
تصمیمات طراحی شما مستقیماً مسئولیت و ایمنی سیستم هوش مصنوعی شما را شکل میدهند. به عنوان مثال، شما تصمیم میگیرید که چگونه منابع داده را انتخاب کنید، رفتار مدل را پیکربندی کنید یا خروجیهای هوش مصنوعی را به کاربران ارائه دهید. این انتخابها پیامدهای دنیای واقعی برای کاربران و شرکت شما دارند.
در این ماژول، ما سه بُعد حیاتی از مدیریت هوش مصنوعی را پوشش میدهیم:
- حریم خصوصی : دادهها را مسئولانه مدیریت کنید، آنچه جمعآوری میشود را توضیح دهید و آنچه از مرورگر خارج میشود را به حداقل برسانید.
- انصاف : مدلهای خود را از نظر رفتار تبعیضآمیز (سوگیری) بررسی کنید و حلقههایی بسازید که به کاربران اجازه دهد مشکلات را علامتگذاری کنند.
- اعتماد و شفافیت : سیستم خود را برای شفافیت و اعتماد سنجیده طراحی کنید، تا کاربران علیرغم عدم قطعیت و اشتباهات احتمالی، همچنان از آن بهرهمند شوند.
برای هر موضوع، توضیح میدهیم که چگونه در محصولات مختلف هوش مصنوعی نمود پیدا میکند. سپس، آن را در سه لایه از راهحل هوش مصنوعی شما تجزیه و تحلیل میکنیم: داده ، هوش و تجربه کاربری . شما یاد خواهید گرفت که مراقب چه چیزی باشید، چگونه به مسائل رسیدگی کنید و چگونه یک مدیریت مؤثر و سبک را حفظ کنید.
حریم خصوصی
شما آموختید که دادههای واقعی استفاده و تعامل، هسته اصلی هر سیستم هوش مصنوعی است. دادهها، یادگیری، ارزیابی و بهبود مستمر را تقویت میکنند. رویههای خوب حفظ حریم خصوصی به شما این امکان را میدهد که دادهها را ایمن نگه دارید، و همچنین به کاربران امکان کنترل اطلاعات خود را بدهید.
انتظارات مربوط به حریم خصوصی بسته به محصول و مخاطب شما بسیار متفاوت است. در محصولات مصرفی، انتظارات معمولاً شامل محافظت از اطلاعات شخصی قابل شناسایی افراد (PII)، مانند نامها، پیامها و رفتار مرور وب است. در محیطهای سازمانی، تمرکز به سمت حاکمیت دادهها، محرمانگی و حفاظت از مالکیت معنوی تغییر میکند.
بخشهایی که بر معیشت یا رفاه مردم تأثیر میگذارند، مانند مراقبتهای بهداشتی، مالی و آموزش، نسبت به حوزههای کمخطرتر، مانند سرگرمی، به حفاظتهای سختگیرانهتری در مورد حریم خصوصی نیاز دارند.
بیایید ببینیم چگونه میتوان حریم خصوصی را در اجزای مختلف سیستم هوش مصنوعی شما مدیریت کرد.
دادهها
برای بهبود مداوم سیستم هوش مصنوعی خود، میتوانید دادههایی در مورد تعاملات کاربر، از جمله ورودیها، خروجیها، بازخوردها و خطاها، جمعآوری کنید. این اطلاعات را میتوان برای ارزیابی، تنظیم دقیق مدل یا نمونههای کوتاه در دستورالعملها مجدداً استفاده کرد. همچنین میتواند در طراحی UX شما مؤثر باشد.
در اینجا چند دستورالعمل برای جمعآوری مسئولانه دادهها ارائه شده است:
- فقط آنچه را که برای یادگیری لازم است جمعآوری کنید . جستجوی محصول مبتنی بر هوش مصنوعی ممکن است برای بهبود نتایج به پروفایل کامل کاربر نیاز نداشته باشد. در بیشتر موارد، ارائه پرسوجو، الگوهای کلیک و دادههای ناشناس جلسه کافی است.
- اطلاعات حساس را حذف کنید . قبل از ارسال دادهها به مدلهای خارجی، تمام PII (اطلاعات شخصی قابل شناسایی) را حذف کنید. میتوانید این کار را با ناشناسسازی، مستعارسازی یا تجمیع انجام دهید.
