
تؤثر قراراتك المتعلقة بالتصميم بشكل مباشر في مسؤولية نظام الذكاء الاصطناعي وأمانه. على سبيل المثال، يمكنك تحديد كيفية اختيار مصادر البيانات أو ضبط سلوك النموذج أو عرض نتائج الذكاء الاصطناعي للمستخدمين. لهذه الخيارات عواقب حقيقية على المستخدمين وشركتك.
في هذه الوحدة، سنتناول ثلاثة جوانب أساسية لإدارة الذكاء الاصطناعي:
- الخصوصية: يجب التعامل مع البيانات بمسؤولية وتوضيح البيانات التي يتم جمعها وتقليل البيانات التي تغادر المتصفّح.
- الإنصاف: تحقَّق من نماذجك للتأكّد من عدم تضمّنها سلوكًا تمييزيًا (تحيّزًا)، وأنشئ حلقات تتيح للمستخدمين الإبلاغ عن المشاكل.
- الثقة والشفافية: صمِّم نظامك ليكون شفافًا وموثوقًا، كي يواصل المستخدمون الاستفادة منه على الرغم من عدم اليقين والأخطاء المحتملة.
بالنسبة إلى كل موضوع، نوضّح كيفية ظهوره في منتجات الذكاء الاصطناعي المختلفة. بعد ذلك، نقسّمها على ثلاث طبقات من حلّ الذكاء الاصطناعي: البيانات والذكاء وتجربة المستخدم. ستتعرّف على ما يجب الانتباه إليه وكيفية معالجة المشاكل وكيفية الحفاظ على إدارة فعّالة وبسيطة.
الخصوصية
لقد تبيّن لك أنّ بيانات الاستخدام والتفاعل الفعلية هي أساس أي نظام مستنِد إلى الذكاء الاصطناعي. تتيح البيانات التعلّم والتقييم والتحسين المستمر. تتيح لك ممارسات الخصوصية الجيدة الحفاظ على أمان هذه البيانات، كما تتيح للمستخدمين التحكّم في معلوماتهم.
تختلف توقعات الخصوصية بشكل كبير حسب منتجك وجمهورك. في المنتجات المخصّصة للمستهلكين، تميل التوقعات إلى حماية معلومات تحديد الهوية الشخصية (PII) للأفراد، مثل الأسماء والرسائل وسلوك التصفّح. في إعدادات المؤسسات، يتحوّل التركيز إلى سيادة البيانات وسرّيتها وحماية الملكية الفكرية.
تتطلّب القطاعات التي تؤثّر في موارد رزق الأشخاص أو رفاهيتهم، مثل الرعاية الصحية والتمويل والتعليم، ضمانات أكثر صرامة للحفاظ على الخصوصية مقارنةً بالمجالات الأقل خطورة، مثل الترفيه.
لنتعرّف على كيفية إدارة الخصوصية في مختلف مكونات نظام الذكاء الاصطناعي.
البيانات
لتحسين نظام الذكاء الاصطناعي بشكل مستمر، يمكنك جمع بيانات حول تفاعلات المستخدمين، بما في ذلك المدخلات والمخرجات والملاحظات والأخطاء. ويمكن إعادة استخدام هذه المعلومات في التقييم أو تحسين النماذج أو تقديم أمثلة قليلة في الطلبات. ويمكن أن تساعدك أيضًا في تصميم تجربة المستخدم.
في ما يلي بعض الإرشادات لجمع البيانات بشكل مسؤول:
- جمع البيانات اللازمة للتعلم فقط: قد لا تحتاج ميزة البحث عن المنتجات المستندة إلى الذكاء الاصطناعي إلى الملف الشخصي الكامل للمستخدم لتحسين النتائج. في معظم الحالات، يكفي تقديم طلب البحث وأنماط النقر وبيانات الجلسات المجهولة الهوية.
- إزالة المعلومات الحسّاسة: يجب إزالة جميع معلومات تحديد الهوية الشخصية قبل إرسال البيانات إلى النماذج الخارجية. يمكنك إجراء ذلك من خلال إخفاء الهوية أو استخدام أسماء مستعارة أو التجميع.
- الحدّ الأقصى لمدة الاحتفاظ بالبيانات: حذف السجلات والبيانات المخزّنة مؤقتًا بعد أن تؤدي الغرض منها تساهم دورات الاحتفاظ القصيرة بالبيانات في الحدّ من المخاطر بدون حظر الإحصاءات.
