹狀結構」一詞,其中包含「轉譯物件」。WebKit 使用「版面配置」一詞來表示元素的放置方式,而 Gecko 則稱之為「Reflow」。「Attachment」是 WebKit 的術語,用於連結 DOM 節點和視覺資訊,以建立轉譯樹狀結構。非語意方面的小差異是,Gecko 在 HTML 和 DOM 樹狀結構之間有額外的層級。這稱為「內容匯流」,是用來製作 DOM 元素的工廠。我們將討論流程的各個部分:
剖析 - 一般
由於剖析是轉譯引擎中非常重要的程序,我們將進一步探討這個程序。首先,我們來簡單介紹剖析。
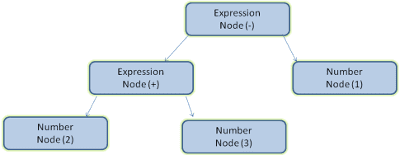
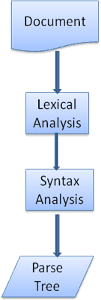
剖析文件是指將文件轉換為程式碼可使用的結構。剖析結果通常是節點樹狀結構,代表文件的結構。這稱為剖析樹或語法樹。
舉例來說,剖析運算式 2 + 3 - 1 可能會傳回這個樹狀結構:
文法
剖析作業會根據文件遵循的語法規則,也就是文件所使用的語言或格式。您可以剖析的每種格式都必須具備確定性的文法,其中包含詞彙和語法規則。這稱為無關聯文法。人類語言並非這類語言,因此無法使用傳統剖析技術剖析。
剖析器 - 字元串結組合
解析可分為兩個子程序:字彙分析和語法分析。
字彙分析是將輸入內容拆解為符記的程序。符記是語言詞彙,也就是有效的構成元素集合。在人類語言中,詞彙表會包含該語言字典中的所有字詞。
語法分析是指套用語言語法規則的過程。
剖析器通常會將工作分派給兩個元件:負責將輸入內容分割成有效符記的剖析器 (有時稱為「剖析器」),以及負責根據語言語法規則分析文件結構,進而建構剖析樹的剖析器。
解析器會知道如何移除空白字元和換行字元等不相關的字元。
剖析程序是重複執行的過程。剖析器通常會向分析器要求新的符記,並嘗試將符記與其中一個語法規則配對。如果符合規則,系統會將符號對應的節點新增至剖析樹狀結構,並要求另一個符號。
如果沒有符合的規則,剖析器會在內部儲存符記,並持續要求符記,直到找到符合所有內部儲存符記的規則為止。如果找不到規則,剖析器就會擲回例外狀況。這表示文件無效,且含有語法錯誤。
翻譯
在許多情況下,剖析樹並非最終產品。剖析通常用於翻譯:將輸入文件轉換為其他格式。編譯就是一個例子。將原始碼編譯為機器碼的編譯器會先將原始碼剖析成剖析樹,然後將樹轉譯為機器碼文件。
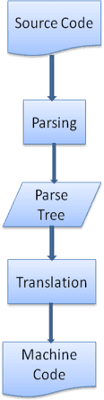
剖析範例
在圖 5 中,我們根據數學運算式建立了剖析樹狀圖。我們來定義簡單的數學語言,並查看剖析程序。
語法:
- 語言語法建構模塊包括運算式、字詞和運算。
- 我們的語言可包含任意數量的運算式。
- 定義為「運算式」後面接著「運算」後面接著另一個運算式
- 運算是加號或減號符號
- 字詞是整數符號或運算式
我們來分析輸入的 2 + 3 - 1。
符合規則的第一個子字串是 2:根據規則 #5,這是一個詞彙。第二個比對結果是 2 + 3:這個結果符合第三個規則:一個字詞後面接著一個運算,再接著另一個字詞。只有在輸入結束時才會觸發下一個比對項目。2 + 3 - 1 是運算式,因為我們已知 2 + 3 是運算式,因此我們有一個運算式,後面接著另一個運算式,再接著另一個運算式。2 + + 不會與任何規則相符,因此是無效的輸入內容。
詞彙和語法的正式定義
詞彙通常會以規則運算式表示。
舉例來說,我們的語言會定義為:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
如您所見,整數是由規則運算式定義。
語法通常會以 BNF 格式定義。我們的語言定義如下:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
我們曾提到,如果語言的語法是無關聯語法,則可由規則剖析器剖析。 無關聯語法的直覺定義,就是可完全以 BNF 表示的語法。如需正式定義,請參閱 維基百科的「無關聯文法」條目
剖析器類型
剖析器分為兩種類型:自上而下的剖析器和自下而上的剖析器。簡單來說,自上而下的剖析器會檢查語法的高層結構,並嘗試找出符合的規則。自底向上的剖析器會從輸入內容開始,逐步轉換為語法規則,從低層級規則開始,直到符合高層級規則為止。
讓我們看看這兩種剖析器如何剖析我們的範例。
自上而下的剖析器會從較高層級規則開始:將 2 + 3 視為運算式。接著,系統會將 2 + 3 - 1 視為運算式 (識別運算式的過程會不斷演進,並與其他規則相符,但起點是最高層級規則)。
自底向上的剖析器會掃描輸入內容,直到找到符合的規則為止。然後,系統會將相符的輸入內容替換為規則。這會持續到輸入結束為止。部分相符的運算式會放置在剖析器的堆疊上。
這種自底向上的剖析器稱為「移位-減少」剖析器,因為輸入內容會向右移動 (想像一下,指標會先指向輸入內容的起始處,然後向右移動),並逐漸減少為語法規則。
自動產生剖析器
有工具可產生剖析器。您可以提供語言的文法 (詞彙和語法規則),讓系統產生可運作的剖析器。建立剖析器需要深入瞭解剖析作業,而且手動建立最佳化剖析器並不容易,因此剖析器產生器非常實用。
WebKit 使用兩種知名的剖析器產生器:Flex 用於建立剖析器,Bison 用於建立剖析器 (您可能會遇到 Lex 和 Yacc 的名稱)。Flex 輸入內容是包含符記規則運算式定義的檔案。Bison 的輸入內容是 BNF 格式的語言語法規則。
HTML 剖析器
HTML 剖析器的工作是將 HTML 標記解析成剖析樹狀結構。
HTML 文法
HTML 的詞彙和語法是由 W3C 機構建立的規格所定義。
如同我們在剖析介紹中所述,文法語法可使用 BNF 等格式正式定義。
很遺憾,所有傳統剖析器主題都不適用於 HTML (我並非為了好玩才提及這些主題,而是因為這些主題會用於剖析 CSS 和 JavaScript)。剖析器需要的無關聯文法無法輕易定義 HTML。
定義 HTML 的正式格式是 DTD (文件類型定義),但這不是無關上下文的語法。
乍看之下,這似乎很奇怪,因為 HTML 與 XML 相當接近。市面上有許多 XML 剖析器可供使用。HTML 有一個 XML 變化版本 - XHTML - 那麼兩者有什麼差異?
