
Hậu trường của trình duyệt web hiện đại


Lời nói đầu
Tài liệu hướng dẫn toàn diện này về hoạt động nội bộ của WebKit và Gecko là kết quả của nhiều nghiên cứu do nhà phát triển người Israel Tali Garsiel thực hiện. Trong vài năm, cô đã xem xét tất cả dữ liệu đã xuất bản về nội bộ trình duyệt và dành nhiều thời gian để đọc mã nguồn trình duyệt web. Cô viết:
Là một nhà phát triển web, việc tìm hiểu nội dung bên trong của các hoạt động của trình duyệt giúp bạn đưa ra quyết định sáng suốt hơn và biết lý do đằng sau các phương pháp hay nhất về phát triển. Mặc dù đây là một tài liệu khá dài, nhưng bạn nên dành thời gian tìm hiểu. Bạn sẽ hài lòng với những gì bạn thiết lập.
Paul Irish, Nhà quản lý quan hệ đối tác với nhà phát triển Chrome
Giới thiệu
Trình duyệt web là phần mềm được sử dụng rộng rãi nhất. Trong bài viết này, tôi sẽ giải thích cách hoạt động của các lớp này. Chúng ta sẽ xem điều gì xảy ra khi bạn nhập google.com vào thanh địa chỉ cho đến khi thấy trang Google trên màn hình trình duyệt.
Các trình duyệt mà chúng ta sẽ đề cập
Hiện nay, có 5 trình duyệt chính được dùng trên máy tính: Chrome, Internet Explorer, Firefox, Safari và Opera. Trên thiết bị di động, các trình duyệt chính là Trình duyệt Android, iPhone, Opera Mini và Opera Mobile, UC Browser, trình duyệt Nokia S40/S60 và Chrome. Tất cả các trình duyệt này (ngoại trừ trình duyệt Opera) đều dựa trên WebKit. Tôi sẽ đưa ra ví dụ từ các trình duyệt nguồn mở Firefox và Chrome, cũng như Safari (một phần là nguồn mở). Theo số liệu thống kê của StatCounter (tính đến tháng 6 năm 2013), Chrome, Firefox và Safari chiếm khoảng 71% mức sử dụng trình duyệt trên máy tính trên toàn cầu. Trên thiết bị di động, Trình duyệt Android, iPhone và Chrome chiếm khoảng 54% mức sử dụng.
Chức năng chính của trình duyệt
Chức năng chính của trình duyệt là hiển thị tài nguyên web mà bạn chọn bằng cách yêu cầu tài nguyên đó từ máy chủ và hiển thị tài nguyên đó trong cửa sổ trình duyệt. Tài nguyên thường là tài liệu HTML, nhưng cũng có thể là tệp PDF, hình ảnh hoặc một số loại nội dung khác. Người dùng chỉ định vị trí của tài nguyên bằng cách sử dụng URI (Mã nhận dạng tài nguyên thống nhất).
Cách trình duyệt diễn giải và hiển thị tệp HTML được chỉ định trong quy cách HTML và CSS. Các thông số kỹ thuật này do tổ chức W3C (World Wide Web Consortium) duy trì. Đây là tổ chức tiêu chuẩn cho web. Trong nhiều năm, các trình duyệt chỉ tuân thủ một phần thông số kỹ thuật và phát triển các tiện ích riêng. Điều đó đã gây ra các vấn đề nghiêm trọng về khả năng tương thích cho các tác giả web. Ngày nay, hầu hết các trình duyệt đều tuân thủ các thông số kỹ thuật.
Giao diện người dùng của trình duyệt có nhiều điểm chung với nhau. Sau đây là một số phần tử giao diện người dùng phổ biến:
- Thanh địa chỉ để chèn URI
- Nút quay lại và nút chuyển tiếp
- Tuỳ chọn đánh dấu trang
- Nút làm mới và dừng để làm mới hoặc dừng tải các tài liệu hiện tại
- Nút màn hình chính đưa bạn đến trang chủ
Lạ lùng thay, giao diện người dùng của trình duyệt không được chỉ định trong bất kỳ quy cách chính thức nào, mà chỉ đến từ các phương pháp hay được hình thành qua nhiều năm kinh nghiệm và các trình duyệt bắt chước lẫn nhau. Quy cách HTML5 không xác định các thành phần giao diện người dùng mà trình duyệt phải có, nhưng liệt kê một số thành phần phổ biến. Trong số đó có thanh địa chỉ, thanh trạng thái và thanh công cụ. Tất nhiên, có những tính năng chỉ dành riêng cho một trình duyệt cụ thể như trình quản lý tệp tải xuống của Firefox.
Cơ sở hạ tầng cấp cao
Các thành phần chính của trình duyệt là:
- Giao diện người dùng: bao gồm thanh địa chỉ, nút quay lại/tiến, trình đơn đánh dấu trang, v.v. Mọi phần của màn hình trình duyệt ngoại trừ cửa sổ nơi bạn thấy trang được yêu cầu.
- Công cụ trình duyệt: điều phối các thao tác giữa giao diện người dùng và công cụ kết xuất.
- Công cụ kết xuất: chịu trách nhiệm hiển thị nội dung được yêu cầu. Ví dụ: nếu nội dung được yêu cầu là HTML, thì công cụ kết xuất sẽ phân tích cú pháp HTML và CSS, đồng thời hiển thị nội dung đã phân tích cú pháp trên màn hình.
- Mạng: đối với các lệnh gọi mạng như yêu cầu HTTP, sử dụng các phương thức triển khai khác nhau cho các nền tảng khác nhau đằng sau giao diện độc lập với nền tảng.
- Phần phụ trợ giao diện người dùng: dùng để vẽ các tiện ích cơ bản như hộp kết hợp và cửa sổ. Phần phụ trợ này hiển thị một giao diện chung không dành riêng cho nền tảng. Bên dưới, lớp này sử dụng các phương thức giao diện người dùng của hệ điều hành.
- Trình thông dịch JavaScript. Dùng để phân tích cú pháp và thực thi mã JavaScript.
- Lưu trữ dữ liệu. Đây là một lớp ổn định. Trình duyệt có thể cần lưu tất cả các loại dữ liệu trên máy, chẳng hạn như cookie. Trình duyệt cũng hỗ trợ các cơ chế lưu trữ như localStorage, IndexedDB, WebSQL và FileSystem.
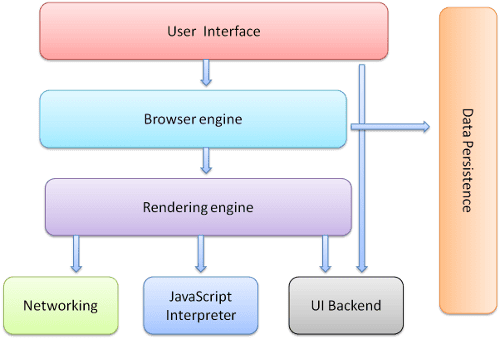
Điều quan trọng cần lưu ý là các trình duyệt như Chrome chạy nhiều phiên bản của công cụ kết xuất: một phiên bản cho mỗi thẻ. Mỗi thẻ chạy trong một quy trình riêng.
Công cụ kết xuất
Công việc của công cụ kết xuất là… Kết xuất, tức là hiển thị nội dung được yêu cầu trên màn hình trình duyệt.
Theo mặc định, công cụ kết xuất có thể hiển thị tài liệu và hình ảnh HTML và XML. WebView có thể hiển thị các loại dữ liệu khác thông qua trình bổ trợ hoặc tiện ích; ví dụ: hiển thị tài liệu PDF bằng trình bổ trợ trình xem PDF. Tuy nhiên, trong chương này, chúng ta sẽ tập trung vào trường hợp sử dụng chính: hiển thị HTML và hình ảnh được định dạng bằng CSS.
Các trình duyệt khác nhau sử dụng các công cụ kết xuất khác nhau: Internet Explorer sử dụng Trident, Firefox sử dụng Gecko, Safari sử dụng WebKit. Chrome và Opera (từ phiên bản 15) sử dụng Blink, một nhánh của WebKit.
WebKit là một công cụ kết xuất nguồn mở, ban đầu là công cụ cho nền tảng Linux và được Apple sửa đổi để hỗ trợ Mac và Windows.
Luồng chính
Công cụ kết xuất sẽ bắt đầu nhận nội dung của tài liệu được yêu cầu từ lớp kết nối mạng. Quá trình này thường được thực hiện theo các đoạn 8 kB.
Sau đó, đây là quy trình cơ bản của công cụ kết xuất:

Công cụ kết xuất sẽ bắt đầu phân tích cú pháp tài liệu HTML và chuyển đổi các phần tử thành nút DOM trong một cây có tên là "cây nội dung". Công cụ này sẽ phân tích cú pháp dữ liệu kiểu, cả trong tệp CSS bên ngoài và trong các phần tử kiểu. Thông tin định kiểu cùng với hướng dẫn trực quan trong HTML sẽ được dùng để tạo một cây khác: cây kết xuất.
Cây kết xuất chứa các hình chữ nhật có các thuộc tính hình ảnh như màu sắc và kích thước. Các hình chữ nhật được hiển thị trên màn hình theo đúng thứ tự.
Sau khi tạo cây kết xuất, cây này sẽ trải qua quy trình "bố cục". Điều này có nghĩa là cung cấp cho mỗi nút toạ độ chính xác nơi nút đó sẽ xuất hiện trên màn hình. Giai đoạn tiếp theo là vẽ – cây kết xuất sẽ được duyệt qua và mỗi nút sẽ được vẽ bằng lớp phụ trợ giao diện người dùng.
Điều quan trọng là bạn phải hiểu rằng đây là một quá trình diễn ra từ từ. Để mang lại trải nghiệm tốt hơn cho người dùng, công cụ kết xuất sẽ cố gắng hiển thị nội dung trên màn hình sớm nhất có thể. Phương thức này sẽ không đợi đến khi tất cả HTML được phân tích cú pháp trước khi bắt đầu tạo và bố cục cây kết xuất. Một số phần nội dung sẽ được phân tích cú pháp và hiển thị, trong khi quá trình này tiếp tục với phần nội dung còn lại liên tục đến từ mạng.
Ví dụ về luồng chính
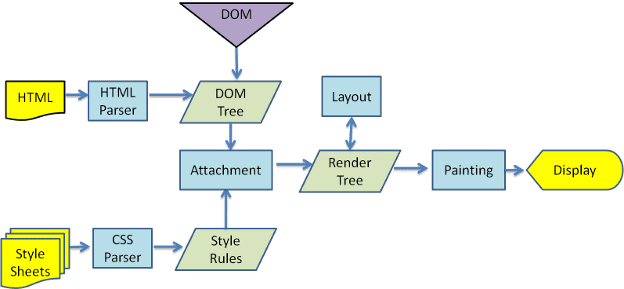
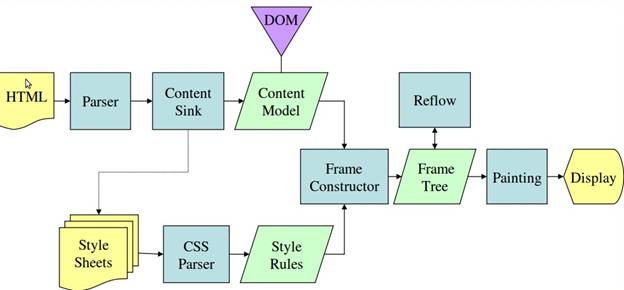
Từ hình 3 và 4, bạn có thể thấy mặc dù WebKit và Gecko sử dụng các thuật ngữ hơi khác nhau, nhưng quy trình về cơ bản là giống nhau.
Gecko gọi cây các phần tử được định dạng trực quan là "Cây khung". Mỗi phần tử là một khung. WebKit sử dụng thuật ngữ "Render Tree" (Cây kết xuất) và thuật ngữ này bao gồm "Render Objects" (Đối tượng kết xuất). WebKit sử dụng thuật ngữ "bố cục" để đặt các phần tử, còn Gecko gọi là "Lưu lại". "Tệp đính kèm" là thuật ngữ của WebKit để kết nối các nút DOM và thông tin hình ảnh nhằm tạo cây kết xuất. Một điểm khác biệt nhỏ không mang tính ngữ nghĩa là Gecko có thêm một lớp giữa HTML và cây DOM. Thành phần này được gọi là "vùng chứa nội dung" và là một nhà máy để tạo các phần tử DOM. Chúng ta sẽ thảo luận về từng phần của quy trình:
Phân tích cú pháp – chung
Vì việc phân tích cú pháp là một quá trình rất quan trọng trong công cụ kết xuất, nên chúng ta sẽ tìm hiểu kỹ hơn một chút về quá trình này. Hãy bắt đầu bằng một phần giới thiệu ngắn về việc phân tích cú pháp.
