
پشت صحنه مرورگرهای وب مدرن


پیشگفتار
این آغازگر جامع در مورد عملیات داخلی WebKit و Gecko نتیجه تحقیقات زیادی است که توسط توسعه دهنده اسرائیلی Tali Garsiel انجام شده است. در طی چند سال، او تمام داده های منتشر شده در مورد داخلی مرورگر را بررسی کرد و زمان زیادی را صرف خواندن کد منبع مرورگر وب کرد. او نوشت:
به عنوان یک توسعهدهنده وب، یادگیری اجزای داخلی عملیات مرورگر به شما کمک میکند تا تصمیمهای بهتری بگیرید و توجیهات پشت بهترین شیوههای توسعه را بدانید . در حالی که این یک سند نسبتا طولانی است، توصیه می کنیم مدتی را صرف کند و کاو در آن کنید. از این کار خوشحال خواهید شد.
Paul Irish, Chrome Developer Relations
مقدمه
مرورگرهای وب پرکاربردترین نرم افزارها هستند. در این پرایمر نحوه عملکرد آنها در پشت صحنه را توضیح می دهم. ما خواهیم دید که وقتی google.com در نوار آدرس تایپ می کنید چه اتفاقی می افتد تا زمانی که صفحه Google را در صفحه مرورگر مشاهده کنید.
مرورگرهایی که در مورد آنها صحبت خواهیم کرد
امروزه پنج مرورگر اصلی روی دسکتاپ استفاده می شود: کروم، اینترنت اکسپلورر، فایرفاکس، سافاری و اپرا. در موبایل، مرورگرهای اصلی عبارتند از مرورگر اندروید، آیفون، اپرا مینی و اپرا موبایل، مرورگر UC، مرورگرهای نوکیا S40/S60 و کروم که همه آنها به جز مرورگرهای اپرا بر پایه WebKit هستند. من مثال هایی از مرورگرهای منبع باز فایرفاکس و کروم و سافاری (که تا حدی منبع باز است) می زنم. طبق آمار StatCounter (تا ژوئن 2013)، کروم، فایرفاکس و سافاری حدود 71 درصد از مرورگرهای دسکتاپ جهانی را تشکیل می دهند. در تلفن همراه، مرورگر اندروید، آیفون و کروم حدود 54 درصد از استفاده را تشکیل می دهند.
عملکرد اصلی مرورگر
عملکرد اصلی یک مرورگر این است که منبع وب را که انتخاب می کنید، با درخواست از سرور و نمایش آن در پنجره مرورگر، ارائه دهد. منبع معمولاً یک سند HTML است، اما ممکن است یک PDF، تصویر یا نوع دیگری از محتوا نیز باشد. مکان منبع توسط کاربر با استفاده از URI (شناسه منبع یکسان) مشخص می شود.
نحوه تفسیر و نمایش فایل های HTML توسط مرورگر در مشخصات HTML و CSS مشخص شده است. این مشخصات توسط سازمان W3C (کنسرسیوم وب جهانی) که سازمان استانداردهای وب است حفظ می شود. برای سالها مرورگرها تنها با بخشی از مشخصات مطابقت داشتند و پسوندهای خود را توسعه دادند. این باعث مشکلات جدی سازگاری برای نویسندگان وب شد. امروزه اکثر مرورگرها کم و بیش با مشخصات مطابقت دارند.
رابط های کاربری مرورگرها شباهت های زیادی با یکدیگر دارند. از جمله عناصر رابط کاربری رایج عبارتند از:
- نوار آدرس برای درج URI
- دکمه های عقب و جلو
- گزینه های نشانک گذاری
- دکمه های بازخوانی و توقف برای بازخوانی یا توقف بارگیری اسناد فعلی
- دکمه صفحه اصلی که شما را به صفحه اصلی خود می برد
به اندازه کافی عجیب، رابط کاربری مرورگر در هیچ مشخصات رسمی مشخص نشده است، فقط از شیوه های خوب شکل گرفته در طول سال ها تجربه و با تقلید مرورگرها از یکدیگر ناشی می شود. مشخصات HTML5 عناصر رابط کاربری را که مرورگر باید داشته باشد تعریف نمی کند، اما برخی از عناصر رایج را فهرست می کند. از جمله آنها می توان به نوار آدرس، نوار وضعیت و نوار ابزار اشاره کرد. البته ویژگی هایی منحصر به فرد برای یک مرورگر خاص مانند مدیریت دانلود فایرفاکس وجود دارد.
زیرساخت های سطح بالا
اجزای اصلی مرورگر عبارتند از:
- رابط کاربری : این شامل نوار آدرس، دکمه برگشت/به جلو، منوی نشانه گذاری، و غیره است. هر قسمت از مرورگر به جز پنجره ای که صفحه درخواستی را می بینید، نمایش داده می شود.
- موتور مرورگر : اقدامات بین رابط کاربری و موتور رندر را به نمایش می گذارد.
- موتور رندر : مسئول نمایش محتوای درخواستی است. به عنوان مثال اگر محتوای درخواستی HTML باشد، موتور رندر HTML و CSS را تجزیه می کند و محتوای تجزیه شده را روی صفحه نمایش می دهد.
- شبکه سازی : برای تماس های شبکه مانند درخواست های HTTP، استفاده از پیاده سازی های مختلف برای پلتفرم های مختلف در پشت یک رابط مستقل از پلت فرم.
- باطن UI : برای ترسیم ویجت های اولیه مانند جعبه های ترکیبی و ویندوز استفاده می شود. این باطن یک رابط عمومی را نشان می دهد که مختص پلتفرم نیست. در زیر آن از روش های رابط کاربری سیستم عامل استفاده می کند.
- مفسر جاوا اسکریپت برای تجزیه و اجرای کد جاوا اسکریپت استفاده می شود.
- ذخیره سازی داده ها . این یک لایه ماندگاری است. ممکن است مرورگر نیاز به ذخیره انواع دادهها به صورت محلی داشته باشد، مانند کوکیها. مرورگرها همچنین از مکانیسم های ذخیره سازی مانند localStorage، IndexedDB، WebSQL و FileSystem پشتیبانی می کنند.
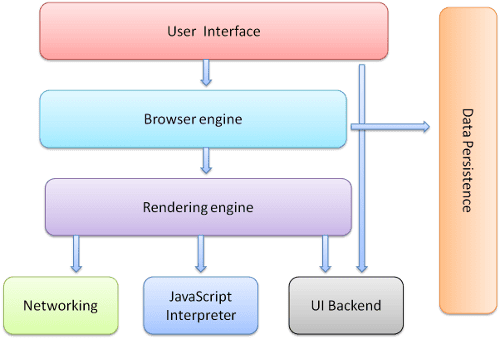
توجه به این نکته مهم است که مرورگرهایی مانند کروم چندین نمونه از موتور رندر را اجرا می کنند: یکی برای هر تب. هر تب در یک فرآیند جداگانه اجرا می شود.
موتورهای رندر
مسئولیت موتور رندر خوب است... رندر، یعنی نمایش محتوای درخواستی در صفحه مرورگر.
به طور پیش فرض موتور رندر می تواند اسناد و تصاویر HTML و XML را نمایش دهد. این می تواند انواع دیگری از داده ها را از طریق پلاگین یا افزونه نمایش دهد. به عنوان مثال، نمایش اسناد PDF با استفاده از یک افزونه نمایش PDF. با این حال، در این فصل ما بر روی مورد اصلی تمرکز خواهیم کرد: نمایش HTML و تصاویری که با استفاده از CSS فرمت شده اند.
مرورگرهای مختلف از موتورهای رندر متفاوتی استفاده می کنند: اینترنت اکسپلورر از Trident، فایرفاکس از Gecko، Safari از WebKit استفاده می کند. کروم و اپرا (از نسخه 15) از Blink، فورک WebKit استفاده می کنند.
WebKit یک موتور رندر متن باز است که به عنوان موتوری برای پلتفرم لینوکس شروع شد و توسط اپل برای پشتیبانی از مک و ویندوز اصلاح شد.
جریان اصلی
موتور رندر شروع به دریافت محتویات سند درخواستی از لایه شبکه می کند. این معمولاً در قطعات 8 کیلوبایتی انجام می شود.
پس از آن، این جریان اصلی موتور رندر است:

موتور رندر شروع به تجزیه سند HTML می کند و عناصر را به گره های DOM در درختی به نام "درخت محتوا" تبدیل می کند. موتور دادههای سبک را هم در فایلهای CSS خارجی و هم در عناصر سبک تجزیه میکند. اطلاعات سبک همراه با دستورالعمل های بصری در HTML برای ایجاد درخت دیگری استفاده می شود: درخت رندر .
درخت رندر شامل مستطیل هایی با ویژگی های بصری مانند رنگ و ابعاد است. مستطیل ها به ترتیبی هستند که روی صفحه نمایش داده می شوند.
پس از ساخت درخت رندر، فرآیند " layout " را طی می کند. این به این معنی است که به هر گره مختصات دقیق جایی که باید روی صفحه نمایش داده شود، بدهید. مرحله بعدی رنگ آمیزی است - درخت رندر پیمایش می شود و هر گره با استفاده از لایه باطن UI نقاشی می شود.
درک این نکته مهم است که این یک روند تدریجی است. برای تجربه کاربری بهتر، موتور رندر سعی می کند در اسرع وقت محتویات را روی صفحه نمایش دهد. قبل از شروع ساختن و چیدمان درخت رندر، منتظر نمی ماند تا تمام HTML تجزیه شود. بخشهایی از محتوا تجزیه و نمایش داده میشود، در حالی که این روند با بقیه مطالبی که از شبکه میآیند ادامه مییابد.
نمونه های جریان اصلی
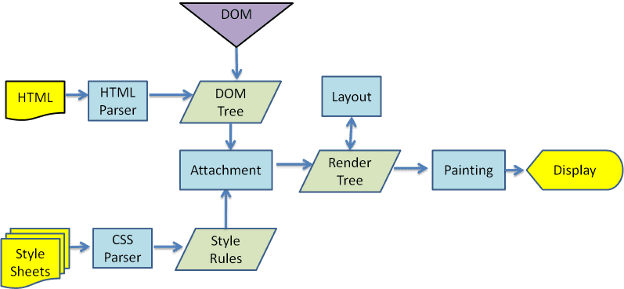
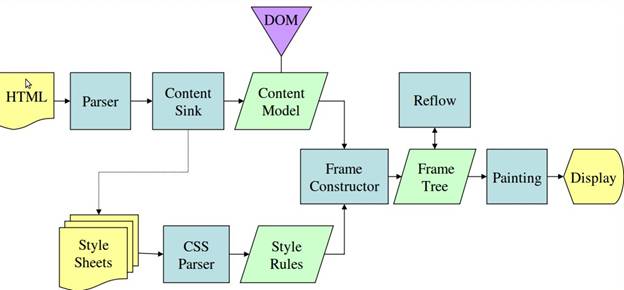
از شکلهای 3 و 4 میبینید که اگرچه WebKit و Gecko از اصطلاحات کمی متفاوت استفاده میکنند، جریان اساساً یکسان است.
Gecko درخت عناصر با فرمت بصری را "درخت قاب" می نامد. هر عنصر یک قاب است. WebKit از اصطلاح "Render Tree" استفاده می کند و از "Render Objects" تشکیل شده است. WebKit از اصطلاح "layout" برای قرار دادن عناصر استفاده می کند، در حالی که Gecko آن را "Reflow" می نامد. "ضمیمه" اصطلاح WebKit برای اتصال گره های DOM و اطلاعات بصری برای ایجاد درخت رندر است. یک تفاوت جزئی غیر معنایی این است که Gecko یک لایه اضافی بین HTML و درخت DOM دارد. به آن "حضور محتوا" می گویند و کارخانه ای برای ساخت عناصر DOM است. ما در مورد هر بخش از جریان صحبت خواهیم کرد:
تجزیه - عمومی
از آنجایی که تجزیه یک فرآیند بسیار مهم در موتور رندر است، ما کمی عمیق تر به آن خواهیم پرداخت. بیایید با یک مقدمه کوچک در مورد تجزیه شروع کنیم.
