

With Service Workers, we gave developers a way to solve network connection. You get control over caching and how requests are handled. That means you get to create your own patterns. Take a look at a few possible patterns in isolation, but in practice, you'll likely use them in tandem, depending on URL and context.
For a working demo of some of these patterns, see Trained-to-thrill.
When to store resources
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)
Service workers let you handle requests independently from caching, so I'll demonstrate them separately. First up, determining when you should use cache.
On install, as a dependency
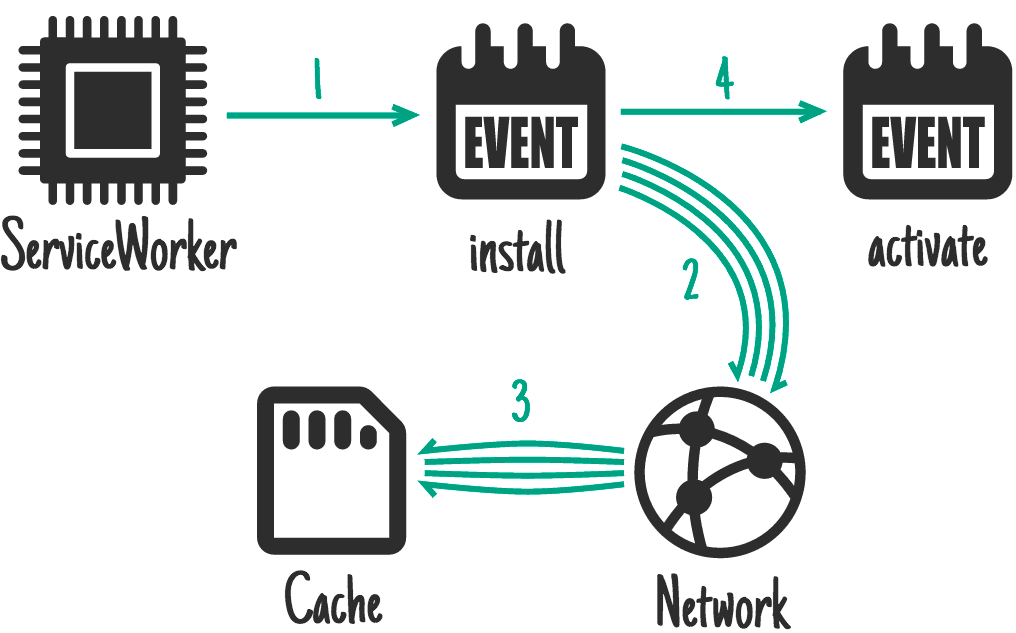
The Service Worker API gives you an install event. You can use this to get
stuff ready, stuff that must be ready before you handle other events. During
install, previous versions of your service worker keep running and serving
pages. Whatever you do at this time shouldn't disrupt the existing
service worker.
Ideal for: CSS, images, fonts, JS, templates, or anything else you'd consider static to that version of your site.
Fetch the things that would make your site entirely unfunctional if they failed to be fetched, things an equivalent platform-specific app would make part of the initial download.
self.addEventListener('install', function (event) {
event.waitUntil(
caches.open('mysite-static-v3').then(function (cache) {
return cache.addAll([
'/css/whatever-v3.css',
'/css/imgs/sprites-v6.png',
'/css/fonts/whatever-v8.woff',
'/js/all-min-v4.js',
// etc.
]);
}),
);
});
event.waitUntil takes a promise to define the length and success of the install. If the promise
rejects, the installation is considered a failure and this Service Worker is abandoned (if an
older version is running, it'll be left intact). caches.open() and cache.addAll() return promises.
If any of the resources fail to be fetched, the cache.addAll() call rejects.
On trained-to-thrill I use this to cache static assets.
On install, not as a dependency

This is similar to installing as a dependency, but won't delay install completing and won't cause installation to fail if caching fails.
Ideal for: Bigger resources that aren't needed straight away, such as assets for later levels of a game.
self.addEventListener('install', function (event) {
event.waitUntil(
caches.open('mygame-core-v1').then(function (cache) {
cache
.addAll
// levels 11-20
();
return cache
.addAll
// core assets and levels 1-10
();
}),
);
});
This example does not pass the cache.addAll promise for levels 11–20 back to
event.waitUntil, so even if it fails, the game will still be available offline. Of course, you'll
have to cater for the possible absence of those levels and reattempt caching them if they're
missing.
The service worker may be killed while levels 11–20 download since it's finished handling events, meaning they won't be cached. Web Periodic Background Synchronization API can handle cases like this, and larger downloads such as movies.
On activate