Phân tích cú pháp tài liệu có nghĩa là dịch tài liệu đó thành một cấu trúc mà mã có thể sử dụng. Kết quả của quá trình phân tích cú pháp thường là một cây gồm các nút đại diện cho cấu trúc của tài liệu. Đây được gọi là cây phân tích cú pháp hoặc cây cú pháp.
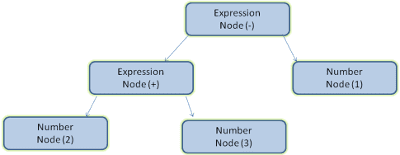
Ví dụ: việc phân tích cú pháp biểu thức 2 + 3 - 1 có thể trả về cây này:
Ngữ pháp
Quá trình phân tích cú pháp dựa trên các quy tắc cú pháp mà tài liệu tuân theo: ngôn ngữ hoặc định dạng mà tài liệu được viết. Mọi định dạng mà bạn có thể phân tích cú pháp đều phải có ngữ pháp xác định bao gồm từ vựng và quy tắc cú pháp. Ngôn ngữ này được gọi là ngữ pháp không có ngữ cảnh. Ngôn ngữ của con người không phải là ngôn ngữ như vậy và do đó không thể được phân tích cú pháp bằng các kỹ thuật phân tích cú pháp thông thường.
Trình phân tích cú pháp – Kết hợp Lexer
Quá trình phân tích cú pháp có thể được chia thành hai quy trình phụ: phân tích từ vựng và phân tích cú pháp.
Phân tích cú pháp từ vựng là quá trình chia dữ liệu đầu vào thành các mã thông báo. Mã thông báo là từ vựng ngôn ngữ: tập hợp các khối hợp lệ. Trong ngôn ngữ của con người, từ vựng sẽ bao gồm tất cả các từ xuất hiện trong từ điển của ngôn ngữ đó.
Phân tích cú pháp là việc áp dụng các quy tắc cú pháp của ngôn ngữ.
Trình phân tích cú pháp thường chia công việc giữa hai thành phần: trình phân tích cú pháp (đôi khi được gọi là trình tạo mã thông báo) chịu trách nhiệm chia dữ liệu đầu vào thành các mã thông báo hợp lệ và trình phân tích cú pháp chịu trách nhiệm tạo cây phân tích cú pháp bằng cách phân tích cấu trúc tài liệu theo quy tắc cú pháp ngôn ngữ.
Trình phân tích cú pháp biết cách loại bỏ các ký tự không liên quan như khoảng trắng và dấu ngắt dòng.
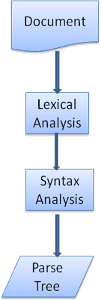
Quá trình phân tích cú pháp là lặp lại. Trình phân tích cú pháp thường sẽ yêu cầu trình phân tích cú pháp cung cấp một mã thông báo mới và cố gắng so khớp mã thông báo đó với một trong các quy tắc cú pháp. Nếu một quy tắc được so khớp, một nút tương ứng với mã thông báo sẽ được thêm vào cây phân tích cú pháp và trình phân tích cú pháp sẽ yêu cầu một mã thông báo khác.
Nếu không có quy tắc nào khớp, trình phân tích cú pháp sẽ lưu trữ mã thông báo trong nội bộ và tiếp tục yêu cầu mã thông báo cho đến khi tìm thấy một quy tắc khớp với tất cả mã thông báo được lưu trữ trong nội bộ. Nếu không tìm thấy quy tắc nào, trình phân tích cú pháp sẽ gửi một trường hợp ngoại lệ. Điều này có nghĩa là tài liệu không hợp lệ và chứa lỗi cú pháp.
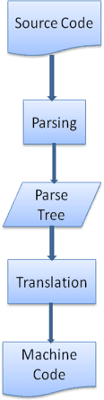
Dịch thuật
Trong nhiều trường hợp, cây phân tích cú pháp không phải là sản phẩm cuối cùng. Phân tích cú pháp thường được dùng trong quá trình dịch: chuyển đổi tài liệu đầu vào sang một định dạng khác. Ví dụ: biên dịch. Trước tiên, trình biên dịch biên dịch mã nguồn thành mã máy sẽ phân tích cú pháp mã nguồn thành cây phân tích cú pháp, sau đó dịch cây này thành tài liệu mã máy.
Ví dụ về phân tích cú pháp
Trong hình 5, chúng ta đã tạo một cây phân tích cú pháp từ một biểu thức toán học. Hãy thử xác định một ngôn ngữ toán học đơn giản và xem quy trình phân tích cú pháp.
Cú pháp:
- Các thành phần cú pháp ngôn ngữ là biểu thức, thuật ngữ và toán tử.
- Ngôn ngữ của chúng ta có thể bao gồm số lượng biểu thức bất kỳ.
- Biểu thức được xác định là một "thông số", theo sau là một "toán tử", theo sau là một thông số khác
- Một phép toán là một mã thông báo cộng hoặc mã thông báo trừ
- Một thuật ngữ là một mã thông báo số nguyên hoặc một biểu thức
Hãy cùng phân tích dữ liệu đầu vào 2 + 3 - 1.
Chuỗi con đầu tiên khớp với một quy tắc là 2: theo quy tắc #5, đây là một thuật ngữ.
Kết quả khớp thứ hai là 2 + 3: kết quả này khớp với quy tắc thứ ba: một thuật toán theo sau là một toán tử theo sau là một thuật toán khác.
Tiêu đề khớp tiếp theo sẽ chỉ được tìm thấy ở cuối dữ liệu đầu vào.
2 + 3 - 1 là một biểu thức vì chúng ta đã biết 2 + 3 là một thuật toán, vì vậy, chúng ta có một thuật toán theo sau là một phép toán và theo sau là một thuật toán khác.
2 + + sẽ không khớp với quy tắc nào nên là dữ liệu đầu vào không hợp lệ.
Định nghĩa chính thức về từ vựng và cú pháp
Từ vựng thường được biểu thị bằng biểu thức chính quy.
Ví dụ: ngôn ngữ của chúng ta sẽ được xác định là:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Như bạn thấy, số nguyên được xác định bằng một biểu thức chính quy.
Cú pháp thường được xác định theo định dạng BNF. Ngôn ngữ của chúng ta sẽ được xác định là:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Chúng ta đã nói rằng một ngôn ngữ có thể được các trình phân tích cú pháp thông thường phân tích cú pháp nếu cú pháp của ngôn ngữ đó là cú pháp không có ngữ cảnh. Một định nghĩa trực quan về cú pháp không có ngữ cảnh là cú pháp có thể được biểu thị hoàn toàn bằng BNF. Để biết định nghĩa chính thức, hãy xem bài viết trên Wikipedia về Ngữ pháp không có ngữ cảnh
Các loại trình phân tích cú pháp
Có hai loại trình phân tích cú pháp: trình phân tích cú pháp từ trên xuống và trình phân tích cú pháp từ dưới lên. Giải thích trực quan là trình phân tích cú pháp từ trên xuống kiểm tra cấu trúc cấp cao của cú pháp và cố gắng tìm một quy tắc khớp. Trình phân tích cú pháp từ dưới lên bắt đầu từ dữ liệu đầu vào và dần chuyển đổi dữ liệu đó thành các quy tắc cú pháp, bắt đầu từ các quy tắc cấp thấp cho đến khi đáp ứng các quy tắc cấp cao.
Hãy xem cách hai loại trình phân tích cú pháp sẽ phân tích cú pháp ví dụ của chúng ta.
Trình phân tích cú pháp từ trên xuống sẽ bắt đầu từ quy tắc cấp cao hơn: trình phân tích cú pháp này sẽ xác định 2 + 3 là một biểu thức. Sau đó, trình biên dịch sẽ xác định 2 + 3 - 1 là một biểu thức (quy trình xác định biểu thức sẽ phát triển, khớp với các quy tắc khác, nhưng điểm bắt đầu là quy tắc cấp cao nhất).
Trình phân tích cú pháp từ dưới lên sẽ quét dữ liệu đầu vào cho đến khi khớp một quy tắc. Sau đó, hàm này sẽ thay thế dữ liệu đầu vào khớp bằng quy tắc. Quá trình này sẽ tiếp tục cho đến khi kết thúc dữ liệu đầu vào. Biểu thức được so khớp một phần được đặt trên ngăn xếp của trình phân tích cú pháp.
Loại trình phân tích cú pháp từ dưới lên này được gọi là trình phân tích cú pháp giảm dần, vì dữ liệu đầu vào được dịch chuyển sang phải (hãy tưởng tượng một con trỏ trỏ vào đầu dữ liệu đầu vào và di chuyển sang phải) và dần dần được giảm xuống thành các quy tắc cú pháp.
Tự động tạo trình phân tích cú pháp
Có một số công cụ có thể tạo trình phân tích cú pháp. Bạn cung cấp cho chúng ngữ pháp của ngôn ngữ – từ vựng và quy tắc cú pháp – và chúng sẽ tạo một trình phân tích cú pháp đang hoạt động. Việc tạo trình phân tích cú pháp đòi hỏi bạn phải hiểu rõ về việc phân tích cú pháp và không dễ để tạo trình phân tích cú pháp được tối ưu hoá theo cách thủ công. Vì vậy, trình tạo trình phân tích cú pháp có thể rất hữu ích.
WebKit sử dụng hai trình tạo trình phân tích cú pháp nổi tiếng: Flex để tạo trình phân tích cú pháp và Bison để tạo trình phân tích cú pháp (bạn có thể gặp các trình phân tích cú pháp này với tên Lex và Yacc). Dữ liệu đầu vào Flex là một tệp chứa các định nghĩa biểu thức chính quy của mã thông báo. Dữ liệu đầu vào của Bison là các quy tắc cú pháp ngôn ngữ ở định dạng BNF.
Trình phân tích cú pháp HTML
Công việc của trình phân tích cú pháp HTML là phân tích cú pháp mã đánh dấu HTML thành cây phân tích cú pháp.
Ngữ pháp HTML
Từ vựng và cú pháp của HTML được xác định trong các thông số kỹ thuật do tổ chức W3C tạo ra.
Như đã thấy trong phần giới thiệu về phân tích cú pháp, cú pháp ngữ pháp có thể được xác định chính thức bằng các định dạng như BNF.
Rất tiếc, tất cả các chủ đề về trình phân tích cú pháp thông thường đều không áp dụng cho HTML (tôi không đưa các chủ đề này ra chỉ để cho vui – chúng sẽ được dùng để phân tích cú pháp CSS và JavaScript). Không thể dễ dàng xác định HTML bằng cú pháp không có ngữ cảnh mà trình phân tích cú pháp cần.
Có một định dạng chính thức để xác định HTML – DTD (Định nghĩa loại tài liệu) – nhưng đây không phải là cú pháp ngữ pháp tự do ngữ cảnh.
Điều này có vẻ lạ khi nhìn qua; HTML khá giống với XML. Có rất nhiều trình phân tích cú pháp XML. Có một biến thể XML của HTML – XHTML – vậy điểm khác biệt lớn là gì?
Điểm khác biệt là phương pháp HTML "khoan dung" hơn: cho phép bạn bỏ qua một số thẻ nhất định (sau đó được thêm ngầm ẩn), hoặc đôi khi bỏ qua thẻ bắt đầu hoặc thẻ kết thúc, v.v. Nhìn chung, đây là cú pháp "mềm", trái ngược với cú pháp cứng và khắt khe của XML.
