
Avant de créer avec l'IA, vous devez choisir la plate-forme sur laquelle elle est hébergée. Votre choix a un impact sur la vitesse, le coût, l'évolutivité et la fiabilité de votre système d'IA. Vous avez le choix entre plusieurs options :
- IA côté client : s'exécute directement dans le navigateur. Cela signifie que les données peuvent rester privées, sur l'appareil de l'utilisateur, et qu'il n'y a pas de latence réseau. Toutefois, pour fonctionner correctement, l'IA côté client a besoin de cas d'utilisation très spécifiques et bien définis.
- IA côté serveur : s'exécute dans le cloud. Il est très performant et évolutif, mais plus coûteux en termes de latence et de coût.
Chaque option présente des avantages et des inconvénients. La configuration appropriée dépend de votre cas d'utilisation, des compétences de votre équipe et de vos ressources. Par exemple, vous pouvez proposer un outil de synthèse qui s'exécute en local afin que les utilisateurs puissent poser des questions personnelles sans avoir à gérer d'informations permettant de les identifier personnellement. Toutefois, un agent du service client pourrait fournir des réponses plus utiles en utilisant un modèle basé sur le cloud qui a accès à une grande base de données de ressources.
Dans ce module, vous allez apprendre à :
- Comparez les compromis entre l'IA côté client et côté serveur.
- Choisissez une plate-forme adaptée à votre cas d'utilisation et aux capacités de votre équipe.
- Concevez des systèmes hybrides, qui offrent l'IA sur le client et le serveur, pour évoluer avec votre produit.
Examiner les options
Pour le déploiement, pensez aux plates-formes d'IA selon deux axes principaux. Vous avez plusieurs choix possibles :
- Où le modèle s'exécute-t-il ? S'exécute-t-il côté client ou côté serveur ?
