

Fecha de publicación: 31 de marzo de 2014
Para la identificación y resolución de cuellos de botella en el rendimiento de la ruta de acceso de representación crítica, se requiere un amplio conocimiento de los inconvenientes comunes. Una visita guiada para identificar patrones de rendimiento comunes te ayudará a optimizar tus páginas.
Optimizar la ruta de acceso de representación crítica permite que el navegador pinte la página lo más pronto posible: las páginas más rápidas proporcionan una mayor atracción, aumentan el número de páginas vistas y mejoran la conversión. Para minimizar la cantidad de tiempo que un visitante pierde en ver una pantalla en blanco, necesitamos optimizar qué recursos se cargan y en qué orden.
Para ayudar a ilustrar este proceso, comienza con el caso más simple posible y avanza de forma incremental en nuestra página para incluir recursos, estilos y lógica de aplicación adicionales. En el proceso, también veremos cuándo las cosas pueden salir mal y cómo optimizar cada uno de esos casos.
Hasta ahora, nos hemos enfocado exclusivamente en lo que sucede en el navegador después de que el recurso (CSS, JS o archivo HTML) está disponible para ser procesado. No hemos tenido en cuenta el tiempo que lleva obtener el recurso del caché o de la red. Supongamos lo siguiente:
- Para un recorrido completo desde la red (latencia de propagación) hasta el servidor se necesitan 100 ms.
- El tiempo de respuesta del servidor es de 100 ms para el documento HTML y de 10 ms para todos los demás archivos.
La experiencia de Hello World
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Critical Path: No Style</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
</body>
</html>
Comienza con lenguaje de marcado HTML básico y una sola imagen (sin CSS ni JavaScript). Luego, abre el panel de red en las Herramientas para desarrolladores de Chrome y, luego, inspecciona la cascada de recursos resultante:

Tal como se esperaba, el archivo HTML tardó aproximadamente 200 ms en descargarse. Ten en cuenta que la parte transparente de la línea azul indica el tiempo de espera del navegador en la red (es decir, aún no se recibió ningún byte de la respuesta), mientras que la parte sólida muestra el tiempo restante hasta que finalice la descarga después de haber recibido los primeros bytes de la respuesta. La descarga HTML es muy pequeña (<4K), por lo que solo necesitamos un recorrido para obtener el archivo completo. En consecuencia, para obtener el documento HTML se necesitan ~200 ms; la mitad de ese tiempo corresponde a la espera en la red y la otra mitad a la respuesta del servidor.
Una vez que esté disponible el contenido HTML, el navegador debe analizar los bytes, convertirlos en tokens y compilar el árbol del DOM. Ten en cuenta que DevTools informa de manera práctica el tiempo para el evento DOMContentLoaded en la parte inferior (216 ms), que también corresponde a la línea vertical azul. La brecha entre el final de la descarga HTML y la línea vertical azul (DOMContentLoaded) es el tiempo que tardó el navegador en compilar el árbol del DOM; en este caso, solo unos milisegundos.
Observa que nuestra "foto increíble" no bloqueó el evento domContentLoaded. Resulta que podemos construir el árbol de renderización y hasta pintar la página sin esperar a cada recurso de la página: no todos los recursos son esenciales para proporcionar la primera pintura rápida. De hecho, cuando hablamos sobre la ruta de acceso de representación crítica generalmente hacemos referencia al lenguaje de marcado HTML, CSS y JavaScript. Las imágenes no bloquean la renderización inicial de la página, aunque también debemos asegurarnos de pintar las imágenes lo antes posible.
Dicho esto, el evento load (también conocido como onload) está bloqueado en la imagen: DevTools informa el evento onload a los 335 ms. Recuerda que el evento onload marca el punto en el que todos los recursos que requiere la página se descargaron y procesaron; es el momento en que el indicador de carga puede dejar de girar en el navegador (la línea vertical roja en la cascada).
Cómo agregar JavaScript y CSS a la combinación
Nuestra página “experiencia Hello World” parece básica, pero hay mucho en juego. En la práctica, necesitaremos más que solo HTML: es probable que tengamos una hoja de estilo CSS y una o más secuencias de comandos para agregar interactividad a nuestra página. Agrega ambas a la mezcla para ver qué sucede:
<!DOCTYPE html>
<html>
<head>
<title>Critical Path: Measure Script</title>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" />
</head>
<body onload="measureCRP()">
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
<script src="timing.js"></script>
</body>
</html>
Antes de agregar JavaScript y CSS:

Con JavaScript y CSS:

