



Fecha de publicación: 21 de mayo de 2025
Policybazaar es una de las plataformas de seguros líderes de la India, con más de 97 millones de clientes registrados. Alrededor del 80% de los clientes visita Policybazaar en línea todos los meses, por lo que es fundamental que sus plataformas ofrezcan experiencias del usuario fluidas.
El equipo de Policybazaar notó que una cantidad significativa de usuarios visitaba su sitio web por las tardes, después del horario de trabajo del equipo de asistencia al cliente. En lugar de que los usuarios tengan que esperar hasta el próximo día laboral para obtener respuestas o contratar personal durante la noche, Policybazaar quería implementar una solución para brindarles un servicio inmediato a esos usuarios.
Los clientes tienen muchas preguntas sobre los planes de seguros, cómo funcionan y cuál cubriría sus necesidades. Las preguntas personalizadas son difíciles de responder con un chatbot de preguntas frecuentes o basado en reglas. Para abordar estas necesidades, el equipo implementó asistencia personalizada con IA generativa.
73%
Los usuarios iniciaron conversaciones de calidad y participaron en ellas
200%
Tasa de clics más alta en comparación con el llamado a la acción anterior
10x
Inferencia más rápida con WebGPU
Asistencia personalizada con Finova AI
Para proporcionar respuestas personalizadas y una mejor asistencia al cliente en inglés y en el idioma nativo de algunos usuarios, Policybazaar creó un chatbot de asistente de seguros potenciado por texto y voz llamado Finova AI.
Se realizaron muchos pasos para que esto fuera posible. Mira una explicación detallada en la conferencia sobre casos de uso y estrategias de IA web en el mundo real de Google I/O 2025.
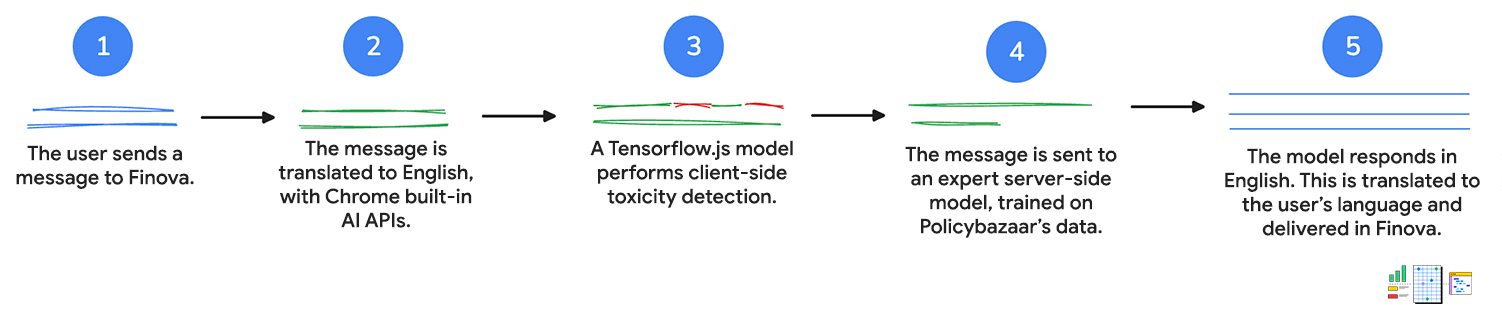
1. Entrada del usuario
Primero, el cliente envía un mensaje al chatbot, ya sea con texto o por voz. Si habla con el chatbot, se usa la API de Web Speech para convertir la voz en texto.
2. Traducir al inglés
El mensaje del cliente se envía a la API de Language Detector. Si la API detecta un idioma indio, la entrada se envía a la API de Translator para su traducción al inglés.
Ambas APIs ejecutan la inferencia del cliente, lo que significa que la entrada del usuario no sale del dispositivo durante la traducción.
3. El mensaje se evalúa con la detección de toxicidad
Se usa un modelo de detección de toxicidad del cliente para evaluar si la entrada del cliente contiene palabras inapropiadas o agresivas. Si es así, se le pedirá al cliente que reescriba el mensaje. El mensaje no pasará al siguiente paso si contiene lenguaje tóxico.
Esto ayuda a mantener conversaciones respetuosas para que el personal de asistencia al cliente las revise y realice un seguimiento, si es necesario.