Ideal for: clean-up and migration.
Once a new service worker has installed and a previous version isn't being used, the new one
activates, and you get an activate event. Because the previous version is out of the way, it's a good
time to handle
schema migrations in IndexedDB
and also delete unused caches.
self.addEventListener('activate', function (event) {
event.waitUntil(
caches.keys().then(function (cacheNames) {
return Promise.all(
cacheNames
.filter(function (cacheName) {
// Return true if you want to remove this cache,
// but remember that caches are shared across
// the whole origin
})
.map(function (cacheName) {
return caches.delete(cacheName);
}),
);
}),
);
});
During activation, events such as fetch are put into a queue, thus a long activation could
block page loads. Keep your activation as lean as possible, and only use it for things you
couldn't do while the previous version was active.
On trained-to-thrill I use this to remove old caches.
On user interaction

Ideal for: when the whole site can't be taken offline, and you chose to allow the user to select the content they want available offline. E.g. a video on something like YouTube, an article on Wikipedia, a particular gallery on Flickr.
Give the user a "Read later" or "Save for offline" button. When it's clicked, fetch what you need from the network and pop it in the cache.
document.querySelector('.cache-article').addEventListener('click', function (event) {
event.preventDefault();
var id = this.dataset.articleId;
caches.open('mysite-article-' + id).then(function (cache) {
fetch('/get-article-urls?id=' + id)
.then(function (response) {
// /get-article-urls returns a JSON-encoded array of
// resource URLs that a given article depends on
return response.json();
})
.then(function (urls) {
cache.addAll(urls);
});
});
});
The Cache API is available from pages and service workers, which means you can add to the cache directly from the page.
On network response

Ideal for: frequently updating resources such as a user's inbox, or article contents. Also useful for non-essential content such as avatars, but care is needed.
If a request doesn't match anything in the cache, get it from the network, send it to the page, and add it to the cache at the same time.
If you do this for a range of URLs, such as avatars, you'll need to be careful you don't bloat the storage of your origin. If the user needs to reclaim disk space you don't want to be the prime candidate. Make sure you get rid of items in the cache you don't need any more.
self.addEventListener('fetch', function (event) {
event.respondWith(
caches.open('mysite-dynamic').then(function (cache) {
return cache.match(event.request).then(function (response) {
return (
response ||
fetch(event.request).then(function (response) {
cache.put(event.request, response.clone());
return response;
})
);
});
}),
);
});
To allow for efficient memory usage, you can only read a response/request's body once. The code
sample uses .clone() to create additional
copies that can be read separately.
On trained-to-thrill I use this to cache Flickr images.
Stale-while-revalidate