La adición de archivos CSS y JavaScript externos suma a nuestra cascada dos solicitudes adicionales que el navegador envía aproximadamente al mismo tiempo. Sin embargo, ten en cuenta que ahora la diferencia de tiempo entre los eventos domContentLoaded y onload es mucho menor.
¿Qué pasó?
- A diferencia de nuestro ejemplo sobre HTML simple, ahora también debemos obtener y analizar el archivo CSS para construir el CSSOM, y necesitamos el DOM y el CSSOM para compilar el árbol de representación.
- Dado que la página también contiene un archivo JavaScript que bloquea el analizador, el evento
domContentLoadedse bloquea hasta que se descargue y analice el archivo CSS: JavaScript puede consultar el CSSOM, por lo que debemos bloquear el archivo CSS hasta que se descargue para poder ejecutar JavaScript.
¿Qué sucede si reemplazamos nuestra secuencia de comandos externa por una secuencia de comandos intercalada? Incluso si la secuencia de comandos está directamente integrada a la página, el navegador no puede ejecutarla hasta que se construye el CSSOM. En resumen, si usamos código JavaScript intercalado, también bloqueará el analizador.
Dicho esto, a pesar del bloqueo del CSS, ¿la integración de la secuencia de comandos hará que la página se represente más rápido? Pruébala y mira qué sucede.
JavaScript externo:

JavaScript intercalado:

Haremos una solicitud menos, pero los tiempos de nuestros eventos onload y domContentLoaded son los mismos. ¿Por qué? Bien, sabemos que no importa si el código JavaScript está integrado o es externo, ya que no bien el navegador alcance la etiqueta de secuencia de comandos se bloqueará y esperará hasta que se construya el CSSOM. Además, en nuestro primer ejemplo, el navegador descarga CSS y JavaScript en paralelo, y estos procesos de descarga finalizan aproximadamente al mismo tiempo. En este caso, integrar el código JavaScript no sirve mucho. Sin embargo, existen varias estrategias que pueden lograr que nuestra página se represente más rápido.
Primero, recuerda que todas las secuencias de comandos intercaladas bloquean el analizador, pero en las secuencias de comandos externas podemos agregar el atributo async para desbloquear el analizador. Deshagamos nuestra integración y veamos qué sucede:
<!DOCTYPE html>
<html>
<head>
<title>Critical Path: Measure Async</title>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" />
</head>
<body onload="measureCRP()">
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
<script async src="timing.js"></script>
</body>
</html>
JavaScript que bloquea el analizador (externo):

JavaScript asincrónico (externo):

Mucho mejor. El evento domContentLoaded se activa poco después del análisis del HTML: el navegador evita bloquearse en JavaScript, y como no hay otro analizador que bloquee secuencias de comandos, la construcción del CSSOM también puede continuar en paralelo.
Como alternativa, podríamos haber integrado tanto el CSS como JavaScript:
<!DOCTYPE html>
<html>
<head>
<title>Critical Path: Measure Inlined</title>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<style>
p {
font-weight: bold;
}
span {
color: red;
}
p span {
display: none;
}
img {
float: right;
}
</style>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
<script>
var span = document.getElementsByTagName('span')[0];
span.textContent = 'interactive'; // change DOM text content
span.style.display = 'inline'; // change CSSOM property
// create a new element, style it, and append it to the DOM
var loadTime = document.createElement('div');
loadTime.textContent = 'You loaded this page on: ' + new Date();
loadTime.style.color = 'blue';
document.body.appendChild(loadTime);
</script>
</body>
</html>