- محدود کردن زمان نگهداری دادهها . لاگها و دادههای ذخیره شده را پس از اتمام کارشان حذف کنید. چرخههای نگهداری کوتاه، بدون مسدود کردن بینش، ریسک را کاهش میدهند.
اطلاعاتی که جمعآوری میکنید، مدت زمان نگهداری آنها و دلیل نیاز به آنها را مستند کنید. اگر نمیتوانید جریان دادههای خود را به طور واضح برای یک کاربر غیرفنی توضیح دهید، احتمالاً این جریانها برای کنترل یا توجیه بسیار پیچیده هستند.
هوش
وقتی کاربران با سیستم هوش مصنوعی شما تعامل میکنند، ممکن است ناآگاهانه یا از روی بیدقتی اطلاعات خصوصی یا حساس را وارد کنند. این خطر به ویژه در چتهای باز یا رابطهای نوشتاری که نمیتوانید نوع تایپ کاربران را محدود کنید، بسیار زیاد است.
اگرچه ممکن است بتوانید از ارسال برخی کلمات جلوگیری کنید، اما این اطلاعات ممکن است از نظر محتوایی حساس باشند. اگر مدل شما روی سروری اجرا شود که توسط یک ارائهدهنده خارجی مدیریت میشود، ممکن است از ورودی کاربر به عنوان دادههای آموزشی استفاده مجدد کند. در نهایت، مدل ممکن است بخشهایی از متن خصوصی، اعتبارنامهها یا سایر جزئیات محرمانه را برای سایر کاربران فاش کند.
در اینجا نحوه محافظت در برابر نقض حریم خصوصی در طول استنتاج آورده شده است:
API های شخص ثالث را با دقت بررسی کنید. شما باید دقیقاً بدانید که چه اتفاقی برای دادههایی که ارسال میکنید میافتد. آیا ورودیها ثبت، نگهداری یا برای آموزش دوباره استفاده میشوند؟ از خدمات مبهم اجتناب کنید و ارائه دهندگانی را ترجیح دهید که سیاستها و کنترلهای شفافی دارند.
اگر خودتان مدلها را آموزش میدهید یا تنظیم دقیق میکنید، از جزئیات حساس در دادههای آموزشی خود دور بمانید. مراقب یادگیری میانبر باشید. به عنوان مثال، در یک برنامه امتیاز اعتباری، کدهای پستی میتوانند مدل را به سمت فرضیاتی در مورد نژاد یا وضعیت اجتماعی-اقتصادی سوق دهند. این میتواند منجر به پیشبینیهای ناعادلانه و تقویت نابرابریهای موجود شود.
در حوزههای حساس، استنتاج سمت کلاینت را ترجیح دهید. این میتواند با هوش مصنوعی داخلی ، یک مدل در مرورگر یا یک مدل سمت کلاینت سفارشی باشد. در ماژول بعدی، انتخاب پلتفرم ، اطلاعات بیشتری در مورد این انتخاب کسب خواهید کرد.
تجربه کاربری
رابط کاربری برنامه شما فرصتی را برای نشان دادن اتفاقات به کاربران، جلب اعتماد آنها و دادن کنترل بر دادههایشان به آنها ارائه میدهد:
- شفاف باشید . برچسبهای کوتاه در رابط کاربری شما، مانند «پردازش محلی» یا «ارسال ایمن برای تجزیه و تحلیل»، میتوانند به شما در ایجاد اعتماد کمک کنند. برای جزئیات بیشتر، افشای تدریجی را در نظر بگیرید، مانند راهنماهایی که توضیح میدهند چه زمانی تجزیه و تحلیل روی دستگاه در مقابل سرور انجام میشود.
- در متن سوال کنید . در صورت مرتبط بودن، درخواست رضایت کنید. «آیا مایلید جستجوهای قبلی را برای بهبود توصیهها به اشتراک بگذارید؟» بسیار معنادارتر از یک انتخاب کلی است.
- کنترلهای ساده ارائه دهید . برای شخصیسازی، ویژگیهای مبتنی بر ابر یا اشتراکگذاری دادهها، دکمههای تغییر وضعیت واضح و قابل مشاهده اضافه کنید.
- قابلیت مشاهده را فراهم کنید . یک داشبورد کوچک برای حفظ حریم خصوصی در نظر بگیرید تا کاربران بتوانند بدون ترک برنامه، دادههای خود را مدیریت کنند.
