

Dipublikasikan: 21 Oktober 2024
Toko online dapat memperoleh peningkatan konversi sebesar 270% dengan menampilkan ulasan produk. Ulasan negatif juga penting, karena membangun kredibilitas. 82% pembeli online mencarinya sebelum membeli.
Mendorong pelanggan untuk memberikan ulasan produk yang bermanfaat, terutama jika negatif, bisa jadi sulit. Di sini, kita akan mempelajari cara menggunakan AI generatif untuk membantu pengguna menulis ulasan informatif yang membantu keputusan pembelian orang lain.
Demo dan kode
Coba demo ulasan produk kami dan pelajari kode di GitHub.
Cara kami mem-buildnya
AI sisi klien
Untuk demo ini, kami menerapkan fitur sisi klien karena alasan berikut:
- Latensi. Kita ingin memberikan saran dengan cepat, segera setelah pengguna berhenti mengetik. Kami dapat menawarkannya dengan menghindari perjalanan bolak-balik server.
- Biaya. Meskipun ini adalah demo, jika Anda mempertimbangkan untuk meluncurkan fitur serupa dalam produksi, sebaiknya lakukan eksperimen tanpa biaya sisi server hingga Anda dapat memvalidasi apakah fitur tersebut sesuai untuk pengguna.
AI generatif MediaPipe
Kami telah memilih untuk menggunakan model Gemma 2B melalui MediaPipe LLM Inference API (paket MediaPipe GenAI), karena alasan berikut:
- Akurasi model: Gemma 2B menawarkan keseimbangan ukuran dan akurasi yang baik. Saat diprompt dengan benar, API ini memberikan hasil yang kami anggap memuaskan untuk demo ini.
- Dukungan lintas browser: MediaPipe didukung di semua browser yang mendukung WebGPU.
Pengalaman pengguna
Menerapkan praktik terbaik performa
Meskipun Gemma 2B adalah LLM kecil, ukuran download-nya masih besar. Terapkan praktik terbaik performa, yang mencakup penggunaan pekerja web.
Membuat fitur menjadi opsional
Kami ingin saran ulasan berbasis AI meningkatkan alur kerja pengguna untuk memposting ulasan produk. Dalam penerapan kami, pengguna dapat memposting ulasan meskipun model belum dimuat, sehingga tidak menawarkan tips peningkatan.
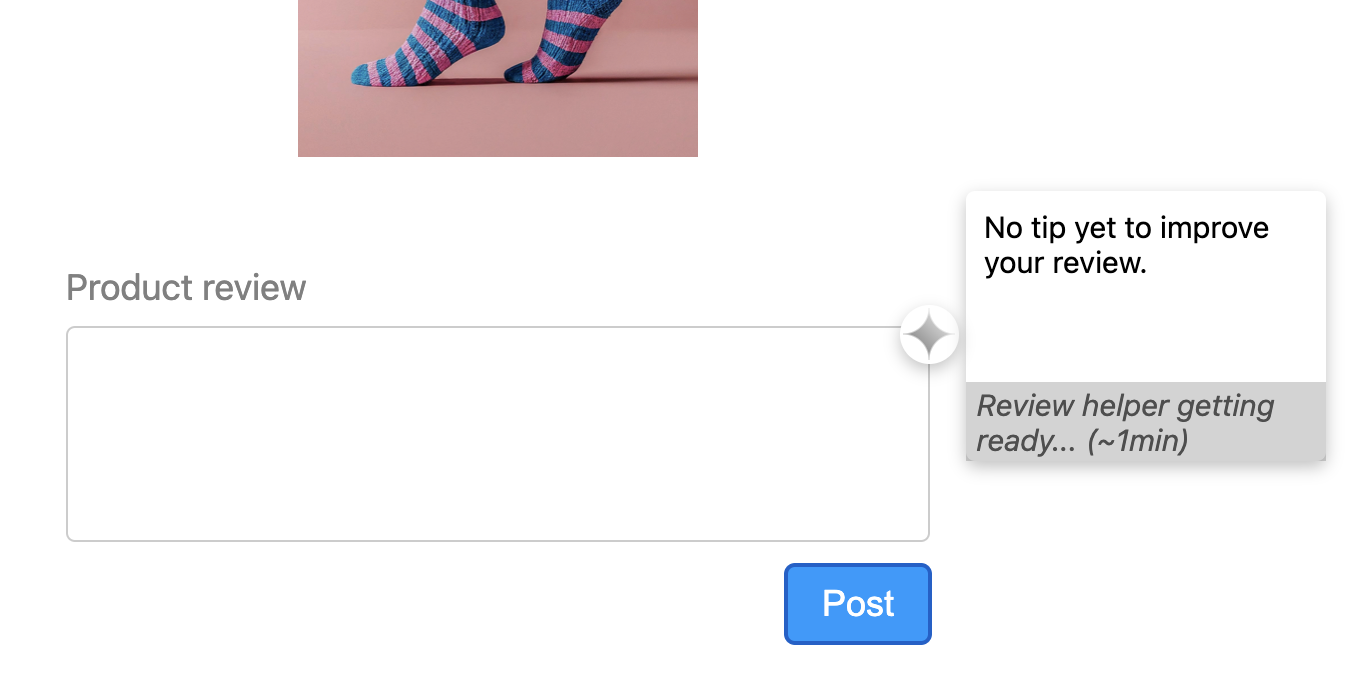
Status dan animasi UI
Inferensi biasanya memerlukan lebih banyak waktu daripada yang terasa langsung, jadi kami memberi sinyal kepada pengguna bahwa model sedang menjalankan inferensi, atau "berpikir". Kami menggunakan animasi untuk memudahkan waktu tunggu, sekaligus meyakinkan pengguna bahwa aplikasi berfungsi sebagaimana mestinya. Temukan berbagai status UI yang telah kami terapkan dalam demo, seperti yang didesain oleh Adam Argyle.