Ten en cuenta que el tiempo de domContentLoaded es el mismo que en el ejemplo anterior: en lugar de marcar nuestro JavaScript como asincrónico, integramos CSS y JS a la página. Esto agrandó mucho nuestra página HTML, pero la ventaja es que el navegador no tiene que esperar para obtener recursos externos; todo está allí, en la página.
Como puedes ver, incluso con una página muy básica, optimizar la ruta de acceso de renderización crítica es un ejercicio no trivial: debemos comprender el gráfico de dependencias entre los diferentes recursos, identificar cuáles son "críticos" y elegir entre diferentes estrategias para incluir esos recursos en la página. No hay una única solución para este problema: cada página es diferente. Debes seguir un proceso similar por tu cuenta para determinar cuál es la mejor estrategia.
Dicho esto, veamos si podemos regresar e identificar algunos patrones de rendimiento generales.
Patrones de rendimiento
La página más sencilla posible consiste simplemente en el lenguaje de marcado HTML: sin CSS, JavaScript ni otros tipos de recursos. Para representar esta página, el navegador debe iniciar la solicitud, esperar que llegue el documento HTML, analizarlo, compilar el DOM y, luego, representarlo en la pantalla:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Critical Path: No Style</title>
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
</body>
</html>
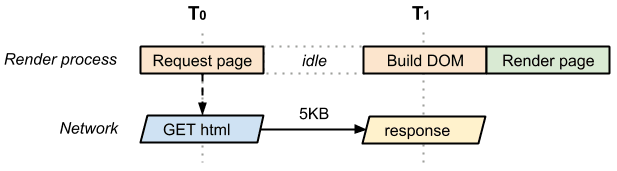
El tiempo entre T0 y T1 captura los tiempos de procesamiento de la red y del servidor. En el mejor de los casos (si el archivo HTML es pequeño), lo único que necesitaremos será un recorrido de la red para obtener todo el documento. Debido a la manera en que el TCP transporta documentos de protocolos, los archivos más grandes pueden requerir más recorridos. Como resultado, en el mejor de los casos, la página anterior tiene una ruta de acceso de representación crítica de un solo recorrido (mínima).
Ahora consideremos la misma página, pero con un archivo CSS externo:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" />
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
</body>
</html>
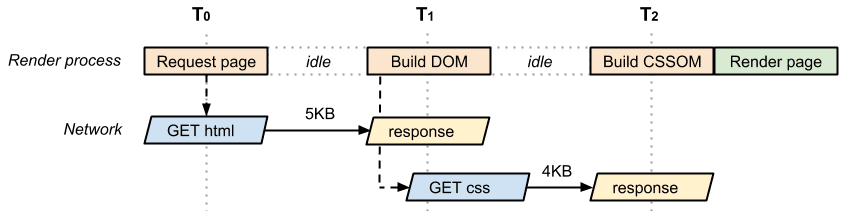
Una vez más, usamos un recorrido de la red para obtener el documento HTML y luego el lenguaje de marcado recuperado nos indica que también necesitaremos el archivo CSS: esto significa que el navegador debe regresar al servidor y obtener el CSS para poder representar la página en la pantalla. Como resultado, esta página realiza como mínimo dos recorridos antes de que pueda mostrarse. Una vez más, el archivo CSS puede requerir varios recorridos. Por ello, ponemos énfasis en “como mínimo”.
Estos son algunos términos que usamos para describir la ruta de acceso de representación crítica:
- Recurso crítico: Es un recurso que podría bloquear la representación inicial de la página.
- Extensión de la ruta de acceso crítica: Cantidad de recorridos o el tiempo total necesario para obtener todos los recursos críticos.
- Bytes críticos: Es la cantidad total de bytes necesarios para llegar a la primera renderización de la página, que es la suma de los tamaños de archivo de transferencia de todos los recursos críticos. Nuestro primer ejemplo, con una sola página HTML, contenía un solo recurso crítico (el documento HTML). La longitud de la ruta de acceso crítica también era igual a un recorrido de red (suponiendo que el archivo era pequeño) y la cantidad total de bytes críticos era solo el tamaño de transferencia del documento HTML.
Ahora compara esto con las características de la ruta crítica del ejemplo anterior de HTML y CSS:
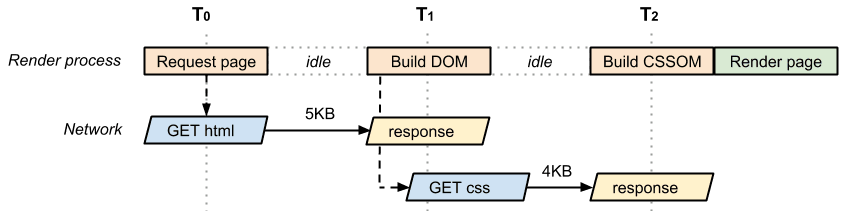
- 2 recursos críticos
- 2 o más recorridos para la longitud mínima de la ruta de acceso crítica
- 9 KB de bytes críticos
Necesitamos tanto el HTML como el CSS para construir el árbol de renderización. En consecuencia, el HTML y el CSS son recursos críticos: el CSS se obtiene solo después de que el navegador obtiene el documento HTML, por lo que la longitud de la ruta de acceso crítica es, como mínimo, de dos recorridos. Ambos recursos suman un total de 9 KB de bytes críticos.
Ahora agrega un archivo JavaScript adicional a la combinación.
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" />
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
<script src="app.js"></script>
</body>
</html>
Agregamos app.js, que es un recurso JavaScript externo en la página y, como ya sabemos, bloquea el analizador (es decir, crítico). Lo que es peor, para poder ejecutar el archivo JavaScript también debemos bloquear y esperar el CSSOM. Recuerda que JavaScript puede consultar el CSSOM y, por lo tanto, el navegador se pausará hasta que se descargue style.css y se construya el CSSOM.