- توضیح دهید که چرا دادهها را جمعآوری میکنید . اگر کاربران بدانند که دادهها چگونه استفاده خواهند شد، ممکن است برای به اشتراک گذاشتن آنها راحتتر باشند. همین امر در مورد سیاستهای نگهداری و مدیریت شما نیز صدق میکند.
حریم خصوصی در هوش مصنوعی وب، یک مرحلهی انطباق واحد نیست، بلکه یک طرز فکر طراحی مداوم است:
- دادهها : کمتر جمعآوری کنید و بیشتر محافظت کنید.
- هوشمندی: کاهش به خاطر سپردن دادههای بالقوه حساس توسط مدلهای خارجی.
- تجربه کاربری: حریم خصوصی را برای کاربران شفاف و قابل کنترل کنید.
انصاف
سیستمهای هوش مصنوعی میتوانند تعصباتی را به همراه داشته باشند که منجر به تبعیض ناعادلانه میشود. این امر به ویژه در حوزههایی مانند استخدام، قانون و امور مالی صادق است، جایی که تعصب میتواند تصمیمات حیاتی را که مستقیماً بر افراد واقعی تأثیر میگذارند، منحرف کند.
برای مثال، یک مدل استخدام که بر اساس دادههای استخدامی تاریخی آموزش دیده است، میتواند ویژگیهای جمعیتشناختی خاصی را با کیفیت پایینتر کاندیدا مرتبط کند و به جای ارزیابی مهارتها و تجربیات مرتبط با شغل، ناخواسته متقاضیان گروههای کمنمایندگیشده را جریمه کند.
دادهها
دادههای آموزشی شما مجموعهای از قطعات اطلاعاتی مجزا هستند که میتوانند سوگیریهای دنیای واقعی را منعکس کنند و حتی سوگیریهای جدیدی را معرفی کنند. در اینجا گامهای عملی برای شفافسازی و مدیریت سوگیریهای مرتبط با دادهها ارائه شده است:
- منابع و پوشش دادههای خود را مستند کنید . یک بیانیه کوتاه منتشر کنید تا به کاربران کمک کند بفهمند مدل در چه مواردی ممکن است نقص داشته باشد. به عنوان مثال، «این مدل در درجه اول بر اساس محتوای انگلیسی زبان آموزش دیده است و نمایش محدودی از متن فنی دارد.»
- بررسیهای تشخیصی را اجرا کنید . از آزمونهای A/B برای آشکار کردن تفاوتهای سیستماتیک استفاده کنید. برای مثال، مقایسه کنید که سیستم شما چگونه با «او رهبر بزرگی است»، «او رهبر بزرگی است» و «آنها رهبر بزرگی هستند» برخورد میکند. اختلافات کوچک در احساسات یا لحن میتواند نشاندهنده سوگیری عمیقتر باشد.
- مجموعه دادههای خود را برچسبگذاری کنید . فرادادههای سبک مانند دامنه، منطقه و سطح رسمیت را اضافه کنید تا ممیزیها، فیلتر کردن و متعادلسازی مجدد در آینده سادهتر شود.
اگر در حال آموزش یا تنظیم دقیق مدلهای سفارشی هستید، مجموعه دادههای خود را متعادل کنید. نمایش گستردهتر، چولگی را به طور مؤثرتری نسبت به اصلاح بایاس پس از ساخت مدل کاهش میدهد.
هوش
در لایه هوش، تعصب به رفتار آموختهشده تبدیل میشود. میتوانید با اضافه کردن تمهیدات حفاظتی، منطق رتبهبندی مجدد یا قوانین ترکیبی، خروجیها را به سمت انصاف و شمول هدایت کنید:
- مرتباً سوگیری را آزمایش کنید . از فیلترهای تشخیص سوگیری برای علامتگذاری عبارات مشکلساز، مانند تشخیص اصطلاحات جنسیتی یا لحن انحصاری، استفاده کنید. به مرور زمان، انحراف را زیر نظر داشته باشید.
- برای مدلهای پیشبینی، مراقب دادههای حساس باشید . ویژگیهایی مانند کد پستی، تحصیلات یا درآمد میتوانند به طور غیرمستقیم ویژگیهای حساسی مانند نژاد یا طبقه را رمزگذاری کنند.
- چندین خروجی تولید و مقایسه کنید . قبل از تعیین اینکه کدام خروجی را با کاربر به اشتراک بگذارید، نتایج را بر اساس بیطرفی، تنوع و لحن رتبهبندی کنید.