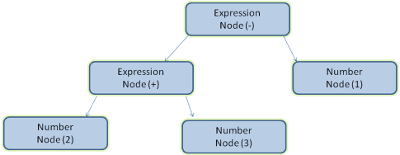
تجزیه یک سند به معنای ترجمه آن به ساختاری است که کد می تواند از آن استفاده کند. نتیجه تجزیه معمولاً درختی از گره ها است که ساختار سند را نشان می دهد. این درخت تجزیه یا درخت نحو نامیده می شود.
به عنوان مثال، تجزیه عبارت 2 + 3 - 1 می تواند این درخت را برگرداند:
گرامر
تجزیه بر اساس قوانین نحوی است که سند از آنها پیروی می کند: زبان یا قالبی که با آن نوشته شده است. هر قالبی که می توانید تجزیه کنید باید دارای دستور زبان قطعی متشکل از قواعد واژگان و نحو باشد. به آن گرامر آزاد متن می گویند. زبانهای انسانی چنین زبانهایی نیستند و بنابراین نمیتوان آنها را با تکنیکهای تجزیه مرسوم تجزیه کرد.
تجزیه کننده - ترکیب لکسر
تجزیه را می توان به دو فرآیند فرعی تقسیم کرد: تحلیل واژگانی و تحلیل نحو.
تحلیل واژگانی فرآیندی است که ورودی را به توکن ها تبدیل می کند. نشانه ها واژگان زبان هستند: مجموعه ای از بلوک های سازنده معتبر. در زبان انسان شامل تمام کلماتی است که در فرهنگ لغت برای آن زبان آمده است.
تحلیل نحوی به کارگیری قواعد نحوی زبان است.
تجزیهکنندهها معمولاً کار را بین دو جزء تقسیم میکنند: lexer (گاهی اوقات به آن نشانهساز میگویند) که مسئول شکستن ورودی به نشانههای معتبر است و تجزیهکنندهای که مسئول ساخت درخت تجزیه با تجزیه و تحلیل ساختار سند بر اساس قوانین نحوی زبان است.
lexer می داند که چگونه کاراکترهای نامربوط مانند فاصله های سفید و شکستن خط را از بین ببرد.
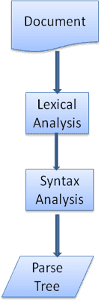
فرآیند تجزیه تکراری است. تجزیه کننده معمولاً از lexer یک نشانه جدید می خواهد و سعی می کند نشانه را با یکی از قوانین نحوی مطابقت دهد. اگر یک قانون مطابقت داشته باشد، یک گره مربوط به نشانه به درخت تجزیه اضافه می شود و تجزیه کننده توکن دیگری را می خواهد.
اگر هیچ قاعدهای مطابقت نداشته باشد، تجزیهکننده توکن را در داخل ذخیره میکند و به درخواست توکنها ادامه میدهد تا زمانی که قاعدهای مطابق با تمام نشانههای ذخیرهشده داخلی پیدا شود. اگر قاعده ای پیدا نشد، تجزیه کننده یک استثنا ایجاد می کند. این بدان معناست که سند معتبر نبوده و حاوی خطاهای نحوی است.
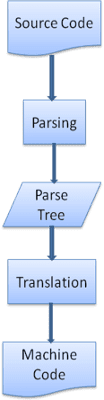
ترجمه
در بسیاری از موارد درخت تجزیه محصول نهایی نیست. تجزیه اغلب در ترجمه استفاده می شود: تبدیل سند ورودی به قالب دیگری. یک نمونه تلفیقی است. کامپایلری که کد منبع را به کد ماشین کامپایل می کند، ابتدا آن را به یک درخت تجزیه تجزیه می کند و سپس درخت را به یک سند کد ماشین ترجمه می کند.
نمونه تجزیه
در شکل 5 یک درخت تجزیه از یک عبارت ریاضی ساختیم. بیایید سعی کنیم یک زبان ریاضی ساده تعریف کنیم و روند تجزیه را ببینیم.
نحو:
- بلوک های ساختار نحو زبان عبارت ها، اصطلاحات و عملیات هستند.
- زبان ما می تواند شامل هر تعداد عبارت باشد.
- یک عبارت به عنوان یک "اصطلاح" به دنبال یک "عملیات" و بعد از یک اصطلاح دیگر تعریف می شود
- یک عملیات یک علامت مثبت یا یک علامت منفی است
- اصطلاح یک نشانه یا یک عبارت است
بیایید ورودی 2 + 3 - 1 را تجزیه و تحلیل کنیم.
اولین رشته فرعی که با یک قانون مطابقت دارد 2 است: طبق قانون شماره 5 این یک اصطلاح است. تطابق دوم 2 + 3 است: این با قانون سوم مطابقت دارد: اصطلاحی که عملیاتی به دنبال آن یک ترم دیگر است. مسابقه بعدی فقط در انتهای ورودی زده می شود. 2 + 3 - 1 یک عبارت است زیرا ما از قبل می دانیم که 2 + 3 یک جمله است، بنابراین ما یک اصطلاح داریم که بعد از آن یک عملیات به دنبال آن یک عبارت دیگر وجود دارد. 2 + + با هیچ قانونی مطابقت ندارد و بنابراین یک ورودی نامعتبر است.
تعاریف رسمی برای واژگان و نحو
واژگان معمولاً با عبارات منظم بیان می شود.
به عنوان مثال زبان ما به صورت زیر تعریف می شود:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
همانطور که می بینید، اعداد صحیح با یک عبارت منظم تعریف می شوند.
نحو معمولاً در قالبی به نام BNF تعریف می شود. زبان ما به صورت زیر تعریف خواهد شد:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
گفتیم که یک زبان می تواند توسط تجزیه کننده های معمولی تجزیه شود اگر دستور زبان آن یک گرامر بدون بافت باشد. یک تعریف شهودی از گرامر آزاد زمینه، دستور زبانی است که می تواند به طور کامل در BNF بیان شود. برای تعریف رسمی به مقاله ویکیپدیا در مورد گرامر بدون زمینه مراجعه کنید
انواع تجزیه کننده ها
دو نوع تجزیه کننده وجود دارد: تجزیه کننده از بالا به پایین و تجزیه کننده از پایین به بالا. یک توضیح شهودی این است که تجزیه کننده های بالا به پایین ساختار سطح بالای نحو را بررسی می کنند و سعی می کنند یک قانون مطابقت پیدا کنند. تجزیه کننده های پایین به بالا با ورودی شروع می شوند و به تدریج آن را به قوانین نحوی تبدیل می کنند، از قوانین سطح پایین شروع می شوند تا قوانین سطح بالا برآورده شوند.
بیایید ببینیم دو نوع تجزیه کننده چگونه مثال ما را تجزیه می کنند.
تجزیه کننده از بالا به پایین از قانون سطح بالاتر شروع می شود: 2 + 3 به عنوان یک عبارت شناسایی می کند. سپس 2 + 3 - 1 را به عنوان یک عبارت شناسایی می کند (فرایند شناسایی عبارت تکامل می یابد، با قوانین دیگر مطابقت دارد، اما نقطه شروع قانون بالاترین سطح است).
تجزیه کننده پایین به بالا ورودی را اسکن می کند تا زمانی که یک قانون مطابقت داشته باشد. سپس ورودی مطابق با قانون جایگزین می شود. این کار تا پایان ورودی ادامه خواهد داشت. عبارت تا حدی مطابقت شده در پشته تجزیه کننده قرار می گیرد.
این نوع تجزیه کننده از پایین به بالا، تجزیه کننده شیفت-کاهش نامیده می شود، زیرا ورودی به سمت راست منتقل می شود (تصور کنید یک اشاره گر ابتدا به شروع ورودی اشاره می کند و به سمت راست حرکت می کند) و به تدریج به قوانین نحوی کاهش می یابد.
تولید تجزیه کننده به صورت خودکار
ابزارهایی وجود دارند که می توانند تجزیه کننده تولید کنند. شما آنها را با دستور زبان خود تغذیه می کنید - واژگان و قواعد نحوی آن - و آنها یک تجزیه کننده فعال تولید می کنند. ایجاد یک تجزیه کننده نیاز به درک عمیق از تجزیه دارد و ایجاد یک تجزیه کننده بهینه شده با دست آسان نیست، بنابراین مولدهای تجزیه کننده می توانند بسیار مفید باشند.
WebKit از دو مولد تجزیه کننده معروف استفاده می کند: Flex برای ایجاد یک lexer و Bison برای ایجاد تجزیه کننده (ممکن است با نام های Lex و Yacc به آنها برخورد کنید). ورودی Flex فایلی است که شامل تعاریف عبارات منظم از نشانهها است. ورودی Bison قوانین نحو زبان در قالب BNF است.
تجزیه کننده HTML
وظیفه تجزیه کننده HTML تجزیه نشانه گذاری HTML به درخت تجزیه است.
گرامر HTML
واژگان و نحو HTML در مشخصات ایجاد شده توسط سازمان W3C تعریف شده است.
همانطور که در مقدمه تجزیه دیدیم، نحو گرامر را می توان به طور رسمی با استفاده از قالب هایی مانند BNF تعریف کرد.
متأسفانه همه موضوعات تجزیه کننده مرسوم در HTML اعمال نمی شوند (من آنها را فقط برای سرگرمی مطرح نکردم - آنها در تجزیه CSS و جاوا اسکریپت استفاده خواهند شد). HTML را نمی توان به راحتی توسط یک گرامر آزاد زمینه تعریف کرد که تجزیه کننده ها به آن نیاز دارند.
یک فرمت رسمی برای تعریف HTML وجود دارد - DTD (تعریف نوع سند) - اما یک گرامر آزاد از زمینه نیست.
این در نگاه اول عجیب به نظر می رسد. HTML بسیار نزدیک به XML است. تجزیه کننده های XML زیادی وجود دارد. یک نوع XML از HTML وجود دارد - XHTML - بنابراین تفاوت بزرگ چیست؟
تفاوت این است که رویکرد HTML بیشتر "بخشنده" است: به شما امکان می دهد تگ های خاصی را حذف کنید (که به طور ضمنی اضافه می شوند) یا گاهی اوقات تگ های شروع یا پایان و غیره را حذف کنید. در کل این یک نحو "نرم" است، برخلاف نحو سخت و سخت XML.
این جزئیات به ظاهر کوچک دنیای متفاوتی را ایجاد می کند. از یک طرف این دلیل اصلی محبوبیت HTML است: اشتباهات شما را می بخشد و زندگی را برای نویسنده وب آسان می کند. از طرفی نوشتن یک دستور زبان رسمی را دشوار می کند. بنابراین به طور خلاصه، HTML را نمی توان به راحتی توسط تجزیه کننده های معمولی تجزیه کرد، زیرا گرامر آن خالی از متن نیست. HTML توسط تجزیه کننده های XML قابل تجزیه نیست.
HTML DTD
تعریف HTML در قالب DTD است. این قالب برای تعریف زبان های خانواده SGML استفاده می شود. این قالب شامل تعاریفی برای همه عناصر مجاز، ویژگی ها و سلسله مراتب آنها است. همانطور که قبلا دیدیم، HTML DTD یک گرامر آزاد از متن را تشکیل نمی دهد.