差異在於 HTML 方法更「寬容」:您可以省略特定標記 (系統會隱含新增),或有時省略起始或結尾標記等等。整體來說,這是一種「軟性」語法,與 XML 的嚴格語法不同。
這個看似微不足道的細節,其實意義重大。另一方面,這也是 HTML 如此受歡迎的主要原因:它會原諒你的錯誤,讓網頁作者更輕鬆地進行編寫。另一方面,這會導致難以編寫正式文法。因此,歸納來說,由於 HTML 的文法並非無關上下文,因此傳統剖析器無法輕易剖析 HTML。XML 剖析器無法剖析 HTML。
HTML DTD
HTML 定義採用 DTD 格式。這個格式用於定義 SGML 家族的語言。此格式包含所有允許元素的定義、屬性和階層。如先前所述,HTML DTD 並未形成無關聯文法的文法。
DTD 有幾種變化版本。嚴格模式只符合規格,但其他模式則支援瀏覽器過去使用的標記。目的是與舊版內容回溯相容。目前的嚴格 DTD 如下:www.w3.org/TR/html4/strict.dtd
DOM
輸出樹狀結構 (「剖析樹狀結構」) 是 DOM 元素和屬性節點的樹狀結構。DOM 是文件物件模型的簡稱。它是 HTML 文件的物件呈現方式,也是 HTML 元素與 JavaScript 等外部世界之間的介面。
樹狀結構的根節點是「Document」物件。
DOM 與標記幾乎是一對一的關係。例如:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
這個標記會轉譯為下列 DOM 樹狀結構:
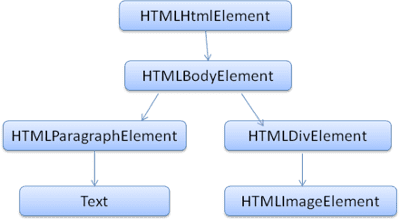
與 HTML 一樣,DOM 是由 W3C 機構指定。請參閱 www.w3.org/DOM/DOMTR。這是用於操作文件的泛型規格。特定模組會說明 HTML 專屬元素。如要查看 HTML 定義,請前往以下網址:www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html。
當我說樹狀結構包含 DOM 節點時,我的意思是樹狀結構是由實作其中一個 DOM 介面的元素所建構而成。瀏覽器會使用具體實作項目,這些項目具有瀏覽器在內部使用的其他屬性。
剖析演算法
如先前章節所述,無法使用一般由上而下或由下而上的剖析器剖析 HTML。
原因如下:
- 語言的寬容性質。
- 瀏覽器具有傳統的錯誤容許值,可支援已知的無效 HTML 情況。
- 剖析程序是可重入的。在其他語言中,原始碼在剖析期間不會變更,但在 HTML 中,動態程式碼 (例如含有
document.write()呼叫的指令碼元素) 可以新增額外的符記,因此剖析程序實際上會修改輸入內容。
由於無法使用一般剖析技術,瀏覽器會建立自訂剖析器來剖析 HTML。
HTML5 規範詳細說明解析演算法。這個演算法包含兩個階段:符記化和樹狀結構建構。
符記化是字彙分析,會將輸入內容剖析為符記。HTML 符記包括起始標記、結束標記、屬性名稱和屬性值。
符號產生器會辨識符號,並將其傳遞給樹狀結構建構函式,然後使用下一個字元來辨識下一個符號,如此類推,直到輸入結束為止。
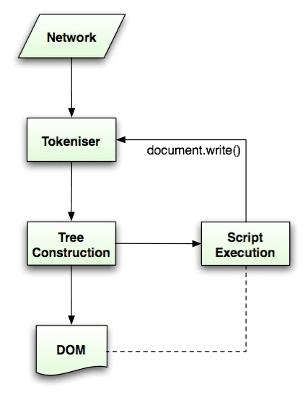
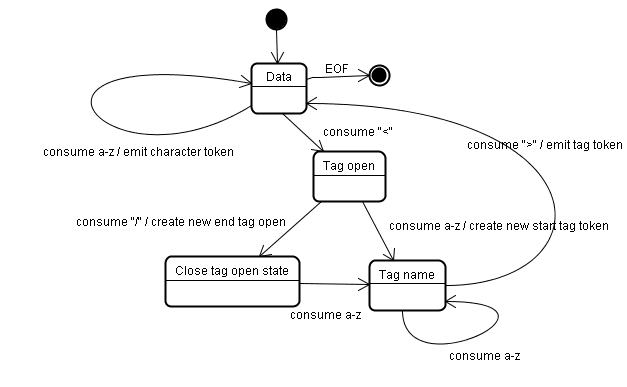
符號化演算法
演算法的輸出內容是 HTML 符記。演算法會以狀態機器的形式表示。每個狀態都會消耗輸入串流的一或多個字元,並根據這些字元更新下一個狀態。這項決定會受到目前的符號化狀態和樹狀結構建構狀態影響。也就是說,同一個已消耗的字元會根據目前狀態,產生不同的正確後續狀態。演算法太複雜,無法完整說明,因此我們提供一個簡單的例子,協助您瞭解原則。
基本範例 - 將下列 HTML 進行符記化:
<html>
<body>
Hello world
</body>
</html>
初始狀態為「資料狀態」。遇到 < 字元時,狀態會變更為 「Tag open state」。使用 a-z 字元會導致系統建立「開始標記符記」,狀態會變更為「標記名稱狀態」。在 > 字元用盡前,我們會維持這個狀態。每個字元都會附加至新的符記名稱。在本範例中,建立的權杖是 html 權杖。
到達 > 標記時,系統會發出目前的符記,並將狀態變更回「Data state」。<body> 標記會採用相同的步驟處理。到目前為止,系統已傳送 html 和 body 標記。我們現在回到「資料狀態」。使用 Hello world 的 H 字元會導致字元符記的建立和發出,直到達到 </body> 的 < 為止。我們會為 Hello world 的每個字元產生字元符記。
我們現在回到「代碼開啟狀態」。使用下一個輸入 / 會導致 end tag token 建立,並移至「Tag name state」。我們會一直處於這個狀態,直到達到 >。接著,系統會發出新的代碼權杖,然後我們會回到「資料狀態」。</html> 輸入內容會與前述情況相同。
樹狀結構建構演算法
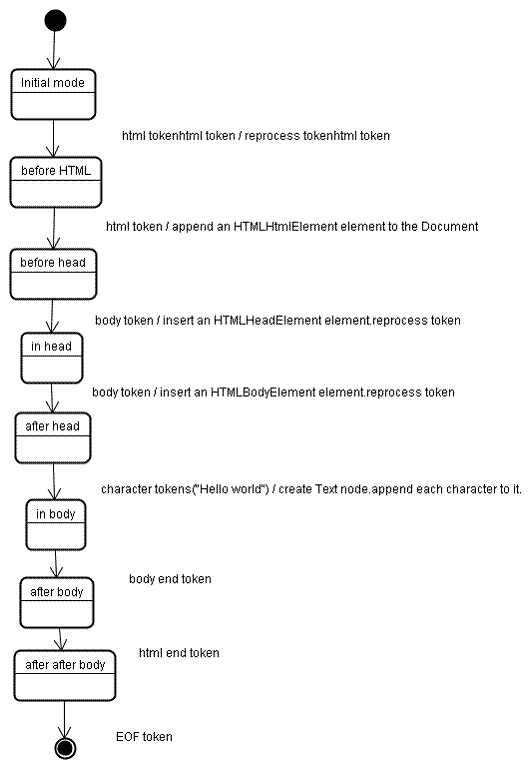
建立剖析器時,系統會建立 Document 物件。在樹狀結構建構階段,系統會修改根目錄中的 DOM 樹狀結構,並新增元素。分割符產生的每個節點都會由樹狀結構建構函式處理。對於每個符記,規格會定義哪些 DOM 元素與該符記相關,並為該符記建立這些元素。元素會加入 DOM 樹狀結構,以及開啟元素的堆疊。這個堆疊用於修正巢狀不相符和未關閉的標記。演算法也稱為狀態機。這些狀態稱為「插入模式」。
我們來看看樹狀結構的建立程序,以範例輸入內容為例:
<html>
<body>
Hello world
</body>
</html>
樹狀結構建構階段的輸入內容,是符記化階段的符記序列。第一個模式是「initial mode」。收到「html」權杖後,系統會移至「before html」模式,並在該模式中重新處理權杖。這會導致 HTMLHtmlElement 元素建立作業,並附加至根 Document 物件。
狀態會變更為 "before head"。接著會收到「body」權杖。雖然我們沒有「head」符記,但系統會隱含建立 HTMLHeadElement,並將其新增至樹狀結構。