دوِّن المعلومات التي تجمعها ومدة الاحتفاظ بها وسبب الحاجة إليها. إذا لم تتمكّن من شرح تدفّقات البيانات بوضوح لمستخدم غير تقني، من المحتمل أن تكون التدفّقات معقّدة جدًا بحيث يصعب التحكّم فيها أو تبريرها.
المراقبة
عندما يتفاعل المستخدمون مع نظام الذكاء الاصطناعي، قد يدخلون معلومات خاصة أو حساسة بدون قصد أو عن غير قصد. ويزداد هذا الخطر بشكل خاص في واجهات المحادثة أو الكتابة المفتوحة، حيث لا يمكنك تقييد ما يكتبه المستخدمون.
على الرغم من أنّه قد يكون بإمكانك منع إرسال كلمات معيّنة، إلا أنّ هذه المعلومات قد تكون حساسة سياقيًا. إذا كان نموذجك يعمل على خادم تديره جهة خارجية، قد تعيد هذه الجهة استخدام مدخلات المستخدم كبيانات تدريب. وقد يكشف النموذج في النهاية عن أجزاء من نصوص خاصة أو بيانات اعتماد أو تفاصيل سرية أخرى للمستخدمين الآخرين.
إليك كيفية الحماية من انتهاكات الخصوصية أثناء الاستدلال:
يجب فحص واجهات برمجة التطبيقات التابعة لجهات خارجية بعناية. يجب أن تعرف بالضبط ما يحدث للبيانات التي ترسلها. هل يتم تسجيل المدخلات أو الاحتفاظ بها أو إعادة استخدامها لأغراض التدريب؟ تجنَّب الخدمات غير الشفافة، واحرص على التعامل مع مقدّمي الخدمات الذين يوفّرون سياسات وعناصر تحكّم شفافة.
إذا كنت تدرب النماذج أو تحسّنها بنفسك، عليك إخفاء التفاصيل الحساسة في بيانات التدريب. تجنَّب التعلّم بطريقة مختصرة. على سبيل المثال، في تطبيق لتقييم الجدارة الائتمانية، يمكن أن تؤدي الرموز البريدية إلى أن يضع النموذج افتراضات بشأن العِرق أو الحالة الاجتماعية والاقتصادية. ويمكن أن يؤدي ذلك إلى توقّعات غير عادلة وتعزيز أوجه عدم المساواة الحالية.
في المجالات الحساسة، يُفضّل الاستدلال من جهة العميل. ويمكن أن يتم ذلك باستخدام الذكاء الاصطناعي المضمّن، أو نموذج في المتصفّح، أو نموذج مخصّص من جهة العميل. يمكنك التعرّف على مزيد من المعلومات حول هذا الخيار في الوحدة التدريبية التالية، اختيار منصة.
تجربة المستخدم
توفّر واجهة تطبيقك فرصة لإظهار ما يحدث للمستخدمين وكسب ثقتهم ومنحهم التحكّم في بياناتهم:
- التحلّي بالشفافية: يمكن أن تساعدك التصنيفات القصيرة في واجهة المستخدم، مثل "تمت المعالجة محليًا" أو "تم الإرسال بشكل آمن لإجراء التحليل"، في بناء الثقة. ننصحك بإضافة ميزة الإفصاح التدريجي لعرض المزيد من التفاصيل، مثل تلميحات الأدوات التي توضّح الحالات التي يتم فيها إجراء التحليل على الجهاز بدلاً من الخادم.
- طرح السؤال في السياق طلب الموافقة عندما يكون ذلك مناسبًا إنّ السؤال "هل تريد مشاركة عمليات البحث السابقة لتحسين التوصيات؟" أكثر فائدة من الموافقة العامة.
- توفير عناصر تحكّم بسيطة: إضافة أزرار تبديل ظاهرة بوضوح لتفعيل التخصيص أو الميزات المستندة إلى السحابة الإلكترونية أو مشاركة البيانات
- منح إذن الوصول تضمين لوحة بيانات خصوصية صغيرة، حتى يتمكّن المستخدمون من إدارة بياناتهم بدون مغادرة التطبيق
- اشرح سبب جمع البيانات. قد يكون المستخدمون أكثر استعدادًا لمشاركة البيانات إذا فهموا كيفية استخدامها. وينطبق الأمر نفسه على سياسات الاحتفاظ بالبيانات وإدارتها.
