
আধুনিক ওয়েব ব্রাউজারগুলির পর্দার আড়ালে


ভূমিকা
WebKit এবং Gecko-এর অভ্যন্তরীণ ক্রিয়াকলাপের উপর এই বিস্তৃত প্রাইমারটি ইসরায়েলি বিকাশকারী তালি গারসিয়েলের করা অনেক গবেষণার ফলাফল। কয়েক বছর ধরে, তিনি ব্রাউজার ইন্টারনাল সম্পর্কে প্রকাশিত সমস্ত ডেটা পর্যালোচনা করেছেন এবং ওয়েব ব্রাউজার সোর্স কোড পড়তে অনেক সময় ব্যয় করেছেন। তিনি লিখেছেন:
একজন ওয়েব ডেভেলপার হিসাবে, ব্রাউজার অপারেশনের অভ্যন্তরীণ বিষয়গুলি শেখা আপনাকে আরও ভাল সিদ্ধান্ত নিতে এবং বিকাশের সর্বোত্তম অনুশীলনের পিছনে ন্যায্যতা জানতে সাহায্য করে ৷ যদিও এটি একটি অপেক্ষাকৃত দীর্ঘ নথি, আমরা আপনাকে খনন করার জন্য কিছু সময় ব্যয় করার পরামর্শ দিচ্ছি৷ আপনি খুশি হবেন৷
পল আইরিশ, ক্রোম বিকাশকারী সম্পর্ক
ভূমিকা
ওয়েব ব্রাউজার হল সবচেয়ে বেশি ব্যবহৃত সফটওয়্যার। এই প্রাইমারে, আমি ব্যাখ্যা করি কিভাবে তারা পর্দার আড়ালে কাজ করে। আপনি ব্রাউজার স্ক্রিনে Google পৃষ্ঠা না দেখা পর্যন্ত ঠিকানা বারে google.com টাইপ করলে কী হয় তা আমরা দেখব।
ব্রাউজার সম্পর্কে আমরা কথা বলতে হবে
বর্তমানে ডেস্কটপে পাঁচটি প্রধান ব্রাউজার ব্যবহার করা হয়েছে: ক্রোম, ইন্টারনেট এক্সপ্লোরার, ফায়ারফক্স, সাফারি এবং অপেরা। মোবাইলে, প্রধান ব্রাউজারগুলি হল অ্যান্ড্রয়েড ব্রাউজার, আইফোন, অপেরা মিনি এবং অপেরা মোবাইল, UC ব্রাউজার, Nokia S40/S60 ব্রাউজার এবং ক্রোম, অপেরা ব্রাউজারগুলি ব্যতীত সবগুলিই ওয়েবকিটের উপর ভিত্তি করে। আমি ওপেন সোর্স ব্রাউজার ফায়ারফক্স এবং ক্রোম এবং সাফারি (যা আংশিকভাবে ওপেন সোর্স) থেকে উদাহরণ দেব। StatCounter পরিসংখ্যান অনুসারে (জুন 2013 অনুযায়ী) ক্রোম, ফায়ারফক্স এবং সাফারি বিশ্বব্যাপী ডেস্কটপ ব্রাউজার ব্যবহারের প্রায় 71% তৈরি করে। মোবাইলে, অ্যান্ড্রয়েড ব্রাউজার, আইফোন এবং ক্রোমের ব্যবহার প্রায় 54%।
ব্রাউজারের প্রধান কার্যকারিতা
একটি ব্রাউজারের প্রধান কাজ হল সার্ভার থেকে অনুরোধ করে এবং ব্রাউজার উইন্ডোতে প্রদর্শন করে আপনার বেছে নেওয়া ওয়েব রিসোর্সটি উপস্থাপন করা। রিসোর্সটি সাধারণত একটি HTML ডকুমেন্ট, তবে এটি একটি PDF, ইমেজ বা অন্য কোনো ধরনের সামগ্রীও হতে পারে। ইউনিফর্ম রিসোর্স আইডেন্টিফায়ার (ইউনিফর্ম রিসোর্স আইডেন্টিফায়ার) ব্যবহার করে রিসোর্সের অবস্থান ব্যবহারকারী দ্বারা নির্দিষ্ট করা হয়।
ব্রাউজার যেভাবে HTML ফাইলগুলিকে ব্যাখ্যা করে এবং প্রদর্শন করে তা HTML এবং CSS স্পেসিফিকেশনে নির্দিষ্ট করা আছে। এই স্পেসিফিকেশনগুলি W3C (ওয়ার্ল্ড ওয়াইড ওয়েব কনসোর্টিয়াম) সংস্থা দ্বারা রক্ষণাবেক্ষণ করা হয়, যা ওয়েবের জন্য মানক সংস্থা। বছরের পর বছর ধরে ব্রাউজারগুলি স্পেসিফিকেশনের শুধুমাত্র একটি অংশ মেনে চলে এবং তাদের নিজস্ব এক্সটেনশন তৈরি করে। এটি ওয়েব লেখকদের জন্য গুরুতর সামঞ্জস্যের সমস্যা সৃষ্টি করেছে। আজকাল বেশিরভাগ ব্রাউজারই কমবেশি স্পেসিফিকেশন মেনে চলে।
ব্রাউজার ইউজার ইন্টারফেস একে অপরের সাথে অনেক মিল আছে। সাধারণ ব্যবহারকারী ইন্টারফেস উপাদানগুলির মধ্যে রয়েছে:
- একটি URI সন্নিবেশ করার জন্য ঠিকানা বার
- পিছনে এবং এগিয়ে বোতাম
- বুকমার্কিং অপশন
- রিফ্রেশ এবং বর্তমান নথি লোড করা বন্ধ করার জন্য বোতামগুলি রিফ্রেশ করুন
- হোম বোতাম যা আপনাকে আপনার হোম পেজে নিয়ে যাবে
আশ্চর্যজনকভাবে, ব্রাউজারের ইউজার ইন্টারফেস কোনো আনুষ্ঠানিক স্পেসিফিকেশনে নির্দিষ্ট করা হয়নি, এটি শুধুমাত্র বছরের পর বছর ধরে তৈরি করা ভাল অনুশীলন এবং ব্রাউজার একে অপরকে অনুকরণ করে। HTML5 স্পেসিফিকেশন ব্রাউজার থাকা আবশ্যক UI উপাদানগুলিকে সংজ্ঞায়িত করে না, তবে কিছু সাধারণ উপাদান তালিকাভুক্ত করে৷ এর মধ্যে অ্যাড্রেস বার, স্ট্যাটাস বার এবং টুল বার রয়েছে। ফায়ারফক্সের ডাউনলোড ম্যানেজারের মতো নির্দিষ্ট ব্রাউজারে অবশ্যই অনন্য বৈশিষ্ট্য রয়েছে।
উচ্চ-স্তরের অবকাঠামো
ব্রাউজারের প্রধান উপাদান হল:
- ইউজার ইন্টারফেস : এর মধ্যে রয়েছে অ্যাড্রেস বার, ব্যাক/ফরওয়ার্ড বোতাম, বুকমার্কিং মেনু, ইত্যাদি। ব্রাউজারের প্রতিটি অংশে আপনি অনুরোধ করা পৃষ্ঠাটি যে উইন্ডোটি দেখেন তা ছাড়া প্রদর্শন করে।
- ব্রাউজার ইঞ্জিন : UI এবং রেন্ডারিং ইঞ্জিনের মধ্যে মার্শাল অ্যাকশন।
- রেন্ডারিং ইঞ্জিন : অনুরোধ করা বিষয়বস্তু প্রদর্শনের জন্য দায়ী। যেমন অনুরোধ করা বিষয়বস্তু যদি HTML হয়, তাহলে রেন্ডারিং ইঞ্জিন HTML এবং CSS পার্স করে এবং পার্স করা কন্টেন্ট স্ক্রিনে প্রদর্শন করে।
- নেটওয়ার্কিং : নেটওয়ার্ক কলের জন্য যেমন HTTP অনুরোধ, একটি প্ল্যাটফর্ম-স্বাধীন ইন্টারফেসের পিছনে বিভিন্ন প্ল্যাটফর্মের জন্য বিভিন্ন বাস্তবায়ন ব্যবহার করে।
- UI ব্যাকএন্ড : কম্বো বক্স এবং উইন্ডোর মতো মৌলিক উইজেটগুলি আঁকার জন্য ব্যবহৃত হয়। এই ব্যাকএন্ড একটি জেনেরিক ইন্টারফেস প্রকাশ করে যা প্ল্যাটফর্ম নির্দিষ্ট নয়। এর নিচে অপারেটিং সিস্টেম ইউজার ইন্টারফেস পদ্ধতি ব্যবহার করা হয়েছে।
- জাভাস্ক্রিপ্ট দোভাষী । জাভাস্ক্রিপ্ট কোড পার্স এবং এক্সিকিউট করতে ব্যবহৃত হয়।
- ডেটা স্টোরেজ । এটি একটি অধ্যবসায় স্তর. ব্রাউজারকে স্থানীয়ভাবে কুকির মতো সব ধরণের ডেটা সংরক্ষণ করতে হতে পারে। ব্রাউজারগুলি স্থানীয় স্টোরেজ, ইনডেক্সডডিবি, ওয়েবএসকিউএল এবং ফাইল সিস্টেমের মতো স্টোরেজ প্রক্রিয়াগুলিকেও সমর্থন করে।
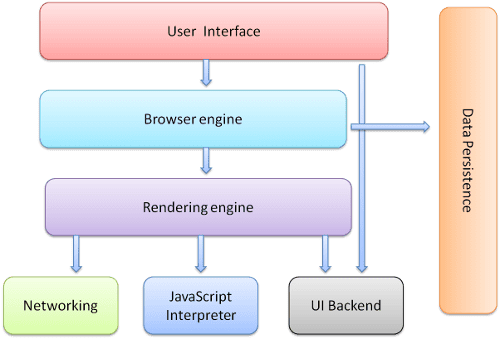
এটি লক্ষ্য করা গুরুত্বপূর্ণ যে Chrome এর মতো ব্রাউজারগুলি রেন্ডারিং ইঞ্জিনের একাধিক উদাহরণ চালায়: প্রতিটি ট্যাবের জন্য একটি। প্রতিটি ট্যাব একটি পৃথক প্রক্রিয়ায় চলে।
রেন্ডারিং ইঞ্জিন
রেন্ডারিং ইঞ্জিনের দায়িত্ব ভাল... রেন্ডারিং, সেটি হল ব্রাউজার স্ক্রিনে অনুরোধ করা বিষয়বস্তু প্রদর্শন।
ডিফল্টরূপে রেন্ডারিং ইঞ্জিন HTML এবং XML নথি এবং ছবি প্রদর্শন করতে পারে। এটি প্লাগ-ইন বা এক্সটেনশনের মাধ্যমে অন্যান্য ধরনের ডেটা প্রদর্শন করতে পারে; উদাহরণস্বরূপ, পিডিএফ ভিউয়ার প্লাগ-ইন ব্যবহার করে পিডিএফ ডকুমেন্ট প্রদর্শন করা। যাইহোক, এই অধ্যায়ে আমরা প্রধান ব্যবহারের ক্ষেত্রে ফোকাস করব: এইচটিএমএল এবং চিত্রগুলি প্রদর্শন করা যা CSS ব্যবহার করে ফর্ম্যাট করা হয়েছে।
বিভিন্ন ব্রাউজার বিভিন্ন রেন্ডারিং ইঞ্জিন ব্যবহার করে: ইন্টারনেট এক্সপ্লোরার ট্রাইডেন্ট ব্যবহার করে, ফায়ারফক্স গেকো ব্যবহার করে, সাফারি ওয়েবকিট ব্যবহার করে। ক্রোম এবং অপেরা (15 সংস্করণ থেকে) ব্লিঙ্ক ব্যবহার করে, ওয়েবকিটের একটি কাঁটা।
ওয়েবকিট হল একটি ওপেন সোর্স রেন্ডারিং ইঞ্জিন যা লিনাক্স প্ল্যাটফর্মের জন্য একটি ইঞ্জিন হিসাবে শুরু হয়েছিল এবং ম্যাক এবং উইন্ডোজ সমর্থন করার জন্য অ্যাপল দ্বারা সংশোধন করা হয়েছিল।
মূল প্রবাহ
রেন্ডারিং ইঞ্জিন নেটওয়ার্কিং স্তর থেকে অনুরোধকৃত নথির বিষয়বস্তু পেতে শুরু করবে। এটি সাধারণত 8kB খণ্ডে করা হবে।
এর পরে, এটি রেন্ডারিং ইঞ্জিনের মৌলিক প্রবাহ:

রেন্ডারিং ইঞ্জিন এইচটিএমএল ডকুমেন্ট পার্সিং শুরু করবে এবং উপাদানগুলিকে "কন্টেন্ট ট্রি" নামক একটি গাছে DOM নোডে রূপান্তর করবে। ইঞ্জিন স্টাইল ডেটা পার্স করবে, উভয় বাহ্যিক CSS ফাইল এবং স্টাইল উপাদানে। এইচটিএমএল-এ ভিজ্যুয়াল নির্দেশাবলীর সাথে স্টাইলিং তথ্য অন্য একটি ট্রি তৈরি করতে ব্যবহার করা হবে: রেন্ডার ট্রি ।
রেন্ডার ট্রিতে রঙ এবং মাত্রার মতো চাক্ষুষ বৈশিষ্ট্য সহ আয়তক্ষেত্র রয়েছে। আয়তক্ষেত্রগুলি পর্দায় প্রদর্শিত হওয়ার জন্য সঠিক ক্রমে রয়েছে৷
রেন্ডার ট্রি নির্মাণের পর এটি একটি " লেআউট " প্রক্রিয়ার মধ্য দিয়ে যায়। এর অর্থ হল প্রতিটি নোডকে সঠিক স্থানাঙ্কগুলি দেওয়া যেখানে এটি পর্দায় উপস্থিত হওয়া উচিত। পরবর্তী ধাপ হল পেইন্টিং - রেন্ডার ট্রিটি ট্রাভার্স করা হবে এবং প্রতিটি নোড UI ব্যাকএন্ড লেয়ার ব্যবহার করে আঁকা হবে।
এটা বোঝা গুরুত্বপূর্ণ যে এটি একটি ধীরে ধীরে প্রক্রিয়া। ভালো ব্যবহারকারীর অভিজ্ঞতার জন্য, রেন্ডারিং ইঞ্জিন যত তাড়াতাড়ি সম্ভব স্ক্রীনে বিষয়বস্তু প্রদর্শন করার চেষ্টা করবে। রেন্ডার ট্রি তৈরি এবং লেআউট শুরু করার আগে সমস্ত HTML পার্স করা পর্যন্ত এটি অপেক্ষা করবে না। বিষয়বস্তুর অংশগুলি পার্স করা হবে এবং প্রদর্শিত হবে, যখন প্রক্রিয়াটি নেটওয়ার্ক থেকে আসা বাকি বিষয়বস্তুর সাথে চলতে থাকবে।
প্রধান প্রবাহ উদাহরণ
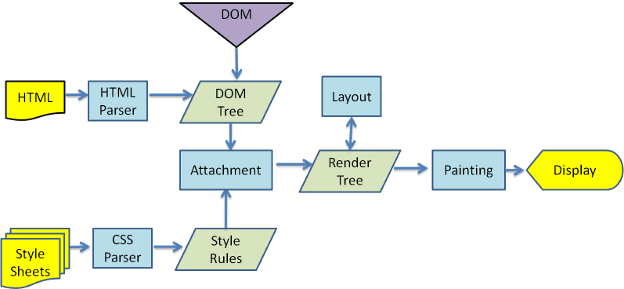
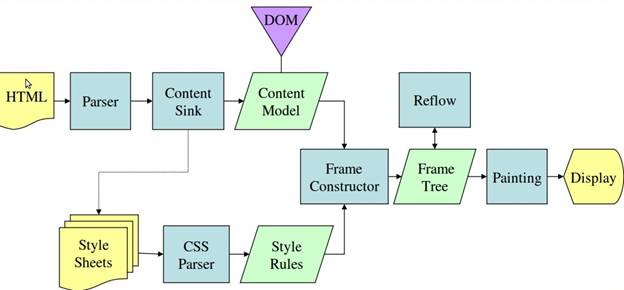
পরিসংখ্যান 3 এবং 4 থেকে আপনি দেখতে পাচ্ছেন যে যদিও WebKit এবং Gecko সামান্য ভিন্ন পরিভাষা ব্যবহার করে, প্রবাহটি মূলত একই।
