



Publié le 21 mai 2025
Policybazaar est l'une des principales plates-formes d'assurance en Inde, avec plus de 97 millions de clients enregistrés. Environ 80% des clients se rendent sur Policybazaar en ligne chaque mois. Il est donc essentiel que ses plates-formes offrent une expérience utilisateur fluide.
L'équipe de Policybazaar a remarqué qu'un nombre important d'utilisateurs accèdent à son site Web le soir, après les heures de travail de l'équipe d'assistance client. Au lieu que les utilisateurs aient à attendre le jour ouvré suivant pour obtenir des réponses ou à embaucher du personnel de nuit, Policybazaar souhaitait mettre en place une solution pour fournir un service immédiat à ces utilisateurs.
Les clients ont de nombreuses questions sur les contrats d'assurance, leur fonctionnement et le contrat qui répondrait à leurs besoins. Les questions personnalisées sont difficiles à traiter avec une FAQ ou des chatbots basés sur des règles. Pour répondre à ces besoins, l'équipe a mis en place une assistance personnalisée avec l'IA générative.
73 %
Les utilisateurs ont lancé des conversations de qualité et y ont participé
2 x
Taux de clics plus élevé par rapport à l'incitation à l'action précédente
10x
Inférence plus rapide avec WebGPU
Assistance personnalisée avec Finova AI
Pour fournir des réponses personnalisées et une meilleure assistance client en anglais et dans la langue indienne maternelle de certains utilisateurs, Policybazaar a créé un chatbot d'assistance d'assurance par texte et par voix appelé Finova AI.
De nombreuses étapes ont été nécessaires pour y parvenir. Regardez une présentation détaillée de la conférence sur les cas d'utilisation et les stratégies de l'IA Web dans le monde réel lors de Google I/O 2025.
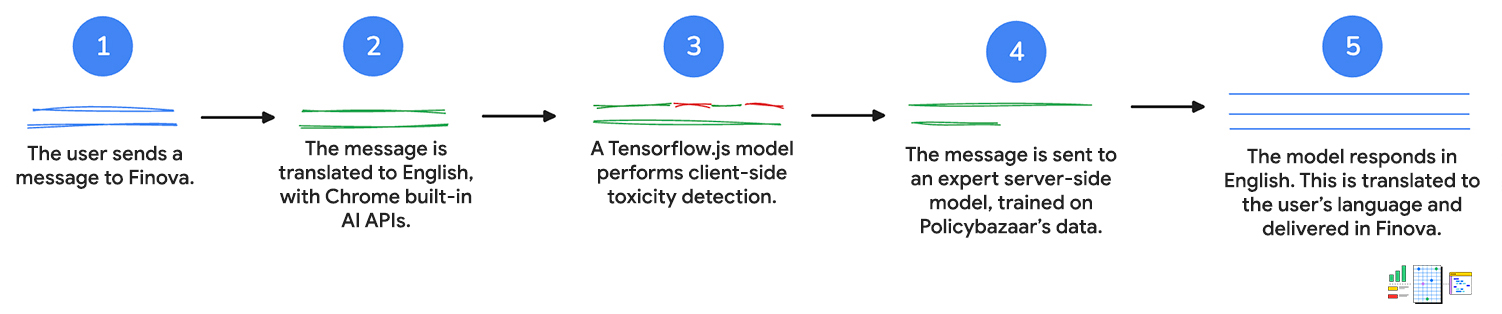
1. Entrée utilisateur
Le client envoie d'abord un message au chatbot, par écrit ou par commande vocale. S'il parle au chatbot, l'API Web Speech est utilisée pour convertir la voix en texte.
2. Traduire en français
Le message du client est envoyé à l'API Language Detector. Si l'API détecte une langue indienne, la saisie est envoyée à l'API Translator pour être traduite en anglais.
Ces deux API exécutent l'inférence côté client, ce qui signifie que l'entrée utilisateur ne quitte pas l'appareil pendant la traduction.
3. Le message est évalué à l'aide de la détection de la toxicité
Un modèle de détection de la toxicité côté client est utilisé pour évaluer si les entrées du client contiennent des propos inappropriés ou agressifs. Si c'est le cas, le client est invité à reformuler le message. Le message ne passe pas à l'étape suivante s'il contient du langage toxique.
Cela permet de maintenir des conversations respectueuses que le personnel d'assistance client pourra examiner et suivre, si nécessaire.