الخصوصية في الذكاء الاصطناعي على الويب ليست خطوة واحدة للامتثال، بل هي طريقة تفكير مستمرة في التصميم:
- البيانات: جمع بيانات أقل وحماية أكبر
- الذكاء: الحدّ من حفظ البيانات التي يحتمل أن تكون حساسة من خلال النماذج الخارجية
- تجربة المستخدم: يجب أن تكون الخصوصية واضحة وقابلة للتحكّم من قِبل المستخدمين.
العدالة
يمكن أن تحمل أنظمة الذكاء الاصطناعي انحيازًا يؤدي إلى تمييز غير عادل. ويصدق ذلك بشكل خاص في مجالات مثل التوظيف والقانون والتمويل، حيث يمكن أن يؤدي التحيز إلى تشويه القرارات المهمة التي تؤثر بشكل مباشر في الأشخاص الحقيقيين.
على سبيل المثال، يمكن أن يربط نموذج توظيف تم تدريبه على بيانات توظيف سابقة بعض السمات الديمغرافية بجودة المرشحين المنخفضة، ما يؤدي إلى معاقبة المتقدمين من الفئات الممثلة تمثيلاً ناقصًا عن غير قصد، بدلاً من تقييم المهارات والخبرات ذات الصلة بالوظيفة.
البيانات
بيانات التدريب هي مجموعة من المعلومات المنفصلة التي يمكن أن تعكس تحيزات من العالم الحقيقي، بل وتتضمّن تحيزات جديدة. في ما يلي خطوات عملية لجعل التحيز المرتبط بالبيانات شفافًا وقابلاً للإدارة:
- توثيق مصادر البيانات ونطاق التغطية انشر بيانًا موجزًا لمساعدة المستخدمين على فهم أوجه القصور المحتملة في النموذج. على سبيل المثال، "تم تدريب هذا النموذج بشكل أساسي على محتوى باللغة الإنجليزية، مع تمثيل محدود للنصوص الفنية".
- إجراء عمليات فحص تشخيصية استخدِم اختبارات A/B للكشف عن الاختلافات المنهجية. على سبيل المثال، قارِن بين طريقة تعامل نظامك مع الجمل التالية: "She is a great leader" و"He is a great leader" و "They are a great leader". يمكن أن تشير الاختلافات البسيطة في المشاعر أو النبرة إلى تحيّز أعمق.
- تصنيف مجموعات البيانات أضِف بيانات وصفية بسيطة، مثل النطاق والمنطقة ومستوى الرسمية، لتسهيل عمليات التدقيق والفلترة وإعادة التوازن في المستقبل.
إذا كنت بصدد تدريب نماذج مخصّصة أو ضبطها بدقة، عليك تحقيق التوازن بين مجموعات البيانات. يؤدي التمثيل الأوسع نطاقًا إلى الحدّ من الانحراف بشكل أكثر فعالية من تصحيح التحيز بعد إنشاء النموذج.
المراقبة
في طبقة الذكاء، يتم تحويل التحيز إلى سلوك مكتسب. يمكنك إضافة ضمانات أو منطق إعادة ترتيب أو قواعد مختلطة لتوجيه النتائج نحو العدالة والشمولية:
- اختبار الانحياز بانتظام: استخدِم فلاتر رصد التحيز للإبلاغ عن الصياغة التي تتضمّن مشاكل، مثل رصد المصطلحات التي تشير إلى جنس معيّن أو الأسلوب الاستبعادي. مراقبة الانحراف بمرور الوقت
- بالنسبة إلى النماذج المستندة إلى التوقّعات، يجب توخّي الحذر عند استخدام البيانات الحسّاسة. يمكن أن تشفّر السمات، مثل الرمز البريدي أو التعليم أو الدخل، بشكل غير مباشر سمات حساسة، مثل العِرق أو الطبقة الاجتماعية.
- إنشاء ومقارنة نتائج متعدّدة: نرتب النتائج استنادًا إلى الحيادية والتنوّع والأسلوب، قبل تحديد النتيجة التي سنشاركها مع المستخدم.
- إضافة قواعد لفرض قيود الإنصاف على سبيل المثال، حظر المخرجات التي تعزّز الصور النمطية أو لا تمثّل أمثلة متنوعة.