গেকো চাক্ষুষরূপে বিন্যাসিত উপাদানের গাছকে "ফ্রেম ট্রি" বলে। প্রতিটি উপাদান একটি ফ্রেম. ওয়েবকিট "রেন্ডার ট্রি" শব্দটি ব্যবহার করে এবং এটি "রেন্ডার অবজেক্ট" নিয়ে গঠিত। ওয়েবকিট উপাদান স্থাপনের জন্য "লেআউট" শব্দটি ব্যবহার করে, যখন গেকো এটিকে "রিফ্লো" বলে। "অ্যাটাচমেন্ট" হল ওয়েবকিটের শব্দ যা DOM নোড এবং ভিজ্যুয়াল ইনফরমেশন সংযোগ করার জন্য রেন্ডার ট্রি তৈরি করার জন্য। একটি ছোট অ-অর্থবোধক পার্থক্য হল যে গেকোর HTML এবং DOM গাছের মধ্যে একটি অতিরিক্ত স্তর রয়েছে। এটিকে "কন্টেন্ট সিঙ্ক" বলা হয় এবং এটি DOM উপাদান তৈরির কারখানা। আমরা প্রবাহের প্রতিটি অংশ সম্পর্কে কথা বলব:
পার্সিং - সাধারণ
যেহেতু পার্সিং রেন্ডারিং ইঞ্জিনের মধ্যে একটি অত্যন্ত তাৎপর্যপূর্ণ প্রক্রিয়া, আমরা এটিতে আরও গভীরভাবে যাব। পার্সিং সম্পর্কে একটু ভূমিকা দিয়ে শুরু করা যাক।
একটি নথি পার্স করা মানে কোডটি ব্যবহার করতে পারে এমন একটি কাঠামোতে এটি অনুবাদ করা। পার্সিংয়ের ফলাফল সাধারণত নোডের একটি গাছ যা নথির গঠনকে প্রতিনিধিত্ব করে। একে পার্স ট্রি বা সিনট্যাক্স ট্রি বলা হয়।
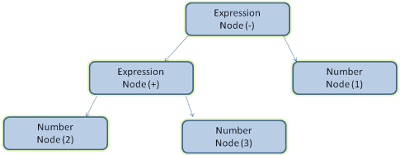
উদাহরণস্বরূপ, এক্সপ্রেশন 2 + 3 - 1 পার্স করা এই ট্রিটি ফিরিয়ে দিতে পারে:
ব্যাকরণ
পার্সিং সিনট্যাক্স নিয়মের উপর ভিত্তি করে যা নথিটি মেনে চলে: যে ভাষা বা বিন্যাসে এটি লেখা হয়েছিল। আপনি পার্স করতে পারেন এমন প্রতিটি বিন্যাসে অবশ্যই শব্দভান্ডার এবং বাক্য গঠনের নিয়ম সমন্বিত নির্ধারক ব্যাকরণ থাকতে হবে। একে বলা হয় প্রসঙ্গ মুক্ত ব্যাকরণ । মানুষের ভাষা এই ধরনের ভাষা নয় এবং তাই প্রচলিত পার্সিং কৌশল দিয়ে পার্স করা যায় না।
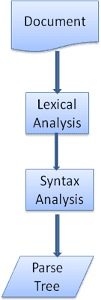
পার্সার - লেক্সার সংমিশ্রণ
পার্সিংকে দুটি উপ প্রক্রিয়ায় বিভক্ত করা যেতে পারে: আভিধানিক বিশ্লেষণ এবং বাক্য গঠন বিশ্লেষণ।
আভিধানিক বিশ্লেষণ হল ইনপুটকে টোকেনে ভাঙার প্রক্রিয়া। টোকেন হল ভাষার শব্দভাণ্ডার: বৈধ বিল্ডিং ব্লকের সংগ্রহ। মানুষের ভাষায় এটি সেই ভাষার অভিধানে উপস্থিত সমস্ত শব্দ নিয়ে গঠিত।
সিনট্যাক্স বিশ্লেষণ হল ভাষার সিনট্যাক্স নিয়ম প্রয়োগ করা।
পার্সাররা সাধারণত দুটি উপাদানের মধ্যে কাজকে ভাগ করে: লেক্সার (কখনও কখনও টোকেনাইজার বলা হয়) যেটি বৈধ টোকেনে ইনপুট ভাঙ্গার জন্য দায়ী, এবং পার্সার যেটি ভাষা সিনট্যাক্স নিয়ম অনুসারে নথির কাঠামো বিশ্লেষণ করে পার্স ট্রি তৈরির জন্য দায়ী৷
লেক্সার জানেন কিভাবে সাদা স্পেস এবং লাইন ব্রেক এর মত অপ্রাসঙ্গিক অক্ষর বাদ দিতে হয়।
পার্সিং প্রক্রিয়াটি পুনরাবৃত্তিমূলক। পার্সার সাধারণত লেক্সারকে একটি নতুন টোকেনের জন্য জিজ্ঞাসা করবে এবং সিনট্যাক্স নিয়মগুলির একটির সাথে টোকেনটি মেলানোর চেষ্টা করবে। যদি একটি নিয়ম মিলে যায়, টোকেনের সাথে সম্পর্কিত একটি নোড পার্স ট্রিতে যোগ করা হবে এবং পার্সার অন্য টোকেন চাইবে।
যদি কোনো নিয়ম মেলে না, পার্সার অভ্যন্তরীণভাবে টোকেন সংরক্ষণ করবে, এবং অভ্যন্তরীণভাবে সঞ্চিত টোকেনগুলির সাথে মেলে এমন একটি নিয়ম পাওয়া না যাওয়া পর্যন্ত টোকেনগুলির জন্য জিজ্ঞাসা করতে থাকবে৷ যদি কোন নিয়ম না পাওয়া যায় তাহলে পার্সার একটি ব্যতিক্রম উত্থাপন করবে। এর মানে ডকুমেন্টটি বৈধ ছিল না এবং এতে সিনট্যাক্স ত্রুটি ছিল।
অনুবাদ
অনেক ক্ষেত্রে পার্স গাছ চূড়ান্ত পণ্য নয়। পার্সিং প্রায়ই অনুবাদে ব্যবহৃত হয়: ইনপুট নথিকে অন্য বিন্যাসে রূপান্তর করা। একটি উদাহরণ হল সংকলন। কম্পাইলার যেটি মেশিন কোডে সোর্স কোড কম্পাইল করে তা প্রথমে পার্স ট্রিতে পার্স করে এবং তারপর ট্রিটিকে মেশিন কোড ডকুমেন্টে অনুবাদ করে।
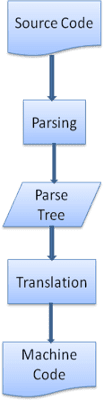
পার্সিং উদাহরণ
চিত্র 5 এ আমরা একটি গাণিতিক অভিব্যক্তি থেকে একটি পার্স গাছ তৈরি করেছি। আসুন একটি সহজ গাণিতিক ভাষা সংজ্ঞায়িত করার চেষ্টা করি এবং পার্স প্রক্রিয়াটি দেখি।
সিনট্যাক্স:
- ভাষার সিনট্যাক্স বিল্ডিং ব্লক হল এক্সপ্রেশন, টার্ম এবং অপারেশন।
- আমাদের ভাষা যেকোন সংখ্যক অভিব্যক্তি অন্তর্ভুক্ত করতে পারে।
- একটি অভিব্যক্তি একটি "টার্ম" হিসাবে সংজ্ঞায়িত করা হয় একটি "অপারেশন" দ্বারা অনুসরণ করে অন্য একটি শব্দ
- একটি অপারেশন একটি প্লাস টোকেন বা একটি বিয়োগ টোকেন
- একটি শব্দ একটি পূর্ণসংখ্যা টোকেন বা একটি অভিব্যক্তি
আসুন ইনপুট 2 + 3 - 1 বিশ্লেষণ করি।
একটি নিয়মের সাথে মেলে প্রথম সাবস্ট্রিং হল 2 : নিয়ম #5 অনুসারে এটি একটি শব্দ। দ্বিতীয় মিলটি হল 2 + 3 : এটি তৃতীয় নিয়মের সাথে মেলে: একটি শব্দের পরে একটি অপারেশন এবং অন্য একটি পদ অনুসরণ করে৷ পরবর্তী ম্যাচ শুধুমাত্র ইনপুট শেষে আঘাত করা হবে. 2 + 3 - 1 একটি অভিব্যক্তি কারণ আমরা ইতিমধ্যেই জানি যে 2 + 3 একটি পদ, তাই আমাদের কাছে একটি শব্দ আছে একটি অপারেশন দ্বারা অনুসরণ করে অন্য একটি পদ। 2 + + কোনো নিয়মের সাথে মেলে না এবং তাই এটি একটি অবৈধ ইনপুট।
শব্দভান্ডার এবং বাক্য গঠনের জন্য আনুষ্ঠানিক সংজ্ঞা
শব্দভান্ডার সাধারণত নিয়মিত অভিব্যক্তি দ্বারা প্রকাশ করা হয়।
উদাহরণস্বরূপ আমাদের ভাষা সংজ্ঞায়িত করা হবে:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
আপনি দেখতে পাচ্ছেন, পূর্ণসংখ্যা একটি নিয়মিত অভিব্যক্তি দ্বারা সংজ্ঞায়িত করা হয়।
সিনট্যাক্স সাধারণত BNF নামে একটি বিন্যাসে সংজ্ঞায়িত করা হয়। আমাদের ভাষা এইভাবে সংজ্ঞায়িত করা হবে:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
আমরা বলেছিলাম যে একটি ভাষা নিয়মিত পার্সার দ্বারা পার্স করা যেতে পারে যদি এর ব্যাকরণ একটি প্রসঙ্গ মুক্ত ব্যাকরণ হয়। একটি প্রসঙ্গ মুক্ত ব্যাকরণের একটি স্বজ্ঞাত সংজ্ঞা হল একটি ব্যাকরণ যা সম্পূর্ণরূপে বিএনএফ-এ প্রকাশ করা যেতে পারে। একটি আনুষ্ঠানিক সংজ্ঞার জন্য উইকিপিডিয়ার প্রসঙ্গ-মুক্ত ব্যাকরণের নিবন্ধটি দেখুন
পার্সারের প্রকারভেদ
দুই ধরনের পার্সার আছে: টপ ডাউন পার্সার এবং বটম আপ পার্সার। একটি স্বজ্ঞাত ব্যাখ্যা হল যে টপ ডাউন পার্সাররা সিনট্যাক্সের উচ্চ স্তরের কাঠামো পরীক্ষা করে এবং একটি নিয়মের মিল খুঁজে বের করার চেষ্টা করে। বটম আপ পার্সার ইনপুট দিয়ে শুরু করে এবং ধীরে ধীরে এটিকে সিনট্যাক্স নিয়মে রূপান্তরিত করে, নিম্ন স্তরের নিয়ম থেকে শুরু করে উচ্চ স্তরের নিয়মগুলি পূরণ না হওয়া পর্যন্ত।
আসুন দেখি কিভাবে দুই ধরনের পার্সার আমাদের উদাহরণটি পার্স করবে।
টপ ডাউন পার্সার উচ্চ স্তরের নিয়ম থেকে শুরু হবে: এটি 2 + 3 একটি অভিব্যক্তি হিসাবে চিহ্নিত করবে। এটি তখন 2 + 3 - 1 একটি অভিব্যক্তি হিসাবে চিহ্নিত করবে (অভিব্যক্তি সনাক্ত করার প্রক্রিয়াটি বিকশিত হয়, অন্যান্য নিয়মের সাথে মিলে যায়, তবে শুরুর বিন্দুটি সর্বোচ্চ স্তরের নিয়ম)।
একটি নিয়ম মেলে না হওয়া পর্যন্ত নীচের উপরের পার্সার ইনপুটটি স্ক্যান করবে। এটি তারপর নিয়মের সাথে মিলিত ইনপুট প্রতিস্থাপন করবে। ইনপুট শেষ না হওয়া পর্যন্ত এটি চলতে থাকবে। আংশিকভাবে মিলে যাওয়া অভিব্যক্তিটি পার্সারের স্ট্যাকের উপর স্থাপন করা হয়।
এই ধরনের বটম আপ পার্সারকে শিফট-রিডুস পার্সার বলা হয়, কারণ ইনপুটটি ডানদিকে স্থানান্তরিত হয় (কল্পনা করুন একটি পয়েন্টার ইনপুট শুরুতে প্রথমে নির্দেশ করে এবং ডানদিকে চলে যায়) এবং ধীরে ধীরে সিনট্যাক্স নিয়মে হ্রাস করা হয়।
স্বয়ংক্রিয়ভাবে পার্সার তৈরি করা হচ্ছে
এমন সরঞ্জাম রয়েছে যা একটি পার্সার তৈরি করতে পারে। আপনি তাদের আপনার ভাষার ব্যাকরণ - এর শব্দভান্ডার এবং বাক্য গঠনের নিয়মগুলি খাওয়ান - এবং তারা একটি কার্যকরী পার্সার তৈরি করে৷ একটি পার্সার তৈরি করার জন্য পার্সিংয়ের গভীর বোঝার প্রয়োজন এবং এটি হাতে একটি অপ্টিমাইজ করা পার্সার তৈরি করা সহজ নয়, তাই পার্সার জেনারেটরগুলি খুব দরকারী হতে পারে।
ওয়েবকিট দুটি সুপরিচিত পার্সার জেনারেটর ব্যবহার করে: একটি লেক্সার তৈরির জন্য ফ্লেক্স এবং একটি পার্সার তৈরি করার জন্য বাইসন (আপনি লেক্স এবং ইয়াক নাম দিয়ে তাদের মধ্যে দৌড়াতে পারেন)। ফ্লেক্স ইনপুট হল একটি ফাইল যাতে টোকেনের রেগুলার এক্সপ্রেশন সংজ্ঞা থাকে। বাইসন এর ইনপুট হল BNF বিন্যাসে ভাষার সিনট্যাক্স নিয়ম।
এইচটিএমএল পার্সার
HTML পার্সারের কাজ হল HTML মার্কআপকে পার্স ট্রিতে পার্স করা।
এইচটিএমএল ব্যাকরণ
HTML এর শব্দভান্ডার এবং সিনট্যাক্স W3C সংস্থা দ্বারা তৈরি স্পেসিফিকেশনে সংজ্ঞায়িত করা হয়েছে।
আমরা পার্সিং ভূমিকাতে দেখেছি, BNF এর মত বিন্যাস ব্যবহার করে ব্যাকরণ বাক্য গঠনকে আনুষ্ঠানিকভাবে সংজ্ঞায়িত করা যেতে পারে।
দুর্ভাগ্যবশত সমস্ত প্রচলিত পার্সার বিষয় এইচটিএমএল-এ প্রযোজ্য নয় (আমি এগুলিকে শুধুমাত্র মজা করার জন্য আনিনি - সেগুলি CSS এবং JavaScript পার্সিংয়ে ব্যবহার করা হবে)। এইচটিএমএল সহজে একটি প্রসঙ্গ মুক্ত ব্যাকরণ দ্বারা সংজ্ঞায়িত করা যায় না যা পার্সারদের প্রয়োজন।
এইচটিএমএল - ডিটিডি (ডকুমেন্ট টাইপ ডেফিনিশন) সংজ্ঞায়িত করার জন্য একটি আনুষ্ঠানিক বিন্যাস রয়েছে - তবে এটি একটি প্রসঙ্গ মুক্ত ব্যাকরণ নয়।
এটি প্রথম দর্শনে অদ্ভুত বলে মনে হয়; এইচটিএমএল বরং XML এর কাছাকাছি। প্রচুর এক্সএমএল পার্সার আছে। এইচটিএমএল - এক্সএইচটিএমএল - এর একটি এক্সএমএল প্রকরণ রয়েছে - তাই বড় পার্থক্য কী?
