
Creators can now edit high-quality video content on the web with Kapwing, thanks to powerful APIs (like IndexedDB and WebCodecs) and performance tools.

Online video consumption has grown rapidly since the start of the pandemic. People are spending more time consuming endless high-quality video on platforms such as TikTok, Instagram, and YouTube. Creatives and small business owners all over the world need quick and easy-to-use tools to make video content.
Companies like Kapwing make it possible to create all this video content right on the web, by using the latest in powerful APIs and performance tools.
About Kapwing
Kapwing is a web-based collaborative video editor designed mainly for casual creatives like game-streamers, musicians, YouTube creators, and meme-rs. It's also a go-to resource for business owners who need an easy way to produce their own social content, such as Facebook and Instagram ads.
People discover Kapwing by searching for a specific task, for example "how to trim a video," "add music to my video," or "resize a video." They can do what they searched for with just one click—without the added friction of navigating to an app store and downloading an app. The web makes it simple for people to search for precisely what task they need help with, and then do it.
After that first click, Kapwing users can do a whole lot more. They can explore free templates, add new layers of free stock videos, insert subtitles, transcribe videos, and upload background music.
How Kapwing brings real-time editing and collaboration to the web
While the web provides unique advantages, it also presents distinct challenges. Kapwing needs to deliver smooth and precise playback of complex, multi-layered projects across a wide range of devices and network conditions. To achieve this, we use a variety of web APIs to achieve our performance and feature goals.
IndexedDB
High performance editing requires that all of our users' content live on the client, avoiding the network whenever possible. Unlike a streaming service, where users typically access a piece of content once, our customers reuse their assets frequently, days and even months after upload.
IndexedDB allows us to provide persistent file system-like storage to our users. The result is that over 90% of media requests in the app are fulfilled locally. Integrating IndexedDB into our system was very straightforward.
Here is some boiler plate initialization code that runs on app load:
import {DBSchema, openDB, deleteDB, IDBPDatabase} from 'idb';
let openIdb: Promise <IDBPDatabase<Schema>>;
const db =
(await openDB) <
Schema >
(
'kapwing',
version, {
upgrade(db, oldVersion) {
if (oldVersion >= 1) {
// assets store schema changed, need to recreate
db.deleteObjectStore('assets');
}
db.createObjectStore('assets', {
keyPath: 'mediaLibraryID'
});
},
async blocked() {
await deleteDB('kapwing');
},
async blocking() {
await deleteDB('kapwing');
},
}
);
We pass a version and define an upgrade function. This is used for
initialization or to update our schema when necessary. We pass error-handling
callbacks, blocked and blocking, which we've found useful in
preventing issues for users with unstable systems.
Finally, note our definition of a primary key keyPath. In our case, this is a
unique ID we call mediaLibraryID. When a user adds a piece of media to our system, whether via our uploader or a third party extension, we add the media
to our media library with the following code:
export async function addAsset(mediaLibraryID: string, file: File) {
return runWithAssetMutex(mediaLibraryID, async () => {
const assetAlreadyInStore = await (await openIdb).get(
'assets',
mediaLibraryID
);
if (assetAlreadyInStore) return;
const idbVideo: IdbVideo = {
file,
mediaLibraryID,
};
await (await openIdb).add('assets', idbVideo);
});
}
runWithAssetMutex is our own internally defined function that serializes
IndexedDB access. This is required for any read-modify-write type operations,
as the IndexedDB API is asynchronous.
Now let's take a look at how we access files. Below is our getAsset function:
export async function getAsset(
mediaLibraryID: string,
source: LayerSource | null | undefined,
location: string
): Promise<IdbAsset | undefined> {
let asset: IdbAsset | undefined;
const { idbCache } = window;
const assetInCache = idbCache[mediaLibraryID];
if (assetInCache && assetInCache.status === 'complete') {
asset = assetInCache.asset;
} else if (assetInCache && assetInCache.status === 'pending') {
asset = await new Promise((res) => {
assetInCache.subscribers.push(res);
});
} else {
idbCache[mediaLibraryID] = { subscribers: [], status: 'pending' };
asset = (await openIdb).get('assets', mediaLibraryID);
idbCache[mediaLibraryID].asset = asset;
idbCache[mediaLibraryID].subscribers.forEach((res: any) => {
res(asset);
});
delete (idbCache[mediaLibraryID] as any).subscribers;
if (asset) {
idbCache[mediaLibraryID].status = 'complete';
} else {
idbCache[mediaLibraryID].status = 'failed';
}
}
return asset;
}
We have our own data structure, idbCache, that is used to minimize IndexedDB
accesses. While IndexedDB is fast, accessing local memory is faster. We
recommend this approach so long as you manage the size of the cache.