تغییرات کمی از DTD وجود دارد. حالت سخت صرفاً با مشخصات مطابقت دارد، اما سایر حالت ها شامل پشتیبانی از نشانه گذاری مورد استفاده مرورگرها در گذشته هستند. هدف، سازگاری معکوس با محتوای قدیمی است. DTD دقیق فعلی اینجا است: www.w3.org/TR/html4/strict.dtd
DOM
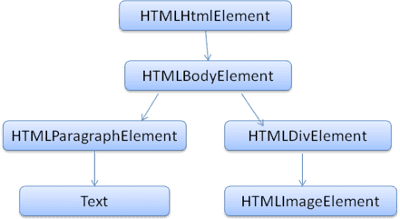
درخت خروجی ("درخت تجزیه") درختی از عنصر DOM و گره های ویژگی است. DOM مخفف Document Object Model است. این ارائه شی سند HTML و رابط عناصر HTML به دنیای خارج مانند جاوا اسکریپت است.
ریشه درخت شیء " سند " است.
DOM تقریباً یک رابطه یک به یک با نشانه گذاری دارد. به عنوان مثال:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
این نشانه گذاری به درخت DOM زیر ترجمه می شود:
مانند HTML، DOM توسط سازمان W3C مشخص شده است. www.w3.org/DOM/DOMTR را ببینید. این یک مشخصات عمومی برای دستکاری اسناد است. یک ماژول خاص عناصر خاص HTML را توصیف می کند. تعاریف HTML را میتوانید در اینجا پیدا کنید: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html .
وقتی میگویم درخت شامل گرههای DOM است، منظورم این است که درخت از عناصری ساخته شده است که یکی از رابطهای DOM را پیادهسازی میکنند. مرورگرها از پیاده سازی های مشخصی استفاده می کنند که دارای ویژگی های دیگری هستند که توسط مرورگر در داخل مورد استفاده قرار می گیرند.
الگوریتم تجزیه
همانطور که در بخش های قبلی دیدیم، HTML را نمی توان با استفاده از تجزیه کننده های معمولی بالا به پایین یا پایین به بالا تجزیه کرد.
دلایل آن عبارتند از:
- ماهیت بخشنده زبان.
- این واقعیت که مرورگرها تحمل خطای سنتی برای پشتیبانی از موارد شناخته شده HTML نامعتبر دارند.
- فرآیند تجزیه مجدد وارد می شود. برای زبانهای دیگر، منبع در طول تجزیه تغییر نمیکند، اما در HTML، کد پویا (مانند عناصر اسکریپت حاوی فراخوانهای
document.write()) میتواند نشانههای اضافی اضافه کند، بنابراین فرآیند تجزیه در واقع ورودی را تغییر میدهد.
مرورگرها قادر به استفاده از تکنیک های تجزیه معمولی نیستند، تجزیه کننده های سفارشی برای تجزیه HTML ایجاد می کنند.
الگوریتم تجزیه با مشخصات HTML5 به تفصیل شرح داده شده است . الگوریتم شامل دو مرحله است: نشانه گذاری و ساخت درخت.
توکنسازی، تحلیل واژگانی است که ورودی را به نشانهها تجزیه میکند. در میان نشانه های HTML، تگ های شروع، تگ های پایانی، نام ویژگی ها و مقادیر ویژگی ها هستند.
توکنایزر توکن را می شناسد، آن را به سازنده درخت می دهد و کاراکتر بعدی را برای تشخیص نشانه بعدی مصرف می کند و تا پایان ورودی به همین ترتیب ادامه می دهد.
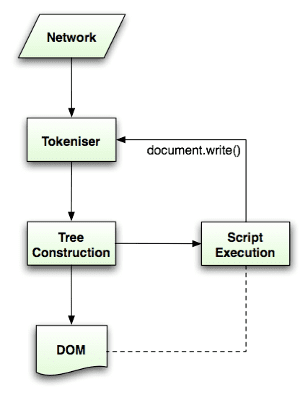
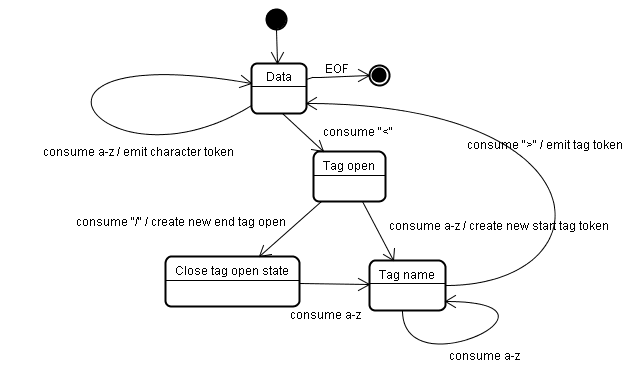
الگوریتم توکن سازی
خروجی الگوریتم یک توکن HTML است. الگوریتم به عنوان یک ماشین حالت بیان می شود. هر حالت یک یا چند کاراکتر از جریان ورودی را مصرف می کند و وضعیت بعدی را با توجه به آن کاراکترها به روز می کند. این تصمیم تحت تأثیر وضعیت نمادسازی فعلی و وضعیت ساخت درخت است. این بدان معناست که همان کاراکتر مصرف شده، بسته به وضعیت فعلی، نتایج متفاوتی را برای حالت بعدی صحیح به همراه خواهد داشت. الگوریتم برای توصیف کامل بسیار پیچیده است، بنابراین بیایید یک مثال ساده را ببینیم که به ما در درک اصل کمک می کند.
مثال اصلی - توکن کردن HTML زیر:
<html>
<body>
Hello world
</body>
</html>
حالت اولیه "وضعیت داده" است. هنگامی که با کاراکتر < مواجه میشوید، وضعیت به "Tag open state" تغییر میکند. مصرف یک کاراکتر az باعث ایجاد یک "Start tag token" می شود، وضعیت به "Tag name state" تغییر می کند. تا زمانی که کاراکتر > مصرف شود در این حالت می مانیم. هر کاراکتر به نام رمز جدید اضافه می شود. در مورد ما توکن ایجاد شده یک توکن html است.
وقتی به تگ > رسید، نشانه فعلی منتشر می شود و وضعیت به "وضعیت داده" تغییر می کند. تگ <body> نیز با همین مراحل درمان می شود. تا کنون تگ های html و body منتشر شده است. اکنون به "وضعیت داده" بازگشته ایم. مصرف کاراکتر H از Hello world باعث ایجاد و انتشار یک نشانه کاراکتر می شود، این کار تا رسیدن به < از </body> ادامه می یابد. ما برای هر شخصیت Hello world یک نشانه کاراکتر منتشر می کنیم.
اکنون به "حالت باز برچسب" بازگشته ایم. مصرف ورودی بعدی / باعث ایجاد یک end tag token و انتقال به "وضعیت نام برچسب" می شود. دوباره در این حالت می مانیم تا زمانی که به > برسیم. سپس نشانه تگ جدید منتشر می شود و به "وضعیت داده" برمی گردیم. با ورودی </html> مانند مورد قبلی رفتار می شود.
الگوریتم ساخت درخت
هنگامی که تجزیه کننده ایجاد می شود، شی Document ایجاد می شود. در مرحله ساخت درخت، درخت DOM با سند در ریشه آن اصلاح می شود و عناصر به آن اضافه می شود. هر گره منتشر شده توسط توکنایزر توسط سازنده درخت پردازش می شود. برای هر توکن، مشخصات مشخص میکند که کدام عنصر DOM مربوط به آن است و برای این توکن ایجاد میشود. عنصر به درخت DOM و همچنین پشته عناصر باز اضافه می شود. این پشته برای تصحیح عدم تطابق تودرتو و تگ های بسته نشده استفاده می شود. این الگوریتم همچنین به عنوان یک ماشین حالت توصیف می شود. حالت ها «حالت های درج» نامیده می شوند.
بیایید فرآیند ساخت درخت را برای ورودی مثال ببینیم:
<html>
<body>
Hello world
</body>
</html>
ورودی مرحله ساخت درخت، دنباله ای از نشانه ها از مرحله توکن سازی است. حالت اول "حالت اولیه" است. دریافت توکن "html" باعث انتقال به حالت "قبل از html" و پردازش مجدد رمز در آن حالت می شود. این باعث ایجاد عنصر HTMLHtmlElement می شود که به شی root Document اضافه می شود.
وضعیت به "قبل از سر" تغییر خواهد کرد. سپس نشانه "body" دریافت می شود. یک HTMLHeadElement به طور ضمنی ایجاد میشود، اگرچه ما یک نشانه "head" نداریم و به درخت اضافه میشود.
اکنون به حالت "in head" و سپس به "after head" می رویم. توکن بدنه دوباره پردازش میشود، یک HTMLBodyElement ایجاد و درج میشود و حالت به "in body" منتقل میشود.
نمادهای کاراکتر رشته "Hello world" اکنون دریافت شده است. اولین مورد باعث ایجاد و درج یک گره "متن" می شود و کاراکترهای دیگر به آن گره اضافه می شوند.
دریافت نشانه پایان بدنه باعث انتقال به حالت "after body" می شود. اکنون تگ پایان html را دریافت می کنیم که ما را به حالت "after after body" منتقل می کند. دریافت نشانه پایان فایل، تجزیه را پایان می دهد.
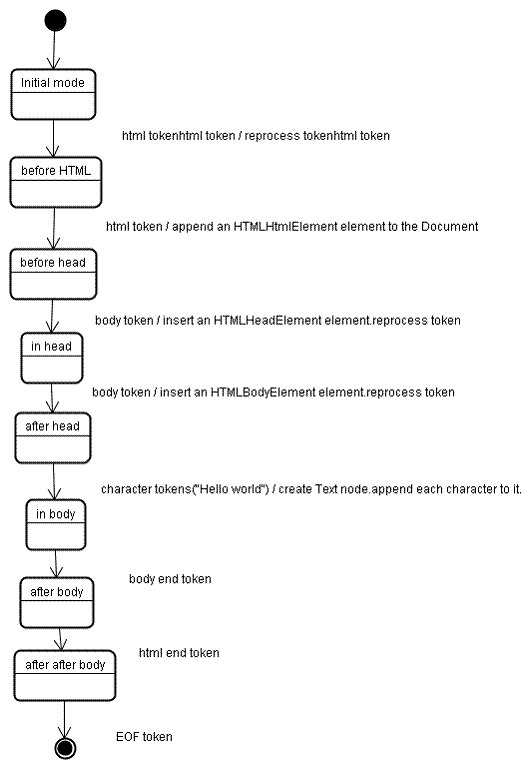
اقدامات زمانی که تجزیه به پایان رسید
در این مرحله، مرورگر سند را بهعنوان تعاملی علامتگذاری میکند و شروع به تجزیه اسکریپتهایی میکند که در حالت "به تعویق افتاده" هستند: آنهایی که باید پس از تجزیه سند اجرا شوند. سپس حالت سند روی "کامل" تنظیم می شود و رویداد "بار" فعال می شود.
می توانید الگوریتم های کامل برای توکن سازی و ساخت درخت را در مشخصات HTML5 مشاهده کنید.
تحمل خطای مرورگرها
شما هرگز خطای "Invalid Syntax" را در صفحه HTML دریافت نمی کنید. مرورگرها هرگونه محتوای نامعتبر را برطرف می کنند و ادامه می دهند.
برای مثال این HTML را در نظر بگیرید:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
من باید حدود یک میلیون قانون را نقض کرده باشم ("mytag" یک برچسب استاندارد نیست، تودرتو اشتباه عناصر "p" و "div" و موارد دیگر) اما مرورگر هنوز آن را به درستی نشان می دهد و شکایت نمی کند. بنابراین بسیاری از کدهای تجزیه کننده اشتباهات نویسنده HTML را رفع می کنند.
