
Lorsque vous créez des requêtes pour des applications réelles, un compromis clé se présente : trouver le juste équilibre entre concision et efficacité. Lorsque tous les facteurs sont égaux, un prompt concis est plus rapide, moins cher et plus facile à gérer qu'un prompt plus long. Cela est particulièrement pertinent dans les environnements Web où la latence et les limites de jetons sont importantes. Toutefois, si votre requête est trop minimaliste, il est possible que le modèle manque de contexte, d'instructions ou d'exemples pour produire des résultats de haute qualité.
Le développement axé sur l'évaluation (EDD, Evaluation-Driven Development) vous permet de surveiller et d'optimiser systématiquement ce compromis. Il offre un processus reproductible et testable pour améliorer les résultats par petites étapes sûres, détecter les régressions et aligner le comportement du modèle sur les attentes des utilisateurs et des produits au fil du temps.
Considérez-le comme un développement piloté par les tests, adapté à l'incertitude de l'IA. Contrairement aux tests unitaires déterministes, les évaluations de l'IA ne peuvent pas être codées en dur, car les résultats, qu'ils soient bien formés ou non, peuvent prendre des formes inattendues.
L'EDD vous aide également dans vos efforts de découverte. Tout comme l'écriture de tests permet de clarifier le comportement d'une fonctionnalité, la définition de critères d'évaluation et l'examen des résultats du modèle vous obligent à faire face au manque de clarté et à ajouter progressivement plus de détails et de structure aux tâches ouvertes ou inconnues.
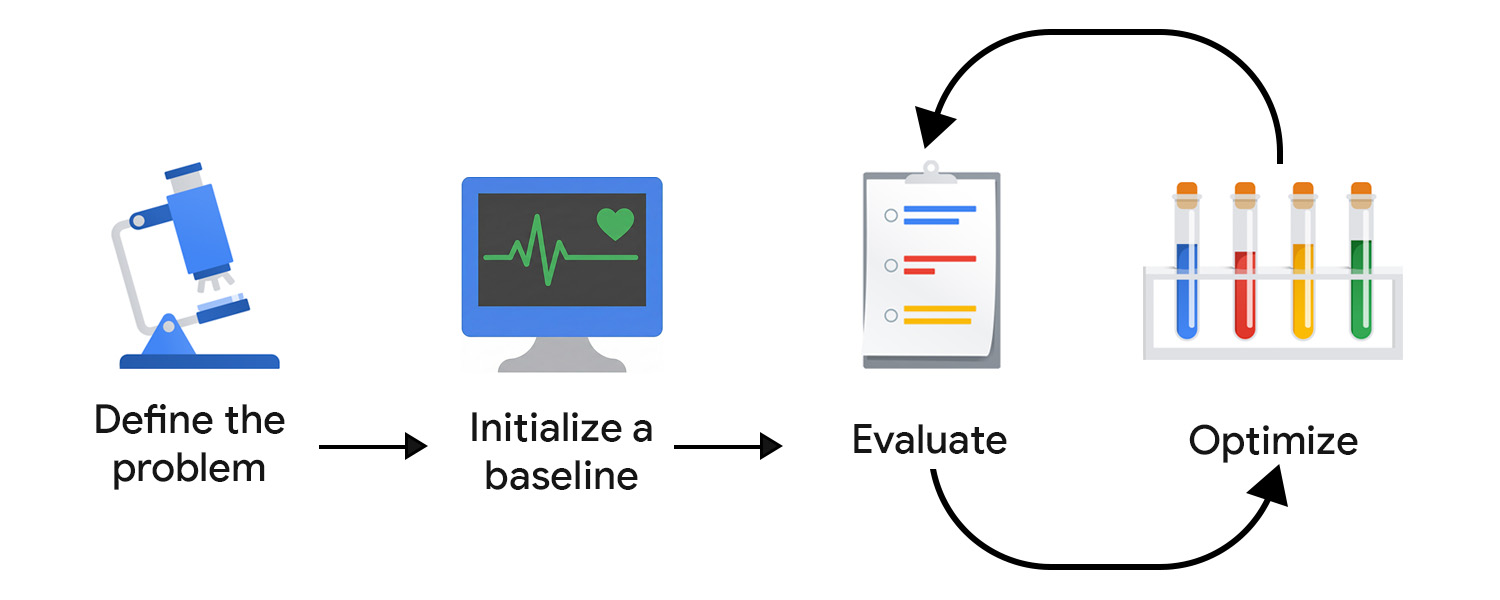
Définir le problème
Vous pouvez formuler votre problème comme un contrat d'API, en incluant le type d'entrée, le format de sortie et toute contrainte supplémentaire. Exemple :
- Type d'entrée : brouillon d'article de blog
- Format de sortie : tableau JSON avec trois titres de posts
- Contraintes : moins de 128 caractères, ton amical
Ensuite, collectez des exemples d'entrées. Pour assurer la diversité des données, vous incluez à la fois des exemples idéaux et des entrées réelles et désordonnées. Pensez aux variations et aux cas extrêmes, comme les posts avec des emoji, une structure imbriquée et de nombreux extraits de code.
