

แม้ว่า "L" ในโมเดลภาษาขนาดใหญ่ (LLM) จะสื่อถึงขนาดที่ใหญ่ แต่ความจริงแล้วมีความซับซ้อนมากกว่านั้น LLM บางรายการมีพารามิเตอร์หลายล้านล้านรายการ ส่วนบางรายการทํางานได้อย่างมีประสิทธิภาพด้วยพารามิเตอร์น้อยกว่ามาก
มาดูตัวอย่างที่เกิดขึ้นจริงและผลกระทบที่ได้จากการใช้โมเดลขนาดต่างๆ
ขนาดและคลาสขนาดของ LLM
ในฐานะนักพัฒนาเว็บ เรามักจะคิดว่าขนาดของทรัพยากรคือขนาดการดาวน์โหลด ขนาดที่บันทึกไว้ของโมเดลจะหมายถึงจํานวนพารามิเตอร์แทน เช่น Gemma 2B หมายถึง Gemma ที่มีพารามิเตอร์ 2, 000 ล้านรายการ
LLM อาจมีพารามิเตอร์หลายแสนล้านล้านหรือแม้แต่หลายแสนล้าน
LLM ขนาดใหญ่มีพารามิเตอร์มากกว่า LLM ขนาดเล็ก ซึ่งช่วยให้สามารถจับความสัมพันธ์ของภาษาที่ซับซ้อนมากขึ้นและจัดการพรอมต์ที่มีความละเอียดอ่อนได้ และมักจะได้รับการฝึกด้วยชุดข้อมูลขนาดใหญ่ด้วย
คุณอาจสังเกตเห็นว่าโมเดลบางขนาด เช่น 2, 000 ล้านหรือ 7, 000 ล้าน นั้นพบได้ทั่วไป เช่น Gemma 2B, Gemma 7B หรือ Mistral 7B คลาสขนาดโมเดลเป็นการจัดกลุ่มโดยประมาณ ตัวอย่างเช่น Gemma 2B มีพารามิเตอร์ประมาณ 2 พันล้านรายการ
คลาสขนาดโมเดลเป็นวิธีที่ใช้ได้จริงในการวัดประสิทธิภาพ LLM ลองนึกถึงคลาสน้ำหนักในการแข่งขันชกมวย โมเดลที่อยู่ในคลาสขนาดเดียวกันจะเปรียบเทียบกันได้มากกว่า โมเดล 2B 2 รายการควรมีประสิทธิภาพใกล้เคียงกัน
อย่างไรก็ตาม โมเดลขนาดเล็กอาจมีประสิทธิภาพเทียบเท่ากับโมเดลขนาดใหญ่สำหรับงานบางอย่าง

แม้ว่าขนาดโมเดลของ LLM ล้ำสมัยล่าสุด เช่น GPT-4 และ Gemini Pro หรือ Ultra จะไม่มีการเปิดเผยเสมอไป แต่เชื่อว่ามีพารามิเตอร์เป็นจำนวนมหาศาลถึงหลายร้อยพันล้านหรือหลายล้านล้านรายการ

โมเดลบางรายการไม่ได้ระบุจํานวนพารามิเตอร์ในชื่อ บางรุ่นจะมีหมายเลขเวอร์ชันต่อท้าย เช่น Gemini 1.5 Pro หมายถึงโมเดลเวอร์ชัน 1.5 (ตามเวอร์ชัน 1)
LLM หรือไม่
โมเดลใดบ้างที่เล็กเกินไปที่จะใช้เป็น LLM คําจํากัดความของ LLM อาจมีความคลุมเครือในชุมชน AI และ ML
บางคนถือว่าเฉพาะโมเดลขนาดใหญ่ที่มีพารามิเตอร์หลายพันล้านรายการเท่านั้นที่เป็น LLM ส่วนโมเดลขนาดเล็ก เช่น DistilBERT จะถือว่าเป็นโมเดล NLP ธรรมดา โมเดลอื่นๆ ที่อยู่ในคำจำกัดความของ LLM นั้นยังมีโมเดลขนาดเล็กแต่มีประสิทธิภาพ เช่น DistilBERT