4. La solicitud se envía al servidor
Luego, la consulta traducida se pasa a un modelo del servidor entrenado con los datos de Policybazaar y muestra una respuesta en inglés a la pregunta.
Los clientes pueden obtener respuestas y recomendaciones personalizadas, así como respuestas a preguntas más complejas sobre los productos.
5. Traducir al idioma del cliente
La API de Translator, que se usa para traducir la consulta inicial, la vuelve a traducir al idioma del cliente, como lo detecta la API de Language Detector. Una vez más, estas APIs se ejecutan del lado del cliente, por lo que todo ese trabajo se realiza en su dispositivo. Esto significa que los clientes pueden obtener asistencia en su idioma principal, lo que hace que el chatbot sea accesible para quienes no hablan inglés.
Arquitectura híbrida
Finova AI, que se ejecuta en plataformas para computadoras de escritorio y dispositivos móviles, se basa en varios modelos para generar los resultados finales. Policybazaar creó una arquitectura híbrida, en la que parte de la solución se ejecuta del lado del cliente y parte del lado del servidor.
Existen varios motivos por los que podrías querer implementar una arquitectura híbrida, ya sea que uses uno o varios modelos.
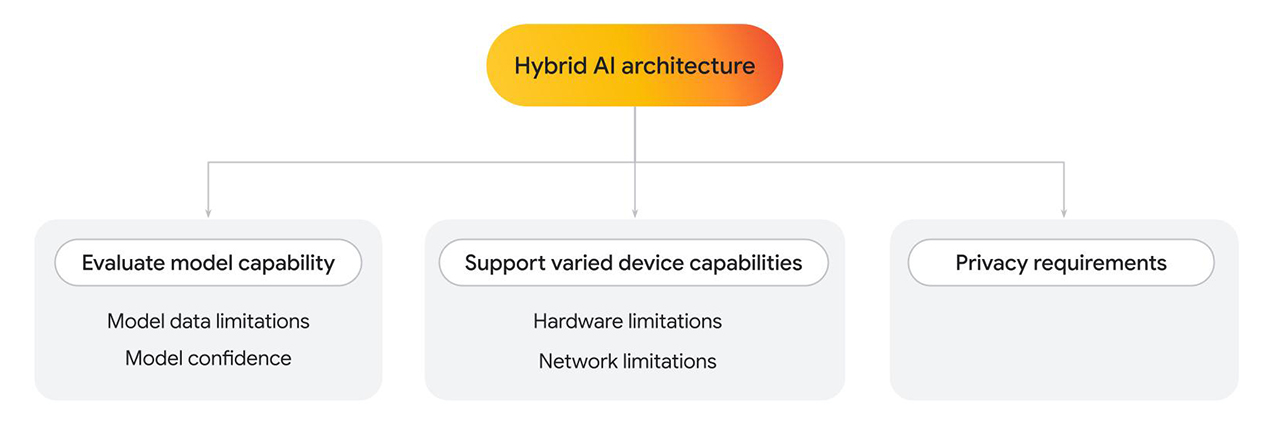
- Evalúa la capacidad del modelo del cliente. Recurre al servidor cuando sea necesario.
- Limitaciones de los datos de los modelos: Los modelos de lenguaje pueden variar mucho en tamaño, lo que también determina las capacidades específicas. Por ejemplo, imagina una situación en la que un usuario hace una pregunta personal referida a un servicio que proporcionas. Es posible que un modelo del cliente pueda responder la pregunta si se entrena en esa área específica. Sin embargo, si no es así, puedes recurrir a una implementación del servidor, que se entrena en un conjunto de datos más complejo y más grande.
- Confianza del modelo: En los modelos de clasificación, como la moderación de contenido o la detección de fraudes, un modelo del cliente puede generar una puntuación de confianza más baja. En este caso, te recomendamos que recurras a un modelo más potente del servidor.
- Admite diferentes capacidades de dispositivos.
- Limitaciones de hardware: Idealmente, todos los usuarios deberían poder acceder a las funciones de IA. En realidad, los usuarios usan una amplia variedad de dispositivos, y no todos pueden admitir la inferencia de IA. Si un dispositivo no puede admitir la inferencia del cliente, puedes recurrir al servidor. Con este enfoque, puedes hacer que tu función sea muy accesible y, al mismo tiempo, minimizar el costo y la latencia cuando sea posible.