رسیدگی به خطا در مرورگرها کاملاً سازگار است، اما به طرز شگفت انگیزی بخشی از مشخصات HTML نبوده است. مانند نشانهگذاری و دکمههای عقب/ جلو، این فقط چیزی است که در طول سالها در مرورگرها توسعه یافته است. ساختارهای نامعتبر HTML وجود دارد که در بسیاری از سایتها تکرار میشوند، و مرورگرها سعی میکنند آنها را به روشی مطابق با سایر مرورگرها اصلاح کنند.
مشخصات HTML5 برخی از این الزامات را تعریف می کند. (WebKit این را به خوبی در نظر ابتدای کلاس تجزیه کننده HTML خلاصه می کند.)
تجزیه کننده ورودی توکن شده را در سند تجزیه می کند و درخت سند را ایجاد می کند. اگر سند به خوبی شکل گرفته باشد، تجزیه آن ساده است.
متأسفانه، ما مجبوریم بسیاری از اسناد HTML را مدیریت کنیم که به خوبی شکل نگرفته اند، بنابراین تجزیه کننده باید نسبت به خطاها مدارا کند.
ما باید حداقل از شرایط خطای زیر مراقبت کنیم:
- عنصری که اضافه می شود به صراحت در داخل برخی از برچسب های بیرونی ممنوع است. در این حالت باید تمام تگ ها را تا آن چیزی که عنصر را ممنوع می کند ببندیم و سپس آن را اضافه کنیم.
- ما مجاز به افزودن مستقیم عنصر نیستیم. ممکن است شخصی که سند را می نویسد برخی از برچسب ها را در این بین فراموش کرده باشد (یا اینکه تگ بین آن اختیاری است). این می تواند در مورد برچسب های زیر باشد: HTML HEAD BODY TBODY TR TD LI (آیا هیچ کدام را فراموش کردم؟).
- ما می خواهیم یک عنصر بلوک را در یک عنصر درون خطی اضافه کنیم. تمام عناصر درون خطی را تا عنصر بلوک بالاتر بعدی ببندید.
- اگر این کمکی نکرد، عناصر را ببندید تا زمانی که اجازه اضافه کردن عنصر را پیدا کنیم - یا تگ را نادیده بگیرید.
بیایید چند نمونه تحمل خطای WebKit را ببینیم:
</br> به جای <br>
برخی از سایت ها به جای <br> از </br> استفاده می کنند. به منظور سازگاری با اینترنت اکسپلورر و فایرفاکس، WebKit با این مورد مانند <br> رفتار می کند.
کد:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
توجه داشته باشید که رسیدگی به خطا داخلی است: به کاربر ارائه نخواهد شد.
یک میز سرگردان
میز ولگرد، جدولی است در داخل جدول دیگری، اما نه در داخل سلول جدول.
به عنوان مثال:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit سلسله مراتب را به دو جدول خواهر و برادر تغییر می دهد:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
کد:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit از یک پشته برای محتویات عنصر فعلی استفاده می کند: جدول داخلی را از پشته جدول بیرونی خارج می کند. اکنون میزها خواهر و برادر خواهند بود.
عناصر فرم تو در تو
در صورتی که کاربر فرمی را در فرم دیگری قرار دهد، فرم دوم نادیده گرفته می شود.
کد:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
سلسله مراتب تگ خیلی عمیق
کامنت برای خودش صحبت می کند.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
تگ های انتهایی html یا بدنه نابجا
باز هم - نظر برای خود صحبت می کند.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
بنابراین نویسندگان وب مراقب باشند - مگر اینکه بخواهید به عنوان نمونه در یک قطعه کد تحمل خطای WebKit ظاهر شوید - HTML خوب بنویسید.
تجزیه CSS
مفاهیم تجزیه را در مقدمه به خاطر دارید؟ خب، برخلاف HTML، CSS یک گرامر آزاد از زمینه است و میتواند با استفاده از انواع تجزیهکنندههایی که در مقدمه توضیح داده شد، تجزیه شود. در واقع مشخصات CSS گرامر واژگانی و نحوی CSS را تعریف می کند .
بیایید چند نمونه را ببینیم:
گرامر واژگانی (واژگان) با عبارات منظم برای هر نشانه تعریف می شود:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" مخفف identifier است، مانند نام کلاس. "name" یک شناسه عنصر است (که با "#" ارجاع می شود)
دستور زبان نحو در BNF توضیح داده شده است.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
توضیح:
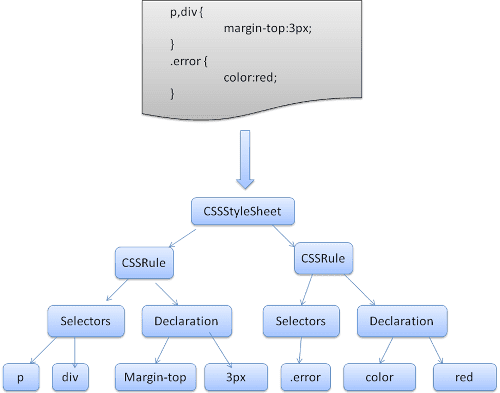
یک مجموعه قوانین این ساختار است:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error و a.error انتخابگر هستند. قسمت داخل بریس های فرفری حاوی قوانینی است که توسط این مجموعه قوانین اعمال می شود. این ساختار به طور رسمی در این تعریف تعریف شده است:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
این بدان معنی است که یک مجموعه قوانین یک انتخابگر یا به صورت اختیاری تعدادی انتخابگر است که با کاما و فاصله از هم جدا شده اند (S مخفف فضای سفید است). یک مجموعه قوانین شامل پرانتزهای فرفری و داخل آنها یک اعلان یا به صورت اختیاری تعدادی اعلان است که با یک نقطه ویرگول از هم جدا شده اند. "اعلامیه" و "انتخاب کننده" در تعاریف BNF زیر تعریف خواهند شد.
تجزیه کننده CSS WebKit
WebKit از ژنراتورهای تجزیه کننده Flex و Bison برای ایجاد تجزیه کننده به طور خودکار از فایل های دستور زبان CSS استفاده می کند. همانطور که از مقدمه تجزیه کننده به یاد می آورید، Bison یک تجزیه کننده کاهش شیفت از پایین به بالا ایجاد می کند. فایرفاکس از تجزیه کننده بالا به پایین استفاده می کند که به صورت دستی نوشته شده است. در هر دو مورد، هر فایل CSS در یک شیء StyleSheet تجزیه می شود. هر شی شامل قوانین CSS است. اشیاء قانون CSS حاوی اشیاء انتخابگر و اعلان و سایر اشیاء مربوط به دستور زبان CSS است.
پردازش سفارش برای اسکریپت ها و شیوه نامه ها
اسکریپت ها
مدل وب همگام است. نویسندگان انتظار دارند اسکریپت ها بلافاصله پس از رسیدن تجزیه کننده به تگ <script> تجزیه و اجرا شوند. تجزیه سند تا زمانی که اسکریپت اجرا نشود متوقف می شود. اگر اسکریپت خارجی است، ابتدا منبع باید از شبکه واکشی شود - این کار به صورت همزمان انجام می شود و تجزیه تا زمانی که منبع واکشی شود متوقف می شود. این مدل سالها بود و در مشخصات HTML4 و 5 نیز مشخص شده است. نویسندگان میتوانند صفت «defer» را به یک اسکریپت اضافه کنند، در این صورت تجزیه سند متوقف نمیشود و پس از تجزیه سند اجرا میشود. HTML5 گزینهای را برای علامتگذاری اسکریپت بهعنوان ناهمزمان اضافه میکند تا توسط یک رشته دیگر تجزیه و اجرا شود.
تجزیه نظری
هم WebKit و هم Firefox این بهینه سازی را انجام می دهند. در حین اجرای اسکریپت ها، رشته دیگری بقیه سند را تجزیه می کند و متوجه می شود که چه منابع دیگری باید از شبکه بارگیری شود و آنها را بارگذاری می کند. به این ترتیب می توان منابع را روی اتصالات موازی بارگذاری کرد و سرعت کلی بهبود یافت. توجه: تجزیه کننده حدسی فقط ارجاع به منابع خارجی مانند اسکریپت های خارجی، شیوه نامه ها و تصاویر را تجزیه می کند: درخت DOM را تغییر نمی دهد - که به تجزیه کننده اصلی واگذار می شود.
برگه های سبک
از طرف دیگر استایل شیت ها مدل متفاوتی دارند. از لحاظ مفهومی به نظر می رسد که از آنجایی که شیوه نامه ها درخت DOM را تغییر نمی دهند، دلیلی وجود ندارد که منتظر آنها باشیم و تجزیه سند را متوقف کنیم. با این حال، مشکلی وجود دارد که اسکریپت ها اطلاعات سبک را در مرحله تجزیه سند می خواهند. اگر استایل هنوز بارگذاری و تجزیه نشده باشد، اسکریپت پاسخ های اشتباه دریافت می کند و ظاهراً این باعث مشکلات زیادی شده است. به نظر می رسد یک مورد لبه است اما بسیار رایج است. فایرفاکس همه اسکریپت ها را وقتی که یک شیوه نامه وجود دارد که هنوز در حال بارگذاری و تجزیه است، مسدود می کند. WebKit تنها زمانی اسکریپت ها را مسدود می کند که سعی کنند به ویژگی های سبک خاصی دسترسی پیدا کنند که ممکن است توسط شیوه نامه های بارگیری نشده تحت تأثیر قرار گیرند.
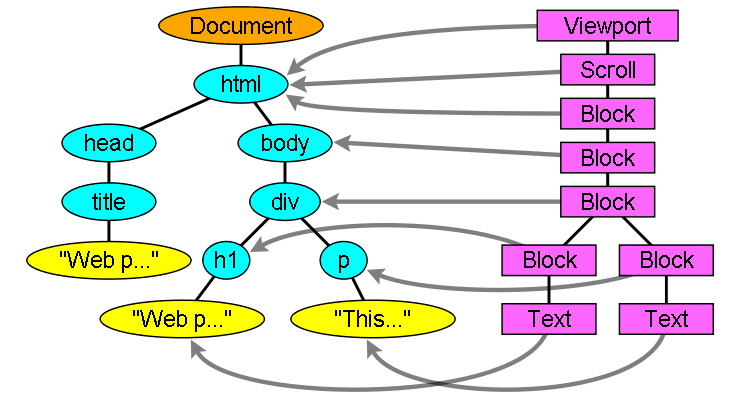
رندر ساخت و ساز درخت
در حالی که درخت DOM در حال ساخت است، مرورگر درخت دیگری به نام درخت رندر می سازد. این درخت از عناصر بصری به ترتیب نمایش داده می شود. این نمایش تصویری سند است. هدف این درخت این است که امکان رنگ آمیزی محتویات به ترتیب صحیح آنها را فراهم کند.
فایرفاکس عناصر موجود در درخت رندر را فریم می نامد. WebKit از اصطلاح renderer یا render object استفاده می کند.
یک رندر می داند چگونه خود و فرزندانش را چیدمان و نقاشی کند.
کلاس RenderObject WebKit، کلاس پایه رندرها، تعریف زیر را دارد:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
هر رندر نمایانگر یک ناحیه مستطیلی است که معمولاً مطابق با جعبه CSS یک گره است، همانطور که توسط مشخصات CSS2 توضیح داده شده است. این شامل اطلاعات هندسی مانند عرض، ارتفاع و موقعیت است.
نوع جعبه تحت تأثیر مقدار "نمایش" ویژگی سبک است که به گره مربوط می شود (به بخش محاسبه سبک مراجعه کنید). در اینجا کد WebKit برای تصمیم گیری در مورد اینکه چه نوع رندری باید برای یک گره DOM ایجاد شود، با توجه به ویژگی نمایش آمده است:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
نوع عنصر نیز در نظر گرفته می شود: به عنوان مثال، کنترل های فرم و جداول دارای قاب های خاص هستند.