我們現在要切換至「in head」模式,然後切換至「after head」模式。系統會重新處理主體符記、建立及插入 HTMLBodyElement,並將模式轉移至「in body」。
系統現在已收到「Hello world」字串的字元符記。第一個會導致「Text」節點的建立和插入作業,而其他字元會附加到該節點。
接收主體結束權杖後,系統會轉移至「主體結束後」模式。我們現在會收到 HTML 結束標記,並切換至 "after after body" 模式。接收檔案結束符號會結束剖析作業。
剖析完成後的動作
在此階段,瀏覽器會將文件標示為互動式,並開始剖析處於「延遲」模式的指令碼,也就是應在剖析文件後執行的指令碼。接著,系統會將文件狀態設為「complete」,並觸發「load」事件。
您可以參閱 HTML5 規格中的完整符號化和樹狀結構建立演算法。
瀏覽器的錯誤容許值
您不會在 HTML 網頁上看到「語法無效」錯誤。瀏覽器會修正任何無效內容,並繼續執行。
請參考以下 HTML:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
我一定違反了約一百萬條規則 (「mytag」不是標準代碼、「p」和「div」元素的錯誤巢狀結構等等),但瀏覽器仍能正確顯示,不會出現錯誤。因此,許多剖析器程式碼會修正 HTML 作者的錯誤。
瀏覽器的錯誤處理方式相當一致,但令人驚訝的是,這並非 HTML 規格的一部分。就像書籤和前進/後退按鈕一樣,這只是瀏覽器多年來的設計。許多網站都會重複使用已知的無效 HTML 結構,而瀏覽器會嘗試以與其他瀏覽器相容的方式修正這些結構。
HTML5 規格確實定義了其中部分要求。(WebKit 在 HTML 剖析器類別開頭的註解中,清楚總結了這項資訊)。
剖析器會將符記化輸入內容剖析至文件中,建立文件樹狀結構。如果文件格式正確,剖析作業就會很簡單。
很遺憾,我們必須處理許多格式不正確的 HTML 文件,因此剖析器必須容許錯誤。
我們至少必須處理下列錯誤情況:
- 系統明確禁止在某些外層標記中加入元素。在這種情況下,我們應該關閉所有標記,直到遇到禁止元素的標記為止,然後再新增元素。
- 我們無法直接新增元素。可能是撰寫文件的人忘了在其中加入某些標記,也可能是中間的標記是選用的。以下標記可能會發生這種情況:HTML HEAD BODY TBODY TR TD LI (我忘了其他標記了嗎?)。
- 我們想在內嵌元素中加入區塊元素。關閉所有內嵌元素,直到下一個較高層級的區塊元素為止。
- 如果這麼做無法解決問題,請關閉元素,直到我們允許新增元素為止,或者忽略標記。
以下列舉幾個 WebKit 錯誤容許值的範例:
</br> 取代 <br>
部分網站使用 </br>,而非 <br>。為了與 IE 和 Firefox 相容,WebKit 會將此視為 <br>。
程式碼:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
請注意,錯誤處理是內部作業,不會向使用者顯示。
遺漏的資料表
孤立表格是指位於其他表格內,但不在表格儲存格內的表格。
例如:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit 會將階層變更為兩個同層表格:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
程式碼:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit 會為目前的元素內容使用堆疊:將內部表格彈出外部表格堆疊。這兩個資料表現在是同層級。
巢狀表單元素
如果使用者將表單放入另一個表單,系統會忽略第二個表單。
程式碼:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
標記階層過深
這項評論不證自明。
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
html 或 body 結尾標記位置錯誤
再次強調,留言不證自明。
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
因此,除非您想在 WebKit 錯誤容許度程式碼片段中顯示為範例,否則請務必編寫正確格式的 HTML。
CSS 剖析
還記得前言中的剖析概念嗎?與 HTML 不同,CSS 是無關聯文法的語法,可使用前言中所述的剖析器類型進行剖析。事實上,CSS 規格定義了 CSS 詞法和語法文法。
以下舉幾個例子:
詞彙規則 (字彙) 是由每個符記的規則運算式定義:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
「ident」是「identifier」的簡寫,類似於類別名稱。「name」是元素 ID (由「#」所參照)
語法文法說明請參閱 BNF。
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
說明:
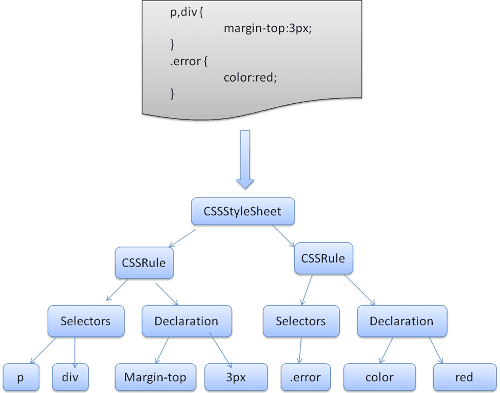
規則集的結構如下:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error 和 a.error 是選取器。大括號內的部分包含這個規則集套用到的規則。這個結構體在以下定義中正式定義:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
也就是說,規則集是選取器,或可選的多個選取器,以半形逗號和空格分隔 (S 代表空格)。規則集包含大括號,內含聲明,或可選的多個以分號分隔的聲明。以下 BNF 定義會定義「宣告」和「選取器」。
WebKit CSS 剖析器
WebKit 會使用 Flex 和 Bison 剖析器產生器,自動從 CSS 文法檔案建立剖析器。如您在剖析器介紹中所知,Bison 會建立自下而上的位移-減少剖析器。Firefox 使用手動編寫的由上而下的剖析器。無論採用何種方式,每個 CSS 檔案都會解析為 StyleSheet 物件。每個物件都包含 CSS 規則。CSS 規則物件包含選取器和宣告物件,以及與 CSS 文法相對應的其他物件。
