



發布日期:2025 年 5 月 21 日
Policybazaar 是印度領先的保險平台之一,擁有超過 9, 700 萬名註冊客戶。約有 80% 的客戶每月會造訪 Policybazaar 網站,因此他們的平台必須提供順暢的使用者體驗。
Policybazaar 團隊發現,大量使用者會在晚間造訪網站,也就是客戶服務團隊下班後。為了讓使用者不必等到下一個工作日才能獲得解答,或聘請夜間值班人員,Policybazaar 希望導入解決方案,為這些使用者提供即時服務。
客戶對保險方案、運作方式,以及哪種方案符合需求等方面有很多疑問。使用常見問題或以規則為基礎的聊天機器人,很難回答個人化問題。為滿足這些需求,團隊導入了運用生成式 AI 技術的個人化協助功能。
73%
使用者發起並參與優質對話
2倍
點閱率高於先前的行動號召
10 x
運用 WebGPU 加快推論速度
透過 Finova AI 提供個人化協助
為提供個人化答案,並以英文和部分使用者的印度次大陸母語提供更完善的客戶協助服務,Policybazaar 打造了名為 Finova AI 的文字和語音輔助保險聊天機器人。
我們必須完成許多步驟才能實現這一點。觀看 2025 年 Google I/O 大會的網路 AI 應用實例和實際策略講座,瞭解詳細的操作步驟。
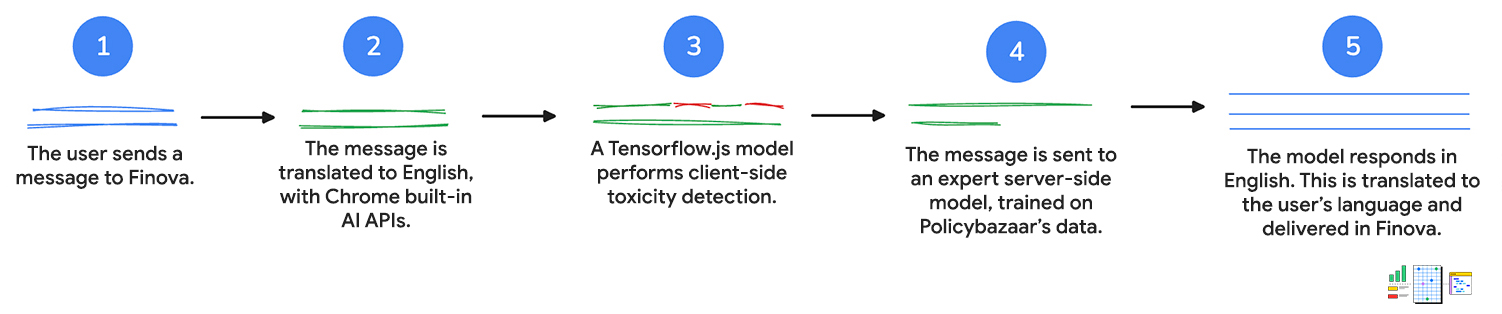
1. 使用者輸入內容
首先,客戶會透過文字或語音傳送訊息給聊天機器人。如果他們與聊天機器人對話,系統會使用 Web Speech API 將語音轉換為文字。
2. 翻譯成繁體中文
客戶的訊息會傳送至 Language Detector API。如果 API 偵測到印度次大陸語言,輸入內容就會傳送至 Translator API,以便翻譯成英文。
這兩個 API 都會在用戶端執行推論,也就是說,使用者輸入內容不會在翻譯期間離開裝置。
3. 訊息會經過惡意指數偵測評估
系統會使用用戶端毒性偵測模型,評估客戶輸入內容是否含有不當或攻擊性字詞。如果是,系統會提示客戶重新表達訊息。如果訊息含有有害的言論,系統就不會繼續下一個步驟。
這樣一來,客戶服務人員就能在必要時查看對話內容並進行後續處理,以便維持禮貌對話。
4. 要求已傳送至伺服器
然後將已翻譯的查詢傳遞至以 Policybazaar 資料訓練的伺服器端模型,並傳回問題的英文回覆。
客戶可以獲得個人化解答和推薦內容,以及關於產品的更複雜問題解答。
5. 翻譯成客戶的語言
Translator API 用於翻譯初始查詢,並將查詢翻譯回 Language Detector API 偵測到的客戶語言。請注意,這些 API 會在用戶端執行,因此所有工作都會在裝置上進行。也就是說,客戶可以以母語獲得協助,讓非英語使用者也能使用聊天機器人。
混合型架構
Finova AI 可在電腦和行動平台上執行,並且會使用多個模型產生最終結果。Policybazaar 建構了混合型架構,其中部分解決方案會在用戶端執行,部分則會在伺服器端執行。
無論您只使用一個還是多個模型,都可能需要實作混合架構,原因有很多。
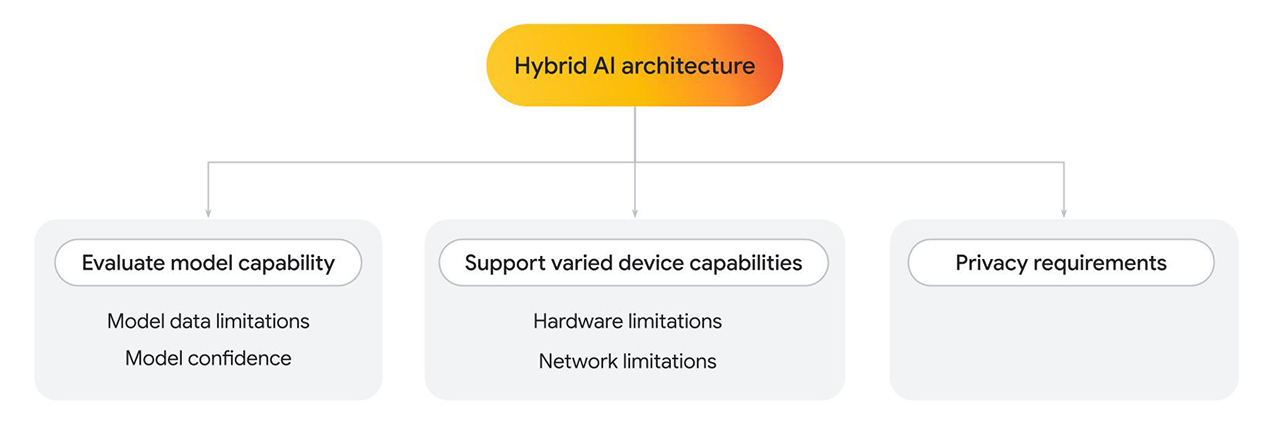
- 評估用戶端模型功能。視需要改用伺服器端。
- 模型資料限制:語言模型的大小可能差異極大,這也決定了特定功能。舉例來說,假設使用者詢問與您提供服務相關的個人問題。如果客戶端模型經過特定領域的訓練,可能就能回答問題。不過,如果無法使用,您可以改用伺服器端實作項目,該項目會針對更複雜且更大型的資料集進行訓練。
- 模型可信度:在分類模型 (例如內容審核或詐欺偵測) 中,用戶端模型可能會輸出較低的可信度分數。在這種情況下,您可能需要改用功能更強大的伺服器端模型。
- 支援各種裝置功能。