- قوانینی را برای اعمال محدودیتهای انصاف اضافه کنید . به عنوان مثال، مسدود کردن خروجیهایی که کلیشهها را تقویت میکنند یا نمیتوانند نمونههای متنوع را نشان دهند.
تجربه کاربری
در رابط کاربری خود، در مورد استدلال مدل شفاف باشید و بازخورد را تشویق کنید:
- برای خروجیهای هوش مصنوعی دلیل منطقی ارائه دهید . برای مثال، «بر اساس ورودیهای قبلی شما، لحن حرفهای توصیه میشود*.» این به کاربران کمک میکند تا ببینند که سیستم از منطق تعریفشده پیروی میکند، نه از قضاوت پنهان.
- به کاربران کنترل معناداری بدهید . به آنها اجازه دهید رفتار مدل را از طریق تنظیمات یا دستورالعملها تنظیم کنند - برای مثال، انتخاب لحن، پیچیدگی یا ترجیحات سبک بصری.
- گزارش سوگیری یا عدم دقت را آسانتر کنید . هرچه گزارش یک مشکل آسانتر باشد، دادههای واقعی بیشتری برای بهبود سیستم هوش مصنوعی خود دریافت خواهید کرد.
- حلقه بازخورد را ببندید . نگذارید گزارشهای کاربران ناپدید شوند. این دادهها را به منطق بازآموزی یا قوانین خود برگردانید و پیشرفت را به طور واضح به اشتراک بگذارید: «ما مدیریت خود را بهروزرسانی کردهایم تا سوگیری فرهنگی در توصیهها کاهش یابد.»
سوگیری در دادهها متولد میشود، از طریق مدلها تقویت میشود و در تجربه کاربری نمود پیدا میکند. میتوانید آن را در هر سه سطح سیستم هوش مصنوعی خود برطرف کنید:
- دادهها: منابع داده را شفاف و متعادل کنید.
- هوش: شناسایی، آزمایش و کاهش سوگیری در خروجیها.
- تجربه کاربری: کاربران را قادر میسازد تا از طریق کنترل و بازخورد، سوگیریها را شناسایی و اصلاح کنند.
اعتماد و شفافیت
اعتماد تعیین میکند که آیا مردم از محصول شما استفاده میکنند، آن را میپذیرند و از آن حمایت میکنند یا خیر.
بیشتر کاربران انتظار برنامههای قابل پیشبینی را دارند. برای مثال، کلیک روی دکمهها همیشه عمل مشخصشده را انجام میدهد و به همان مکان منتهی میشود. هوش مصنوعی این انتظار را نقض میکند، زیرا رفتار آن بسیار متغیر و اغلب غیرقابل پیشبینی است. علاوه بر این، سیستمهای هوش مصنوعی ذاتاً پتانسیل شکست دارند: مدلهای زبانی واقعیتها را توهم میکنند ، مدلهای پیشبینی دادهها را اشتباه برچسبگذاری میکنند و عاملها سرکش میشوند .
کاربران شما آخرین خط دفاعی در برابر این خطاها هستند.
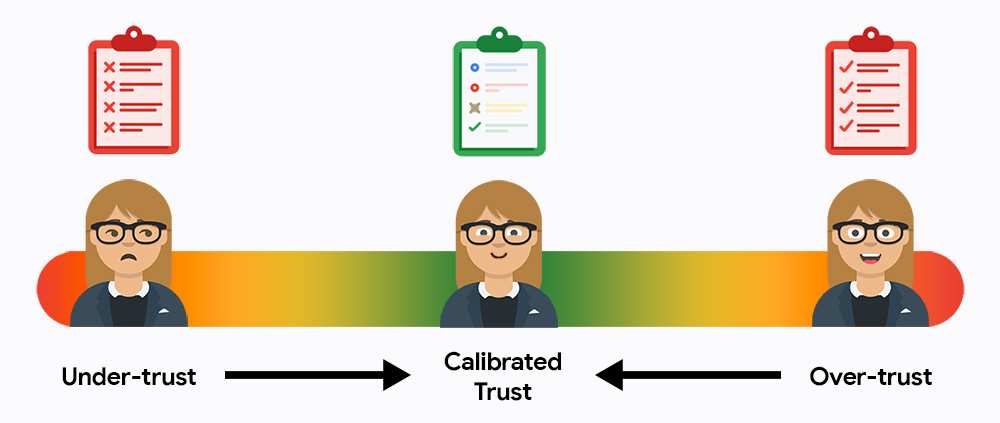
در ابتدا، کاربران احتمالاً به سیستم شما اعتماد کم یا بیش از حد دارند. اعتماد کم به این معنی است که آنها از سیستم استفاده نمیکنند و اعتماد بیش از حد به این معنی است که آنها خروجیها را کاملاً میپذیرند، بدون اینکه خطاها را بررسی کنند. وظیفه شما این است که کاربران را به میانه طلایی اعتماد کالیبره شده سوق دهید، جایی که آنها برای کارایی به هوش مصنوعی تکیه میکنند و در عین حال مسئولیت نتایج نهایی را بر عهده میگیرند.
