
الذكاء الاصطناعي التوقّعي (أو التحليلي) هو مجموعة من الخوارزميات التي تساعدك في فهم البيانات الحالية والتنبؤ بما سيحدث على الأرجح في المستقبل. استنادًا إلى الأنماط السابقة، تتعلّم نماذج الذكاء الاصطناعي التوقّعية مهام تحليلية مختلفة تساعد المستخدمين على فهم بياناتهم:
- التصنيف: تجميع العناصر في فئات محدّدة مسبقًا استنادًا إلى الأنماط في البيانات على سبيل المثال، قد يصنّف متجر على الإنترنت الزوّار حسب النية (البحث، الشراء، المرتجعات)، حتى يتمكّن من تعديل اقتراحاته وفقًا لذلك.
- الانحدار: توقّع القيم الرقمية، مثل معدّل التفاعل أو مدة الجلسة أو احتمال الإحالة الناجحة
- الاقتراح: يشير إلى اقتراح عناصر ذات صلة بالمستخدم أو السياق. يمكنك التفكير في "المستخدمون الذين يشبهونك شاهدوا أيضًا" أو "برامج تعليمية مقترَحة استنادًا إلى مستوى تقدّمك".
- التوقّع ورصد الحالات الشاذة: يتوقّع النموذج الأحداث المستقبلية، مثل ارتفاع عدد الزيارات بشكل كبير، أو يرصد السلوك غير المعتاد، مثل الحالات الشاذة في الدفع أو الاحتيال.
تم تصميم بعض المنتجات بالكامل استنادًا إلى الذكاء الاصطناعي التوقعي، مثل أدوات استكشاف الموسيقى. في حالات أخرى، يحسّن الذكاء الاصطناعي التوقعي تجربة محددة، مثل موقع إلكتروني لبث المحتوى يتضمّن اقتراحات مخصّصة. يمكن