LLM ขนาดเล็กสําหรับกรณีการใช้งานในอุปกรณ์
LLM ขนาดใหญ่ต้องใช้พื้นที่เก็บข้อมูลจำนวนมากและพลังในการประมวลผลจำนวนมากสำหรับการอนุมาน โดยต้องทำงานบนเซิร์ฟเวอร์ที่มีประสิทธิภาพสูงโดยเฉพาะซึ่งมีฮาร์ดแวร์เฉพาะ (เช่น TPU)
สิ่งหนึ่งที่เราสนใจในฐานะนักพัฒนาเว็บคือโมเดลมีขนาดเล็กพอที่จะดาวน์โหลดและใช้งานในอุปกรณ์ของผู้ใช้หรือไม่
แต่นี่เป็นเรื่องที่ตอบได้ยาก ปัจจุบันคุณยังไม่มีวิธีง่ายๆ ที่จะทราบว่า "รุ่นนี้ใช้งานได้ในอุปกรณ์ระดับกลางส่วนใหญ่" เนื่องด้วยเหตุผลต่อไปนี้
- ความสามารถของอุปกรณ์จะแตกต่างกันไปอย่างมากในด้านหน่วยความจำ ข้อมูลจำเพาะของ GPU/CPU และอื่นๆ โทรศัพท์ Android ระดับล่างกับแล็ปท็อป NVIDIA® RTX นั้นแตกต่างกันอย่างมาก คุณอาจมีจุดข้อมูลบางอย่างเกี่ยวกับอุปกรณ์ที่ผู้ใช้มี เรายังไม่มีคำจำกัดความสำหรับอุปกรณ์พื้นฐานที่ใช้เข้าถึงเว็บ
- โมเดลหรือเฟรมเวิร์กที่ใช้งานอาจได้รับการเพิ่มประสิทธิภาพให้ทำงานบนฮาร์ดแวร์บางประเภท
- ไม่มีวิธีแบบเป็นโปรแกรมในการระบุว่า LLM บางรายการสามารถดาวน์โหลดและใช้งานในอุปกรณ์หนึ่งๆ ได้หรือไม่ ความสามารถในการดาวน์โหลดของอุปกรณ์ขึ้นอยู่กับปริมาณ VRAM ใน GPU และปัจจัยอื่นๆ
อย่างไรก็ตาม เรามีข้อมูลเชิงประจักษ์บางอย่าง ซึ่งปัจจุบันโมเดลบางรุ่นมีพารามิเตอร์ตั้งแต่ 2-3 ล้านรายการไปจนถึง 2-3 พันล้านรายการที่ทำงานได้ในเบราว์เซอร์บนอุปกรณ์ระดับผู้บริโภค
เช่น
- Gemma 2B ที่มี MediaPipe LLM Inference API (เหมาะสำหรับอุปกรณ์ที่ใช้ CPU เท่านั้น) ลองใช้เลย
- DistilBERT ด้วย Transformers.js
นี่เป็นสาขาที่กำลังพัฒนา คุณสามารถคาดหวังได้ว่าภาพรวมจะเปลี่ยนแปลงไปดังนี้
- นวัตกรรม WebAssembly และ WebGPU จะช่วยให้ WebGPU รองรับไลบรารี ไลบรารีใหม่ และการเพิ่มประสิทธิภาพได้มากขึ้น อุปกรณ์ของผู้ใช้จึงสามารถเรียกใช้ LLM ขนาดต่างๆ ได้อย่างมีประสิทธิภาพมากขึ้น
- คาดว่า LLM ขนาดเล็กที่มีประสิทธิภาพสูงจะได้รับความนิยมมากขึ้นเรื่อยๆ ผ่านเทคนิคการลดขนาดที่พัฒนาขึ้น
