
Ahora, los creadores pueden editar contenido de video de alta calidad en la Web con Kapwing, gracias a las poderosas APIs (como IndexedDB y WebCodecs) y las herramientas de rendimiento.

El consumo de videos en línea creció rápidamente desde el comienzo de la pandemia. Las personas pasan más tiempo mirando videos de alta calidad en plataformas como TikTok, Instagram y YouTube. Los creativos y los propietarios de pequeñas empresas de todo el mundo necesitan herramientas rápidas y fáciles de usar para crear contenido de video.
Empresas como Kapwing permiten crear todo este contenido de video directamente en la Web con las herramientas de rendimiento y las APIs potentes más recientes.
Acerca de Kapwing
Kapwing es un editor de video colaborativo basado en la Web diseñado principalmente para creadores ocasionales, como streamers de videojuegos, músicos, creadores de YouTube y creadores de memes. También es un recurso de referencia para los propietarios de empresas que necesitan una forma fácil de producir su propio contenido de redes sociales, como anuncios de Facebook e Instagram.
Las personas descubren Kapwing cuando buscan una tarea específica, por ejemplo,"cómo recortar un video", "agregar música a mi video" o "cambiar el tamaño de un video". Pueden hacer lo que buscaron con un solo clic, sin la dificultad adicional de navegar a una tienda de aplicaciones y descargar una app. La Web permite que las personas busquen con precisión la tarea con la que necesitan ayuda y, luego, realizarla.
Después de ese primer clic, los usuarios de Kapwing pueden hacer mucho más. Pueden explorar plantillas gratuitas, agregar nuevas capas de videos de archivo gratuitos, insertar subtítulos, transcribir videos y subir música de fondo.
Cómo Kapwing lleva la edición y la colaboración en tiempo real a la Web
Si bien la Web ofrece ventajas únicas, también presenta desafíos distintos. Kapwing debe ofrecer una reproducción fluida y precisa de proyectos complejos y de varias capas en una amplia variedad de dispositivos y condiciones de red. Para lograrlo, usamos una variedad de APIs web para alcanzar nuestros objetivos de rendimiento y funciones.
IndexedDB
La edición de alto rendimiento requiere que todo el contenido de nuestros usuarios se publique en el cliente, lo que evita la red siempre que sea posible. A diferencia de un servicio de transmisión, en el que los usuarios suelen acceder a un contenido una vez, nuestros clientes reutilizan sus recursos con frecuencia, días o incluso meses después de la carga.
IndexedDB nos permite proporcionar almacenamiento continuo similar al sistema de archivos a nuestros usuarios. El resultado es que más del 90% de las solicitudes de contenido multimedia en la app se entregan de forma local. La integración de IndexedDB en nuestro sistema fue muy sencilla.
Este es un código de inicialización de plantilla que se ejecuta cuando se carga la app:
import {DBSchema, openDB, deleteDB, IDBPDatabase} from 'idb';
let openIdb: Promise <IDBPDatabase<Schema>>;
const db =
(await openDB) <
Schema >
(
'kapwing',
version, {
upgrade(db, oldVersion) {
if (oldVersion >= 1) {
// assets store schema changed, need to recreate
db.deleteObjectStore('assets');
}
db.createObjectStore('assets', {
keyPath: 'mediaLibraryID'
});
},
async blocked() {
await deleteDB('kapwing');
},
async blocking() {
await deleteDB('kapwing');
},
}
);
Pasamos una versión y definimos una función upgrade. Se usa para la inicialización o para actualizar nuestro esquema cuando sea necesario. Pasamos devoluciones de llamada de manejo de errores, blocked y blocking, que nos resultaron útiles para evitar problemas para los usuarios con sistemas inestables.