أن يكون الذكاء الاصطناعي القائم على التوقّعات أيضًا أداة داخلية فعّالة: يمكنك استخدامه لتحليل بيانات المنتجات والمستخدمين من أجل الكشف عن الإحصاءات وتوجيه الإجراءات الذكية التالية.
حلقة الذكاء الاصطناعي التوقّعي
يتّبع تطوير نظام تنبؤي يعمل بالذكاء الاصطناعي دورة متكررة تتضمّن الخطوات التالية: تحديد فرصتك، وإعداد بياناتك، وتدريب النموذج، وتقييم النموذج، ونشر النموذج.
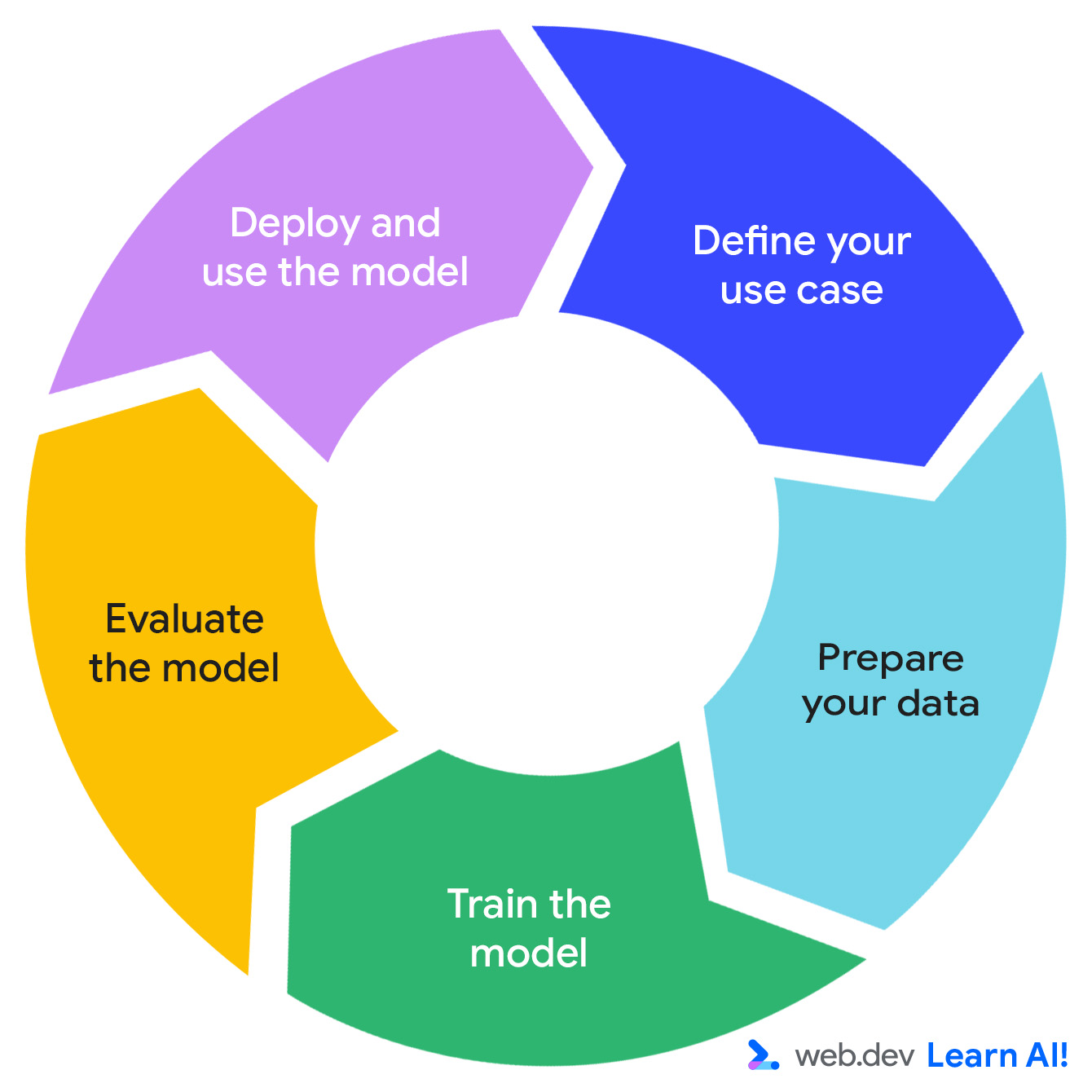
لنفترض أنّك تعمل على تطبيق إنتاجية يستند إلى الاشتراك، وهو Do All The Things. تجمع حاليًا بيانات الاستخدام، مثل عدد مرّات مشاهدة الصفحة ومدّة الجلسة واستخدام الميزات وتجديد الاشتراكات. الآن، تريد استخراج قيمة أكبر قابلة للاستخدام من البيانات. إليك كيفية التنقّل في حلقة الذكاء الاصطناعي التوقّعي.
تحديد حالة الاستخدام
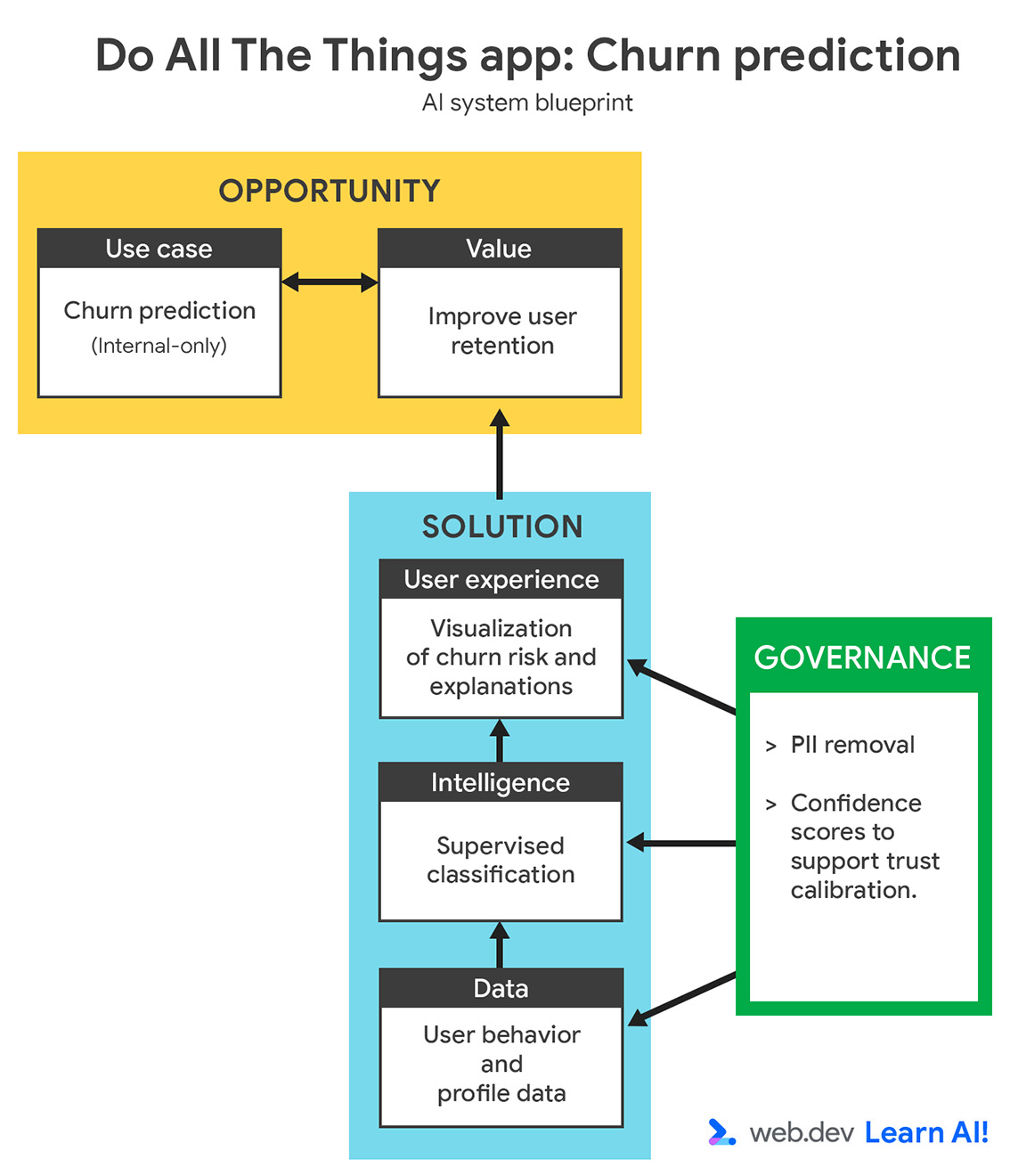{kind=link}
ارتفع معدّل توقّف العملاء عن استخدام الخدمة خلال الأشهر الثلاثة الماضية. بدلاً من التفاعل مع المستخدمين بعد إلغاء اشتراكاتهم، عليك استخدام الذكاء الاصطناعي التوقّعي لتحديد المستخدمين الذين من المحتمل أن يتوقفوا عن استخدام التطبيق قبل إلغاء اشتراكاتهم. والهدف من ذلك هو تقديم إشارات مبكرة لفريق نجاح العملاء، ما يتيح له اتّخاذ إجراءات استباقية موجّهة للاحتفاظ بالمستخدمين المعرّضين للخطر.