Initialiser une référence
Rédigez votre première requête. Commencez par le zero-shot et incluez des instructions claires, un format de sortie et un espace réservé pour le contenu d'entrée.
Vous augmenterez la complexité de votre système et utiliserez des composants ou des techniques d'incitation supplémentaires pour optimiser votre système d'IA. Pour utiliser notre temps efficacement et optimiser les bons composants, vous devez configurer un système d'évaluation.
Créer votre système d'évaluation
Dans le développement piloté par les tests, vous commencez à écrire des tests une fois que vous connaissez les exigences. Avec l'IA générative, il n'existe pas de résultats définitifs à tester. Vous devez donc redoubler d'efforts pour concevoir votre boucle d'évaluation.
Vous aurez probablement besoin de plusieurs outils de mesure pour évaluer efficacement vos campagnes.
Définir vos métriques d'évaluation
Les métriques d'évaluation peuvent être déterministes, ce qui signifie qu'il existe une réponse correcte connue. Par exemple, vous pouvez vérifier si le modèle renvoie un code JSON valide ou s'il génère le bon nombre d'éléments.
Cependant, avec l'IA, vous passerez la majeure partie de votre temps à identifier et à affiner les mesures qualitatives subjectives. Cela inclut la qualité, l'utilité, le ton et la créativité des résultats. Vous pouvez commencer par définir des objectifs de réussite plus généraux pour déterminer comment le résultat doit répondre à vos attentes. Vous finirez par rencontrer des problèmes spécifiques et nuancés qui vous aideront à mieux définir vos objectifs.
Par exemple, supposons que votre générateur de titres utilise trop souvent certaines expressions ou certains schémas, ce qui donne des résultats répétitifs et robotiques. Dans ce cas, vous devez définir de nouvelles métriques pour encourager la variation et décourager les structures ou les mots clés trop utilisés. Au fil du temps, vos métriques clés se stabiliseront et vous pourrez suivre vos progrès.
Ce processus peut bénéficier de l'aide d'experts qui comprennent ce qui est bien dans le domaine de votre application et qui peuvent identifier les modes de défaillance subtils. Par exemple, si vous développez un assistant de rédaction, associez-vous à un producteur de contenu ou à un rédacteur pour vous assurer que votre évaluation correspond à leur vision du monde.
Choisir vos juges
Différents critères d'évaluation nécessitent différents évaluateurs :
- Les vérifications basées sur le code fonctionnent bien pour les sorties déterministes ou basées sur des règles. Par exemple, vous pouvez rechercher des mots à éviter dans les titres, vérifier le nombre de caractères ou valider la structure JSON. Elles sont rapides, répétables et parfaites pour les éléments d'UI à sortie fixe, tels que les boutons ou les champs de formulaire.
- Les commentaires humains sont essentiels pour évaluer des qualités plus subjectives, comme le ton, la clarté ou l'utilité. Surtout au début, l'examen des résultats du modèle par vous-même (ou avec des experts du domaine) permet une itération rapide. Toutefois, cette approche n'est pas très évolutive. Une fois votre application lancée, vous pouvez également collecter des signaux dans l'application, comme une note en étoiles, mais ils ont tendance à être bruyants et manquent de la nuance nécessaire pour une optimisation précise.
- LLM-as-judge offre un moyen évolutif d'évaluer des critères subjectifs en utilisant un autre modèle d'IA pour noter ou critiquer les résultats. Elle est plus rapide que la révision humaine, mais n'est pas sans écueils : dans une implémentation naïve, elle peut perpétuer et même renforcer les biais et les lacunes du modèle.
Privilégiez la qualité à la quantité. Dans le machine learning classique et l'IA prédictive, il est courant de faire appel au crowdsourcing pour annoter les données. Pour l'IA générative, les annotateurs crowdsourcés manquent souvent de contexte de domaine. Une évaluation de haute qualité et riche en contexte est plus importante que l'échelle.
Évaluer et optimiser
Plus vite vous pourrez tester et affiner vos requêtes, plus vite vous obtiendrez un résultat qui correspond aux attentes des utilisateurs. Vous devez prendre l'habitude d'optimiser en continu. Essayez une amélioration, évaluez-la, puis essayez autre chose.
