

على الرغم من أنّ الحرف "ل" في النماذج اللغوية الكبيرة (LLM) يشير إلى نطاق واسع، فالحقيقة أكثر دقة. تحتوي بعض النماذج اللغوية الكبيرة على تريليونات المَعلمات، بينما تعمل نماذج أخرى بفعالية باستخدام عدد أقل بكثير من المَعلمات.
اطّلِع على بعض الأمثلة الواقعية والنتائج العملية ل أحجام النماذج المختلفة.
أحجام النماذج اللغوية الكبيرة وفئاتها
بصفتنا مطوّري ويب، نميل إلى اعتبار حجم المورد هو حجم التنزيل. يشير حجم النموذج المُسجَّل إلى عدد مَعلماته بدلاً من ذلك. على سبيل المثال، يشير Gemma 2B إلى Gemma التي تتضمّن مليارَي مَعلمة.
قد تحتوي النماذج اللغوية الكبيرة على مئات الآلاف أو الملايين أو المليارات أو حتى التريليونات من المَعلمات.
تحتوي النماذج اللغوية الكبيرة على معلَمات أكثر من النماذج الأصغر حجمًا، ما يسمح لها بالتقاط العلاقات اللغوية الأكثر تعقيدًا والتعامل مع الطلبات الدقيقة. ويتم تدريبها أيضًا غالبًا على مجموعات بيانات أكبر.
ربما لاحظت أنّ أحجام نماذج معيّنة، مثل مليارَي مستخدم أو 7 مليار مستخدم، شائعة. على سبيل المثال، Gemma 2B أو Gemma 7B، أو Mistral 7B. فئات حجم النموذج هي مجموعات تقريبية. على سبيل المثال، تحتوي Gemma 2B على تقريبًا 2 مليار مَعلمة، ولكن ليس بالضبط.
توفّر فئات حجم النماذج طريقة عملية لقياس أداء النماذج اللغوية الكبيرة. يمكنك اعتبارها مثل فئات الوزن في الملاكمة: فالنماذج ضمن فئة الحجم نفسها تكون أكثر مقارنةً. من المفترض أن يقدّم نموذجَا 2B أداءً مشابهًا.
ومع ذلك، يمكن أن يحقّق النموذج الأصغر الأداء نفسه الذي يحقّقه النموذج الأكبر حجمًا في مهام معيّنة.

على الرغم من أنّه لا يتم أحيانًا الإفصاح عن أحجام النماذج لأحدث النماذج اللغوية الكبيرة الحجم، مثل GPT-4 وGemini Pro أو Ultra، يُعتقد أنّها تتضمن مئات المليارات أو تريليونات المَعلمات.