- Personnalisation : dans quelle mesure pouvez-vous contrôler les connaissances et les capacités du modèle ? Si vous pouvez contrôler le modèle, c'est-à-dire modifier les pondérations du modèle, vous pouvez personnaliser son comportement pour répondre à vos exigences spécifiques.
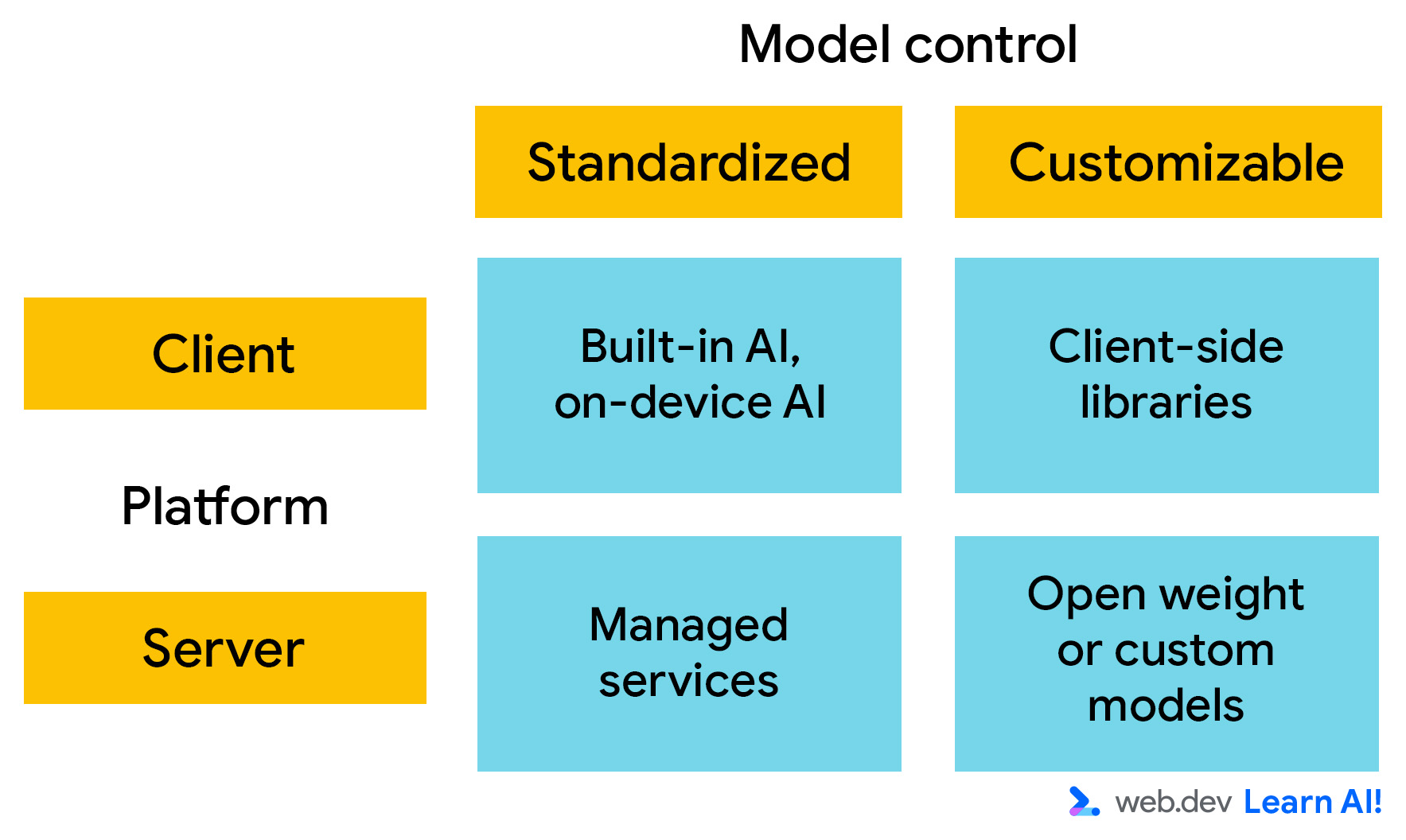
IA côté client
L'IA côté client s'exécute dans le navigateur et les calculs sont effectués localement sur l'appareil de l'utilisateur. Vous n'avez pas besoin de fournir de ressources de calcul pour l'inférence, et les données restent sur la machine de l'utilisateur. Il est donc rapide, privé et adapté aux expériences interactives légères.
Toutefois, les modèles côté client sont généralement assez petits, ce qui peut limiter leurs capacités et leurs performances. Ils sont plus adaptés aux tâches très spécialisées, comme la détection de toxicité ou l'analyse des sentiments. Il s'agit souvent de tâches d'IA prédictive avec un espace de sortie limité.
Vous avez deux options principales :
- IA intégrée : les navigateurs, tels que Google Chrome et Microsoft Edge, intègrent des modèles d'IA. Elles sont accessibles via des appels JavaScript, sans configuration ni hébergement requis. Une fois le modèle téléchargé, il peut être appelé par tous les sites Web qui l'utilisent.
- Modèles personnalisés : vous pouvez utiliser des bibliothèques côté client, telles que Transformers.js et MediaPipe, pour intégrer des modèles à votre application. Cela signifie que vous pouvez contrôler les pondérations du modèle. Toutefois, cela signifie également que chaque utilisateur de votre site Web doit télécharger votre modèle personnalisé. Même les plus petits modèles d'IA sont volumineux dans le contexte d'un site Web.
IA côté serveur
Avec l'IA côté serveur, votre application Web appelle une API pour envoyer des entrées au modèle d'IA et recevoir ses sorties. Cette configuration est compatible avec des modèles plus volumineux et plus complexes, et est indépendante du matériel de l'utilisateur.