পার্থক্য হল যে এইচটিএমএল পদ্ধতিটি আরও "ক্ষমাকারী": এটি আপনাকে নির্দিষ্ট ট্যাগগুলি বাদ দিতে দেয় (যা পরে নিহিতভাবে যোগ করা হয়), বা কখনও কখনও শুরু বা শেষ ট্যাগগুলি বাদ দিতে দেয় এবং আরও অনেক কিছু। মোটের উপর এটি একটি "নরম" সিনট্যাক্স, XML এর কঠোর এবং দাবিকৃত সিনট্যাক্সের বিপরীতে।
এই আপাতদৃষ্টিতে ছোট বিশদটি একটি পার্থক্যের বিশ্ব তৈরি করে। একদিকে এটি HTML এত জনপ্রিয় হওয়ার মূল কারণ: এটি আপনার ভুলগুলি ক্ষমা করে এবং ওয়েব লেখকের জীবনকে সহজ করে তোলে৷ অন্যদিকে, এটি একটি আনুষ্ঠানিক ব্যাকরণ লিখতে কঠিন করে তোলে। তাই সংক্ষেপে বলতে গেলে, প্রচলিত পার্সারের দ্বারা HTML সহজে পার্স করা যায় না, যেহেতু এর ব্যাকরণ প্রসঙ্গ মুক্ত নয়। XML পার্সারের দ্বারা HTML পার্স করা যাবে না।
এইচটিএমএল ডিটিডি
এইচটিএমএল সংজ্ঞা একটি DTD বিন্যাসে হয়. এই বিন্যাসটি SGML পরিবারের ভাষা সংজ্ঞায়িত করতে ব্যবহৃত হয়। বিন্যাসে সমস্ত অনুমোদিত উপাদান, তাদের বৈশিষ্ট্য এবং অনুক্রমের সংজ্ঞা রয়েছে। আমরা আগে দেখেছি, HTML DTD একটি প্রসঙ্গ মুক্ত ব্যাকরণ গঠন করে না।
DTD এর কয়েকটি বৈচিত্র রয়েছে। কঠোর মোড শুধুমাত্র নির্দিষ্টকরণের সাথে সামঞ্জস্যপূর্ণ কিন্তু অন্যান্য মোডগুলি অতীতে ব্রাউজারদের দ্বারা ব্যবহৃত মার্কআপের জন্য সমর্থন ধারণ করে। উদ্দেশ্য পুরানো বিষয়বস্তুর সাথে পিছনের সামঞ্জস্য। বর্তমান কঠোর DTD এখানে: www.w3.org/TR/html4/strict.dtd
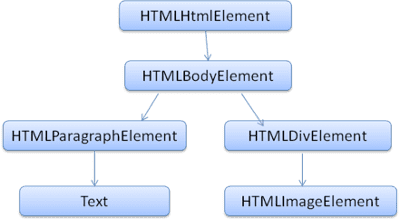
DOM
আউটপুট ট্রি ("পার্স ট্রি") হল DOM এলিমেন্ট এবং অ্যাট্রিবিউট নোডের একটি ট্রি। ডকুমেন্ট অবজেক্ট মডেলের জন্য DOM সংক্ষিপ্ত। এটি হল এইচটিএমএল ডকুমেন্টের অবজেক্ট প্রেজেন্টেশন এবং জাভাস্ক্রিপ্টের মত বাইরের জগতে এইচটিএমএল উপাদানগুলির ইন্টারফেস।
গাছের মূল হল " ডকুমেন্ট " অবজেক্ট।
মার্কআপের সাথে DOM-এর প্রায় এক-এক সম্পর্ক রয়েছে। যেমন:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
এই মার্কআপটি নিম্নলিখিত DOM ট্রিতে অনুবাদ করা হবে:
HTML এর মত, DOM W3C সংস্থা দ্বারা নির্দিষ্ট করা হয়। www.w3.org/DOM/DOMTR দেখুন। এটি নথিগুলি হেরফের করার জন্য একটি জেনেরিক স্পেসিফিকেশন। একটি নির্দিষ্ট মডিউল HTML নির্দিষ্ট উপাদান বর্ণনা করে। HTML সংজ্ঞা এখানে পাওয়া যাবে: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html ।
যখন আমি বলি গাছটিতে DOM নোড রয়েছে, আমি বলতে চাচ্ছি যে গাছটি এমন উপাদান দিয়ে তৈরি করা হয়েছে যা DOM ইন্টারফেসগুলির একটিকে বাস্তবায়ন করে। ব্রাউজারগুলি অভ্যন্তরীণভাবে ব্রাউজার দ্বারা ব্যবহৃত অন্যান্য বৈশিষ্ট্য রয়েছে এমন কংক্রিট বাস্তবায়ন ব্যবহার করে।
পার্সিং অ্যালগরিদম
আমরা পূর্ববর্তী বিভাগে দেখেছি, নিয়মিত টপ ডাউন বা বটম আপ পার্সার ব্যবহার করে HTML পার্স করা যায় না।
কারণগুলি হল:
- ভাষার ক্ষমাশীল প্রকৃতি।
- অবৈধ HTML এর সুপরিচিত ক্ষেত্রে সমর্থন করার জন্য ব্রাউজারগুলির ঐতিহ্যগত ত্রুটি সহনশীলতা রয়েছে।
- পার্সিং প্রক্রিয়াটি পুনঃপ্রবেশকারী। অন্যান্য ভাষার জন্য, পার্সিংয়ের সময় উৎস পরিবর্তন হয় না, কিন্তু HTML-এ, ডাইনামিক কোড (যেমন
document.write()কল সম্বলিত স্ক্রিপ্ট উপাদান) অতিরিক্ত টোকেন যোগ করতে পারে, তাই পার্সিং প্রক্রিয়া আসলে ইনপুট পরিবর্তন করে।
নিয়মিত পার্সিং কৌশল ব্যবহার করতে অক্ষম, ব্রাউজার HTML পার্স করার জন্য কাস্টম পার্সার তৈরি করে।
পার্সিং অ্যালগরিদম HTML5 স্পেসিফিকেশন দ্বারা বিশদভাবে বর্ণনা করা হয়েছে । অ্যালগরিদম দুটি পর্যায় নিয়ে গঠিত: টোকেনাইজেশন এবং গাছ নির্মাণ।
টোকেনাইজেশন হল আভিধানিক বিশ্লেষণ, ইনপুটকে টোকেনে পার্স করা। এইচটিএমএল টোকেনের মধ্যে রয়েছে স্টার্ট ট্যাগ, এন্ড ট্যাগ, অ্যাট্রিবিউটের নাম এবং অ্যাট্রিবিউটের মান।
টোকেনাইজার টোকেনটি চিনতে পারে, এটি ট্রি কনস্ট্রাক্টরকে দেয় এবং পরবর্তী টোকেনটি সনাক্ত করার জন্য পরবর্তী অক্ষরটি গ্রহণ করে এবং ইনপুট শেষ না হওয়া পর্যন্ত।
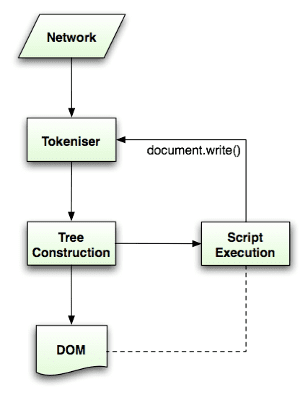
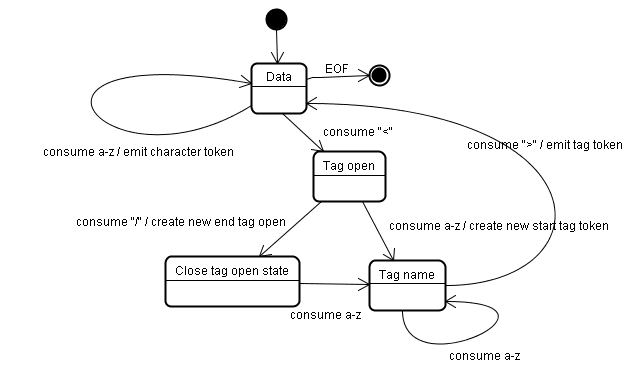
টোকেনাইজেশন অ্যালগরিদম
অ্যালগরিদমের আউটপুট একটি HTML টোকেন। অ্যালগরিদম একটি রাষ্ট্র মেশিন হিসাবে প্রকাশ করা হয়. প্রতিটি স্টেট ইনপুট স্ট্রীমের এক বা একাধিক অক্ষর গ্রহণ করে এবং সেই অক্ষর অনুযায়ী পরবর্তী অবস্থা আপডেট করে। সিদ্ধান্তটি বর্তমান টোকেনাইজেশন অবস্থা এবং গাছ নির্মাণের অবস্থা দ্বারা প্রভাবিত হয়। এর মানে বর্তমান অবস্থার উপর নির্ভর করে সঠিক পরবর্তী অবস্থার জন্য একই ব্যবহার করা অক্ষর বিভিন্ন ফলাফল দেবে। অ্যালগরিদম সম্পূর্ণরূপে বর্ণনা করার জন্য খুবই জটিল, তাই আসুন একটি সাধারণ উদাহরণ দেখি যা আমাদের নীতিটি বুঝতে সাহায্য করবে।
মৌলিক উদাহরণ - নিম্নলিখিত HTML টোকেনাইজ করা:
<html>
<body>
Hello world
</body>
</html>
প্রাথমিক অবস্থা হল "ডেটা স্টেট"। যখন < অক্ষরটির সম্মুখীন হয়, তখন অবস্থাটি "ট্যাগ ওপেন স্টেট" এ পরিবর্তিত হয়। একটি az অক্ষর ব্যবহার করার ফলে একটি "স্টার্ট ট্যাগ টোকেন" তৈরি হয়, অবস্থাটি "ট্যাগ নেম স্টেট" এ পরিবর্তিত হয়। > অক্ষরটি গ্রাস না হওয়া পর্যন্ত আমরা এই অবস্থায় থাকি। প্রতিটি অক্ষর নতুন টোকেন নামের সাথে যুক্ত করা হয়। আমাদের ক্ষেত্রে তৈরি টোকেন একটি html টোকেন।
যখন > ট্যাগ পৌঁছে যায়, তখন বর্তমান টোকেন নির্গত হয় এবং অবস্থা আবার "ডেটা স্টেট" -এ পরিবর্তিত হয়। <body> ট্যাগটিকে একই ধাপে বিবেচনা করা হবে। এ পর্যন্ত html এবং body ট্যাগ নির্গত হয়েছে। আমরা এখন "ডেটা স্টেট" এ ফিরে এসেছি। Hello world H অক্ষর ব্যবহার করলে একটি অক্ষর টোকেন তৈরি এবং নির্গত হবে, এটি < এর </body> না হওয়া পর্যন্ত চলবে। আমরা Hello world প্রতিটি চরিত্রের জন্য একটি অক্ষর টোকেন নির্গত করব।
আমরা এখন "ট্যাগ ওপেন স্টেট" এ ফিরে এসেছি। পরবর্তী ইনপুট গ্রহণ করা / একটি end tag token তৈরি করবে এবং "ট্যাগ নাম রাজ্য" এ চলে যাবে। আবার আমরা এই অবস্থায় থাকি যতক্ষণ না আমরা > পৌঁছাই। তারপর নতুন ট্যাগ টোকেন নির্গত হবে এবং আমরা "ডেটা স্টেটে" ফিরে যাই। </html> ইনপুটটিকে আগের কেসের মতোই বিবেচনা করা হবে।
গাছ নির্মাণ অ্যালগরিদম
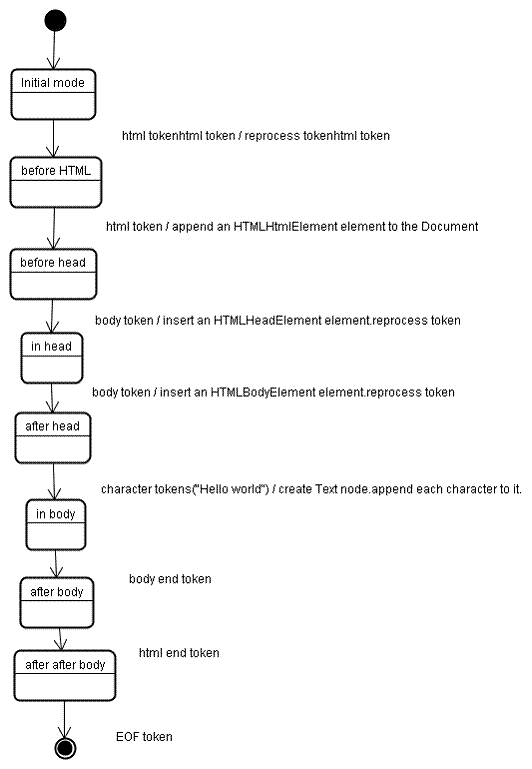
যখন পার্সার তৈরি করা হয় তখন ডকুমেন্ট অবজেক্ট তৈরি হয়। গাছ নির্মাণের পর্যায়ে ডকুমেন্টের মূলে থাকা DOM গাছটিকে পরিবর্তন করা হবে এবং এতে উপাদান যোগ করা হবে। টোকেনাইজার দ্বারা নির্গত প্রতিটি নোড ট্রি কনস্ট্রাক্টর দ্বারা প্রক্রিয়া করা হবে। প্রতিটি টোকেনের জন্য স্পেসিফিকেশন নির্ধারণ করে যে কোন DOM উপাদান এটির সাথে প্রাসঙ্গিক এবং এই টোকেনের জন্য তৈরি করা হবে। উপাদানটি DOM ট্রিতে যোগ করা হয়, এবং খোলা উপাদানগুলির স্ট্যাকও। এই স্ট্যাকটি নেস্টিং অমিল এবং আনক্লোজড ট্যাগগুলি সংশোধন করতে ব্যবহৃত হয়। অ্যালগরিদম একটি রাষ্ট্র মেশিন হিসাবে বর্ণনা করা হয়. রাজ্যগুলিকে "সন্নিবেশ মোড" বলা হয়।
উদাহরণ ইনপুট জন্য গাছ নির্মাণ প্রক্রিয়া দেখুন:
<html>
<body>
Hello world
</body>
</html>
গাছ নির্মাণ পর্যায়ে ইনপুট হল টোকেনাইজেশন পর্যায় থেকে টোকেনের একটি ক্রম। প্রথম মোড হল "প্রাথমিক মোড" । "html" টোকেন প্রাপ্তির ফলে "html" মোডে সরানো হবে এবং সেই মোডে টোকেন পুনঃপ্রসেস করা হবে। এর ফলে HTMLHtmlElement এলিমেন্ট তৈরি হবে, যা রুট ডকুমেন্ট অবজেক্টে যুক্ত হবে।
রাষ্ট্র পরিবর্তন করা হবে "মাথার আগে" । তারপর "শরীর" টোকেন প্রাপ্ত হয়। একটি HTMLHeadElement অন্তর্নিহিতভাবে তৈরি করা হবে যদিও আমাদের কাছে "হেড" টোকেন নেই এবং এটি গাছে যোগ করা হবে।
আমরা এখন "ইন হেড" মোডে এবং তারপরে "আফটার হেড" এ চলে যাই। বডি টোকেন পুনঃপ্রসেস করা হয়, একটি HTMLBodyElement তৈরি করা হয় এবং সন্নিবেশ করা হয় এবং মোডটি "ইন বডি" এ স্থানান্তরিত হয়।
"হ্যালো ওয়ার্ল্ড" স্ট্রিংয়ের অক্ষর টোকেনগুলি এখন প্রাপ্ত হয়েছে৷ প্রথমটি একটি "টেক্সট" নোড তৈরি এবং সন্নিবেশ ঘটাবে এবং অন্যান্য অক্ষরগুলি সেই নোডে যুক্ত করা হবে।
বডি এন্ড টোকেন প্রাপ্তির ফলে "আফটার বডি" মোডে স্থানান্তরিত হবে। আমরা এখন html শেষ ট্যাগ পাব যা আমাদেরকে "আফটার আফটার বডি" মোডে নিয়ে যাবে। ফাইল টোকেনের শেষ প্রাপ্তি পার্সিং শেষ হবে।
পার্সিং শেষ হলে অ্যাকশন
এই পর্যায়ে ব্রাউজার নথিটিকে ইন্টারেক্টিভ হিসাবে চিহ্নিত করবে এবং "বিলম্বিত" মোডে থাকা স্ক্রিপ্টগুলিকে পার্সিং শুরু করবে: যেগুলি নথিটি পার্স করার পরে কার্যকর করা উচিত৷ নথির অবস্থা তারপর "সম্পূর্ণ" সেট করা হবে এবং একটি "লোড" ইভেন্ট ফায়ার করা হবে।
আপনি HTML5 স্পেসিফিকেশনে টোকেনাইজেশন এবং ট্রি নির্মাণের জন্য সম্পূর্ণ অ্যালগরিদম দেখতে পারেন।
ব্রাউজারের ত্রুটি সহনশীলতা
আপনি কখনই একটি HTML পৃষ্ঠায় একটি "অবৈধ সিনট্যাক্স" ত্রুটি পাবেন না৷ ব্রাউজার কোন অবৈধ বিষয়বস্তু ঠিক করে এবং চালিয়ে যান।
উদাহরণস্বরূপ এই HTML নিন:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
আমি অবশ্যই প্রায় এক মিলিয়ন নিয়ম লঙ্ঘন করেছি ("mytag" একটি আদর্শ ট্যাগ নয়, "p" এবং "div" উপাদানগুলির ভুল নেস্টিং এবং আরও অনেক কিছু) কিন্তু ব্রাউজার এখনও এটি সঠিকভাবে দেখায় এবং অভিযোগ করে না৷ তাই পার্সার কোড অনেক HTML লেখক ভুল সংশোধন করা হয়.