لا تشير بعض النماذج إلى عدد المَعلمات في اسمها. تتم إضافة رقم الإصدار في نهاية بعض الطُرز. على سبيل المثال، يشير Gemini 1.5 Pro إلى الإصدار 1.5 من النموذج (بعد الإصدار 1).
LLM or not?
متى يكون النموذج صغيرًا جدًا لدرجة أنّه لا يمكن اعتباره نموذج لغة برمجة كبيرة؟ يمكن أن يكون تعريف النماذج اللغوية الكبيرة متحوّلاً نوعًا ما في منتدى الذكاء الاصطناعي وتعلُّم الآلة.
يرى البعض أنّ النماذج الكبيرة فقط التي تحتوي على مليارات المَعلمات هي نماذج لغوية كبيرة (LLM) حقيقية، في حين أنّ النماذج الأصغر حجمًا، مثل DistilBERT، تُعدّ نماذج معالجة لغة طبيعية (NLP) بسيطة. وتشمل النماذج الأخرى نماذج أصغر حجمًا، ولكنها لا تزال فعّالة في تعريف النماذج اللغوية الكبيرة (LLM)، مثل DistilBERT.
نماذج لغوية كبيرة أصغر حجمًا لحالات الاستخدام على الجهاز
تتطلّب النماذج اللغوية الكبيرة مساحة تخزين كبيرة وقدرة حسابية كبيرة لإجراء المعالجة المرجعية. يجب تشغيلها على خوادم قوية مخصّصة تتضمّن أجهزة معيّنة (مثل وحدات معالجة الموتّرات).
نحن مهتمون، بصفتنا مطوّرين على الويب، بمعرفة ما إذا كان النموذج صغيرًا بما يكفي لتنزيله وتشغيله على جهاز المستخدم.
ولكن هذا سؤال صعب الإجابة عنه. في الوقت الحالي، لا تتوفّر طريقة سهلة لتحديد ما إذا كان "يمكن تشغيل هذا الطراز على معظم الأجهزة متوسطة المستوى"، وذلك لأسباب قليلة:
- تختلف إمكانات الأجهزة على نطاق واسع حسب الذاكرة ومواصفات وحدة معالجة الرسومات/وحدة المعالجة المركزية وغير ذلك. هناك اختلاف كبير بين هاتف Android المنخفض التكلفة وجهاز الكمبيوتر المحمول NVIDIA® RTX. قد يكون لديك بعض نقاط البيانات حول الأجهزة التي يستخدمها المستخدمون. ليس لدينا حتى الآن تعريف للجهاز الأساسي المستخدَم للوصول إلى الويب.
- قد يكون النموذج أو إطار العمل الذي يتم تشغيله فيه محسّنًا للعمل على جهاز معيّن.
- لا تتوفّر طريقة آلية لتحديد ما إذا كان يمكن تنزيل نموذج لغوي كبير معيّن وتشغيله على جهاز معيّن. تعتمد قدرة الجهاز على التنزيل على مقدار ذاكرة الوصول العشوائي للفيديو (VRAM) المتوفرة في وحدة معالجة الرسومات، بالإضافة إلى عوامل أخرى.
ومع ذلك، لدينا بعض المعرفة التجريبية: في الوقت الحالي، يمكن تشغيل بعض النماذج التي تتضمّن من بضع ملايين إلى بضع مليارات مَعلمة في المتصفّح على الأجهزة المخصّصة للمستهلكين.
على سبيل المثال:
- Gemma 2B مع MediaPipe LLM Inference API (مناسبة أيضًا للأجهزة التي تستخدم وحدة المعالجة المركزية فقط ). جرِّب ذلك.
- DistilBERT مع Transformers.js
هذا حقل ناشئ. يمكنك توقّع تطور المشهد:
- من خلال ابتكارات WebAssembly وWebGPU، أصبح WebGPU متاحًا في المزيد من المكتبات والمكتبات الجديدة والتحسينات، ونتوقع أن تصبح أجهزة المستخدمين أكثر قدرة على تشغيل LLMs بكفاءة وبأحجام مختلفة.
- من المتوقّع أن تصبح النماذج اللغوية الكبيرة الأصغر حجمًا والأكثر أداءً شائعة بشكلٍ متزايد، وذلك من خلال استخدام أساليب التصغير الناشئة.
اعتبارات بشأن النماذج اللغوية الكبيرة الحجم
عند استخدام نماذج لغوية كبيرة أصغر حجمًا، يجب دائمًا مراعاة الأداء و حجم التنزيل.
الأداء
تعتمد قدرة أيّ نموذج بشكل كبير على حالة الاستخدام. قد يحقّق نموذج لغوي أصغر حجمًا تم ضبطه بدقّة ليتلاءم مع حالة الاستخدام أداءً أفضل من نموذج لغوي عام أكبر حجمًا.
ومع ذلك، ضمن عائلة النماذج نفسها، تكون النماذج اللغوية الكبيرة الأصغر حجمًا أقل قدرة من نماذجها الأكبر حجمًا. في حالة الاستخدام نفسها، عليك عادةً تنفيذ المزيد من العمل الهندسي الفوري عند استخدام نموذج معالجة لغوية أكبر.
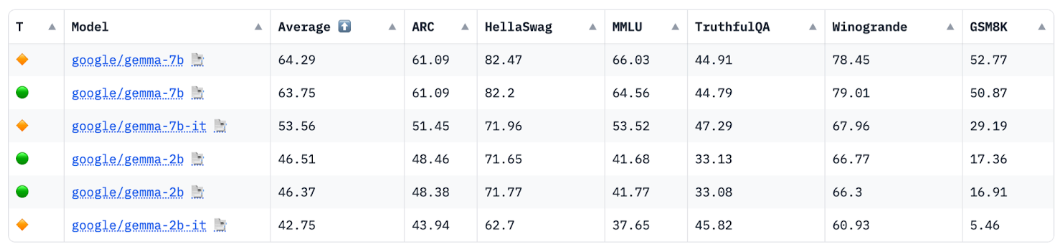
المصدر: قائمة الصدارة لنموذج اللغة الضخم المفتوح (LLM) من HuggingFace، نيسان (أبريل) 2024
حجم التنزيل
كلما زاد عدد المَعلمات، زاد حجم التنزيل، ما يؤثّر أيضًا في ما إذا كان يمكن تنزيل نموذج معيّن بشكل معقول لحالات الاستخدام على الجهاز، حتى إذا كان يُعتبر صغيرًا.
على الرغم من توفّر أساليب لحساب حجم تنزيل النموذج استنادًا إلى عدد المَعلمات، يمكن أن يكون ذلك معقدًا.
اعتبارًا من أوائل عام 2024، نادرًا ما يتم تسجيل أحجام تنزيل النماذج. لذلك، بالنسبة إلى حالات الاستخدام على الجهاز وفي المتصفّح، ننصحك بالاطّلاع على حجم التنزيل بشكل تجريبي، في لوحة الشبكة ضمن "أدوات مطوّري برامج Chrome" أو باستخدام أدوات المطوّرين في المتصفّح الأخرى.

يتم استخدام Gemma مع MediaPipe LLM Inference API. يتم استخدام DistilBERT مع Transformers.js.
تقنيات تصغير النماذج
تتوفّر أساليب متعدّدة للحدّ بشكل كبير من متطلبات الذاكرة للنموذج:
- LoRA (التكيّف منخفض الترتيب): أسلوب التحسين الدقيق الذي يتم فيه تجميد paramter المدرَّبة مسبقًا مزيد من المعلومات حول LoRA
- التقليم: إزالة الأوزان الأقل أهمية من النموذج لتصغير حجمه
- التكمية: تقليل دقة الأوزان من الأرقام المبرمَجة بنقطة عائمة (مثل 32 بت) إلى تمثيلات ببتات أقل (مثل 8 بت).
- تقطير المعرفة: تدريب نموذج أصغر حجمًا لمحاكاة سلوك نموذج أكبر حجمًا ومُدرَّب مسبقًا
- مشاركة المَعلمات: استخدام الأوزان نفسها لأجزاء متعدّدة من النموذج، مما يؤدي إلى خفض إجمالي عدد المَعلمات الفريدة