Il existe deux catégories d'IA côté serveur :
- Services gérés : il s'agit de modèles hébergés dans des centres de données par un tiers, comme Gemini 3 et GPT-5. Le propriétaire du modèle fournit une API pour y accéder. Cela signifie que vous pouvez utiliser des modèles de pointe avec une configuration minimale. Ils sont idéaux pour le prototypage rapide, les conversations ouvertes et le raisonnement à usage général. Toutefois, la mise à l'échelle sur un service géré peut être coûteuse.
- Modèles auto-hébergés : vous pouvez déployer des modèles Open Source, tels que Gemma ou Llama, sur votre propre infrastructure ou dans un conteneur géré, tel que Vertex AI ou Hugging Face Inference. Cette approche vous permet de bénéficier du pré-entraînement effectué par le créateur du modèle, tout en gardant le contrôle sur le modèle, les données d'affinage et les performances.
Choisir une plate-forme initiale
Examinez les caractéristiques architecturales des plates-formes d'IA et analysez les compromis pour décider de votre configuration initiale.
Définir vos exigences architecturales
Chaque décision implique des compromis. Examinez les principales caractéristiques qui définissent le coût et la valeur de votre plate-forme d'IA :
- Puissance du modèle : performances du modèle pour un large éventail d'utilisateurs et de tâches, sans réglage. Cela est souvent corrélé à la taille du modèle.
- Personnalisation : mesure dans laquelle vous pouvez affiner, modifier ou contrôler le comportement et l'architecture du modèle.
- Justesse : qualité et fiabilité globales des prédictions ou des générations du modèle.
- Confidentialité : degré de localisation des données utilisateur et de contrôle par l'utilisateur.
- Coût fixe : dépense récurrente nécessaire au fonctionnement du système d'IA, quelle que soit son utilisation, y compris le provisionnement et la maintenance de l'infrastructure.
- Coût par requête : coût supplémentaire de chaque requête entrante.
- Compatibilité : mesure de la compatibilité de l'approche avec les navigateurs, les appareils et les environnements sans logique de secours.
- Confort de l'utilisateur : indique si les utilisateurs doivent effectuer des étapes supplémentaires pour utiliser le système d'IA, comme télécharger un modèle.
- Facilité d'utilisation pour les développeurs : rapidité et facilité avec lesquelles la plupart des développeurs peuvent déployer, intégrer et gérer le modèle, sans expertise spécialisée en IA.
Le tableau suivant fournit un exemple d'estimations des performances de chaque plate-forme pour chaque critère, où 1 correspond à la valeur la plus faible et 5 à la valeur la plus élevée.
| Critères | Client | sur le serveur GAIA | ||
| IA intégrée ou sur l'appareil | Modèle personnalisé | Service géré | Modèle auto-hébergé | |