- Limitaciones de red: Si el usuario no tiene conexión o está en redes inestables, pero tiene un modelo almacenado en caché en el navegador, puedes ejecutar el modelo del lado del cliente.
- Requisitos de privacidad.
- Es posible que tengas requisitos de privacidad estrictos para tu aplicación. Por ejemplo, si parte del flujo de usuarios requiere la verificación de identidad con información personal o detección facial, elige un modelo del cliente para procesar los datos en el dispositivo y enviar el resultado de la verificación (como aprobado o no aprobado) al modelo del servidor para los próximos pasos.
En el caso de Policybazaar, donde se requerían latencia baja, rentabilidad y privacidad, se usó una solución del cliente. Cuando se necesitaban modelos más complejos entrenados con datos personalizados, se usaba una solución del servidor.
Aquí, analizamos con más detalle la implementación del modelo del cliente.
Detección de toxicidad del cliente
Después de que se traducen los mensajes, el mensaje del cliente se pasa al modelo de detección de toxicidad de TensorFlow.js, que se ejecuta del lado del cliente, en computadoras y dispositivos móviles. Dado que la transcripción se reenvía al personal de asistencia humana para que realice un seguimiento, es importante evitar el lenguaje tóxico. Los mensajes se analizan en el dispositivo del usuario antes de enviarse al servidor, y luego el personal de asistencia humana final los revisa.
Además, el análisis del cliente permitió quitar la información sensible. La privacidad del usuario es una prioridad de primer nivel, y la inferencia del cliente ayuda a que eso sea posible.
Hay varios pasos obligatorios para cada mensaje. Con la detección de toxicidad, además de la detección y traducción de idiomas, cada mensaje requeriría varios viajes de ida y vuelta al servidor. Si realizas estas tareas del cliente, Policybazaar podría limitar significativamente el costo proyectado de la función.
Policybazaar cambió de WebGL a un backend de WebGPU (para navegadores compatibles) y el tiempo de inferencia mejoró 10 veces. Los usuarios recibieron comentarios más rápidos para revisar su mensaje, lo que generó una mayor participación y satisfacción del cliente.
// Create an instance of the toxicity model.
const createToxicityModelInstance = async () => {
try {
//use WebGPU backend if available
if (navigator.gpu) {
await window.tf.setBackend('webgpu');
await window.tf.ready();
}
return await window.toxicity.load(0.9).then(model => {
return model;
}).catch(error => {
console.log(error);
return null;
});
} catch (er) {
console.error(er);
}
}
Alta participación y tasa de clics
Combinando varios modelos con APIs web, Policybazaar amplió con éxito la asistencia al cliente después del horario de atención. Los primeros resultados de una versión limitada de esta función indicaron una alta participación de los usuarios.
El 73% de los usuarios que abrieron el chatbot participaron en conversaciones de varias preguntas que duraron varios minutos, lo que generó un porcentaje de rebote bajo. Además, el programa piloto demostró una tasa de clics 2 veces más alta en esta nueva llamada a la acción de asistencia al cliente, lo que demuestra una interacción exitosa de los clientes con Finova para sus consultas. Además, cambiar a un backend de WebGPU para la detección de toxicidad del cliente aceleró la inferencia 10 veces, lo que generó comentarios de los usuarios más rápidos.
73%
Los usuarios iniciaron conversaciones de calidad y participaron en ellas
200%
Tasa de clics más alta en comparación con el llamado a la acción anterior
10x
Inferencia más rápida con WebGPU
Recursos
Si te interesa ampliar las capacidades de tu propia app web con IA del cliente, haz lo siguiente:
- Obtén información para implementar la detección de toxicidad del cliente.
- Revisa una colección de demostraciones de IA del cliente.
- Obtén información sobre Mediapipe y Transformers.js. Puedes trabajar con modelos previamente entrenados y, luego, integrarlos en tu aplicación con JavaScript.
- La colección de IA en Chrome para desarrolladores proporciona recursos, prácticas recomendadas y actualizaciones sobre las tecnologías que potencian la IA en Chrome y más allá.
- Esto incluye el caso de éxito sobre cómo Policybazaar y JioHotstar usan las APIs de Translator y Language Detector para crear experiencias multilingües.
- Obtén información sobre los ejemplos reales de IA web en I/O 2025.