

Introduzione
Le estensioni Media Source (MSE)
forniscono un controllo esteso del buffering e della riproduzione per gli elementi HTML5 <audio> e
<video>. Sebbene originariamente sviluppati per facilitare i video player basati su
Dynamic Adaptive Streaming over HTTP (DASH),
di seguito vedremo come possono essere utilizzati per l'audio, in particolare per la
riproduzione senza interruzioni.
Probabilmente hai ascoltato un album musicale in cui i brani si susseguono senza interruzioni tra le tracce; potresti anche starne ascoltando uno in questo momento. Gli artisti creano queste esperienze di riproduzione senza interruzioni sia come scelta artistica sia come artefatto di vinili e CD in cui l'audio è stato scritto come un unico flusso continuo. Purtroppo, a causa del funzionamento dei moderni codec audio come MP3 e AAC, questa esperienza uditiva fluida viene spesso persa oggi.
Di seguito esamineremo i dettagli del motivo, ma per ora iniziamo con una dimostrazione. Di seguito sono riportati i primi 30 secondi dell'eccellente Sintel suddivisi in cinque file MP3 separati e riassemblati utilizzando MSE. Le linee rosse indicano i vuoti introdotti durante la creazione (codifica) di ogni MP3; in questi punti sentirai dei problemi.
Bleah! Non è una bella esperienza, possiamo fare di meglio. Con un po' di lavoro in più, utilizzando gli stessi file MP3 della demo precedente, possiamo utilizzare MSE per rimuovere questi fastidiosi spazi vuoti. Le linee verdi nella demo successiva indicano dove i file sono stati uniti e le lacune rimosse. Su Chrome 38 e versioni successive, la riproduzione sarà perfetta.
Esistono diversi modi per creare contenuti senza interruzioni. Ai fini di questa demo, ci concentreremo sul tipo di file che un utente normale potrebbe avere a disposizione. In cui ogni file è stato codificato separatamente senza tenere conto dei segmenti audio precedenti o successivi.
Impostazione di base
Innanzitutto, torniamo indietro e vediamo la configurazione di base di un'istanza MediaSource.
Le estensioni delle origini media, come suggerisce il nome, sono solo estensioni degli elementi multimediali esistenti. Di seguito, assegniamo un
Object URL,
che rappresenta la nostra istanza MediaSource, all'attributo sorgente di un elemento audio,
proprio come faresti con un URL standard.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
Una volta connesso l'oggetto MediaSource, verrà eseguita l'inizializzazione e verrà attivato un evento sourceopen, a quel punto potremo creare un SourceBuffer. Nell'esempio
precedente, stiamo creando un audio/mpeg, che è in grado di analizzare e
decodificare i nostri segmenti MP3. Sono disponibili diversi
altri tipi.
Forme d'onda anomale
Torneremo al codice tra un attimo, ma ora esaminiamo più da vicino il file che abbiamo appena aggiunto, in particolare la fine. Di seguito è riportato un grafico degli ultimi 3000 campioni, calcolati come media su entrambi i canali della traccia sintel_0.mp3. Ogni pixel sulla linea rossa è un
campione in virgola mobile
nell'intervallo di [-1.0, 1.0].

Che cosa sono tutti questi campioni con valore zero (silenziosi)? Sono dovuti in realtà ad artefatti di compressione introdotti durante la codifica. Quasi tutti i codificatori introducono un qualche tipo di padding. In questo caso, LAME ha aggiunto esattamente 576 campioni di padding alla fine del file.
Oltre al padding alla fine, a ogni file è stato aggiunto anche un padding all'inizio. Se diamo un'occhiata alla
sintel_1.mp3
traccia, vedremo altri 576 campioni di padding all'inizio. La quantità
di padding varia in base al codificatore e ai contenuti, ma conosciamo i valori esatti in base a
metadata inclusi in ogni file.
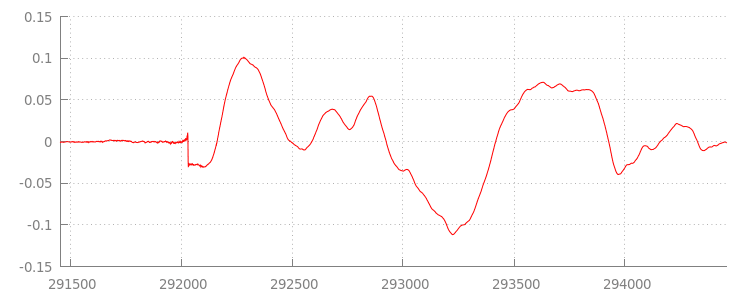
Le sezioni di silenzio all'inizio e alla fine di ogni file sono la causa dei
glitch tra i segmenti della demo precedente. Per ottenere una riproduzione senza interruzioni,
dobbiamo rimuovere queste sezioni di silenzio. Per fortuna, questa operazione è facile da eseguire con
MediaSource. Di seguito, modificheremo il nostro metodo onAudioLoaded() per utilizzare una finestra di accodamento e un offset del timestamp per rimuovere questo silenzio.