Chi tiết tưởng chừng như nhỏ này lại tạo ra sự khác biệt lớn. Một mặt, đây là lý do chính khiến HTML trở nên phổ biến: nó tha thứ cho lỗi của bạn và giúp nhà sáng tạo web dễ dàng làm việc. Mặt khác, điều này khiến việc viết cú pháp chính thức trở nên khó khăn. Tóm lại, các trình phân tích cú pháp thông thường không thể dễ dàng phân tích cú pháp HTML vì cú pháp của HTML không phải là cú pháp tự do ngữ cảnh. Trình phân tích cú pháp XML không thể phân tích cú pháp HTML.
DTD HTML
Định nghĩa HTML ở định dạng DTD. Định dạng này dùng để xác định các ngôn ngữ thuộc họ SGML. Định dạng này chứa các định nghĩa cho tất cả phần tử được phép, thuộc tính và hệ phân cấp của các phần tử đó. Như chúng ta đã thấy trước đó, DTD HTML không tạo thành một cú pháp không có ngữ cảnh.
Có một số biến thể của DTD. Chế độ nghiêm ngặt chỉ tuân thủ các thông số kỹ thuật, nhưng các chế độ khác có hỗ trợ việc đánh dấu mà trình duyệt từng sử dụng. Mục đích là để tương thích ngược với nội dung cũ. DTD nghiêm ngặt hiện tại tại đây: www.w3.org/TR/html4/strict.dtd
DOM
Cây đầu ra ("cây phân tích cú pháp") là một cây gồm các phần tử DOM và nút thuộc tính. DOM là viết tắt của Document Object Model (Mô hình đối tượng tài liệu). Đây là bản trình bày đối tượng của tài liệu HTML và giao diện của các phần tử HTML với thế giới bên ngoài như JavaScript.
Gốc của cây là đối tượng "Document" (Tài liệu).
DOM có mối quan hệ gần như một với một với mã đánh dấu. Ví dụ:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Mã đánh dấu này sẽ được dịch thành cây DOM sau:
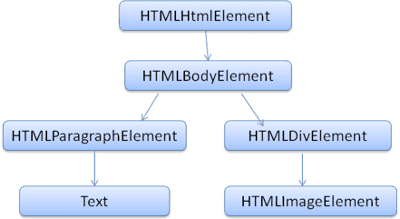
Giống như HTML, DOM do tổ chức W3C chỉ định. Xem www.w3.org/DOM/DOMTR. Đây là thông số kỹ thuật chung để thao tác với tài liệu. Một mô-đun cụ thể mô tả các phần tử cụ thể của HTML. Bạn có thể xem định nghĩa HTML tại đây: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Khi tôi nói cây chứa các nút DOM, tôi muốn nói rằng cây được tạo thành từ các phần tử triển khai một trong các giao diện DOM. Các trình duyệt sử dụng các phương thức triển khai cụ thể có các thuộc tính khác mà trình duyệt sử dụng nội bộ.
Thuật toán phân tích cú pháp
Như chúng ta đã thấy trong các phần trước, không thể phân tích cú pháp HTML bằng trình phân tích cú pháp thông thường từ trên xuống hoặc từ dưới lên.
Lý do là:
- Bản chất dễ tha thứ của ngôn ngữ.
- Thực tế là các trình duyệt có khả năng dung sai lỗi truyền thống để hỗ trợ các trường hợp HTML không hợp lệ đã biết.
- Quy trình phân tích cú pháp có thể truy cập lại. Đối với các ngôn ngữ khác, nguồn không thay đổi trong quá trình phân tích cú pháp, nhưng trong HTML, mã động (chẳng hạn như các phần tử tập lệnh chứa lệnh gọi
document.write()) có thể thêm các mã thông báo bổ sung, vì vậy, quá trình phân tích cú pháp thực sự sửa đổi dữ liệu đầu vào.
Không thể sử dụng các kỹ thuật phân tích cú pháp thông thường, trình duyệt sẽ tạo trình phân tích cú pháp tuỳ chỉnh để phân tích cú pháp HTML.
Thuật toán phân tích cú pháp được mô tả chi tiết trong quy cách HTML5. Thuật toán này bao gồm hai giai đoạn: mã hoá và tạo cây.
Mã hoá là quá trình phân tích từ vựng, phân tích cú pháp dữ liệu đầu vào thành mã thông báo. Trong số các mã thông báo HTML có thẻ bắt đầu, thẻ kết thúc, tên thuộc tính và giá trị thuộc tính.
Trình phân tích cú pháp nhận dạng mã thông báo, chuyển mã thông báo đó đến hàm khởi tạo cây và sử dụng ký tự tiếp theo để nhận dạng mã thông báo tiếp theo, v.v. cho đến khi kết thúc dữ liệu đầu vào.
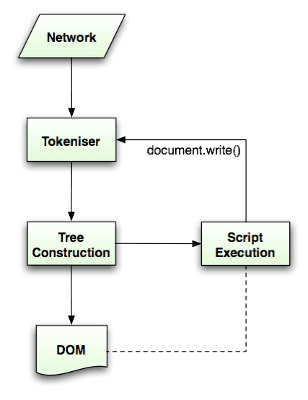
Thuật toán mã hoá
Kết quả của thuật toán là một mã thông báo HTML. Thuật toán được biểu thị dưới dạng một máy trạng thái. Mỗi trạng thái sử dụng một hoặc nhiều ký tự của luồng đầu vào và cập nhật trạng thái tiếp theo theo các ký tự đó. Quyết định này chịu ảnh hưởng của trạng thái mã hoá hiện tại và trạng thái tạo cây. Điều này có nghĩa là cùng một ký tự đã tiêu thụ sẽ mang lại kết quả khác nhau cho trạng thái tiếp theo chính xác, tuỳ thuộc vào trạng thái hiện tại. Thuật toán này quá phức tạp để mô tả đầy đủ, vì vậy, hãy xem một ví dụ đơn giản để giúp chúng ta hiểu được nguyên tắc.
Ví dụ cơ bản – tạo mã thông báo cho HTML sau:
<html>
<body>
Hello world
</body>
</html>
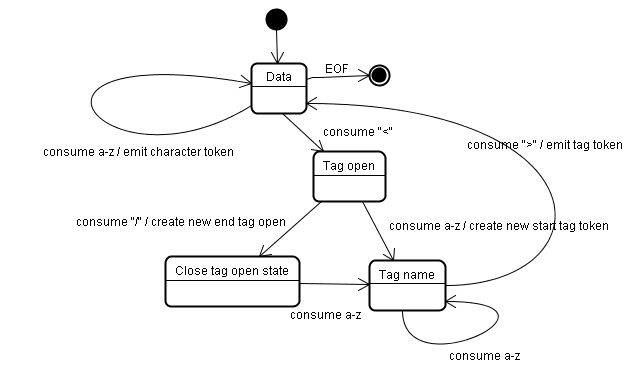
Trạng thái ban đầu là "Trạng thái dữ liệu".
Khi gặp ký tự <, trạng thái sẽ thay đổi thành "Trạng thái mở thẻ".
Việc sử dụng ký tự a-z sẽ tạo ra một "Giá trị bắt đầu của thẻ", trạng thái sẽ thay đổi thành "Trạng thái tên thẻ".
Chúng ta sẽ ở trạng thái này cho đến khi ký tự > được sử dụng. Mỗi ký tự được thêm vào tên mã thông báo mới. Trong trường hợp của chúng ta, mã thông báo được tạo là mã thông báo html.
Khi đến thẻ >, mã thông báo hiện tại sẽ được phát và trạng thái sẽ thay đổi trở lại thành "Trạng thái dữ liệu".
Thẻ <body> sẽ được xử lý theo các bước tương tự.
Cho đến nay, các thẻ html và body đã được phát ra. Chúng ta hiện đã quay lại phần "Trạng thái dữ liệu".
Việc sử dụng ký tự H của Hello world sẽ tạo và phát một mã thông báo ký tự, quá trình này sẽ tiếp tục cho đến khi đạt đến < của </body>. Chúng ta sẽ phát một mã thông báo ký tự cho mỗi ký tự của Hello world.
Chúng ta hiện đã quay lại "Trạng thái mở thẻ".
Việc sử dụng / đầu vào tiếp theo sẽ tạo ra một end tag token và chuyển sang "Trạng thái tên thẻ". Một lần nữa, chúng ta sẽ ở trạng thái này cho đến khi đạt đến >.Sau đó, mã thông báo thẻ mới sẽ được phát và chúng ta sẽ quay lại "Trạng thái dữ liệu".
Dữ liệu đầu vào </html> sẽ được xử lý như trường hợp trước.
Thuật toán tạo cây
Khi trình phân tích cú pháp được tạo, đối tượng Document sẽ được tạo. Trong giai đoạn tạo cây, cây DOM có Tài liệu ở gốc sẽ được sửa đổi và các phần tử sẽ được thêm vào cây đó. Mỗi nút do trình tạo mã thông báo phát ra sẽ được hàm khởi tạo cây xử lý. Đối với mỗi mã thông báo, thông số kỹ thuật xác định phần tử DOM nào có liên quan đến mã thông báo đó và sẽ được tạo cho mã thông báo này. Phần tử này được thêm vào cây DOM và cũng là ngăn xếp các phần tử đang mở. Ngăn xếp này dùng để sửa lỗi không khớp khi lồng và thẻ chưa đóng. Thuật toán này cũng được mô tả là một máy trạng thái. Các trạng thái này được gọi là "chế độ chèn".
Hãy xem quy trình tạo cây cho dữ liệu đầu vào mẫu:
<html>
<body>
Hello world
</body>
</html>
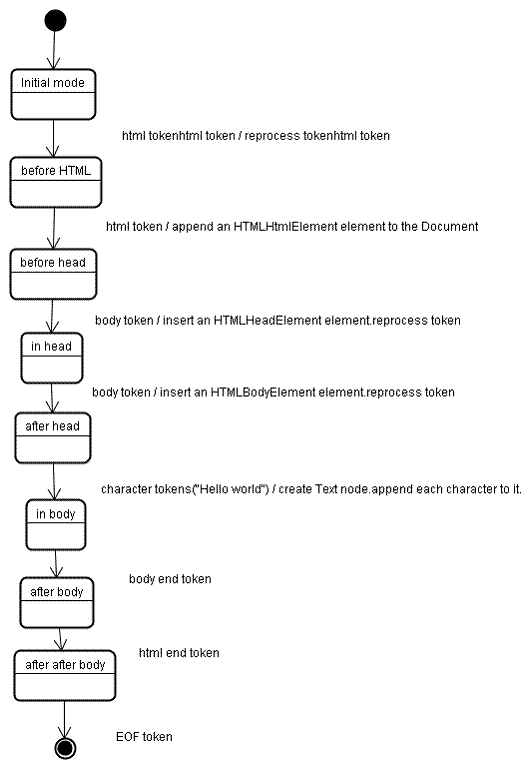
Dữ liệu đầu vào cho giai đoạn tạo cây là một chuỗi mã thông báo từ giai đoạn mã hoá. Chế độ đầu tiên là "chế độ ban đầu". Việc nhận mã thông báo "html" sẽ khiến bạn chuyển sang chế độ "trước html" và xử lý lại mã thông báo trong chế độ đó. Thao tác này sẽ tạo phần tử HTMLHtmlElement. Phần tử này sẽ được thêm vào đối tượng Document gốc.
Trạng thái sẽ được thay đổi thành "trước đầu". Sau đó, mã thông báo "body" sẽ được nhận. HTMLHeadElement sẽ được tạo ngầm mặc dù chúng ta không có mã thông báo "head" và mã này sẽ được thêm vào cây.
Bây giờ, chúng ta sẽ chuyển sang chế độ "in head" (trong đầu) rồi chuyển sang chế độ "after head" (sau đầu). Mã thông báo nội dung được xử lý lại, một HTMLBodyElement được tạo và chèn vào, đồng thời chế độ được chuyển sang "trong nội dung".
Giờ đây, bạn đã nhận được mã thông báo ký tự của chuỗi "Hello world". Ký tự đầu tiên sẽ tạo và chèn nút "Văn bản", còn các ký tự khác sẽ được thêm vào nút đó.
Việc nhận mã thông báo kết thúc nội dung sẽ chuyển sang chế độ "sau nội dung". Bây giờ, chúng ta sẽ nhận được thẻ kết thúc html, thẻ này sẽ chuyển chúng ta sang chế độ "sau phần nội dung". Việc nhận được mã thông báo kết thúc tệp sẽ kết thúc quá trình phân tích cú pháp.