Ideal for: frequently updating resources where having the very latest version is non-essential. Avatars can fall into this category.
If there's a cached version available, use it, but fetch an update for next time.
self.addEventListener('fetch', function (event) {
event.respondWith(
caches.open('mysite-dynamic').then(function (cache) {
return cache.match(event.request).then(function (response) {
var fetchPromise = fetch(event.request).then(function (networkResponse) {
cache.put(event.request, networkResponse.clone());
return networkResponse;
});
return response || fetchPromise;
});
}),
);
});
This is very similar to HTTP's stale-while-revalidate.
On push message
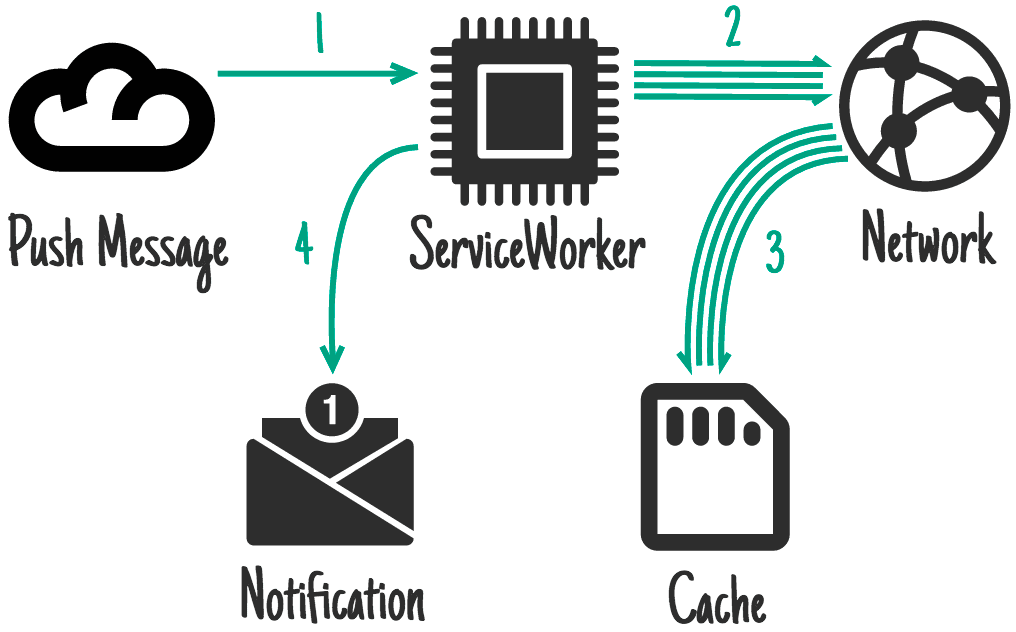
The Push API is another feature built on top of service worker. This allows the service worker to be awoken in response to a message from the OS's messaging service. This happens even when the user doesn't have a tab open to your site. Only the service worker is woken up. You request permission to do this from a page and the user is prompted.
Ideal for: content relating to a notification, such as a chat message, a breaking news story, or an email. Also infrequently changing content that benefits from immediate sync, such as a to-do list update or a calendar alteration.
The common final outcome is a notification which, when tapped, opens and focuses a relevant page, and for which updating caches beforehand is extremely important. The user is online at the time of receiving the push message, but they may not be when they finally interact with the notification, so it's critical to make this content available offline.
This code updates caches before showing a notification:
self.addEventListener('push', function (event) {
if (event.data.text() == 'new-email') {
event.waitUntil(
caches
.open('mysite-dynamic')
.then(function (cache) {
return fetch('/inbox.json').then(function (response) {
cache.put('/inbox.json', response.clone());
return response.json();
});
})
.then(function (emails) {
registration.showNotification('New email', {
body: 'From ' + emails[0].from.name,
tag: 'new-email',
});
}),
);
}
});
self.addEventListener('notificationclick', function (event) {
if (event.notification.tag == 'new-email') {
// Assume that all of the resources needed to render
// /inbox/ have previously been cached, e.g. as part
// of the install handler.
new WindowClient('/inbox/');
}
});
On background-sync

Background sync is another feature built on top of service worker. It lets you to request background data synchronization as a one-off, or on an (extremely heuristic) interval. This happens even when the user doesn't have a tab open to your site. Only the service worker is woken up. You request permission to do this from a page and the user is prompted.
Ideal for: non-urgent updates, especially those that happen so regularly that a push message per update would be too frequent for users, such as social timelines or news articles.
self.addEventListener('sync', function (event) {
if (event.id == 'update-leaderboard') {
event.waitUntil(
caches.open('mygame-dynamic').then(function (cache) {
return cache.add('/leaderboard.json');
}),
);
}
});
Cache persistence
Your origin is given a certain amount of free space to do what it wants with. That free space is shared between all origin storage: (local) Storage, IndexedDB, File System Access, and of course Caches.
The amount you get isn't spec'd. It differs depending on device and storage conditions. You can find out how much you've got with:
if (navigator.storage && navigator.storage.estimate) {
const quota = await navigator.storage.estimate();
// quota.usage -> Number of bytes used.
// quota.quota -> Maximum number of bytes available.
const percentageUsed = (quota.usage / quota.quota) * 100;
console.log(`You've used ${percentageUsed}% of the available storage.`);
const remaining = quota.quota - quota.usage;
console.log(`You can write up to ${remaining} more bytes.`);
}
However, like all browser storage, the browser is free to throw away your data if the device comes under storage pressure. Unfortunately the browser can't tell the difference between those movies you want to keep at all costs, and the game you don't really care about.
To work around this, use the StorageManager interface:
// From a page:
navigator.storage.persist()
.then(function(persisted) {
if (persisted) {
// Hurrah, your data is here to stay!
} else {
// So sad, your data may get chucked. Sorry.
});
Of course, the user has to grant permission. For this, use the Permissions API.
Making the user part of this flow is important, as we can now expect them to be in control of deletion. If their device comes under storage pressure, and clearing non-essential data doesn't solve it, the user gets to judge which items to keep and remove.
For this to work, it requires operating systems to treat "durable" origins as equivalent to platform-specific apps in their breakdowns of storage usage, rather than reporting the browser as a single item.
Serving suggestions
It doesn't matter how much caching you do, the service worker only uses the cache when you tell it when and how. Here are a few patterns to handle requests:
Cache only