عند تحديد حالة استخدام للذكاء الاصطناعي التوقعي، ابدأ بالتحقّق من إمكانية الإجابة عن السؤال باستخدام البيانات. يمكن أن تكون هذه البيانات هي البيانات التي سبق أن جمعتها أو البيانات التي يمكنك جمعها بشكل واقعي من الآن فصاعدًا. تتطلّب هذه الخطوة غالبًا التعاون مع خبراء في المجال، مثل فِرق نجاح العملاء أو النمو أو التسويق، لضمان أن تكون التوقعات مفيدة وقابلة للتنفيذ.
يجب أن يحدّد تعريف المشكلة القوي ما يلي:
- الهدف: ما هي النتيجة التجارية التي تحاول التأثير فيها؟ على سبيل المثال، تريد تقليل معدّل توقّف العملاء عن استخدام الخدمة من خلال التواصل الاستباقي معهم.
- بيانات الإدخال: ما هي الإشارات السابقة التي يتعلّم منها النموذج؟ على سبيل المثال، يمكنك تقديم أنماط الاستخدام وأنواع الخطط وتفاعلات الدعم.
- النتيجة: ما الذي سينتجه النموذج؟ على سبيل المثال، تريد أن ينشئ النموذج نتيجة احتمالية التوقّف عن الاستخدام لكل مستخدم.
- المستخدم: مَن يستخدم التوقّع أو يتّخذ إجراءً استنادًا إليه؟ على سبيل المثال، هذه البيانات مخصّصة لمدراء نجاح العملاء.
- معايير النجاح: كيف تقيس التأثير؟ على سبيل المثال، يمكنك قياس معدّل الاحتفاظ بالمستخدمين لتحديد ما إذا كنت قد خفّضت معدّل إيقاف الاستخدام.