ত্রুটি হ্যান্ডলিং ব্রাউজারে বেশ সামঞ্জস্যপূর্ণ, কিন্তু আশ্চর্যজনকভাবে এটি HTML স্পেসিফিকেশনের অংশ নয়। বুকমার্কিং এবং ব্যাক/ফরোয়ার্ড বোতামের মতো এটি এমন কিছু যা ব্রাউজারে বছরের পর বছর ধরে উন্নত হয়েছে। অনেক সাইটে বারবার অকার্যকর এইচটিএমএল কনস্ট্রাক্ট রয়েছে এবং ব্রাউজারগুলি অন্য ব্রাউজারগুলির সাথে সামঞ্জস্যপূর্ণ উপায়ে সেগুলি ঠিক করার চেষ্টা করে৷
HTML5 স্পেসিফিকেশন এই প্রয়োজনীয়তাগুলির কিছু সংজ্ঞায়িত করে। (ওয়েবকিট এইচটিএমএল পার্সার ক্লাসের শুরুতে মন্তব্যে এটিকে সুন্দরভাবে সংক্ষিপ্ত করে।)
পার্সার নথিতে টোকেনাইজড ইনপুট পার্স করে, ডকুমেন্ট ট্রি তৈরি করে। যদি নথিটি সুগঠিত হয় তবে এটিকে পার্স করা সহজ।
দুর্ভাগ্যবশত, আমাদের অনেক এইচটিএমএল ডকুমেন্ট পরিচালনা করতে হবে যা সুগঠিত নয়, তাই পার্সারকে ত্রুটির বিষয়ে সহনশীল হতে হবে।
আমাদের কমপক্ষে নিম্নলিখিত ত্রুটি শর্তগুলির যত্ন নিতে হবে:
- যে উপাদানটি যোগ করা হচ্ছে তা কিছু বাইরের ট্যাগের ভিতরে স্পষ্টভাবে নিষিদ্ধ। এই ক্ষেত্রে আমাদের সমস্ত ট্যাগ বন্ধ করা উচিত যা উপাদানটিকে নিষিদ্ধ করে এবং পরে এটি যোগ করে।
- আমরা সরাসরি উপাদান যোগ করার অনুমতি দেওয়া হয় না. এটা হতে পারে যে নথিটি লেখা ব্যক্তি তার মধ্যে কিছু ট্যাগ ভুলে গেছেন (বা এর মধ্যে ট্যাগটি ঐচ্ছিক)। নিম্নলিখিত ট্যাগগুলির ক্ষেত্রে এটি হতে পারে: HTML HEAD BODY TBODY TR TD LI (আমি কি ভুলে গেছি?)।
- আমরা একটি ইনলাইন উপাদানের ভিতরে একটি ব্লক উপাদান যোগ করতে চাই। পরবর্তী উচ্চতর ব্লক উপাদান পর্যন্ত সমস্ত ইনলাইন উপাদান বন্ধ করুন।
- যদি এটি সাহায্য না করে, আমাদের উপাদান যোগ করার অনুমতি না দেওয়া পর্যন্ত উপাদান বন্ধ করুন - বা ট্যাগ উপেক্ষা করুন।
আসুন কিছু WebKit ত্রুটি সহনশীলতার উদাহরণ দেখি:
</br> এর পরিবর্তে <br>
কিছু সাইট <br> এর পরিবর্তে </br> ব্যবহার করে। IE এবং Firefox-এর সাথে সামঞ্জস্যপূর্ণ হওয়ার জন্য, WebKit এটিকে <br> মত ব্যবহার করে।
কোড:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
মনে রাখবেন যে ত্রুটি হ্যান্ডলিং অভ্যন্তরীণ: এটি ব্যবহারকারীর কাছে উপস্থাপন করা হবে না।
একটি বিপথগামী টেবিল
একটি স্ট্রে টেবিল অন্য টেবিলের ভিতরে একটি টেবিল, কিন্তু একটি টেবিল ঘরের ভিতরে নয়।
যেমন:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit অনুক্রম দুটি ভাইবোন টেবিলে পরিবর্তন করবে:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
কোড:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
ওয়েবকিট বর্তমান উপাদান বিষয়বস্তুর জন্য একটি স্ট্যাক ব্যবহার করে: এটি বাইরের টেবিল স্ট্যাকের বাইরের টেবিলটি পপ করবে। টেবিল এখন ভাইবোন হবে.
নেস্টেড ফর্ম উপাদান
যদি ব্যবহারকারী অন্য ফর্মের ভিতরে একটি ফর্ম রাখে, দ্বিতীয় ফর্মটি উপেক্ষা করা হয়।
কোড:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
একটি খুব গভীর ট্যাগ অনুক্রম
মন্তব্য নিজেই জন্য কথা বলে.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
ভুল এইচটিএমএল বা বডি এন্ড ট্যাগ
আবার - মন্তব্য নিজের জন্য কথা বলে।
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
তাই ওয়েব লেখকরা সতর্ক থাকুন - যদি না আপনি একটি ওয়েবকিট ত্রুটি সহনশীলতা কোড স্নিপেটে একটি উদাহরণ হিসাবে উপস্থিত হতে চান - ভালভাবে গঠিত HTML লিখুন৷
CSS পার্সিং
ভূমিকায় পার্সিং ধারণাগুলি মনে রাখবেন? ঠিক আছে, HTML এর বিপরীতে, CSS হল একটি প্রসঙ্গ মুক্ত ব্যাকরণ এবং ভূমিকায় বর্ণিত পার্সারের প্রকারগুলি ব্যবহার করে পার্স করা যেতে পারে। আসলে CSS স্পেসিফিকেশন CSS আভিধানিক এবং সিনট্যাক্স ব্যাকরণকে সংজ্ঞায়িত করে ।
আসুন কিছু উদাহরণ দেখি:
আভিধানিক ব্যাকরণ (শব্দভান্ডার) প্রতিটি টোকেনের জন্য নিয়মিত অভিব্যক্তি দ্বারা সংজ্ঞায়িত করা হয়:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" শনাক্তকারীর জন্য সংক্ষিপ্ত, যেমন একটি শ্রেণীর নাম। "নাম" হল একটি উপাদান আইডি (যেটি "#" দ্বারা উল্লেখ করা হয়)
সিনট্যাক্স ব্যাকরণ বিএনএফ-এ বর্ণিত হয়েছে।
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
ব্যাখ্যা:
একটি নিয়ম সেট এই কাঠামো:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error এবং a.error হল নির্বাচক। কোঁকড়া ধনুর্বন্ধনীর ভিতরের অংশে এই নিয়ম সেট দ্বারা প্রয়োগ করা নিয়ম রয়েছে। এই কাঠামোটি এই সংজ্ঞায় আনুষ্ঠানিকভাবে সংজ্ঞায়িত করা হয়েছে:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
এর মানে হল একটি রুলসেট হল একটি নির্বাচক বা ঐচ্ছিকভাবে একটি কমা এবং স্পেস (S মানে হোয়াইট স্পেস) দ্বারা বিভক্ত একাধিক নির্বাচক। একটি রুলসেটে কোঁকড়া ধনুর্বন্ধনী থাকে এবং তাদের ভিতরে একটি ঘোষণা বা ঐচ্ছিকভাবে একটি সেমিকোলন দ্বারা পৃথক করা অনেকগুলি ঘোষণা থাকে। "ঘোষণা" এবং "নির্বাচক" নিম্নলিখিত BNF সংজ্ঞাগুলিতে সংজ্ঞায়িত করা হবে।
ওয়েবকিট সিএসএস পার্সার
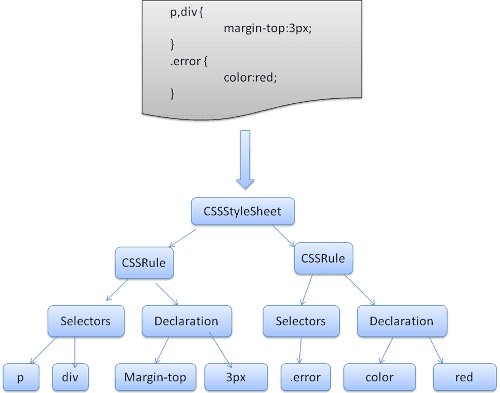
ওয়েবকিট CSS ব্যাকরণ ফাইল থেকে স্বয়ংক্রিয়ভাবে পার্সার তৈরি করতে ফ্লেক্স এবং বাইসন পার্সার জেনারেটর ব্যবহার করে। যেমন আপনি পার্সার ভূমিকা থেকে স্মরণ করছেন, বাইসন একটি বটম আপ শিফট-রিডুস পার্সার তৈরি করে। ফায়ারফক্স ম্যানুয়ালি লেখা একটি টপ ডাউন পার্সার ব্যবহার করে। উভয় ক্ষেত্রেই প্রতিটি CSS ফাইল একটি স্টাইলশিট অবজেক্টে পার্স করা হয়। প্রতিটি বস্তুতে CSS নিয়ম রয়েছে। সিএসএস নিয়ম অবজেক্টে সিলেক্টর এবং ডিক্লেয়ারেশন অবজেক্ট এবং সিএসএস ব্যাকরণের সাথে সম্পর্কিত অন্যান্য অবজেক্ট থাকে।
স্ক্রিপ্ট এবং শৈলী শীট জন্য আদেশ প্রক্রিয়াকরণ
স্ক্রিপ্ট
ওয়েবের মডেলটি সিঙ্ক্রোনাস। লেখকরা আশা করেন স্ক্রিপ্টগুলি পার্স করা হবে এবং অবিলম্বে পার্সার একটি <script> ট্যাগে পৌঁছাবে। স্ক্রিপ্টটি কার্যকর না হওয়া পর্যন্ত নথির পার্সিং বন্ধ হয়ে যায়। যদি স্ক্রিপ্টটি বাহ্যিক হয় তবে সংস্থানটি প্রথমে নেটওয়ার্ক থেকে আনতে হবে - এটিও সিঙ্ক্রোনাসভাবে করা হয়, এবং সম্পদ আনা না হওয়া পর্যন্ত পার্সিং বন্ধ থাকে। এটি বহু বছর ধরে মডেল ছিল এবং এটি HTML4 এবং 5 স্পেসিফিকেশনেও উল্লেখ করা হয়েছে। লেখকরা একটি স্ক্রিপ্টে "defer" অ্যাট্রিবিউট যোগ করতে পারেন, এই ক্ষেত্রে এটি ডকুমেন্ট পার্সিং বন্ধ করবে না এবং ডকুমেন্ট পার্স করার পরে এক্সিকিউট করবে। HTML5 স্ক্রিপ্টটিকে অ্যাসিঙ্ক্রোনাস হিসাবে চিহ্নিত করার জন্য একটি বিকল্প যোগ করে যাতে এটি একটি ভিন্ন থ্রেড দ্বারা পার্স এবং কার্যকর করা হবে।
অনুমানমূলক পার্সিং
ওয়েবকিট এবং ফায়ারফক্স উভয়ই এই অপ্টিমাইজেশনটি করে। স্ক্রিপ্টগুলি চালানোর সময়, অন্য একটি থ্রেড নথির বাকি অংশগুলিকে পার্স করে এবং নেটওয়ার্ক থেকে অন্য কোন সংস্থানগুলি লোড করতে হবে তা খুঁজে বের করে এবং সেগুলি লোড করে৷ এইভাবে, সমান্তরাল সংযোগগুলিতে সংস্থানগুলি লোড করা যেতে পারে এবং সামগ্রিক গতি উন্নত হয়। দ্রষ্টব্য: অনুমানমূলক পার্সার শুধুমাত্র বাহ্যিক স্ক্রিপ্ট, স্টাইল শীট এবং চিত্রগুলির মতো বাহ্যিক সংস্থানগুলির রেফারেন্সগুলিকে পার্স করে: এটি DOM ট্রিকে পরিবর্তন করে না - যা মূল পার্সারে ছেড়ে দেওয়া হয়।
শৈলী শীট
অন্যদিকে শৈলী শীট একটি ভিন্ন মডেল আছে. ধারণাগতভাবে মনে হচ্ছে যেহেতু স্টাইল শীটগুলি DOM ট্রি পরিবর্তন করে না, তাদের জন্য অপেক্ষা করার এবং নথি পার্সিং বন্ধ করার কোন কারণ নেই। ডকুমেন্ট পার্সিং পর্যায়ে স্ক্রিপ্টের শৈলী তথ্যের জন্য জিজ্ঞাসা করার একটি সমস্যা আছে। যদি স্টাইলটি এখনও লোড এবং পার্স করা না হয় তবে স্ক্রিপ্টটি ভুল উত্তর পাবে এবং দৃশ্যত এটি অনেক সমস্যার সৃষ্টি করেছে। এটি একটি প্রান্ত কেস বলে মনে হচ্ছে কিন্তু বেশ সাধারণ। ফায়ারফক্স সমস্ত স্ক্রিপ্ট ব্লক করে যখন একটি স্টাইল শীট থাকে যা এখনও লোড এবং পার্স করা হচ্ছে। WebKit শুধুমাত্র স্ক্রিপ্টগুলিকে ব্লক করে যখন তারা নির্দিষ্ট শৈলী বৈশিষ্ট্যগুলি অ্যাক্সেস করার চেষ্টা করে যা আনলোড করা স্টাইল শীট দ্বারা প্রভাবিত হতে পারে।
গাছ নির্মাণ রেন্ডার
যখন DOM ট্রি নির্মাণ করা হচ্ছে, ব্রাউজারটি আরেকটি ট্রি তৈরি করে, রেন্ডার ট্রি। এই গাছটি চাক্ষুষ উপাদানের যে ক্রমে তারা প্রদর্শিত হবে। এটি নথির চাক্ষুষ উপস্থাপনা। এই গাছের উদ্দেশ্য হল বিষয়বস্তুকে তাদের সঠিক ক্রমে পেইন্টিং সক্ষম করা।
ফায়ারফক্স রেন্ডার ট্রির উপাদানগুলিকে "ফ্রেম" বলে। ওয়েবকিট রেন্ডারার বা রেন্ডার অবজেক্ট শব্দটি ব্যবহার করে।
একজন উপস্থাপক জানেন কিভাবে নিজেকে এবং তার সন্তানদের সাজাতে এবং আঁকতে হয়।
ওয়েবকিটের রেন্ডারঅবজেক্ট ক্লাস, রেন্ডারারদের বেস ক্লাস, এর নিম্নলিখিত সংজ্ঞা রয়েছে:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
প্রতিটি রেন্ডারার একটি আয়তক্ষেত্রাকার অঞ্চলকে প্রতিনিধিত্ব করে যা সাধারণত একটি নোডের CSS বক্সের সাথে সম্পর্কিত, যেমন CSS2 স্পেক দ্বারা বর্ণনা করা হয়েছে। এটি প্রস্থ, উচ্চতা এবং অবস্থানের মতো জ্যামিতিক তথ্য অন্তর্ভুক্ত করে।
বক্স টাইপ স্টাইল অ্যাট্রিবিউটের "ডিসপ্লে" মান দ্বারা প্রভাবিত হয় যা নোডের সাথে প্রাসঙ্গিক ( স্টাইল গণনা বিভাগটি দেখুন)। ডিসপ্লে অ্যাট্রিবিউট অনুসারে একটি DOM নোডের জন্য কি ধরনের রেন্ডারার তৈরি করা উচিত তা নির্ধারণের জন্য এখানে WebKit কোড রয়েছে:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
উপাদানের ধরনটিও বিবেচনা করা হয়: উদাহরণস্বরূপ, ফর্ম নিয়ন্ত্রণ এবং টেবিলের বিশেষ ফ্রেম রয়েছে।
ওয়েবকিটে যদি একটি উপাদান একটি বিশেষ রেন্ডারার তৈরি করতে চায়, তবে এটি createRenderer() পদ্ধতিকে ওভাররাইড করবে। রেন্ডারাররা এমন স্টাইল অবজেক্টের দিকে নির্দেশ করে যেখানে অ জ্যামিতিক তথ্য নেই।
DOM গাছের সাথে রেন্ডার ট্রি সম্পর্ক
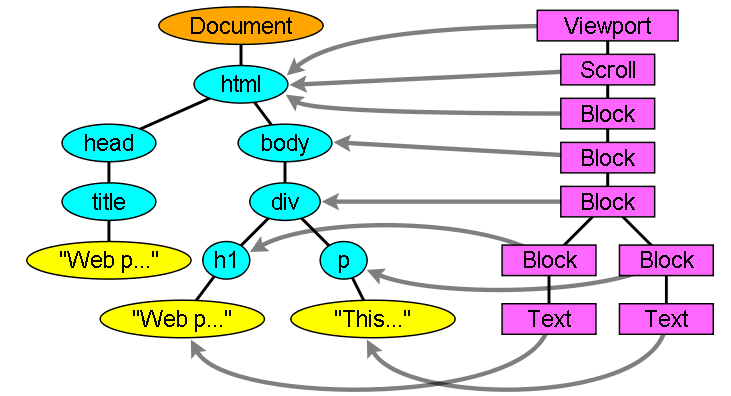
রেন্ডারারগুলি DOM উপাদানগুলির সাথে মিলে যায়, কিন্তু সম্পর্ক একের সাথে এক নয়৷ নন-ভিজ্যুয়াল DOM উপাদানগুলি রেন্ডার ট্রিতে ঢোকানো হবে না। একটি উদাহরণ হল "মাথা" উপাদান। এছাড়াও যে উপাদানগুলির প্রদর্শনের মান "কোনটি" তে নির্ধারিত ছিল সেগুলি গাছে উপস্থিত হবে না (যেখানে "লুকানো" দৃশ্যমানতা সহ উপাদানগুলি গাছে উপস্থিত হবে)।
DOM উপাদান আছে যা বেশ কিছু ভিজ্যুয়াল বস্তুর সাথে মিলে যায়। এগুলি সাধারণত জটিল কাঠামোর উপাদান যা একটি আয়তক্ষেত্র দ্বারা বর্ণনা করা যায় না। উদাহরণস্বরূপ, "নির্বাচন করুন" উপাদানটির তিনটি রেন্ডারার রয়েছে: একটি প্রদর্শন এলাকার জন্য, একটি ড্রপ ডাউন তালিকা বাক্সের জন্য এবং একটি বোতামের জন্য৷ এছাড়াও যখন পাঠ্য একাধিক লাইনে বিভক্ত হয় কারণ প্রস্থ একটি লাইনের জন্য যথেষ্ট নয়, তখন নতুন লাইনগুলি অতিরিক্ত রেন্ডারার হিসাবে যোগ করা হবে।
একাধিক রেন্ডারারের আরেকটি উদাহরণ হল ভাঙা HTML। CSS স্পেক অনুযায়ী একটি ইনলাইন এলিমেন্টে শুধুমাত্র ব্লক এলিমেন্ট বা শুধুমাত্র ইনলাইন এলিমেন্ট থাকতে হবে। মিশ্র সামগ্রীর ক্ষেত্রে, ইনলাইন উপাদানগুলিকে মোড়ানোর জন্য বেনামী ব্লক রেন্ডারার তৈরি করা হবে।
কিছু রেন্ডার অবজেক্ট একটি DOM নোডের সাথে মিলে যায় কিন্তু গাছের একই জায়গায় নয়। ফ্লোট এবং একেবারে অবস্থান করা উপাদানগুলি প্রবাহের বাইরে, গাছের একটি ভিন্ন অংশে স্থাপন করা হয় এবং বাস্তব ফ্রেমে ম্যাপ করা হয়। একটি স্থানধারক ফ্রেম যেখানে তারা থাকা উচিত ছিল.