دادهها
در لایه داده، اعتماد با توضیح واضح پوشش و منشأ دادههای شما ایجاد میشود:
- در مورد منشأ و تبار دادهها صریح باشید.
- تازگی و کهنگی دادههای سند.
- توضیح دهید که مدل چه نوع محتوایی را مشاهده کرده است و در چه مواردی ممکن است با مشکل مواجه شود، مانند دادههای غیرانگلیسی زبان.
همچنان که سیستم هوش مصنوعی شما تعاملات و بازخوردها را در طول زمان جمعآوری میکند، در نظر داشته باشید که نسخههای مختلفی از دادهها را نگهداری کنید تا بتوانید نحوه تکامل خروجیها را توضیح دهید.
هوش
در لایه هوش، میتوانید اعتماد را از طریق قابلیت توضیح، شاخصهای اطمینان و طراحی ماژولار مدیریت کنید:
- توضیحات متنی و بهموقع ارائه دهید . طبق پارادوکس کاربر فعال ، بهتر است توضیحات خرد را مستقیماً در متن تعاملات بگنجانید تا کاربران هنگام استفاده از سیستم هوش مصنوعی، متوجه شوند که آن سیستم چه کاری انجام میدهد.
- محدودیتها و حالتهای شکست را از قبل به کاربران اطلاع دهید . به کاربران بگویید که هوش مصنوعی ممکن است در کجا دچار مشکل شود. برای مثال، «از طنز یا اصطلاحات تخصصی پرهیز کنید تا نتایج بهتری بگیرید.» نشانههای کوتاه و زمینهای، بدون ایجاد اختلال در روند کار، شفافیت ایجاد میکنند.
- شاخصهای اطمینان و منطق جایگزین، هوش مصنوعی را در شرایط عدم قطعیت قابل اعتماد نگه میدارند. میتوانید اطمینان را از طریق شاخصهایی مانند نمرات احتمال یا نرخ موفقیت گذشته تخمین بزنید. برای خروجیهایی که به وضوح نادرست هستند، جایگزینهای ایمن تعریف کنید.
- معماریهای ماژولار، هوش مصنوعی را شفافتر میکنند. برای مثال، اگر یک دستیار نویسنده، دستور زبان، سبک و لحن را در مراحل جداگانه مدیریت میکند، مشخص کنید که در هر مرحله چه چیزی تغییر کرده است: «لحن: غیررسمیتر؛ پیچیدگی: سادهتر».
تجربه کاربری
تجربه کاربری، زمینه وسیعی را برای ایجاد و ارزیابی اعتماد در اختیار شما قرار میدهد. در اینجا چند تکنیک و الگو برای امتحان کردن آورده شده است:
- محتوای آموزشی را متناسبسازی کنید . فرض نکنید که کاربران شما در هوش مصنوعی مهارت دارند. برای کاربران حرفهای راهنماییهای مختصر و برای مبتدیان توضیحات مفصلی ارائه دهید.
- افشای تدریجی را اعمال کنید . با نشانههای کوچک شروع کنید. متنی را قرار دهید که بیان کند از هوش مصنوعی استفاده کردهاید، مانند «این به صورت خودکار تولید شده است» و به کاربران اجازه دهید برای اطلاعات بیشتر کلیک کنند.
- حلقههای بازخورد را با نتایج قابل مشاهده ببندید . وقتی کاربران یک پیشنهاد هوش مصنوعی را ارزیابی، تصحیح یا لغو میکنند، به اشتراک بگذارید که چگونه ورودی آنها رفتار آینده را شکل میدهد: "شما پاسخهای مختصر را ترجیح میدادید. لحن را بر این اساس تنظیم کنید." قابل مشاهده بودن، بازخورد را به اعتماد تبدیل میکند.