من خلال تحديد هذه التفاصيل في البداية، يمكنك تجنُّب خطأ شائع: إنشاء نموذج مخصّص سليم من الناحية الفنية، ولكن لا يتم استخدامه أبدًا.
إعداد البيانات
لتزويد النموذج بإشارات تعلّم مفيدة، عليك تصنيف بياناتك السابقة باستخدام التوقّعات المثالية. صنِّف مستخدمي Do All The Things على أنّهم "توقّفوا عن استخدام الخدمة" أو "لم يتوقّفوا عن استخدام الخدمة".
بعد ذلك، تعاون مع فريق نجاح العملاء لتحديد الميزات السلوكية الأكثر صلة بتوقّع معدّل توقّف العملاء عن استخدام الخدمة. ضيِّق نطاق مجموعة البيانات لتشمل هذه الميزات الرئيسية، وأزِل الحقول غير الضرورية حتى لا يضطر النموذج إلى التعامل مع التشويش. يُرجى مراعاة خصوصية البيانات. إزالة المعلومات التي تكشف الهوية الشخصية، مثل الأسماء أو عناوين البريد الإلكتروني، وتخزين البيانات السلوكية المجمّعة فقط
يعرض الجدول التالي مقتطفًا من مجموعة البيانات الناتجة:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | مميّز | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | Google AI Pro | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | مجانًا | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | مميّز | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | Google AI Pro | 4.2 | 2 | 1 | 3 | 1 |
يمنح ذلك نموذجك مدخلات رقمية وفئوية واضحة (مثل plan_type أو avg_session_time) وتصنيفًا مستهدفًا واضحًا (churned). ويجب تحويل الفئات إلى معرّفات رقمية فريدة.
أخيرًا، قسِّم مجموعة البيانات إلى ثلاث مجموعات فرعية:
- مجموعة التدريب (عادةً ما تتراوح بين 70 و80%) لتعليم النموذج
- مجموعة التحقّق (تُعرف أحيانًا أيضًا باسم مجموعة التطوير) لضبط المَعلمات الفائقة ومنع الإفراط في التكيّف
- مجموعة الاختبار لتقييم مستوى أداء النموذج على بيانات لم يسبق رؤيتها.
يساعد ذلك النموذج في تعميم القرارات بدلاً من الاعتماد على أمثلة سابقة محفوظة.
تدريب النموذج
على عكس الذكاء الاصطناعي التوليدي الذي غالبًا ما يستند إلى نماذج كبيرة مدرَّبة مسبقًا، تعتمد معظم أنظمة الذكاء الاصطناعي القائم على التوقعات على نماذج مدرَّبة ذاتيًا. ويرجع ذلك إلى أنّ المهام المستندة إلى التوقّعات تكون خاصة جدًا بمنتجك وبالمستخدمين. تسهّل أدوات مثل scikit-learn (Python) أو AutoML (بدون ترميز أو بترميز منخفض) أو TensorFlow.js (JavaScript) عملية تدريب نماذج تنبؤية وتقييمها بدون الحاجة إلى الاهتمام بالعمليات الحسابية الأساسية.
في مثالنا عن معدل توقّف العملاء عن استخدام الخدمة، نقدّم مجموعة التدريب التي تم تنظيفها إلى خوارزمية تصنيف خاضعة للإشراف، مثل الانحدار اللوجستي أو شبكة عصبية. جرِّب خيارات متعددة لتحديد الخيار الأنسب لبياناتك.
يتعلّم النموذج أنماط السلوك المرتبطة بتوقّف العملاء عن استخدام الخدمة. في النهاية، يمكنه تعيين درجة احتمالية لكل مستخدم. على سبيل المثال، هناك احتمال بنسبة% 72 أن يلغي المستخدم X اشتراكه في الشهر التالي.
بعد كل عملية تدريب، قيِّم النموذج الناتج باستخدام مجموعة التحقّق. يمكن تحسين أداء النموذج من خلال تعديل المَعلمات الفائقة، ولكن أيضًا من خلال إجراء تحسينات مستهدَفة على مجموعة البيانات.
