

Published: October 21, 2024
Online stores can see a 270% increase in conversions by displaying product reviews. Negative reviews are key, too, as they build credibility. 82% of online shoppers look for them before buying.
Encouraging customers to leave helpful product reviews, especially when negative, can be tricky. Here, we'll explore how to use generative AI to help users write informative reviews that aid others' purchasing decisions.
Demo and code
Play around with our product review demo and investigate the code on GitHub.
How we built this
Client-side AI
For this demo, we implemented the feature client-side for the following reasons:
- Latency. We want to provide suggestions quickly, as soon as the user stops typing. We can offer this by avoiding server round-trips.
- Cost. While this is a demo, if you're considering launching a similar feature in production, it's great to experiment at zero server-side cost until you can validate whether the feature makes sense for your users.
MediaPipe generative AI
We've chosen to use the Gemma 2B model through the MediaPipe LLM Inference API (MediaPipe GenAI package), for the following reasons:
- Model accuracy: Gemma 2B offers a great balance of size and accuracy. When properly prompted, it gave results that we found satisfying for this demo.
- Cross-browser support: MediaPipe is supported in all browsers that support WebGPU.
User experience
Apply performance best practices
While Gemma 2B is a small LLM, it's still a large download. Apply performance best practices, which include using a web worker.
Make the feature optional
We want the AI-based review suggestions to enhance the user's workflow to post a product review. In our implementation, the user can post a review even if the model hasn't loaded, and thus isn't offering improvement tips.
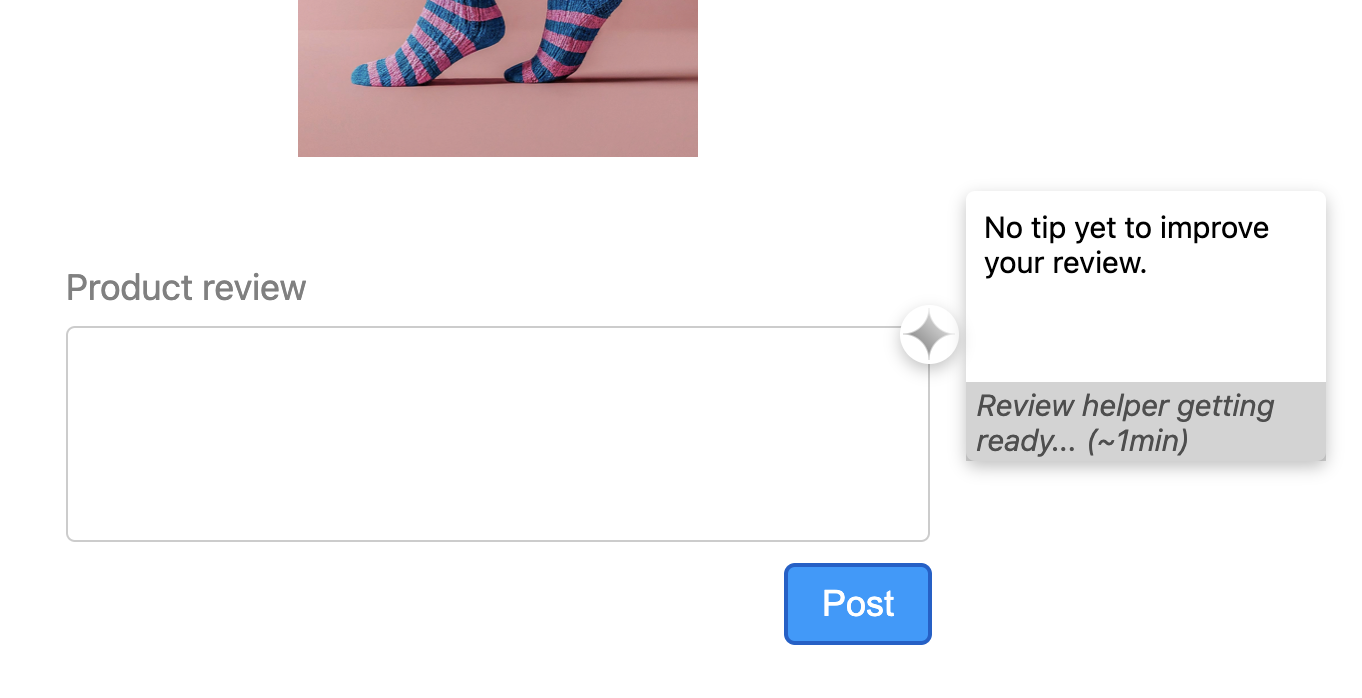
UI states and animations
Inference typically takes more time than what would feel immediate, so we signal to the user that the model is running inference, or "thinking." We use animations to ease the wait, while assuring the user that the application is working as intended. Discover the different UI states we've implemented in our demo, as designed by Adam Argyle.
