
Modern web tarayıcıların perde arkası


Önsöz
WebKit ve Gecko'nun dahili işlemleriyle ilgili bu kapsamlı giriş makalesi, İsrailli geliştirici Tali Garsiel tarafından yapılan kapsamlı bir araştırmanın sonucudur. Birkaç yıl boyunca tarayıcı iç işleyişiyle ilgili yayınlanan tüm verileri inceledi ve web tarayıcısı kaynak kodunu okumak için çok zaman harcadı. Şunu yazdı:
Web geliştiricisi olarak tarayıcı işlemlerinin iç işleyişini öğrenmek, daha iyi kararlar almanıza ve geliştirmeyle ilgili en iyi uygulamaların nedenlerini anlamanıza yardımcı olur. Bu doküman oldukça uzun olsa da biraz zaman ayırıp incelemenizi öneririz. Bunu yaptığınızdan memnun olacaksınız.
Paul Irish, Chrome Geliştirici İlişkileri
Giriş
Web tarayıcıları en yaygın kullanılan yazılımlardır. Bu giriş niteliğindeki makalede, bu araçların perde arkasında nasıl çalıştığını açıklayacağım. Tarayıcı ekranında Google sayfasını görene kadar adres çubuğuna google.com yazdığınızda ne olacağını göreceğiz.
Konuşacağımız tarayıcılar
Günümüzde masaüstünde kullanılan beş ana tarayıcı vardır: Chrome, Internet Explorer, Firefox, Safari ve Opera. Mobil cihazlarda kullanılan başlıca tarayıcılar Android Tarayıcı, iPhone, Opera Mini ve Opera Mobile, UC Tarayıcı, Nokia S40/S60 tarayıcıları ve Chrome'dur. Opera tarayıcıları hariç bunların tümü WebKit'e dayanır. Açık kaynaklı Firefox ve Chrome tarayıcılarından ve kısmen açık kaynaklı Safari'den örnekler vereceğim. StatCounter istatistiklerine (Haziran 2013 itibarıyla) göre Chrome, Firefox ve Safari, dünya genelindeki masaüstü tarayıcı kullanımının yaklaşık% 71'ini oluşturuyor. Mobil cihazlarda Android Tarayıcı, iPhone ve Chrome'un kullanımının yaklaşık% 54'ü bu tarayıcılara aittir.
Tarayıcının ana işlevi
Bir tarayıcının ana işlevi, seçtiğiniz web kaynağını sunucudan isteyip tarayıcı penceresinde göstermektir. Kaynak genellikle bir HTML belgesidir ancak PDF, resim veya başka bir içerik türü de olabilir. Kaynağın konumu, kullanıcı tarafından URI (Tekdüzen Kaynak Tanımlayıcısı) kullanılarak belirtilir.
Tarayıcının HTML dosyalarını yorumlama ve görüntüleme şekli, HTML ve CSS spesifikasyonlarında belirtilir. Bu spesifikasyonlar, web'in standartlar kuruluşu olan W3C (World Wide Web Consortium) tarafından yönetilir. Tarayıcılar yıllarca spesifikasyonların yalnızca bir kısmına uyuyor ve kendi uzantılarını geliştiriyordu. Bu durum, web yazarları için ciddi uyumluluk sorunlarına neden oldu. Günümüzde çoğu tarayıcı bu spesifikasyonlara az çok uygundur.
Tarayıcı kullanıcı arayüzlerinin birbirleriyle çok ortak noktası vardır. Yaygın kullanıcı arayüzü öğeleri arasında şunlar yer alır:
- URI eklemek için adres çubuğu
- Geri ve ileri düğmeleri
- Yer işareti seçenekleri
- Mevcut dokümanların yenilenmesi veya yüklemesinin durdurulması için yenile ve durdur düğmeleri
- Ana sayfanıza götüren ana sayfa düğmesi
Tuhaf bir şekilde, tarayıcının kullanıcı arayüzü herhangi bir resmi spesifikasyonda belirtilmemiştir. Bu arayüz, yıllar süren deneyimler ve tarayıcıların birbirini taklit etmesi sonucunda ortaya çıkan iyi uygulamalardan oluşur. HTML5 spesifikasyonu, bir tarayıcıda bulunması gereken kullanıcı arayüzü öğelerini tanımlamaz ancak bazı yaygın öğeleri listeler. Bunlar arasında adres çubuğu, durum çubuğu ve araç çubuğu bulunur. Elbette Firefox'un indirme yöneticisi gibi belirli bir tarayıcıya özgü özellikler de vardır.
Üst düzey altyapı
Tarayıcının ana bileşenleri şunlardır:
- Kullanıcı arayüzü: Adres çubuğu, geri/ileri düğmesi, yer işareti menüsü vb. istenen sayfayı gördüğünüz pencere hariç tarayıcı ekranının her bölümü.
- Tarayıcı motoru: Kullanıcı arayüzü ile oluşturma motoru arasındaki işlemleri düzenler.
- Oluşturma motoru: İstenen içeriği göstermekten sorumludur. Örneğin, istenen içerik HTML ise oluşturma motoru HTML ve CSS'yi ayrıştırır ve ayrıştırılan içeriği ekranda gösterir.
- Ağ: Platformdan bağımsız bir arayüzün arkasında farklı platformlar için farklı uygulamalar kullanılarak HTTP istekleri gibi ağ çağrıları için.
- Kullanıcı arayüzü arka ucu: Açılır listeler ve pencereler gibi temel widget'ları çizmek için kullanılır. Bu arka uç, platforma özgü olmayan genel bir arayüz sunar. Alt katmanlarda işletim sistemi kullanıcı arayüzü yöntemleri kullanılır.
- JavaScript yorumlayıcısı. JavaScript kodunu ayrıştırmak ve yürütmek için kullanılır.
- Veri depolama. Bu, bir kalıcılık katmanıdır. Tarayıcının çerezler gibi her türlü veriyi yerel olarak kaydetmesi gerekebilir. Tarayıcılar, localStorage, IndexedDB, WebSQL ve FileSystem gibi depolama mekanizmalarını da destekler.
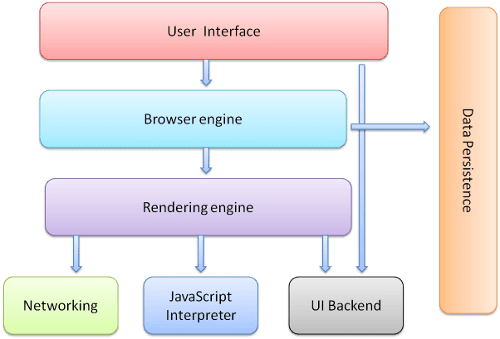
Chrome gibi tarayıcıların, her sekme için bir tane olmak üzere birden fazla oluşturma motoru örneği çalıştırdığını unutmayın. Her sekme ayrı bir işlemde çalışır.
Oluşturma motorları
Oluşturma motorunun sorumluluğu, istenen içeriklerin tarayıcı ekranında gösterilmesidir.
Oluşturma motoru varsayılan olarak HTML ve XML dokümanlarını ve resimlerini görüntüleyebilir. Eklentiler veya uzantılar aracılığıyla diğer veri türlerini de görüntüleyebilir. Örneğin, PDF görüntüleyici eklentisi kullanarak PDF belgelerini görüntüleyebilir. Ancak bu bölümde ana kullanım alanına odaklanacağız: CSS kullanılarak biçimlendirilmiş HTML ve resimleri görüntüleme.
Farklı tarayıcılar farklı oluşturma motorları kullanır: Internet Explorer Trident, Firefox Gecko, Safari WebKit kullanır. Chrome ve Opera (15 sürümünden itibaren), WebKit'in bir çatalı olan Blink'i kullanır.
WebKit, Linux platformu için bir motor olarak başlayan ve Apple tarafından Mac ile Windows'u desteklemek için değiştirilen açık kaynak bir oluşturma motorudur.
Ana akış
Oluşturma motoru, istenen dokümanın içeriğini ağ katmanından almaya başlar. Bu işlem genellikle 8 KB'lık parçalar halinde yapılır.
Ardından, oluşturma motorunun temel akışı şu şekildedir:

Oluşturma motoru, HTML dokümanını ayrıştırmaya başlar ve öğeleri "içerik ağacı" adı verilen bir ağaçtaki DOM düğümlerine dönüştürür. Motor, hem harici CSS dosyalarındaki hem de stil öğelerindeki stil verilerini ayrıştırır. HTML'deki görsel talimatlarla birlikte stil bilgileri, başka bir ağaç oluşturmak için kullanılır: oluşturma ağacı.
Oluşturma ağacı, renk ve boyutlar gibi görsel özelliklere sahip dikdörtgenler içerir. Dikdörtgenler ekranda gösterilecek şekilde doğru sıradadır.
Oluşturma ağacı oluşturulduktan sonra "düzenleme" işlemine girer. Yani her düğüme ekranda görünmesi gereken tam koordinatları vermeniz gerekir. Sonraki aşama boyama işlemidir. Oluşturma ağacı taranacak ve her düğüm, kullanıcı arayüzü arka uç katmanı kullanılarak boyanacaktır.
Bu sürecin kademeli olduğunu anlamanız önemlidir. Oluşturma motoru, daha iyi bir kullanıcı deneyimi için içeriği mümkün olan en kısa sürede ekranda göstermeye çalışır. Oluşturma ağacını oluşturmaya ve biçimlendirmeye başlamadan önce tüm HTML'nin ayrıştırılmasını beklemez. İçeriğin bazı bölümleri ayrıştırılıp gösterilirken işlem, ağdan gelen diğer içeriklerle devam eder.
Ana akış örnekleri
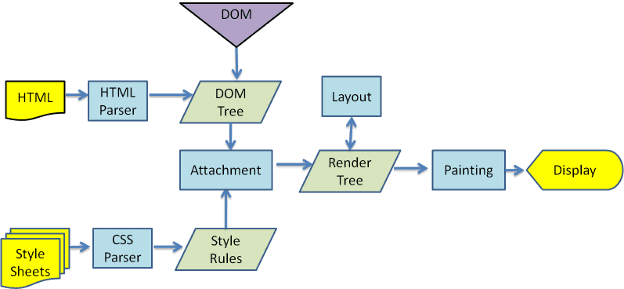
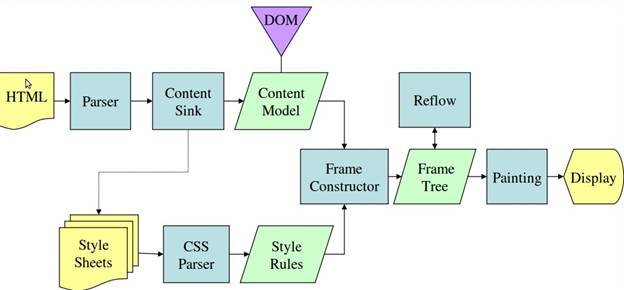
3. ve 4. resimlerde, WebKit ve Gecko'nun biraz farklı terminolojiler kullanmasına rağmen akışın temelde aynı olduğunu görebilirsiniz.