تقييم النموذج
توفّر التصنيفات في مجموعة البيانات الحقيقة الأساسية التي يمكنك مقارنة نواتج النموذج بها. المقاييس الرئيسية التي يجب تتبُّعها هي:
- الدقة: من بين جميع المستخدمين الذين تم تصنيفهم على أنّهم "توقّفوا عن استخدام الخدمة"، كم عدد المستخدمين الذين توقّفوا عن استخدامها فعلاً؟
- الاسترجاع: من بين جميع المستخدمين الذين توقّفوا عن استخدام التطبيق، كم عدد المستخدمين الذين رصد النموذج توقّفهم؟
- مقياس F1: هو رقم واحد يوازن بين الدقة والتذكّر، ويكون مفيدًا عندما تريد مقياسًا إجماليًا للدقة بدون تحسين أحدهما بشكل مفرط على حساب الآخر.
يؤدي العدد الكبير جدًا من النتائج الإيجابية الخاطئة إلى إهدار الجهود المبذولة للاحتفاظ بالعملاء، بينما يؤدي العدد الكبير جدًا من النتائج السلبية الخاطئة إلى خسارة العملاء. يعتمد التوازن الصحيح على أولويات نشاطك التجاري. على سبيل المثال، قد تفضّل شركتك التعامل مع بعض الإنذارات الكاذبة إذا كان ذلك يزيد من احتمالية جذب المزيد من المستخدمين قبل مغادرتهم.
تفعيل النموذج والحفاظ عليه
بعد التحقّق من صحة النموذج، يمكنك نشره باستخدام واجهة برمجة تطبيقات أو كخدمة بسيطة من جهة العميل مدمجة في لوحة بيانات الإحصاءات. ويمكنه كل يوم تسجيل نقاط للمستخدمين وتعديل عرض مرئي لمخاطر إلغاء الاشتراك، ما يتيح لفريقك تحديد أولويات التواصل. للحفاظ على دقة النموذج وموثوقيته، اتّبِع الدروس التالية من فِرق عمليات تعلُّم الآلة (MLOps):
- مراقبة انحراف البيانات: رصد الحالات التي يتغيّر فيها سلوك المستخدمين وتصبح فيها بيانات التدريب غير ممثّلة للواقع.
- على سبيل المثال، بعد إطلاق عملية إعادة تصميم رئيسية لواجهة المستخدم، يتفاعل المستخدمون مع الميزات بشكل مختلف، ما يؤدي إلى انخفاض دقة توقّعات معدّل التوقّف عن الاستخدام.
- التعلم من الأخطاء: حدِّد الأنماط الشائعة التي تؤدي إلى التوقعات الخاطئة وأضِف أمثلة مستهدَفة لتحسين دورة التدريب التالية.
- على سبيل المثال، يصنّف النموذج المستخدمين المتقدّمين بشكل متكرّر على أنّهم معرّضون لخطر التوقّف عن استخدام الخدمة لأنّهم يرسلون العديد من طلبات الدعم. بعد المراجعة، أضِف ميزات جديدة تميّز تحديد المشاكل وحلّها عن عدم التفاعل.
- إعادة التدريب بانتظام: حتى إذا بدا الأداء ثابتًا، أعِد تدريب النموذج بشكل دوري لمراعاة الأنماط الموسمية أو تحديثات المنتجات أو التغييرات في الأسعار.
- على سبيل المثال، يمكنك إعادة تدريب النموذج بعد طرح خطط سنوية، لأنّ هيكل الأسعار يغيّر طريقة تصرّف المستخدمين قبل التجديد.
تشكّل دورة الحياة هذه أساس الذكاء الاصطناعي التنبؤي. باستخدام أدوات مثل MLflow وWeights & Biases، يمكنك تنفيذ هذه العملية بدون الحاجة إلى خبرة كبيرة في تعلُّم الآلة.
المشاكل الشائعة وطرق حلّها
على الرغم من حدوث أخطاء عرضية، يمكنك الحماية من الأسباب الجذرية الشائعة التي يمكن أن تقوّض الأداء وثقة المستخدمين، وذلك من خلال اتّخاذ الإجراءات التالية:
- البيانات المنخفضة الجودة: إذا كانت بيانات الإدخال غير دقيقة أو غير مكتملة، ستكون التوقعات كذلك. للتخفيف من حدة هذه المشكلة، يمكنك عرض بياناتك والتحقّق من صحتها قبل بدء التدريب. تأكَّد من توفّر إشارات التعلّم المطلوبة والتعامل مع القيم الناقصة. مراقبة جودة البيانات في مرحلة الإنتاج
فرط التخصيص: يعمل النموذج بشكل جيد جدًا على بيانات التدريب، ولكنّه لا ينجح في الحالات الجديدة. للتخفيف من هذا التأثير، استخدِم التحقّق المتبادل والتسوية ومجموعات بيانات الاحتفاظ. يساعد ذلك النموذج في التعميم إلى ما هو أبعد من أمثلة التدريب.