| Puissance du modèle |
Pourquoi deux étoiles pour la puissance du modèle ?L'IA intégrée et sur l'appareil utilise de petits modèles de navigateur préchargés, optimisés pour des fonctionnalités spécifiques et limitées, plutôt que pour des conversations ou des raisonnements ouverts. |
Pourquoi trois étoiles pour la puissance du modèle ?Les bibliothèques personnalisées côté client offrent plus de flexibilité que l'IA intégrée, mais vous êtes toujours limité par la taille du téléchargement, les limites de mémoire et le matériel de l'utilisateur. |
Pourquoi 4 étoiles pour la puissance du modèle ?Avec les services gérés et l'auto-hébergement, vous avez accès à de grands modèles de pointe, capables de raisonnements complexes, de gestion de contexte étendu et d'une large couverture de tâches. |
|
| Personnalisation |
Pourquoi avez-vous attribué une étoile à la personnalisation ?Les modèles intégrés n'autorisent pas l'accès aux pondérations du modèle ni aux données d'entraînement. Le principal moyen de personnaliser leur comportement est l'ingénierie des requêtes. |
Pourquoi 5 étoiles pour la personnalisation ?Cette option vous permet de contrôler la sélection et les pondérations des modèles. De nombreuses bibliothèques côté client permettent également d'affiner et d'entraîner des modèles. |
Pourquoi avez-vous attribué une étoile à la personnalisation ?Les services gérés exposent des modèles puissants, mais offrent un contrôle minimal sur leur comportement interne. La personnalisation est généralement limitée à l'invite et au contexte d'entrée. |
Pourquoi 5 étoiles pour la personnalisation ?Les modèles auto-hébergés offrent un contrôle total sur les pondérations des modèles, les données d'entraînement, le réglage fin et la configuration du déploiement. |
| Justesse |
Pourquoi avez-vous attribué deux étoiles pour l'exactitude ?La précision des modèles intégrés est suffisante pour les tâches bien définies, mais la taille et la généralisation limitées des modèles réduisent la fiabilité pour les entrées complexes ou nuancées. |
Pourquoi la précision est-elle évaluée à trois étoiles ?La précision des modèles personnalisés côté client peut être améliorée lors du processus de sélection des modèles. Toutefois, elle reste limitée par la taille du modèle, la quantification et la variabilité du matériel client. |
Pourquoi 5 étoiles pour la précision ?Les services gérés offrent généralement une précision relativement élevée, grâce à des modèles volumineux, à des données d'entraînement étendues et aux améliorations continues apportées par le fournisseur. |
Pourquoi 4 étoiles pour la précision ?La précision peut être élevée, mais dépend du modèle sélectionné et de l'effort d'optimisation. Les performances peuvent être inférieures à celles des services gérés. |