Gecko, görsel olarak biçimlendirilmiş öğelerin ağacını "Çerçeve ağacı" olarak adlandırır. Her öğe bir çerçevedir. WebKit, "Oluşturma Ağacı" terimini kullanır ve "Oluşturma Nesneleri"nden oluşur. WebKit, öğelerin yerleştirilmesi için "düzenleme" terimini kullanırken Gecko bunu "yeniden akış" olarak adlandırır. "Ek", WebKit'in oluşturma ağacı oluşturmak için DOM düğümlerini ve görsel bilgileri bağlamak için kullandığı terimdir. Semantik olmayan küçük bir fark, Gecko'nun HTML ile DOM ağacı arasında ekstra bir katmana sahip olmasıdır. "İçerik havuzu" olarak adlandırılan bu öğe, DOM öğeleri oluşturmaya yönelik bir fabrikadır. Akıştaki her bir bölümden bahsedeceğiz:
Ayrıştırma - genel
Ayrıştırma, oluşturma motorunda çok önemli bir işlem olduğundan bu konuyu biraz daha ayrıntılı olarak ele alacağız. Ayrıştırma hakkında kısa bir girişle başlayalım.
Bir dokümanı ayrıştırmak, dokümanı kodun kullanabileceği bir yapıya çevirmektir. Ayrıştırmanın sonucu genellikle dokümanın yapısını temsil eden bir düğüm ağacıdır. Buna ayrıştırma ağacı veya söz dizimi ağacı denir.
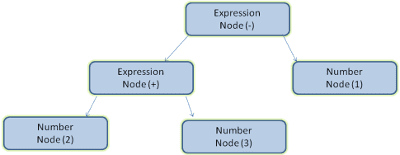
Örneğin, 2 + 3 - 1 ifadesi ayrıştırıldığında şu ağaç döndürülebilir:
Dilbilgisi
Ayrıştırma işlemi, belgenin uyduğu söz dizimi kurallarına (yazıldığı dil veya biçim) dayanır. Ayrıştırabileceğiniz her biçimin, kelime hazinesi ve söz dizimi kuralları içeren belirlenebilir bir dil bilgisine sahip olması gerekir. Buna bağlamdan bağımsız dil bilgisi denir. İnsan dilleri bu tür diller olmadığından geleneksel ayrıştırma teknikleriyle ayrıştırılamaz.
Ayrıştırıcı - Söz dizimi analizörü kombinasyonu
Ayrıştırma işlemi, iki alt sürece ayrılabilir: söz dizimi analizi ve söz dizimi analizi.
Sözcük analizi, girişin jetonlara bölünmesi işlemidir. Jetonlar, geçerli yapı taşlarının bir araya getirilmesiyle oluşan dil kelime hazinesidir. Bu dil için sözlükte yer alan tüm kelimelerden oluşur.
Söz dizimi analizi, dil söz dizimi kurallarının uygulanmasıdır.
Ayrıştırıcılar genellikle işi iki bileşen arasında böler: Giriş karakter dizisini geçerli jetonlara bölme sorumlusu olan token ayırıcı (bazen jeton dizilici olarak da adlandırılır) ve belge yapısını dil söz dizimi kurallarına göre analiz ederek ayrıştırma ağacını oluşturmaktan sorumlu olan ayrıştırıcı.
Ayrıştırıcı, boşluklar ve satır sonları gibi alakasız karakterleri nasıl kaldıracağını bilir.
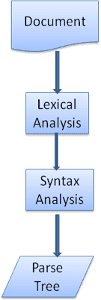
Ayrıştırma işlemi yinelemeli bir süreçtir. Ayrıştırıcı genellikle dize ayrıştırıcıdan yeni bir jeton ister ve jetonu söz dizimi kurallarından biriyle eşleştirmeye çalışır. Bir kural eşleşirse jetona karşılık gelen bir düğüm ayrıştırma ağacına eklenir ve ayrıştırıcı başka bir jeton ister.
Hiçbir kural eşleşmezse ayrıştırıcı, jetonu dahili olarak depolar ve dahili olarak depolanan tüm jetonlarla eşleşen bir kural bulunana kadar jeton istemeye devam eder. Hiçbir kural bulunmazsa ayrıştırıcı bir istisna oluşturur. Bu durum, belgenin geçerli olmadığı ve söz dizimi hataları içerdiği anlamına gelir.
Çeviri
Çoğu durumda, ayrıştırma ağacı nihai ürün değildir. Ayrıştırma, çeviride sıklıkla kullanılır: Giriş dokümanı başka bir biçime dönüştürülür. Derleme buna örnek gösterilebilir. Kaynak kodunu makine koduna derleyen derleyici, önce kodu bir ayrıştırma ağacına ayırır, ardından ağacı bir makine kodu belgesine çevirir.
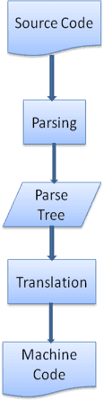
Ayrıştırma örneği
5. resimde, matematiksel bir ifadeden bir ayrıştırma ağacı oluşturduk. Basit bir matematik dili tanımlayıp ayrıştırma işlemini inceleyelim.
Söz dizimi:
- Dil söz dizimi yapı taşları ifadeler, terimler ve işlemlerdir.
- Dilimiz herhangi bir sayıda ifade içerebilir.
- Bir ifade, "terim", ardından "işlem" ve ardından başka bir terim olarak tanımlanır.
- İşlem, artı veya eksi jetondur.
- Terim, tam sayı jetonu veya ifadedir
2 + 3 - 1 girişini analiz edelim.
Bir kuralla eşleşen ilk alt dize 2'tür: 5. kurala göre bu bir terimdir.
İkinci eşleme 2 + 3: Bu, üçüncü kuralla eşleşir: Bir terimin ardından bir işlem ve ardından başka bir terim.
Sonraki eşleme yalnızca girişin sonunda gerçekleşir.
2 + 3 bir terim olduğu için 2 + 3 - 1 bir ifadedir. Dolayısıyla, bir terimin ardından bir işlem ve ardından başka bir terimimiz var.
2 + + hiçbir kuralla eşleşmez ve bu nedenle geçersiz bir giriştir.
Sözlük ve söz dizimi için resmi tanımlar
Kelime dağarcığı genellikle normal ifadelerle ifade edilir.
Örneğin, dilimiz şu şekilde tanımlanır:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Gördüğünüz gibi, tam sayılar normal ifadeyle tanımlanır.
Söz dizimi genellikle BNF adlı bir biçimde tanımlanır. Dilimiz şu şekilde tanımlanır:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Bir dilin söz dizimi bağlamsız söz dizimiyse normal ayrıştırıcılar tarafından ayrıştırılabileceğini söylemiştik. Bağlamsız söz dizimi, tamamen BNF ile ifade edilebilen bir söz dizimidir. Resmi bir tanım için Wikipedia'nın Bağlamdan Bağımsız Dil Bilgisi makalesine bakın.
Ayrıştırıcı türleri
İki tür ayrıştırıcı vardır: yukarıdan aşağı ayrıştırıcılar ve aşağıdan yukarı ayrıştırıcılar. Üstten aşağı ayrıştırıcıların, söz dizisinin üst düzey yapısını inceleyip kural eşleşmesi bulmaya çalıştıklarını sezgisel bir şekilde açıklayabiliriz. Aşağıdan yukarıya doğru ayrıştırıcılar, girişle başlar ve girişi düşük düzeyli kurallardan başlayarak yüksek düzeyli kurallar karşılanana kadar yavaş yavaş söz dizimi kurallarına dönüştürür.
İki tür ayrıştırıcının örneğimizi nasıl ayrıştırdığını görelim.
Yukarıdan aşağı ayrıştırıcı, daha yüksek düzeydeki kuraldan başlar: 2 + 3 ifadesi olarak tanımlar. Ardından 2 + 3 - 1 ifadesi tanımlanır (ifadeyi tanımlama süreci, diğer kurallarla eşleşerek gelişir ancak başlangıç noktası en üst düzey kuraldır).
Aşağıdan yukarıya doğru ayrıştırıcı, bir kural eşleşene kadar girişi tarar. Ardından, eşleşen girişi kuralla değiştirir. Bu işlem, girişin sonuna kadar devam eder. Kısmen eşleşen ifade, ayrıştırıcının yığınına yerleştirilir.
Giriş sağa kaydırılıp (ilk olarak girişin başlangıcını işaret eden ve sağa doğru hareket eden bir işaretçi düşünün) yavaş yavaş söz dizimi kurallarına indirgendiği için bu tür bir aşağıdan yukarıya ayrıştırıcıya kaydırma-azaltma ayrıştırıcısı denir.
Ayrıştırıcıları otomatik olarak oluşturma
Ayrıştırıcı oluşturabilen araçlar vardır. Dilinizin dil bilgisini (sözlüğü ve söz dizimi kuralları) beslediğinizde çalışan bir ayrıştırıcı oluştururlar. Ayrıştırıcı oluşturmak için ayrıştırma hakkında derin bir bilgi sahibi olmanız gerekir. Ayrıca, optimize edilmiş bir ayrıştırıcıyı manuel olarak oluşturmak kolay değildir. Bu nedenle, ayrıştırıcı oluşturucular çok yararlı olabilir.
WebKit, iki iyi bilinen ayrıştırıcı oluşturucu kullanır: Ayrıştırıcı oluşturmak için Flex ve ayrıştırıcı oluşturmak için Bison (bunlara Lex ve Yacc adlarıyla da rastlayabilirsiniz). Flex girişi, jetonların normal ifade tanımlarını içeren bir dosyadır. Bison'un girişi, BNF biçimindeki dil söz dizimi kurallarıdır.
HTML Ayrıştırıcı
HTML ayrıştırıcının görevi, HTML işaretlemesini bir ayrıştırma ağacına ayrıştırmaktır.
HTML dil bilgisi
HTML'nin kelime dağarcığı ve söz dizimi, W3C kuruluşu tarafından oluşturulan spesifikasyonlarda tanımlanır.
Ayrıştırma girişinde gördüğümüz gibi, dil bilgisi söz dizimi BNF gibi biçimler kullanılarak resmi olarak tanımlanabilir.
Maalesef geleneksel ayrıştırıcı konuların tümü HTML için geçerli değildir (Bunları sadece eğlence için gündeme getirmedim; CSS ve JavaScript'i ayrıştırırken kullanılacaklardır). HTML, ayrıştırıcıların ihtiyaç duyduğu bağlamsız bir dil bilgisiyle kolayca tanımlanamaz.
HTML'yi tanımlamak için resmi bir biçim (DTD - Document Type Definition) vardır ancak bu bağlamdan bağımsız bir dil bilgisi değildir.
Bu durum ilk bakışta garip görünebilir; HTML, XML'e oldukça yakındır. Birçok XML ayrıştırıcı mevcuttur. HTML'nin XML varyantı olan XHTML'in ne gibi avantajları vardır?
Aradaki fark, HTML yaklaşımının daha "affedici" olmasıdır: Belirli etiketleri (daha sonra dolaylı olarak eklenir) veya bazen başlangıç ya da bitiş etiketlerini atlamanıza olanak tanır. Genel olarak, XML'in katı ve talepkar söz dizimine kıyasla "yumuşak" bir söz dizimidir.
Küçük görünen bu ayrıntı, büyük bir fark yaratabilir. HTML'nin bu kadar popüler olmasının başlıca nedeni, hatalarınızı bağışlaması ve web yazarı için hayatı kolaylaştırmasıdır. Diğer yandan, biçimsel bir dil bilgisi yazmanızı zorlaştırır. Özetlemek gerekirse, dil bilgisi bağlamdan bağımsız olmadığı için HTML, geleneksel ayrıştırıcılar tarafından kolayca ayrıştırılamaz. HTML, XML ayrıştırıcılar tarafından ayrıştırılamaz.