Ideal for: anything you'd consider static to a particular "version" of your site. You should have cached these in the install event, so you can depend on them being there.
self.addEventListener('fetch', function (event) {
// If a match isn't found in the cache, the response
// will look like a connection error
event.respondWith(caches.match(event.request));
});
…although you don't often need to handle this case specifically, Cache, falling back to network covers it.
Network only

Ideal for: things that have no offline equivalent, such as analytics pings, non-GET requests.
self.addEventListener('fetch', function (event) {
event.respondWith(fetch(event.request));
// or don't call event.respondWith, which
// will result in default browser behavior
});
…although you don't often need to handle this case specifically, Cache, falling back to network covers it.
Cache, falling back to network

Ideal for: building offline-first. In such cases, this is how you'll handle the majority of requests. Other patterns are exceptions based on the incoming request.
self.addEventListener('fetch', function (event) {
event.respondWith(
caches.match(event.request).then(function (response) {
return response || fetch(event.request);
}),
);
});
This gives you the "cache only" behavior for things in the cache and the "network only" behavior for anything not-cached (which includes all non-GET requests, as they cannot be cached).
Cache and network race

Ideal for: small assets where you're chasing performance on devices with slow disk access.
With some combinations of older hard drives, virus scanners, and faster internet connections, getting resources from the network can be quicker than going to disk. However, going to the network when the user has the content on their device can be a waste of data, so bear that in mind.
// Promise.race rejects when a promise rejects before fulfilling.
// To make a race function:
function promiseAny(promises) {
return new Promise((resolve, reject) => {
// make sure promises are all promises
promises = promises.map((p) => Promise.resolve(p));
// resolve this promise as soon as one resolves
promises.forEach((p) => p.then(resolve));
// reject if all promises reject
promises.reduce((a, b) => a.catch(() => b)).catch(() => reject(Error('All failed')));
});
}
self.addEventListener('fetch', function (event) {
event.respondWith(promiseAny([caches.match(event.request), fetch(event.request)]));
});
Network falling back to cache

Ideal for: a quick-fix for resources that update frequently, outside of the "version" of the site. E.g. articles, avatars, social media timelines, and game leaderboards.
This means you give online users the most up-to-date content, but offline users get an older cached version. If the network request succeeds you'll most likely want to update the cache entry.
However, this method has flaws. If the user has an intermittent or slow connection they'll have to wait for the network to fail before they get the perfectly acceptable content already on their device. This can take an extremely long time and is a frustrating user experience. See the next pattern, Cache then network, for a better solution.
self.addEventListener('fetch', function (event) {
event.respondWith(
fetch(event.request).catch(function () {
return caches.match(event.request);
}),
);
});
Cache then network