Por último, ten en cuenta nuestra definición de una clave primaria keyPath. En nuestro caso, este es un ID único que llamamos mediaLibraryID. Cuando un usuario agrega un elemento multimedia a nuestro sistema, ya sea a través de nuestro cargador o de una extensión de terceros, lo agregamos a nuestra biblioteca multimedia con el siguiente código:
export async function addAsset(mediaLibraryID: string, file: File) {
return runWithAssetMutex(mediaLibraryID, async () => {
const assetAlreadyInStore = await (await openIdb).get(
'assets',
mediaLibraryID
);
if (assetAlreadyInStore) return;
const idbVideo: IdbVideo = {
file,
mediaLibraryID,
};
await (await openIdb).add('assets', idbVideo);
});
}
runWithAssetMutex es nuestra propia función definida de forma interna que serializa el acceso a IndexedDB. Esto es obligatorio para cualquier operación de tipo de lectura, modificación y escritura, ya que la API de IndexedDB es asíncrona.
Ahora, veamos cómo accedemos a los archivos. A continuación, se muestra nuestra función getAsset:
export async function getAsset(
mediaLibraryID: string,
source: LayerSource | null | undefined,
location: string
): Promise<IdbAsset | undefined> {
let asset: IdbAsset | undefined;
const { idbCache } = window;
const assetInCache = idbCache[mediaLibraryID];
if (assetInCache && assetInCache.status === 'complete') {
asset = assetInCache.asset;
} else if (assetInCache && assetInCache.status === 'pending') {
asset = await new Promise((res) => {
assetInCache.subscribers.push(res);
});
} else {
idbCache[mediaLibraryID] = { subscribers: [], status: 'pending' };
asset = (await openIdb).get('assets', mediaLibraryID);
idbCache[mediaLibraryID].asset = asset;
idbCache[mediaLibraryID].subscribers.forEach((res: any) => {
res(asset);
});
delete (idbCache[mediaLibraryID] as any).subscribers;
if (asset) {
idbCache[mediaLibraryID].status = 'complete';
} else {
idbCache[mediaLibraryID].status = 'failed';
}
}
return asset;
}
Tenemos nuestra propia estructura de datos, idbCache, que se usa para minimizar los accesos a IndexedDB. Si bien IndexedDB es rápido, el acceso a la memoria local es más rápido. Recomendamos este enfoque, siempre y cuando administres el tamaño de la caché.
De lo contrario, el array subscribers, que se usa para evitar el acceso simultáneo a IndexedDB, sería común durante la carga.
API de Web Audio