HTML DTD
HTML tanımı DTD biçimindedir. Bu biçim, SGML ailesinin dillerini tanımlamak için kullanılır. Biçim, izin verilen tüm öğelerin, özelliklerinin ve hiyerarşisinin tanımlarını içerir. Daha önce de gördüğümüz gibi, HTML DTD bağlamdan bağımsız bir dil bilgisi oluşturmaz.
DTD'nin birkaç varyasyonu vardır. Katı mod yalnızca spesifikasyonlara uygundur ancak diğer modlar, tarayıcılar tarafından geçmişte kullanılan işaretleme için destek içerir. Amaç, eski içeriklerle geriye dönük uyumluluk sağlamaktır. Mevcut katı DTD şu adrestedir: www.w3.org/TR/html4/strict.dtd
DOM
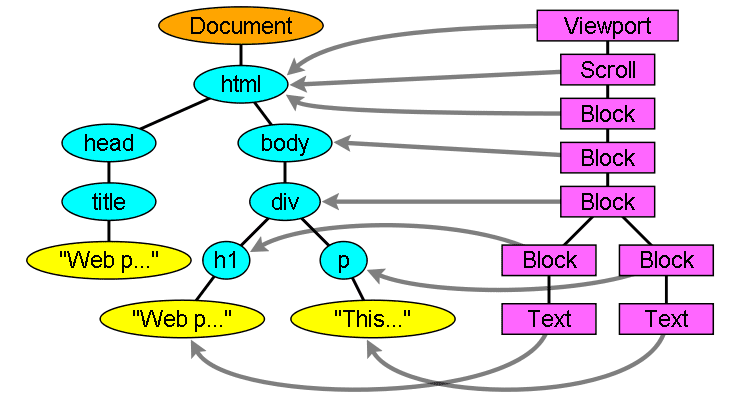
Çıkış ağacı ("ayrıştırma ağacı"), DOM öğesi ve özellik düğümlerinden oluşan bir ağaçtır. DOM, Belge Nesne Modeli'nin kısaltmasıdır. HTML dokümanındaki nesne sunumu ve HTML öğelerinin JavaScript gibi dış dünyayla arayüzüdür.
Ağacın kökü "Document" nesnesidir.
DOM, işaretlemeyle neredeyse bire bir ilişkilidir. Örneğin:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Bu işaretleme aşağıdaki DOM ağacına çevrilir:
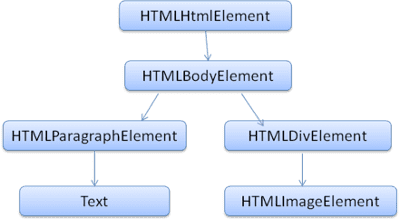
HTML gibi DOM da W3C kuruluşu tarafından belirtilir. www.w3.org/DOM/DOMTR adresine bakın. Belgeleri değiştirmeye yönelik genel bir spesifikasyondur. Belirli bir modül, HTML'ye özgü öğeleri açıklar. HTML tanımlarını www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html adresinde bulabilirsiniz.
Ağacın DOM düğümleri içerdiğini söylerken, ağacın DOM arayüzlerinden birini uygulayan öğelerden oluştuğunu kastediyorum. Tarayıcılar, tarayıcı tarafından dahili olarak kullanılan başka özelliklere sahip somut uygulamalar kullanır.
Ayrıştırma algoritması
Önceki bölümlerde gördüğümüz gibi, HTML normal yukarıdan aşağıya veya aşağıdan yukarıya ayrıştırıcılar kullanılarak ayrıştırılamaz.
Bunun nedenleri şunlardır:
- Dilin bağışlayıcı yapısı.
- Tarayıcıların, bilinen geçersiz HTML durumlarını desteklemek için geleneksel hata toleransına sahip olması.
- Ayrıştırma işlemi yeniden girilebilir. Diğer diller için kaynak, ayrıştırma sırasında değişmez ancak HTML'de dinamik kod (
document.write()çağrıları içeren komut dosyası öğeleri gibi) ek jetonlar ekleyebilir. Bu nedenle, ayrıştırma işlemi aslında girişi değiştirir.
Normal ayrıştırma tekniklerini kullanamayan tarayıcılar, HTML'yi ayrıştırmak için özel ayrıştırıcılar oluşturur.
Ayrıştırma algoritması, HTML5 spesifikasyonunda ayrıntılı olarak açıklanır. Algoritma iki aşamadan oluşur: jeton oluşturma ve ağaç oluşturma.
Örneklendirme, girişi örnekçelere ayıran söz dizimi analizidir. HTML jetonları arasında başlangıç etiketleri, bitiş etiketleri, özellik adları ve özellik değerleri bulunur.
Ayrıştırıcı, jetonu tanır, ağaç oluşturucuya verir ve sonraki jetonu tanımak için sonraki karakteri tüketir. Bu işlem, girişin sonuna kadar devam eder.
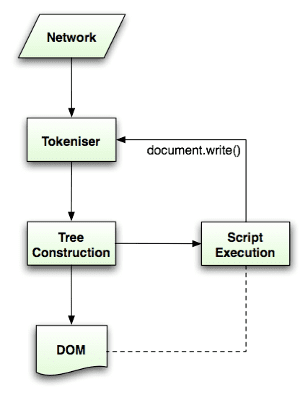
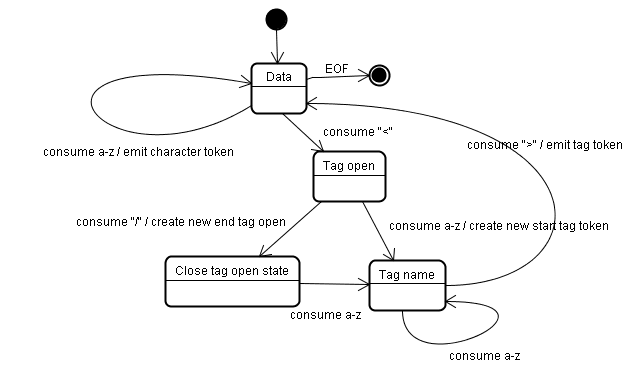
Jeton oluşturma algoritması
Algoritmanın çıktısı bir HTML jetonudur. Algoritma, durum makinesi olarak ifade edilir. Her durum, giriş akışındaki bir veya daha fazla karakteri tüketir ve bir sonraki durumu bu karakterlere göre günceller. Karar, mevcut jeton oluşturma durumu ve ağaç oluşturma durumundan etkilenir. Bu, aynı tüketilen karakterin, mevcut duruma bağlı olarak doğru bir sonraki durum için farklı sonuçlar vereceği anlamına gelir. Algoritma, tam olarak açıklanamayacak kadar karmaşıktır. Bu nedenle, ilkeyi anlamamıza yardımcı olacak basit bir örnekle başlayalım.
Temel örnek: Aşağıdaki HTML'nin jetonlara ayrılması:
<html>
<body>
Hello world
</body>
</html>
İlk durum "Veri durumu"dur.
< karakteriyle karşılaşıldığında durum "Etiket açık durumu" olarak değiştirilir.
Bir a-z karakteri tüketildiğinde "Başlangıç etiketi jetonu" oluşturulur ve durum "Etiket adı durumu" olarak değiştirilir.
> karakteri tüketilene kadar bu durumda kalırız. Her karakter yeni jeton adına eklenir. Örneğimizde oluşturulan jeton bir html jetonudur.
> etiketine ulaşıldığında mevcut jeton yayınlanır ve durum "Veri durumu" olarak geri döner.
<body> etiketi de aynı adımlarla işlenir.
Şu ana kadar html ve body etiketleri yayınlandı. Şimdi "Veri durumu" sayfasına geri döndük.
Hello world'un H karakteri tüketildiğinde bir karakter jetonu oluşturulur ve yayınlanır. Bu işlem, </body>'ın < karakterine ulaşılana kadar devam eder. Hello world karakterinin her biri için bir karakter jetonu göndeririz.
Şimdi "Etiket açık durumu"'na geri döndük.
Sonraki giriş / tüketildiğinde bir end tag token oluşturulur ve "Etiket adı durumu"'na geçilir. > değerine ulaşana kadar yine bu durumda kalırız.Ardından yeni etiket jetonu yayınlanır ve "Veri durumu"'na geri döneriz.
</html> girişi, önceki örnekte olduğu gibi değerlendirilir.
Ağaç oluşturma algoritması
Ayrıştırıcı oluşturulduğunda Document nesnesi de oluşturulur. Ağaç oluşturma aşamasında, kökünde Document bulunan DOM ağacı değiştirilir ve ağaca öğeler eklenir. Ayrıştırıcı tarafından oluşturulan her düğüm, ağaç oluşturucu tarafından işlenir. Spesifikasyon, her jeton için hangi DOM öğesinin onunla alakalı olduğunu ve bu jeton için oluşturulacağını tanımlar. Öğe, DOM ağacına ve açık öğe yığınına eklenir. Bu yığın, iç içe yerleştirme uyuşmazlıklarını ve kapatılmamış etiketleri düzeltmek için kullanılır. Algoritma, durum makinesi olarak da açıklanır. Bu durumlara "ekleme modları" denir.
Örnek giriş için ağaç oluşturma sürecine göz atalım:
<html>
<body>
Hello world
</body>
</html>
Ağaç oluşturma aşamasına girilen giriş, jeton oluşturma aşamasından alınan bir jeton dizisidir. İlk mod "ilk mod"'dur. "html" jetonunun alınması, "html'den önce" moduna geçilmesine ve jetonun bu modda yeniden işlenmesine neden olur. Bu işlem, kök Document nesnesine eklenecek HTMLHtmlElement öğesinin oluşturulmasına neden olur.
Durum "before head" olarak değiştirilir. Ardından "body" jetonu alınır. "head" jetonumuz olmasa da bir HTMLHeadElement örtük olarak oluşturulur ve ağaca eklenir.
Şimdi "kafa içinde" moduna, ardından "kafadan sonra" moduna geçiyoruz. Gövde jetonu yeniden işlenir, bir HTMLBodyElement oluşturulup eklenir ve mod "in body" olarak aktarılır.
"Merhaba dünya" dizesinin karakter jetonları artık alınır. İlki bir "Metin" düğümünün oluşturulmasına ve eklenmesine neden olur ve diğer karakterler bu düğüme eklenir.
Gövde sonu jetonunun alınması, "gövden sonra" moduna geçişe neden olur. Ardından, bizi "body'dan sonra" moduna geçirecek html bitiş etiketini alırız. Dosya sonu jetonu alındığında ayrıştırma işlemi sonlandırılır.