Ideal for: content that updates frequently. E.g. articles, social media timelines, and games. leaderboards.
This requires the page to make two requests, one to the cache, and one to the network. The idea is to show the cached data first, then update the page when and if the network data arrives.
Sometimes you can just replace the current data when new data arrives (such as a game leaderboard), but that can be disruptive with larger pieces of content. Basically, don't "disappear" something the user may be reading or interacting with.
Twitter adds the new content above the old content and adjusts the scroll position so the user is uninterrupted. This is possible because Twitter retains a mostly-linear order to content. I copied this pattern for trained-to-thrill to get content on screen as fast as possible, while displaying up-to-date content as soon as it arrives.
Code in the page:
var networkDataReceived = false;
startSpinner();
// fetch fresh data
var networkUpdate = fetch('/data.json')
.then(function (response) {
return response.json();
})
.then(function (data) {
networkDataReceived = true;
updatePage(data);
});
// fetch cached data
caches
.match('/data.json')
.then(function (response) {
if (!response) throw Error('No data');
return response.json();
})
.then(function (data) {
// don't overwrite newer network data
if (!networkDataReceived) {
updatePage(data);
}
})
.catch(function () {
// we didn't get cached data, the network is our last hope:
return networkUpdate;
})
.catch(showErrorMessage)
.then(stopSpinner);
Code in the service worker:
You should always go to the network and update a cache as you go.
self.addEventListener('fetch', function (event) {
event.respondWith(
caches.open('mysite-dynamic').then(function (cache) {
return fetch(event.request).then(function (response) {
cache.put(event.request, response.clone());
return response;
});
}),
);
});
In trained-to-thrill I worked around this by using XHR instead of fetch, and abusing the Accept header to tell the service worker where to get the result from (page code, service worker code).
Generic fallback

If you fail to serve something from the cache or network, provide a generic fallback.
Ideal for: secondary imagery such as avatars, failed POST requests, and an "Unavailable while offline" page.
self.addEventListener('fetch', function (event) {
event.respondWith(
// Try the cache
caches
.match(event.request)
.then(function (response) {
// Fall back to network
return response || fetch(event.request);
})
.catch(function () {
// If both fail, show a generic fallback:
return caches.match('/offline.html');
// However, in reality you'd have many different
// fallbacks, depending on URL and headers.
// Eg, a fallback silhouette image for avatars.
}),
);
});
The item you fallback to is likely to be an install dependency.
If your page is posting an email, your service worker may fall back to storing the email in an IndexedDB outbox and respond by telling the page that the send failed but the data was successfully retained.
Service worker-side templating

Ideal for: pages that cannot have their server response cached.
It's faster to render pages on the server, but that can mean including state data that may not make sense in a cache, such as sign-in state. If your page is controlled by a service worker, you could choose to request JSON data along with a template and render that instead.
importScripts('templating-engine.js');
self.addEventListener('fetch', function (event) {
var requestURL = new URL(event.request.url);
event.respondWith(
Promise.all([
caches.match('/article-template.html').then(function (response) {
return response.text();
}),
caches.match(requestURL.path + '.json').then(function (response) {
return response.json();
}),
]).then(function (responses) {
var template = responses[0];
var data = responses[1];
return new Response(renderTemplate(template, data), {
headers: {
'Content-Type': 'text/html',
},
});
}),
);
});
Put it together
You aren't limited to one of these methods. In fact, you'll likely use many of them depending on request URL. For example, trained-to-thrill uses:
- Cache on install, for the static UI and behavior
- Cache on network response, for the Flickr images and data
- Fetch from cache, falling back to network, for most requests
- Fetch from cache, then network, for the Flickr search results
Just look at the request and decide what to do:
self.addEventListener('fetch', function (event) {
// Parse the URL:
var requestURL = new URL(event.request.url);
// Handle requests to a particular host specifically
if (requestURL.hostname == 'api.example.com') {
event.respondWith(/* some combination of patterns */);
return;
}
// Routing for local URLs
if (requestURL.origin == location.origin) {
// Handle article URLs
if (/^\/article\//.test(requestURL.pathname)) {
event.respondWith(/* some other combination of patterns */);
return;
}
if (/\.webp$/.test(requestURL.pathname)) {
event.respondWith(/* some other combination of patterns */);
return;
}
if (request.method == 'POST') {
event.respondWith(/* some other combination of patterns */);
return;
}
if (/cheese/.test(requestURL.pathname)) {
event.respondWith(
new Response('Flagrant cheese error', {
status: 512,
}),
);
return;
}
}
// A sensible default pattern
event.respondWith(
caches.match(event.request).then(function (response) {
return response || fetch(event.request);
}),
);
});
Further reading
- Service workers and the Cache Storage API
- JavaScript Promises—an Introduction: Guide to promises
Credits
For the lovely icons:
- Code by buzzyrobot
- Calendar by Scott Lewis
- Network by Ben Rizzo
- SD by Thomas Le Bas
- CPU by iconsmind.com
- Trash by trasnik
- Notification by @daosme
- Layout by Mister Pixel
- Cloud by P.J. Onori
And thanks to Jeff Posnick for catching many howling errors before I hit "publish".