

The I/O APIs on the web are asynchronous, but they're synchronous in most system languages. When compiling code to WebAssembly, you need to bridge one kind of APIs to another—and this bridge is Asyncify. In this post, you'll learn when and how to use Asyncify and how it works under the hood.
I/O in system languages
I'll start with a simple example in C. Say, you want to read the user's name from a file, and greet them with a "Hello, (username)!" message:
#include <stdio.h>
int main() {
FILE *stream = fopen("name.txt", "r");
char name[20+1];
size_t len = fread(&name, 1, 20, stream);
name[len] = '\0';
fclose(stream);
printf("Hello, %s!\n", name);
return 0;
}
While the example doesn't do much, it already demonstrates something you'll find in an application of any size: it reads some inputs from the external world, processes them internally and writes outputs back to the external world. All such interaction with the outside world happens via a few functions commonly called input-output functions, also shortened to I/O.
To read the name from C, you need at least two crucial I/O calls: fopen, to open the file, and
fread to read data from it. Once you retrieve the data, you can use another I/O function printf
to print the result to the console.
Those functions look quite simple at first glance and you don't have to think twice about the machinery involved to read or write data. However, depending on the environment, there can be quite a lot going on inside:
- If the input file is located on a local drive, the application needs to perform a series of memory and disk accesses to locate the file, check permissions, open it for reading, and then read block by block until the requested number of bytes is retrieved. This can be pretty slow, depending on the speed of your disk and the requested size.
- Or, the input file might be located on a mounted network location, in which case, the network stack will now be involved too, increasing the complexity, latency and number of potential retries for each operation.
- Finally, even
printfis not guaranteed to print things to the console and might be redirected to a file or a network location, in which case it would have to go via the same steps above.
Long story short, I/O can be slow and you can't predict how long a particular call will take by a quick glance at the code. While that operation is running, your whole application will appear frozen and unresponsive to the user.
This is not limited to C or C++ either. Most system languages present all the I/O in a form of synchronous APIs. For example, if you translate the example to Rust, the API might look simpler, but the same principles apply. You just make a call and synchronously wait for it to return the result, while it performs all the expensive operations and eventually returns the result in a single invocation:
fn main() {
let s = std::fs::read_to_string("name.txt");
println!("Hello, {}!", s);
}
But what happens when you try to compile any of those samples to WebAssembly and translate them to the web? Or, to provide a specific example, what could "file read" operation translate to? It would need to read data from some storage.
Asynchronous model of the web
The web has a variety of different storage options you could map to, such as in-memory storage (JS
objects), localStorage,
IndexedDB, server-side storage,
and a new File System Access API.
However, only two of those APIs—the in-memory storage and the localStorage—can be used
synchronously, and both are the most limiting options in what you can store and for how long. All
the other options provide only asynchronous APIs.
This is one of the core properties of executing code on the web: any time-consuming operation, which includes any I/O, has to be asynchronous.
The reason is that the web is historically single-threaded, and any user code that touches the UI has to run on the same thread as the UI. It has to compete with the other important tasks like layout, rendering and event handling for the CPU time. You wouldn't want a piece of JavaScript or WebAssembly to be able to start a "file read" operation and block everything else—the entire tab, or, in the past, the entire browser—for a range from milliseconds to a few seconds, until it's over.
Instead, code is only allowed to schedule an I/O operation together with a callback to be executed once it's finished. Such callbacks are executed as part of the browser's event loop. I won't be going into details here, but if you're interested in learning how the event loop works under the hood, check out Tasks, microtasks, queues and schedules which explains this topic in-depth.
The short version is that the browser runs all the pieces of code in sort of an infinite loop, by taking them from the queue one by one. When some event is triggered, the browser queues the corresponding handler, and on the next loop iteration it's taken out from the queue and executed. This mechanism allows simulating concurrency and running lots of parallel operations while using only a single thread.
The important thing to remember about this mechanism is that, while your custom JavaScript (or WebAssembly) code executes, the event loop is blocked and, while it is, there is no way to react to any external handlers, events, I/O, etc. The only way to get the I/O results back is to register a callback, finish executing your code, and give the control back to the browser so that it can keep processing any pending tasks. Once I/O is finished, your handler will become one of those tasks and will get executed.