La visualización de audio es increíblemente importante para la edición de video. Para comprender el motivo, observa una captura de pantalla del editor:
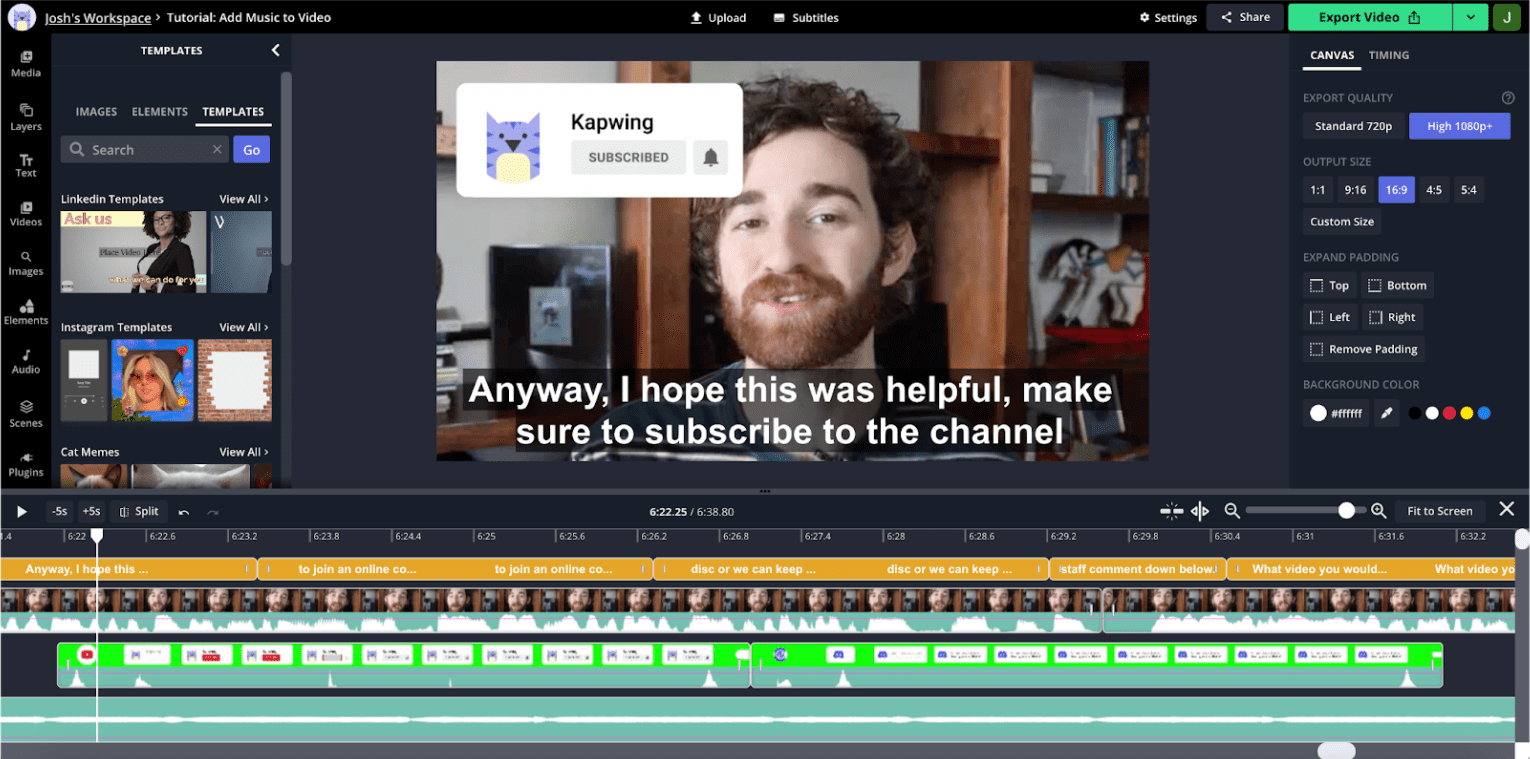
Este es un video al estilo de YouTube, que es común en nuestra app. El usuario no se mueve mucho durante el clip, por lo que las miniaturas visuales de las líneas de tiempo no son tan útiles para navegar entre las secciones. Por otro lado, la forma de onda de audio muestra picos y valles, y los valles suelen corresponder al tiempo muerto en la grabación. Si acercaras la línea de tiempo, verías información de audio más detallada con valles que corresponden a interrupciones y pausas.
Nuestra investigación sobre usuarios muestra que los creadores suelen guiarse por estas formas de onda cuando unen su contenido. La API de audio web nos permite presentar esta información de manera eficiente y actualizarla rápidamente cuando se acerca o se desplaza el cronograma.
En el siguiente fragmento, se muestra cómo lo hacemos:
const getDownsampledBuffer = (idbAsset: IdbAsset) =>
decodeMutex.runExclusive(
async (): Promise<Float32Array> => {
const arrayBuffer = await idbAsset.file.arrayBuffer();
const audioContext = new AudioContext();
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
const offline = new OfflineAudioContext(
audioBuffer.numberOfChannels,
audioBuffer.duration * MIN_BROWSER_SUPPORTED_SAMPLE_RATE,
MIN_BROWSER_SUPPORTED_SAMPLE_RATE
);
const downsampleSource = offline.createBufferSource();
downsampleSource.buffer = audioBuffer;
downsampleSource.start(0);
downsampleSource.connect(offline.destination);
const downsampledBuffer22K = await offline.startRendering();
const downsampledBuffer22KData = downsampledBuffer22K.getChannelData(0);
const downsampledBuffer = new Float32Array(
Math.floor(
downsampledBuffer22KData.length / POST_BROWSER_SAMPLE_INTERVAL
)
);
for (
let i = 0, j = 0;
i < downsampledBuffer22KData.length;
i += POST_BROWSER_SAMPLE_INTERVAL, j += 1
) {
let sum = 0;
for (let k = 0; k < POST_BROWSER_SAMPLE_INTERVAL; k += 1) {
sum += Math.abs(downsampledBuffer22KData[i + k]);
}
const avg = sum / POST_BROWSER_SAMPLE_INTERVAL;
downsampledBuffer[j] = avg;
}
return downsampledBuffer;
}
);
Le pasamos a este ayudante el activo que se almacena en IndexedDB. Cuando se complete, actualizaremos el activo en IndexedDB y en nuestra propia caché.