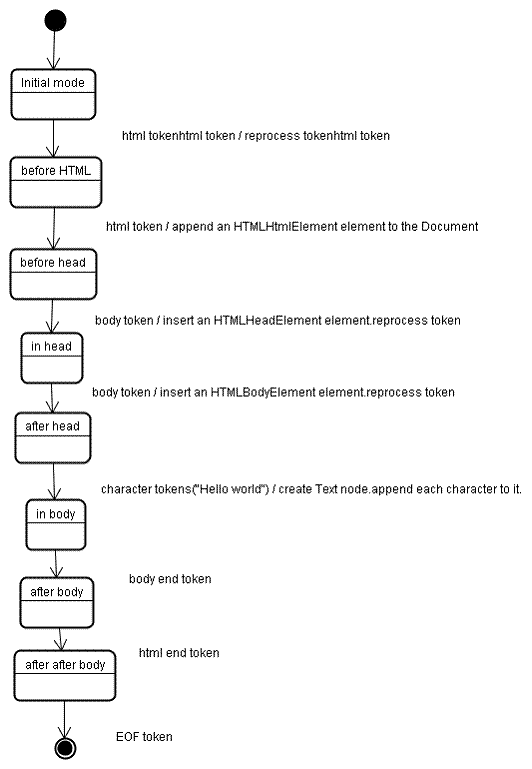
Ayrıştırma işlemi tamamlandığında yapılacak işlemler
Bu aşamada tarayıcı, dokümanı etkileşimli olarak işaretler ve "ertelenen" modda olan komut dosyalarını ayrıştırmaya başlar: doküman ayrıştırıldıktan sonra yürütülmesi gerekenler. Ardından belge durumu "tamamlandı" olarak ayarlanır ve bir "yükleme" etkinliği tetiklenir.
HTML5 spesifikasyonunda jeton oluşturma ve ağaç oluşturma algoritmalarının tamamını görebilirsiniz.
Tarayıcıların hata toleransı
HTML sayfalarında hiçbir zaman "Geçersiz Söz Dizimi" hatası almazsınız. Tarayıcılar geçersiz içerikleri düzeltip devam eder.
Aşağıdaki HTML'yi örnek olarak alalım:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Yaklaşık bir milyon kuralı ihlal etmiş olmalıyım ("mytag" standart bir etiket değil, "p" ve "div" öğelerinin yanlış yerleştirilmesi ve daha fazlası) ancak tarayıcı yine de doğru şekilde gösteriyor ve şikayet etmiyor. Bu nedenle, ayrıştırıcı kodunun büyük bir kısmı HTML yazarı hatalarını düzeltiyor.
Hata işleme, tarayıcılarda oldukça tutarlı bir şekilde uygulanır ancak şaşırtıcı bir şekilde HTML spesifikasyonlarının bir parçası değildir. Yer işareti ekleme ve geri/ileri düğmeleri gibi, bu da tarayıcılarda yıllar içinde geliştirilmiş bir özelliktir. Birçok sitede tekrarlanan geçersiz HTML yapıları vardır ve tarayıcılar bunları diğer tarayıcılarla uyumlu olacak şekilde düzeltmeye çalışır.
HTML5 spesifikasyonunda bu koşulların bazıları tanımlanmıştır. (WebKit, bunu HTML ayrıştırıcı sınıfının başındaki yorumda güzel bir şekilde özetler.)
Ayrıştırıcı, dokümana ayrıştırılmış girişi ayrıştırarak doküman ağacını oluşturur. Doküman iyi biçimlendirilmişse ayrıştırması kolaydır.
Maalesef iyi biçimlendirilmemiş çok sayıda HTML belgesiyle ilgilenmemiz gerekiyor. Bu nedenle, ayrıştırıcının hatalar konusunda hoşgörülü olması gerekiyor.
En azından aşağıdaki hata koşullarını ele almamız gerekir:
- Eklenen öğe, bazı dış etiketlerin içinde açıkça yasaklanmıştır. Bu durumda, öğeyi yasaklayana kadar tüm etiketleri kapatıp öğeyi daha sonra eklememiz gerekir.
- Öğeyi doğrudan eklememize izin verilmiyor. Dokümanı yazan kişi, aradaki bazı etiketleri unutmuş olabilir (veya aradaki etiket isteğe bağlı olabilir). Bu durum aşağıdaki etiketler için geçerli olabilir: HTML HEAD BODY TBODY TR TD LI (unuttuğum var mı?).
- Satır içi bir öğenin içine bir blok öğesi eklemek istiyoruz. Bir sonraki üst blok öğeye kadar tüm satır içi öğeleri kapatın.
- Bu işe yaramazsa öğeyi eklememize izin verilene kadar öğeleri kapatın veya etiketi yoksayın.
WebKit hata toleransı örneklerini inceleyelim:
<br> yerine </br>
Bazı siteler <br> yerine </br> kullanır. WebKit, IE ve Firefox ile uyumlu olmak için bunu <br> olarak ele alır.
Kod:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Hata işleme işleminin dahili olduğunu ve kullanıcıya gösterilmeyeceğini unutmayın.
Dağınık bir tablo
Başıboş tablo, başka bir tablonun içinde bulunan ancak tablo hücresinin içinde bulunmayan bir tablodur.
Örneğin:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit, hiyerarşiyi iki kardeş tabloyla değiştirir:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Kod:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit, mevcut öğe içerikleri için bir yığın kullanır: İç tabloyu dış tablo yığınından çıkarır. Tablolar artık kardeş olur.
İç içe yerleştirilmiş form öğeleri
Kullanıcı bir formu başka bir formun içine yerleştirirse ikinci form yok sayılır.
Kod:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Çok derin bir etiket hiyerarşisi
Yorum her şeyi açıklıyor.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Yanlış yerleştirilmiş html veya body son etiketleri
Yorumlar her şeyi açıklıyor.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Bu nedenle, web yazarları WebKit hata toleransı kod snippet'inde örnek olarak görünmek istemiyorlarsa iyi biçimlendirilmiş HTML yazmalıdır.
CSS ayrıştırma
Girişteki ayrıştırma kavramlarını hatırlıyor musunuz? HTML'den farklı olarak CSS, bağlamsız bir dil bilgisidir ve girişte açıklanan ayrıştırıcı türleri kullanılarak ayrıştırılabilir. Aslında CSS spesifikasyonu, CSS sözcüksel ve söz dizimi dil bilgisini tanımlar.
Birkaç örneğe göz atalım:
Sözlük dil bilgisi (sözlük), her bir parça için normal ifadelerle tanımlanır:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident", sınıf adı gibi tanımlayıcıların kısaltmasıdır. "ad", bir öğe kimliğidir ("#" ile belirtilir).
Söz dizimi dil bilgisi BNF'de açıklanır.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Açıklama:
Kural kümesi şu yapıdadır:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error ve a.error seçicilerdir. Açılı parantez içindeki kısım, bu kural kümesi tarafından uygulanan kuralları içerir.
Bu yapı, aşağıdaki tanımda resmi olarak tanımlanmıştır:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Bu, kural kümesinin bir seçici veya isteğe bağlı olarak virgül ve boşluklarla ayrılmış bir dizi seçici (Boşluk karakteri S ile gösterilir) olduğu anlamına gelir. Kural kümesi, köşeli parantez içerir ve bunların içinde bir bildirim veya isteğe bağlı olarak noktalı virgülle ayrılmış birkaç bildirim bulunur. "declaration" ve "selector", aşağıdaki BNF tanımlarında açıklanacaktır.
WebKit CSS ayrıştırıcısı
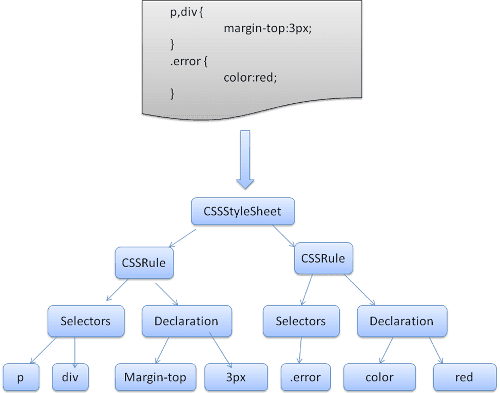
WebKit, CSS dil bilgisi dosyalarından otomatik olarak ayrıştırıcılar oluşturmak için Flex ve Bison ayrıştırıcı oluşturucularını kullanır. Ayıklama aracı girişinde de belirtildiği gibi, Bison alttan yukarı doğru kaydırma azaltma ayrıştırıcısı oluşturur. Firefox, manuel olarak yazılmış bir yukarıdan aşağıya ayrıştırıcı kullanır. Her iki durumda da her CSS dosyası bir StyleSheet nesnesine ayrıştırılır. Her nesne CSS kuralları içerir. CSS kural nesneleri, CSS diline karşılık gelen seçici ve bildirim nesneleri ile diğer nesneleri içerir.
Komut dosyaları ve stil sayfaları için işleme sırası
Komut Dosyaları
Web'in modeli senkronizedir. Yazarlar, ayrıştırıcı bir <script> etiketine ulaştığında komut dosyalarının anında ayrıştırılıp yürütülmesini bekler.
Komut dosyası çalıştırılana kadar belgenin ayrıştırılması duraklatılır.
Komut dosyası hariciyse kaynak önce ağdan getirilmelidir. Bu işlem de senkronize olarak yapılır ve kaynak getirilene kadar ayrıştırma duraklatılır.
Bu model uzun yıllar boyunca kullanıldı ve HTML4 ile 5 spesifikasyonlarında da belirtilmiştir.
Yazarlar, bir komut dosyasına "defer" özelliğini ekleyebilir. Bu durumda, belge ayrıştırma işlemi durdurulmaz ve belge ayrıştırıldıktan sonra komut dosyası yürütülür. HTML5, komut dosyasını farklı bir iş parçacığı tarafından ayrıştırılıp yürütülmesi için ayarlama seçeneği ekler.
Spekülatif ayrıştırma
Hem WebKit hem de Firefox bu optimizasyonu yapar. Komut dosyaları yürütülürken başka bir iş parçacığı, dokümanın geri kalanını ayrıştırır ve ağdan hangi diğer kaynakların yüklenmesi gerektiğini bulup bunları yükler. Bu sayede kaynaklar paralel bağlantılara yüklenebilir ve genel hız artar. Not: Tahmini ayrıştırıcı yalnızca harici komut dosyaları, stil sayfaları ve resimler gibi harici kaynaklara yapılan referansları ayrıştırır. DOM ağacını değiştirmez. Bu işlem ana ayrıştırıcıya bırakılır.
Stil sayfaları
Öte yandan stil sayfalarının farklı bir modeli vardır. Stil sayfaları DOM ağacını değiştirmediğinden, bunları bekleyip doküman ayrıştırmayı durdurmanın kavramsal olarak bir anlamı yoktur. Ancak, doküman ayrıştırma aşamasında stil bilgileri isteyen komut dosyalarıyla ilgili bir sorun var. Stil henüz yüklenmemiş ve ayrıştırılmamışsa komut dosyası yanlış yanıtlar alır ve bu da birçok soruna neden olur. Bu durum uç bir durum gibi görünse de oldukça yaygındır. Firefox, hâlâ yüklenmekte ve ayrıştırılmakta olan bir stil sayfası olduğunda tüm komut dosyalarını engeller. WebKit, komut dosyalarını yalnızca yüklenmemiş stil sayfalarından etkilenebilecek belirli stil özelliklerine erişmeye çalıştıklarında engeller.
Oluşturma ağacı oluşturma
DOM ağacı oluşturulurken tarayıcı başka bir ağaç (oluşturma ağacı) oluşturur. Bu ağaç, görsel öğelerin gösterilecekleri sırayla gösterilir. Dokümanın görsel temsilidir. Bu ağacın amacı, içeriklerin doğru sırayla boyanmasını sağlamaktır.
Firefox, oluşturma ağacındaki öğeleri "çerçeveler" olarak adlandırır. WebKit, oluşturma aracı veya oluşturma nesnesi terimini kullanır.