Thao tác khi quá trình phân tích cú pháp hoàn tất
Ở giai đoạn này, trình duyệt sẽ đánh dấu tài liệu là tương tác và bắt đầu phân tích cú pháp các tập lệnh ở chế độ "đã trì hoãn": những tập lệnh sẽ được thực thi sau khi tài liệu được phân tích cú pháp. Sau đó, trạng thái tài liệu sẽ được đặt thành "hoàn tất" và sự kiện "tải" sẽ được kích hoạt.
Bạn có thể xem các thuật toán đầy đủ để tạo mã thông báo và xây dựng cây trong quy cách HTML5.
Mức độ chấp nhận lỗi của trình duyệt
Bạn không bao giờ gặp lỗi "Cú pháp không hợp lệ" trên trang HTML. Trình duyệt sẽ sửa mọi nội dung không hợp lệ và tiếp tục.
Lấy ví dụ về HTML sau:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Tôi phải đã vi phạm khoảng một triệu quy tắc ("mytag" không phải là thẻ chuẩn, lồng ghép sai các phần tử "p" và "div", v.v.) nhưng trình duyệt vẫn hiển thị chính xác và không phàn nàn. Vì vậy, nhiều mã trình phân tích cú pháp đang sửa lỗi của tác giả HTML.
Việc xử lý lỗi khá nhất quán trong các trình duyệt, nhưng đáng ngạc nhiên là việc này chưa có trong thông số kỹ thuật HTML. Giống như tính năng đánh dấu trang và các nút quay lại/tiến, đây chỉ là một tính năng được phát triển trong trình duyệt qua nhiều năm. Có một số cấu trúc HTML không hợp lệ được lặp lại trên nhiều trang web và trình duyệt cố gắng khắc phục các cấu trúc đó theo cách tương thích với các trình duyệt khác.
Quy cách HTML5 xác định một số yêu cầu này. (WebKit tóm tắt điều này một cách rõ ràng trong phần nhận xét ở đầu lớp trình phân tích cú pháp HTML.)
Trình phân tích cú pháp phân tích cú pháp dữ liệu đầu vào được mã hoá thành mã thông báo vào tài liệu, tạo ra cây tài liệu. Nếu tài liệu được định dạng đúng cách, việc phân tích cú pháp sẽ rất đơn giản.
Rất tiếc, chúng ta phải xử lý nhiều tài liệu HTML không được định dạng đúng cách, vì vậy, trình phân tích cú pháp phải có khả năng chấp nhận lỗi.
Chúng ta phải xử lý ít nhất các điều kiện lỗi sau:
- Phần tử đang được thêm bị cấm rõ ràng bên trong một số thẻ bên ngoài. Trong trường hợp này, chúng ta nên đóng tất cả các thẻ cho đến thẻ cấm phần tử đó, sau đó thêm phần tử đó.
- Chúng ta không được phép thêm trực tiếp phần tử này. Có thể người viết tài liệu đã quên một số thẻ ở giữa (hoặc thẻ ở giữa là không bắt buộc). Điều này có thể xảy ra với các thẻ sau: HTML HEAD BODY TBODY TR TD LI (tôi có quên thẻ nào không?).
- Chúng ta muốn thêm một phần tử khối bên trong một phần tử cùng dòng. Đóng tất cả phần tử cùng dòng cho đến phần tử khối cao hơn tiếp theo.
- Nếu cách này không hiệu quả, hãy đóng các phần tử cho đến khi chúng ta được phép thêm phần tử hoặc bỏ qua thẻ.
Hãy xem một số ví dụ về khả năng dung sai lỗi của WebKit:
</br> thay vì <br>
Một số trang web sử dụng </br> thay vì <br>. Để tương thích với IE và Firefox, WebKit sẽ coi đây là <br>.
Mã:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Xin lưu ý rằng việc xử lý lỗi là nội bộ: người dùng sẽ không thấy lỗi.
Một bảng lạc chỗ
Bảng lạc là một bảng nằm bên trong một bảng khác, nhưng không nằm bên trong ô của bảng.
Ví dụ:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit sẽ thay đổi hệ phân cấp thành hai bảng đồng cấp:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Mã:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit sử dụng ngăn xếp cho nội dung phần tử hiện tại: ngăn xếp này sẽ đẩy bảng bên trong ra khỏi ngăn xếp bảng bên ngoài. Giờ đây, các bảng sẽ là bảng đồng cấp.
Các phần tử biểu mẫu được lồng
Trong trường hợp người dùng đặt một biểu mẫu bên trong một biểu mẫu khác, thì biểu mẫu thứ hai sẽ bị bỏ qua.
Mã:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Hệ phân cấp thẻ quá sâu
Bình luận đó đã tự nói lên tất cả.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Đặt nhầm thẻ html hoặc thẻ đóng nội dung
Xin nhắc lại rằng bình luận đó đã nói lên tất cả.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Vì vậy, các tác giả trang web hãy cẩn thận – trừ phi bạn muốn xuất hiện dưới dạng ví dụ trong đoạn mã dung sai lỗi WebKit – hãy viết HTML được định dạng đúng cách.
Phân tích cú pháp CSS
Bạn còn nhớ các khái niệm về phân tích cú pháp trong phần giới thiệu không? Không giống như HTML, CSS là một cú pháp không có ngữ cảnh và có thể được phân tích cú pháp bằng các loại trình phân tích cú pháp được mô tả trong phần giới thiệu. Trên thực tế, quy cách CSS xác định cú pháp và từ vựng CSS.
Hãy xem một số ví dụ:
Ngữ pháp từ vựng (lexical grammar) được xác định bằng biểu thức chính quy cho mỗi mã thông báo:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" là viết tắt của giá trị nhận dạng, chẳng hạn như tên lớp. "name" là mã nhận dạng phần tử (được tham chiếu bằng "#")
Ngữ pháp cú pháp được mô tả trong BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Giải thích:
Quy tắc là cấu trúc sau:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error và a.error là bộ chọn. Phần bên trong dấu ngoặc nhọn chứa các quy tắc được áp dụng theo bộ quy tắc này.
Cấu trúc này được xác định chính thức trong định nghĩa sau:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Điều này có nghĩa là quy tắc là một bộ chọn hoặc một số bộ chọn (không bắt buộc) được phân tách bằng dấu phẩy và dấu cách (S là ký hiệu cho khoảng trắng). Quy tắc chứa dấu ngoặc nhọn và bên trong đó là một nội dung khai báo hoặc một số nội dung khai báo (không bắt buộc) được phân tách bằng dấu chấm phẩy. "declaration" (khai báo) và "selector" ( bộ chọn) sẽ được xác định trong các định nghĩa BNF sau.
Trình phân tích cú pháp CSS WebKit
WebKit sử dụng trình tạo trình phân tích cú pháp Flex và Bison để tự động tạo trình phân tích cú pháp từ các tệp cú pháp CSS. Như bạn đã nhớ trong phần giới thiệu về trình phân tích cú pháp, Bison tạo một trình phân tích cú pháp giảm dần từ dưới lên. Firefox sử dụng trình phân tích cú pháp từ trên xuống được viết theo cách thủ công. Trong cả hai trường hợp, mỗi tệp CSS đều được phân tích cú pháp thành một đối tượng StyleSheet. Mỗi đối tượng chứa các quy tắc CSS. Các đối tượng quy tắc CSS chứa đối tượng bộ chọn và khai báo cũng như các đối tượng khác tương ứng với cú pháp CSS.

Trình tự xử lý tập lệnh và trang kiểu
Tập lệnh
Mô hình của web là đồng bộ. Tác giả mong muốn tập lệnh được phân tích cú pháp và thực thi ngay lập tức khi trình phân tích cú pháp gặp thẻ <script>.
Quá trình phân tích cú pháp của tài liệu sẽ bị tạm dừng cho đến khi tập lệnh được thực thi.
Nếu tập lệnh là bên ngoài, thì trước tiên, bạn phải tìm nạp tài nguyên từ mạng – việc này cũng được thực hiện đồng bộ và quá trình phân tích cú pháp sẽ tạm dừng cho đến khi tài nguyên được tìm nạp.
Đây là mô hình trong nhiều năm và cũng được chỉ định trong thông số kỹ thuật HTML4 và 5.
Tác giả có thể thêm thuộc tính "defer" vào tập lệnh. Trong trường hợp này, tập lệnh sẽ không tạm dừng quá trình phân tích cú pháp tài liệu và sẽ thực thi sau khi tài liệu được phân tích cú pháp. HTML5 thêm một tuỳ chọn để đánh dấu tập lệnh là không đồng bộ để tập lệnh đó được phân tích cú pháp và thực thi bởi một luồng khác.
Phân tích cú pháp suy đoán
Cả WebKit và Firefox đều thực hiện việc tối ưu hoá này. Trong khi thực thi tập lệnh, một luồng khác sẽ phân tích cú pháp phần còn lại của tài liệu và tìm ra những tài nguyên khác cần tải từ mạng rồi tải các tài nguyên đó. Bằng cách này, tài nguyên có thể được tải trên các kết nối song song và tốc độ tổng thể được cải thiện. Lưu ý: trình phân tích cú pháp dự đoán chỉ phân tích cú pháp các tệp tham chiếu đến tài nguyên bên ngoài như tập lệnh bên ngoài, trang kiểu và hình ảnh: trình phân tích cú pháp này không sửa đổi cây DOM – việc này được để lại cho trình phân tích cú pháp chính.
Biểu định kiểu
Mặt khác, các trang kiểu có mô hình khác. Về mặt khái niệm, có vẻ như vì các tệp định kiểu không thay đổi cây DOM, nên không có lý do gì để chờ các tệp đó và dừng quá trình phân tích cú pháp tài liệu. Tuy nhiên, có một vấn đề về tập lệnh yêu cầu thông tin kiểu trong giai đoạn phân tích cú pháp tài liệu. Nếu kiểu chưa được tải và phân tích cú pháp, tập lệnh sẽ nhận được câu trả lời không chính xác và rõ ràng là điều này đã gây ra nhiều vấn đề. Đây có vẻ là một trường hợp hiếm gặp nhưng khá phổ biến. Firefox chặn tất cả tập lệnh khi có một trang định kiểu vẫn đang được tải và phân tích cú pháp. WebKit chỉ chặn tập lệnh khi các tập lệnh đó cố gắng truy cập vào một số thuộc tính kiểu nhất định có thể chịu ảnh hưởng của các trang kiểu chưa tải.
Xây dựng cây kết xuất
Trong khi cây DOM đang được tạo, trình duyệt sẽ tạo một cây khác, đó là cây hiển thị. Cây này bao gồm các thành phần hình ảnh theo thứ tự hiển thị. Đây là bản trình bày trực quan của tài liệu. Mục đích của cây này là cho phép vẽ nội dung theo đúng thứ tự.
Firefox gọi các phần tử trong cây kết xuất là "khung". WebKit sử dụng thuật ngữ trình kết xuất hoặc đối tượng kết xuất.
Trình kết xuất biết cách bố trí và vẽ chính nó cũng như các phần tử con.
Lớp RenderObject của WebKit, lớp cơ sở của trình kết xuất, có định nghĩa sau:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Mỗi trình kết xuất đại diện cho một vùng hình chữ nhật thường tương ứng với hộp CSS của một nút, như mô tả trong thông số kỹ thuật CSS2. Vùng này bao gồm thông tin hình học như chiều rộng, chiều cao và vị trí.
Loại hộp chịu ảnh hưởng của giá trị "hiển thị" của thuộc tính kiểu có liên quan đến nút (xem phần tính toán kiểu). Dưới đây là mã WebKit để quyết định loại trình kết xuất cần tạo cho một nút DOM, theo thuộc tính hiển thị:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Loại phần tử cũng được xem xét: ví dụ: các thành phần điều khiển biểu mẫu và bảng có khung đặc biệt.
Trong WebKit, nếu một phần tử muốn tạo một trình kết xuất đặc biệt, thì phần tử đó sẽ ghi đè phương thức createRenderer().
Trình kết xuất trỏ đến các đối tượng kiểu chứa thông tin không phải hình học.