Dicho esto, si en la práctica observamos la "cascada de red" de esta página, notarás que las solicitudes de CSS y JavaScript se iniciarán aproximadamente al mismo tiempo: el navegador obtiene el HTML, detecta ambos recursos e inicia ambas solicitudes. Como resultado, la página que se muestra en la imagen anterior tiene las siguientes características de ruta de acceso crítica:
- 3 recursos críticos
- 2 o más recorridos para la longitud mínima de la ruta de acceso crítica
- 11 KB de bytes críticos
Ahora tenemos tres recursos críticos que suman 11 KB de bytes críticos, pero la longitud de nuestra ruta de acceso crítica aún es de dos recorridos, ya que podemos transferir el CSS y el JavaScript en paralelo. Determinar las características de tu ruta de acceso de representación crítica implica que podrás identificar los recursos críticos y comprender la manera en que el navegador programará la obtención de estos.
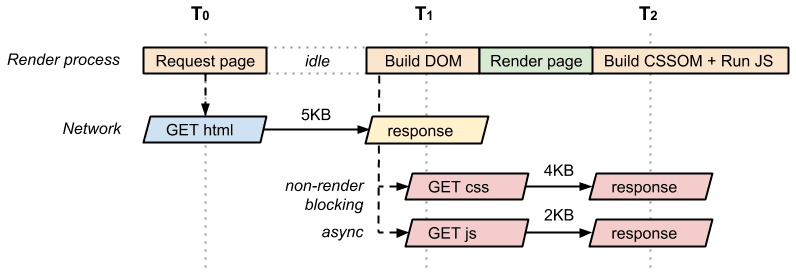
Después de conversar con nuestros desarrolladores de sitios, nos dimos cuenta de que el JavaScript que incluimos en nuestra página no debe ser de bloqueo: contamos con algunas herramientas de análisis y otros elementos de código que no necesitan bloquear la representación de nuestra página. Sabiendo esto, podemos agregar el atributo async al elemento <script> para desbloquear el analizador:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" />
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
<script src="app.js" async></script>
</body>
</html>
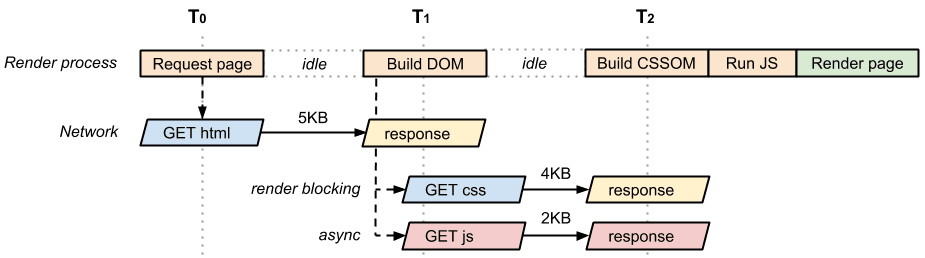
Una secuencia de comandos asíncrona tiene varias ventajas:
- La secuencia de comandos ya no bloquea el analizador y no forma parte de la ruta de acceso de representación crítica.
- Debido a que no hay otras secuencias de comandos críticas, el CSS tampoco necesita bloquear el evento
domContentLoaded. - Cuanto antes se active el evento
domContentLoaded, antes podrá comenzar a ejecutarse otra lógica de la app.
Como resultado, nuestra página optimizada volvió a tener dos recursos críticos (HTML y CSS) con una extensión mínima de ruta de acceso de representación crítica, de dos recorridos, y un total de 9 KB de bytes críticos.
Por último, si la hoja de estilo CSS solo fuese necesaria para imprimir, ¿cómo se vería?
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<link href="style.css" rel="stylesheet" media="print" />
</head>
<body>
<p>Hello <span>web performance</span> students!</p>
<div><img src="awesome-photo.jpg" /></div>
<script src="app.js" async></script>
</body>
</html>
Dado que el recurso style.css solo se usa para imprimir, el navegador no necesita aplicar un bloqueo para representar la página. Por lo tanto, no bien se complete la construcción del DOM, el navegador tendrá suficiente información para representar la página. Como resultado, esta página solo tiene un recurso crítico (el documento HTML) y la longitud mínima de la ruta de acceso de representación crítica es de un recorrido.