Oluşturucu, kendisini ve alt öğelerini nasıl düzenleyeceğini ve boyayacağını bilir.
Oluşturucuların temel sınıfı olan WebKit'in RenderObject sınıfı aşağıdaki şekilde tanımlanır:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Her oluşturucu, genellikle CSS2 spesifikasyonunda açıklandığı gibi bir düğümün CSS kutusuna karşılık gelen dikdörtgen bir alanı temsil eder. Bu alan, genişlik, yükseklik ve konum gibi geometrik bilgileri içerir.
Kutu türü, düğümle alakalı stil özelliğinin "display" değerinden etkilenir (stil hesaplaması bölümüne bakın). Görüntüleme özelliğine göre bir DOM düğümü için ne tür bir oluşturma aracının oluşturulacağına karar vermek için kullanılan WebKit kodu aşağıda verilmiştir:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Öğe türü de dikkate alınır. Örneğin, form kontrolleri ve tablolar özel çerçevelere sahiptir.
WebKit'te bir öğe özel bir oluşturucu oluşturmak isterse createRenderer() yöntemini geçersiz kılar.
Oluşturucular, geometrik olmayan bilgiler içeren stil nesnelerini işaret eder.
Oluşturma ağacının DOM ağacıyla ilişkisi
Oluşturucular DOM öğelerine karşılık gelir ancak ilişki bire bir değildir. Görsel olmayan DOM öğeleri oluşturma ağacına eklenmez. Örneğin, "head" öğesi. Ayrıca, görüntüleme değeri "yok" olarak atanan öğeler de ağaçta görünmez (ancak "gizli" görünürlük değerine sahip öğeler ağaçta görünür).
Birkaç görsel nesneye karşılık gelen DOM öğeleri vardır. Bunlar genellikle tek bir dikdörtgenle açıklanamayan karmaşık yapıya sahip öğelerdir. Örneğin, "select" öğesinin üç oluşturucusu vardır: biri görüntüleme alanı, biri açılır liste kutusu ve biri düğme içindir. Ayrıca, genişlik bir satır için yeterli olmadığından metin birden fazla satıra bölündüğünde yeni satırlar ek oluşturucular olarak eklenir.
Birden fazla oluşturma aracına örnek olarak bozuk HTML verilebilir. CSS spesifikasyonuna göre satır içi öğeler yalnızca blok öğeler veya yalnızca satır içi öğeler içermelidir. Karışık içerik söz konusu olduğunda, satır içi öğeleri sarmalamak için anonim blok oluşturucular oluşturulur.
Bazı oluşturma nesneleri bir DOM düğümüne karşılık gelir ancak ağaçta aynı yerde değildir. Yüzen ve mutlak konumlandırılmış öğeler akış dışındadır, ağacın farklı bir bölümüne yerleştirilir ve gerçek çerçeveyle eşlenir. Yer tutucu çerçeve, öğelerin olması gereken yerdir.
Ağacın oluşturulma akışı
Firefox'ta sunu, DOM güncellemeleri için dinleyici olarak kaydedilir.
Sunum, çerçeve oluşturma işlemini FrameConstructor'e delege eder ve kurucu, stili çözer (stil hesaplaması bölümüne bakın) ve bir çerçeve oluşturur.
WebKit'te stili çözme ve bir oluşturma işlemine "ekleme" adı verilir. Her DOM düğümünün bir "attach" yöntemi vardır. Ekleme işlemi senkronizedir. DOM ağacına düğüm ekleme işlemi, yeni düğümün "attach" yöntemini çağırır.
HTML ve body etiketleri işlendiğinde oluşturma ağacı kökü oluşturulur.
Kök oluşturma nesnesi, CSS spesifikasyonunda kapsayıcı blok olarak adlandırılan öğeye karşılık gelir: diğer tüm blokları içeren en üstteki blok. Boyutları, görüntü alanıdır: tarayıcı penceresi görüntü alanı boyutları.
Firefox buna ViewPortFrame, WebKit ise RenderView adını verir.
Bu, belgenin işaret ettiği oluşturma nesnesidir.
Ağacın geri kalanı, DOM düğümü ekleme olarak oluşturulur.
İşleme modelindeki CSS2 spesifikasyonuna bakın.
Stil hesaplama
Oluşturma ağacını oluşturmak için her oluşturma nesnesinin görsel özelliklerinin hesaplanması gerekir. Bu işlem, her bir öğenin stil özellikleri hesaplanarak yapılır.
Stil, çeşitli kaynaklardan gelen stil sayfalarını, satır içi stil öğelerini ve HTML'deki görsel özellikleri ("bgcolor" özelliği gibi) içerir. Sonrakiler, eşleşen CSS stil özelliklerine çevrilir.
Stil sayfalarının kaynakları; tarayıcının varsayılan stil sayfaları, sayfa yazarı tarafından sağlanan stil sayfaları ve kullanıcı stil sayfalarıdır. Bu sayfalar, tarayıcı kullanıcısı tarafından sağlanan stil sayfalarıdır (tarayıcılar, en sevdiğiniz stilleri tanımlamanıza olanak tanır). Örneğin, Firefox'ta bu işlem "Firefox Profili" klasörüne bir stil sayfası yerleştirilerek yapılır.
Stil hesaplaması birkaç zorluk ortaya çıkarır:
- Stil verileri, çok sayıda stil özelliğini barındıran çok büyük bir yapıdır. Bu durum, bellek sorunlarına neden olabilir.
Her öğe için eşleşen kuralları bulmak, öğe optimize edilmemişse performans sorunlarına neden olabilir. Eşleşmeleri bulmak için her öğe için kural listesinin tamamını taramak zor bir iştir. Seçiciler karmaşık bir yapıya sahip olabilir. Bu durum, eşleştirme sürecinin ümit verici görünen bir yolda başlamasına neden olabilir. Ancak bu yol işe yaramaz ve başka bir yol denenmesi gerekir.
Örneğin, şu bileşik seçici:
div div div div{ ... }Bu, kuralların 3 div'in alt öğesi olan bir
<div>için geçerli olduğu anlamına gelir. Kuralın belirli bir<div>öğesi için geçerli olup olmadığını kontrol etmek istediğinizi varsayalım. Kontrol için ağaçta belirli bir yol seçersiniz. Yalnızca iki div olduğunu ve kuralın geçerli olmadığını öğrenmek için düğüm ağacını yukarı doğru incelemeniz gerekebilir. Ardından ağaçtaki diğer yolları denemeniz gerekir.Kuralları uygulamak, kuralların hiyerarşisini tanımlayan oldukça karmaşık basamaklı kurallar içerir.
Tarayıcıların bu sorunlarla nasıl başa çıktığına bakalım:
Stil verilerini paylaşma
WebKit düğümleri stil nesnelerine (RenderStyle) referans verir. Bu nesneler bazı koşullarda düğümler tarafından paylaşılabilir. Düğümler kardeş veya kuzendir ve:
- Öğeler aynı fare durumunda olmalıdır (ör. biri :hover durumundayken diğeri bu durumda olamaz)
- Hiçbir öğenin kimliği olmamalıdır.
- Etiket adları eşleşmelidir
- Sınıf özellikleri eşleşmelidir
- Eşlenen özellikler grubu aynı olmalıdır
- Bağlantı durumları eşleşmelidir
- Odak durumları eşleşmelidir
- Hiçbir öğe özellik seçicilerden etkilenmemelidir. Etkilenen, seçici içinde herhangi bir konumda özellik seçici kullanan herhangi bir seçici eşleşmesine sahip olmak olarak tanımlanır.
- Öğelerde satır içi stil özelliği bulunmamalıdır.
- Kullanımda hiç kardeş seçici olmamalıdır. WebCore, herhangi bir kardeş seçiciyle karşılaşıldığında genel bir anahtar atar ve mevcut olduğunda stil paylaşımını belgenin tamamı için devre dışı bırakır. + seçici ve :first-child ve :last-child gibi seçiciler bu kapsamdadır.
Firefox kural ağacı
Firefox'ta stil hesaplamasını kolaylaştırmak için iki ek ağaç bulunur: kural ağacı ve stil bağlamı ağacı. WebKit'te de stil nesneleri vardır ancak bunlar stil bağlamı ağacı gibi bir ağaçta depolanmaz. Yalnızca DOM düğümü ilgili stili gösterir.
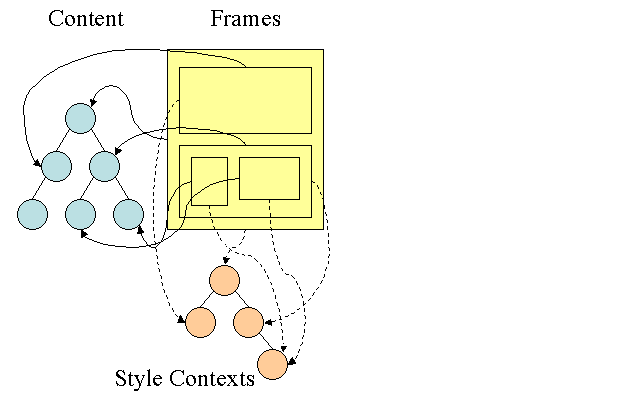
Stil bağlamları bitiş değerleri içerir. Değerler, tüm eşleşme kurallarının doğru sırada uygulanması ve mantıksal değerlerden somut değerlere dönüştüren işlemler yapılmasıyla hesaplanır. Örneğin, mantıksal değer ekranın yüzdesiyse hesaplanır ve mutlak birimlere dönüştürülür. Kural ağacı fikri gerçekten akıllıca. Bu değerleri tekrar hesaplamamak için düğümler arasında paylaşılmasını sağlar. Bu işlem, alandan da tasarruf etmenizi sağlar.
Eşleşen tüm kurallar bir ağaçta depolanır. Bir yoldaki alt düğümler daha yüksek önceliğe sahiptir. Ağaç, bulunan kural eşleşmelerinin tüm yollarını içerir. Kurallar, tembel bir şekilde depolanır. Ağaç, her düğüm için başlangıçta hesaplanmaz ancak bir düğüm stilinin hesaplanması gerektiğinde hesaplanan yollar ağaca eklenir.
Buradaki amaç, ağaç yollarını bir sözlükteki kelimeler olarak görmektir. Bu kural ağacını zaten hesapladığımızı varsayalım:
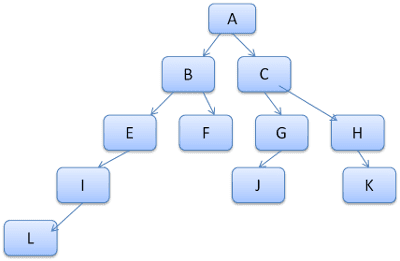
İçerik ağacındaki başka bir öğeyle ilgili kuralları eşleştirmemiz gerektiğini ve eşleşen kuralların (doğru sırada) B-E-I olduğunu varsayalım. A-B-E-I-L yolunu zaten hesapladığımız için bu yol ağaçta zaten mevcuttur. Artık daha az işimiz olacak.
Ağacın bize nasıl iş kazandırdığına bakalım.
Yapılara bölme
Stil bağlamları yapılara ayrılır. Bu yapıların her biri, kenar veya renk gibi belirli bir kategoriye ait stil bilgilerini içerir. Bir yapıdaki tüm özellikler devralınır veya devralınmaz. Devralınan özellikler, öğe tarafından tanımlanmayan ve üst öğesinden devralınan özelliklerdir. Devralınmayan özellikler ("sıfırlama" özellikleri olarak adlandırılır) tanımlanmamışsa varsayılan değerleri kullanır.