Recopilamos datos sobre audioBuffer con el constructor AudioContext, pero como no renderizamos en el hardware del dispositivo, usamos OfflineAudioContext para renderizar en un ArrayBuffer, donde almacenaremos los datos de amplitud.
La API en sí muestra datos a una tasa de muestreo mucho más alta de la necesaria para una visualización eficaz. Por eso, reducimos manualmente la muestra a 200 Hz, que resultó ser suficiente para obtener formas de onda útiles y visualmente atractivas.
WebCodecs
En algunos videos, las miniaturas de las pistas son más útiles para la navegación por la línea de tiempo que las formas de onda. Sin embargo, generar miniaturas requiere más recursos que generar formas de onda.
No podemos almacenar en caché todas las miniaturas posibles durante la carga, por lo que la decodificación rápida en el desplazamiento o el zoom de la línea de tiempo es fundamental para una aplicación responsiva y de alto rendimiento. El cuello de botella para lograr un dibujo de fotogramas fluido es la decodificación de fotogramas, que hasta hace poco hacíamos con un reproductor de video HTML5. El rendimiento de ese enfoque no era confiable y, a menudo, observábamos una respuesta degradada de la app durante la renderización de fotogramas.
Recientemente, migramos a WebCodecs, que se puede usar en trabajadores web. Esto debería mejorar nuestra capacidad para dibujar miniaturas para grandes cantidades de capas sin afectar el rendimiento del subproceso principal. Si bien la implementación del trabajador web aún está en curso, a continuación, presentamos un esquema de nuestra implementación existente del subproceso principal.
Un archivo de video contiene varias transmisiones: video, audio, subtítulos, etcétera, que se “muxan” en conjunto. Para usar WebCodecs, primero debemos tener una transmisión de video demuxada. Demuxamos los archivos mp4 con la biblioteca mp4box, como se muestra a continuación:
async function create(demuxer: any) {
demuxer.file = (await MP4Box).createFile();
demuxer.file.onReady = (info: any) => {
demuxer.info = info;
demuxer._info_resolver(info);
};
demuxer.loadMetadata();
}
const loadMetadata = async () => {
let offset = 0;
const asset = await getAsset(this.mediaLibraryId, null, this.url);
const maxFetchOffset = asset?.file.size || 0;
const end = offset + FETCH_SIZE;
const response = await fetch(this.url, {
headers: { range: `bytes=${offset}-${end}` },
});
const reader = response.body.getReader();
let done, value;
while (!done) {
({ done, value } = await reader.read());
if (done) {
this.file.flush();
break;
}
const buf: ArrayBufferLike & { fileStart?: number } = value.buffer;
buf.fileStart = offset;
offset = this.file.appendBuffer(buf);
}
};
Este fragmento hace referencia a una clase demuxer, que usamos para encapsular la interfaz en MP4Box. Volvemos a acceder al recurso desde IndexedDB. Estos segmentos no se almacenan necesariamente en orden de bytes y el método appendBuffer muestra el desplazamiento del siguiente fragmento.