গাছ নির্মাণের প্রবাহ
ফায়ারফক্সে, উপস্থাপনাটি DOM আপডেটের জন্য শ্রোতা হিসাবে নিবন্ধিত হয়। উপস্থাপনা ফ্রেম নির্মাণকে FrameConstructor অর্পণ করে এবং কনস্ট্রাক্টর শৈলী সমাধান করে ( স্টাইল গণনা দেখুন) এবং একটি ফ্রেম তৈরি করে।
ওয়েবকিটে শৈলী সমাধান এবং একটি রেন্ডারার তৈরি করার প্রক্রিয়াটিকে "সংযুক্তি" বলা হয়। প্রতিটি DOM নোডের একটি "সংযুক্ত" পদ্ধতি রয়েছে। সংযুক্তি সিঙ্ক্রোনাস, DOM ট্রিতে নোড সন্নিবেশ নতুন নোডকে "সংযুক্ত" পদ্ধতি বলে।
এইচটিএমএল এবং বডি ট্যাগ প্রক্রিয়াকরণের ফলে রেন্ডার ট্রি রুট তৈরি হয়। রুট রেন্ডার অবজেক্টের সাথে মিল রয়েছে যা CSS স্পেক কন্টেনিং ব্লককে বলে: টপ মোস্ট ব্লক যাতে অন্য সব ব্লক থাকে। এর মাত্রা হল ভিউপোর্ট: ব্রাউজার উইন্ডো প্রদর্শন এলাকা মাত্রা। ফায়ারফক্স এটিকে ViewPortFrame বলে এবং ওয়েবকিট এটিকে RenderView বলে। এটি সেই রেন্ডার অবজেক্ট যা নথিটি নির্দেশ করে। গাছের বাকী অংশগুলি একটি ডোম নোড সন্নিবেশ হিসাবে নির্মিত হয়।
প্রসেসিং মডেলটিতে সিএসএস 2 স্পেস দেখুন।
স্টাইল গণনা
রেন্ডার গাছ তৈরির জন্য প্রতিটি রেন্ডার অবজেক্টের ভিজ্যুয়াল বৈশিষ্ট্যগুলি গণনা করা প্রয়োজন। এটি প্রতিটি উপাদানের স্টাইলের বৈশিষ্ট্য গণনা করে করা হয়।
শৈলীতে বিভিন্ন উত্সের স্টাইল শীট, এইচটিএমএলে ("বিজকোলার" সম্পত্তিটির মতো) ইনলাইন স্টাইল উপাদান এবং ভিজ্যুয়াল বৈশিষ্ট্যগুলি অন্তর্ভুক্ত রয়েছে। পরে সিএসএস স্টাইলের বৈশিষ্ট্যগুলির সাথে মেলে অনুবাদ করা হয়।
স্টাইল শিটগুলির উত্স হ'ল ব্রাউজারের ডিফল্ট স্টাইল শিটগুলি, পৃষ্ঠা লেখক এবং ব্যবহারকারী স্টাইলের শীট দ্বারা সরবরাহিত স্টাইল শিটগুলি - এগুলি ব্রাউজার ব্যবহারকারী দ্বারা সরবরাহিত স্টাইল শিটগুলি (ব্রাউজারগুলি আপনাকে আপনার প্রিয় শৈলীগুলি সংজ্ঞায়িত করতে দেয়। উদাহরণস্বরূপ, এটি "ফায়ারফক্স প্রোফাইল" ফোল্ডারে একটি স্টাইল শীট স্থাপন করে করা হয়।
স্টাইল গণনা কয়েকটি অসুবিধা নিয়ে আসে:
- স্টাইলের ডেটা একটি খুব বড় নির্মাণ, অসংখ্য স্টাইলের বৈশিষ্ট্য ধারণ করে, এটি মেমরির সমস্যার কারণ হতে পারে।
প্রতিটি উপাদানের জন্য ম্যাচিং বিধিগুলি সন্ধান করা যদি এটি অনুকূলিত না হয় তবে পারফরম্যান্সের সমস্যাগুলির কারণ হতে পারে। ম্যাচগুলি সন্ধানের জন্য প্রতিটি উপাদানটির জন্য পুরো নিয়মের তালিকাটি অনুসরণ করা একটি ভারী কাজ। নির্বাচকদের জটিল কাঠামো থাকতে পারে যা ম্যাচিং প্রক্রিয়াটিকে একটি আপাতদৃষ্টিতে প্রতিশ্রুতিবদ্ধ পথে শুরু করতে পারে যা নিরর্থক হিসাবে প্রমাণিত এবং অন্য পথটি চেষ্টা করতে হবে।
উদাহরণস্বরূপ - এই যৌগিক নির্বাচক:
div div div div{ ... }এর অর্থ বিধিগুলি একটি
<div>এর ক্ষেত্রে প্রযোজ্য যিনি 3 ডিভের বংশধর। ধরুন আপনি প্রদত্ত<div>উপাদানটির জন্য নিয়মটি প্রযোজ্য কিনা তা পরীক্ষা করতে চান। আপনি চেক করার জন্য গাছের উপরে একটি নির্দিষ্ট পথ বেছে নিন। কেবলমাত্র দুটি ডিভস রয়েছে এবং নিয়মটি প্রযোজ্য নয় তা জানতে আপনার নোড গাছটি অতিক্রম করতে হবে। তারপরে আপনার গাছের অন্যান্য পথ চেষ্টা করা দরকার।নিয়ম প্রয়োগের ক্ষেত্রে বেশ জটিল ক্যাসকেড বিধি জড়িত যা নিয়মের শ্রেণিবিন্যাসকে সংজ্ঞায়িত করে।
আসুন দেখি ব্রাউজারগুলি কীভাবে এই সমস্যার মুখোমুখি হয়:
শৈলীর ডেটা ভাগ করে নেওয়া
ওয়েবকিট নোডগুলি স্টাইল অবজেক্টস (রেন্ডারস্টাইল) রেফারেন্স করে। এই বস্তুগুলি কিছু শর্তে নোড দ্বারা ভাগ করা যায়। নোডগুলি ভাইবোন বা কাজিন এবং:
- উপাদানগুলি অবশ্যই একই মাউস অবস্থায় থাকতে হবে (যেমন, একজন হতে পারে না: অন্যটি না থাকলেও হোভার)
- কোনও উপাদানই আইডি থাকা উচিত নয়
- ট্যাগের নামগুলি মেলে
- শ্রেণীর বৈশিষ্ট্যগুলি মেলে উচিত
- ম্যাপযুক্ত বৈশিষ্ট্যের সেটটি অবশ্যই অভিন্ন হতে হবে
- লিঙ্কটি অবশ্যই মেলে
- ফোকাস রাজ্যগুলি অবশ্যই মেলে
- কোনও উপাদানই অ্যাট্রিবিউট সিলেক্টরদের দ্বারা প্রভাবিত হওয়া উচিত নয়, যেখানে প্রভাবিত এমন কোনও নির্বাচক ম্যাচ হিসাবে সংজ্ঞায়িত করা হয় যা নির্বাচকের মধ্যে কোনও অবস্থানে কোনও অ্যাট্রিবিউট সিলেক্টর ব্যবহার করে
- উপাদানগুলির উপর অবশ্যই কোনও ইনলাইন স্টাইলের বৈশিষ্ট্য থাকতে হবে
- মোটেও ব্যবহারে কোনও ভাইবোন নির্বাচক থাকতে হবে না। ওয়েবকোর যখন কোনও ভাইবোন নির্বাচকের মুখোমুখি হয় তখন কেবল একটি গ্লোবাল স্যুইচ ছুড়ে দেয় এবং উপস্থিত থাকাকালীন পুরো দস্তাবেজের জন্য স্টাইল ভাগ করে নেওয়া অক্ষম করে। এর মধ্যে + নির্বাচক এবং নির্বাচকরা যেমন রয়েছে: প্রথম-শিশু এবং: শেষ-শিশু।
ফায়ারফক্স নিয়ম গাছ
ফায়ারফক্সে সহজ শৈলীর গণনার জন্য দুটি অতিরিক্ত গাছ রয়েছে: নিয়ম গাছ এবং স্টাইলের প্রসঙ্গ গাছ। ওয়েবকিটের স্টাইলের অবজেক্টও রয়েছে তবে এগুলি স্টাইলের প্রসঙ্গ গাছের মতো গাছে সংরক্ষণ করা হয় না, কেবলমাত্র ডোম নোড তার প্রাসঙ্গিক শৈলীতে নির্দেশ করে।
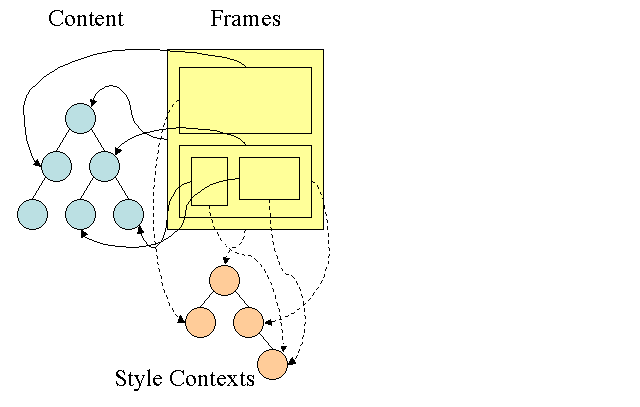
শৈলীর প্রসঙ্গে শেষ মান রয়েছে। মানগুলি সঠিক ক্রমে সমস্ত ম্যাচিং বিধি প্রয়োগ করে এবং ম্যানিপুলেশনগুলি সম্পাদন করে যা তাদের যৌক্তিক থেকে কংক্রিটের মানগুলিতে রূপান্তরিত করে গণনা করা হয়। উদাহরণস্বরূপ, যদি যৌক্তিক মানটি স্ক্রিনের শতাংশ হয় তবে এটি গণনা করা হবে এবং পরম ইউনিটে রূপান্তরিত হবে। নিয়ম গাছের ধারণাটি সত্যিই চতুর। এটি নোডগুলির মধ্যে আবার গণনা এড়াতে এই মানগুলি ভাগ করে নিতে সক্ষম করে। এটি স্থানও বাঁচায়।
সমস্ত মিলে যাওয়া নিয়ম একটি গাছে সংরক্ষণ করা হয়। একটি পথে নীচের নোডগুলির উচ্চ অগ্রাধিকার রয়েছে। গাছটিতে পাওয়া নিয়ম ম্যাচের জন্য সমস্ত পাথ রয়েছে। নিয়ম সংরক্ষণ করা অলসভাবে সম্পন্ন হয়। প্রতিটি নোডের শুরুতে গাছটি গণনা করা হয় না, তবে যখনই কোনও নোড শৈলীর গণনা করা দরকার তখন গাছের সাথে গণিত পাথ যুক্ত করা হয়।
ধারণাটি হ'ল গাছের পথগুলি একটি অভিধানের শব্দ হিসাবে দেখা। বলি আমরা ইতিমধ্যে এই নিয়ম গাছটি গণনা করেছি:
ধরুন আমাদের সামগ্রী গাছের অন্য উপাদানগুলির জন্য নিয়মগুলি মেলে এবং ম্যাচ করা নিয়মগুলি (সঠিক ক্রমে) বেইয়ের সন্ধান করতে হবে। আমাদের কাছে ইতিমধ্যে গাছটিতে এই পথ রয়েছে কারণ আমরা ইতিমধ্যে পথটি আবিলকে গণনা করেছি। আমাদের এখন কম কাজ করতে হবে।
আসুন দেখুন কীভাবে গাছটি আমাদের কাজ করে।
কাঠামোতে বিভাজন
স্টাইলের প্রসঙ্গগুলি স্ট্রাক্টগুলিতে বিভক্ত। এই স্ট্রাক্টগুলিতে সীমানা বা রঙের মতো নির্দিষ্ট বিভাগের জন্য স্টাইলের তথ্য রয়েছে। কোনও স্ট্রাক্টের সমস্ত বৈশিষ্ট্য হয় উত্তরাধিকার সূত্রে প্রাপ্ত বা উত্তরাধিকার সূত্রে প্রাপ্ত। উত্তরাধিকার সূত্রে প্রাপ্ত বৈশিষ্ট্যগুলি এমন বৈশিষ্ট্য যা উপাদান দ্বারা সংজ্ঞায়িত না হলে তার পিতামাতার কাছ থেকে উত্তরাধিকার সূত্রে প্রাপ্ত হয়। উত্তরাধিকারী বৈশিষ্ট্যগুলি ("রিসেট" বৈশিষ্ট্য বলা হয়) সংজ্ঞায়িত না হলে ডিফল্ট মানগুলি ব্যবহার করে।
গাছটি গাছের পুরো স্ট্রাক্টগুলি (গণিত প্রান্তের মানগুলি সমন্বিত) ক্যাশে করে আমাদের সহায়তা করে। ধারণাটি হ'ল যদি নীচের নোড কোনও স্ট্রাক্টের জন্য কোনও সংজ্ঞা সরবরাহ না করে তবে উপরের নোডে একটি ক্যাশেড স্ট্রাক্ট ব্যবহার করা যেতে পারে।
নিয়ম গাছ ব্যবহার করে স্টাইলের প্রসঙ্গগুলি গণনা করা
নির্দিষ্ট উপাদানটির জন্য স্টাইলের প্রসঙ্গটি গণনা করার সময়, আমরা প্রথমে নিয়ম গাছের একটি পথ গণনা করি বা একটি বিদ্যমান ব্যবহার করি। তারপরে আমরা আমাদের নতুন স্টাইলের প্রসঙ্গে স্ট্রাক্টগুলি পূরণ করার পথে নিয়মগুলি প্রয়োগ করতে শুরু করি। আমরা পথের নীচের নোডে শুরু করি - সর্বাধিক অগ্রাধিকার (সাধারণত সর্বাধিক নির্দিষ্ট নির্বাচক) সহ একটি এবং আমাদের কাঠামো পূর্ণ না হওয়া পর্যন্ত গাছটি অতিক্রম করে। যদি সেই নিয়ম নোডে স্ট্রাক্টের জন্য কোনও স্পেসিফিকেশন না থাকে, তবে আমরা ব্যাপকভাবে অনুকূল করতে পারি - আমরা গাছের উপরে উঠে না যাওয়া পর্যন্ত আমরা এমন একটি নোড খুঁজে পাই যা এটি পুরোপুরি নির্দিষ্ট করে এবং এটি নির্দেশ করে - এটিই সেরা অপ্টিমাইজেশন - পুরো স্ট্রাক্টটি ভাগ করা হয়। এটি শেষ মান এবং মেমরির গণনা সংরক্ষণ করে।
যদি আমরা আংশিক সংজ্ঞাগুলি খুঁজে পাই তবে স্ট্রাক্টটি পূরণ না হওয়া পর্যন্ত আমরা গাছের উপরে চলে যাই।
আমরা যদি আমাদের কাঠামোর জন্য কোনও সংজ্ঞা খুঁজে না পাই তবে স্ট্রাক্টটি যদি "উত্তরাধিকার সূত্রে প্রাপ্ত" প্রকার হয় তবে আমরা প্রসঙ্গ গাছটিতে আমাদের পিতামাতার কাঠামোর দিকে ইঙ্গিত করি। এক্ষেত্রে আমরা স্ট্রাক্টগুলি ভাগ করে নিতেও সফল হয়েছি। যদি এটি একটি রিসেট স্ট্রাক্ট হয় তবে ডিফল্ট মানগুলি ব্যবহার করা হবে।
যদি সর্বাধিক নির্দিষ্ট নোড মান যুক্ত করে তবে আমাদের এটিকে প্রকৃত মানগুলিতে রূপান্তর করার জন্য কিছু অতিরিক্ত গণনা করতে হবে। আমরা তখন গাছের নোডে ফলাফলটি ক্যাশে করি যাতে এটি শিশুরা ব্যবহার করতে পারে।
যদি কোনও উপাদানের কোনও ভাইবোন বা ভাই থাকে যা একই গাছের নোডের দিকে নির্দেশ করে তবে পুরো স্টাইলের প্রসঙ্গটি তাদের মধ্যে ভাগ করা যায়।
একটি উদাহরণ দেখতে দিন: ধরুন আমাদের এই এইচটিএমএল আছে