تجربة المستخدم
في واجهة المستخدم، يجب أن تكون شفافًا بشأن طريقة استدلال النموذج وأن تشجّع المستخدمين على تقديم الملاحظات:
- توفير تفسيرات للنتائج التي تخرجها أدوات الذكاء الاصطناعي: على سبيل المثال، "يُنصح باستخدام أسلوب احترافي استنادًا إلى إدخالاتك السابقة*." يساعد ذلك المستخدمين في إدراك أنّ النظام يتّبع منطقًا محدّدًا، وليس حكمًا خفيًا.
- منح المستخدمين إمكانية تحكّم مفيدة: السماح لهم بتعديل سلوك النموذج من خلال الإعدادات أو الطلبات، مثل اختيار الإعدادات المفضّلة للأسلوب أو التعقيد أو النمط المرئي
- تسهيل الإبلاغ عن الانحياز أو عدم الدقة: كلما سهُل الإبلاغ عن مشكلة، زادت البيانات الواقعية التي ستحصل عليها لتحسين نظام الذكاء الاصطناعي.
- إنهاء التواصل بشأن الطلب: لا تدع تقارير المستخدمين تختفي. أدخِل هذه البيانات مرة أخرى في عملية إعادة التدريب أو منطق القواعد، وشارك مستوى التقدّم بشكل واضح: "عدّلنا عملية الإشراف للحدّ من التحيز الثقافي في الاقتراحات".
ينشأ التحيز في البيانات، ويتم تضخيمه من خلال النماذج، ويظهر في تجربة المستخدم. يمكنك معالجة هذه المشكلة على جميع مستويات نظام الذكاء الاصطناعي:
- البيانات: يجب أن تكون مصادر البيانات شفافة ومتوازنة.
- الذكاء: رصد التحيز في النتائج واختباره والحدّ منه
- تجربة المستخدم: يجب تمكين المستخدمين من تحديد التحيزات وتصحيحها من خلال توفير عناصر تحكّم وملاحظات.
الثقة والشفافية
تحدّد الثقة ما إذا كان المستخدمون سيستخدمون منتجك ويتبنّونه ويدافعون عنه.
يتوقّع معظم المستخدمين أن تكون التطبيقات قابلة للتوقّع. على سبيل المثال، تؤدي النقرات على الأزرار دائمًا إلى تنفيذ الإجراء المحدّد والانتقال إلى المكان نفسه. يخالف الذكاء الاصطناعي هذا التوقّع، لأنّ سلوكه متغيّر للغاية ولا يمكن التنبؤ به في كثير من الأحيان. بالإضافة إلى ذلك، تنطوي أنظمة الذكاء الاصطناعي على احتمال كامن لحدوث أخطاء: تتوهّم النماذج اللغوية حقائق، تُصنّف النماذج التنبؤية البيانات بشكل خاطئ، تخرج البرامج عن السيطرة.
المستخدمون هم خط الدفاع الأخير ضد هذه الأخطاء.
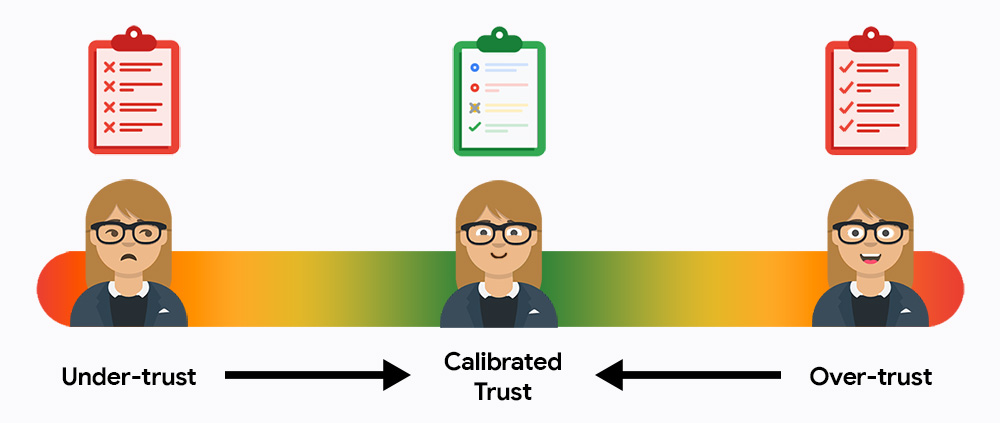
في البداية، من المحتمل أن يقلل المستخدمون من أهمية نظامك أو يبالغوا في تقديرها. فإذا كان مستوى الثقة منخفضًا، لن يستخدموا النظام، وإذا كان مرتفعًا، سيقبلون النتائج تمامًا بدون التحقّق من الأخطاء. مهمتك هي جذب المستخدمين إلى نقطة التوازن بين الثقة والمسؤولية، حيث يعتمدون على الذكاء الاصطناعي لتحقيق الكفاءة مع تحمّل مسؤولية النتائج النهائية.