For example, if you wanted to rewrite the samples above in modern JavaScript and decided to read a name from a remote URL, you would use Fetch API and async-await syntax:
async function main() {
let response = await fetch("name.txt");
let name = await response.text();
console.log("Hello, %s!", name);
}
Even though it looks synchronous, under the hood each await is essentially syntax sugar for
callbacks:
function main() {
return fetch("name.txt")
.then(response => response.text())
.then(name => console.log("Hello, %s!", name));
}
In this de-sugared example, which is a bit clearer, a request is started and responses are subscribed to with the first callback. Once the browser receives the initial response—just the HTTP
headers—it asynchronously invokes this callback. The callback starts reading the body as text using
response.text(), and subscribes to the result with another callback. Finally, once fetch has
retrieved all the contents, it invokes the last callback, which prints "Hello, (username)!" to the
console.
Thanks to the asynchronous nature of those steps, the original function can return control to the browser as soon as the I/O has been scheduled, and leave the entire UI responsive and available for other tasks, including rendering, scrolling and so on, while the I/O is executing in background.
As a final example, even simple APIs like "sleep", which makes an application wait a specified number of seconds, are also a form of an I/O operation:
#include <stdio.h>
#include <unistd.h>
// ...
printf("A\n");
sleep(1);
printf("B\n");
Sure, you could translate it in a very straightforward manner that would block the current thread until the time expires:
console.log("A");
for (let start = Date.now(); Date.now() - start < 1000;);
console.log("B");
In fact, that's exactly what Emscripten does in its default implementation of "sleep", but that's very inefficient, will block the entire UI and won't allow any other events to be handled meanwhile. Generally, don't do that in production code.
Instead, a more idiomatic version of "sleep" in JavaScript would involve calling setTimeout(), and
subscribing with a handler:
console.log("A");
setTimeout(() => {
console.log("B");
}, 1000);
What's common to all these examples and APIs? In each case, the idiomatic code in the original systems language uses a blocking API for the I/O, whereas an equivalent example for the web uses an asynchronous API instead. When compiling to the web, you need to somehow transform between those two execution models, and WebAssembly has no built-in ability to do so just yet.
Bridging the gap with Asyncify
This is where Asyncify comes in. Asyncify is a compile-time feature supported by Emscripten that allows pausing the entire program and asynchronously resuming it later.

Usage in C / C++ with Emscripten
If you wanted to use Asyncify to implement an asynchronous sleep for the last example, you could do it like this:
#include <stdio.h>
#include <emscripten.h>
EM_JS(void, async_sleep, (int seconds), {
Asyncify.handleSleep(wakeUp => {
setTimeout(wakeUp, seconds * 1000);
});
});
…
puts("A");
async_sleep(1);
puts("B");
EM_JS is a
macro that allows defining JavaScript snippets as if they were C functions. Inside, use a function
Asyncify.handleSleep()
which tells Emscripten to suspend the program and provides a wakeUp() handler that should be
called once the asynchronous operation has finished. In the example above, the handler is passed to
setTimeout(), but it could be used in any other context that accepts callbacks. Finally, you can
call async_sleep() anywhere you want just like regular sleep() or any other synchronous API.
When compiling such code, you need to tell Emscripten to activate the Asyncify feature. Do that by
passing -s ASYNCIFY as well as -s ASYNCIFY_IMPORTS=[func1,
func2] with an
array-like list of functions that might be asynchronous.
emcc -O2 \
-s ASYNCIFY \
-s ASYNCIFY_IMPORTS=[async_sleep] \
...
This lets Emscripten know that any calls to those functions might require saving and restoring the state, so the compiler will inject supporting code around such calls.
Now, when you execute this code in the browser you'll see a seamless output log like you'd expect, with B coming after a short delay after A.