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
এবং নিম্নলিখিত নিয়ম:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
জিনিসগুলি সহজ করার জন্য আসুন আমরা বলি যে আমাদের কেবল দুটি স্ট্রাক্ট পূরণ করতে হবে: রঙ কাঠামো এবং মার্জিন স্ট্রাক্ট। রঙিন স্ট্রাক্টে কেবল একটি সদস্য রয়েছে: রঙটি মার্জিন স্ট্রাক্টে চারটি দিক রয়েছে।
ফলস্বরূপ নিয়ম গাছটি দেখতে এটির মতো হবে (নোডগুলি নোডের নামের সাথে চিহ্নিত করা হয়েছে: তারা যে নিয়মটি দেখিয়েছে তার সংখ্যা):
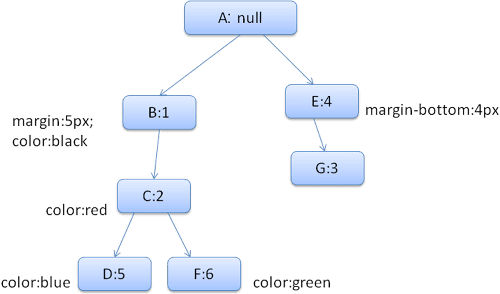
প্রসঙ্গ গাছটি দেখতে এটির মতো হবে (নোডের নাম: নিয়ম নোড তারা নির্দেশ করে):
ধরুন আমরা এইচটিএমএলকে পার্স করি এবং দ্বিতীয় <div> ট্যাগে পৌঁছে যাই। আমাদের এই নোডের জন্য একটি স্টাইল প্রসঙ্গ তৈরি করতে হবে এবং এর স্টাইল স্ট্রাক্টগুলি পূরণ করতে হবে।
আমরা নিয়মগুলির সাথে মেলে এবং আবিষ্কার করব যে <div> এর সাথে মিলের নিয়মগুলি 1, 2 এবং 6।
আমরা একটি স্টাইল প্রসঙ্গ তৈরি করব এবং এটি প্রসঙ্গে গাছটিতে রাখব। নতুন স্টাইলের প্রসঙ্গটি নিয়ম গাছের নোড এফের দিকে নির্দেশ করবে।
আমাদের এখন স্টাইল স্ট্রাক্টগুলি পূরণ করতে হবে। আমরা মার্জিন স্ট্রাক্ট পূরণ করে শুরু করব। যেহেতু সর্বশেষ নিয়ম নোড (এফ) মার্জিন স্ট্রাক্টে যোগ করে না, তাই আমরা আগের নোড সন্নিবেশে একটি ক্যাশেড স্ট্রাক্ট গণনা না করা এবং এটি ব্যবহার না করা পর্যন্ত আমরা গাছের উপরে যেতে পারি। আমরা এটি নোড বিতে খুঁজে পাব, এটি উপরের নোড যা মার্জিন বিধিগুলি নির্দিষ্ট করে।
রঙিন স্ট্রাক্টের জন্য আমাদের একটি সংজ্ঞা রয়েছে, তাই আমরা ক্যাশেড স্ট্রাক্ট ব্যবহার করতে পারি না। যেহেতু রঙের একটি বৈশিষ্ট্য রয়েছে তাই আমাদের অন্যান্য বৈশিষ্ট্যগুলি পূরণ করতে গাছের উপরে উঠতে হবে না। আমরা শেষ মানটি গণনা করব (স্ট্রিং স্ট্রিং আরজিবি ইত্যাদি) এবং এই নোডে গণিত স্ট্রাক্ট ক্যাশে করব।
দ্বিতীয় <span> উপাদানটির কাজটি আরও সহজ। আমরা নিয়মগুলির সাথে মেলে এবং এই সিদ্ধান্তে আসব যে এটি পূর্ববর্তী স্প্যানের মতো জি রুল জি -তে নির্দেশ করে। যেহেতু আমাদের ভাইবোন রয়েছে যা একই নোডের দিকে নির্দেশ করে, তাই আমরা পুরো স্টাইলের প্রসঙ্গটি ভাগ করে নিতে পারি এবং কেবল পূর্ববর্তী স্প্যানের প্রসঙ্গে নির্দেশ করতে পারি।
পিতামাতার কাছ থেকে উত্তরাধিকার সূত্রে প্রাপ্ত নিয়মগুলি ধারণ করে এমন স্ট্রাক্টগুলির জন্য, ক্যাশিং প্রসঙ্গ গাছটিতে করা হয় (রঙের সম্পত্তিটি আসলে উত্তরাধিকার সূত্রে প্রাপ্ত হয়, তবে ফায়ারফক্স এটিকে পুনরায় সেট হিসাবে বিবেচনা করে এবং এটি নিয়ম গাছটিতে ক্যাশে করে)।
উদাহরণস্বরূপ, যদি আমরা একটি অনুচ্ছেদে ফন্টের জন্য নিয়ম যুক্ত করি:
p {font-family: Verdana; font size: 10px; font-weight: bold}
তারপরে অনুচ্ছেদের উপাদান, যা প্রসঙ্গ গাছের ডিভের সন্তান, তার পিতামাতার মতো একই ফন্ট স্ট্রাক্ট ভাগ করে নিতে পারত। এটি যদি অনুচ্ছেদের জন্য কোনও ফন্টের নিয়ম নির্দিষ্ট না করা হয়।
ওয়েবকিটে, যার কোনও নিয়ম গাছ নেই, ম্যাচ করা ঘোষণাগুলি চারবার অতিক্রম করা হয়। প্রথম অ-গুরুত্বপূর্ণ উচ্চ অগ্রাধিকারের বৈশিষ্ট্যগুলি প্রয়োগ করা হয় (বৈশিষ্ট্যগুলি যা প্রথমে প্রয়োগ করা উচিত কারণ অন্যরা তাদের উপর নির্ভর করে যেমন প্রদর্শন করা উচিত), তারপরে উচ্চ অগ্রাধিকার গুরুত্বপূর্ণ, তারপরে স্বাভাবিক অগ্রাধিকার অ-গুরুত্বপূর্ণ, তারপরে স্বাভাবিক অগ্রাধিকার গুরুত্বপূর্ণ বিধি। এর অর্থ হ'ল একাধিকবার প্রদর্শিত বৈশিষ্ট্যগুলি সঠিক ক্যাসকেড অর্ডার অনুসারে সমাধান করা হবে। শেষ জয়।
সুতরাং সংক্ষিপ্তসার হিসাবে: স্টাইল অবজেক্টগুলি ভাগ করে নেওয়া (সম্পূর্ণরূপে বা তাদের অভ্যন্তরের কিছু স্ট্রাক্ট) ইস্যু 1 এবং 3 সমাধান করে। ফায়ারফক্স নিয়ম গাছটিও সঠিক ক্রমে বৈশিষ্ট্যগুলি প্রয়োগ করতে সহায়তা করে।
একটি সহজ ম্যাচের জন্য নিয়মগুলি পরিচালনা করা
শৈলীর নিয়মের জন্য বেশ কয়েকটি উত্স রয়েছে:
- সিএসএস নিয়মগুলি হয়, হয় বাহ্যিক স্টাইলের শীটগুলিতে বা স্টাইল উপাদানগুলিতে।
css p {color: blue} -
html <p style="color: blue" />মতো ইনলাইন স্টাইলের বৈশিষ্ট্যগুলি - এইচটিএমএল ভিজ্যুয়াল অ্যাট্রিবিউটস (যা প্রাসঙ্গিক শৈলীর নিয়মগুলিতে ম্যাপ করা হয়)
html <p bgcolor="blue" />শেষ দুটি সহজেই উপাদানটির সাথে মিলে যায় যেহেতু তিনি স্টাইলের বৈশিষ্ট্যগুলির মালিক এবং এইচটিএমএল বৈশিষ্ট্যগুলি কী হিসাবে উপাদানটি ব্যবহার করে ম্যাপ করা যায়।
যেমনটি ইস্যু #2 এ পূর্বে উল্লিখিত হয়েছে, সিএসএস বিধি ম্যাচিং আরও জটিল হতে পারে। অসুবিধা সমাধানের জন্য, নিয়মগুলি সহজে অ্যাক্সেসের জন্য ম্যানিপুলেটেড করা হয়।
স্টাইল শীটটি পার্স করার পরে, নির্বাচক অনুসারে বেশ কয়েকটি হ্যাশ মানচিত্রের একটিতে নিয়মগুলি যুক্ত করা হয়। আইডি অনুসারে মানচিত্র রয়েছে, শ্রেণীর নাম অনুসারে, ট্যাগ নাম অনুসারে এবং যে কোনও কিছুর জন্য একটি সাধারণ মানচিত্র যা এই বিভাগগুলিতে ফিট করে না। নির্বাচক যদি আইডি হয় তবে নিয়মটি আইডি মানচিত্রে যুক্ত করা হবে, যদি এটি কোনও শ্রেণি হয় তবে এটি শ্রেণীর মানচিত্রে যুক্ত করা হবে ইত্যাদি।
এই হেরফের নিয়মের সাথে মেলে এটি আরও সহজ করে তোলে। প্রতিটি ঘোষণায় দেখার দরকার নেই: আমরা মানচিত্রগুলি থেকে কোনও উপাদানের জন্য প্রাসঙ্গিক নিয়মগুলি বের করতে পারি। এই অপ্টিমাইজেশন নিয়মগুলির 95+% অপসারণ করে, যাতে তাদের ম্যাচিং প্রক্রিয়া চলাকালীন (4.1) বিবেচনা করার প্রয়োজন হয় না।
আসুন উদাহরণস্বরূপ নিম্নলিখিত শৈলীর নিয়মগুলি দেখুন:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
প্রথম নিয়মটি শ্রেণীর মানচিত্রে serted োকানো হবে। দ্বিতীয় আইডি মানচিত্রে এবং তৃতীয়টি ট্যাগ মানচিত্রে।
নিম্নলিখিত এইচটিএমএল খণ্ডের জন্য;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
আমরা প্রথমে পি উপাদানটির জন্য নিয়মগুলি সন্ধান করার চেষ্টা করব। শ্রেণীর মানচিত্রে একটি "ত্রুটি" কী থাকবে যার অধীনে "পি। এরর" এর নিয়ম পাওয়া যায়। ডিভ উপাদানটির আইডি মানচিত্রে প্রাসঙ্গিক নিয়ম থাকবে (কীটি আইডি) এবং ট্যাগ মানচিত্র। সুতরাং একমাত্র কাজ বাকী হ'ল কীগুলি সত্যই মেলে কোন নিয়মগুলি বের করা হয়েছিল তা সন্ধান করা।
উদাহরণস্বরূপ যদি ডিভের নিয়মটি ছিল:
table div {margin: 5px}
এটি এখনও ট্যাগ মানচিত্র থেকে বের করা হবে, কারণ কীটি সঠিকতম নির্বাচক, তবে এটি আমাদের ডিভ উপাদানটির সাথে মেলে না, যার কোনও টেবিল পূর্বপুরুষ নেই।
ওয়েবকিট এবং ফায়ারফক্স উভয়ই এই হেরফের করে।
স্টাইল শীট ক্যাসকেড অর্ডার
স্টাইল অবজেক্টে প্রতিটি ভিজ্যুয়াল বৈশিষ্ট্যের সাথে সম্পর্কিত বৈশিষ্ট্য রয়েছে (সমস্ত সিএসএস বৈশিষ্ট্যগুলি তবে আরও জেনেরিক)। যদি সম্পত্তিটি কোনও ম্যাচযুক্ত নিয়ম দ্বারা সংজ্ঞায়িত না করা হয়, তবে কিছু সম্পত্তি পিতামাতার উপাদান শৈলী অবজেক্ট দ্বারা উত্তরাধিকার সূত্রে প্রাপ্ত হতে পারে। অন্যান্য বৈশিষ্ট্যগুলির ডিফল্ট মান রয়েছে।
একাধিক সংজ্ঞা থাকলে সমস্যা শুরু হয় - এখানে সমস্যা সমাধানের জন্য ক্যাসকেড অর্ডার আসে।
স্টাইলের সম্পত্তির জন্য একটি ঘোষণা বেশ কয়েকটি স্টাইলের শীটে এবং বেশ কয়েকবার স্টাইলের শীটের ভিতরে উপস্থিত হতে পারে। এর অর্থ বিধি প্রয়োগের ক্রমটি অত্যন্ত গুরুত্বপূর্ণ। একে "ক্যাসকেড" অর্ডার বলা হয়। সিএসএস 2 স্পেক অনুসারে, ক্যাসকেড অর্ডারটি (নিম্ন থেকে উচ্চে):
- ব্রাউজার ঘোষণা
- ব্যবহারকারী সাধারণ ঘোষণা
- লেখক সাধারণ ঘোষণা
- লেখক গুরুত্বপূর্ণ ঘোষণা
- ব্যবহারকারী গুরুত্বপূর্ণ ঘোষণা
ব্রাউজারের ঘোষণাগুলি কমপক্ষে গুরুত্বপূর্ণ এবং ব্যবহারকারী কেবল লেখককে ওভাররাইড করে যদি ঘোষণাটি গুরুত্বপূর্ণ হিসাবে চিহ্নিত করা হয়। একই আদেশের সাথে ঘোষণাগুলি সুনির্দিষ্টতার দ্বারা বাছাই করা হবে এবং তারপরে সেগুলি নির্দিষ্ট করা হবে। এইচটিএমএল ভিজ্যুয়াল বৈশিষ্ট্যগুলি সিএসএস ঘোষণার সাথে মেলে অনুবাদ করা হয়। তাদের কম অগ্রাধিকার সহ লেখকের নিয়ম হিসাবে বিবেচনা করা হয়।
বিশেষত্ব
নির্বাচকের সুনির্দিষ্টতা সিএসএস 2 স্পেসিফিকেশন দ্বারা নিম্নলিখিত হিসাবে সংজ্ঞায়িত করা হয়েছে:
- গণনা 1 যদি এটি ঘোষণাটি থেকে হয় তবে কোনও নির্বাচকের সাথে নিয়মের পরিবর্তে একটি 'স্টাইল' বৈশিষ্ট্য, 0 অন্যথায় (= এ)
- নির্বাচকের মধ্যে আইডি বৈশিষ্ট্যের সংখ্যা গণনা করুন (= বি)
- নির্বাচক (= সি) এ অন্যান্য বৈশিষ্ট্য এবং সিউডো-শ্রেণীর সংখ্যা গণনা করুন
- নির্বাচক (= ডি) এ উপাদানগুলির নাম এবং সিউডো-উপাদানগুলির সংখ্যা গণনা করুন
চারটি নম্বর এবিসিডি (একটি বৃহত বেস সহ একটি সংখ্যা সিস্টেমে) সংহতকরণ নির্দিষ্টতা দেয়।
আপনার যে নম্বর বেসটি ব্যবহার করতে হবে তা আপনার কোনও বিভাগে সর্বোচ্চ গণনা দ্বারা সংজ্ঞায়িত করা হয়।
উদাহরণস্বরূপ, যদি a = 14 আপনি হেক্সাডেসিমাল বেস ব্যবহার করতে পারেন। অসম্ভব ক্ষেত্রে যেখানে A = 17 আপনার 17 টি সংখ্যা নম্বর বেসের প্রয়োজন হবে। পরবর্তী পরিস্থিতি এই জাতীয় নির্বাচকের সাথে ঘটতে পারে: এইচটিএমএল বডি ডিভ ডিভ পি… (আপনার নির্বাচকের 17 টি ট্যাগ ... খুব সম্ভবত নয়)।