البيانات
في طبقة البيانات، يتم بناء الثقة من خلال توضيح نطاق بياناتك ومصدرها بشكل واضح:
- توضيح مصدر البيانات وتسلسلها
- حداثة بيانات المستندات وقِدمها
- توضّح هذه البطاقة أنواع المحتوى الذي اطّلع عليه النموذج والمواضع التي قد يواجه فيها صعوبة، مثل البيانات غير الإنجليزية.
مع تراكم التفاعلات والملاحظات في نظام الذكاء الاصطناعي بمرور الوقت، ننصحك بالاحتفاظ بنسخ من البيانات مع تحديد إصداراتها، حتى تتمكّن من شرح كيفية تطوّر النتائج.
المراقبة
في طبقة الذكاء، يمكنك إدارة الثقة من خلال إمكانية التفسير ومؤشرات الثقة والتصميم المعياري:
- تقديم شروحات سياقية في الوقت المناسب: وفقًا لمفارقة المستخدم النشط، من الأفضل تضمين تفسيرات صغيرة في السياق مباشرةً في التفاعلات، ليتمكّن المستخدمون من فهم ما يفعله نظام الذكاء الاصطناعي أثناء استخدامه.
- توضيح القيود وحالات الأعطال المحتملة مسبقًا: أخبِر المستخدمين بمواضع الخطأ المحتملة لدى الذكاء الاصطناعي. على سبيل المثال، "تجنَّب استخدام الفكاهة أو المصطلحات الخاصة بمجال معيّن للحصول على نتائج أفضل". تقدّم الإشارات القصيرة حسب السياق الشفافية بدون مقاطعة تجربة المستخدم.
- تساعد مؤشرات الثقة ومنطق الاحتياط في الحفاظ على موثوقية الذكاء الاصطناعي في الحالات غير الواضحة. يمكنك تقدير مستوى الثقة من خلال مقاييس تقريبية، مثل احتمالية الحصول على نتائج جيدة أو معدلات النجاح السابقة. تحديد بدائل آمنة للنتائج التي تكون خاطئة بشكل واضح
- تساهم البُنى النموذجية في جعل الذكاء الاصطناعي أكثر شفافية. على سبيل المثال، إذا كان مساعد الكتابة يعالج القواعد والأسلوب والنبرة في خطوات منفصلة، يجب توضيح التغييرات التي تم إجراؤها في كل مرحلة: "النبرة: أقل رسمية، التعقيد: مبسط".
تجربة المستخدم
توفّر تجربة المستخدم مساحة واسعة لبناء الثقة وضبطها. في ما يلي بعض الأساليب والأنماط التي يمكنك تجربتها:
- تكييف المحتوى التعليمي: لا تفترض أنّ المستخدمين على دراية بالذكاء الاصطناعي. قدِّم إرشادات بسيطة للمستخدمين المتقدّمين وشروحات مفصّلة للمبتدئين.
- تطبيق الإفصاح التدريجي ابدأ بإشارات صغيرة. أدرِج نصًا يشير إلى أنّك استخدمت الذكاء الاصطناعي، مثل "تم إنشاء هذا المحتوى تلقائيًا"، واطلب من المستخدمين النقر للحصول على مزيد من المعلومات.
- إغلاق حلقات الملاحظات من خلال نتائج مرئية: عندما يقيّم المستخدمون اقتراحًا من الذكاء الاصطناعي أو يصحّحونه أو يتجاهلونه، شارِك معهم كيف ستؤثر مدخلاتهم في السلوك المستقبلي للذكاء الاصطناعي: "فضّلت الردود الموجزة. تم تعديل درجة الصوت وفقًا لذلك". يساهم مستوى الظهور في تحويل الملاحظات إلى ثقة.