A
B
You can return values from
Asyncify functions too. What
you need to do is return the result of handleSleep(), and pass the result to the wakeUp()
callback. For example, if, instead of reading from a file, you want to fetch a number from a remote
resource, you can use a snippet like the one below to issue a request, suspend the C code, and
resume once the response body is retrieved—all done seamlessly as if the call were synchronous.
EM_JS(int, get_answer, (), {
return Asyncify.handleSleep(wakeUp => {
fetch("answer.txt")
.then(response => response.text())
.then(text => wakeUp(Number(text)));
});
});
puts("Getting answer...");
int answer = get_answer();
printf("Answer is %d\n", answer);
In fact, for Promise-based APIs like fetch(), you can even combine Asyncify with JavaScript's
async-await feature instead of using the callback-based API. For that, instead of
Asyncify.handleSleep(), call Asyncify.handleAsync(). Then, instead of having to schedule a
wakeUp() callback, you can pass an async JavaScript function and use await and return
inside, making code look even more natural and synchronous, while not losing any of the benefits of
the asynchronous I/O.
EM_JS(int, get_answer, (), {
return Asyncify.handleAsync(async () => {
let response = await fetch("answer.txt");
let text = await response.text();
return Number(text);
});
});
int answer = get_answer();
Awaiting complex values
But this example still limits you only to numbers. What if you want to implement the original example, where I tried to get a user's name from a file as a string? Well, you can do that too!
Emscripten provides a feature called
Embind that allows
you to handle conversions between JavaScript and C++ values. It has support for Asyncify as well, so
you can call await() on external Promises and it will act just like await in async-await
JavaScript code:
val fetch = val::global("fetch");
val response = fetch(std::string("answer.txt")).await();
val text = response.call<val>("text").await();
auto answer = text.as<std::string>();
When using this method, you don't even need to pass ASYNCIFY_IMPORTS as a compile flag, as it's
already included by default.
Okay, so this all works great in Emscripten. What about other toolchains and languages?
Usage from other languages
Say that you have a similar synchronous call somewhere in your Rust code that you want to map to an async API on the web. Turns out, you can do that too!
First, you need to define such a function as a regular import via extern block (or your chosen
language's syntax for foreign functions).
extern {
fn get_answer() -> i32;
}
println!("Getting answer...");
let answer = get_answer();
println!("Answer is {}", answer);
And compile your code to WebAssembly:
cargo build --target wasm32-unknown-unknown
Now you need to instrument the WebAssembly file with code for storing/restoring the stack. For C / C++, Emscripten would do this for us, but it's not used here, so the process is a bit more manual.
Luckily, the Asyncify transform itself is completely toolchain-agnostic. It can transform arbitrary
WebAssembly files, no matter which compiler it's produced by. The transform is provided separately
as part of the wasm-opt optimiser from the Binaryen
toolchain and can be invoked like this:
wasm-opt -O2 --asyncify \
--pass-arg=asyncify-imports@env.get_answer \
[...]
Pass --asyncify to enable the transform, and then use --pass-arg=… to provide a comma-separated
list of asynchronous functions, where the program state should be suspended and later resumed.
All that's left is to provide supporting runtime code that will actually do that—suspend and resume WebAssembly code. Again, in the C / C++ case this would be included by Emscripten, but now you need custom JavaScript glue code that would handle arbitrary WebAssembly files. We've created a library just for that.
You can find it on GitHub at
https://github.com/GoogleChromeLabs/asyncify or npm
under the name asyncify-wasm.
It simulates a standard WebAssembly instantiation API, but under its own namespace. The only difference is that, under a regular WebAssembly API you can only provide synchronous functions as imports, while under the Asyncify wrapper, you can provide asynchronous imports as well:
const { instance } = await Asyncify.instantiateStreaming(fetch('app.wasm'), {
env: {
async get_answer() {
let response = await fetch("answer.txt");
let text = await response.text();
return Number(text);
}
}
});
…
await instance.exports.main();
Once you try to call such an asynchronous function - like get_answer() in the example above - from
the WebAssembly side, the library will detect the returned Promise, suspend and save the state of
the WebAssembly application, subscribe to the promise completion, and later, once it's resolved,
seamlessly restore the call stack and state and continue execution as if nothing has happened.