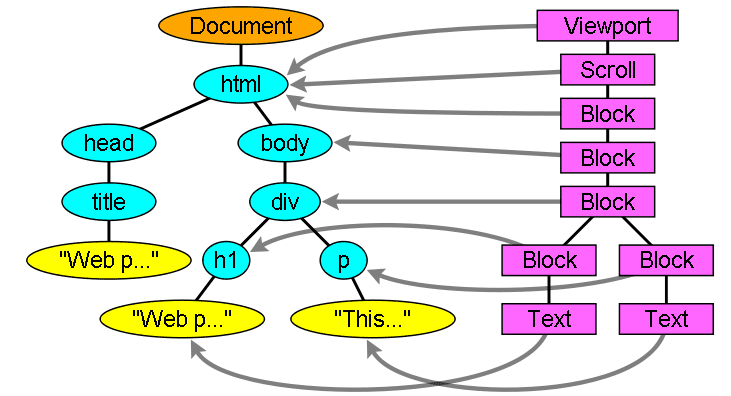
Mối quan hệ giữa cây kết xuất với cây DOM
Trình kết xuất tương ứng với các phần tử DOM, nhưng mối quan hệ không phải là một với một. Các phần tử DOM không phải hình ảnh sẽ không được chèn vào cây kết xuất. Ví dụ: phần tử "head". Ngoài ra, các phần tử có giá trị hiển thị được gán thành "none" (không có) sẽ không xuất hiện trong cây (trong khi các phần tử có chế độ hiển thị "hidden" (ẩn) sẽ xuất hiện trong cây).
Có các phần tử DOM tương ứng với một số đối tượng hình ảnh. Đây thường là các phần tử có cấu trúc phức tạp không thể mô tả bằng một hình chữ nhật duy nhất. Ví dụ: phần tử "select" có ba trình kết xuất: một cho khu vực hiển thị, một cho hộp danh sách thả xuống và một cho nút. Ngoài ra, khi văn bản được chia thành nhiều dòng do chiều rộng không đủ cho một dòng, các dòng mới sẽ được thêm vào dưới dạng trình kết xuất bổ sung.
Một ví dụ khác về nhiều trình kết xuất là HTML bị hỏng. Theo thông số kỹ thuật CSS, phần tử nội tuyến chỉ được chứa phần tử khối hoặc phần tử nội tuyến. Trong trường hợp nội dung hỗn hợp, trình kết xuất khối ẩn danh sẽ được tạo để gói các phần tử cùng dòng.
Một số đối tượng kết xuất tương ứng với một nút DOM nhưng không ở cùng một vị trí trong cây. Các phần tử nổi và phần tử có vị trí tuyệt đối nằm ngoài luồng, được đặt ở một phần khác của cây và được liên kết với khung thực. Khung giữ chỗ là nơi chúng đáng ra phải xuất hiện.
Quy trình tạo cây
Trong Firefox, bản trình bày được đăng ký làm trình nghe cho các bản cập nhật DOM.
Bản trình bày uỷ quyền việc tạo khung cho FrameConstructor và hàm khởi tạo phân giải kiểu (xem phần tính toán kiểu) và tạo khung.
Trong WebKit, quá trình phân giải kiểu và tạo trình kết xuất được gọi là "tệp đính kèm". Mỗi nút DOM đều có một phương thức "đính kèm". Tệp đính kèm là đồng bộ, thao tác chèn nút vào cây DOM sẽ gọi phương thức "attach" (đính kèm) của nút mới.
Việc xử lý thẻ html và body sẽ dẫn đến việc tạo gốc cây kết xuất.
Đối tượng kết xuất gốc tương ứng với nội dung mà thông số kỹ thuật CSS gọi là khối chứa: khối trên cùng chứa tất cả các khối khác. Kích thước của khung nhìn này là khung nhìn: kích thước khu vực hiển thị của cửa sổ trình duyệt.
Firefox gọi là ViewPortFrame và WebKit gọi là RenderView.
Đây là đối tượng kết xuất mà tài liệu trỏ đến.
Phần còn lại của cây được tạo dưới dạng một thao tác chèn nút DOM.
Xem thông số kỹ thuật CSS2 về mô hình xử lý.
Tính toán kiểu
Việc tạo cây kết xuất đòi hỏi phải tính toán các thuộc tính hình ảnh của từng đối tượng kết xuất. Việc này được thực hiện bằng cách tính toán các thuộc tính kiểu của từng phần tử.
Kiểu này bao gồm các trang kiểu của nhiều nguồn gốc, phần tử kiểu nội tuyến và các thuộc tính hình ảnh trong HTML (chẳng hạn như thuộc tính "bgcolor").Thuộc tính sau được dịch thành các thuộc tính kiểu CSS phù hợp.
Nguồn gốc của các trang kiểu là trang kiểu mặc định của trình duyệt, trang kiểu do tác giả trang cung cấp và trang kiểu do người dùng cung cấp – đây là các trang kiểu do người dùng trình duyệt cung cấp (các trình duyệt cho phép bạn xác định các kiểu bạn yêu thích. Ví dụ: trong Firefox, bạn có thể thực hiện việc này bằng cách đặt một trang kiểu vào thư mục "Hồ sơ Firefox").
Việc tính toán kiểu gây ra một số khó khăn:
- Dữ liệu kiểu là một cấu trúc rất lớn, chứa nhiều thuộc tính kiểu, điều này có thể gây ra sự cố về bộ nhớ.
Việc tìm quy tắc so khớp cho từng phần tử có thể gây ra vấn đề về hiệu suất nếu không được tối ưu hoá. Việc duyệt qua toàn bộ danh sách quy tắc cho mỗi phần tử để tìm phần tử trùng khớp là một nhiệm vụ nặng nề. Bộ chọn có thể có cấu trúc phức tạp khiến quá trình so khớp bắt đầu trên một đường dẫn có vẻ hứa hẹn nhưng đã được chứng minh là vô ích và phải thử một đường dẫn khác.
Ví dụ: bộ chọn phức hợp này:
div div div div{ ... }Có nghĩa là các quy tắc áp dụng cho
<div>là phần tử con của 3 div. Giả sử bạn muốn kiểm tra xem quy tắc có áp dụng cho một phần tử<div>nhất định hay không. Bạn chọn một đường dẫn nhất định trên cây để kiểm tra. Bạn có thể phải di chuyển lên cây nút để chỉ tìm thấy 2 div và quy tắc không áp dụng. Sau đó, bạn cần thử các đường dẫn khác trong cây.Việc áp dụng các quy tắc này liên quan đến các quy tắc dạng thác nước khá phức tạp, xác định hệ phân cấp của các quy tắc.
Hãy xem cách các trình duyệt xử lý những vấn đề này:
Chia sẻ dữ liệu kiểu
Các nút WebKit tham chiếu đến các đối tượng kiểu (RenderStyle). Các đối tượng này có thể được các nút chia sẻ trong một số điều kiện. Các nút là anh chị em hoặc họ hàng và:
- Các phần tử phải ở cùng trạng thái chuột (ví dụ: một phần tử không được ở trạng thái :hover trong khi phần tử còn lại không ở trạng thái này)
- Cả hai phần tử đều không được có mã nhận dạng
- Tên thẻ phải khớp
- Các thuộc tính của lớp phải khớp
- Tập hợp thuộc tính được liên kết phải giống hệt nhau
- Trạng thái liên kết phải khớp
- Trạng thái tiêu điểm phải khớp
- Không có phần tử nào được ảnh hưởng bởi bộ chọn thuộc tính, trong đó bị ảnh hưởng được xác định là có bất kỳ bộ chọn nào khớp sử dụng bộ chọn thuộc tính ở bất kỳ vị trí nào trong bộ chọn
- Không được có thuộc tính kiểu cùng dòng trên các phần tử
- Không được sử dụng bộ chọn đồng cấp nào. WebCore chỉ cần gửi một nút chuyển toàn cục khi gặp bất kỳ bộ chọn đồng cấp nào và tắt tính năng chia sẻ kiểu cho toàn bộ tài liệu khi có các bộ chọn đó. Điều này bao gồm bộ chọn + và các bộ chọn như :first-child và :last-child.
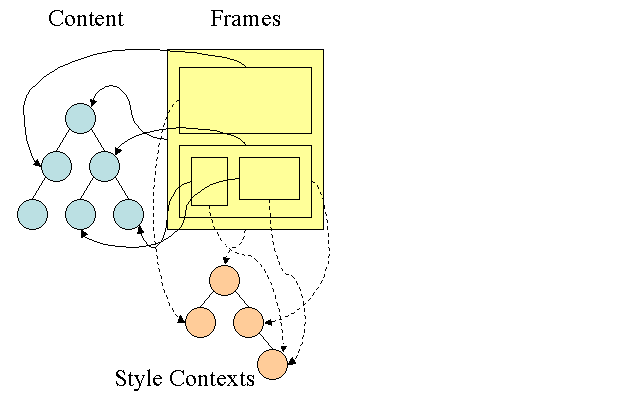
Cây quy tắc Firefox
Firefox có thêm hai cây để tính toán kiểu dễ dàng hơn: cây quy tắc và cây ngữ cảnh kiểu. WebKit cũng có các đối tượng kiểu nhưng chúng không được lưu trữ trong cây như cây ngữ cảnh kiểu, chỉ có nút DOM trỏ đến kiểu liên quan.
Ngữ cảnh kiểu chứa các giá trị kết thúc. Các giá trị được tính toán bằng cách áp dụng tất cả các quy tắc so khớp theo đúng thứ tự và thực hiện các thao tác biến đổi các giá trị đó từ logic thành giá trị cụ thể. Ví dụ: nếu giá trị logic là tỷ lệ phần trăm của màn hình, thì giá trị này sẽ được tính toán và chuyển đổi thành đơn vị tuyệt đối. Ý tưởng về cây quy tắc thực sự rất thông minh. Tính năng này cho phép chia sẻ các giá trị này giữa các nút để tránh tính toán lại. Việc này cũng giúp tiết kiệm không gian.
Tất cả các quy tắc đã so khớp được lưu trữ trong một cây. Các nút dưới cùng trong một đường dẫn có mức độ ưu tiên cao hơn. Cây này chứa tất cả các đường dẫn cho các kết quả trùng khớp với quy tắc đã tìm thấy. Việc lưu trữ các quy tắc được thực hiện một cách lười biếng. Cây không được tính toán ngay từ đầu cho mọi nút, nhưng bất cứ khi nào cần tính toán kiểu nút, các đường dẫn đã tính toán sẽ được thêm vào cây.
Ý tưởng là xem các đường dẫn cây dưới dạng từ trong từ vựng. Giả sử chúng ta đã tính toán cây quy tắc này:
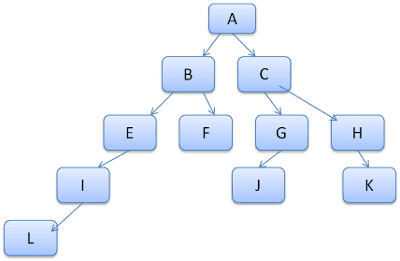
Giả sử chúng ta cần so khớp các quy tắc cho một phần tử khác trong cây nội dung và tìm ra các quy tắc được so khớp (theo thứ tự chính xác) là B-E-I. Chúng ta đã có đường dẫn này trong cây vì đã tính toán đường dẫn A-B-E-I-L. Giờ đây, chúng ta sẽ có ít việc hơn.
Hãy xem cách cây giúp chúng ta tiết kiệm công sức.
Phân chia thành cấu trúc
Ngữ cảnh kiểu được chia thành các cấu trúc. Các cấu trúc đó chứa thông tin kiểu cho một danh mục nhất định như đường viền hoặc màu sắc. Tất cả thuộc tính trong một cấu trúc đều được kế thừa hoặc không được kế thừa. Thuộc tính kế thừa là các thuộc tính được kế thừa từ phần tử mẹ, trừ phi phần tử đó xác định. Các thuộc tính không được kế thừa (gọi là thuộc tính "đặt lại") sử dụng giá trị mặc định nếu không được xác định.
Cây này giúp chúng ta bằng cách lưu toàn bộ cấu trúc (chứa các giá trị cuối được tính toán) vào bộ nhớ đệm trong cây. Ý tưởng là nếu nút dưới cùng không cung cấp định nghĩa cho một cấu trúc, thì bạn có thể sử dụng cấu trúc được lưu vào bộ nhớ đệm trong nút trên.