Pertimbangan lainnya
Dalam lingkungan produksi, Anda dapat:
- Menyediakan mekanisme masukan. Bagaimana jika sarannya biasa-biasa saja, atau tidak masuk akal? Terapkan mekanisme masukan cepat (seperti suka dan tidak suka) dan andalkan heuristik untuk menentukan hal yang dianggap berguna oleh pengguna. Misalnya, perkirakan berapa banyak pengguna yang berinteraksi dengan fitur tersebut, dan apakah mereka menonaktifkannya.
- Izinkan pilihan tidak ikut. Bagaimana jika pengguna lebih suka menggunakan kata-katanya sendiri tanpa bantuan AI, atau merasa fitur tersebut mengganggu? Izinkan pengguna memilih tidak ikut serta dan memilih untuk ikut serta kembali sesuai keinginan.
- Jelaskan alasan fitur ini ada. Penjelasan singkat dapat mendorong pengguna untuk menggunakan alat masukan. Misalnya, "Masukan yang lebih baik akan membantu sesama pembeli memutuskan apa yang akan dibeli, dan membantu kami membuat produk yang Anda inginkan". Anda dapat menambahkan penjelasan panjang tentang cara kerja fitur dan alasan Anda menyediakan fitur tersebut, mungkin sebagai link pelajari lebih lanjut.
- Mengungkapkan penggunaan AI jika relevan. Dengan AI sisi klien, konten pengguna tidak dikirim ke server untuk diproses, sehingga dapat dirahasiakan. Namun, jika Anda membuat penggantian sisi server atau mengumpulkan informasi dengan AI, pertimbangkan untuk menambahkannya ke kebijakan privasi, persyaratan layanan, atau tempat lainnya.
Penerapan
Implementasi kami untuk penasihat ulasan produk dapat digunakan untuk berbagai kasus penggunaan. Pertimbangkan informasi berikut sebagai dasar untuk fitur AI sisi klien Anda di masa mendatang.
MediaPipe di pekerja web
Dengan inferensi LLM MediaPipe, kode AI hanya terdiri dari beberapa baris: buat resolver file dan objek inferensi LLM dengan meneruskan URL model, lalu gunakan instance inferensi LLM tersebut untuk membuat respons.
Namun, contoh kode kami sedikit lebih luas. Hal ini karena kode tersebut diimplementasikan di pekerja web, sehingga meneruskan pesan dengan skrip utama melalui kode pesan kustom. Pelajari lebih lanjut pola ini.
// Trigger model preparation *before* the first message arrives
self.postMessage({ code: MESSAGE_CODE.PREPARING_MODEL });
try {
// Create a FilesetResolver instance for GenAI tasks
const genai = await FilesetResolver.forGenAiTasks(MEDIAPIPE_WASM);
// Create an LLM Inference instance from the specified model path
llmInference = await LlmInference.createFromModelPath(genai, MODEL_URL);
self.postMessage({ code: MESSAGE_CODE.MODEL_READY });
} catch (error) {
self.postMessage({ code: MESSAGE_CODE.MODEL_ERROR });
}
// Trigger inference upon receiving a message from the main script
self.onmessage = async function (message) {
// Run inference = Generate an LLM response
let response = null;
try {
response = await llmInference.generateResponse(
// Create a prompt based on message.data, which is the actual review
// draft the user has written. generatePrompt is a local utility function.