Since any function in the module might make an asynchronous call, all the exports become potentially
asynchronous too, so they get wrapped as well. You might have noticed in the example above that you
need to await the result of instance.exports.main() to know when the execution is truly
finished.
How does this all work under the hood?
When Asyncify detects a call to one of the ASYNCIFY_IMPORTS functions, it starts an asynchronous
operation, saves the entire state of the application, including the call stack and any temporary
locals, and later, when that operation is finished, restores all the memory and call stack and
resumes from the same place and with the same state as if the program has never stopped.
This is quite similar to async-await feature in JavaScript that I showed earlier, but, unlike the JavaScript one, doesn't require any special syntax or runtime support from the language, and instead works by transforming plain synchronous functions at compile-time.
When compiling the earlier shown asynchronous sleep example:
puts("A");
async_sleep(1);
puts("B");
Asyncify takes this code and transforms it to roughly like the following one (pseudo-code, real transformation is more involved than this):
if (mode == NORMAL_EXECUTION) {
puts("A");
async_sleep(1);
saveLocals();
mode = UNWINDING;
return;
}
if (mode == REWINDING) {
restoreLocals();
mode = NORMAL_EXECUTION;
}
puts("B");
Initially mode is set to NORMAL_EXECUTION. Correspondingly, the first time such transformed code
is executed, only the part leading up to async_sleep() will get evaluated. As soon as the
asynchronous operation is scheduled, Asyncify saves all the locals, and unwinds the stack by
returning from each function all the way to the top, this way giving control back to the browser
event loop.
Then, once async_sleep() resolves, Asyncify support code will change mode to REWINDING, and
call the function again. This time, the "normal execution" branch is skipped - since it already did
the job last time and I want to avoid printing "A" twice - and instead it comes straight to the
"rewinding" branch. Once it's reached, it restores all the stored locals, changes mode back to
"normal" and continues the execution as if the code were never stopped in the first place.
Transformation costs
Unfortunately, Asyncify transform isn't completely free, since it has to inject quite a bit of supporting code for storing and restoring all those locals, navigating the call stack under different modes and so on. It tries to modify only functions marked as asynchronous on the command line, as well as any of their potential callers, but the code size overhead might still add up to approximately 50% before compression.