কিছু উদাহরণ:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
নিয়ম বাছাই
নিয়মগুলি মিলে যাওয়ার পরে, সেগুলি ক্যাসকেড বিধি অনুসারে বাছাই করা হয়। ওয়েবকিট ছোট তালিকাগুলির জন্য বুদ্বুদ বাছাই এবং বড়গুলির জন্য মার্জ বাছাই করে। ওয়েবকিট বিধিগুলির জন্য > অপারেটরকে ওভাররাইড করে বাছাই করে:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
ধীরে ধীরে প্রক্রিয়া
ওয়েবকিট একটি পতাকা ব্যবহার করে যা চিহ্নিত করে যদি সমস্ত শীর্ষ স্তরের স্টাইলের শীট ( @আইএমপোর্ট সহ) লোড করা থাকে। সংযুক্ত হওয়ার সময় যদি স্টাইলটি পুরোপুরি লোড না হয় তবে স্থানধারীরা ব্যবহার করা হয় এবং এটি নথিতে চিহ্নিত করা হয় এবং স্টাইলের শীটগুলি লোড হয়ে গেলে সেগুলি পুনরায় গণনা করা হবে।
লেআউট
যখন রেন্ডারারটি তৈরি করা হয় এবং গাছটিতে যুক্ত হয়, তখন এটির কোনও অবস্থান এবং আকার নেই। এই মানগুলি গণনা করা লেআউট বা রিফ্লো বলা হয়।
এইচটিএমএল একটি প্রবাহ ভিত্তিক লেআউট মডেল ব্যবহার করে যার অর্থ বেশিরভাগ সময় একক পাসে জ্যামিতিটি গণনা করা সম্ভব। উপাদানগুলি পরে "প্রবাহে" সাধারণত উপাদানগুলির জ্যামিতিকে প্রভাবিত করে না যা আগে "প্রবাহে" থাকে, তাই বিন্যাসটি ডকুমেন্টের মাধ্যমে বাম-থেকে-ডান, শীর্ষ-থেকে নীচে এগিয়ে যেতে পারে। ব্যতিক্রম রয়েছে: উদাহরণস্বরূপ, এইচটিএমএল টেবিলগুলিতে একাধিক পাস প্রয়োজন হতে পারে।
সমন্বয় ব্যবস্থা মূল ফ্রেমের সাথে সম্পর্কিত। শীর্ষ এবং বাম স্থানাঙ্ক ব্যবহার করা হয়।
লেআউট একটি পুনরাবৃত্ত প্রক্রিয়া। এটি রুট রেন্ডারারে শুরু হয়, যা এইচটিএমএল ডকুমেন্টের <html> উপাদানটির সাথে মিলে যায়। লেআউটটি প্রতিটি রেন্ডারারের জন্য জ্যামিতিক তথ্য কম্পিউটিংয়ের জন্য কিছু বা সমস্ত ফ্রেম হায়ারার্কির মাধ্যমে পুনরাবৃত্তভাবে অব্যাহত থাকে।
রুট রেন্ডারারের অবস্থান 0,0 এবং এর মাত্রাগুলি ভিউপোর্ট - ব্রাউজার উইন্ডোর দৃশ্যমান অংশ।
সমস্ত রেন্ডারারদের একটি "লেআউট" বা "রিফ্লো" পদ্ধতি রয়েছে, প্রতিটি রেন্ডারার তার বাচ্চাদের বিন্যাসের পদ্ধতিটি অনুরোধ করে যা বিন্যাসের প্রয়োজন।
নোংরা বিট সিস্টেম
প্রতিটি ছোট পরিবর্তনের জন্য একটি সম্পূর্ণ বিন্যাস না করার জন্য, ব্রাউজারগুলি একটি "নোংরা বিট" সিস্টেম ব্যবহার করে। এমন একটি রেন্ডারার যা পরিবর্তিত বা যুক্ত করা হয় নিজেই এবং এর বাচ্চাদের "নোংরা" হিসাবে চিহ্নিত করে: লেআউটের প্রয়োজন।
দুটি পতাকা রয়েছে: "নোংরা", এবং "শিশুরা নোংরা" যার অর্থ রেন্ডারার নিজেই ঠিক থাকতে পারে তবে এর কমপক্ষে একটি শিশু রয়েছে যার একটি বিন্যাসের প্রয়োজন।
গ্লোবাল এবং ইনক্রিমেন্টাল লেআউট
পুরো রেন্ডার ট্রিতে লেআউটটি ট্রিগার করা যেতে পারে - এটি "গ্লোবাল" লেআউট। এটি এর ফলে ঘটতে পারে:
- একটি বিশ্বব্যাপী স্টাইল পরিবর্তন যা সমস্ত রেন্ডারারকে প্রভাবিত করে, যেমন ফন্ট আকারের পরিবর্তনের মতো।
- একটি পর্দার ফলাফল হিসাবে পুনরায় আকার দেওয়া হচ্ছে
লেআউটটি বর্ধিত হতে পারে, কেবল নোংরা রেন্ডারারদের স্থাপন করা হবে (এটি কিছু ক্ষতির কারণ হতে পারে যার জন্য অতিরিক্ত বিন্যাসের প্রয়োজন হবে)।
যখন রেন্ডারারগুলি নোংরা হয় তখন ইনক্রিমেন্টাল লেআউটটি ট্রিগার করা হয় (অ্যাসিঙ্ক্রোনালি)। উদাহরণস্বরূপ, যখন নতুন রেন্ডারারগুলি নেটওয়ার্ক থেকে অতিরিক্ত সামগ্রী আসার পরে রেন্ডার ট্রিতে যুক্ত করা হয় এবং ডোম গাছটিতে যুক্ত করা হয়েছিল।
অ্যাসিঙ্ক্রোনাস এবং সিঙ্ক্রোনাস লেআউট
ইনক্রিমেন্টাল লেআউটটি অ্যাসিঙ্ক্রোনালিভাবে সম্পন্ন হয়। ফায়ারফক্স সারিগুলি ইনক্রিমেন্টাল লেআউটগুলির জন্য "রিফ্লো কমান্ডগুলি" এবং এই কমান্ডগুলির একটি শিডিয়ুলার ট্রিগার ব্যাচ এক্সিকিউশন। ওয়েবকিটের একটি টাইমারও রয়েছে যা একটি ইনক্রিমেন্টাল লেআউট কার্যকর করে - গাছটি অনুসরণ করা হয় এবং "নোংরা" রেন্ডারারগুলি বিন্যাসের বাইরে থাকে।
স্টাইলের তথ্যের জন্য জিজ্ঞাসা করা স্ক্রিপ্টগুলি, যেমন "অফথাইট" এর মতো ইনক্রিমেন্টাল লেআউটটি সিঙ্ক্রোনালিভাবে ট্রিগার করতে পারে।
গ্লোবাল লেআউটটি সাধারণত সিঙ্ক্রোনালি ট্রিগার করা হবে।
কখনও কখনও লেআউটটি প্রাথমিক বিন্যাসের পরে কলব্যাক হিসাবে ট্রিগার করা হয় কারণ স্ক্রোলিং পজিশনের মতো কিছু বৈশিষ্ট্য পরিবর্তিত হয়।
অপ্টিমাইজেশন
যখন কোনও লেআউটটি "আকার পরিবর্তন" বা রেন্ডারারের অবস্থানের পরিবর্তন (এবং আকার নয়) দ্বারা ট্রিগার করা হয়, তখন রেন্ডার আকারগুলি একটি ক্যাশে থেকে নেওয়া হয় এবং পুনরায় গণনা করা হয় না ...
কিছু ক্ষেত্রে কেবল একটি সাব ট্রি সংশোধন করা হয় এবং লেআউটটি মূল থেকে শুরু হয় না। এটি এমন ক্ষেত্রে ঘটতে পারে যেখানে পরিবর্তনটি স্থানীয় এবং এর চারপাশের প্রভাব ফেলে না - যেমন পাঠ্য ক্ষেত্রগুলিতে .োকানো পাঠ্য (অন্যথায় প্রতিটি কীস্ট্রোক মূল থেকে শুরু করে একটি বিন্যাসকে ট্রিগার করবে)।
লেআউট প্রক্রিয়া
লেআউটটিতে সাধারণত নিম্নলিখিত প্যাটার্ন থাকে:
- প্যারেন্ট রেন্ডারার তার নিজস্ব প্রস্থ নির্ধারণ করে।
- পিতামাতারা বাচ্চাদের উপর দিয়ে যান এবং:
- চাইল্ড রেন্ডারার রাখুন (এর এক্স এবং ওয়াই সেট করে)।
- প্রয়োজনে শিশু লেআউটকে কল করে - সেগুলি নোংরা বা আমরা বিশ্বব্যাপী লেআউটে বা অন্য কোনও কারণে - যা সন্তানের উচ্চতা গণনা করে।
- পিতামাতারা নিজস্ব উচ্চতা নির্ধারণের জন্য বাচ্চাদের জমে থাকা উচ্চতা এবং মার্জিন এবং প্যাডিংয়ের উচ্চতা ব্যবহার করেন - এটি পিতামাতার রেন্ডারারের পিতামাতার দ্বারা ব্যবহৃত হবে।
- এর নোংরা বিটকে মিথ্যা বলে সেট করে।
ফায়ারফক্স লেআউট ("রিফ্লো" বলা হয়) হিসাবে প্যারামিটার হিসাবে একটি "রাষ্ট্র" অবজেক্ট (এনএসএইচটিএমএলআরফ্লোস্টেট) ব্যবহার করে। অন্যদের মধ্যে রাজ্যে পিতামাতার প্রস্থ অন্তর্ভুক্ত রয়েছে।
ফায়ারফক্স লেআউটের আউটপুট হ'ল একটি "মেট্রিকস" অবজেক্ট (এনএসএইচটিএমএলআরফ্লোমেট্রিক্স)। এটিতে রেন্ডারার গণিত উচ্চতা থাকবে।
প্রস্থ গণনা
রেন্ডারারের প্রস্থটি কনটেইনার ব্লকের প্রস্থ, রেন্ডারারের স্টাইল "প্রস্থ" সম্পত্তি, মার্জিন এবং সীমানা ব্যবহার করে গণনা করা হয়।
উদাহরণস্বরূপ নিম্নলিখিত ডিভের প্রস্থ:
<div style="width: 30%"/>
ওয়েবকিট দ্বারা নিম্নলিখিত হিসাবে গণনা করা হবে (ক্লাস রেন্ডারবক্স পদ্ধতি ক্যালকউইথ):
- ধারক প্রস্থটি উপলভ্যউথ এবং 0 টির সর্বোচ্চ পাত্রে সর্বাধিক।
clientWidth() - paddingLeft() - paddingRight()
ক্লায়েন্টউইথ এবং ক্লায়েন্টহাইট সীমানা এবং স্ক্রোলবার বাদে কোনও বস্তুর অভ্যন্তর উপস্থাপন করে।
উপাদানগুলির প্রস্থ হ'ল "প্রস্থ" শৈলীর বৈশিষ্ট্য। এটি ধারক প্রস্থের শতাংশের গণনা করে একটি পরম মান হিসাবে গণনা করা হবে।
অনুভূমিক সীমানা এবং প্যাডিংগুলি এখন যুক্ত করা হয়েছে।
এখনও অবধি এটি ছিল "পছন্দসই প্রস্থ" এর গণনা। এখন সর্বনিম্ন এবং সর্বাধিক প্রস্থ গণনা করা হবে।
যদি পছন্দের প্রস্থটি সর্বোচ্চ প্রস্থের চেয়ে বেশি হয় তবে সর্বাধিক প্রস্থ ব্যবহার করা হয়। যদি এটি সর্বনিম্ন প্রস্থের (ক্ষুদ্রতম অবিচ্ছেদ্য ইউনিট) এর চেয়ে কম হয় তবে সর্বনিম্ন প্রস্থ ব্যবহার করা হয়।
কোনও বিন্যাসের প্রয়োজন হলে মানগুলি ক্যাশে করা হয় তবে প্রস্থটি পরিবর্তন হয় না।
লাইন ব্রেকিং
যখন কোনও লেআউটের মাঝখানে কোনও রেন্ডারার সিদ্ধান্ত নেয় যে এটি ভাঙতে হবে, তখন রেন্ডারার থামে এবং লেআউটের পিতামাতার কাছে প্রচার করে যে এটি ভেঙে ফেলা দরকার। পিতামাতারা অতিরিক্ত রেন্ডারার তৈরি করে এবং তাদের উপর লেআউট কল করে।
পেইন্টিং
পেইন্টিং পর্যায়ে, রেন্ডার গাছটি ট্র্যাভারস করা হয় এবং রেন্ডারারের "পেইন্ট ()" পদ্ধতিটি স্ক্রিনে সামগ্রী প্রদর্শনের জন্য ডাকা হয়। পেইন্টিং ইউআই অবকাঠামো উপাদান ব্যবহার করে।
গ্লোবাল এবং ইনক্রিমেন্টাল
লেআউটের মতো চিত্রকর্মটিও বিশ্বব্যাপী হতে পারে - পুরো গাছটি আঁকা - বা ইনক্রিমেন্টাল। ইনক্রিমেন্টাল পেইন্টিংয়ে, কিছু রেন্ডারার এমনভাবে পরিবর্তিত হয় যা পুরো গাছকে প্রভাবিত করে না। পরিবর্তিত রেন্ডারার স্ক্রিনে এর আয়তক্ষেত্রকে অবৈধ করে। এর ফলে ওএস এটি একটি "নোংরা অঞ্চল" হিসাবে দেখতে এবং একটি "পেইন্ট" ইভেন্ট তৈরি করে। ওএস এটি চতুরতার সাথে করে এবং বেশ কয়েকটি অঞ্চলকে একটিতে একত্রিত করে। ক্রোমে এটি আরও জটিল কারণ রেন্ডারারটি আলাদা প্রক্রিয়াতে থাকে তারপরে মূল প্রক্রিয়া। ক্রোম কিছুটা হলেও ওএস আচরণকে অনুকরণ করে। উপস্থাপনাটি এই ইভেন্টগুলি শোনায় এবং বার্তাটি রেন্ডার রুটে অর্পণ করে। প্রাসঙ্গিক রেন্ডারার পৌঁছানো পর্যন্ত গাছটি অনুসরণ করা হয়। এটি নিজেকে পুনরায় রঙ করবে (এবং সাধারণত এর সন্তান)।
পেইন্টিং অর্ডার
সিএসএস 2 পেইন্টিং প্রক্রিয়াটির ক্রমকে সংজ্ঞায়িত করে । এটি আসলে সেই ক্রম যেখানে উপাদানগুলি স্ট্যাকিং প্রসঙ্গে স্ট্যাক করা হয়। স্ট্যাকগুলি পিছনে থেকে সামনের দিকে আঁকা হওয়ায় এই ক্রমটি পেইন্টিংকে প্রভাবিত করে। একটি ব্লক রেন্ডারারের স্ট্যাকিং অর্ডার হ'ল:
- পটভূমির রঙ
- ব্যাকগ্রাউন্ড ইমেজ
- সীমান্ত
- শিশু
- রূপরেখা