The subscribers array, which is used to prevent simultaneous access to
IndexedDB, would otherwise be common on load.
Web Audio API
Audio visualization is incredibly important for video editing. To understand why, take a look at a screenshot from the editor:
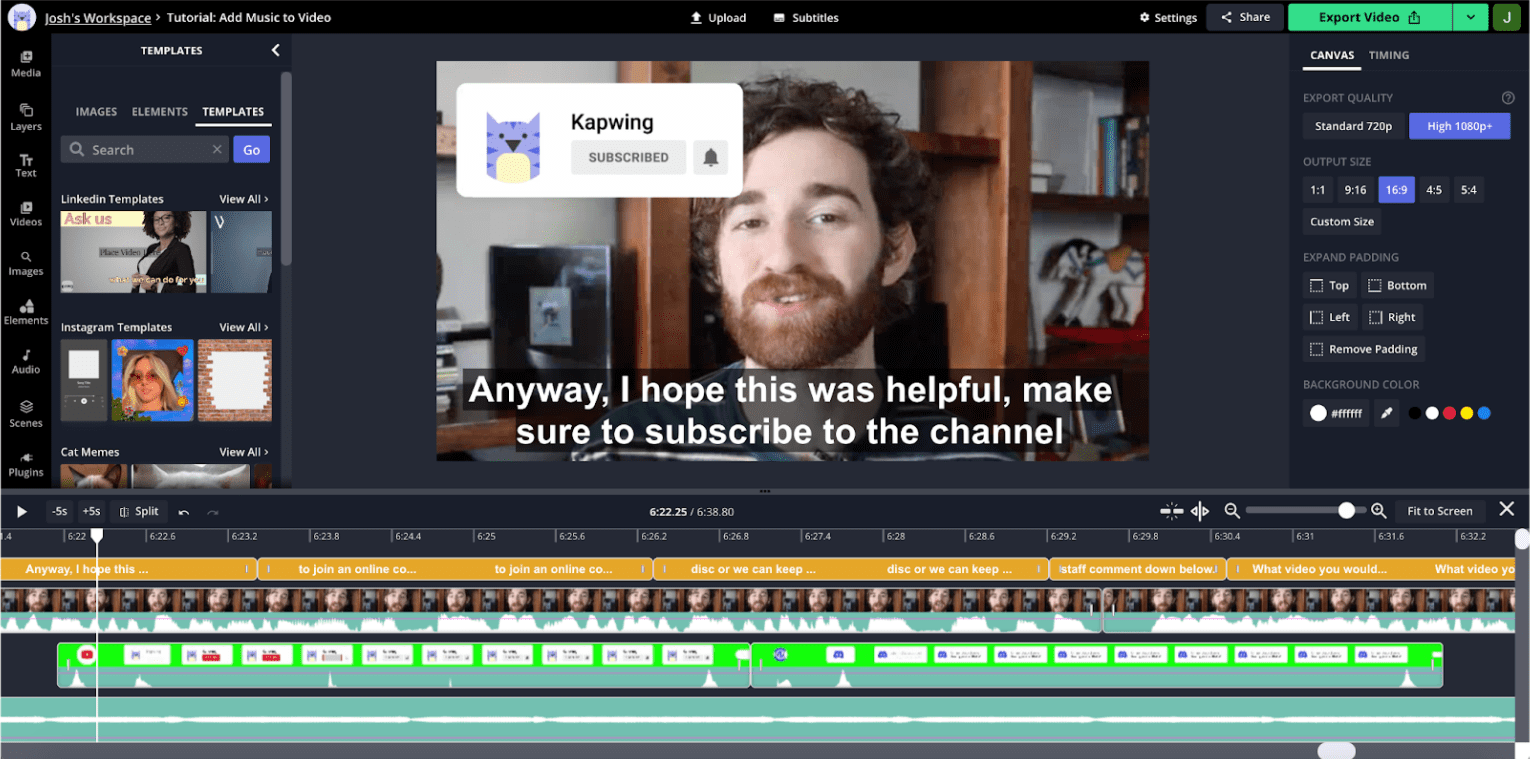
This is a YouTube style video, which is common in our app. The user doesn't move very much throughout the clip, so the timelines visual thumbnails aren't as useful for navigating between sections. On the other hand, the audio waveform shows peaks and valleys, with the valleys typically corresponding to dead time in the recording. If you zoom in on the timeline, you'd see more fine grained audio information with valleys corresponding to stutters and pauses.