generatePrompt(message.data),
);
} catch (error) {
self.postMessage({ code: MESSAGE_CODE.INFERENCE_ERROR });
return;
}
// Parse and process the output using a local utility function
const reviewHelperOutput = generateReviewHelperOutput(response);
// Post a message to the main thread
self.postMessage({
code: MESSAGE_CODE.RESPONSE_READY,
payload: reviewHelperOutput,
});
};
export const MESSAGE_CODE ={
PREPARING_MODEL: 'preparing-model',
MODEL_READY: 'model-ready',
GENERATING_RESPONSE: 'generating-response',
RESPONSE_READY: 'response-ready',
MODEL_ERROR: 'model-error',
INFERENCE_ERROR: 'inference-error',
};
Input dan output
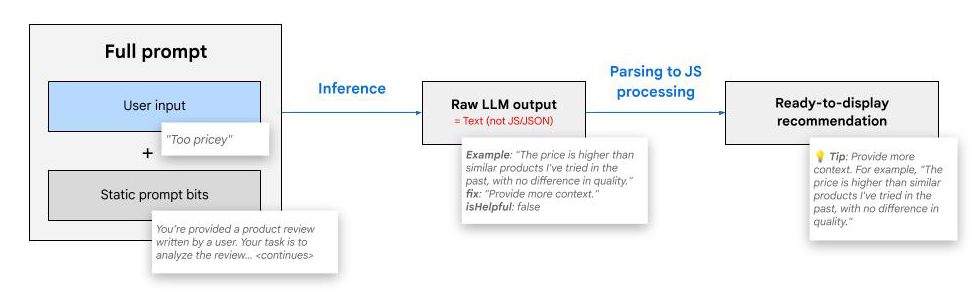
Perintah lengkap kami dibuat dengan perintah singkat. Data ini mencakup input pengguna, atau dengan kata lain draf ulasan yang telah ditulis pengguna.
Untuk membuat perintah berdasarkan input pengguna, kita memanggil fungsi utilitas
generatePrompt saat runtime.
Model dan library AI sisi klien biasanya memiliki lebih sedikit utilitas daripada AI sisi server. Misalnya, mode JSON sering kali tidak tersedia. Artinya, kita perlu memberikan struktur output yang diinginkan di dalam perintah. Hal ini kurang rapi, dapat dikelola, dan andal dibandingkan dengan menyediakan skema melalui konfigurasi model. Selain itu, model sisi klien cenderung lebih kecil, yang berarti lebih rentan terhadap error struktural dalam output-nya.
Dalam praktiknya, kami mengamati bahwa Gemma 2B lebih baik dalam memberikan output terstruktur sebagai teks dibandingkan dengan JSON atau JavaScript. Jadi, untuk demo ini, kami memilih format output berbasis teks. Model menghasilkan teks, yang kemudian kami uraikan outputnya menjadi objek JavaScript untuk pemrosesan lebih lanjut dalam aplikasi web kami.
Meningkatkan perintah kami
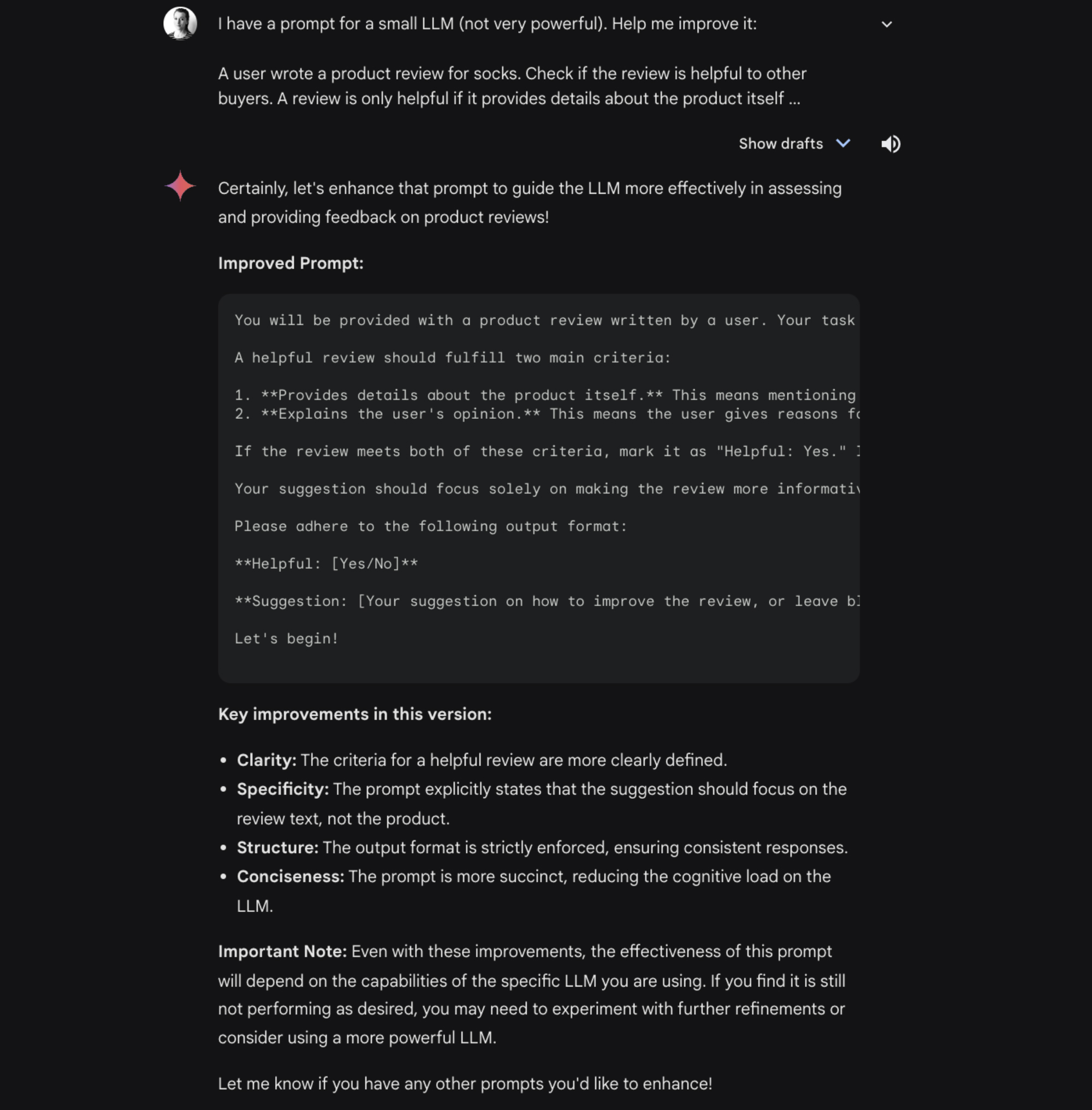
Kita menggunakan LLM untuk melakukan iterasi pada perintah.
- Few-shot prompting. Untuk membuat contoh perintah few-shot, kami mengandalkan Gemini Chat. Gemini Chat menggunakan model Gemini yang paling canggih. Hal ini memastikan kami menghasilkan contoh berkualitas tinggi.
- Peningkatan kualitas perintah. Setelah struktur perintah siap, kami juga menggunakan Gemini Chat untuk meningkatkan kualitas perintah. Hal ini meningkatkan kualitas output.