| Latence du réseau |
Pourquoi 5 étoiles pour la latence du réseau ?Le traitement a lieu directement sur l'appareil de l'utilisateur. |
Pourquoi deux étoiles pour la latence du réseau ?Il y a un aller-retour vers un serveur. |
||
| Confidentialité |
Pourquoi cinq étoiles pour la confidentialité ?Les données utilisateur doivent rester sur l'appareil par défaut, ce qui minimise l'exposition des données et simplifie la conformité en matière de confidentialité. |
Pourquoi avez-vous attribué deux étoiles à la confidentialité ?Les entrées utilisateur doivent être envoyées à des serveurs externes, ce qui augmente l'exposition des données et les exigences de conformité. Toutefois, il existe des solutions spécifiques pour atténuer les problèmes de confidentialité, comme Private AI Compute. |
Pourquoi trois étoiles pour la confidentialité ?Les données restent sous le contrôle de votre organisation, mais quittent l'appareil de l'utilisateur. Elles nécessitent donc des mesures de conformité et de gestion sécurisée. |
|
| Coût fixe |
Pourquoi 5 étoiles pour les coûts fixes ?Les modèles s'exécutent sur les appareils existants des utilisateurs, ce qui évite des coûts d'infrastructure supplémentaires. |
Pourquoi 5 étoiles pour les coûts fixes ?La plupart des API facturent en fonction de l'utilisation. Il n'y a donc pas de coût fixe. |
Pourquoi deux étoiles pour le coût fixe ?Les coûts fixes incluent l'infrastructure, la maintenance et les frais généraux opérationnels. |
|
| Coût par requête |
Pourquoi 5 étoiles pour le coût par demande ?Aucun coût par requête n'est appliqué, car l'inférence s'exécute sur l'appareil de l'utilisateur. |
Pourquoi deux étoiles pour le coût par demande ?Les services gérés ont généralement une tarification par requête. Les coûts de scaling peuvent devenir importants, en particulier en cas de volumes de trafic élevés. |
Pourquoi trois étoiles pour le coût par demande ?Aucun coût direct par requête. Le coût effectif par requête dépend de l'utilisation de l'infrastructure. |
|
| Compatibilité |
Pourquoi la compatibilité est-elle évaluée à deux étoiles ?La disponibilité varie selon le navigateur et l'appareil, ce qui nécessite des solutions de secours pour les environnements non compatibles. |
Pourquoi une étoile pour la compatibilité ?La compatibilité dépend des capacités matérielles et de la prise en charge de l'exécution, ce qui limite la couverture sur les appareils. |
Pourquoi cinq étoiles pour la compatibilité ?Les plates-formes côté serveur sont largement compatibles pour tous les utilisateurs, car l'inférence se produit côté serveur et les clients ne consomment qu'une API. |
|
| Commodité pour l'utilisateur |