Tính toán ngữ cảnh kiểu bằng cây quy tắc
Khi tính toán ngữ cảnh kiểu cho một phần tử nhất định, trước tiên, chúng ta sẽ tính toán một đường dẫn trong cây quy tắc hoặc sử dụng một đường dẫn hiện có. Sau đó, chúng ta bắt đầu áp dụng các quy tắc trong đường dẫn để điền các cấu trúc trong ngữ cảnh kiểu mới. Chúng ta bắt đầu từ nút dưới cùng của đường dẫn – nút có mức độ ưu tiên cao nhất (thường là bộ chọn cụ thể nhất) và duyệt qua cây cho đến khi cấu trúc của chúng ta đầy. Nếu không có thông số kỹ thuật cho cấu trúc trong nút quy tắc đó, thì chúng ta có thể tối ưu hoá đáng kể – chúng ta đi lên cây cho đến khi tìm thấy một nút chỉ định đầy đủ cấu trúc đó và trỏ đến nút đó – đó là cách tối ưu hoá tốt nhất – toàn bộ cấu trúc được chia sẻ. Điều này giúp tiết kiệm bộ nhớ và tính toán giá trị cuối cùng.
Nếu tìm thấy một phần định nghĩa, chúng ta sẽ đi lên cây cho đến khi điền xong cấu trúc.
Nếu không tìm thấy định nghĩa nào cho cấu trúc của chúng ta, thì trong trường hợp cấu trúc là loại "kế thừa", chúng ta sẽ trỏ đến cấu trúc của thành phần mẹ trong cây ngữ cảnh. Trong trường hợp này, chúng ta cũng đã chia sẻ thành công các cấu trúc. Nếu đó là cấu trúc đặt lại, thì các giá trị mặc định sẽ được sử dụng.
Nếu nút cụ thể nhất thêm các giá trị, thì chúng ta cần thực hiện một số phép tính bổ sung để chuyển đổi nút đó thành các giá trị thực tế. Sau đó, chúng ta lưu kết quả vào bộ nhớ đệm trong nút cây để các nút con có thể sử dụng.
Trong trường hợp một phần tử có phần tử đồng cấp trỏ đến cùng một nút cây, thì toàn bộ ngữ cảnh kiểu có thể được chia sẻ giữa các phần tử đó.
Hãy xem ví dụ: Giả sử chúng ta có HTML sau
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
Và các quy tắc sau:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Để đơn giản hoá vấn đề, giả sử chúng ta chỉ cần điền vào hai cấu trúc: cấu trúc màu và cấu trúc lề. Cấu trúc màu chỉ chứa một thành phần: màu Cấu trúc lề chứa bốn cạnh.
Cây quy tắc thu được sẽ có dạng như sau (các nút được đánh dấu bằng tên nút: số của quy tắc mà chúng trỏ đến):
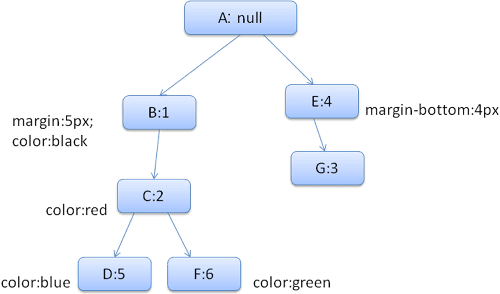
Cây ngữ cảnh sẽ có dạng như sau (tên nút: nút quy tắc mà chúng trỏ đến):
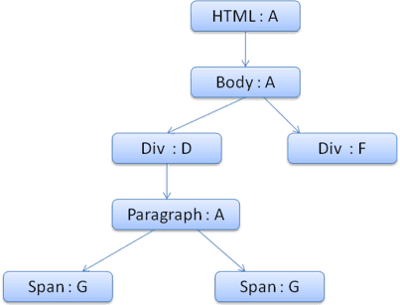
Giả sử chúng ta phân tích cú pháp HTML và chuyển đến thẻ <div> thứ hai. Chúng ta cần tạo ngữ cảnh kiểu cho nút này và điền vào cấu trúc kiểu của nút.
Chúng ta sẽ so khớp các quy tắc và phát hiện rằng các quy tắc khớp với <div> là 1, 2 và 6.
Điều này có nghĩa là đã có một đường dẫn hiện có trong cây mà phần tử của chúng ta có thể sử dụng và chúng ta chỉ cần thêm một nút khác vào đường dẫn đó cho quy tắc 6 (nút F trong cây quy tắc).
Chúng ta sẽ tạo một ngữ cảnh kiểu và đặt ngữ cảnh đó vào cây ngữ cảnh. Ngữ cảnh kiểu mới sẽ trỏ đến nút F trong cây quy tắc.
Bây giờ, chúng ta cần điền vào các cấu trúc kiểu. Chúng ta sẽ bắt đầu bằng cách điền vào cấu trúc lề. Vì nút quy tắc cuối cùng (F) không thêm vào cấu trúc lề, nên chúng ta có thể di chuyển lên cây cho đến khi tìm thấy một cấu trúc được lưu vào bộ nhớ đệm được tính toán trong một lần chèn nút trước đó và sử dụng cấu trúc đó. Chúng ta sẽ tìm thấy nó trên nút B, đây là nút trên cùng đã chỉ định các quy tắc lề.
Chúng ta có định nghĩa cho cấu trúc màu, vì vậy, chúng ta không thể sử dụng cấu trúc được lưu vào bộ nhớ đệm. Vì màu có một thuộc tính nên chúng ta không cần phải đi lên cây để điền các thuộc tính khác. Chúng ta sẽ tính toán giá trị cuối cùng (chuyển đổi chuỗi thành RGB, v.v.) và lưu cấu trúc đã tính toán vào bộ nhớ đệm trên nút này.
Việc làm trên phần tử <span> thứ hai còn dễ dàng hơn. Chúng ta sẽ so khớp các quy tắc và đi đến kết luận rằng quy tắc này trỏ đến quy tắc G, giống như span trước đó.
Vì các phần tử con trỏ đến cùng một nút, nên chúng ta có thể chia sẻ toàn bộ ngữ cảnh kiểu và chỉ trỏ đến ngữ cảnh của span trước đó.
Đối với các cấu trúc chứa các quy tắc được kế thừa từ cấu trúc mẹ, việc lưu vào bộ nhớ đệm được thực hiện trên cây ngữ cảnh (thuộc tính màu thực sự được kế thừa, nhưng Firefox coi thuộc tính này là đặt lại và lưu vào bộ nhớ đệm trên cây quy tắc).
Ví dụ: nếu chúng ta thêm các quy tắc cho phông chữ trong một đoạn văn:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Sau đó, phần tử đoạn văn (là phần tử con của div trong cây ngữ cảnh) có thể đã chia sẻ cùng một cấu trúc phông chữ với phần tử mẹ. Đây là trường hợp nếu bạn không chỉ định quy tắc phông chữ cho đoạn văn.
Trong WebKit, không có cây quy tắc, các phần khai báo được so khớp sẽ được duyệt qua bốn lần. Trước tiên, các thuộc tính không quan trọng có mức độ ưu tiên cao sẽ được áp dụng (các thuộc tính nên được áp dụng trước tiên vì các thuộc tính khác phụ thuộc vào chúng, chẳng hạn như hiển thị), sau đó là các thuộc tính quan trọng có mức độ ưu tiên cao, sau đó là các thuộc tính không quan trọng có mức độ ưu tiên bình thường, sau đó là các quy tắc quan trọng có mức độ ưu tiên bình thường. Điều này có nghĩa là các thuộc tính xuất hiện nhiều lần sẽ được phân giải theo thứ tự thác nước chính xác. Lượt ghi gần nhất sẽ thắng.
Tóm lại: việc chia sẻ các đối tượng kiểu (toàn bộ hoặc một số cấu trúc bên trong) sẽ giải quyết được vấn đề 1 và 3. Cây quy tắc Firefox cũng giúp áp dụng các thuộc tính theo đúng thứ tự.
Thao tác với các quy tắc để dễ dàng so khớp
Có một số nguồn cho quy tắc kiểu:
- Quy tắc CSS, trong biểu định kiểu bên ngoài hoặc trong phần tử kiểu.
css p {color: blue} - Các thuộc tính kiểu cùng dòng như
html <p style="color: blue" /> - Thuộc tính hình ảnh HTML (được liên kết với các quy tắc kiểu liên quan)
html <p bgcolor="blue" />Hai thuộc tính cuối cùng dễ dàng so khớp với phần tử này vì phần tử này sở hữu các thuộc tính kiểu và có thể liên kết các thuộc tính HTML bằng cách sử dụng phần tử này làm khoá.
Như đã lưu ý trước đó trong vấn đề #2, việc so khớp quy tắc CSS có thể khó khăn hơn. Để giải quyết vấn đề này, các quy tắc được điều khiển để dễ truy cập hơn.
Sau khi phân tích cú pháp trang kiểu, các quy tắc sẽ được thêm vào một trong nhiều bản đồ băm, tuỳ theo bộ chọn. Có các bản đồ theo mã nhận dạng, theo tên lớp, theo tên thẻ và một bản đồ chung cho mọi thứ không thuộc các danh mục đó. Nếu bộ chọn là một mã nhận dạng, quy tắc sẽ được thêm vào bản đồ mã nhận dạng, nếu là một lớp thì quy tắc sẽ được thêm vào bản đồ lớp, v.v.
Thao tác này giúp so khớp quy tắc dễ dàng hơn nhiều. Không cần phải xem trong mọi phần khai báo: chúng ta có thể trích xuất các quy tắc liên quan cho một phần tử từ các bản đồ. Tính năng tối ưu hoá này loại bỏ hơn 95% quy tắc, nhờ đó, bạn thậm chí không cần xem xét các quy tắc đó trong quá trình so khớp(4.1).
Hãy xem ví dụ về các quy tắc kiểu sau:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
Quy tắc đầu tiên sẽ được chèn vào bản đồ lớp. Mục thứ hai vào bản đồ mã nhận dạng và mục thứ ba vào bản đồ thẻ.
Đối với mảnh HTML sau;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Trước tiên, chúng ta sẽ tìm các quy tắc cho phần tử p. Bản đồ lớp sẽ chứa khoá "error" (lỗi) trong đó có quy tắc cho "p.error". Phần tử div sẽ có các quy tắc liên quan trong bản đồ mã nhận dạng (khoá là mã nhận dạng) và bản đồ thẻ. Vì vậy, việc duy nhất còn lại là tìm ra quy tắc nào trong số các quy tắc được trích xuất bằng khoá thực sự khớp.
Ví dụ: nếu quy tắc cho div là:
table div {margin: 5px}
Thẻ này vẫn sẽ được trích xuất từ bản đồ thẻ vì khoá là bộ chọn ngoài cùng bên phải, nhưng không khớp với phần tử div của chúng ta, phần tử này không có phần tử mẹ là bảng.
Cả WebKit và Firefox đều thực hiện thao tác này.
Thứ tự xếp chồng của biểu định kiểu
Đối tượng kiểu có các thuộc tính tương ứng với mọi thuộc tính hình ảnh (tất cả thuộc tính CSS nhưng chung hơn). Nếu thuộc tính không được xác định bởi bất kỳ quy tắc nào được so khớp, thì một số thuộc tính có thể được đối tượng kiểu phần tử mẹ kế thừa. Các thuộc tính khác có giá trị mặc định.
Vấn đề bắt đầu khi có nhiều định nghĩa – đây là thứ tự thác nước để giải quyết vấn đề.
Nội dung khai báo cho một thuộc tính kiểu có thể xuất hiện trong một số trang kiểu và nhiều lần bên trong một trang kiểu. Điều này có nghĩa là thứ tự áp dụng các quy tắc rất quan trọng. Đây được gọi là thứ tự "tầng". Theo thông số kỹ thuật CSS2, thứ tự lũy thừa là (từ thấp đến cao):
- Nội dung khai báo trình duyệt
- Khai báo thông thường của người dùng
- Nội dung khai báo thông thường của tác giả
- Khai báo quan trọng của tác giả
- Nội dung khai báo quan trọng dành cho người dùng
Nội dung khai báo của trình duyệt ít quan trọng nhất và người dùng chỉ ghi đè tác giả nếu nội dung khai báo được đánh dấu là quan trọng. Các nội dung khai báo có cùng thứ tự sẽ được sắp xếp theo độ cụ thể, sau đó là thứ tự được chỉ định. Các thuộc tính hình ảnh HTML được dịch thành các nội dung khai báo CSS phù hợp . Các quy tắc này được coi là quy tắc của tác giả có mức độ ưu tiên thấp.