Menggunakan konteks untuk meningkatkan kualitas
Menyertakan jenis produk ke dalam perintah kami membantu model memberikan saran yang lebih relevan dan berkualitas lebih tinggi. Dalam demo ini, jenis produk bersifat statis. Dalam aplikasi yang sebenarnya, Anda dapat menyertakan produk secara dinamis ke dalam perintah, berdasarkan halaman yang dikunjungi pengguna.
Review: "I love these."
Helpful: No
Fix: Be more specific, explain why you like these **socks**.
Example: "I love the blend of wool in these socks. Warm and not too heavy."
Salah satu contoh di bagian beberapa gambar dari perintah kami: jenis produk ("kaus kaki") disertakan dalam perbaikan yang disarankan, dan dalam contoh ulasan.
Masalah dan perbaikan LLM
Gemma 2B biasanya memerlukan lebih banyak rekayasa perintah daripada model sisi server yang lebih besar dan lebih canggih.
Kami mengalami beberapa tantangan dengan Gemma 2B. Berikut cara kami meningkatkan hasilnya:
- Terlalu bagus. Gemma 2B kesulitan menandai ulasan sebagai "tidak membantu", tampaknya ragu untuk menilai. Kami mencoba membuat bahasa label lebih netral ("spesifik" dan "tidak spesifik", bukan "berguna" dan "tidak berguna") dan menambahkan contoh, tetapi hal ini tidak meningkatkan hasil. Yang meningkatkan hasil adalah desakan dan pengulangan dalam perintah. Pendekatan alur pemikiran juga akan menghasilkan peningkatan.
Petunjuk tidak jelas. Model terkadang menafsirkan perintah secara berlebihan. Alih-alih menilai ulasan, alat ini melanjutkan daftar contoh. Untuk memperbaikinya, kami menyertakan transisi yang jelas dalam perintah:
I'll give you example reviews and outputs, and then give you one review to analyze. Let's go: Examples: <... Examples> Review to analyze: <... User input>Menyusun perintah dengan jelas akan membantu model membedakan antara daftar contoh (beberapa gambar) dan input sebenarnya.
Target salah. Terkadang, model menyarankan perubahan pada produk, bukan teks ulasan. Misalnya, untuk ulasan yang menyatakan "Saya tidak suka kaus kaki ini", model dapat menyarankan "Pertimbangkan untuk mengganti kaus kaki dengan merek atau gaya yang berbeda", yang bukan efek yang diinginkan. Memisahkan perintah membantu memperjelas tugas, dan meningkatkan fokus model pada peninjauan.