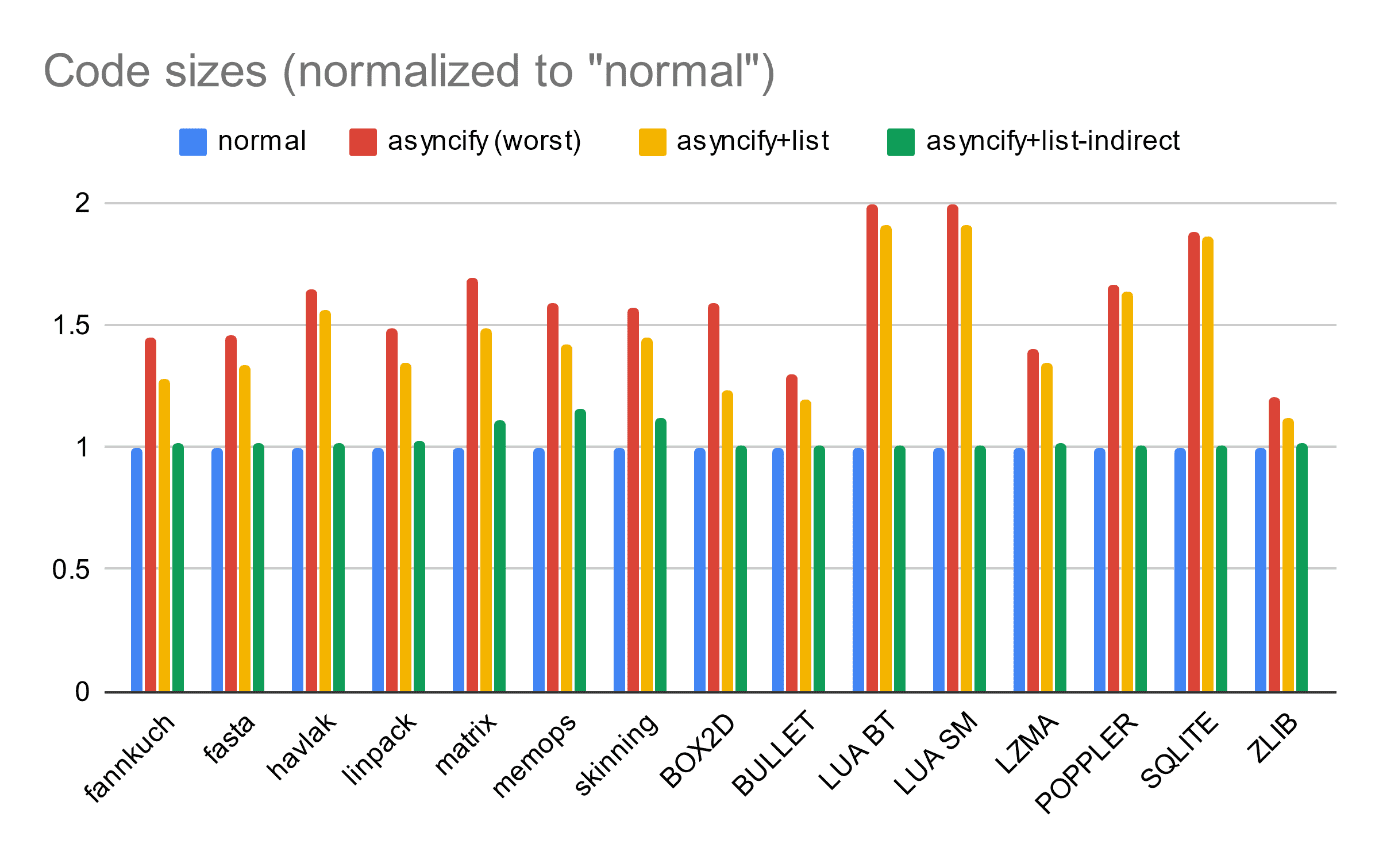
This isn't ideal, but in many cases acceptable when the alternative is not having the functionality altogether or having to make significant rewrites to the original code.
Make sure to always enable optimizations for the final builds to avoid it going even higher. You can also check Asyncify-specific optimization options to reduce the overhead by limiting transforms only to specified functions and/or only direct function calls. There is also a minor cost to runtime performance, but it's limited to the async calls themselves. However, compared to the cost of the actual work, it's usually negligible.
Real-world demos
Now that you've looked at the simple examples, I'll move on to more complicated scenarios.
As mentioned in the beginning of the article, one of the storage options on the web is an asynchronous File System Access API. It provides access to a real host filesystem from a web application.
On the other hand, there is a de-facto standard called WASI for WebAssembly I/O in the console and the server-side. It was designed as a compilation target for system languages, and exposes all sorts of file system and other operations in a traditional synchronous form.
What if you could map one to another? Then you could compile any application in any source language with any toolchain supporting the WASI target, and run it in a sandbox on the web, while still allowing it to operate on real user files! With Asyncify, you can do just that.
In this demo, I've compiled Rust coreutils crate with a few minor patches to WASI, passed via Asyncify transform and implemented asynchronous bindings from WASI to File System Access API on the JavaScript side. Once combined with Xterm.js terminal component, this provides a realistic shell running in the browser tab and operating on real user files - just like an actual terminal.
Check it out live at https://wasi.rreverser.com/.
Asyncify use-cases are not limited just to timers and filesystems, either. You can go further and use more niche APIs on the web.
For example, also with the help of Asyncify, it's possible to map libusb—probably the most popular native library for working with USB devices—to a WebUSB API, which gives asynchronous access to such devices on the web. Once mapped and compiled, I got standard libusb tests and examples to run against chosen devices right in the sandbox of a web page.
It's probably a story for another blog post though.
Those examples demonstrate just how powerful Asyncify can be for bridging the gap and porting all sorts of applications to the web, allowing you to gain cross-platform access, sandboxing, and better security, all without losing functionality.