指令碼和樣式表單的處理順序
指令碼
網頁的模型是同步的。作者預期在剖析器到達 <script> 標記時,系統會立即剖析及執行指令碼。在執行指令碼之前,文件的剖析作業會暫停。如果是外部腳本,則必須先從網路擷取資源,這也是同步執行的作業,且在擷取資源前,剖析會暫停。這也是多年來的模式,並在 HTML4 和 5 規格中指定。作者可以在指令碼中加入「defer」屬性,這樣指令碼就不會停止文件剖析,而是在剖析完成後執行。HTML5 新增了一個選項,可將指令碼標示為非同步,以便由不同的執行緒進行剖析及執行。
推測剖析
WebKit 和 Firefox 都會進行這項最佳化。執行指令碼時,另一個執行緒會剖析文件的其餘部分,並找出需要從網路載入的其他資源,然後載入這些資源。這樣一來,資源就能在平行連線中載入,整體速度也會提升。注意:推測剖析器只會剖析外部資源的參照,例如外部指令碼、樣式表單和圖片。它不會修改 DOM 樹狀結構,而是交由主要剖析器處理。
樣式表
另一方面,樣式表單則採用不同的模型。從概念上來說,由於樣式表不會變更 DOM 樹狀結構,因此沒有理由等待樣式表並停止文件剖析。不過,在文件剖析階段,指令碼會要求樣式資訊,這會造成問題。如果尚未載入和剖析樣式,指令碼就會取得錯誤答案,這可能會導致許多問題。這似乎是極端情況,但相當常見。如果仍有樣式表正在載入及剖析,Firefox 會封鎖所有指令碼。WebKit 只會在試圖存取可能受到未載入樣式表格影響的特定樣式屬性時,封鎖指令碼。
轉譯樹狀結構建構
在建構 DOM 樹狀結構時,瀏覽器會建構另一個樹狀結構,即轉譯樹狀結構。這個樹狀圖是視覺元素的顯示順序。這是文件的視覺化呈現結果。這個樹狀結構的用途是讓內容以正確順序繪製。
Firefox 會將轉譯樹狀結構中的元素稱為「影格」。WebKit 會使用「轉譯器」或「轉譯物件」一詞。
轉譯器會瞭解如何安排及繪製本身和子項。
WebKit 的 RenderObject 類別是轉譯器的基礎類別,定義如下:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
每個轉譯器都代表一個矩形區域,通常會對應至節點的 CSS 方塊,如 CSS2 規格所述。其中包含寬度、高度和位置等幾何資訊。
盒子類型會受到與節點相關的樣式屬性「display」值影響 (請參閱「樣式運算」一節)。以下是 WebKit 程式碼,可根據顯示屬性決定應為 DOM 節點建立哪種轉譯器:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
系統也會考量元素類型:例如,表單控制項和表格有特殊框架。
在 WebKit 中,如果元素想要建立特殊轉譯器,就會覆寫 createRenderer() 方法。轉譯器會指向包含非幾何資訊的樣式物件。
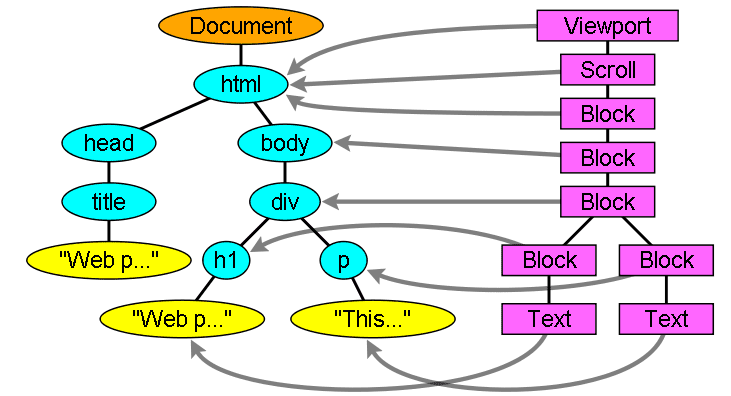
轉譯樹狀結構與 DOM 樹狀結構的關聯
轉譯器對應至 DOM 元素,但關係並非一對一。非視覺 DOM 元素不會插入轉譯樹狀結構中。例如「head」元素。此外,如果元素的顯示值已指派為「none」,則不會顯示在樹狀結構中 (顯示值為「hidden」的元素會顯示在樹狀結構中)。
有幾個 DOM 元素對應至多個視覺物件。這些元素通常具有複雜的結構,無法用單一矩形描述。舉例來說,「select」元素有三個轉譯器:一個用於顯示區域、一個用於下拉式清單方塊,以及一個用於按鈕。此外,如果文字因寬度不足而分成多行,系統會將新行新增為額外的轉譯器。
另一個多重轉譯器的例子是損毀的 HTML。根據 CSS 規格,內嵌元素只能包含區塊元素或內嵌元素。在混合內容的情況下,系統會建立匿名區塊轉譯器,用於包裝內嵌元素。
部分轉譯物件對應至 DOM 節點,但不在樹狀結構中的相同位置。浮動和絕對定位元素會脫離流程,放置在樹狀結構的不同部分,並對應至實際影格。預留位置框架應位於該處。
建構樹狀結構的流程
在 Firefox 中,系統會將簡報註冊為 DOM 更新的事件監聽器。簡報會將影格建立作業委派給 FrameConstructor,而建構函式會解析樣式 (請參閱「樣式運算」) 並建立影格。
在 WebKit 中,解析樣式並建立轉譯器的程序稱為「附件」。每個 DOM 節點都有「attach」方法。附加作業是同步的,在 DOM 樹狀結構中插入節點會呼叫新節點的「attach」方法。
處理 html 和 body 標記後,系統會建構轉譯樹狀結構的根節點。根轉譯物件對應至 CSS 規格所稱的包含區塊:包含所有其他區塊的頂層區塊。其尺寸為可視區域:瀏覽器視窗顯示區域的尺寸。Firefox 稱之為 ViewPortFrame,WebKit 則稱之為 RenderView。這是文件所指向的轉譯物件。樹狀結構的其餘部分則會以 DOM 節點插入的方式建構。
請參閱處理模型的 CSS2 規格。
樣式運算
建構轉譯樹狀結構時,需要計算每個轉譯物件的視覺屬性。這項作業是透過計算每個元素的樣式屬性來完成。
樣式包含不同來源的樣式表、內嵌樣式元素和 HTML 中的視覺屬性 (例如「bgcolor」屬性)。後者會轉譯為相符的 CSS 樣式屬性。
樣式表來源包括瀏覽器的預設樣式表、網頁作者提供的樣式表,以及使用者樣式表 (這些是瀏覽器使用者提供的樣式表)。舉例來說,在 Firefox 中,您可以將樣式表放入「Firefox 設定檔」資料夾中。
樣式運算會帶來一些困難:
- 樣式資料是相當龐大的結構,可容納大量樣式屬性,因此可能會導致記憶體問題。
找出各個元素的配對規則,如果未經過最佳化,可能會導致效能問題。為每個元素遍歷整個規則清單以尋找相符項目是一項繁重的工作。選取器可能具有複雜的結構,導致比對程序從看似可行的路徑開始,但後來證明該路徑無效,因此必須嘗試其他路徑。
舉例來說,以下是複合選取器:
div div div div{ ... }表示規則適用於 3 個 div 的子項
<div>。假設您想檢查規則是否適用於特定<div>元素。您可以選擇樹狀結構中的特定路徑進行檢查。您可能需要向上逐一檢查節點樹狀結構,才能發現只有兩個 div,而規則並未套用。接著,您需要嘗試樹狀結構中的其他路徑。套用規則時,會涉及相當複雜的連鎖規則,用於定義規則的階層。