Pourquoi 3 étoiles pour la facilité d'utilisation ?Une fois disponible, l'IA intégrée est généralement transparente, mais elle nécessite un téléchargement initial du modèle et la compatibilité du navigateur. |
Pourquoi deux étoiles pour la facilité d'utilisation ?Les utilisateurs peuvent rencontrer des retards en raison de téléchargements ou de matériel non compatible. |
Pourquoi 4 étoiles pour la facilité d'utilisation ?Il fonctionne immédiatement, sans téléchargement ni exigences concernant l'appareil, ce qui offre une expérience utilisateur fluide. Toutefois, il peut y avoir un décalage si la connexion réseau est faible. |
|
| Commodité pour les développeurs |
Pourquoi 5 étoiles pour la commodité des développeurs ?L'IA intégrée nécessite une configuration minimale, aucune infrastructure et peu d'expertise en IA, ce qui la rend facile à intégrer et à gérer. |
Pourquoi deux étoiles pour la commodité des développeurs ?Nécessite la gestion des modèles, des runtimes, de l'optimisation des performances et de la compatibilité entre les appareils. |
Pourquoi 4 étoiles pour la facilité d'utilisation par les développeurs ?Les services gérés simplifient le déploiement et le scaling. Toutefois, ils nécessitent toujours une intégration d'API, une gestion des coûts et une ingénierie des requêtes. |
Pourquoi une note de 1 étoile pour la commodité du développeur ?Un déploiement personnalisé côté serveur exige une expertise considérable en matière d'infrastructure, de gestion des modèles, de surveillance et d'optimisation. |
| Effort de maintenance |
Pourquoi 4 étoiles pour la charge de travail requise en matière de maintenance ?Les navigateurs gèrent les mises à jour et l'optimisation des modèles, mais les développeurs doivent s'adapter aux changements de disponibilité. |
Pourquoi avez-vous attribué deux étoiles à l'effort de maintenance ?Nécessite des mises à jour continues pour les modèles, l'optimisation des performances et la compatibilité à mesure que les navigateurs et les appareils évoluent. |
Pourquoi 5 étoiles pour la charge de travail requise en matière de maintenance ?La maintenance est gérée par le fournisseur. |
Pourquoi avez-vous attribué deux étoiles à l'effort de maintenance ?Nécessite une maintenance continue, y compris les mises à jour des modèles, la gestion de l'infrastructure, le scaling et la sécurité. |
Analyser les compromis
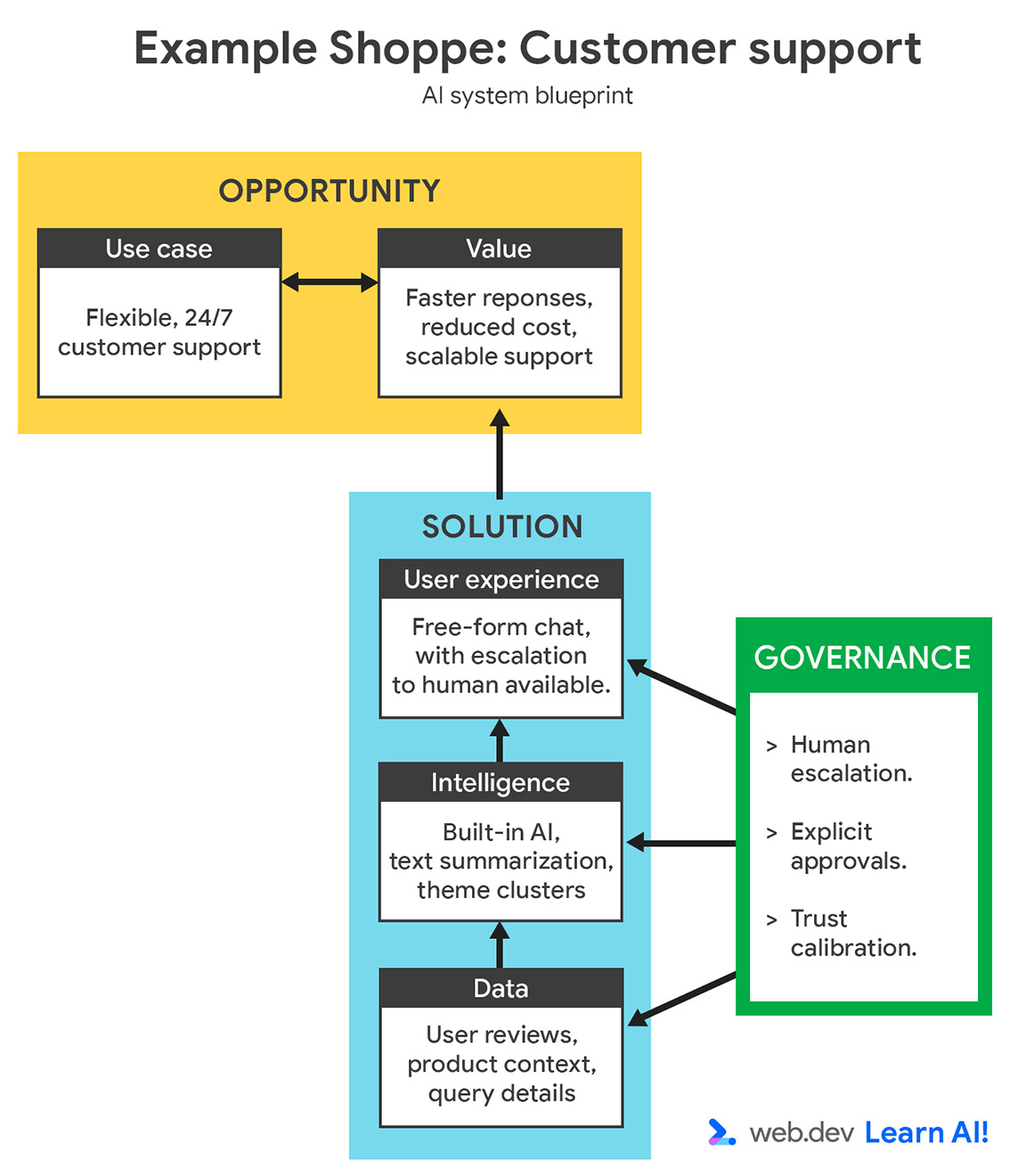
Pour illustrer le processus de prise de décision, nous allons ajouter une autre fonctionnalité à Example Shoppe, une plate-forme d'e-commerce de taille moyenne. Vous souhaitez réduire les coûts du service client en dehors des heures d'ouverture. Vous décidez donc de créer un assistant optimisé par l'IA pour répondre aux questions des utilisateurs sur les commandes, les retours et les produits.