ข้อควรพิจารณาสำหรับ LLM ขนาดเล็ก
เมื่อทํางานกับ LLM ขนาดเล็ก คุณควรพิจารณาประสิทธิภาพและขนาดการดาวน์โหลดเสมอ
ประสิทธิภาพ
ความสามารถของโมเดลใดๆ ขึ้นอยู่กับกรณีการใช้งานของคุณเป็นอย่างมาก LLM ขนาดเล็กที่ปรับให้เหมาะกับกรณีการใช้งานของคุณอาจมีประสิทธิภาพดีกว่า LLM ทั่วไปขนาดใหญ่
อย่างไรก็ตาม ภายในกลุ่มโมเดลเดียวกัน LLM ขนาดเล็กจะมีความสามารถน้อยกว่า LLM ขนาดใหญ่ สําหรับ Use Case เดียวกัน โดยทั่วไปคุณจะต้องทํางานวิศวกรที่รวดเร็วมากขึ้นเมื่อใช้ LLM ขนาดเล็ก
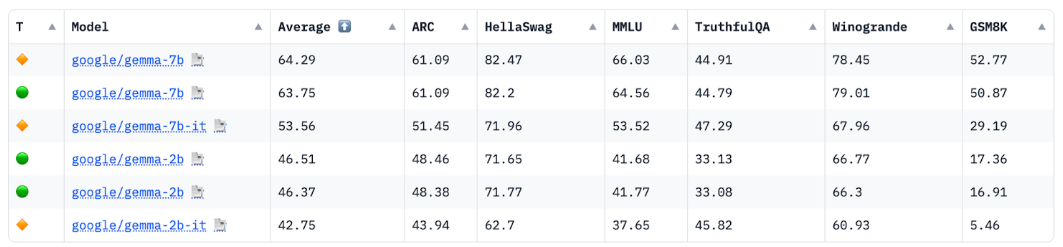
แหล่งที่มา: ตารางอันดับ LLM แบบเปิดของ HuggingFace, เมษายน 2024
ขนาดการดาวน์โหลด
พารามิเตอร์ที่มากขึ้นหมายความว่าขนาดการดาวน์โหลดจะใหญ่ขึ้น ซึ่งส่งผลต่อความสามารถในการดาวน์โหลดโมเดลอย่างเหมาะสมสำหรับกรณีการใช้งานในอุปกรณ์ แม้ว่าจะถือว่ามีขนาดเล็กก็ตาม
แม้ว่าจะมีเทคนิคในการคํานวณขนาดการดาวน์โหลดของโมเดลตามจํานวนพารามิเตอร์ แต่วิธีนี้อาจมีความซับซ้อน
ตั้งแต่ช่วงต้นปี 2024 เราไม่บันทึกขนาดการดาวน์โหลดโมเดลบ่อยนัก ดังนั้นสําหรับ Use Case ในอุปกรณ์และในเบราว์เซอร์ เราขอแนะนําให้ดูขนาดการดาวน์โหลดจากประสบการณ์จริงในแผง Network ของเครื่องมือสําหรับนักพัฒนาเว็บใน Chrome หรือใช้เครื่องมือสําหรับนักพัฒนาเบราว์เซอร์อื่นๆ

Gemma ใช้กับ MediaPipe LLM Inference API DistilBERT ใช้ร่วมกับ Transformers.js
เทคนิคการลดขนาดโมเดล
มีเทคนิคหลายอย่างที่ช่วยลดความต้องการหน่วยความจำของโมเดลได้อย่างมาก ดังนี้
- LoRA (Low-Rank Adaptation): เทคนิคการปรับแต่งแบบละเอียดซึ่งจะตรึงน้ำหนักที่ผ่านการฝึกล่วงหน้าไว้ อ่านเพิ่มเติมเกี่ยวกับ LoRA
- การตัดแต่ง: การนำน้ำหนักที่ไม่สําคัญออกจากโมเดลเพื่อลดขนาด
- การแปลงค่าเป็นจำนวนเต็ม: การลดความแม่นยำของน้ำหนักจากตัวเลขทศนิยม (เช่น 32 บิต) เป็นการนำเสนอแบบบิตที่ต่ำลง (เช่น 8 บิต)
- การกลั่นความรู้: การฝึกโมเดลขนาดเล็กให้เลียนแบบลักษณะการทํางานของโมเดลขนาดใหญ่ที่ผ่านการฝึกไว้ล่วงหน้า
- การแชร์พารามิเตอร์: การใช้น้ำหนักเดียวกันกับหลายส่วนของโมเดล ซึ่งจะช่วยลดจํานวนพารามิเตอร์ที่ไม่ซ้ำกันทั้งหมด