讓我們看看瀏覽器如何處理這些問題:
分享樣式資料
WebKit 節點會參照樣式物件 (RenderStyle)。在某些情況下,這些物件可由節點共用。節點是兄弟姊妹或表親,且:
- 元素必須處於相同的滑鼠狀態 (例如,一個元素無法處於 :hover 狀態,而另一個元素則否)
- 兩個元素都不應有 ID
- 標記名稱應相符
- 類別屬性應相符
- 對應的屬性組合必須相同
- 連結狀態必須一致
- 焦點狀態必須一致
- 這兩個元素都不會受到屬性選取器的影響,所謂的「影響」是指在選取器中任何位置使用屬性選取器的任何選取器比對
- 元素上不得有內嵌樣式屬性
- 不得使用任何同層選取器。WebCore 在遇到任何同層別的選取器時,就會擲回全域切換鍵,並在同層別的選取器出現時,停用整份文件的樣式共用功能。包括 + 選取器和 :first-child 和 :last-child 等選取器。
Firefox 規則樹狀結構
Firefox 有兩個額外的樹狀結構,可簡化樣式運算:規則樹狀結構和樣式內容樹狀結構。WebKit 也有樣式物件,但並未儲存在樹狀結構中 (例如樣式內容樹狀結構),只有 DOM 節點會指向相關樣式。
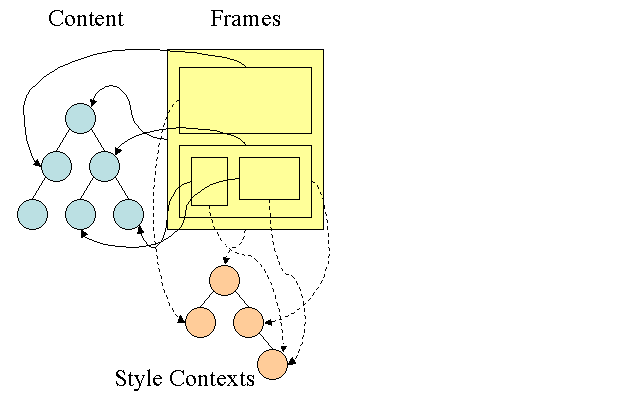
樣式內容包含結束值。系統會依正確順序套用所有比對規則,並執行操控,將這些值從邏輯值轉換為具體值,藉此計算值。舉例來說,如果邏輯值是螢幕的百分比,系統會計算並轉換為絕對單位。規則樹狀圖的概念非常聰明。這可讓這些值在節點之間共用,避免重複計算。這麼做也可以節省空間。
所有符合的規則都會儲存在樹狀結構中。路徑中的底層節點優先順序較高。樹狀圖包含找到的所有相符規則路徑。儲存規則是延遲執行的作業。系統不會一開始就為每個節點計算樹狀結構,但只要需要計算節點樣式,就會將計算出的路徑新增至樹狀結構。
這個想法是將樹狀結構路徑視為字典中的字詞。假設我們已計算出這個規則樹狀結構:
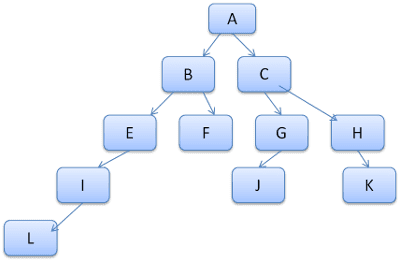
假設我們需要比對內容樹狀結構中其他元素的規則,並發現相符的規則 (正確順序) 為 B-E-I。我們已在樹狀結構中找到這個路徑,因為我們已計算出路徑 A-B-E-I-L。我們現在的工作量會減少。
讓我們來看看樹狀結構如何幫助我們節省工作量。
將資料分割為結構體
樣式內容會分成結構體。這些結構體包含邊框或顏色等特定類別的樣式資訊。結構體中的所有屬性都會繼承或不繼承。繼承的屬性是指除非由元素定義,否則會從父項繼承的屬性。如未定義,非繼承屬性 (稱為「重設」屬性) 會使用預設值。
樹狀結構可在樹狀結構中快取整個結構體 (包含已計算的結束值),協助我們處理這項問題。這個概念是,如果底層節點未提供結構體定義,則可使用上層節點中的快取結構體。
使用規則樹狀圖計算樣式內容
計算特定元素的樣式內容時,我們會先在規則樹狀結構中計算路徑,或使用現有的路徑。接著,我們開始在路徑中套用規則,以便在新的樣式內容中填入結構體。我們從路徑的底層節點開始,也就是優先順序最高的節點 (通常是最具體的 selector),然後向上逐一遍歷樹狀結構,直到結構體填滿為止。如果該規則節點中沒有結構體規格,我們可以大幅改善效能 - 我們會向上尋找節點,直到找到完整指定該結構體的節點並指向該節點 - 這是最佳的最佳化方式 - 整個結構體都會共用。這樣一來,系統就不需要計算結束值和記憶體。
如果我們發現部分定義,就會向上移動樹狀結構,直到結構體填滿為止。
如果我們找不到結構體的定義,如果結構體是「繼承」類型,我們會在內容樹狀結構中指向父項的結構體。在這種情況下,我們也成功共用結構體。如果是重設結構體,則會使用預設值。
如果最具體的節點確實會新增值,我們就需要進行一些額外計算,將其轉換為實際值。接著,我們會將結果快取到樹狀節點,以供子節點使用。
如果元素有兄弟或姊妹元素,而這些元素指向相同的樹狀節點,則整個樣式內容可供這些元素共用。
我們來看看以下範例: 假設我們有以下 HTML
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
以及下列規則:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
為簡化流程,我們假設只需要填入兩個結構體:顏色結構體和邊距結構體。顏色結構體只包含一個成員:顏色。邊距結構體包含四個邊。
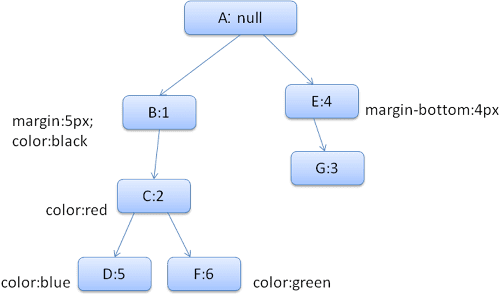
產生的規則樹狀圖如下所示 (節點會標示節點名稱:所指向規則的編號):
內容樹狀結構如下所示 (節點名稱:所指向的規則節點):
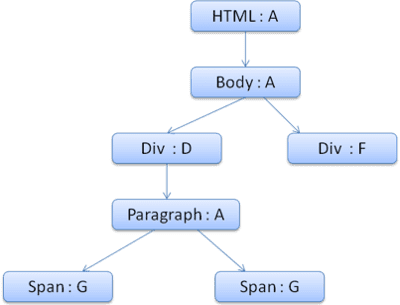
假設我們剖析 HTML 並取得第二個 <div> 標記。我們需要為這個節點建立樣式內容,並填入其樣式結構體。
我們會比對規則,發現 <div> 的規則為 1、2 和 6。也就是說,樹狀結構中已有元素可用的現有路徑,我們只需為規則 6 (樹狀結構中的節點 F) 新增另一個節點即可。
我們會建立樣式背景資訊,並將其放入背景資訊樹狀結構中。新的樣式內容會指向規則樹狀結構中的節點 F。
我們現在需要填入樣式結構體。我們將從填入邊界結構開始。由於最後一個規則節點 (F) 不會加入邊距結構體,我們可以向上瀏覽樹狀結構,直到找到先前節點插入時計算的快取結構體,然後使用該結構體。我們會在節點 B 中找到它,這是指定邊界規則的最高層節點。
我們確實有顏色結構體的定義,因此無法使用快取的結構體。由於顏色只有一個屬性,因此我們不需要向上移動樹狀結構來填入其他屬性。我們會計算結束值 (將字串轉換為 RGB 等),並在這個節點上快取已計算的結構體。
處理第二個 <span> 元素的工作更簡單。我們會比對規則,並得出結論,指出它指向規則 G,就像前一個 span 一樣。由於同層元素會指向相同節點,因此我們可以共用整個樣式內容,並只指向前一個 span 的內容。
如果結構體包含從父項繼承的規則,則會在內容樹狀結構中快取 (顏色屬性實際上會繼承,但 Firefox 會將其視為重設,並在規則樹狀結構中快取)。