Our user research shows that creators are often guided by these waveforms as they splice their content. The web audio API allows us to present this information performantly and to update quickly on a zoom or pan of the timeline.
The snippet below demonstrates how we do this:
const getDownsampledBuffer = (idbAsset: IdbAsset) =>
decodeMutex.runExclusive(
async (): Promise<Float32Array> => {
const arrayBuffer = await idbAsset.file.arrayBuffer();
const audioContext = new AudioContext();
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
const offline = new OfflineAudioContext(
audioBuffer.numberOfChannels,
audioBuffer.duration * MIN_BROWSER_SUPPORTED_SAMPLE_RATE,
MIN_BROWSER_SUPPORTED_SAMPLE_RATE
);
const downsampleSource = offline.createBufferSource();
downsampleSource.buffer = audioBuffer;
downsampleSource.start(0);
downsampleSource.connect(offline.destination);
const downsampledBuffer22K = await offline.startRendering();
const downsampledBuffer22KData = downsampledBuffer22K.getChannelData(0);
const downsampledBuffer = new Float32Array(
Math.floor(
downsampledBuffer22KData.length / POST_BROWSER_SAMPLE_INTERVAL
)
);
for (
let i = 0, j = 0;
i < downsampledBuffer22KData.length;
i += POST_BROWSER_SAMPLE_INTERVAL, j += 1
) {
let sum = 0;
for (let k = 0; k < POST_BROWSER_SAMPLE_INTERVAL; k += 1) {
sum += Math.abs(downsampledBuffer22KData[i + k]);
}
const avg = sum / POST_BROWSER_SAMPLE_INTERVAL;
downsampledBuffer[j] = avg;
}
return downsampledBuffer;
}
);
We pass this helper the asset that is stored in IndexedDB. Upon completion we will update the asset in IndexedDB as well as our own cache.
We gather data about the audioBuffer with the AudioContext constructor,
but because we aren't rendering to the device hardware we use the
OfflineAudioContext to render to an ArrayBuffer where we will store
amplitude data.
The API itself returns data at a sample rate much higher than needed for effective visualization. That's why we manually downsample to 200 Hz, which we found to be enough for useful, visually appealing waveforms.
WebCodecs
For certain videos the track thumbnails are more useful for timeline navigation than the waveforms. However, generating thumbnails is more resource intensive than generating waveforms.
We can't cache every potential thumbnail on load, so quick decode on timeline pan/zoom is critical to a performant and responsive application. The bottleneck to achieving smooth frame drawing is decoding frames, which until recently we did using an HTML5 video player. The performance of that approach wasn't reliable and we often saw degraded app responsiveness during frame rendering.
Recently we have moved over to WebCodecs, which can be used in web workers. This should enhance our ability to draw thumbnails for large amounts of layers without impacting main thread performance. While the web worker implementation is still in progress, we give an outline below of our existing main thread implementation.