در WebKit اگر عنصری بخواهد یک رندر ویژه ایجاد کند، متد createRenderer() لغو می کند. رندرها به اشیایی با سبک اشاره می کنند که حاوی اطلاعات غیر هندسی هستند.
رابطه درخت رندر با درخت DOM
رندرها با عناصر DOM مطابقت دارند، اما رابطه یک به یک نیست. عناصر DOM غیر بصری در درخت رندر درج نمی شوند. یک مثال عنصر "سر" است. همچنین عناصری که مقدار نمایش آنها به "none" اختصاص داده شده است، در درخت ظاهر نمی شوند (در حالی که عناصر با نمای "پنهان" در درخت ظاهر می شوند).
عناصر DOM وجود دارد که با چندین شیء بصری مطابقت دارد. اینها معمولاً عناصری با ساختار پیچیده هستند که با یک مستطیل قابل توصیف نیستند. به عنوان مثال، عنصر "انتخاب" سه رندر دارد: یکی برای ناحیه نمایش، یکی برای کادر لیست کشویی و دیگری برای دکمه. همچنین هنگامی که متن به چند خط شکسته می شود زیرا عرض برای یک خط کافی نیست، خطوط جدید به عنوان رندر اضافی اضافه می شوند.
نمونه دیگری از رندرهای متعدد، HTML شکسته است. طبق مشخصات CSS، یک عنصر درون خطی باید فقط شامل عناصر بلوک یا فقط عناصر درون خطی باشد. در مورد محتوای مختلط، رندرهای بلوک ناشناس برای بسته بندی عناصر درون خطی ایجاد خواهند شد.
برخی از اشیاء رندر با یک گره DOM مطابقت دارند اما در همان مکان درخت نیستند. شناورها و عناصر کاملاً قرار گرفته خارج از جریان هستند، در قسمت دیگری از درخت قرار می گیرند و به قاب واقعی نگاشت می شوند. قاب نگهدارنده مکان جایی است که باید میبودند.
جریان ساخت درخت
در فایرفاکس، ارائه به عنوان شنونده برای به روز رسانی های DOM ثبت می شود. ارائه ایجاد فریم را به FrameConstructor واگذار می کند و سازنده سبک را حل می کند (به محاسبه سبک مراجعه کنید) و یک فریم ایجاد می کند.
در WebKit به فرآیند حل استایل و ایجاد رندر «پیوست» می گویند. هر گره DOM دارای یک روش "اتصال" است. ضمیمه همزمان است ، درج گره به درخت DOM ، روش جدید "ضمیمه" را می خواند.
پردازش برچسب های HTML و بدن منجر به ساخت ریشه درخت رندر می شود. شیء رندر ریشه مطابق با آنچه مشخصات CSS را بلوک حاوی آن می نامد مطابقت دارد: بالای بلوک که حاوی تمام بلوک های دیگر است. ابعاد آن منظره است: ابعاد منطقه نمایشگر پنجره مرورگر. Firefox آن را ViewPortFrame می نامد و WebKit آن را RenderView می نامد. این شیء رندر است که سند به آن اشاره می کند. بقیه درخت به عنوان درج گره DOM ساخته شده است.
مشخصات CSS2 را در مدل پردازش مشاهده کنید.
محاسبه سبک
ساختن درخت رندر نیاز به محاسبه خصوصیات بصری هر شیء رندر دارد. این کار با محاسبه خصوصیات سبک هر عنصر انجام می شود.
این سبک شامل برگه های سبک با ریشه های مختلف ، عناصر سبک درون خطی و خصوصیات بصری در HTML (مانند خاصیت "bgcolor") است. بعداً به ویژگی های سبک CSS ترجمه می شود.
منشأ برگه های سبک ، برگه های سبک پیش فرض مرورگر ، برگه های سبک ارائه شده توسط نویسنده صفحه و برگه های سبک کاربر است - این برگه های سبک ارائه شده توسط کاربر مرورگر است (مرورگرها به شما اجازه می دهند سبک های مورد علاقه خود را تعریف کنید. در Firefox ، به عنوان مثال ، این کار با قرار دادن یک برگه سبک در پوشه "Firefox Profile") انجام می شود.
محاسبه سبک چند مشکل را به وجود می آورد:
- داده های سبک یک سازه بسیار بزرگ است و دارای ویژگی های بی شماری از سبک است ، این می تواند باعث ایجاد مشکلات حافظه شود.
یافتن قوانین تطبیق برای هر عنصر در صورت عدم بهینه سازی می تواند باعث ایجاد مشکلات عملکرد شود. عبور از لیست کل قانون برای هر عنصر برای یافتن مسابقات یک کار سنگین است. انتخاب کنندگان می توانند ساختار پیچیده ای داشته باشند که می تواند باعث شود روند تطبیق در مسیری به ظاهر امیدوار کننده شروع شود که اثبات می شود بیهوده است و باید مسیر دیگری را امتحان کرد.
به عنوان مثال - این انتخاب کننده ترکیب:
div div div div{ ... }به معنای این است که قوانین مربوط به
<div>که فرزندان 3 بخش است. فرض کنید می خواهید بررسی کنید که آیا این قانون برای یک عنصر<div>داده شده اعمال می شود یا خیر. شما یک مسیر خاص را برای بررسی درخت انتخاب می کنید. ممکن است لازم باشد که درخت گره را به سمت بالا طی کنید تا بدانید که فقط دو بخش وجود دارد و این قانون اعمال نمی شود. سپس باید مسیرهای دیگر را در درخت امتحان کنید.استفاده از قوانین شامل قوانین کاملاً پیچیده آبشار است که سلسله مراتب قوانین را تعریف می کند.
بیایید ببینیم که مرورگرها چگونه با این مسائل روبرو هستند:
به اشتراک گذاری داده های سبک
گره های WebKit اشیاء سبک (Renderstyle) را منابع ارجاع می دهند. این اشیاء را می توان در برخی شرایط توسط گره ها به اشتراک گذاشت. گره ها خواهر و برادر یا پسر عموی هستند و:
- عناصر باید در همان حالت موش قرار بگیرند (به عنوان مثال ، کسی نمی تواند در آن قرار بگیرد: شناور در حالی که دیگری نیست)
- هیچ یک از عناصر نباید شناسه داشته باشند
- نام های برچسب باید مطابقت داشته باشند
- ویژگی های کلاس باید مطابقت داشته باشند
- مجموعه ویژگی های نقشه برداری باید یکسان باشد
- ایالات پیوند باید مطابقت داشته باشند
- حالت های تمرکز باید مطابقت داشته باشند
- هیچ یک از عنصر نباید تحت تأثیر انتخاب کنندگان ویژگی قرار بگیرند ، جایی که تحت تأثیر قرار می گیرد که دارای هر مسابقه انتخابی است که از یک انتخاب کننده در هر موقعیتی در انتخاب کننده استفاده می کند
- نباید هیچ ویژگی سبک درون خطی بر روی عناصر وجود داشته باشد
- به هیچ وجه نباید انتخاب کننده خواهر و برادر استفاده شود. Webcore هنگامی که هر انتخاب کننده خواهر و برادر با آن روبرو می شود ، یک سوئیچ جهانی را به سادگی پرتاب می کند و به اشتراک گذاری سبک برای کل سند در هنگام حضور آنها غیرفعال می شود. این شامل + انتخاب کننده و انتخاب کننده هایی مانند: کودک اول و: آخرین کودک است.
درخت قانون فایرفاکس
Firefox برای محاسبه سبک آسانتر دو درخت اضافی دارد: درخت قانون و درخت متن. WebKit همچنین دارای اشیاء سبک است اما در درختی مانند درخت زمینه سبک ذخیره نمی شوند ، فقط گره DOM به سبک مربوطه خود اشاره می کند.
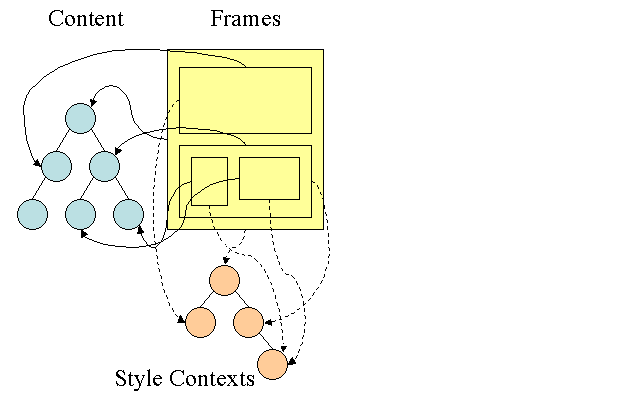
زمینه های سبک حاوی مقادیر نهایی هستند. مقادیر با استفاده از تمام قوانین تطبیق به ترتیب صحیح و انجام دستکاری هایی که آنها را از مقادیر منطقی به بتن تبدیل می کنند ، محاسبه می شوند. به عنوان مثال ، اگر مقدار منطقی درصدی از صفحه نمایش باشد ، محاسبه و به واحدهای مطلق تبدیل می شود. ایده درخت قانون واقعاً باهوش است. این امکان را برای به اشتراک گذاشتن این مقادیر بین گره ها فراهم می کند تا دوباره از محاسبه آنها جلوگیری شود. این همچنین باعث صرفه جویی در فضا می شود.
تمام قوانین همسان در یک درخت ذخیره می شوند. گره های پایین در یک مسیر اولویت بالاتری دارند. این درخت شامل تمام مسیرهای مربوط به مسابقات قانون است که یافت شده است. ذخیره قوانین تنبل انجام می شود. درخت در ابتدا برای هر گره محاسبه نمی شود ، اما هر زمان که یک سبک گره محاسبه شود ، مسیرهای محاسبه شده به درخت اضافه می شود.
ایده این است که مسیرهای درخت را به عنوان کلمات در یک واژگان ببینیم. بیایید بگوییم که ما قبلاً این درخت قانون را محاسبه کرده ایم:
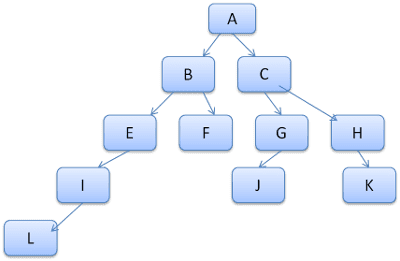
فرض کنید ما باید قوانین دیگری را در درخت محتوا مطابقت دهیم و دریابیم که قوانین همسان (به ترتیب صحیح) BEI هستند. ما قبلاً این مسیر را در درخت داریم زیرا قبلاً مسیر آبهیل را محاسبه کرده ایم. اکنون کار کمتری خواهیم داشت.
بیایید ببینیم که چگونه درخت کار ما را نجات می دهد.
تقسیم به ساختارها
زمینه های سبک به ساختارها تقسیم می شوند. این ساختارها حاوی اطلاعات سبک برای دسته خاصی مانند مرز یا رنگ هستند. تمام خواص موجود در یک ساختار یا به ارث رسیده یا به ارث رسیده است. خواص ارثی خواصی هستند که مگر اینکه توسط عنصر تعریف شود ، از والدین آن به ارث می برند. خصوصیات غیر ارثی (خواص "تنظیم مجدد") در صورت عدم تعریف از مقادیر پیش فرض استفاده می کنند.
این درخت با ذخیره کل ساختارها (حاوی مقادیر پایان محاسبه شده) در درخت به ما کمک می کند. ایده این است که اگر گره پایین تعریفی را برای یک ساختار ارائه ندهد ، می توان از یک ساختار ذخیره شده در یک گره فوقانی استفاده کرد.