舉例來說,如果我們在段落中新增字型規則:
p {font-family: Verdana; font size: 10px; font-weight: bold}
接著,段落元素 (即內容樹狀結構中 div 的子項) 可能會與其父項共用相同的字型結構。這是指未為段落指定字型規則的情況。
在沒有規則樹狀結構的 WebKit 中,系統會四次遍歷符合條件的宣告。系統會先套用非重要高優先順序的屬性 (其他屬性會依附於這些屬性,因此應先套用這些屬性,例如顯示屬性),然後再套用重要高優先順序的屬性、一般優先順序的非重要屬性,最後再套用一般優先順序的重要屬性。也就是說,重複出現的屬性會依照正確的層疊順序解析。最後一個為準。
總結來說,共用樣式物件 (全部或其中的部分結構體) 可解決問題 1 和 3。Firefox 規則樹狀結構也有助於以正確順序套用屬性。
操控簡易比對的規則
您可以透過以下幾種方式取得樣式規則:
- 外部樣式表或樣式元素中的 CSS 規則。
css p {color: blue} - 內嵌樣式屬性,例如
html <p style="color: blue" /> - HTML 視覺屬性 (會對應至相關樣式規則)
html <p bgcolor="blue" />後兩者擁有樣式屬性,且 HTML 屬性可使用元素做為索引進行對應,因此很容易與元素配對。
如同先前在第 2 個問題中所述,CSS 規則比對可能較為棘手。為瞭解決這個問題,我們調整了規則,讓使用者更容易存取。
剖析樣式表後,系統會根據選取器將規則加入其中一個雜湊圖中。您可以依 ID、類別名稱、標記名稱建立地圖,也可以為不屬於這些類別的任何項目建立一般地圖。如果選取器是 ID,則會將規則新增至 ID 對應表;如果是類別,則會新增至類別對應表等。
這項操作可讓規則比對更加容易。您不必查看每個宣告:我們可以從對應的圖表中擷取元素的相關規則。這項最佳化功能可消除 95% 以上的規則,因此在比對程序中,系統甚至不需要考慮這些規則(4.1)。
舉例來說,請參考下列樣式規則:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
第一個規則會插入類別對應表。將第二個值放入 ID 對應表,第三個值放入代碼對應表。
針對下列 HTML 片段:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
我們會先嘗試找出 p 元素的規則。類別對應會包含「error」索引鍵,您可以在該索引鍵下找到「p.error」的規則。div 元素會在 ID 對應項目 (鍵為 ID) 和標記對應項目中加入相關規則。因此,您只需要找出哪些由鍵值擷取的規則確實相符即可。
舉例來說,如果 div 的規則如下:
table div {margin: 5px}
因為鍵是最右邊的選取器,所以系統仍會從標記對應表中擷取該元素,但這不會與沒有表格祖系的 div 元素相符。
WebKit 和 Firefox 都會執行這項操作。
樣式表級聯順序
樣式物件具有與每個視覺屬性相對應的屬性 (所有 CSS 屬性,但更通用)。如果屬性未由任何相符的規則定義,則部分屬性可由父項元素樣式物件繼承。其他屬性則有預設值。
當定義多於一個時,就會發生問題,這時就需要使用層疊順序來解決問題。
樣式屬性的宣告可以在多個樣式表單中出現,也可以在樣式表單中出現多次。也就是說,套用規則的順序非常重要。這稱為「層疊」順序。根據 CSS2 規格,級聯順序如下 (由低至高):
- 瀏覽器宣告
- 使用者一般宣告
- 作者的一般聲明
- 作者重要聲明
- 使用者重要聲明
瀏覽器宣告的重要性最低,只有在宣告標示為重要時,使用者才會覆寫作者。同樣順序的宣告會依特定性排序,然後按照指定的順序排序。HTML 視覺屬性會轉譯為相符的 CSS 宣告。系統會將這些規則視為優先順序較低的作者規則。
優先權
選取器的特殊性是由 CSS2 規格定義,如下所示:
- 如果宣告來自「樣式」屬性,而非含有選取器的規則,則計為 1,否則為 0 (= a)
- 計算選取器中的 ID 屬性數量 (= b)
- 計算選取器中其他屬性和擬似類別的數量 (= c)
- 計算選取器中元素名稱和疑似元素的數量 (= d)
將四個數字 a-b-c-d 連接起來 (在具有大基數的數字系統中),即可得出特定值。
您需要使用的數字基數,取決於某個類別中最高的計數。
舉例來說,如果 a=14,您可以使用十六進制基數。在 a=17 的情況下,您需要 17 位數的數字基底。後者情況可能會發生在以下類似的選取器中:html body div div p… (選取器中有 17 個標記,不太可能)。
以下提供一些例子:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
排序規則
比對規則後,系統會依據層疊規則排序。WebKit 會針對小型清單使用氣泡排序,針對大型清單使用合併排序。WebKit 會透過覆寫規則的 > 運算子來實作排序:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
逐步程序
WebKit 會使用標記,標示是否已載入所有頂層樣式表單 (包括 @imports)。如果附加時樣式未完全載入,系統會使用預留位置,並在文件中標示,等到樣式表單載入後,系統就會重新計算。
版面配置
建立並新增至樹狀結構的轉譯器,並沒有位置和大小。計算這些值的程序稱為版面配置或重新流動。
HTML 使用以流程為基礎的版面配置模型,這表示在大多數情況下,可以在單一傳送次數中計算幾何圖形。後續「流程中」的元素通常不會影響「流程中」較早出現的元素幾何形狀,因此版面配置可以從左到右、從上到下地在文件中進行。但也有例外狀況:例如,HTML 表格可能需要多次掃描。
座標系是相對於根框架。使用頂端和左側座標。
版面配置是遞迴程序。它會從根轉譯器開始,該轉譯器對應至 HTML 文件的 <html> 元素。版面配置會繼續遞迴檢查部分或所有影格階層,為每個需要的轉譯器計算幾何資訊。
根轉譯器的位置為 0,0,其尺寸為可視區域,也就是瀏覽器視窗的可視部分。
所有轉譯器都有「版面配置」或「重新流動」方法,每個轉譯器都會叫用其子項的版面配置方法。
髒位元系統