Codice di esempio
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Una forma d'onda senza interruzioni
Vediamo cosa ha ottenuto il nostro nuovo codice esaminando di nuovo la
forma d'onda dopo aver applicato le finestre di accodamento. Di seguito, puoi notare che la
sezione silenziosa alla fine di
sintel_0.mp3
(in rosso) e la sezione silenziosa all'inizio di
sintel_1.mp3
(in blu) sono state rimosse, lasciando una transizione fluida tra i
segmenti.
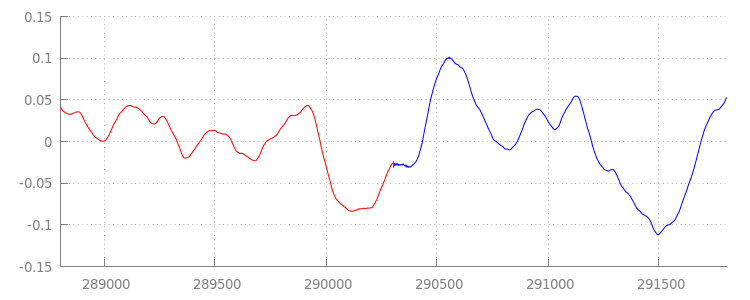
Conclusione
In questo modo, abbiamo unito tutti e cinque i segmenti in modo fluido e abbiamo
raggiunto la fine della nostra demo. Prima di andare, avrai notato
che il nostro metodo onAudioLoaded() non tiene conto di container o codec.
Ciò significa che tutte queste tecniche funzioneranno indipendentemente dal tipo di container o
codec. Di seguito puoi riprodurre la demo originale in formato MP4 frammentato pronto per DASH
anziché MP3.
Se vuoi saperne di più, consulta le appendici di seguito per un'analisi più approfondita della
creazione di contenuti senza interruzioni e dell'analisi dei metadati. Puoi anche esplorare
gapless.js per dare un'occhiata più da vicino
al codice che alimenta questa demo.
Grazie per l'attenzione.
Appendice A: Creazione di contenuti senza interruzioni
Creare contenuti senza interruzioni può essere difficile. Di seguito esamineremo la creazione dei contenuti multimediali Sintel utilizzati in questa demo. Per iniziare, avrai bisogno di una copia della colonna sonora FLAC lossless di Sintel; per i posteri, l'SHA1 è incluso di seguito. Per gli strumenti, avrai bisogno di FFmpeg, MP4Box, LAME e un'installazione OSX con afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Per prima cosa, estraiamo i primi 31,5 secondi della traccia 1-Snow_Fight.flac. Vogliamo
anche aggiungere una dissolvenza in uscita di 2,5 secondi a partire dal 28° secondo per evitare
clic al termine della riproduzione. Utilizzando la riga di comando FFmpeg riportata di seguito, possiamo
ottenere tutto questo e inserire i risultati in sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Successivamente, divideremo il file in 5 file wave
di 6,5 secondi ciascuno.È più facile utilizzare wave perché quasi tutti i codificatori
ne supportano l'importazione. Anche in questo caso, possiamo farlo con precisione con FFmpeg, dopo
di che avremo: sintel_0.wav, sintel_1.wav, sintel_2.wav,
sintel_3.wav e sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
A questo punto, creiamo i file MP3. LAME offre diverse opzioni per creare contenuti
senza interruzioni. Se hai il controllo dei contenuti, potresti prendere in considerazione l'utilizzo di --nogap
con una codifica batch di tutti i file per evitare del tutto il padding tra i segmenti.
Ai fini di questa demo, però, vogliamo questo padding, quindi utilizzeremo una codifica VBR standard di alta qualità dei file wave.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
Questo è tutto ciò che è necessario per creare i file MP3. Ora vediamo la creazione dei file MP4 frammentati. Seguiremo le indicazioni di Apple per la creazione di contenuti multimediali masterizzati per iTunes. Di seguito, convertiremo i file wave in file CAF intermedi, come da istruzioni, prima di codificarli come AAC in un contenitore MP4 utilizzando i parametri consigliati.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Ora abbiamo diversi file M4A che dobbiamo
frammentare
in modo appropriato prima di poterli utilizzare con
MediaSource. Ai nostri fini, utilizzeremo una dimensione del frammento di un secondo. MP4Box
scriverà ogni MP4 frammentato come sintel_#_dashinit.mp4 insieme a un
manifest MPEG-DASH (sintel_#_dash.mpd) che può essere eliminato.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
È tutto. Ora abbiamo file MP4 e MP3 frammentati con i metadati corretti necessari per la riproduzione senza interruzioni. Per ulteriori dettagli su come appaiono questi metadati, consulta l'appendice B.
