
Первоначально Google разработал WebP как формат изображений с потерями, чтобы заменить JPEG, который мог создавать файлы меньшего размера, чем файл изображения сопоставимого качества, закодированный как JPEG. Более поздние обновления формата представили возможность сжатия без потерь, прозрачность альфа-канала в стиле PNG и анимацию в стиле GIF — все это можно использовать вместе со сжатием с потерями в стиле JPEG. WebP — невероятно универсальный формат.
Алгоритм сжатия с потерями WebP основан на методе, который видеокодек VP8 использует для сжатия ключевых кадров в видео. На высоком уровне это похоже на кодирование JPEG: WebP работает с «блоками», а не с отдельными пикселями, и имеет аналогичное разделение между яркостью и цветностью. Блоки яркости WebP имеют размер 16x16, а блоки цветности — 8x8, и эти «макроблоки» дополнительно подразделяются на подблоки 4x4.
WebP радикально отличается от JPEG двумя особенностями: «предсказанием блоков» и «адаптивным квантованием блоков».
Блокировать предсказание
Прогнозирование блоков — это процесс, посредством которого содержимое каждого блока цветности и яркости прогнозируется на основе значений окружающих их блоков, в частности блоков выше и слева от текущего блока. Как вы можете себе представить, алгоритмы, выполняющие эту работу, довольно сложны, но, говоря простым языком: «если над текущим блоком есть синий цвет, а слева от него — синий, предположим, что этот блок синий».
По правде говоря, и PNG, и JPEG в некоторой степени также выполняют подобные прогнозы. WebP, однако, уникален тем, что он выбирает данные окружающих блоков, а затем пытается заполнить текущий блок с помощью нескольких различных «режимов прогнозирования», эффективно пытаясь «нарисовать» недостающую часть изображения. Результаты, полученные в каждом режиме прогнозирования, затем сравниваются с данными реального изображения, и выбирается наиболее близкое прогнозируемое совпадение.
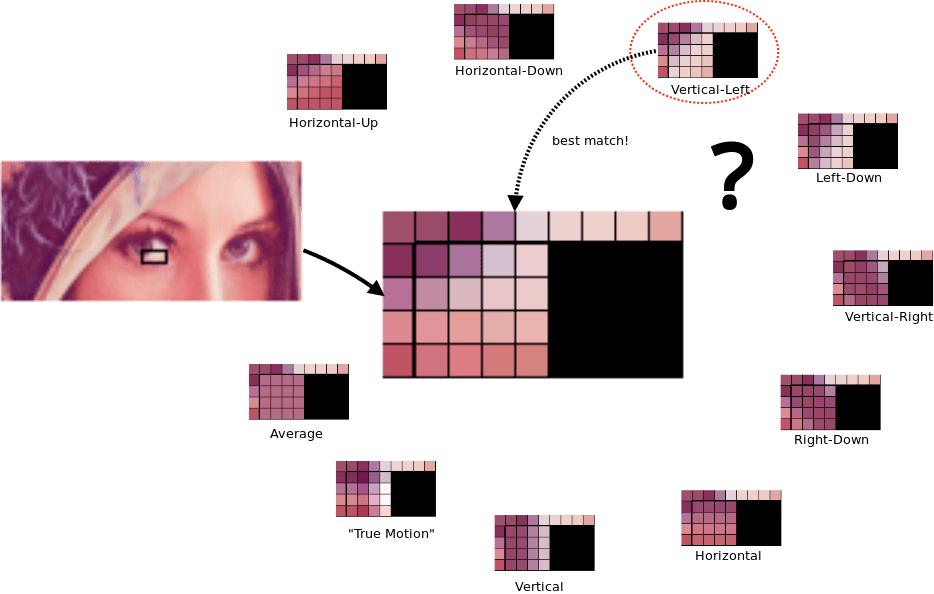
Конечно, даже самое близкое прогнозируемое совпадение не будет полностью правильным, поэтому различия между прогнозируемыми и фактическими значениями этого блока закодированы в файле. При декодировании изображения механизм рендеринга использует одни и те же данные для применения одной и той же логики прогнозирования, что приводит к одинаковым прогнозируемым значениям для каждого блока. Разница между прогнозом и ожидаемым изображением, которое было закодировано в файле, затем применяется к прогнозам — аналогично тому, как фиксация Git представляет собой дифференциальный патч, который применяется к локальному файлу, а не к совершенно новой копии файла.
Для иллюстрации: вместо того, чтобы копаться в сложной математике, связанной с настоящим алгоритмом прогнозирования, мы изобретем кодировку, подобную WebP, с одним режимом прогнозирования и будем использовать ее для эффективной передачи сетки чисел, как мы это делали с устаревшими форматами. . Наш алгоритм имеет единственный режим прогнозирования, который мы назовем «первым режимом прогнозирования»: значение каждого блока представляет собой сумму значений блоков над ним и слева от него, начиная с 1.