محاسبه زمینه های سبک با استفاده از درخت قانون
هنگام محاسبه زمینه سبک برای یک عنصر خاص ، ابتدا مسیری را در درخت قانون محاسبه می کنیم یا از یک موجود موجود استفاده می کنیم. سپس ما شروع به اعمال قوانین در مسیر پر کردن ساختارها در متن سبک جدید خود می کنیم. ما از گره پایین مسیر شروع می کنیم - یکی با بالاترین برتری (معمولاً خاص ترین انتخاب) و درخت را تا زمانی که ساختار ما پر شود ، عبور می کنیم. اگر مشخصاتی برای ساختار در آن گره قاعده وجود نداشته باشد ، می توانیم تا حد زیادی بهینه سازی کنیم - تا زمانی که گره ای پیدا کنیم که آن را به طور کامل مشخص کند و به آن اشاره کند - این بهترین بهینه سازی است - کل ساختار مشترک است. این باعث محاسبه مقادیر پایان و حافظه می شود.
اگر تعاریف جزئی پیدا کنیم ، تا زمانی که ساختار پر شود ، از درخت بالا می رویم.
اگر ما هیچ تعاریفی برای ساختار خود پیدا نکردیم ، در صورتی که ساختار یک نوع "ارثی" باشد ، ما به ساختار والدین خود در درخت متن اشاره می کنیم. در این حالت ما نیز موفق به اشتراک گذاری ساختار شدیم. اگر این یک ساختار تنظیم مجدد باشد ، از مقادیر پیش فرض استفاده می شود.
اگر خاص ترین گره مقادیر اضافه کند ، ما باید برای تبدیل آن به مقادیر واقعی ، محاسبات اضافی انجام دهیم. سپس نتیجه را در گره درخت ذخیره می کنیم تا توسط کودکان قابل استفاده باشد.
در صورتی که یک عنصر خواهر و برادر یا یک برادر داشته باشد که به همان گره درخت اشاره می کند ، می توان کل زمینه سبک را بین آنها به اشتراک گذاشت.
بیایید مثالی را ببینیم: فرض کنید ما این HTML را داریم
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
و قوانین زیر:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
برای ساده کردن چیزها بیایید بگوییم که ما فقط باید دو ساختار را پر کنیم: ساختار رنگ و ساختار حاشیه. ساختار رنگ فقط شامل یک عضو است: رنگ ساختار حاشیه حاوی چهار طرف است.
درخت قانون حاصل به این شکل خواهد بود (گره ها با نام گره مشخص شده اند: تعداد قاعده ای که به آنها اشاره می کنند):
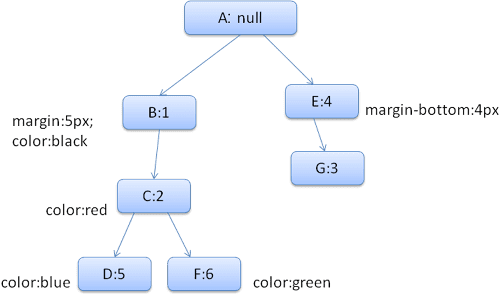
درخت زمینه به این شکل خواهد بود (نام گره: گره قاعده ای که به آنها اشاره می کنند):
فرض کنید ما HTML را تجزیه کرده و به برچسب دوم <div> می رسیم. ما باید یک زمینه سبک برای این گره ایجاد کنیم و ساختارهای سبک آن را پر کنیم.
ما با قوانین مطابقت خواهیم داشت و متوجه خواهیم شد که قوانین تطبیق برای <div> 1 ، 2 و 6 است. این بدان معنی است که در حال حاضر یک مسیر موجود در درخت وجود دارد که عنصر ما می تواند از آن استفاده کند و ما فقط باید برای قانون 6 (گره F در درخت قانون) گره دیگری به آن اضافه کنیم.
ما یک زمینه سبک ایجاد خواهیم کرد و آن را در درخت متن قرار خواهیم داد. زمینه سبک جدید به گره F در درخت قانون اشاره خواهد کرد.
اکنون باید ساختارهای سبک را پر کنیم. ما با پر کردن ساختار حاشیه شروع خواهیم کرد. از آنجا که آخرین گره قانون (F) به ساختار حاشیه اضافه نمی کند ، می توانیم از درخت بالا برویم تا زمانی که یک ساختار ذخیره شده را در یک درج گره قبلی محاسبه کنیم و از آن استفاده کنیم. ما آن را در گره B پیدا خواهیم کرد ، که بالاترین گره ای است که قوانین حاشیه مشخص شده است.
ما برای ساختار رنگ تعریفی داریم ، بنابراین نمی توانیم از یک ساختار ذخیره شده استفاده کنیم. از آنجا که رنگ یک ویژگی دارد ، ما برای پر کردن سایر ویژگی ها نیازی به بالا رفتن از درخت نداریم. ما مقدار نهایی (تبدیل رشته به RGB و غیره) را محاسبه می کنیم و ساختار محاسبه شده را روی این گره ذخیره می کنیم.
کار روی عنصر <span> دوم حتی ساده تر است. ما با قوانین مطابقت خواهیم داشت و به این نتیجه می رسیم که این امر به قانون G ، مانند دهانه قبلی اشاره دارد. از آنجا که ما خواهر و برادر داریم که به همان گره اشاره می کنند ، می توانیم کل زمینه را به اشتراک بگذاریم و فقط به متن دهانه قبلی اشاره کنیم.
برای ساختارهایی که حاوی قوانینی هستند که از والدین به ارث می برند ، ذخیره سازی روی درخت زمینه انجام می شود (خاصیت رنگ در واقع به ارث رسیده است ، اما Firefox آن را به عنوان تنظیم مجدد رفتار می کند و آن را بر روی درخت قانون ذخیره می کند).
به عنوان مثال ، اگر در یک پاراگراف قوانینی را برای قلم ها اضافه کنیم:
p {font-family: Verdana; font size: 10px; font-weight: bold}
سپس عنصر پاراگراف ، که فرزند Div در درخت متن است ، می توانست همان ساختار قلم را به عنوان والدین خود به اشتراک بگذارد. این در صورتی است که هیچ قانون قلم برای پاراگراف مشخص نشده است.
در WebKit ، که درخت قانون ندارد ، اعلامیه های همسان چهار بار طی می شوند. ابتدا از خصوصیات اولویت بالا غیر مهم استفاده می شود (خواصی که ابتدا باید اعمال شود زیرا دیگران به آنها وابسته هستند ، مانند نمایشگر) ، سپس با اولویت بالا مهم ، سپس اولویت عادی غیر مهم و سپس قوانین مهم اولویت عادی است. این بدان معنی است که خواصی که چندین بار به نظر می رسند مطابق دستور آبشار صحیح برطرف می شوند. آخرین برد
به طور خلاصه: به اشتراک گذاشتن اشیاء سبک (کاملاً یا برخی از ساختارهای داخل آنها) مسائل 1 و 3 را حل می کند. درخت قانون Firefox همچنین در استفاده از خواص به ترتیب صحیح کمک می کند.
دستکاری قوانین برای یک مسابقه آسان
چندین منبع برای قوانین سبک وجود دارد:
- قوانین CSS ، چه در برگه های سبک خارجی و چه در عناصر سبک.
css p {color: blue} - ویژگی های سبک درون خطی مانند
html <p style="color: blue" /> - ویژگی های بصری HTML (که به قوانین سبک مربوطه نقشه برداری می شوند)
html <p bgcolor="blue" />دو مورد آخر به راحتی با عنصر مطابقت دارند زیرا او صاحب ویژگی های سبک است و ویژگی های HTML را می توان با استفاده از عنصر به عنوان کلید نقشه برداری کرد.
همانطور که قبلاً در شماره شماره 2 ذکر شد ، مطابقت با قانون CSS می تواند پیچیده تر باشد. برای حل مشکل ، قوانین برای دسترسی آسان تر دستکاری می شوند.
طبق گفته انتخاب کننده ، قوانین پس از تجزیه برگه سبک ، به یکی از چندین نقشه هش اضافه می شوند. نقشه هایی از طریق شناسه ، با نام کلاس ، با نام برچسب و یک نقشه کلی برای هر چیزی که در آن دسته از دسته ها قرار نمی گیرد وجود دارد. اگر انتخاب کننده یک شناسه باشد ، این قانون به نقشه شناسه اضافه می شود ، اگر یک کلاس باشد ، به نقشه کلاس و غیره اضافه می شود.
این دستکاری باعث می شود مطابقت با قوانین بسیار ساده تر شود. نیازی به نگاه در هر اعلامیه نیست: ما می توانیم قوانین مربوطه را برای یک عنصر از نقشه ها استخراج کنیم. این بهینه سازی 95 ٪ از قوانین را از بین می برد ، به طوری که آنها حتی در طی فرآیند تطبیق نیز در نظر گرفته نشوند (4.1).
بیایید به عنوان مثال قوانین سبک زیر را ببینیم:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
قانون اول در نقشه کلاس وارد می شود. دوم به نقشه شناسه و سوم در نقشه برچسب.
برای قطعه HTML زیر ؛
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
ما ابتدا سعی خواهیم کرد قوانینی را برای عنصر P پیدا کنیم. نقشه کلاس حاوی یک کلید "خطا" است که طبق آن قانون "P.error" یافت می شود. عنصر DIV قوانین مربوطه را در نقشه شناسه (کلید شناسه) و نقشه برچسب دارد. بنابراین تنها کار باقی مانده این است که پیدا کردن کدام یک از قوانینی که توسط کلیدها استخراج شده اند مطابقت دارند.
به عنوان مثال اگر قانون برای DIV بود:
table div {margin: 5px}
هنوز هم از نقشه برچسب استخراج می شود ، زیرا کلید مناسب ترین انتخاب است ، اما با عنصر DIV ما مطابقت ندارد ، که یک اجداد جدول ندارد.
هر دو WebKit و Firefox این دستکاری را انجام می دهند.
سفارش آبشار ورق سبک
شیء سبک دارای خواص مربوط به هر ویژگی بصری (تمام ویژگی های CSS اما عمومی تر) است. اگر این ملک توسط هیچ یک از قوانین همسان تعریف نشده باشد ، می توان برخی از خصوصیات را توسط شیء سبک والدین به ارث برد. سایر خصوصیات دارای مقادیر پیش فرض هستند.
مشکل از زمانی شروع می شود که بیش از یک تعریف وجود داشته باشد - در اینجا دستور آبشار برای حل مسئله می آید.
اعلامیه ای برای یک ویژگی سبک می تواند در چندین برگه سبک و چندین بار در داخل یک برگه سبک ظاهر شود. این بدان معنی است که ترتیب اعمال قوانین بسیار مهم است. به این دستور "آبشار" گفته می شود. با توجه به مشخصات CSS2 ، دستور آبشار (از پایین تا زیاد) است:
- اعلامیه های مرورگر
- اعلامیه های عادی کاربر
- اعلامیه های عادی نویسنده
- اعلامیه های مهم نویسنده
- اعلامیه های مهم کاربر
اعلامیه های مرورگر کم اهمیت هستند و کاربر فقط در صورتی که اعلامیه به عنوان مهم مشخص شود ، نویسنده را نادیده می گیرد. اعلامیه ها با همان سفارش با ویژگی و سپس ترتیب مشخص شده آنها طبقه بندی می شوند. ویژگی های بصری HTML به تطبیق اعلامیه های CSS ترجمه شده است. آنها به عنوان قوانین نویسنده با اولویت پایین رفتار می شوند.