Appendice B: analisi dei metadati senza interruzioni
Proprio come la creazione di contenuti senza interruzioni, l'analisi dei metadati senza interruzioni può essere complicata
poiché non esiste un metodo di archiviazione standard. Di seguito vedremo come i due codificatori più comuni, LAME e iTunes, archiviano i metadati gapless. Iniziamo configurando alcuni metodi helper e una struttura per ParseGaplessData() utilizzato
sopra.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Inizieremo con il formato dei metadati di iTunes di Apple, perché è il più semplice da analizzare e spiegare. All'interno dei file MP3 e M4A, iTunes (e afconvert) scrivono una breve sezione in ASCII come segue:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Queste informazioni vengono scritte all'interno di un tag ID3 nel contenitore MP3 e all'interno di un atomo di metadati nel contenitore MP4. Ai nostri fini, possiamo ignorare il primo
token 0000000. I tre token successivi sono il padding iniziale, il padding finale e
il conteggio totale dei campioni non di padding. Dividendo ciascuno di questi valori per la frequenza di campionamento dell'audio, otteniamo la durata di ciascuno.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
Al contrario, la maggior parte dei codificatori MP3 open source memorizza i metadati gapless all'interno di un'intestazione Xing speciale inserita in un frame MPEG silenzioso (è silenzioso, quindi i decoder che non comprendono l'intestazione Xing riprodurranno semplicemente il silenzio). Purtroppo questo tag non è sempre presente e ha diversi campi facoltativi. Ai fini di questa demo, abbiamo il controllo sui contenuti multimediali, ma in pratica saranno necessari alcuni controlli di sensibilità aggiuntivi per sapere quando i metadati gapless sono effettivamente disponibili.
Per prima cosa, analizzeremo il conteggio totale dei campioni. Per semplicità, leggeremo questo valore dall'intestazione Xing, ma potrebbe essere costruito dall'intestazione audio MPEG normale.
Le intestazioni Xing possono essere contrassegnate da un tag Xing o Info. Esattamente 4 byte
dopo questo tag ci sono 32 bit che rappresentano il numero totale di frame nel
file; moltiplicando questo valore per il numero di campioni per frame si ottiene il
numero totale di campioni nel file.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Ora che abbiamo il numero totale di campioni, possiamo passare alla lettura del numero di campioni di riempimento. A seconda del codificatore, questa informazione potrebbe essere scritta in un tag LAME o Lavf nidificato nell'intestazione Xing. Esattamente 17 byte dopo questa intestazione ci sono 3 byte che rappresentano il padding iniziale e finale rispettivamente in 12 bit ciascuno.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
In questo modo, abbiamo una funzione completa per analizzare la stragrande maggioranza dei contenuti senza spazi. Tuttavia, i casi limite sono certamente numerosi, quindi si consiglia cautela prima di utilizzare un codice simile in produzione.
Appendice C: sulla raccolta dei rifiuti
La memoria appartenente alle istanze SourceBuffer viene
raccolta attivamente
in base al tipo di contenuti, ai limiti specifici della piattaforma e alla posizione
di riproduzione corrente. In Chrome, la memoria verrà recuperata prima dai buffer già riprodotti.
Tuttavia, se la memoria utilizzata supera i limiti specifici della piattaforma, la memoria viene rimossa dai buffer non riprodotti.
Quando la riproduzione raggiunge un intervallo nella sequenza temporale a causa della memoria recuperata, potrebbe presentare problemi se l'intervallo è abbastanza piccolo o bloccarsi completamente se l'intervallo è troppo grande. Nessuna delle due soluzioni offre un'esperienza utente ottimale, pertanto è importante evitare di aggiungere troppi dati contemporaneamente e rimuovere manualmente gli intervalli dalla cronologia dei contenuti multimediali che non sono più necessari.
Gli intervalli possono essere rimossi tramite il metodo
remove()
su ogni SourceBuffer, che richiede un intervallo di [start, end] secondi.
Analogamente a appendBuffer(), ogni remove() attiverà un evento updateend una volta
completato. Altre rimozioni o aggiunte non devono essere eseguite finché non viene attivato l'evento.
Nella versione desktop di Chrome, puoi memorizzare contemporaneamente circa 12 megabyte di contenuti audio e 150 megabyte di contenuti video. Non devi fare affidamento su questi valori su browser o piattaforme; ad esempio, non sono certamente rappresentativi dei dispositivi mobili.
La garbage collection influisce solo sui dati aggiunti a SourceBuffers; non ci sono limiti alla quantità di dati che puoi mantenere memorizzati nelle variabili JavaScript. Se necessario, puoi anche riaggiungere gli stessi dati nella stessa posizione.