ফায়ারফক্স ডিসপ্লে তালিকা
ফায়ারফক্স রেন্ডার গাছের ওপরে যায় এবং আঁকা আয়তক্ষেত্রাকার জন্য একটি প্রদর্শন তালিকা তৈরি করে। এটিতে আয়তক্ষেত্রাকার জন্য রেন্ডারারগুলি রয়েছে, ডান পেইন্টিং ক্রমে (রেন্ডারারদের ব্যাকগ্রাউন্ড, তারপরে সীমানা ইত্যাদি)।
এইভাবে গাছটিকে বেশ কয়েকবার পরিবর্তে পুনরায় রঙ করার জন্য একবারে ট্র্যাভার করা দরকার - সমস্ত ব্যাকগ্রাউন্ড, তারপরে সমস্ত চিত্র, তারপরে সমস্ত সীমানা ইত্যাদি আঁকা
ফায়ারফক্স অন্যান্য অস্বচ্ছ উপাদানগুলির নীচে সম্পূর্ণ উপাদানগুলির মতো লুকানো হবে এমন উপাদানগুলি যুক্ত না করে প্রক্রিয়াটিকে অনুকূল করে তোলে।
ওয়েবকিট আয়তক্ষেত্র স্টোরেজ
পুনর্নির্মাণের আগে, ওয়েবকিট একটি বিটম্যাপ হিসাবে পুরানো আয়তক্ষেত্রটি সংরক্ষণ করে। এটি তখন নতুন এবং পুরানো আয়তক্ষেত্রগুলির মধ্যে কেবল ডেল্টা আঁকেন।
গতিশীল পরিবর্তন
ব্রাউজারগুলি পরিবর্তনের প্রতিক্রিয়ায় ন্যূনতম সম্ভাব্য ক্রিয়াগুলি করার চেষ্টা করে। সুতরাং একটি উপাদান বর্ণের পরিবর্তনগুলি কেবল উপাদানটির পুনঃনির্মাণের কারণ হতে পারে। উপাদান অবস্থানের পরিবর্তনের ফলে উপাদান, তার শিশু এবং সম্ভবত ভাইবোনদের বিন্যাস এবং পুনরায় রঙ করা হবে। একটি ডোম নোড যুক্ত করার ফলে নোডের বিন্যাস এবং পুনরায় রঙ করা হবে। "এইচটিএমএল" উপাদানটির ফন্টের আকার বাড়ানোর মতো বড় পরিবর্তনগুলি ক্যাশে অবৈধকরণ, রিলেআউট এবং পুরো গাছের পুনরায় রঙ করতে পারে।
রেন্ডারিং ইঞ্জিনের থ্রেড
রেন্ডারিং ইঞ্জিনটি একক থ্রেডযুক্ত। নেটওয়ার্ক অপারেশন ব্যতীত প্রায় সমস্ত কিছুই একক থ্রেডে ঘটে। ফায়ারফক্স এবং সাফারিতে এটি ব্রাউজারের মূল থ্রেড। ক্রোমে এটি ট্যাব প্রক্রিয়া মূল থ্রেড।
নেটওয়ার্ক অপারেশনগুলি বেশ কয়েকটি সমান্তরাল থ্রেড দ্বারা সম্পাদন করা যেতে পারে। সমান্তরাল সংযোগের সংখ্যা সীমিত (সাধারণত 2 - 6 সংযোগ)।
ইভেন্ট লুপ
ব্রাউজারের প্রধান থ্রেড একটি ইভেন্ট লুপ। এটি একটি অসীম লুপ যা প্রক্রিয়াটিকে বাঁচিয়ে রাখে। এটি ইভেন্টগুলির জন্য অপেক্ষা করে (লেআউট এবং পেইন্ট ইভেন্টগুলির মতো) এবং সেগুলি প্রক্রিয়া করে। এটি মূল ইভেন্টের লুপের জন্য ফায়ারফক্স কোড:
while (!mExiting)
NS_ProcessNextEvent(thread);
সিএসএস 2 ভিজ্যুয়াল মডেল
ক্যানভাস
সিএসএস 2 স্পেসিফিকেশন অনুসারে, ক্যানভাস শব্দটি "ফর্ম্যাটিং কাঠামোটি রেন্ডার করা হয়েছে এমন স্থানটি বর্ণনা করে": যেখানে ব্রাউজারটি সামগ্রীটি আঁকেন।
ক্যানভাস স্থানের প্রতিটি মাত্রার জন্য অসীম তবে ব্রাউজারগুলি ভিউপোর্টের মাত্রার উপর ভিত্তি করে প্রাথমিক প্রস্থকে বেছে নেয়।
Www.w3.org/tr/css2/zindex.html অনুসারে, ক্যানভাসটি অন্যের মধ্যে থাকা থাকলে স্বচ্ছ, এবং এটি না থাকলে একটি ব্রাউজার সংজ্ঞায়িত রঙ দেওয়া হয়।
সিএসএস বক্স মডেল
সিএসএস বক্স মডেলটি আয়তক্ষেত্রাকার বাক্সগুলি বর্ণনা করে যা নথি গাছের উপাদানগুলির জন্য উত্পন্ন হয় এবং ভিজ্যুয়াল ফর্ম্যাটিং মডেল অনুসারে স্থাপন করা হয়।
প্রতিটি বাক্সে একটি সামগ্রী অঞ্চল (যেমন পাঠ্য, একটি চিত্র ইত্যাদি) এবং আশেপাশের প্যাডিং, সীমানা এবং মার্জিন অঞ্চল রয়েছে।
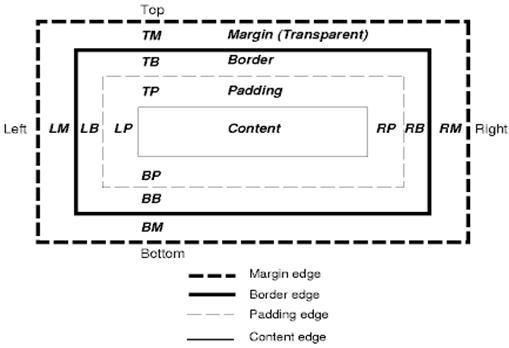
প্রতিটি নোড 0… এন এরকম বাক্স উত্পন্ন করে।
সমস্ত উপাদানগুলির একটি "প্রদর্শন" সম্পত্তি রয়েছে যা উত্পন্ন হবে এমন বাক্সের ধরণ নির্ধারণ করে।
উদাহরণ:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
ডিফল্টটি ইনলাইন তবে ব্রাউজার স্টাইল শীট অন্যান্য ডিফল্ট সেট করতে পারে। উদাহরণস্বরূপ: "ডিভ" উপাদানটির জন্য ডিফল্ট প্রদর্শনটি ব্লক।
আপনি এখানে একটি ডিফল্ট স্টাইল শীট উদাহরণ পেতে পারেন: www.w3.org/tr/css2/sample.html ।
পজিশনিং স্কিম
তিনটি স্কিম রয়েছে:
- সাধারণ: অবজেক্টটি নথিতে তার স্থান অনুসারে অবস্থিত। এর অর্থ রেন্ডার গাছের জায়গাটি ডোম গাছের জায়গার মতো এবং এর বাক্সের ধরণ এবং মাত্রা অনুসারে স্থাপন করা
- ভাসমান: বস্তুটি প্রথমে সাধারণ প্রবাহের মতো স্থাপন করা হয়, তারপরে যতদূর সম্ভব বাম বা ডানদিকে সরানো হয়
- পরম: অবজেক্টটি ডোম গাছের চেয়ে আলাদা জায়গায় রেন্ডার গাছের মধ্যে রাখা হয়
পজিশনিং স্কিমটি "অবস্থান" সম্পত্তি এবং "ভাসমান" বৈশিষ্ট্য দ্বারা সেট করা হয়।
- স্থির এবং আপেক্ষিক একটি সাধারণ প্রবাহের কারণ
- পরম এবং স্থির কারণ পরম অবস্থান
স্ট্যাটিক অবস্থানে কোনও অবস্থান সংজ্ঞায়িত করা হয় না এবং ডিফল্ট অবস্থান ব্যবহৃত হয়। অন্যান্য স্কিমগুলিতে লেখক অবস্থানটি নির্দিষ্ট করে: শীর্ষ, নীচে, বাম, ডান।
বাক্সটি যেভাবে স্থাপন করা হয়েছে তা নির্ধারিত হয়:
- বক্স টাইপ
- বক্সের মাত্রা
- পজিশনিং স্কিম
- বাহ্যিক তথ্য যেমন চিত্রের আকার এবং পর্দার আকার
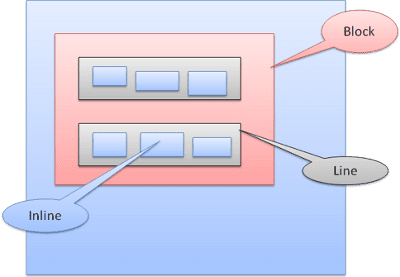
বাক্সের ধরন
ব্লক বক্স: একটি ব্লক গঠন করে - ব্রাউজার উইন্ডোতে এর নিজস্ব আয়তক্ষেত্র রয়েছে।

ইনলাইন বক্স: এর নিজস্ব ব্লক নেই, তবে এটি একটি ব্লকের ভিতরে রয়েছে।
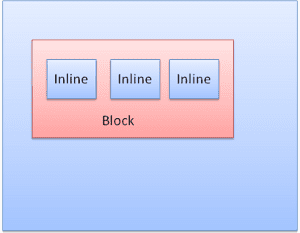
ব্লকগুলি একের পর এক উল্লম্বভাবে ফর্ম্যাট করা হয়। ইনলাইনগুলি অনুভূমিকভাবে ফর্ম্যাট করা হয়।
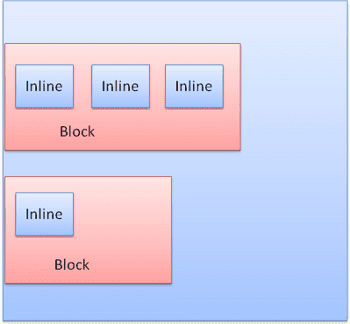
ইনলাইন বাক্সগুলি লাইন বা "লাইন বাক্স" ভিতরে রাখা হয়। লাইনগুলি কমপক্ষে লম্বা বাক্সের মতো লম্বা তবে লম্বা হতে পারে, যখন বাক্সগুলি "বেসলাইন" সারিবদ্ধ করা হয় - যার অর্থ কোনও উপাদানের নীচের অংশটি অন্য বাক্সের একটি বিন্দুতে সংযুক্ত করা হয় এবং নীচের অংশে। যদি ধারক প্রস্থ পর্যাপ্ত না হয় তবে ইনলাইনগুলি বেশ কয়েকটি লাইনে রাখা হবে। এটি সাধারণত একটি অনুচ্ছেদে ঘটে।
পজিশনিং
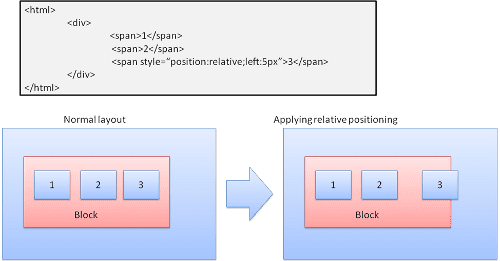
আপেক্ষিক
আপেক্ষিক অবস্থান - স্বাভাবিকের মতো অবস্থানযুক্ত এবং তারপরে প্রয়োজনীয় ডেল্টা দ্বারা সরানো।
ভাসছে
একটি ভাসমান বাক্সটি একটি লাইনের বাম বা ডানদিকে স্থানান্তরিত হয়। আকর্ষণীয় বৈশিষ্ট্যটি হ'ল অন্যান্য বাক্সগুলি এর চারপাশে প্রবাহিত হয়। এইচটিএমএল:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
এর মত দেখাবে:

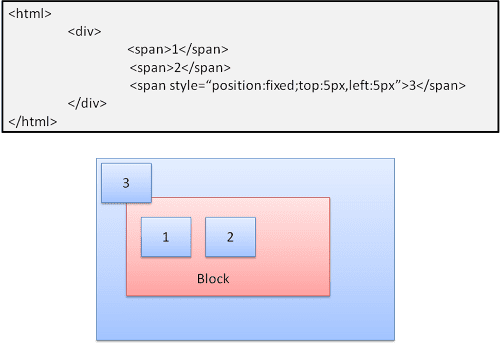
পরম এবং স্থির
সাধারণ প্রবাহ নির্বিশেষে বিন্যাসটি ঠিক সংজ্ঞায়িত করা হয়। উপাদানটি স্বাভাবিক প্রবাহে অংশ নেয় না। মাত্রাগুলি ধারকটির সাথে সম্পর্কিত। স্থিরভাবে, ধারকটি ভিউপোর্ট।
স্তরযুক্ত উপস্থাপনা
এটি জেড-সূচক সিএসএস সম্পত্তি দ্বারা নির্দিষ্ট করা হয়েছে। এটি বাক্সের তৃতীয় মাত্রা উপস্থাপন করে: "জেড অক্ষ" বরাবর এর অবস্থান।
বাক্সগুলি স্ট্যাকগুলিতে বিভক্ত করা হয় (স্ট্যাকিং প্রসঙ্গে বলা হয়)। প্রতিটি স্ট্যাকে পিছনের উপাদানগুলি প্রথমে আঁকা হবে এবং শীর্ষে ফরোয়ার্ড উপাদানগুলি ব্যবহারকারীর কাছাকাছি। ওভারল্যাপের ক্ষেত্রে সর্বাধিক উপাদানটি পূর্বের উপাদানটিকে আড়াল করবে।
স্ট্যাকগুলি জেড-সূচক সম্পত্তি অনুযায়ী অর্ডার করা হয়। "জেড-সূচক" সম্পত্তি সহ বাক্সগুলি একটি স্থানীয় স্ট্যাক গঠন করে। ভিউপোর্টে বাইরের স্ট্যাক রয়েছে।
উদাহরণ:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
ফলাফল এটি হবে:

যদিও লাল ডিভটি মার্কআপে সবুজটির আগে রয়েছে এবং এটি নিয়মিত প্রবাহের আগে আঁকা হত, জেড-সূচক সম্পত্তিটি বেশি, সুতরাং এটি মূল বাক্সের দ্বারা রাখা স্ট্যাকটিতে আরও এগিয়ে রয়েছে।
সম্পদ
ব্রাউজার আর্কিটেকচার
- গ্রসকুর্থ, অ্যালান। ওয়েব ব্রাউজারগুলির জন্য একটি রেফারেন্স আর্কিটেকচার (পিডিএফ)
- গুপ্ত, ভাইনেট। ব্রাউজারগুলি কীভাবে কাজ করে - অংশ 1 - আর্কিটেকচার
পার্সিং
- আহো, শেঠি, উলম্যান, সংকলক: নীতি, কৌশল এবং সরঞ্জামগুলি (ওরফে দ্য "ড্রাগন বুক"), অ্যাডিসন-ওয়েসলি, 1986
- রিক জেলিফ। সাহসী এবং সুন্দর: এইচটিএমএল 5 এর জন্য দুটি নতুন খসড়া।
ফায়ারফক্স
- এল। ডেভিড ব্যারন, দ্রুত এইচটিএমএল এবং সিএসএস: ওয়েব বিকাশকারীদের জন্য লেআউট ইঞ্জিন ইন্টার্নাল।
- এল। ডেভিড ব্যারন, দ্রুত এইচটিএমএল এবং সিএসএস: ওয়েব বিকাশকারীদের জন্য লেআউট ইঞ্জিন ইন্টার্নালস (গুগল টেক টক ভিডিও)
- এল ডেভিড ব্যারন, মোজিলার লেআউট ইঞ্জিন
- এল ডেভিড ব্যারন, মোজিলা স্টাইল সিস্টেম ডকুমেন্টেশন
- ক্রিস ওয়াটারসন, এইচটিএমএল রিফ্লোতে নোট
- ক্রিস ওয়াটারসন, গেকো ওভারভিউ
- আলেকজান্ডার লারসন, একটি এইচটিএমএল এইচটিটিপি অনুরোধের জীবন
ওয়েবকিট
- ডেভিড হায়াট, সিএসএস বাস্তবায়ন (অংশ 1)
- ডেভিড হায়াত, ওয়েবকোরের একটি ওভারভিউ
- ডেভিড হায়াত, ওয়েবকোর রেন্ডারিং
- ডেভিড হায়াত, ফাউক সমস্যা
W3C স্পেসিফিকেশন
ব্রাউজারগুলি নির্দেশাবলী তৈরি করে
- ফায়ারফক্স। https://developer.mozilla.org/build_docamentation
- ওয়েবকিট। http://webkit.org/building/build.html
অনুবাদ
এই পৃষ্ঠাটি জাপানি ভাষায় অনুবাদ করা হয়েছে, দু'বার:
- ব্রাউজারগুলি কীভাবে কাজ করে - @ কোসেই দ্বারা আধুনিক ওয়েব ব্রাউজারগুলির (জেএ) এর পর্দার আড়ালে
- @(モダン ওয়েব @ @আইকেইকে 443 এবং @কিয়োটো 01 দ্বারা।
আপনি কোরিয়ান এবং তুর্কিদের বাহ্যিকভাবে হোস্ট করা অনুবাদগুলি দেখতে পারেন।
সবাইকে ধন্যবাদ!