

Chociaż „L” w terminie „duże modele językowe” sugeruje ogromną skalę, rzeczywistość jest bardziej złożona. Niektóre modele LLM zawierają biliony parametrów, a inne działają skutecznie z wielokrotnie mniejszą ich liczbą.
Zapoznaj się z kilkoma praktycznymi przykładami i zastosowaniami różnych rozmiarów modeli.
Rozmiary i klasy rozmiarów LLM
Jako programiści stron internetowych zwykle myślimy o rozmiarze zasobu jako o rozmiarze pliku do pobrania. Udokumentowany rozmiar modelu odnosi się do liczby jego parametrów. Na przykład Gemma 2B oznacza model Gemma z 2 miliardami parametrów.
Sieci LLM mogą mieć setki tysięcy, miliony, miliardy, a nawet tryliony parametrów.
Większe modele LLM mają więcej parametrów niż ich mniejsze odpowiedniki, co pozwala im uchwycić bardziej złożone relacje językowe i rozpoznawać subtelne prompty. Są one też często trenowane na większych zbiorach danych.
Zauważysz pewnie, że niektóre rozmiary modeli, np. 2 mld lub 7 mld, są popularne. Na przykład Gemma 2B, Gemma 7B lub Mistral 7B. Klasy rozmiarów modeli to przybliżone grupy. Na przykład Gemma 2B ma około 2 miliardów parametrów, ale nie dokładnie.
Klasy rozmiarów modeli to praktyczny sposób na oszacowanie wydajności LLM. Traktuj je jak kategorie wagowe w boksie: modele w tej samej klasie rozmiarów są bardziej porównywalne. Oba modele 2B powinny zapewniać podobną skuteczność.
W przypadku niektórych zadań mniejszy model może osiągnąć taką samą wydajność jak większy model.

Chociaż rozmiary najnowszych, najnowocześniejszych modeli LLM, takich jak GPT-4 czy Gemini Pro lub Ultra, nie są zawsze ujawniane, szacuje się, że mają one setki miliardów lub tryliony parametrów.