تغيُّر البيانات: يتغيّر سلوك المستخدمين وبيئاتهم، ولكن نموذجك لا يتغيّر. للتخفيف من هذه المشكلة، يمكنك جدولة إعادة التدريب وإضافة ميزة المراقبة لرصد انخفاض الدقة.
المقاييس السيئة: لا تعكس الدقة الإجمالية دائمًا أولويات المستخدمين. على سبيل المثال، في بعض الأحيان، تكون "تكلفة" خطأ معيّن أكثر أهمية. في عملية رصد الاحتيال، يكون عدم رصد حالة احتيال (سالب خاطئ) أسوأ بكثير من الإبلاغ عن حالة بريئة (موجب خاطئ). للتخفيف من هذه المشكلة، يجب مواءمة المقاييس مع الأهداف الواقعية لرصد الاحتيال.
معظم هذه المشاكل ليست خطيرة. أطلِق نظامك تدريجيًا، وعالِج المشاكل عند ظهورها.
مفتاح هذا الأسلوب المرن والبسيط هو إمكانية المراقبة. يجب تحديد إصدارات لنماذجك وتسجيل خصائص الدقة والأدوات المستخدَمة لإنشاء النموذج وتتبُّع الأداء بمرور الوقت ومواصلة المراقبة النشطة. وعندما يحدث أي خلل أو خطأ، ستتمكّن من رصده وإصلاحه قبل أن يلاحظه المستخدمون.
الخلاصات الرئيسية
يحوّل الذكاء الاصطناعي التوقّعي بياناتك الحالية إلى معلومات استشرافية، ما يكشف عن النتائج المحتملة والإجراءات التي يجب اتّخاذها، وهو الشكل الأكثر واقعية وقابلية للقياس من الذكاء الاصطناعي. ركِّز على المشاكل المحدّدة جيدًا التي يمكن التعبير عنها في البيانات، وواصِل التكرار مع تطوّر منتجك، وراقِب الأداء بمرور الوقت.
في الوحدة التالية، ستتعرّف على الذكاء الاصطناعي التوليدي، الذي يساعدك في إنشاء محتوى جديد استنادًا إلى البيانات المتاحة.
الموارد
إذا كنت مهتمًا بفهم الرياضيات التي تستند إليها تكنولوجيات الذكاء الاصطناعي التوقعي، ننصحك بمراجعة المراجع التالية:
- دورات مكثّفة عن تعلّم الآلة في التصنيف والانحدار الخطي والانحدار اللوجستي
- كتبت مؤلفة الدورة التدريبية، "جانا ليبينكوفا"، المزيد حول موضوع الذكاء الاصطناعي التوقعي في الفصل 4 من كتاب فن تطوير منتجات الذكاء الاصطناعي: تحقيق قيمة تجارية.
- الذكاء الاصطناعي: أسلوب حديث من تأليف "ستيوارت جوناثان راسل" و"بيتر نورفيغ". تم نشر هذا الكتاب لأول مرة في عام 1995، وتم نشر أحدث إصدار منه في عام 2021. ويتم تدريسها عادةً في برامج هندسة الذكاء الاصطناعي.
- التعرّف على الأنماط وتعلُّم الآلة من تأليف كريستوفر إم. Bishop، وذلك لاتباعه نهجًا أكاديميًا وشاملاً للغاية في التعلّم من الذكاء الاصطناعي التوقعي.
التحقّق من فهمك
ما هي الوظيفة الأساسية للذكاء الاصطناعي التوقّعي؟
أيّ مهمة تتضمّن تصنيف العناصر إلى فئات محدّدة مسبقًا استنادًا إلى الأنماط؟
في "حلقة الذكاء الاصطناعي التوقّعية"، لماذا يجب تقسيم مجموعة البيانات إلى مجموعات تدريب وتحقّق واختبار؟
ما هو المقياس الذي يوازن بين الدقة والتذكّر لتقديم مقياس عام للدقة؟
ما هو الانحراف في البيانات، وكيف يمكن الحدّ منه؟