خاص بودن
ویژگی انتخاب توسط مشخصات CSS2 به شرح زیر تعریف شده است:
- تعداد 1 اگر اعلامیه از آن باشد ، یک ویژگی "سبک" است نه یک قاعده با یک انتخاب ، 0 در غیر این صورت (= a)
- تعداد ویژگی های شناسه را در انتخاب کننده حساب کنید (= b)
- تعداد سایر ویژگی ها و کلاس های شبه را در انتخاب کننده حساب کنید (= C)
- تعداد نام عناصر و عناصر شبه را در انتخاب کننده حساب کنید (= D)
هماهنگی چهار عدد ABCD (در یک سیستم شماره با یک پایه بزرگ) ویژگی را نشان می دهد.
شماره ای که باید استفاده کنید با بالاترین تعداد مورد نظر در یکی از دسته ها تعریف شده است.
به عنوان مثال ، اگر A = 14 می توانید از پایه شش ضلعی استفاده کنید. در مورد بعید که A = 17 به یک پایه شماره 17 رقمی نیاز دارید. وضعیت بعدی می تواند با انتخابی مانند این اتفاق بیفتد: HTML Body Div P… (17 برچسب در انتخاب شما ... خیلی محتمل نیست).
چند نمونه:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
مرتب سازی قوانین
پس از هماهنگی قوانین ، آنها طبق قوانین آبشار طبقه بندی می شوند. WebKit از نوع حباب برای لیست های کوچک و ادغام مرتب سازی برای موارد بزرگ استفاده می کند. WebKit با غلبه بر > اپراتور برای قوانین ، مرتب سازی را انجام می دهد:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
روند تدریجی
WebKit از پرچمی استفاده می کند که اگر تمام برگه های سبک سطح بالا (از جمله IMPORTS) بارگیری شود ، علامت گذاری می شود. اگر سبک هنگام اتصال به طور کامل بارگیری نشود ، از دارندگان مکان استفاده می شود و در سند مشخص می شود و پس از بارگیری ورق های سبک ، آنها را مجدداً محاسبه می شود.
طرح بندی
هنگامی که رندر ایجاد شده و به درخت اضافه می شود ، موقعیت و اندازه ندارد. محاسبه این مقادیر طرح یا بازتاب نامیده می شود.
HTML از یک مدل طرح بندی مبتنی بر جریان استفاده می کند ، به این معنی که بیشتر اوقات می توان هندسه را در یک پاس واحد محاسبه کرد. عناصر بعداً "در جریان" به طور معمول بر هندسه عناصری که زودتر "در جریان" هستند ، تأثیر نمی گذارد ، بنابراین طرح می تواند از طریق سند به سمت چپ به راست و بالا به پایین ادامه یابد. استثنائات وجود دارد: به عنوان مثال ، جداول HTML ممکن است به بیش از یک پاس نیاز داشته باشد.
سیستم مختصات نسبت به قاب ریشه است. از مختصات بالا و چپ استفاده می شود.
طرح یک فرآیند بازگشتی است. این در Root Renderer آغاز می شود ، که مطابق با عنصر <html> سند HTML است. چیدمان به صورت بازگشتی از طریق برخی یا همه سلسله مراتب فریم ادامه می یابد و اطلاعات هندسی را برای هر رندر که به آن نیاز دارد محاسبه می کند.
موقعیت رندر ریشه 0/0 و ابعاد آن منظره است - قسمت قابل مشاهده پنجره مرورگر.
همه رندرها از روش "طرح" یا "بازتاب" برخوردار هستند ، هر رندر از روش طرح بندی فرزندان خود استفاده می کند که به طرح نیاز دارند.
سیستم بیت کثیف
برای اینکه یک طرح کامل برای هر تغییر کوچک انجام ندهید ، مرورگرها از یک سیستم "بیت کثیف" استفاده می کنند. یک رندر که تغییر کرده یا اضافه شده است ، خود و فرزندان خود را به عنوان "کثیف" نشان می دهد: نیاز به طرح.
دو پرچم وجود دارد: "کثیف" و "کودکان کثیف هستند" به این معنی که اگرچه ممکن است خود رندر خوب باشد ، اما حداقل یک کودک دارد که به طرح نیاز دارد.
طرح جهانی و افزایشی
طرح را می توان در کل درخت رندر ایجاد کرد - این طرح "جهانی" است. این می تواند در نتیجه:
- یک تغییر سبک جهانی که مانند تغییر اندازه قلم ، بر همه رندرها تأثیر می گذارد.
- در نتیجه تغییر مکان صفحه نمایش
چیدمان می تواند افزایشی باشد ، فقط رندرهای کثیف ارائه می شوند (این می تواند برخی از آسیب ها را ایجاد کند که به طرح های اضافی نیاز دارد).
طرح افزایشی در هنگام کثیف بودن ارائه دهنده ها (به صورت ناهمزمان) ایجاد می شود. به عنوان مثال ، هنگامی که رندرهای جدید پس از آمدن محتوای اضافی از شبکه به درخت رندر پیوستند و به درخت DOM اضافه شد.
طرح ناهمزمان و همزمان
طرح افزایشی به صورت ناهمزمان انجام می شود. صف های Firefox "دستورات بازتاب" برای چیدمان های افزایشی و یک برنامه ریزی باعث اجرای دسته ای از این دستورات می شود. WebKit همچنین دارای تایمر است که یک طرح افزایشی را اجرا می کند - درخت عبور می کند و رندرهای "کثیف" از طرح خارج می شوند.
اسکریپت هایی که درخواست اطلاعات سبک می کنند ، مانند "Offsetheight" می توانند به طور همزمان طرح افزایشی را ایجاد کنند.
طرح جهانی معمولاً همزمان به صورت همزمان انجام می شود.
گاهی اوقات طرح به عنوان پاسخ به تماس پس از طرح اولیه ایجاد می شود زیرا برخی از ویژگی ها مانند موقعیت پیمایش تغییر می کنند.
بهینه سازی ها
هنگامی که یک طرح توسط "تغییر اندازه" یا تغییر در موقعیت رندر (و نه اندازه) ایجاد می شود ، اندازه های ارائه دهنده از حافظه نهان گرفته می شوند و محاسبه نمی شوند ...
در بعضی موارد فقط یک زیر درخت اصلاح شده و طرح از ریشه شروع نمی شود. این می تواند در مواردی اتفاق بیفتد که تغییر محلی باشد و محیط اطراف آن را تحت تأثیر قرار ندهد - مانند متن درج شده در قسمت های متن (در غیر این صورت هر کلید کلیدی باعث ایجاد طرح از ریشه می شود).
فرآیند چیدمان
طرح بندی معمولاً الگوی زیر را دارد:
- پدر و مادر رندر عرض خود را تعیین می کند.
- والدین بیش از کودکان می روند و:
- رندر کودک را قرار دهید (X و Y خود را تنظیم می کند).
- در صورت لزوم طرح کودک را فراخوانی می کند - آنها کثیف هستند یا ما در یک طرح جهانی هستیم یا به دلایل دیگری - که قد کودک را محاسبه می کند.
- والدین برای تعیین قد خود از ارتفاعات تجمع کودکان و ارتفاع حاشیه و بالشتک استفاده می کنند - این توسط والدین رندر والدین استفاده می شود.
- بیت کثیف خود را به دروغ تنظیم می کند.
Firefox از یک شیء "حالت" (NSHTMLReFlowState) به عنوان یک پارامتر برای طرح استفاده می کند (به نام "Reflow"). در میان دیگران ، دولت شامل عرض والدین است.
خروجی طرح Firefox یک شی "معیارها" است (NSHTMLReFlowMetrics). این شامل ارتفاع محاسبه شده رندر است.
محاسبه عرض
عرض رندر با استفاده از عرض بلوک کانتینر ، خاصیت "عرض" سبک رندر ، حاشیه ها و مرزها محاسبه می شود.
به عنوان مثال عرض div زیر:
<div style="width: 30%"/>
توسط WebKit به عنوان زیر محاسبه می شود (روش کلاس Renderbox CalcWidth):
- عرض کانتینر حداکثر ظروف موجود در عرض و 0 است. عرض موجود در این حالت ، عرضه محتوا است که به صورت محاسبه می شود:
clientWidth() - paddingLeft() - paddingRight()
ClientWidth و ClientHeight نمایانگر فضای داخلی یک شی به استثنای مرز و پیمایش است.
عرض عناصر ویژگی سبک "عرض" است. با محاسبه درصد عرض کانتینر به عنوان یک مقدار مطلق محاسبه می شود.
مرزها و بالشتک های افقی اکنون اضافه شده است.
تاکنون این محاسبه "عرض ترجیحی" بود. اکنون حداقل و حداکثر عرض محاسبه می شود.
اگر عرض مورد نظر بیشتر از حداکثر عرض باشد ، از حداکثر عرض استفاده می شود. اگر کمتر از حداقل عرض (کوچکترین واحد غیرقابل شکست) باشد ، از حداقل عرض استفاده می شود.
در صورت نیاز به طرح بندی ، مقادیر ذخیره می شوند ، اما عرض تغییر نمی کند.
شکستن خط
هنگامی که یک رندر در وسط یک طرح تصمیم می گیرد که نیاز به شکستن دارد ، رندر متوقف می شود و به والدین طرح می پردازد که نیاز به شکسته شدن دارد. والدین رندرهای اضافی را ایجاد می کنند و روی آنها چیدمان می کنند.
نقاشی
در مرحله نقاشی ، درخت رندر طی می شود و روش "رنگ ()" رندر برای نمایش محتوا روی صفحه نمایش داده می شود. نقاشی از مؤلفه زیرساخت UI استفاده می کند.
جهانی و افزایشی
مانند چیدمان ، نقاشی نیز می تواند جهانی باشد - کل درخت نقاشی شده است - یا افزایشی. در نقاشی افزایشی ، برخی از رندرها به شکلی تغییر می کنند که بر کل درخت تأثیر نمی گذارد. رندر تغییر یافته مستطیل خود را روی صفحه بی اعتبار می کند. این باعث می شود سیستم عامل آن را به عنوان "منطقه کثیف" ببیند و یک رویداد "رنگ" ایجاد کند. سیستم عامل این کار را هوشمندانه انجام می دهد و چندین منطقه را به یک منطقه می پیوندد. در کروم پیچیده تر است زیرا رندر در یک فرآیند متفاوت از روند اصلی قرار دارد. Chrome رفتار سیستم عامل را تا حدی شبیه سازی می کند. ارائه به این رویدادها گوش می دهد و پیام را به ریشه رندر واگذار می کند. درخت تا رسیدن به رندر مربوطه ، عبور می کند. این خود را دوباره رنگ آمیزی می کند (و معمولاً فرزندانش).
دستور نقاشی
CSS2 ترتیب روند نقاشی را تعریف می کند . این در واقع نظمی است که در آن عناصر در زمینه های انباشت جمع می شوند. این ترتیب بر نقاشی تأثیر می گذارد زیرا پشته ها از پشت به جلو نقاشی می شوند. ترتیب انباشت یک رندر بلوک:
- رنگ پس زمینه
- تصویر پس زمینه
- مرز
- کودکان
- طرح کلی
لیست نمایشگر Firefox
Firefox از بالای درخت رندر می رود و یک لیست نمایشگر برای مستطیل نقاشی شده ایجاد می کند. این شامل رندرهای مربوط به مستطیل شکل ، به ترتیب نقاشی مناسب (زمینه های رندر ، سپس مرزها و غیره) است.
به این ترتیب درخت باید به جای چندین بار ، فقط یک بار برای رنگ آمیزی عبور کند - نقاشی همه پس زمینه ها ، سپس همه تصاویر ، سپس همه مرزها و غیره.
Firefox فرایند را با اضافه کردن عناصری که پنهان می شوند ، مانند عناصر کاملاً در زیر سایر عناصر مات بهینه می کنند.