Mức độ cụ thể
Quy cách CSS2 xác định mức độ cụ thể của bộ chọn như sau:
- đếm 1 nếu phần khai báo của thuộc tính này là thuộc tính "style" thay vì một quy tắc có bộ chọn, nếu không thì đếm 0 (= a)
- đếm số lượng thuộc tính mã nhận dạng trong bộ chọn (= b)
- đếm số lượng thuộc tính và lớp giả lập khác trong bộ chọn (= c)
- đếm số lượng tên phần tử và phần tử giả trong bộ chọn (= d)
Việc nối bốn số a-b-c-d (trong hệ thống số có cơ số lớn) sẽ cho ra độ cụ thể.
Cơ sở số bạn cần sử dụng được xác định theo số lượng cao nhất mà bạn có trong một trong các danh mục.
Ví dụ: nếu a=14, bạn có thể sử dụng cơ số thập lục phân. Trong trường hợp hiếm gặp khi a=17, bạn sẽ cần cơ số số 17 chữ số. Trường hợp sau có thể xảy ra với bộ chọn như sau: html body div div p… (17 thẻ trong bộ chọn… không có nhiều khả năng).
Một số ví dụ:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Sắp xếp các quy tắc
Sau khi so khớp, các quy tắc sẽ được sắp xếp theo quy tắc xếp chồng.
WebKit sử dụng phương thức sắp xếp bong bóng cho danh sách nhỏ và phương thức sắp xếp hợp nhất cho danh sách lớn.
WebKit triển khai việc sắp xếp bằng cách ghi đè toán tử > cho các quy tắc:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Quy trình dần dần
WebKit sử dụng một cờ đánh dấu nếu tất cả các trang tính kiểu cấp cao nhất (bao gồm cả @imports) đã được tải. Nếu kiểu không được tải đầy đủ khi đính kèm, thì phần giữ chỗ sẽ được sử dụng và được đánh dấu trong tài liệu. Các phần giữ chỗ này sẽ được tính toán lại sau khi tải xong trang tính kiểu.
Bố cục
Khi được tạo và thêm vào cây, trình kết xuất không có vị trí và kích thước. Việc tính toán các giá trị này được gọi là bố cục hoặc luồng lại.
HTML sử dụng mô hình bố cục dựa trên luồng, nghĩa là hầu hết thời gian bạn có thể tính toán hình học trong một lần truyền. Các phần tử "trong luồng" sau này thường không ảnh hưởng đến hình học của các phần tử "trong luồng" trước đó, vì vậy, bố cục có thể tiến hành từ trái sang phải, từ trên xuống dưới trong tài liệu. Có một số trường hợp ngoại lệ: ví dụ: bảng HTML có thể yêu cầu nhiều lượt truyền.
Hệ toạ độ tương ứng với khung gốc. Sử dụng toạ độ trên cùng và bên trái.
Bố cục là một quá trình đệ quy. Quá trình này bắt đầu từ trình kết xuất gốc, tương ứng với phần tử <html> của tài liệu HTML. Bố cục tiếp tục đệ quy thông qua một số hoặc tất cả hệ phân cấp khung, tính toán thông tin hình học cho từng trình kết xuất cần thông tin đó.
Vị trí của trình kết xuất gốc là 0,0 và kích thước của trình kết xuất này là khung nhìn – phần hiển thị của cửa sổ trình duyệt.
Tất cả trình kết xuất đều có phương thức "bố cục" hoặc "lưu lại luồng", mỗi trình kết xuất gọi phương thức bố cục của các phần tử con cần bố cục.
Hệ thống bit bẩn
Để không phải tạo bố cục đầy đủ cho mọi thay đổi nhỏ, trình duyệt sử dụng hệ thống "bit bẩn". Một trình kết xuất được thay đổi hoặc thêm sẽ đánh dấu chính nó và các thành phần con là "bẩn": cần bố cục.
Có hai cờ: "bẩn" và "các phần tử con bị bẩn", nghĩa là mặc dù trình kết xuất có thể hoạt động bình thường, nhưng ít nhất một phần tử con cần có bố cục.
Bố cục toàn cục và tăng dần
Bạn có thể kích hoạt bố cục trên toàn bộ cây kết xuất – đây là bố cục "chung". Điều này có thể xảy ra do:
- Thay đổi kiểu chung ảnh hưởng đến tất cả trình kết xuất, chẳng hạn như thay đổi kích thước phông chữ.
- Do màn hình được đổi kích thước
Bố cục có thể tăng dần, chỉ những trình kết xuất bị bẩn mới được bố trí (điều này có thể gây ra một số thiệt hại và cần thêm bố cục).
Bố cục gia tăng được kích hoạt (không đồng bộ) khi trình kết xuất bị bẩn. Ví dụ: khi trình kết xuất mới được thêm vào cây kết xuất sau khi nội dung bổ sung đến từ mạng và được thêm vào cây DOM.
Bố cục không đồng bộ và đồng bộ
Bố cục gia tăng được thực hiện không đồng bộ. Firefox đưa "lệnh luồng lại" vào hàng đợi cho các bố cục tăng dần và trình lập lịch biểu sẽ kích hoạt quá trình thực thi hàng loạt các lệnh này. WebKit cũng có một bộ hẹn giờ thực thi bố cục tăng dần – cây được duyệt qua và các trình kết xuất "bẩn" được bố trí.
Các tập lệnh yêu cầu thông tin kiểu, chẳng hạn như "offsetHeight" có thể kích hoạt bố cục gia tăng một cách đồng bộ.
Bố cục toàn cục thường được kích hoạt đồng bộ.
Đôi khi, bố cục được kích hoạt dưới dạng lệnh gọi lại sau bố cục ban đầu vì một số thuộc tính, chẳng hạn như vị trí cuộn đã thay đổi.
Tối ưu hoá
Khi một bố cục được kích hoạt bằng thao tác "đổi kích thước" hoặc thay đổi vị trí trình kết xuất(chứ không phải kích thước), kích thước kết xuất sẽ được lấy từ bộ nhớ đệm và không được tính toán lại…
Trong một số trường hợp, chỉ một cây con được sửa đổi và bố cục không bắt đầu từ gốc. Điều này có thể xảy ra trong trường hợp thay đổi là cục bộ và không ảnh hưởng đến môi trường xung quanh, chẳng hạn như văn bản được chèn vào các trường văn bản (nếu không, mỗi thao tác nhấn phím sẽ kích hoạt một bố cục bắt đầu từ gốc).
Quy trình bố cục
Bố cục thường có mẫu sau:
- Trình kết xuất mẹ xác định chiều rộng của riêng nó.
- Thành phần mẹ sẽ đi qua các thành phần con và:
- Đặt trình kết xuất con (đặt x và y).
- Gọi bố cục con nếu cần – các bố cục này bị bẩn hoặc chúng ta đang ở bố cục toàn cục hoặc vì một lý do nào đó khác – để tính chiều cao của bố cục con.
- Phần tử mẹ sử dụng chiều cao tích luỹ của phần tử con và chiều cao của lề và khoảng đệm để đặt chiều cao của chính nó – phần tử mẹ này sẽ được phần tử mẹ của trình kết xuất mẹ sử dụng.
- Đặt bit bẩn thành false.
Firefox sử dụng đối tượng "trạng thái" (nsHTMLReflowState) làm tham số cho bố cục (gọi là "lưu lại"). Trong số các trạng thái khác, trạng thái này bao gồm chiều rộng của thành phần mẹ.
Kết quả của bố cục Firefox là một đối tượng "metrics" (nsHTMLReflowMetrics). Thuộc tính này sẽ chứa chiều cao được tính toán của trình kết xuất.
Tính toán chiều rộng
Chiều rộng của trình kết xuất được tính bằng chiều rộng của khối vùng chứa, thuộc tính "width" (chiều rộng) của kiểu trình kết xuất, lề và đường viền.
Ví dụ: chiều rộng của div sau:
<div style="width: 30%"/>
Sẽ được WebKit tính toán như sau(phương thức calcWidth của lớp RenderBox):
- Chiều rộng vùng chứa là giá trị tối đa của vùng chứa availableWidth và 0. availableWidth trong trường hợp này là contentWidth được tính như sau:
clientWidth() - paddingLeft() - paddingRight()
clientWidth và clientHeight đại diện cho phần bên trong của một đối tượng ngoại trừ đường viền và thanh cuộn.
Chiều rộng của phần tử là thuộc tính kiểu "width" (chiều rộng). Giá trị này sẽ được tính dưới dạng giá trị tuyệt đối bằng cách tính tỷ lệ phần trăm chiều rộng của vùng chứa.
Các đường viền và khoảng đệm theo chiều ngang hiện đã được thêm.
Cho đến nay, đây là cách tính "chiều rộng ưu tiên". Bây giờ, chiều rộng tối thiểu và tối đa sẽ được tính toán.
Nếu chiều rộng ưu tiên lớn hơn chiều rộng tối đa, thì chiều rộng tối đa sẽ được sử dụng. Nếu chiều rộng này nhỏ hơn chiều rộng tối thiểu (đơn vị không thể phá vỡ nhỏ nhất), thì chiều rộng tối thiểu sẽ được sử dụng.
Các giá trị được lưu vào bộ nhớ đệm trong trường hợp cần bố cục, nhưng chiều rộng không thay đổi.
Ngắt dòng
Khi một trình kết xuất ở giữa bố cục quyết định cần ngắt, trình kết xuất sẽ dừng và truyền đến phần tử mẹ của bố cục rằng cần ngắt. Thành phần mẹ tạo các trình kết xuất bổ sung và gọi bố cục trên các trình kết xuất đó.
Hội họa
Trong giai đoạn vẽ, cây kết xuất được duyệt qua và phương thức "paint()" của trình kết xuất được gọi để hiển thị nội dung trên màn hình. Painting sử dụng thành phần cơ sở hạ tầng giao diện người dùng.
Toàn cục và gia tăng
Giống như bố cục, hoạt động vẽ cũng có thể là toàn cục – toàn bộ cây được vẽ – hoặc tăng dần. Trong quá trình vẽ tăng dần, một số trình kết xuất thay đổi theo cách không ảnh hưởng đến toàn bộ cây. Trình kết xuất đã thay đổi sẽ vô hiệu hoá hình chữ nhật trên màn hình. Điều này khiến hệ điều hành xem đó là "vùng bị bẩn" và tạo ra sự kiện "vẽ". Hệ điều hành thực hiện việc này một cách thông minh và hợp nhất một số vùng thành một vùng. Trong Chrome, việc này phức tạp hơn vì trình kết xuất nằm trong một quy trình khác với quy trình chính. Chrome mô phỏng hành vi của hệ điều hành ở một mức độ nào đó. Bản trình bày sẽ theo dõi các sự kiện này và uỷ quyền thông báo cho gốc kết xuất. Cây được duyệt cho đến khi gặp trình kết xuất có liên quan. Thành phần hiển thị này sẽ tự vẽ lại (và thường là các thành phần con).
Thứ tự vẽ
CSS2 xác định thứ tự của quy trình vẽ. Đây thực sự là thứ tự các phần tử được xếp chồng trong bối cảnh xếp chồng. Thứ tự này ảnh hưởng đến quá trình vẽ vì các ngăn xếp được vẽ từ sau ra trước. Thứ tự xếp chồng của trình kết xuất khối là:
- màu nền
- hình nền
- border
- trẻ em
- outline
Danh sách hiển thị của Firefox
Firefox sẽ xem xét cây kết xuất và tạo danh sách hiển thị cho hình chữ nhật được vẽ. Nó chứa các trình kết xuất liên quan đến hình chữ nhật, theo thứ tự vẽ đúng (nền của trình kết xuất, sau đó là đường viền, v.v.).