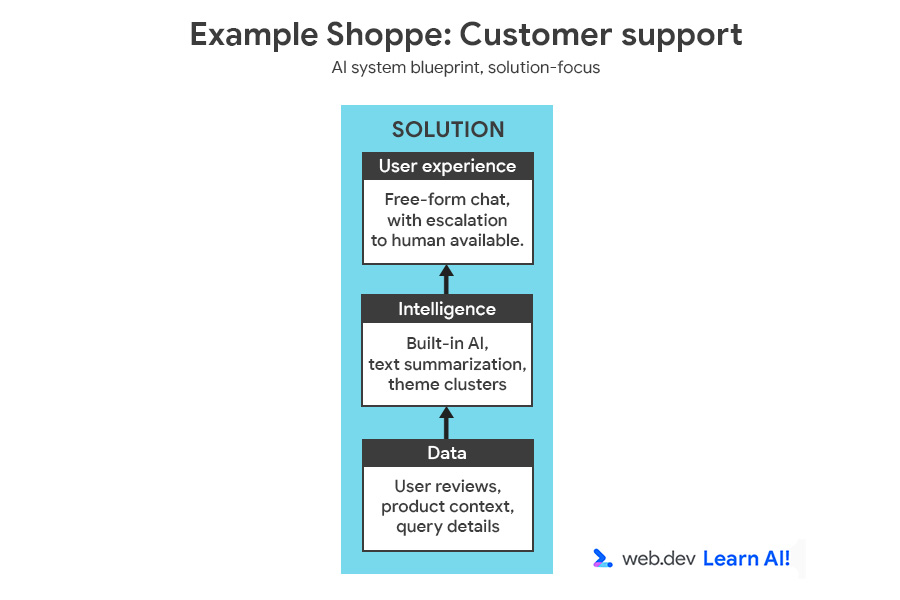
Vous pouvez consulter le schéma complet du système d'IA, qui présente l'opportunité et la solution.
{kind=link}
Analysez le scénario en utilisant deux angles : les exigences du cas d'utilisation et les contraintes de l'entreprise ou de l'équipe.
| Exigence | Analyse | Critères | Implication |
| Haute précision et polyvalence | Les utilisateurs posent des questions complexes sur les commandes, les produits et les retours. | Puissance et précision du modèle | Nécessite un grand modèle de langage (LLM). |
| Spécificité des données | Il doit répondre à des questions spécifiques aux données, aux produits et aux règles de l'entreprise. | Possibilité de personnalisation | Nécessite l'ingestion de données, comme RAG, mais pas l'affinage du modèle. |
| Exigence | Analyse | Critères | Implication |
| Base d'utilisateurs | Des centaines de milliers d'utilisateurs. | Évolutivité, compatibilité | Nécessite une architecture capable de gérer un trafic élevé et fiable. |
| Priorités post-lancement | L'équipe passera à d'autres projets après le lancement de la version 1. | Charge de travail requise pour la maintenance | Vous avez besoin d'une solution qui nécessite un minimum de maintenance continue. |
| Expertise de l'équipe | Développeurs Web expérimentés, expertise limitée en IA/ML | Commodité pour les développeurs | La solution doit être facile à déployer et à intégrer sans compétences spécialisées en IA. |
Maintenant que vous avez hiérarchisé vos critères, vous pouvez consulter le tableau d'estimation des compromis pour déterminer quelle plate-forme correspond à vos critères les plus importants :
Il ressort clairement de cette répartition que vous devez utiliser l'IA côté serveur, et probablement un service géré. Il s'agit d'un modèle polyvalent pour les questions complexes des clients. Il minimise les efforts de maintenance et de développement en déchargeant l'infrastructure, la qualité des modèles et le temps d'activité sur le fournisseur.
Bien que la personnalisation soit limitée, cela reste un compromis intéressant pour une équipe de développement Web ayant une expérience limitée en ingénierie de modèles.
Une configuration de génération augmentée par récupération (RAG) peut vous aider à fournir le contexte approprié au modèle au moment de l'inférence.
IA hybride
Les systèmes d'IA matures fonctionnent rarement sur une seule plate-forme ou avec un seul modèle. Elles distribuent plutôt les charges de travail d'IA pour optimiser les compromis.
Identifier les opportunités d'IA hybride
Une fois que vous avez lancé votre application, vous devez affiner vos exigences en fonction des données et des commentaires réels. Dans notre exemple, Example Shoppe, vous attendez quelques mois pour analyser les résultats et vous constatez ce qui suit :
- Environ 80 % des demandes sont répétitives ("Où est ma commande ?", "Comment renvoyer cet article ?"). L'envoi de ces requêtes à un service géré génère beaucoup de surcharge et de coûts.