Nie wszystkie modele podają liczbę parametrów w nazwie. Niektóre modele mają w przydomku numer wersji. Na przykład Gemini 1.5 Pro odnosi się do wersji 1.5 modelu (po wersji 1).
LLM czy nie LLM?
Kiedy model jest za mały, aby był dużym modelem językowym? Definicja LLM może być nieco płynna w środowisku AI i ML.
Niektórzy uważają, że prawdziwe LLM to tylko największe modele z miliardami parametrów, podczas gdy mniejsze modele, takie jak DistilBERT, są uważane za proste modele NLP. Inni autorzy definiują LLM jako mniejsze, ale nadal wydajne modele, np. DistilBERT.
Mniejsze modele LLM do zastosowań na urządzeniu
Większe LLM wymagają dużo miejsca na dane i dużej mocy obliczeniowej na potrzeby wnioskowania. Muszą one działać na dedykowanych, wydajnych serwerach z użyciem określonego sprzętu (np. TPU).
Jako deweloperzy witryn interesuje nas m.in. to, czy model jest wystarczająco mały, aby można go było pobrać i uruchomić na urządzeniu użytkownika.
To trudne pytanie. Obecnie nie ma łatwego sposobu na to, aby wiedzieć, że „ten model może działać na większości urządzeń klasy średniej”, z kilku powodów:
- Możliwości urządzeń różnią się w zależności od specyfikacji pamięci, procesora graficznego i procesora. Tani telefon z Androidem a laptop z kartą NVIDIA® RTX to dwa zupełnie inne urządzenia. Możesz mieć pewne dane o tym, jakie urządzenia mają Twoi użytkownicy. Nie mamy jeszcze definicji urządzenia bazowego używanego do uzyskiwania dostępu do internetu.
- Model lub platforma, na której działa, może być zoptymalizowany pod kątem działania na określonym sprzęcie.
- Nie ma programowego sposobu na określenie, czy dany model LLM można pobrać i uruchomić na konkretnym urządzeniu. Możliwości pobierania urządzenia zależą m.in. od ilości pamięci VRAM na karcie graficznej.
Mamy jednak pewne dane empiryczne: obecnie w przeglądarce na urządzeniach konsumenckich mogą działać modele z kilkoma milionami do kilku miliardów parametrów.
Na przykład:
- Gemma 2B z interfejsem MediaPipe LLM Inference API (nawet na urządzenia z procesorem tylko na potrzeby CPU). Wypróbuj
- DistilBERT z Transformers.js.
To jest nowe pole. Oto, czego możesz się spodziewać:
- Dzięki innowacjom związanym z WebAssembly i WebGPU oraz obsłudze WebGPU w coraz większej liczbie bibliotek oraz nowych bibliotek i optymalizacji urządzenia użytkowników będą coraz lepiej radzić sobie z efektywnym uruchamianiem LLM o różnej wielkości.
- Spodziewaj się, że mniejsze, bardzo wydajne LLM będą coraz bardziej popularne dzięki nowym technikom kompresji.
Uwagi dotyczące mniejszych modeli LSTM
Podczas pracy z mniejszymi modelami LLM należy zawsze uwzględniać wydajność i rozmiar pobierania.
Wyniki
Możliwości każdego modelu w dużej mierze zależą od przypadku użycia. Mniejszy model LLM dostosowany do Twojego przypadku użycia może działać lepiej niż większy ogólny model LLM.
Jednak w ramach tej samej rodziny modeli mniejsze modele LLM są mniej wydajne niż ich większe odpowiedniki. W przypadku tego samego zastosowania zazwyczaj trzeba wykonać więcej prac związanych z promptami, gdy używa się mniejszego LLM.
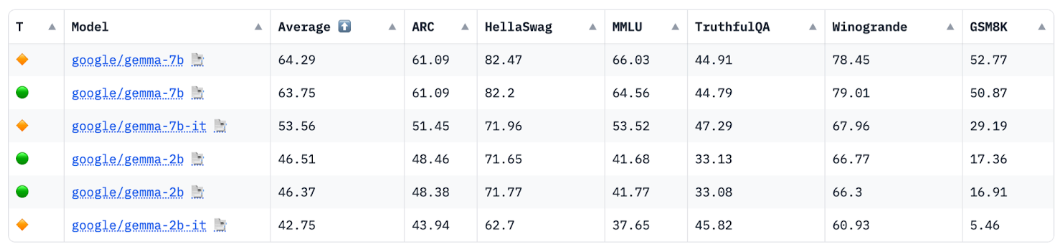
Źródło: tablica liderów w kategorii Open LLM na stronie huggingface.co, kwiecień 2024 r.
Rozmiar pobierania
Więcej parametrów oznacza większy rozmiar pliku do pobrania, co wpływa na to, czy model, nawet jeśli jest mały, może być pobierany w rozsądnym rozmiarze na potrzeby użycia na urządzeniu.
Chociaż istnieją techniki umożliwiające obliczenie rozmiaru pobrania modelu na podstawie liczby parametrów, może to być skomplikowane.
Na początku 2024 r. rozmiary plików do pobrania modeli są rzadko dokumentowane. Dlatego w przypadku korzystania z urządzenia i przeglądarki zalecamy sprawdzenie rozmiaru pobierania empirycznie na panelu Sieć w Narzędziach deweloperskich Chrome lub za pomocą innych narzędzi dla programistów w przeglądarce.

Gemma jest używana z interfejsem MediaPipe LLM Inference API. DistilBERT jest używany z Transformers.js.
Techniki zmniejszania rozmiaru modelu
Istnieje kilka metod na znaczne zmniejszenie wymagań pamięciowych modelu:
- LoRA (Low-Rank Adaptation): technika dokładnego dostrajania, w której zamrożone są wstępnie wytrenowane wartości wag. Więcej informacji o LoRA
- Pruning: usuwanie z modelu mniej ważnych wag w celu zmniejszenia jego rozmiaru.
- Kwantizowanie: zmniejszenie dokładności wag z liczb zmiennoprzecinkowych (np. 32-bitowych) do reprezentacji o mniejszej precyzji (np. 8-bitowej).
- Destylacja wiedzy: trenowanie mniejszego modelu w celu naśladowania zachowania większego, wstępnie wytrenowanego modelu.
- Udostępnianie parametrów: w wielu częściach modelu używasz tych samych wag, co zmniejsza łączną liczbę unikalnych parametrów.