Bằng cách đó, bạn chỉ cần duyệt qua cây một lần để vẽ lại thay vì nhiều lần – vẽ tất cả nền, sau đó vẽ tất cả hình ảnh, sau đó vẽ tất cả đường viền, v.v.
Firefox tối ưu hoá quy trình này bằng cách không thêm các phần tử sẽ bị ẩn, chẳng hạn như các phần tử nằm hoàn toàn bên dưới các phần tử mờ khác.
Bộ nhớ hình chữ nhật WebKit
Trước khi vẽ lại, WebKit sẽ lưu hình chữ nhật cũ dưới dạng bitmap. Sau đó, hàm này chỉ vẽ delta giữa hình chữ nhật mới và cũ.
Thay đổi động
Trình duyệt cố gắng thực hiện ít thao tác nhất có thể để phản hồi một thay đổi. Vì vậy, các thay đổi đối với màu của một phần tử sẽ chỉ khiến phần tử đó được vẽ lại. Các thay đổi đối với vị trí phần tử sẽ khiến bố cục và phần tử được vẽ lại, các phần tử con và có thể là các phần tử đồng cấp. Việc thêm một nút DOM sẽ khiến bố cục và sơn lại nút đó. Các thay đổi lớn, chẳng hạn như tăng cỡ chữ của phần tử "html", sẽ khiến bộ nhớ đệm không hợp lệ, bố cục lại và vẽ lại toàn bộ cây.
Luồng của công cụ kết xuất
Công cụ kết xuất là đơn luồng. Hầu hết mọi thứ, ngoại trừ các thao tác mạng, đều diễn ra trong một luồng. Trong Firefox và Safari, đây là luồng chính của trình duyệt. Trong Chrome, đó là luồng chính của quy trình thẻ.
Các hoạt động mạng có thể được thực hiện bằng một số luồng song song. Số lượng kết nối song song bị giới hạn (thường là 2 đến 6 kết nối).
Vòng lặp sự kiện
Luồng chính của trình duyệt là một vòng lặp sự kiện. Đây là một vòng lặp vô hạn giúp duy trì quá trình. Lớp này chờ các sự kiện (như sự kiện bố cục và vẽ) rồi xử lý các sự kiện đó. Đây là mã Firefox cho vòng lặp sự kiện chính:
while (!mExiting)
NS_ProcessNextEvent(thread);
Mô hình hình ảnh CSS2
Canvas
Theo quy cách CSS2, thuật ngữ canvas mô tả "không gian hiển thị cấu trúc định dạng": nơi trình duyệt vẽ nội dung.
Canvas là vô hạn đối với mỗi kích thước của không gian, nhưng trình duyệt chọn chiều rộng ban đầu dựa trên kích thước của khung nhìn.
Theo www.w3.org/TR/CSS2/zindex.html, canvas sẽ trong suốt nếu nằm trong một canvas khác và có màu do trình duyệt xác định nếu không.
Mô hình hộp CSS
Mô hình hộp CSS mô tả các hộp hình chữ nhật được tạo cho các phần tử trong cây tài liệu và được bố trí theo mô hình định dạng hình ảnh.
Mỗi hộp có một vùng nội dung (ví dụ: văn bản, hình ảnh, v.v.) và các vùng khoảng đệm, đường viền và lề xung quanh (không bắt buộc).
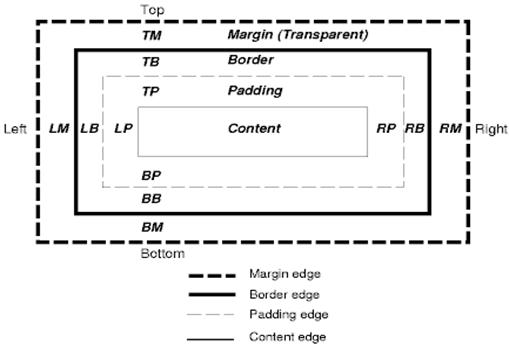
Mỗi nút tạo ra 0…n hộp như vậy.
Tất cả phần tử đều có thuộc tính "display" (hiển thị) xác định loại hộp sẽ được tạo.
Ví dụ:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
Giá trị mặc định là nội tuyến nhưng trang kiểu của trình duyệt có thể đặt các giá trị mặc định khác. Ví dụ: chế độ hiển thị mặc định cho phần tử "div" là khối.
Bạn có thể xem ví dụ về tệp định kiểu mặc định tại đây: www.w3.org/TR/CSS2/sample.html.
Lược đồ định vị
Có 3 lược đồ:
- Thông thường: đối tượng được định vị theo vị trí của đối tượng trong tài liệu. Điều này có nghĩa là vị trí của thành phần hiển thị trong cây hiển thị giống như vị trí của thành phần hiển thị trong cây DOM và được bố trí theo loại hộp và kích thước của thành phần hiển thị
- Float (Nổi): trước tiên, đối tượng được bố trí như luồng thông thường, sau đó được di chuyển sang trái hoặc phải càng xa càng tốt
- Tuyệt đối: đối tượng được đặt trong cây kết xuất ở một vị trí khác với trong cây DOM
Lược đồ định vị được đặt bằng thuộc tính "position" và thuộc tính "float".
- tĩnh và tương đối gây ra luồng thông thường
- tuyệt đối và cố định gây ra vị trí tuyệt đối
Trong chế độ định vị tĩnh, không có vị trí nào được xác định và chế độ định vị mặc định sẽ được sử dụng. Trong các lược đồ khác, tác giả chỉ định vị trí: trên cùng, dưới cùng, bên trái, bên phải.
Cách bố trí hộp được xác định bằng:
- Loại hộp
- Kích thước hộp
- Lược đồ định vị
- Thông tin bên ngoài, chẳng hạn như kích thước hình ảnh và kích thước màn hình
Loại hộp
Hộp khối: tạo một khối – có hình chữ nhật riêng trong cửa sổ trình duyệt.

Hộp nội tuyến: không có khối riêng, nhưng nằm bên trong một khối chứa.
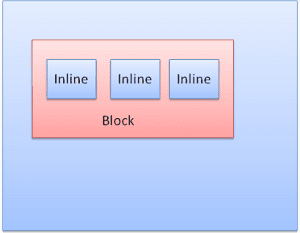
Các khối được định dạng theo chiều dọc, khối này sau khối kia. Nội dung nội tuyến được định dạng theo chiều ngang.
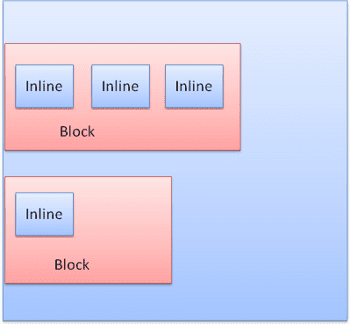
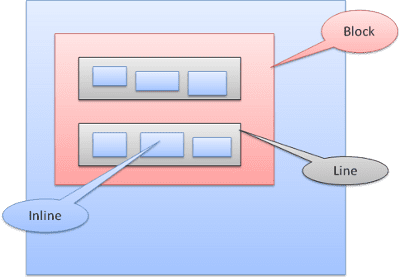
Hộp nội tuyến được đặt bên trong các đường hoặc "hộp đường". Các đường này ít nhất phải cao bằng hộp cao nhất nhưng có thể cao hơn khi các hộp được căn chỉnh "dòng cơ sở" – nghĩa là phần dưới cùng của một phần tử được căn chỉnh tại một điểm của hộp khác không phải là phần dưới cùng. Nếu chiều rộng vùng chứa không đủ, các dòng nội dung cùng dòng sẽ được đặt trên nhiều dòng. Đây thường là những gì xảy ra trong một đoạn văn.
Khẳng định vị thế
Họ hàng
Định vị tương đối – được định vị như bình thường rồi di chuyển theo delta bắt buộc.
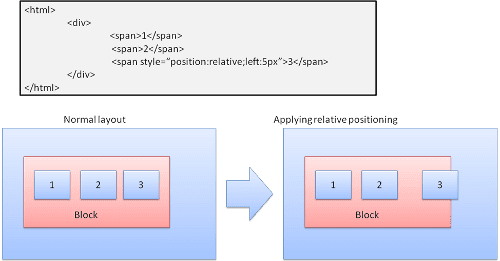
Nổi
Hộp nổi được dịch chuyển sang trái hoặc phải của một dòng. Điểm thú vị là các hộp khác sẽ trôi xung quanh hộp này. HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Sẽ có dạng như sau:

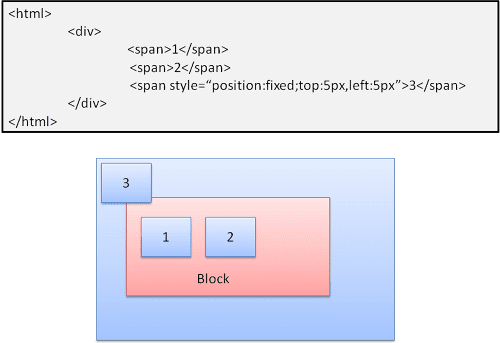
Tuyệt đối và cố định
Bố cục được xác định chính xác bất kể luồng thông thường. Phần tử không tham gia vào luồng thông thường. Các kích thước này tương ứng với vùng chứa. Trong chế độ cố định, vùng chứa là khung nhìn.
Biểu diễn theo lớp
Điều này được chỉ định bằng thuộc tính CSS z-index. Giá trị này thể hiện chiều thứ ba của hộp: vị trí của hộp dọc theo "trục z".
Các hộp được chia thành ngăn xếp (gọi là ngữ cảnh xếp chồng). Trong mỗi ngăn xếp, các phần tử lui sẽ được vẽ trước và các phần tử chuyển tiếp ở trên cùng, gần người dùng hơn. Trong trường hợp chồng chéo, phần tử ở trên cùng sẽ ẩn phần tử trước đó.
Các ngăn xếp được sắp xếp theo thuộc tính z-index. Các hộp có thuộc tính "z-index" tạo thành một ngăn xếp cục bộ. Khung nhìn có ngăn xếp bên ngoài.
Ví dụ:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Kết quả sẽ là:

Mặc dù div màu đỏ đứng trước div màu xanh lục trong mã đánh dấu và sẽ được vẽ trước trong luồng thông thường, nhưng thuộc tính z-index cao hơn, vì vậy, thuộc tính này sẽ nằm ở phía trước hơn trong ngăn xếp do hộp gốc giữ.
Tài nguyên
Cấu trúc trình duyệt
- Grosskurth, Alan. Cấu trúc tham chiếu cho trình duyệt web (pdf)
- Gupta, Vineet. Cách hoạt động của trình duyệt – Phần 1 – Cấu trúc
Phân tích cú pháp
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (còn gọi là "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: hai bản nháp mới cho HTML 5.
Firefox
- L. David Baron, HTML và CSS nhanh hơn: Nội dung bên trong công cụ bố cục dành cho nhà phát triển web.
- L. David Baron, HTML và CSS nhanh hơn: Nội dung bên trong của công cụ bố cục dành cho nhà phát triển web (video nói chuyện về công nghệ của Google)
- L. David Baron, Công cụ bố cục của Mozilla
- L. David Baron, Tài liệu về hệ thống theo phong cách Mozilla
- Chris Waterson, Ghi chú về tính năng Luồng lại HTML
- Chris Waterson, Tổng quan về Gecko
- Alexander Larsson, Vòng đời của một yêu cầu HTTP HTML
WebKit
- David Hyatt, Triển khai CSS(phần 1)
- David Hyatt, Tổng quan về WebCore
- David Hyatt, Hiển thị WebCore
- David Hyatt, Vấn đề FOUC
Thông số kỹ thuật của W3C
Hướng dẫn tạo bản dựng trình duyệt
Bản dịch
Trang này đã được dịch sang tiếng Nhật hai lần:
- Cách hoạt động của trình duyệt – Nhìn vào hoạt động hậu trường của trình duyệt web hiện đại (tiếng Nhật) của @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 của @ikeike443 và @kiyoto01.
Bạn có thể xem các bản dịch được lưu trữ bên ngoài bằng ngôn ngữ tiếng Hàn và tiếng Thổ Nhĩ Kỳ.
Cảm ơn mọi người!