Ağaç, yapıların tamamını (hesaplanmış bitiş değerlerini içeren) ağaçta önbelleğe alarak bize yardımcı olur. Buradaki amaç, alt düğüm bir yapı için bir tanım sağlamadıysa üst düğümdeki önbelleğe alınmış bir yapının kullanılabilmesidir.
Kural ağacını kullanarak stil bağlamlarını hesaplama
Belirli bir öğenin stil bağlamını hesaplarken önce kural ağacında bir yol hesaplanır veya mevcut bir yol kullanılır. Ardından, yapıları yeni stil bağlamımızda doldurmak için yoldaki kuralları uygulamaya başlarız. Yolun en alt düğümünden (en yüksek önceliğe sahip olandan, genellikle en spesifik seçiciden) başlar ve yapımız dolana kadar ağacı tararız. Söz konusu kural düğümünde yapı için bir spesifikasyon yoksa büyük ölçüde optimizasyon yapabiliriz. Yapıyı tam olarak belirten ve işaret eden bir düğüm bulana kadar ağaçta yukarı doğru gideriz. Bu, en iyi optimizasyondur. Yapının tamamı paylaşılır. Bu sayede son değerlerin hesaplanması ve bellek tasarrufu sağlanır.
Kısmi tanımlar bulursak yapı doldurulana kadar ağaçta yukarı doğru ilerleriz.
Yapımız için herhangi bir tanım bulamazsak yapı "devralınan" bir türse bağlam ağacında ebeveynimizin yapısını işaret ederiz. Bu durumda yapıları da paylaşmayı başardık. Sıfırlanan bir yapıysa varsayılan değerler kullanılır.
En spesifik düğüm değer ekliyorsa bunu gerçek değerlere dönüştürmek için bazı ek hesaplamalar yapmamız gerekir. Ardından, sonucu çocukların kullanabilmesi için ağaç düğümünde önbelleğe alırız.
Bir öğenin aynı ağaç düğümünü işaret eden bir kardeşi veya abisi varsa stil bağlamının tamamı bunlar arasında paylaşılabilir.
Bir örneğe göz atalım: Şu HTML'ye sahip olduğumuzu varsayalım:
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
Ayrıca aşağıdaki kurallara uyulmalıdır:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
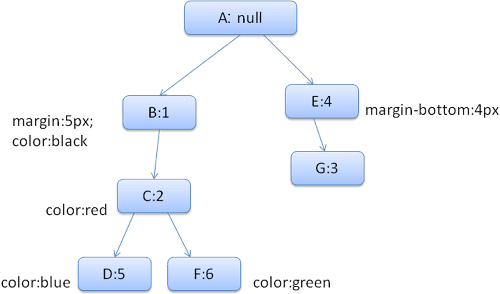
İşlemi basitleştirmek için yalnızca iki struct doldurmamız gerektiğini varsayalım: renk struct'u ve kenar boşluğu struct'u. Renk yapısı yalnızca bir üye içerir: renk. Kenarlık yapısı dört tarafı içerir.
Sonuçta ortaya çıkan kural ağacı aşağıdaki gibi görünür (düğümler, düğüm adıyla işaretlenir: işaret ettikleri kuralın numarası):
Bağlam ağacı şöyle görünür (düğüm adı: işaret ettikleri kural düğümü):
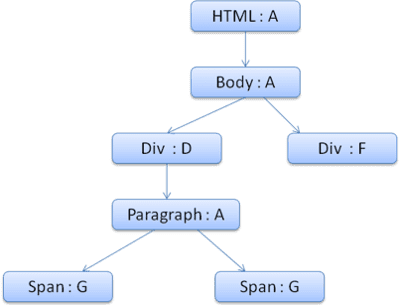
HTML'yi ayrıştırıp ikinci <div> etiketine ulaştığımızı varsayalım. Bu düğüm için bir stil bağlamı oluşturmamız ve stil yapılarını doldurmamız gerekir.
Kuralları eşleştiririz ve <div> için eşleşen kuralların 1, 2 ve 6 olduğunu görürüz.
Bu, ağaçta öğemizin kullanabileceği mevcut bir yol olduğu anlamına gelir. 6. kural için bu yola başka bir düğüm (kural ağacındaki F düğümü) eklememiz yeterlidir.
Bir stil bağlamı oluşturup bağlam ağacına ekleyeceğiz. Yeni stil bağlamı, kural ağacındaki F düğümünü işaret eder.
Şimdi stil yapılarını doldurmamız gerekiyor. Öncelikle margin yapısını doldurarak başlayacağız. Son kural düğümü (F), kenar boşluğu yapısını artırmadığından, önceki bir düğüm eklemede hesaplanan önbelleğe alınmış bir yapı bulana kadar ağaçta yukarı gidebilir ve bu yapıyı kullanabiliriz. Bu değeri, kenar boşluğu kurallarını belirten en üstteki B düğümünde buluruz.
Renk yapısı için bir tanımımız olduğundan önbelleğe alınmış bir yapı kullanamıyoruz. Renk tek bir özelliğe sahip olduğundan diğer özellikleri doldurmak için ağaca geri dönmemiz gerekmez. Bitiş değerini hesaplar (dizeyi RGB'ye dönüştürür vb.) ve hesaplanan yapıyı bu düğümde önbelleğe alırız.
İkinci <span> öğesiyle ilgili çalışma daha da kolaydır. Kuralları eşleştiririz ve önceki aralığın yaptığı gibi G kuralını işaret ettiği sonucuna varırız.
Aynı düğümü işaret eden kardeş öğelerimiz olduğundan stil bağlamının tamamını paylaşabilir ve yalnızca önceki aralığın bağlamını işaret edebiliriz.
Üst öğeden devralınan kurallar içeren yapıların önbelleğe alınması, bağlam ağacında yapılır (renk özelliği aslında devralınır ancak Firefox bunu sıfırlanmış olarak değerlendirir ve kural ağacında önbelleğe alır).
Örneğin, bir paragrafta yazı tipleriyle ilgili kurallar eklediysek:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Bu durumda, bağlam ağacındaki div öğesinin alt öğesi olan paragraf öğesi, üst öğesiyle aynı yazı tipi yapısını paylaşabilir. Bu, paragraf için yazı tipi kuralı belirtilmemişse geçerlidir.
Kural ağacı olmayan WebKit'te eşleşen bildirimler dört kez taranır. Öncelikle önemli olmayan yüksek öncelikli mülkler (görüntülü reklam gibi diğer mülkler bunlara bağlı olduğu için önce uygulanması gereken mülkler), ardından önemli olan yüksek öncelikli mülkler, ardından normal öncelikli önemli olmayan mülkler ve ardından normal öncelikli önemli kurallar uygulanır. Bu, birden fazla kez görünen mülklerin doğru basamak sırasına göre çözüleceği anlamına gelir. Sonuncu kazanır.
Özetlemek gerekirse: Stil nesnelerini (tamamen veya içindeki yapıların bir kısmını) paylaşmak 1. ve 3. sorunları çözer. Firefox kural ağacı, özelliklerin doğru sırayla uygulanmasına da yardımcı olur.
Kolay bir eşleşme için kuralları değiştirme
Stil kurallarının birkaç kaynağı vardır:
- Harici stil sayfalarında veya stil öğelerinde CSS kuralları.
css p {color: blue} html <p style="color: blue" />gibi satır içi stil özellikleri- HTML görsel özellikleri (ilgili stil kurallarıyla eşlenir)
html <p bgcolor="blue" />Son iki özellik, stil özelliklerinin sahibi olduğu ve HTML özelliklerinin anahtar olarak öğe kullanılarak eşlenebildiği için öğeyle kolayca eşlenir.
2. sorunda daha önce belirtildiği gibi, CSS kuralı eşleştirmesi daha zor olabilir. Bu zorluğu çözmek için kurallar, daha kolay erişim için değiştirilir.
Stil sayfası ayrıştırıldıktan sonra kurallar, seçiciye göre çeşitli karma haritalarından birine eklenir. Kimliğe, sınıf adına, etiket adına göre haritalar ve bu kategorilere uymayan her şey için genel bir harita vardır. Seçici bir kimlikse kural, kimlik haritasına, sınıfsa sınıf haritasına eklenir.
Bu işlem, kuralları eşleştirmeyi çok daha kolay hale getirir. Her beyanı incelemeniz gerekmez. Bir öğeyle ilgili alakalı kuralları haritalardan ayıklayabiliriz. Bu optimizasyon, kuralların% 95'inden fazlasını ortadan kaldırır. Böylece, eşleştirme işlemi sırasında(4.1) kuralların dikkate alınmasına bile gerek kalmaz.
Örneğin, aşağıdaki stil kurallarına bakalım:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
İlk kural sınıf haritasına eklenir. İkincisi kimlik haritasına, üçüncüsü ise etiket haritasına eklenir.
Aşağıdaki HTML parçası için:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Öncelikle p öğesi için kurallar bulmaya çalışacağız. Sınıf haritası, "p.error" kuralının bulunduğu bir "error" anahtarı içerir. div öğesi, kimlik haritasında (anahtar kimliktir) ve etiket haritasında ilgili kurallara sahiptir. Geriye kalan tek iş, anahtarlardan ayıklanan kurallardan hangilerinin gerçekten eşleştiğini bulmaktır.
Örneğin, div için kural şu şekildeyse:
table div {margin: 5px}
Anahtar en sağdaki seçici olduğundan etiket haritasından yine ayıklanır ancak tablo üst öğesi olmayan div öğemizle eşleşmez.
Hem WebKit hem de Firefox bu manipülasyonu yapar.
Stil sayfası basamaklı sıralaması
Stil nesnesi, her görsel özelliğe karşılık gelen özelliklere (tüm CSS özellikleri ancak daha genel) sahiptir. Mülk, eşleşen kurallardan hiçbiriyle tanımlanmamışsa bazı özellikler üst öğe stili nesnesi tarafından devralınabilir. Diğer özellikler varsayılan değerlere sahiptir.
Sorun, birden fazla tanım olduğunda başlar. Bu noktada, sorunu çözmek için basamaklı sıra devreye girer.
Bir stil mülkünün beyanı, birkaç stil sayfasında ve bir stil sayfasında birkaç kez görünebilir. Bu nedenle, kuralların uygulanma sırası çok önemlidir. Buna "düşey" sıra denir. CSS2 spesifikasyonuna göre, basamak sırası (düşükten yükseğe):
- Tarayıcı bildirimleri
- Kullanıcı normal bildirimleri
- Yazar normal beyanları
- Yazar önemli beyanları
- Kullanıcı için önemli beyanlar
Tarayıcı beyanları en az önemlidir ve kullanıcı, yalnızca beyan önemli olarak işaretlenmişse yazarı geçersiz kılar. Aynı sıraya sahip bildirimler, özgüllüğe ve ardından belirtildikleri sıraya göre sıralanır. HTML görsel özellikleri, eşleşen CSS beyanlarına çevrilir . Bunlar, düşük öncelikli yazar kuralları olarak değerlendirilir.
Belirginlik
Seçici özgüllüğü, CSS2 spesifikasyonu tarafından aşağıdaki şekilde tanımlanır:
- Kaynaktaki beyan bir seçici içeren kural yerine "stil" özelliğiyse 1, aksi takdirde 0 değerini alır (= a)
- Seçicideki kimlik özelliklerinin sayısını sayın (= b).