4. La requête est envoyée au serveur.
La requête traduite est ensuite transmise à un modèle côté serveur entraîné sur les données de Policybazaar et renvoie une réponse en anglais à la question.
Les clients peuvent obtenir des réponses et des recommandations personnalisées, ainsi que des réponses à des questions plus complexes sur les produits.
5. Traduire dans la langue du client
L'API Translator, utilisée pour traduire la requête initiale, la traduit à nouveau dans la langue du client, comme détecté par l'API Language Detector. Encore une fois, ces API s'exécutent côté client. Tout ce travail se passe donc sur l'appareil. Cela signifie que les clients peuvent obtenir de l'aide dans leur langue principale, ce qui rend le chatbot accessible aux personnes qui ne parlent pas anglais.
Architecture hybride
Finova AI, qui s'exécute à la fois sur les plates-formes pour ordinateur et mobile, s'appuie sur plusieurs modèles pour générer les résultats finaux. Policybazaar a créé une architecture hybride, dans laquelle une partie de la solution s'exécute côté client et une autre côté serveur.
Vous pouvez être amené à implémenter une architecture hybride pour plusieurs raisons, que vous n'utilisiez qu'un seul modèle ou plusieurs.
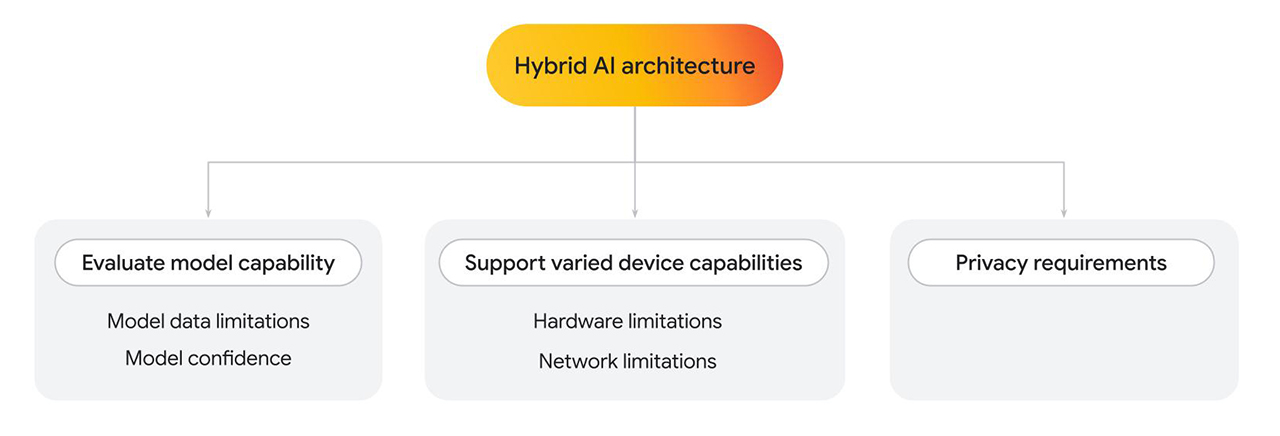
- Évaluez les fonctionnalités du modèle côté client. Retourner au côté serveur si nécessaire.
- Limites des données du modèle: la taille des modèles de langage peut varier considérablement, ce qui détermine également des fonctionnalités spécifiques. Par exemple, imaginons qu'un utilisateur pose une question personnelle concernant un service que vous fournissez. Un modèle côté client peut être en mesure de répondre à la question, s'il est entraîné dans ce domaine spécifique. Toutefois, si ce n'est pas possible, vous pouvez utiliser une implémentation côté serveur, qui est entraînée sur un ensemble de données plus complexe et plus volumineux.
- Fiabilité du modèle: dans les modèles de classification, tels que la modération de contenu ou la détection de fraude, un modèle côté client peut renvoyer un score de confiance inférieur. Dans ce cas, vous pouvez utiliser un modèle côté serveur plus performant.
- Prendre en charge différentes fonctionnalités de l'appareil
- Limites matérielles: dans l'idéal, toutes vos fonctionnalités d'IA devraient être accessibles à tous vos utilisateurs. En réalité, les utilisateurs utilisent un large éventail d'appareils, et tous ne sont pas compatibles avec l'inférence IA. Si un appareil ne prend pas en charge l'inférence côté client, vous pouvez utiliser le serveur. Avec cette approche, vous pouvez rendre votre fonctionnalité hautement accessible, tout en réduisant les coûts et la latence lorsque cela est possible.