Теперь предположим, что мы начинаем со следующих реальных данных изображения:
111151111
122456389
Используя нашу прогнозирующую модель для определения содержимого сетки 2x9, мы получим следующий результат:
111111111
123456789
Наши данные хорошо подходят для изобретенного нами алгоритма прогнозирования — прогнозируемые данные очень близко соответствуют нашим реальным данным. Конечно, это не идеальное совпадение — фактические данные содержат несколько блоков, которые отличаются от прогнозируемых данных. Итак, отправляемая нами кодировка включает в себя не только используемый метод прогнозирования, но и разницу любых блоков, которые должны отличаться от их прогнозируемых значений:
_ _ _ _ +4 _ _ _ _
_ _ -1 _ _ _ -4 _ _
Напишите таким же простым языком, как и некоторые устаревшие кодировки форматов, которые мы обсуждали:
Сетка 2x9 с использованием первого режима прогнозирования. +4 к 1x5, -1 к 2x3, -4 к 2x7.
Конечным результатом является невероятно эффективный закодированный файл.
Адаптивное блочное квантование
Сжатие JPEG — это общая операция, применяющая один и тот же уровень квантования к каждому блоку изображения. Для изображения с однородной композицией это, конечно, имеет смысл, но реальные фотографии не более однородны, чем мир вокруг нас. На практике это означает, что наши настройки сжатия JPEG определяются не высокочастотными деталями (в которых сжатие JPEG превосходно), а частями нашего изображения, где наиболее вероятно появление артефактов сжатия.

Как вы можете видеть на этом преувеличенном примере, крылья монарха на переднем плане выглядят относительно резкими — немного зернистыми по сравнению с оригиналом в высоком разрешении, но, конечно, не заметными без сравниваемого с ним оригинала. Точно так же детализированные соцветия молочая и листья на переднем плане — мы с вами можем увидеть следы артефактов сжатия нашими тренированными глазами, но даже при сжатии, значительно превышающем разумные уровни, вещи на переднем плане по-прежнему выглядят достаточно четкими. Низкочастотная информация в левом верхнем углу изображения — размытый зеленый фон из листьев — выглядит ужасно . Даже неподготовленный зритель сразу заметит проблему с качеством — тонкие градиенты на заднем плане округляются до неровных однотонных блоков.
Чтобы избежать этого, WebP использует адаптивный подход к квантованию: изображение разбивается на четыре визуально похожих сегмента, а параметры сжатия для этих сегментов настраиваются независимо. Использование того же нестандартного сжатия с WebP:

Размер обоих этих файлов изображений примерно одинаков. Качество примерно такое же, когда мы смотрим на крылья монарха — если присмотреться очень-очень внимательно, можно заметить несколько крошечных различий в конечном результате, но реальной разницы в общем качестве нет. В WebP цветы молочая немного острее — опять же, вероятно, недостаточно, чтобы быть заметными, если только вы не сравниваете их рядом и действительно не ищете различий в качестве, как мы. С фоном совсем другая история: на нем почти нет следов явно очевидных артефактов JPEG. WebP дает нам тот же размер файла, но изображение гораздо более высокого качества — плюс-минус несколько мелких деталей, которые наши психовизуальные системы не смогли бы обнаружить, если бы мы не сравнивали их так внимательно.
Использование WebP
Внутреннее устройство WebP может быть значительно более сложным, чем кодирование JPEG, но столь же простым для целей нашей повседневной работы: вся сложность кодирования WebP стандартизирована вокруг одного значения «качества», выражаемого от 0 до 100, как и в JPEG. . И еще раз: это не значит, что вы ограничены одной всеобъемлющей настройкой «качества». Вы можете — и должны — повозиться со всеми тонкими деталями кодирования WebP, хотя бы для того, чтобы лучше понять, как эти обычно невидимые настройки могут повлиять на размер и качество файла.
Google предлагает кодировщик командной строки cwebp , который позволяет конвертировать или сжимать отдельные файлы или целые каталоги изображений:
$ cwebp -q 80 butterfly.jpg -o butterfly.webp
Saving file 'butterfly.webp'
File: butterfly.jpg
Dimension: 1676 x 1418
Output: 208418 bytes Y-U-V-All-PSNR 41.00 43.99 44.95 41.87 dB
(0.70 bpp)
block count: intra4: 7644 (81.80%)
Intra16: 1701 (18.20%)
Skipped: 63 (0.67%)
bytes used: header: 249 (0.1%)
mode-partition: 36885 (17.7%)
Residuals bytes |segment 1|segment 2|segment 3|segment 4| total
macroblocks: | 8%| 22%| 26%| 44%| 9345
quantizer: | 27 | 25 | 21 | 13 |
filter level: | 8 | 6 | 19 | 16 |
А если вы не склонны к командной строке, Squoosh также подойдет нам для кодирования WebP. Это дает нам возможность параллельного сравнения различных кодировок, настроек, уровней качества и различий в размере файла по сравнению с кодировкой JPEG.