- Seules 20 % des demandes nécessitent un raisonnement plus approfondi et une conversation interactive et ouverte.
Un modèle local léger pourrait classer les entrées utilisateur et répondre aux requêtes de routine, comme "Quelles sont vos conditions de retour ?" Vous pouvez acheminer les questions complexes, rares ou ambiguës vers le modèle côté serveur.
En implémentant l'IA côté serveur et côté client, vous pouvez réduire les coûts et la latence, tout en conservant l'accès à un raisonnement puissant lorsque cela est nécessaire.
Distribuer la charge de travail
Pour créer ce système hybride pour Example Shoppe, vous devez commencer par définir le système par défaut. Dans ce cas, il est préférable de commencer côté client. L'application doit être redirigée vers l'IA côté serveur dans deux cas :
- Solution de secours basée sur la compatibilité : si l'appareil ou le navigateur de l'utilisateur ne peuvent pas traiter la demande, ils doivent revenir au serveur.
- Escalade basée sur les capacités : si la requête est trop complexe ou trop ouverte pour le modèle côté client, selon des critères prédéterminés, elle doit être escaladée vers un modèle côté serveur plus grand. Vous pouvez utiliser un modèle pour classer la requête comme courante (et effectuer la tâche côté client) ou comme inhabituelle (et envoyer la requête au système côté serveur). Par exemple, si le modèle côté client détermine que la question est liée à un problème peu courant, comme l'obtention d'un remboursement dans une autre devise.
La flexibilité introduit plus de complexité
La répartition des charges de travail entre deux plates-formes vous offre plus de flexibilité, mais ajoute également de la complexité :
- Orchestration : deux environnements d'exécution impliquent plus de composants mobiles. Vous avez besoin d'une logique pour le routage, les nouvelles tentatives et les solutions de repli.
- Gestion des versions : si vous utilisez le même modèle sur plusieurs plates-formes, il doit rester compatible dans les deux environnements.
- Ingénierie des requêtes et ingénierie du contexte : si vous utilisez différents modèles sur chaque plate-forme, vous devez effectuer l'ingénierie des requêtes pour chacun d'eux.
- Surveillance : les journaux et les métriques sont divisés et nécessitent un effort supplémentaire pour être unifiés.
- Sécurité : vous gérez deux surfaces d'attaque. Les points de terminaison locaux et cloud doivent être renforcés.
Il s'agit d'un autre compromis à prendre en compte. Si votre équipe est petite ou si vous développez une fonctionnalité non essentielle, vous n'aurez peut-être pas envie d'ajouter cette complexité.
Vos points à retenir
Attendez-vous à ce que votre choix de plate-forme évolue. Commencez par le cas d'utilisation, alignez-vous sur l'expérience et les ressources de votre équipe, et itérez à mesure que votre produit et votre maturité en matière d'IA évoluent. Votre tâche consiste à trouver le bon équilibre entre vitesse, confidentialité et contrôle pour vos utilisateurs, puis à créer votre application avec une certaine flexibilité. Vous pouvez ainsi vous adapter aux exigences changeantes et bénéficier des futures mises à jour de la plate-forme et du modèle.
Ressources
- Le choix de la plate-forme et du modèle étant interdépendants, consultez Sélection de modèles pour en savoir plus.
- Découvrez comment aller au-delà du cloud avec l'IA hybride et côté client.
Vérifier que vous avez bien compris
Quels sont les deux principaux facteurs à prendre en compte lorsque vous choisissez une plate-forme d'IA pour votre application ?
Quand un service géré côté serveur, comme Gemini Pro, est-il le meilleur choix pour votre plate-forme ?
Quel est le principal avantage de l'implémentation d'un système d'IA hybride ?