- Limites réseau: si l'utilisateur est hors connexion ou sur des réseaux instables, mais qu'il dispose d'un modèle mis en cache dans le navigateur, vous pouvez exécuter le modèle côté client.
- Exigences en termes de confidentialité
- Vous pouvez avoir des exigences de confidentialité strictes pour votre application. Par exemple, si une partie du parcours utilisateur nécessite la validation de l'identité à l'aide d'informations personnelles ou de la détection de visage, optez pour un modèle côté client afin de traiter les données sur l'appareil et d'envoyer la sortie de validation (par exemple, "OK" ou "Échec") au modèle côté serveur pour les étapes suivantes.
Pour Policybazaar, où une faible latence, une rentabilité et une confidentialité étaient requises, une solution côté client a été utilisée. Lorsque des modèles plus complexes entraînés sur des données personnalisées étaient nécessaires, une solution côté serveur était utilisée.
Nous allons maintenant examiner de plus près l'implémentation du modèle côté client.
Détection de la toxicité côté client
Une fois les messages traduits, le message du client est transmis au modèle de détection de la toxicité TensorFlow.js, qui s'exécute côté client, sur ordinateur et sur mobile. La transcription est transmise à l'équipe d'assistance humaine pour suivi. Il est donc important d'éviter tout langage toxique. Les messages sont analysés sur l'appareil de l'utilisateur avant d'être envoyés au serveur, puis à l'équipe d'assistance humaine finale.
De plus, l'analyse côté client a permis de supprimer les informations sensibles. La confidentialité des utilisateurs est une priorité absolue, et l'inférence côté client y contribue.
Plusieurs étapes sont nécessaires pour chaque message. Avec la détection de la toxicité, en plus de la détection et de la traduction de la langue, chaque message nécessiterait plusieurs aller-retours vers le serveur. En effectuant ces tâches côté client, Policybazaar peut considérablement limiter le coût projeté de la fonctionnalité.
Policybazaar est passé de WebGL à un backend WebGPU (pour les navigateurs compatibles), et le temps d'inférence a été multiplié par 10. Les utilisateurs ont reçu des commentaires plus rapides pour réviser leur message, ce qui a entraîné un engagement et une satisfaction client plus élevés.
// Create an instance of the toxicity model.
const createToxicityModelInstance = async () => {
try {
//use WebGPU backend if available
if (navigator.gpu) {
await window.tf.setBackend('webgpu');
await window.tf.ready();
}
return await window.toxicity.load(0.9).then(model => {
return model;
}).catch(error => {
console.log(error);
return null;
});
} catch (er) {
console.error(er);
}
}
Engagement et taux de clics élevés
En combinant plusieurs modèles avec des API Web, Policybazaar a réussi à étendre l'assistance client après les heures ouvrées. Les premiers résultats d'une version limitée de cette fonctionnalité ont indiqué un engagement utilisateur élevé.
73% des utilisateurs qui ont ouvert le chatbot ont participé à des conversations multiquestions de plusieurs minutes, ce qui a entraîné un faible taux de rebond. De plus, le programme pilote a démontré un taux de clics deux fois plus élevé pour ce nouvel incitant à l'assistance client, ce qui montre que les clients ont bien interagi avec Finova pour leurs demandes. De plus, le passage à un backend WebGPU pour la détection de la toxicité côté client a accéléré l'inférence de 10 fois, ce qui a permis d'obtenir des commentaires plus rapides des utilisateurs.
73 %
Les utilisateurs ont lancé des conversations de qualité et y ont participé
2 x
Taux de clics plus élevé par rapport à l'incitation à l'action précédente
10x
Inférence plus rapide avec WebGPU
Ressources
Si vous souhaitez étendre les fonctionnalités de votre propre application Web avec l'IA côté client:
- Découvrez comment implémenter la détection de la toxicité côté client.
- Consultez une collection de démonstrations de l'IA côté client.
- En savoir plus sur Mediapipe et Transformers.js Vous pouvez utiliser des modèles pré-entraînés et les intégrer à votre application avec JavaScript.
- La collection sur l'IA dans Chrome pour les développeurs fournit des ressources, des bonnes pratiques et des informations à jour sur les technologies qui alimentent l'IA dans Chrome et au-delà.
- Cela inclut l'étude de cas sur la façon dont Policybazaar et JioHotstar utilisent les API Translator et Language Detector pour créer des expériences multilingues.
- Découvrez des exemples concrets d'IA Web lors de l'I/O 2025.