- Seçicideki diğer özelliklerin ve sözde sınıfların sayısını sayın (= c).
- Seçicideki öğe adlarının ve sözde öğelerin sayısını sayma (= d)
a-b-c-d dört sayısının birleştirilmesi (büyük tabanlı bir sayı sisteminde) özgünlüğü sağlar.
Kullanmanız gereken sayı tabanı, kategorilerden birinde sahip olduğunuz en yüksek sayıya göre belirlenir.
Örneğin, a=14 ise on altılık taban kullanabilirsiniz. a=17 olması ihtimali düşük olsa da 17 haneli bir sayı tabanına ihtiyacınız olacaktır. İkinci durum, aşağıdaki gibi bir seçici kullanıldığında ortaya çıkabilir: html body div div p… (Seçicinizde 17 etiket var… Bu olasılık çok düşüktür.)
Bazı örnekler:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Kuralları sıralama
Kurallar eşleştirildikten sonra basamak kuralına göre sıralanır.
WebKit, küçük listeler için kabarcık sıralama, büyük listeler için ise birleştirme sıralama kullanır.
WebKit, kurallar için > operatörünü geçersiz kılarak sıralamayı uygular:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Kademeli süreç
WebKit, tüm üst düzey stil sayfalarının ("@imports" dahil) yüklenip yüklenmediğini işaretleyen bir işaret kullanır. Stil eklenirken tam olarak yüklenmezse yer tutucular kullanılır ve dokümanda işaretlenir. Stil sayfaları yüklendikten sonra yeniden hesaplanır.
Düzen
Oluşturulan ve ağaca eklenen oluşturma aracının konumu ve boyutu yoktur. Bu değerlerin hesaplanmasına sayfa düzeni veya yeniden akış adı verilir.
HTML, akışa dayalı bir düzen modeli kullanır. Bu, çoğu zaman geometrinin tek bir geçişte hesaplanabileceği anlamına gelir. "Akışta" daha sonra gelen öğeler genellikle "akışta" daha önce gelen öğelerin geometrisini etkilemez. Bu nedenle, sayfa düzeni belgede soldan sağa, yukarıdan aşağıya doğru ilerleyebilir. Bununla birlikte, istisnalar da vardır. Örneğin, HTML tabloları için birden fazla geçiş gerekebilir.
Koordinat sistemi, kök çerçeveye göredir. Üst ve sol koordinatlar kullanılır.
Düzenleme, yinelemeli bir süreçtir. HTML dokümanının <html> öğesine karşılık gelen kök oluşturucuda başlar. Düzenleme, çerçeve hiyerarşisinin bir kısmında veya tamamında yinelemeli olarak devam eder ve bunu gerektiren her oluşturma aracı için geometrik bilgileri hesaplar.
Kök oluşturma aracının konumu 0,0'dır ve boyutları, tarayıcı penceresinin görünür kısmı olan görüntü alanıdır.
Tüm oluşturucuların bir "layout" veya "reflow" yöntemi vardır. Her oluşturucu, düzene ihtiyaç duyan alt öğelerinin layout yöntemini çağırır.
Kirli bit sistemi
Tarayıcılar, her küçük değişiklik için tam bir düzen oluşturmamak amacıyla "kirli bit" sistemi kullanır. Değiştirilen veya eklenen bir oluşturucu, kendisini ve alt öğelerini "kirli" olarak işaretler: düzene ihtiyaç duyar.
İki işaret vardır: "kirli" ve "alt öğeler kirli". Bu işaretler, oluşturucunun kendisi iyi olsa bile düzene ihtiyaç duyan en az bir alt öğesinin olduğu anlamına gelir.
Genel ve artımlı düzen
Düzen, oluşturma ağacının tamamında tetiklenebilir. Bu "evrensel" düzendir. Bu durum aşağıdakilerden kaynaklanabilir:
- Yazı tipi boyutu değişikliği gibi tüm oluşturma araçlarını etkileyen genel bir stil değişikliği.
- Ekranın yeniden boyutlandırılması
Düzen artan olabilir, yalnızca kirli oluşturucular düzenlenir (bu, ek düzenler gerektiren bazı hasarlara neden olabilir).
Oluşturucular kirli olduğunda artımlı düzen tetiklenir (eşzamansız olarak). Örneğin, ağdan gelen ek içerik DOM ağacına eklendikten sonra oluşturma ağacına yeni oluşturucular eklendiğinde.
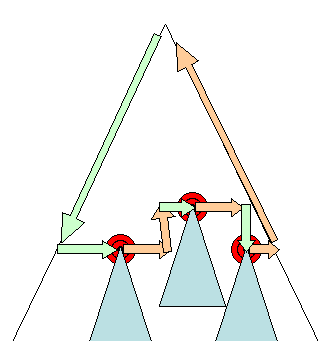
Eşzamansız ve eşzamanlı düzen
Artımlı düzen, eşzamansız olarak yapılır. Firefox, artımlı düzenler için "yeniden akış komutlarını" sıraya alır ve bir planlayıcı bu komutların toplu olarak yürütülmesini tetikler. WebKit'te, artımlı bir düzeni yürüten bir zamanlayıcı da vardır. Ağda gezinilir ve "kirli" oluşturma araçları düzenlenir.
"offsetHeight" gibi stil bilgileri isteyen komut dosyaları, artımlı düzeni senkronize olarak tetikleyebilir.
Genel düzen genellikle senkronize olarak tetiklenir.
Kaydırma konumu gibi bazı özellikler değiştiğinden, bazen düzen ilk düzenden sonra geri çağırma olarak tetiklenir.
Optimizasyonlar
Bir düzen "yeniden boyutlandırma" veya oluşturma konumunda(boyutta değil) bir değişiklik nedeniyle tetiklendiğinde, oluşturma boyutları bir önbellekten alınır ve yeniden hesaplanmaz…
Bazı durumlarda yalnızca bir alt ağaç değiştirilir ve düzen kökten başlamaz. Bu durum, değişikliğin yerel olduğu ve etrafındakileri etkilemediği durumlarda (ör. metin alanlarına eklenen metin) ortaya çıkabilir. Aksi takdirde her tuş vuruşu, kökten başlayan bir düzeni tetikler.
Düzenleme süreci
Düzen genellikle aşağıdaki kalıba sahiptir:
- Üst oluşturucu kendi genişliğini belirler.
- Üst reklamveren, alt reklamverenlerin üzerinden geçer ve:
- Alt oluşturucuyu yerleştirin (x ve y değerlerini ayarlar).
- Gerekirse alt öğe düzenini çağırır (öğeler kirliyse veya küresel bir düzendeysek ya da başka bir nedenle). Bu düzen, alt öğenin yüksekliğini hesaplar.
- Üst öğe, kendi yüksekliğini ayarlamak için alt öğelerin kümülatif yüksekliklerini ve kenar boşluklarının ve dolguların yüksekliklerini kullanır. Bu değer, üst öğe oluşturma aracının üst öğesi tarafından kullanılır.
- "Kirli" bitini yanlış olarak ayarlar.
Firefox, sayfa düzeni için parametre olarak bir "durum" nesnesi (nsHTMLReflowState) kullanır. Bu işleme "yeniden akış" adı verilir. Durum, diğerlerinin yanı sıra ebeveyn genişliğini içerir.
Firefox düzeninin çıkışı bir "metrics" nesnesi(nsHTMLReflowMetrics) olur. Oluşturucunun hesapladığı yüksekliği içerir.
Genişlik hesaplaması
Oluşturucunun genişliği, kapsayıcı bloğunun genişliği, oluşturucunun stil "genişlik" özelliği, kenar boşlukları ve kenarlıklar kullanılarak hesaplanır.
Örneğin, aşağıdaki div'in genişliği:
<div style="width: 30%"/>
WebKit tarafından aşağıdaki gibi hesaplanır(RenderBox sınıfı calcWidth yöntemi):
- Kapsayıcı genişliği, availableWidth kapsayıcısının ve 0 değerinin maksimumudur. Bu durumda availableWidth, contentWidth değeridir ve şu şekilde hesaplanır:
clientWidth() - paddingLeft() - paddingRight()
clientWidth ve clientHeight, kenarlığı ve kaydırma çubuğunu hariç tutarak bir nesnenin içini temsil eder.
Öğenin genişliği, "width" stil özelliğidir. Bu değer, kapsayıcı genişliğinin yüzdesi hesaplanarak mutlak değer olarak hesaplanır.
Yatay kenarlıklar ve dolgular eklendi.
Şimdiye kadar "tercih edilen genişlik" hesaplaması bu şekildeydi. Ardından minimum ve maksimum genişlikler hesaplanır.
Tercih edilen genişlik maksimum genişlikten büyükse maksimum genişlik kullanılır. Minimum genişlikten (en küçük bölünemez birim) azsa minimum genişlik kullanılır.
Bir düzene ihtiyaç duyulması ihtimaline karşı değerler önbelleğe alınır ancak genişlik değişmez.
Satır sonu
Bir düzenin ortasında bulunan bir oluşturucu, bölünmesi gerektiğine karar verdiğinde durur ve düzenin üst öğesine bölünmesi gerektiğini bildirir. Üst öğe, ek oluşturucular oluşturur ve bunlarda düzeni çağırır.
Resim
Boyama aşamasında, oluşturma ağacı taranır ve ekranda içerik görüntülemek için oluşturucunun "paint()" yöntemi çağrılır. Boyama, kullanıcı arayüzü altyapı bileşenini kullanır.
Genel ve artımlı
Düzenleme gibi boyama da genel olabilir (ağacın tamamı boyanır) veya artımlı olabilir. Artımlı boyamada, bazı oluşturma araçları ağacın tamamını etkilemeyecek şekilde değişir. Değiştirilen oluşturucu, ekrandaki dikdörtgenini geçersiz kılar. Bu, işletim sisteminin bu alanı "kirli bölge" olarak görmesine ve bir "boya" etkinliği oluşturmasına neden olur. İşletim sistemi bunu akıllıca yapar ve birkaç bölgeyi tek bir bölgede birleştirir. Chrome'da, oluşturma aracı ana işlemden farklı bir işlemde olduğu için bu işlem daha karmaşıktır. Chrome, işletim sistemi davranışını bir dereceye kadar simüle eder. Sunum bu etkinlikleri dinler ve mesajı oluşturma köküne atar. İlgili oluşturma aracına ulaşılana kadar ağaç taranacaktır. Kendini (ve genellikle alt öğelerini) yeniden boyar.
Boyama sırası
CSS2, boyama sürecinin sırasını tanımlar. Bu, aslında öğelerin yığın bağlamlarında yığıldığı sıradır. Gruplar arkadan öne doğru boyandığından bu sıra boyamayı etkiler. Bir blok oluşturma aracının yığılma sırası şu şekildedir:
- arka plan rengi
- arka plan resmi
- border
- çocuklar
- outline
Firefox görüntüleme listesi
Firefox, oluşturma ağacını inceler ve boyanmış dikdörtgen için bir görüntü listesi oluşturur. Dikdörtgenle alakalı oluşturucuları doğru boyama sırasına göre (oluşturucuların arka planları, ardından kenarlıklar vb.) içerir.