- خطاها را با ظرافت مدیریت کنید . وقتی سیستم شما اشتباه میکند یا نتیجهای با ضریب اطمینان پایین ارائه میدهد، آن را تصدیق کنید و بررسی را به کاربر واگذار کنید. برای مثال، «این پیشنهاد ممکن است با هدف شما مطابقت نداشته باشد. قبل از انتشار، آن را بررسی کنید.» با اجازه دادن به کاربر برای تلاش مجدد، ویرایش یا بازگشت به یک جایگزین امن، مسیر روشنی را برای پیشرفت فراهم کنید.
به طور خلاصه، برای پرداختن به عدم قطعیت و پتانسیل خطای ذاتی هوش مصنوعی، کاربران را از شک یا اتکای بیش از حد به سمت کالیبراسیون صحیح اعتماد هدایت کنید:
- دادهها : در مورد منشأ دادهها شفاف باشید.
- هوش : استدلال را ماژولار و قابل توضیح کنید.
- تجربه کاربری : طراحی برای وضوح و بازخورد پیشرفته.
نکات مهم شما
در این ماژول، ما سه رکن اصلی هوش مصنوعی مسئولانه، یعنی حریم خصوصی، انصاف و اعتماد را بررسی کردیم. این ممکن است طاقتفرسا به نظر برسد، به خصوص وقتی که تازه شروع به کار کردهاید یا سعی دارید از نمونه اولیه به محصول نهایی جهش کنید.
تلاشهای خود را بر روی حیاتیترین حوزهها متمرکز کنید و رویکرد خود را در مورد مدیریت هوش مصنوعی تعریف کنید. تکرار کلید اصلی است . هر نسخه و دور بازخورد کاربر، درک شما را از اینکه سیستم شما در کجا به محافظ، شفافیت یا انعطافپذیری بیشتری نیاز دارد، دقیقتر میکند.
منابع
در اینجا منابع پیشرفتهتری در مورد مباحث مطرح شده در این ماژول ارائه شده است:
- مقایسه حریم خصوصی و امنیت دستیار هوش مصنوعی، نگاهی عمیق به سیاستهای حفظ حریم خصوصی هوش مصنوعی ارائه میدهد.
- مقالهای در مورد به خاطر سپردن LLM ، یک حالت خرابی بحرانی در حریم خصوصی که در آن یک مدل اطلاعات خاص و حساس را از دادههای آموزشی خود حفظ میکند و میتوان از آن برای بازتولید اطلاعات استفاده کرد.
- منابعی را که مستقیماً با مدلی که انتخاب میکنید مرتبط هستند، بررسی کنید. به عنوان مثال، Google Cloud منابع امنیتی را ارائه میدهد .
- جعبه ابزار هوش مصنوعی مسئولانه، منابع توسعهدهندگان را در مورد تمام مباحثی که در این ماژول پوشش دادیم، ارائه میدهد.
منابع
در اینجا منابع پیشرفتهتری در مورد مباحث مطرح شده در این ماژول ارائه شده است:
- مقایسه حریم خصوصی و امنیت دستیار هوش مصنوعی، نگاهی عمیق به سیاستهای حفظ حریم خصوصی هوش مصنوعی ارائه میدهد.
- مقالهای در مورد به خاطر سپردن LLM ، یک حالت خرابی بحرانی در حریم خصوصی که در آن یک مدل اطلاعات خاص و حساس را از دادههای آموزشی خود حفظ میکند و میتوان از آن برای بازتولید اطلاعات استفاده کرد.
- منابعی را که مستقیماً با مدلی که انتخاب میکنید مرتبط هستند، بررسی کنید. به عنوان مثال، Google Cloud منابع امنیتی را ارائه میدهد .
- جعبه ابزار هوش مصنوعی مسئولانه، منابع توسعهدهندگان را در مورد تمام مباحثی که در این ماژول پوشش دادیم، ارائه میدهد.
درک خود را بررسی کنید
یک رویه حفظ حریم خصوصی توصیه شده در مورد جمعآوری دادهها برای هوش مصنوعی چیست؟
اعتماد کالیبره شده چیست؟
برای اطمینان از عدالت در لایه «هوش»، توسعهدهندگان چه اقداماتی میتوانند انجام دهند؟
تکنیک UX برای ایجاد اعتماد و شفافیت چیست؟