為了避免每次進行小幅變更時都執行完整版面配置,瀏覽器會使用「髒位元」系統。變更或新增的轉譯器會將自身和子項標示為「髒」:需要版面配置。
有兩個標記:「dirty」和「children are dirty」,這表示即使轉譯器本身可能沒問題,但至少有一個需要版面的子項。
全域和逐步版面配置
版面配置可在整個轉譯樹狀結構中觸發 - 這就是「全域」版面配置。導致這種情況的原因可能包括:
- 全域樣式變更會影響所有轉譯器,例如字型大小變更。
- 因為螢幕大小已調整
版面配置可採漸進式,只會排版髒汙的轉譯器 (這可能會造成損壞,需要額外的版面配置)。
當轉譯器髒了,系統會以非同步方式觸發增量版面配置。舉例來說,當額外內容從網路傳送並新增至 DOM 樹狀結構後,新轉譯器就會附加至轉譯樹狀結構。
非同步和同步版面配置
增量版面配置會以非同步方式完成。Firefox 會為漸進式版面配置排入「重新流動指令」,而排程器會觸發這些指令的批次執行作業。WebKit 也提供計時器,可執行漸進式版面配置,也就是會逐一檢查樹狀結構,並將「髒」轉譯器排版。
要求樣式資訊 (例如「offsetHeight」) 的指令碼,可以同步觸發增量版版面配置。
全域版面配置通常會同步觸發。
有時,系統會在初始版面配置後觸發版面配置回呼,因為捲動位置等某些屬性會發生變化。
最佳化
當版面配置由「調整大小」或轉譯器位置(而非大小) 變更觸發時,系統會從快取取得轉譯大小,而非重新計算…
在某些情況下,系統只會修改子樹狀結構,而不會從根目錄開始進行版面配置。當變更是局部且不會影響周圍內容時,就可能發生這種情況,例如插入文字欄位的文字 (否則每個按鍵都會觸發從根目錄開始的版面配置)。
版面配置程序
版面配置通常採用以下模式:
- 父項轉譯器會決定自身的寬度。
- 父項會檢查子項,並執行下列操作:
- 放置子轉譯器 (設定其 x 和 y)。
- 視需要呼叫子版面配置 (如果子版面配置不正確或處於全域版面配置,或其他原因),以便計算子項的高度。
- 父項會使用子項的累積高度,以及邊框和邊框間距的高度,設定自身的高度,這會由父項轉譯器的父項使用。
- 將髒位設為 false。
Firefox 會使用「state」物件(nsHTMLReflowState) 做為版面配置參數 (稱為「reflow」)。其中狀態包含父項寬度。
Firefox 版面配置的輸出內容是「metrics」物件(nsHTMLReflowMetrics)。其中會包含算繪器計算的高度。
寬度計算
算出轉譯器的寬度時,系統會使用容器區塊的寬度、轉譯器的樣式「width」屬性、邊界和邊框。
例如,下列 div 的寬度:
<div style="width: 30%"/>
WebKit 會計算以下值(RenderBox 類別的 calcWidth 方法):
- 容器寬度為容器可用的寬度和 0 的最大值。在這種情況下,availableWidth 就是 contentWidth,計算方式如下:
clientWidth() - paddingLeft() - paddingRight()
clientWidth 和 clientHeight 代表物件的內部,不含邊框和捲軸。
元素的寬度是「width」樣式屬性。系統會計算容器寬度的百分比,並將其做為絕對值。
水平邊框和邊距現已加入。
這就是「偏好寬度」的計算方式。系統現在會計算最小和最大寬度。
如果偏好寬度大於最大寬度,系統會使用最大寬度。如果寬度小於最小寬度 (最小不可分割的單位),則會使用最小寬度。
系統會快取這些值,以備版面配置需要時使用,但寬度不會變更。
換行
當版面配置中間的轉譯器判斷需要中斷時,轉譯器會停止並傳播至版面配置的父項,表示需要中斷。父項會建立額外的轉譯器,並在這些轉譯器上呼叫版面配置。
繪畫
在繪製階段,系統會逐一檢查轉譯樹狀結構,並呼叫轉譯器的「paint()」方法,在螢幕上顯示內容。繪圖會使用 UI 基礎架構元件。
全域和增量
與版面配置一樣,繪製作業也可以是全域性的 (繪製整個樹狀結構) 或遞增式。在逐步繪製時,部分轉譯器會以不會影響整個樹狀結構的方式進行變更。變更後的轉譯器會使其在螢幕上的矩形失效。這會導致作業系統將其視為「髒區域」,並產生「繪圖」事件。作業系統會巧妙地將多個區域合併為一個區域。在 Chrome 中,情況會更複雜,因為轉譯器位於與主程序不同的程序中。Chrome 會在某種程度上模擬作業系統的行為。簡報會監聽這些事件,並將訊息委派給轉譯根目錄。系統會逐一檢查樹狀結構,直到找到相關的轉譯器為止。它會重新繪製自身 (通常是子項)。
繪製順序
CSS2 定義了繪製程序的順序。這其實是元素在堆疊情境中堆疊的順序。這個順序會影響繪圖,因為堆疊會從後方到前方繪製。區塊轉譯器的堆疊順序如下:
- 背景顏色
- 背景圖片
- border
- 孩子
- outline
Firefox 顯示清單
Firefox 會查看轉譯樹狀結構,並為已著色的矩形建立顯示清單。它包含與矩形相關的算繪器,並以正確的繪製順序排列 (算繪器的背景、邊框等)。
這樣一來,系統只需為重新繪製作業遍歷一次樹狀結構,而非多次遍歷 (繪製所有背景、所有圖片、所有邊框等)。
Firefox 會避免加入會遭到隱藏的元素,例如完全位於其他不透明元素下方的元素,藉此最佳化處理程序。
WebKit 矩形儲存空間
重新繪製前,WebKit 會將舊矩形儲存為位圖。接著,只會繪製新矩形與舊矩形之間的差異。
動態變更
瀏覽器會盡量減少回應變更的動作。因此,變更元素的顏色只會導致元素重繪。變更元素位置會導致元素、子項和可能的同胞元素重新繪製版面配置。新增 DOM 節點會導致節點的版面配置和重繪。重大變更 (例如增加「html」元素的字型大小) 會導致快取無效,並重新排版及重新繪製整個樹狀結構。
轉譯引擎的執行緒
算繪引擎為單執行緒。除了網路作業,幾乎所有作業都會在單一執行緒中執行。在 Firefox 和 Safari 中,這是瀏覽器的主執行緒。在 Chrome 中,這會是分頁處理程序的主執行緒。
網路作業可由多個並行執行緒執行。並行連線數量有限 (通常為 2 到 6 個連線)。
事件迴圈
瀏覽器主執行緒是事件迴圈。這是一個無限迴圈,可讓程序持續運作。會等待事件 (例如版面配置和繪圖事件),並加以處理。以下是主要事件迴圈的 Firefox 程式碼:
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 視覺模型
畫布
根據 CSS2 規格,畫布一詞是指「格式化結構算繪的空間」:瀏覽器繪製內容的位置。
無論空間的每個維度為何,畫布都是無限的,但瀏覽器會根據可視區域的尺寸選擇初始寬度。
根據 www.w3.org/TR/CSS2/zindex.html,如果畫布包含在另一個畫布中,則會是透明的,如果不包含則會指定瀏覽器定義的顏色。
CSS 盒模型
CSS 盒模型會說明為文件樹狀結構中的元素產生矩形框,並根據視覺格式設定模型進行版面配置。
每個方塊都有內容區域 (例如文字、圖片等),以及可選的周圍邊框間距、邊框和邊距區域。
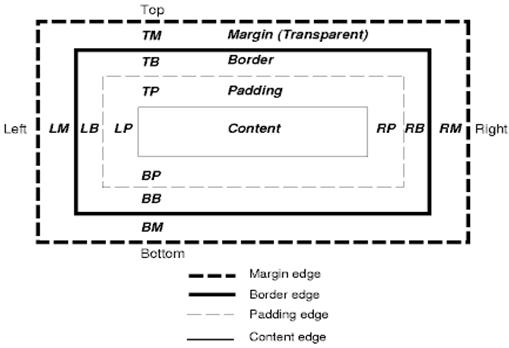
每個節點都會產生 0…n 個此類方塊。
所有元素都有「display」屬性,用於決定要產生的方塊類型。
範例:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
預設值為內嵌,但瀏覽器樣式表可能會設定其他預設值。例如:「div」元素的預設顯示方式為「block」。
如需預設樣式表範例,請參閱 www.w3.org/TR/CSS2/sample.html。
定位配置
共有三種命名方式:
- 正常:物件會根據文件中的位址定位。也就是說,它在轉譯樹狀結構中的位置,就像在 DOM 樹狀結構中的位置一樣,並根據其方塊類型和尺寸進行版面配置
- 浮動:物件會先像正常流程一樣排版,然後盡可能向左或右移動
- 絕對:物件會放置在轉譯樹狀結構中,而非 DOM 樹狀結構
定位配置是由「position」屬性和「float」屬性設定。
- 靜態和相對會導致正常流程
- 絕對和固定會導致絕對定位
在靜態定位中,系統不會定義位置,而是使用預設定位。在其他配置方案中,作者會指定位置:頂端、底部、左側、右側。
盒子的版面配置方式取決於:
- Box 類型
- 盒子尺寸
- 定位配置
- 外部資訊,例如圖片大小和螢幕大小
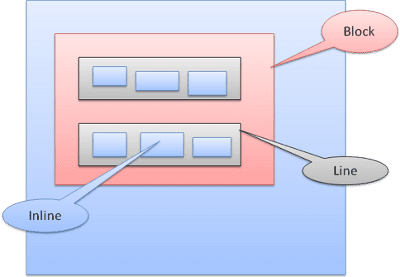
Box 類型
區塊方塊:形成一個區塊,在瀏覽器視窗中具有專屬的矩形。

內嵌邊框:沒有自己的區塊,但位於包含區塊內。
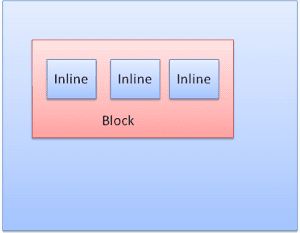
展示塊會以垂直排列的格式一一顯示。內嵌式會以水平格式顯示。
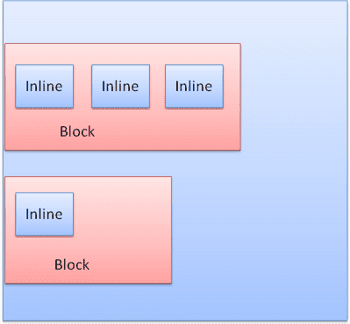
內嵌方塊會放置在行內或「行框」中。當方塊對齊「基線」時,線條的高度至少會與最高的方塊一樣高,但可以更高。所謂「基線」是指元素的底部會與另一個方塊的某個點對齊,而非底部。如果容器寬度不足,內嵌內容會分成多行。這通常是段落中發生的情況。
位置
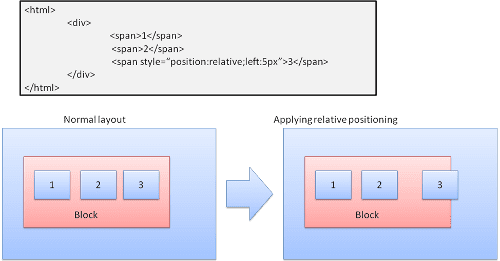
相對時間
相對定位:以一般方式定位,然後根據所需的差異值移動。
浮動
浮動方塊會向左或向右偏移一行。有趣的是,其他方塊會在該方塊周圍流動。HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
如下所示:

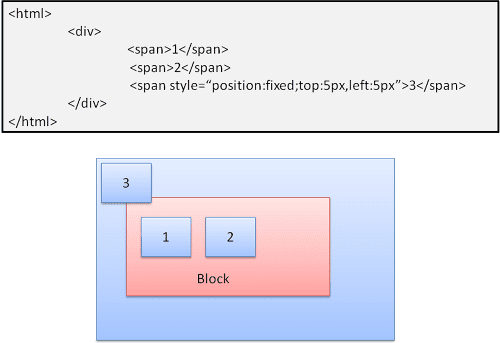
絕對值和固定值
無論一般流程為何,版面配置都會精確定義。元素不會參與一般流程。尺寸是相對於容器而言。在固定模式中,容器就是可視區域。
分層表示法
這是透過 z-index CSS 屬性指定。代表方塊的第三個維度:沿著「z 軸」的位移。
這些方塊會分成堆疊 (稱為堆疊內容)。在每個堆疊中,系統會先繪製背景元素,再繪製前景元素,以便更靠近使用者。如果重疊,最前方的元素會隱藏先前的元素。
堆疊會依據 z-index 屬性排序。具有「z-index」屬性的方塊會形成本機堆疊。可視區域包含外部堆疊。
範例:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
結果如下所示:

雖然紅色 div 在標記中排在綠色 div 之前,且在一般流程中會先繪製,但 z-index 屬性較高,因此在根盒子所保留的堆疊中排在前面。
資源
瀏覽器架構
- Grosskurth, Alan. 網路瀏覽器參考架構 (PDF)
- Gupta, Vineet。瀏覽器的運作方式 - 第 1 部分 - 架構
剖析
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (又稱「Dragon book」),Addison-Wesley,1986 年
- Rick Jelliffe。The Bold and the Beautiful:兩個新的 HTML5 草稿。
Firefox
- L. David Baron,Faster HTML and CSS: Layout Engine Internals for Web Developers。
- L. David Baron,Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron,Mozilla 版面配置引擎
- L. David Baron,Mozilla 系統說明文件樣式
- Chris Waterson,HTML Reflow 相關說明
- Chris Waterson,Gecko 總覽
- Alexander Larsson,HTML HTTP 要求的生命週期
WebKit
- David Hyatt,CSS 實作(第 1 部分)
- David Hyatt, An Overview of WebCore
- David Hyatt,WebCore 算繪
- David Hyatt,The FOUC Problem
W3C 規格
瀏覽器建構指示
翻譯
本頁已翻譯成日文兩次:
- 瀏覽器運作方式 - 現代網路瀏覽器的幕後作業 (日文),作者:@kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 by @ikeike443 and @kiyoto01.
謝謝大家!