Bu sayede, ağacın yeniden boyanması için birkaç kez yerine yalnızca bir kez dolaşılması gerekir. Önce tüm arka planlar, ardından tüm resimler, ardından tüm kenarlıklar vb. boyanır.
Firefox, tamamen diğer opak öğelerin altında olan öğeler gibi gizlenecek öğeler eklemeyerek süreci optimize eder.
WebKit dikdörtgen depolama alanı
WebKit, yeniden boyamadan önce eski dikdörtgeni bitmap olarak kaydeder. Ardından, yalnızca yeni ve eski dikdörtgenler arasındaki farkı boyar.
Dinamik değişiklikler
Tarayıcılar, bir değişikliğe yanıt olarak mümkün olan en az işlemi yapmaya çalışır. Bu nedenle, bir öğenin renginde yapılan değişiklikler yalnızca öğenin yeniden boyanmasına neden olur. Öğenin konumunda yapılan değişiklikler, öğenin, alt öğelerinin ve muhtemelen kardeşlerinin yeniden düzenlenmesine ve yeniden boyanmasına neden olur. DOM düğümü eklemek, düğümün düzenlenmesine ve yeniden boyanmasına neden olur. "html" öğesinin yazı tipi boyutunu artırmak gibi önemli değişiklikler, önbellekleri geçersiz kılar, ağacın tamamını yeniden düzenler ve yeniden boyar.
Oluşturma motorunun iş parçacıkları
Oluşturma motoru tek iş parçacıklıdır. Ağ işlemleri hariç neredeyse her şey tek bir iş parçacığında gerçekleşir. Firefox ve Safari'de bu, tarayıcının ana mesaj dizisidir. Chrome'da bu, sekme işleminin ana mesaj dizisidir.
Ağ işlemleri birkaç paralel iş parçacığı tarafından gerçekleştirilebilir. Paralel bağlantı sayısı sınırlıdır (genellikle 2-6 bağlantı).
Etkinlik döngüsü
Tarayıcı ana iş parçacığı bir etkinlik döngüsüdür. Bu, süreci canlı tutan sonsuz bir döngüdür. Etkinlikleri (düzenleme ve boyama etkinlikleri gibi) bekler ve işler. Aşağıda, ana etkinlik döngüsü için Firefox kodu verilmiştir:
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 görsel modeli
Tuval
CSS2 spesifikasyonuna göre, tuval terimi "biçimlendirme yapısının oluşturulduğu alanı", yani tarayıcının içeriği boyadığı alanı tanımlar.
Tuval, alanın her boyutu için sonsuzdur ancak tarayıcılar, görünüm alanının boyutlarına göre bir ilk genişlik seçer.
www.w3.org/TR/CSS2/zindex.html adresine göre, kanvas başka bir öğenin içindeyse şeffaftır, aksi takdirde tarayıcı tarafından tanımlanan bir renge sahip olur.
CSS kutusu modeli
CSS kutu modeli, belge ağacındaki öğeler için oluşturulan ve görsel biçimlendirme modeline göre düzenlenen dikdörtgen kutuları tanımlar.
Her kutunun bir içerik alanı (ör. metin, resim vb.) ve isteğe bağlı olarak çevreleyen dolgu, kenar ve kenar boşluğu alanları vardır.
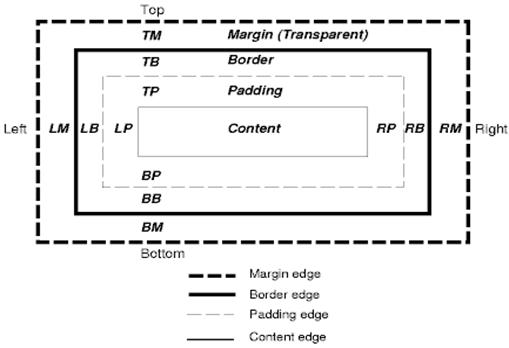
Her düğüm 0 ila n tane böyle kutu oluşturur.
Tüm öğelerin, oluşturulacak kutunun türünü belirleyen bir "display" özelliği vardır.
Örnekler:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
Varsayılan değer satır içidir ancak tarayıcı stil sayfası başka varsayılan değerler belirleyebilir. Örneğin: "div" öğesinin varsayılan gösterimi bloktur.
Varsayılan stil sayfası örneğini burada bulabilirsiniz: www.w3.org/TR/CSS2/sample.html.
Konumlandırma şeması
Üç şema vardır:
- Normal: Nesne, dokümandaki yerine göre konumlandırılır. Bu, oluşturma ağacındaki yerinin DOM ağacındaki yerine benzediği ve kutu türüne ve boyutlarına göre düzenlendiği anlamına gelir.
- Yüzen: Nesne önce normal akış gibi düzenlenir, ardından mümkün olduğunca sola veya sağa taşınır.
- Mutlak: Nesne, oluşturma ağacına DOM ağacından farklı bir yere yerleştirilir.
Konumlandırma şeması, "position" mülkü ve "float" özelliği tarafından belirlenir.
- statik ve göreli normal bir akışa neden olur
- mutlak ve sabit, mutlak konumlandırmaya neden olur
Statik konumlandırmada konum tanımlanmaz ve varsayılan konumlandırma kullanılır. Diğer şemalara yazar tarafından konum belirtilir: üst, alt, sol, sağ.
Kutunun düzeni şu faktörlere göre belirlenir:
- Kutu türü
- Kutu boyutları
- Konumlandırma şeması
- Resim boyutu ve ekran boyutu gibi harici bilgiler
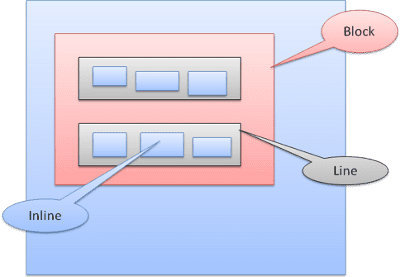
Kutu türleri
Engelleme kutusu: Bir blok oluşturur. Tarayıcı penceresinde kendi dikdörtgeni vardır.

Satır içi kutu: Kendi bloğuna sahip değildir ancak kapsayıcı bir bloğun içindedir.
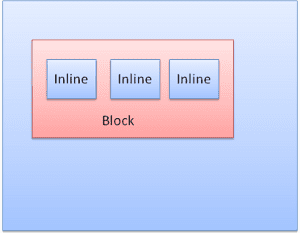
Bloklar, birbiri ardına dikey olarak biçimlendirilir. Satır içi öğeler yatay olarak biçimlendirilir.
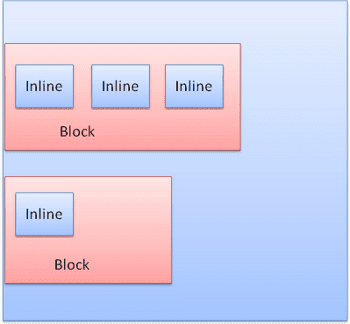
Satır içi kutular, satırların veya "satır kutularının" içine yerleştirilir. Çizgiler en az en yüksek kutunun yüksekliğindedir ancak kutular "referans değeri"yle hizalandığında daha yüksek olabilir. Bu, bir öğenin alt kısmının, alttan başka bir kutunun bir noktasında hizalandığı anlamına gelir. Kapsayıcı genişliği yeterli değilse satır içi öğeler birkaç satıra yerleştirilir. Bu genellikle bir paragrafta olur.
Konumlandırma
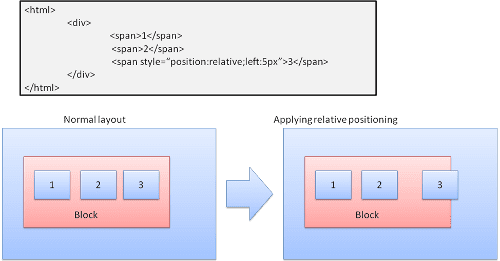
Akraba
Göreli konumlandırma: Normal şekilde konumlandırılır ve ardından gereken delta kadar hareket ettirilir.
Kayanlar
Yüzen kutu, bir satırın soluna veya sağına kaydırılır. İlginç bir özellik de diğer kutuların etrafında akmasıdır. HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Şu şekilde görünür:

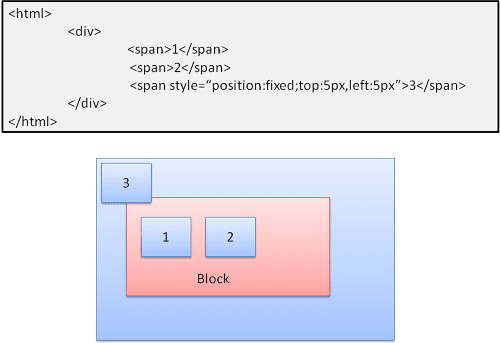
Mutlak ve sabit
Düzen, normal akıştan bağımsız olarak tam olarak tanımlanır. Öğe normal akışa dahil değildir. Boyutlar kapsayıcıya göredir. Sabit durumda kapsayıcı, görüntü alanıdır.
Katmanlı temsil
Bu, z-index CSS mülkü tarafından belirtilir. Kutunun üçüncü boyutunu (yani "z ekseni"ndeki konumunu) temsil eder.
Kutular, yığınlara (yığın bağlamı olarak adlandırılır) ayrılır. Her grupta önce arkadaki öğeler, ardından kullanıcıya daha yakın olan öndeki öğeler boyanır. Örtüşme durumunda en öndeki öğe önceki öğeyi gizler.
Gruplar, z-endeksi özelliğine göre sıralanır. "z-index" özelliğine sahip kutular yerel bir grup oluşturur. Görüntü alanında dış yığın bulunur.
Örnek:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Sonuç şu şekilde olur:

Kırmızı div, işaretlemede yeşil div'den önce gelir ve normal akışta daha önce boyanırdı. Ancak z-endeksi özelliği daha yüksek olduğundan kök kutu tarafından tutulan yığınta daha ileridedir.
Kaynaklar
Tarayıcı mimarisi
- Grosskurth, Alan. Web Tarayıcıları İçin Referans Mimari (pdf)
- Gupta, Vineet. Tarayıcıların İşleyiş Şekli - 1. Bölüm - Mimari
Ayrıştırma
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools ("Dragon book" olarak da bilinir), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: HTML 5 için iki yeni taslak.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Daha Hızlı HTML ve CSS: Web Geliştiricileri İçin İçerik Motoru İçeriği).
- L. David Baron, Daha Hızlı HTML ve CSS: Web Geliştiricileri İçin İçerik Oluşturma Motoru İçeriği (Google teknik konuşması videosu)
- L. David Baron, Mozilla'nın Düzenleme Motoru
- L. David Baron, Mozilla Stilinde Sistem Dokümanları
- Chris Waterson, HTML Reflow ile ilgili notlar
- Chris Waterson, Gecko'ya Genel Bakış
- Alexander Larsson, HTML HTTP isteğinin ömrü
WebKit
- David Hyatt, CSS'yi uygulama(1. bölüm)
- David Hyatt, WebCore'a Genel Bakış
- David Hyatt, WebCore Oluşturma
- David Hyatt, The FOUC Problem
W3C Spesifikasyonları
Tarayıcılar için derleme talimatları
Çeviriler
Bu sayfa Japoncaya iki kez çevrilmiştir:
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) @kosei tarafından
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 @ikeike443 ve @kiyoto01 tarafından.
Korece ve Türkçe dillerinde harici olarak barındırılan çevirileri görüntüleyebilirsiniz.
Hepinize teşekkürler.