A continuación, te mostramos cómo decodificamos un fotograma de video:
const getFrameFromVideoDecoder = async (demuxer: any): Promise<any> => {
let desiredSampleIndex = demuxer.getFrameIndexForTimestamp(this.frameTime);
let timestampToMatch: number;
let decodedSample: VideoFrame | null = null;
const outputCallback = (frame: VideoFrame) => {
if (frame.timestamp === timestampToMatch) decodedSample = frame;
else frame.close();
};
const decoder = new VideoDecoder({
output: outputCallback,
});
const {
codec,
codecWidth,
codecHeight,
description,
} = demuxer.getDecoderConfigurationInfo();
decoder.configure({ codec, codecWidth, codecHeight, description });
/* begin demuxer interface */
const preceedingKeyFrameIndex = demuxer.getPreceedingKeyFrameIndex(
desiredSampleIndex
);
const trak_id = demuxer.trak_id
const trak = demuxer.moov.traks.find((trak: any) => trak.tkhd.track_id === trak_id);
const data = await demuxer.getFrameDataRange(
preceedingKeyFrameIndex,
desiredSampleIndex
);
/* end demuxer interface */
for (let i = preceedingKeyFrameIndex; i <= desiredSampleIndex; i += 1) {
const sample = trak.samples[i];
const sampleData = data.readNBytes(
sample.offset,
sample.size
);
const sampleType = sample.is_sync ? 'key' : 'delta';
const encodedFrame = new EncodedVideoChunk({
sampleType,
timestamp: sample.cts,
duration: sample.duration,
samapleData,
});
if (i === desiredSampleIndex)
timestampToMatch = encodedFrame.timestamp;
decoder.decodeEncodedFrame(encodedFrame, i);
}
await decoder.flush();
return { type: 'value', value: decodedSample };
};
La estructura del demultiplexor es bastante compleja y está fuera del alcance de este artículo. Almacena cada fotograma en un array titulado samples. Usamos el demuxer para encontrar el fotograma clave anterior más cercano a la marca de tiempo deseada, que es donde debemos comenzar la decodificación de video.
Los videos se componen de fotogramas completos, conocidos como fotogramas clave o I, así como fotogramas delta mucho más pequeños, a los que a menudo se hace referencia como fotogramas P o B. La decodificación siempre debe comenzar en un fotograma clave.
La aplicación decodifica los fotogramas de la siguiente manera:
- Crea una instancia del decodificador con una devolución de llamada de salida de fotogramas.
- Configurar el decodificador para el códec y la resolución de entrada específicos
- Crea un
encodedVideoChunkcon datos del demultiplexor. - Mediante una llamada al método
decodeEncodedFrame
Hacemos esto hasta que llegamos al fotograma con la marca de tiempo deseada.
Próximos pasos
Definimos la escala en nuestro frontend como la capacidad de mantener una reproducción precisa y de alto rendimiento a medida que los proyectos se vuelven más grandes y complejos. Una forma de escalar el rendimiento es activar la menor cantidad posible de videos a la vez. Sin embargo, cuando hacemos esto, corremos el riesgo de que las transiciones sean lentas y entrecortadas. Si bien desarrollamos sistemas internos para almacenar en caché componentes de video para su reutilización, existen limitaciones en cuanto al control que pueden proporcionar las etiquetas de video HTML5.
En el futuro, es posible que intentemos reproducir todo el contenido multimedia con WebCodecs. Esto podría permitirnos ser muy precisos sobre los datos que almacenamos en búfer, lo que debería ayudar a escalar el rendimiento.
También podemos hacer un mejor trabajo para descargar grandes cálculos del panel táctil a los trabajadores web y ser más inteligentes en cuanto a la recuperación anticipada de archivos y la generación previa de fotogramas. Vemos grandes oportunidades para optimizar el rendimiento general de nuestras aplicaciones y extender la funcionalidad con herramientas como WebGL.
Nos gustaría continuar con nuestra inversión en TensorFlow.js, que actualmente usamos para el retiro inteligente de fondos. Planeamos aprovechar TensorFlow.js para otras tareas más sofisticadas, como la detección de objetos, la extracción de características, la transferencia de estilo, etcétera.
En última instancia, nos entusiasma seguir desarrollando nuestro producto con un rendimiento y una funcionalidad similares a los nativos en una Web abierta y gratuita.