ذخیره مستطیل WebKit
قبل از تکرار ، WebKit مستطیل قدیمی را به عنوان یک مپ کوچک ذخیره می کند. سپس فقط دلتا بین مستطیل های جدید و قدیمی نقاشی می کند.
تغییرات پویا
مرورگرها سعی می کنند حداقل اقدامات ممکن را در پاسخ به تغییر انجام دهند. بنابراین تغییر در رنگ یک عنصر فقط باعث رنگ آمیزی عنصر می شود. تغییر در موقعیت عناصر باعث ایجاد طرح و رنگ آمیزی مجدد عنصر ، فرزندان آن و احتمالاً خواهر و برادر می شود. اضافه کردن یک گره DOM باعث ایجاد طرح و رنگ آمیزی گره می شود. تغییرات اساسی ، مانند افزایش اندازه قلم عنصر "HTML" ، باعث بی اعتبار شدن انبارها ، رله و رنگ آمیزی مجدد کل درخت می شود.
موضوعات موتور رندر
موتور رندر یک موضوع است. تقریباً همه چیز ، به جز عملیات شبکه ، در یک موضوع واحد اتفاق می افتد. در Firefox و Safari این نخ اصلی مرورگر است. در Chrome موضوع اصلی فرآیند برگه است.
عملیات شبکه را می توان با چندین موضوع موازی انجام داد. تعداد اتصالات موازی محدود است (معمولاً 2 - 6 اتصالات).
حلقه رویداد
موضوع اصلی مرورگر یک حلقه رویداد است. این یک حلقه بی نهایت است که روند را زنده نگه می دارد. منتظر وقایع (مانند چیدمان و وقایع نقاشی) است و آنها را پردازش می کند. این کد Firefox برای حلقه رویداد اصلی است:
while (!mExiting)
NS_ProcessNextEvent(thread);
مدل بصری CSS2
بوم
با توجه به مشخصات CSS2 ، اصطلاح بوم "فضایی را که ساختار قالب بندی در آن ارائه می شود" توصیف می کند: جایی که مرورگر محتوا را نقاشی می کند.
بوم برای هر بعد از فضا نامتناهی است اما مرورگرها بر اساس ابعاد دیدگاه ، عرض اولیه را انتخاب می کنند.
طبق گفته www.w3.org/tr/css2/zindex.html ، بوم در صورت موجود در دیگری شفاف است و در صورت عدم وجود یک مرورگر رنگ مشخص شده است.
مدل جعبه CSS
مدل CSS Box جعبه های مستطیلی را که برای عناصر موجود در درخت اسناد تولید می شود ، توصیف می کند و مطابق با مدل قالب بندی بصری قرار می گیرد.
هر جعبه دارای یک منطقه محتوا (به عنوان مثال متن ، یک تصویر و غیره) و قسمتهای اطراف آن ، حاشیه ، مرز و حاشیه است.
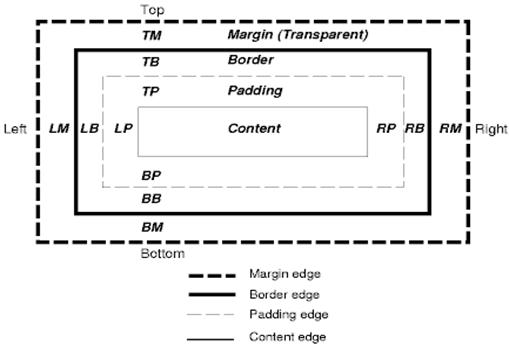
هر گره 0… چنین جعبه هایی تولید می کند.
همه عناصر دارای یک ویژگی "نمایش" هستند که نوع جعبه ای را که تولید می شود تعیین می کند.
مثال ها:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
پیش فرض درون خطی است اما برگه سبک مرورگر ممکن است پیش فرض های دیگر را تنظیم کند. به عنوان مثال: صفحه نمایش پیش فرض برای عنصر "Div" بلوک است.
شما می توانید یک مثال به سبک پیش فرض را در اینجا بیابید: www.w3.org/tr/css2/sample.html .
طرح موقعیت یابی
سه طرح وجود دارد:
- عادی: شیء با توجه به جایگاه خود در سند قرار می گیرد. این بدان معنی است که جای آن در درخت رندر مانند مکان آن در درخت DOM است و مطابق نوع و ابعاد جعبه آن قرار گرفته است
- شناور: ابتدا شیء مانند جریان عادی گذاشته می شود ، سپس تا حد امکان به سمت چپ یا راست حرکت می کند
- مطلق: شیء در درخت رندر در مکانی متفاوت از درخت DOM قرار می گیرد
طرح موقعیت یابی توسط ویژگی "موقعیت" و ویژگی "شناور" تنظیم شده است.
- استاتیک و نسبی باعث جریان طبیعی می شود
- مطلق و ثابت باعث موقعیت یابی مطلق
در موقعیت استاتیک هیچ موقعیتی تعریف نشده و از موقعیت پیش فرض استفاده می شود. در طرح های دیگر ، نویسنده موقعیت را مشخص می کند: بالا ، پایین ، چپ ، راست.
نحوه قرار دادن جعبه توسط:
- نوع جعبه
- ابعاد جعبه
- طرح موقعیت یابی
- اطلاعات خارجی مانند اندازه تصویر و اندازه صفحه نمایش
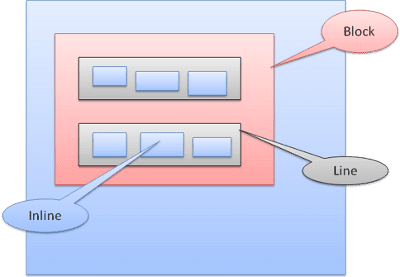
انواع جعبه
جعبه بلوک: یک بلوک را تشکیل می دهد - مستطیل خاص خود را در پنجره مرورگر دارد.

Inline Box: بلوک خاص خود را ندارد ، اما در داخل یک بلوک حاوی قرار دارد.
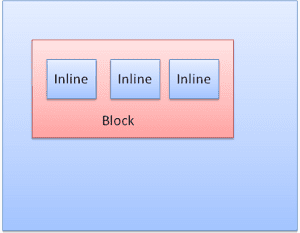
بلوک ها به صورت عمودی یکی پس از دیگری قالب بندی می شوند. خطوط به صورت افقی قالب بندی می شوند.
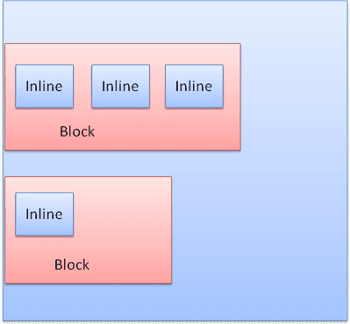
جعبه های درون خطی در داخل خطوط یا "جعبه های خط" قرار داده شده است. خطوط حداقل به اندازه بلندترین جعبه بلند هستند اما می توانند بلندتر باشند ، هنگامی که جعبه ها "پایه" تراز می شوند - به این معنی که قسمت پایین یک عنصر در نقطه ای از جعبه دیگر و همچنین پایین قرار می گیرد. اگر عرض کانتینر کافی نباشد ، خطوط در چندین خط قرار می گیرند. این معمولاً اتفاقی است که در یک پاراگراف رخ می دهد.
موقعیت یابی
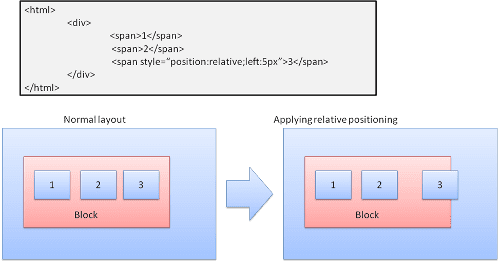
نسبی
موقعیت یابی نسبی - مانند معمول قرار گرفته و سپس توسط دلتا مورد نیاز حرکت می کند.
شناورها
یک جعبه شناور به سمت چپ یا راست یک خط منتقل می شود. ویژگی جالب این است که جعبه های دیگر در اطراف آن جریان دارند. HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
به نظر می رسد:

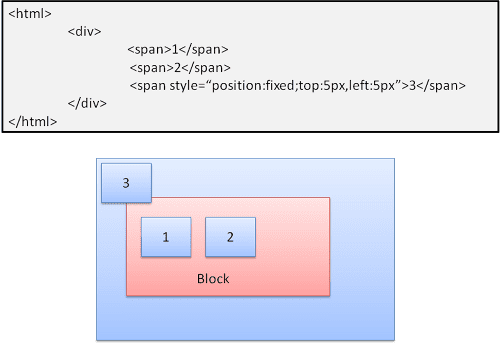
مطلق و ثابت
طرح دقیقاً بدون در نظر گرفتن جریان طبیعی تعریف شده است. این عنصر در جریان عادی شرکت نمی کند. ابعاد نسبت به ظرف است. در ثابت ، ظرف نمای است.
نمایندگی لایه ای
این توسط خاصیت Z-Index CSS مشخص شده است. این نشان دهنده ابعاد سوم جعبه است: موقعیت آن در امتداد "محور Z".
جعبه ها به پشته ها تقسیم می شوند (به نام زمینه های انباشت). در هر پشته ، عناصر پشتی ابتدا نقاشی می شوند و عناصر رو به جلو در بالا ، نزدیکتر به کاربر. در صورت همپوشانی ، عنصر مهمترین عنصر سابق را پنهان می کند.
پشته ها مطابق با خاصیت Z-Index سفارش داده می شوند. جعبه هایی با خاصیت "Z-Index" یک پشته محلی را تشکیل می دهند. منظره دارای پشته بیرونی است.
مثال:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
نتیجه این خواهد بود:

اگرچه قسمت قرمز قبل از رنگ سبز در نشانه گذاری است و قبلاً در جریان منظم نقاشی می شد ، اما خاصیت Z-Index بیشتر است ، بنابراین در پشته ای که توسط جعبه ریشه نگه داشته می شود ، جلوتر است.
منابع
معماری مرورگر
- گروسکورت ، آلن. معماری مرجع برای مرورگرهای وب (PDF)
- گوپتا ، تاک. چگونه مرورگرها کار می کنند - قسمت 1 - معماری
تجزیه
- Aho ، Sethi ، Ullman ، کامپایلرها: اصول ، تکنیک ها و ابزارها (با نام "کتاب اژدها") ، آدیسون-وسلی ، 1986
- ریک جلیف. The Bold and the Beautiful: دو پیش نویس جدید برای HTML 5.
فایرفاکس
- L. David Baron ، Faster HTML و CSS: Internal Engine Layout برای توسعه دهندگان وب.
- L. David Baron ، Faster HTML و CSS: Internal Engine Layout برای توسعه دهندگان وب (Google Tech Talk Video)
- L. دیوید بارون ، موتور طرح موزیلا
- L. دیوید بارون ، مستندات سیستم سبک موزیلا
- کریس واترسون ، یادداشت هایی در مورد بازتاب HTML
- کریس واترسون ، نمای کلی گکو
- الكساندر لارسون ، زندگی درخواست HTML HTTP
وب کیت
- دیوید هیات ، اجرای CSS (قسمت 1)
- دیوید هیات ، مروری بر وب سایت
- دیوید هیات ، ارائه وب سایت
- دیوید هیات ، مشکل FOUC
مشخصات W3C
مرورگرها دستورالعمل می سازند
ترجمه ها
این صفحه دو بار به ژاپنی ترجمه شده است:
- چگونه مرورگرها کار می کنند - پشت صحنه مرورگرهای وب مدرن (JA) توسط @ kosei
- ブラウザってどうやって動いてるの? (モダン وب ブラウザシーンの裏側توسط @ikeike443 و @ kiyoto01.
می توانید ترجمه های میزبان خارجی کره ای و ترکی را مشاهده کنید.
با تشکر از همه!