A video file contains multiple streams: video, audio, subtitles and so on that are 'muxed' together. To use WebCodecs, we first need to have a demuxed video stream. We demux mp4s with the mp4box library, as shown here:
async function create(demuxer: any) {
demuxer.file = (await MP4Box).createFile();
demuxer.file.onReady = (info: any) => {
demuxer.info = info;
demuxer._info_resolver(info);
};
demuxer.loadMetadata();
}
const loadMetadata = async () => {
let offset = 0;
const asset = await getAsset(this.mediaLibraryId, null, this.url);
const maxFetchOffset = asset?.file.size || 0;
const end = offset + FETCH_SIZE;
const response = await fetch(this.url, {
headers: { range: `bytes=${offset}-${end}` },
});
const reader = response.body.getReader();
let done, value;
while (!done) {
({ done, value } = await reader.read());
if (done) {
this.file.flush();
break;
}
const buf: ArrayBufferLike & { fileStart?: number } = value.buffer;
buf.fileStart = offset;
offset = this.file.appendBuffer(buf);
}
};
This snippet refers to a demuxer class, which we use to encapsulate the
interface to MP4Box. We once again access the asset from IndexedDB. These
segments aren't necessarily stored in byte order, and that the appendBuffer
method returns the offset of the next chunk.
Here's how we decode a video frame:
const getFrameFromVideoDecoder = async (demuxer: any): Promise<any> => {
let desiredSampleIndex = demuxer.getFrameIndexForTimestamp(this.frameTime);
let timestampToMatch: number;
let decodedSample: VideoFrame | null = null;
const outputCallback = (frame: VideoFrame) => {
if (frame.timestamp === timestampToMatch) decodedSample = frame;
else frame.close();
};
const decoder = new VideoDecoder({
output: outputCallback,
});
const {
codec,
codecWidth,
codecHeight,
description,
} = demuxer.getDecoderConfigurationInfo();
decoder.configure({ codec, codecWidth, codecHeight, description });
/* begin demuxer interface */
const preceedingKeyFrameIndex = demuxer.getPreceedingKeyFrameIndex(
desiredSampleIndex
);
const trak_id = demuxer.trak_id
const trak = demuxer.moov.traks.find((trak: any) => trak.tkhd.track_id === trak_id);
const data = await demuxer.getFrameDataRange(
preceedingKeyFrameIndex,
desiredSampleIndex
);
/* end demuxer interface */
for (let i = preceedingKeyFrameIndex; i <= desiredSampleIndex; i += 1) {
const sample = trak.samples[i];
const sampleData = data.readNBytes(
sample.offset,
sample.size
);
const sampleType = sample.is_sync ? 'key' : 'delta';
const encodedFrame = new EncodedVideoChunk({
sampleType,
timestamp: sample.cts,
duration: sample.duration,
samapleData,
});
if (i === desiredSampleIndex)
timestampToMatch = encodedFrame.timestamp;
decoder.decodeEncodedFrame(encodedFrame, i);
}
await decoder.flush();
return { type: 'value', value: decodedSample };
};
The structure of the demuxer is quite complex and beyond the scope of this
article. It stores each frame in an array titled samples. We use the demuxer
to find the closest preceding key frame to our desired timestamp, which is
where we must begin video decode.
Videos are composed of full frames, known as key or i-frames, as well as much smaller delta frames, often referred to as p- or b-frames. Decode must always begin at a key frame.
The application decodes frames by:
- Instantiating the decoder with a frame output callback.
- Configuring the decoder for the specific codec and input resolution.
- Creating an
encodedVideoChunkusing data from the demuxer. - Calling the
decodeEncodedFramemethod.
We do this until we reach the frame with the desired timestamp.
What's next?
We define scale on our frontend as the ability to maintain precise and performant playback as projects get larger and more complex. One way to scale performance is to mount as few videos as possible at once, however when we do this, we risk slow and choppy transitions. While we've developed internal systems to cache video components for reuse, there are limitations to how much control HTML5 video tags can provide.
In the future, we may attempt to play all media using WebCodecs. This could allow us to be very precise about what data we buffer which should help scale performance.
We can also do a better job of offloading large trackpad computations to web workers, and we can be smarter about pre-fetching files and pre-generating frames. We see large opportunities to optimize our overall application performance and to extend functionality with tools like WebGL.
We would like to continue our investment in TensorFlow.js, which we currently use for intelligent background removal. We plan to leverage TensorFlow.js for other sophisticated tasks such as object detection, feature extraction, style transfer, and so on.
Ultimately, we're excited to continue building our product with native-like performance and functionality on a free and open web.