Une fois en production, continuez à observer et à évaluer le comportement de vos utilisateurs et de votre système d'IA. Ensuite, analysez et transformez ces données en étapes d'optimisation.
Automatiser votre pipeline d'évaluation
Pour réduire les frictions dans vos efforts d'optimisation, vous avez besoin d'une infrastructure opérationnelle qui automatise l'évaluation, suit les modifications et relie le développement à la production. C'est ce qu'on appelle communément LLMOps. Bien qu'il existe des plates-formes qui peuvent vous aider à automatiser vos tâches, vous devez concevoir votre workflow idéal avant de vous engager avec une solution tierce.
Voici quelques composants clés à prendre en compte :
- Gestion des versions : stockez les requêtes, les métriques d'évaluation et les entrées de test dans le contrôle des versions. Traitez-les comme du code pour garantir la reproductibilité et un historique des modifications clair.
- Évaluations par lot automatisées : utilisez des workflows (tels que GitHub Actions) pour exécuter des évaluations à chaque mise à jour d'invite et générer des rapports comparatifs.
- CI/CD pour les requêtes : contrôlez les déploiements avec des vérifications automatisées, telles que des tests déterministes, des scores LLM-as-judge ou des garde-fous, et bloquez les fusions lorsque la qualité régresse.
- Journalisation et observabilité de la production : capturez les entrées, les sorties, les erreurs, la latence et l'utilisation des jetons. Surveillez la dérive, les schémas inattendus ou les pics d'échecs.
- Ingestion des commentaires : collectez les signaux utilisateur (pouces, réécritures, abandon) et transformez les problèmes récurrents en nouveaux cas de test.
- Suivi des tests : suivez les versions de prompts, les configurations de modèles et les résultats d'évaluation.
Effectuez des itérations avec des modifications ciblées et de petite envergure.
Le raffinement des requêtes commence généralement par l'amélioration du langage de votre requête. Cela peut signifier rendre les instructions plus spécifiques, clarifier l'intention ou supprimer les ambiguïtés.
Veillez à ne pas surajuster le modèle. Une erreur courante consiste à ajouter des règles trop strictes pour corriger les problèmes liés au modèle. Par exemple, si votre générateur de titres continue de produire des titres commençant par Le guide ultime, vous pourriez être tenté d'interdire explicitement cette expression. Abstrayez plutôt le problème et ajustez l'instruction de niveau supérieur. Cela peut signifier que vous mettez l'accent sur l'originalité, la variété ou un style éditorial spécifique, de sorte que le modèle apprend la préférence sous-jacente plutôt qu'une seule exception.
Une autre approche consiste à tester davantage de techniques d'incitation et à combiner ces efforts. Lorsque vous choisissez une technique, demandez-vous si la tâche est mieux résolue par analogie (few-shot), par un raisonnement étape par étape (chain-of-thought) ou par un affinement itératif (self-reflection).
Lorsque votre système passe en production, votre flywheel EDD ne doit pas ralentir. Au contraire, elle devrait s'accélérer. Si votre système traite et enregistre les saisies des utilisateurs, celles-ci devraient devenir votre source d'informations la plus précieuse. Ajoutez des modèles récurrents à votre suite d'évaluation, et identifiez et implémentez en permanence les meilleures étapes d'optimisation suivantes.
Vos points à retenir
Le développement de requêtes axé sur l'évaluation vous permet de gérer l'incertitude de l'IA de manière structurée. En définissant clairement votre problème, en créant un système d'évaluation personnalisé et en apportant des améliorations ciblées, vous créez une boucle de rétroaction qui améliore progressivement les sorties du modèle.
Ressources
Voici quelques lectures recommandées si vous souhaitez implémenter LLM-as-judge :
- Comparer les capacités des LLM avec la synthèse
- Consultez le guide de Hamel Husain sur l'utilisation des LLM comme juges.
- Consultez l'étude A Survey on LLM-as-a-Judge.
Si vous souhaitez améliorer vos requêtes, consultez Développement contextuel. Il est préférable que cette tâche soit effectuée par un ingénieur en machine learning.
Vérifier que vous avez bien compris
Quel est l'objectif principal du développement axé sur l'évaluation ?
Pourquoi utiliser des modèles plus grands pour évaluer un système côté client ?
Quel est l'un des pièges potentiels de l'utilisation d'un LLM comme juge pour l'évaluation ?
Quel composant fait partie d'un pipeline d'évaluation automatique recommandé ?
Lorsque vous choisissez des juges pour votre système d'évaluation, quelle est la principale limite de l'utilisation du feedback humain ?