- التعامل مع الأخطاء بشكل سليم: عندما يرتكب نظامك خطأً أو يعرض نتيجة غير دقيقة، عليك الاعتراف بذلك وتفويض المستخدم بمراجعتها. على سبيل المثال، "قد لا يتطابق هذا الاقتراح مع نيتك. يُرجى مراجعة الدبلجة قبل نشرها". قدِّم مسارًا واضحًا للمتابعة من خلال السماح للمستخدم بإعادة المحاولة أو التعديل أو الرجوع إلى خيار احتياطي آمن.
باختصار، لمعالجة حالة عدم اليقين والأخطاء المحتملة في الذكاء الاصطناعي، يجب توجيه المستخدمين من الشك أو الاعتماد المفرط إلى المعايرة السليمة للثقة:
- البيانات: يجب التحلي بالشفافية بشأن مصدر البيانات.
- الذكاء: جعل عملية الاستدلال نموذجية وقابلة للتفسير
- UX: تصميم يوفّر وضوحًا وتلقائية في تقديم الملاحظات.
الخلاصات الرئيسية
في هذه الوحدة، استكشفنا ثلاثة أركان أساسية للذكاء الاصطناعي المسؤول، وهي الخصوصية والعدالة والثقة. قد يبدو هذا الأمر مربكًا، خاصةً عندما تكون في بداية رحلتك أو تحاول الانتقال من النموذج الأوّلي إلى مرحلة الإنتاج.
ركِّز جهودك على المجالات الأكثر أهميةً وحدِّد طريقتك الخاصة في إدارة الذكاء الاصطناعي. التكرار هو مفتاح النجاح: سيساعدك كل إصدار وكل جولة من ملاحظات المستخدمين في فهم المجالات التي يحتاج فيها نظامك إلى المزيد من الضوابط أو الشفافية أو المرونة.
الموارد
في ما يلي بعض المراجع الأكثر تقدّمًا حول المواضيع الواردة في هذه الوحدة:
- تقدّم مقارنة بين سياسات الخصوصية والأمان في المساعدات المستندة إلى الذكاء الاصطناعي نظرة مفصّلة على سياسات الخصوصية المتعلّقة بالذكاء الاصطناعي.
- ورقة بحثية حول تذكُّر النماذج اللغوية الكبيرة، وهو وضع خطير لفشل الخصوصية حيث يحتفظ النموذج بمعلومات حساسة ومحدّدة من بيانات التدريب ويمكن أن يُطلب منه إعادة إنتاجها.
- راجِع المراجع المرتبطة مباشرةً بالنموذج الذي تختاره. على سبيل المثال، توفّر Google Cloud مراجع أمان.
- تقدّم مجموعة أدوات الذكاء الاصطناعي المسؤول مراجع للمطوّرين حول جميع المواضيع التي تناولناها في هذه الوحدة.
الموارد
في ما يلي بعض المراجع الأكثر تقدّمًا حول المواضيع الواردة في هذه الوحدة:
- تقدّم مقارنة بين سياسات الخصوصية والأمان في المساعدات المستندة إلى الذكاء الاصطناعي نظرة مفصَّلة على سياسات الخصوصية المتعلّقة بالذكاء الاصطناعي.
- ورقة بحثية حول تذكُّر النماذج اللغوية الكبيرة، وهو وضع خطير لفشل الخصوصية حيث يحتفظ النموذج بمعلومات حساسة ومحدّدة من بيانات التدريب ويمكن أن يُطلب منه إعادة إنتاجها.
- راجِع المراجع المرتبطة مباشرةً بالنموذج الذي تختاره. على سبيل المثال، توفّر Google Cloud موارد أمان.
- تقدّم مجموعة أدوات الذكاء الاصطناعي المسؤول موارد للمطوّرين حول جميع المواضيع التي تناولناها في هذه الوحدة.
اختبِر معلوماتك
ما هي ممارسة الخصوصية المقترَحة بشأن جمع البيانات لأغراض الذكاء الاصطناعي؟
ما المقصود بالثقة المعايرة؟
لضمان العدل في طبقة "الذكاء"، ما الإجراء الذي يمكن للمطوّرين اتخاذه؟
ما هي إحدى تقنيات تجربة المستخدم التي تساعد في بناء الثقة والشفافية؟