- 硬體限制:理想情況下,所有使用者都能使用 AI 功能。實際上,使用者會使用各種裝置,而且並非所有裝置都能支援 AI 推論。如果裝置無法支援用戶端推論,您可以改用伺服器。透過這種做法,您可以讓功能高度可用,同時盡可能降低成本和延遲。
- 網路限制:如果使用者處於離線狀態或網路不穩定,但瀏覽器上有快取的模型,您可以執行用戶端模型。
- 隱私權相關規定。
- 您可能會對應用程式設下嚴格的隱私權要求。舉例來說,如果使用者流程的某部分需要透過個人資訊或臉部辨識驗證身分,請選擇使用用戶端模型,在裝置上處理資料,並將驗證輸出內容 (例如通過或失敗) 傳送至伺服器端模型,以便進行後續步驟。
對於需要低延遲、成本效益和隱私權的 Policybazaar,我們採用了用戶端解決方案。如需以自訂資料訓練更複雜的模型,則會使用伺服器端解決方案。
我們將進一步探討用戶端模型的實作方式。
用戶端惡意指數偵測
翻譯訊息後,系統會將客戶的訊息傳送至 TensorFlow.js 有害內容偵測模型,在電腦和行動裝置上執行用戶端。由於語音轉錄內容會轉交給人工協助人員,請務必避免使用有害的言論。系統會先在使用者的裝置上分析訊息,然後再傳送至伺服器,最後由人力協助人員提供協助。
此外,用戶端分析功能可移除機密資訊。使用者隱私是首要考量,而用戶端推論功能有助於實現這項目標。
每則訊息都需要執行幾個步驟。除了語言偵測和翻譯之外,使用有害內容偵測功能時,每則訊息都需要與伺服器進行多次往返傳輸。透過在用戶端執行這些工作,Policybazaar 可大幅限制預估功能成本。
Policybazaar 從 WebGL 改用 WebGPU 後端 (適用於支援的瀏覽器),推論時間縮短了 10 倍。使用者能更快收到意見回饋,以便修改訊息,進而提高參與度和顧客滿意度。
// Create an instance of the toxicity model.
const createToxicityModelInstance = async () => {
try {
//use WebGPU backend if available
if (navigator.gpu) {
await window.tf.setBackend('webgpu');
await window.tf.ready();
}
return await window.toxicity.load(0.9).then(model => {
return model;
}).catch(error => {
console.log(error);
return null;
});
} catch (er) {
console.error(er);
}
}
高參與度和點閱率
結合多個模型與網路 API 後,Policybazaar 成功在營業時間結束後提供客戶協助服務。這項功能的初步測試結果顯示,使用者參與度很高。
73% 的使用者開啟聊天機器人後,會進行多個問題的對話,對話時間長達數分鐘,因此跳出率偏低。此外,前測計畫顯示,這項新的客戶協助行動呼籲點閱率提高了 2 倍,顯示 Finova 成功與客戶互動,解答他們的疑問。此外,將用戶端毒性偵測功能切換為 WebGPU 後端,推論速度加快了 10 倍,因此使用者回饋的速度也加快了。
73%
使用者發起並參與優質對話
2倍
點閱率高於先前的行動號召
10 x
運用 WebGPU 加快推論速度
資源
如果您想使用用戶端 AI 擴充自有網頁應用程式的功能,請按照下列步驟操作:
- 瞭解如何實作用戶端有害內容偵測功能。
- 查看一系列用戶端 AI 示範。
- 請參閱 Mediapipe 和 Transformers.js 相關說明。您可以使用預先訓練的模型,並透過 JavaScript 將其整合至應用程式。
- Chrome 開發人員專用的 AI 資源集提供 Chrome 和其他平台的 AI 技術相關資源、最佳做法和最新資訊。
- 歡迎參閱 2025 年 I/O 大會的 Web AI 實際應用案例。