Other considerations
In a production environment, you may want to:
- Provide a feedback mechanism. What if the suggestions are mediocre, or don't make sense? Implement a quick feedback mechanism (such as thumbs-up and thumbs-down) and rely on heuristics to determine what users find useful. For example, assess how many of your users are interacting with the feature, and if they turn it off.
- Allow opt-out. What if the user prefers to use their own words without AI assistance, or finds the feature annoying? Allow the user to opt out and opt back in as wanted.
- Explain why this feature exists. A short explanation may encourage your users to use the feedback tool. For example, "Better feedback helps fellow shoppers decide what to buy, and helps us create the products you want." You could add a lengthy explanation of how the feature works and why you've provided it, perhaps as a linked-out learn more.
- Disclose AI usage where relevant. With client-side AI, the user's content is not sent to a server for processing, thus can be kept private. However, if you build a server-side fallback or otherwise collect information with AI, consider adding it to your privacy policy, terms of service, or other places.
Implementation
Our implementation for the product review suggester could work for a large range of use cases. Consider the following information as a base for your future client-side AI features.
MediaPipe in a web worker
With MediaPipe LLM inference, the AI code is just a few lines: create a file resolver and an LLM inference object by passing it a model URL, and later use that LLM inference instance to generate a response.
However, our code sample is a bit more expansive. That's because it's implemented in a web worker, so it passes messages with the main script through custom message codes. Learn more about this pattern.
// Trigger model preparation *before* the first message arrives
self.postMessage({ code: MESSAGE_CODE.PREPARING_MODEL });
try {
// Create a FilesetResolver instance for GenAI tasks
const genai = await FilesetResolver.forGenAiTasks(MEDIAPIPE_WASM);
// Create an LLM Inference instance from the specified model path
llmInference = await LlmInference.createFromModelPath(genai, MODEL_URL);
self.postMessage({ code: MESSAGE_CODE.MODEL_READY });
} catch (error) {
self.postMessage({ code: MESSAGE_CODE.MODEL_ERROR });
}
// Trigger inference upon receiving a message from the main script
self.onmessage = async function (message) {
// Run inference = Generate an LLM response
let response = null;
try {
response = await llmInference.generateResponse(
// Create a prompt based on message.data, which is the actual review
// draft the user has written. generatePrompt is a local utility function.
generatePrompt(message.data),
);
} catch (error) {
self.postMessage({ code: MESSAGE_CODE.INFERENCE_ERROR });
return;
}
// Parse and process the output using a local utility function
const reviewHelperOutput = generateReviewHelperOutput(response);
// Post a message to the main thread
self.postMessage({
code: MESSAGE_CODE.RESPONSE_READY,
payload: reviewHelperOutput,
});
};
export const MESSAGE_CODE ={
PREPARING_MODEL: 'preparing-model',
MODEL_READY: 'model-ready',
GENERATING_RESPONSE: 'generating-response',
RESPONSE_READY: 'response-ready',
MODEL_ERROR: 'model-error',
INFERENCE_ERROR: 'inference-error',
};
Input and output
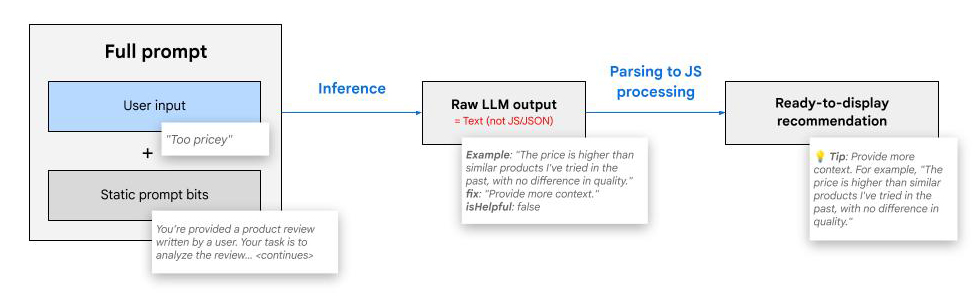
Our full prompt was built with few-shot prompting. It includes the user's input, or in other words the review draft the user has written.
To generate our prompt based on the user input, we call at runtime our utility
function generatePrompt.
Client-side AI models and libraries typically come with less utilities than server-side AI. For example, JSON mode is often not available. This means we need to provide the desired output structure inside our prompt. This is less clean, maintainable, and reliable than supplying a schema through model configuration. Additionally, client-side models tend to be smaller, which means they're more prone to structural errors in their output.
In practice, we observed that Gemma 2B does a better job at providing a structured output as text as compared to JSON or JavaScript. So for this demo, we opted for a text-based output format. The model generates text, that we then parse the output into a JavaScript object for further processing within our web app.
Improving our prompt
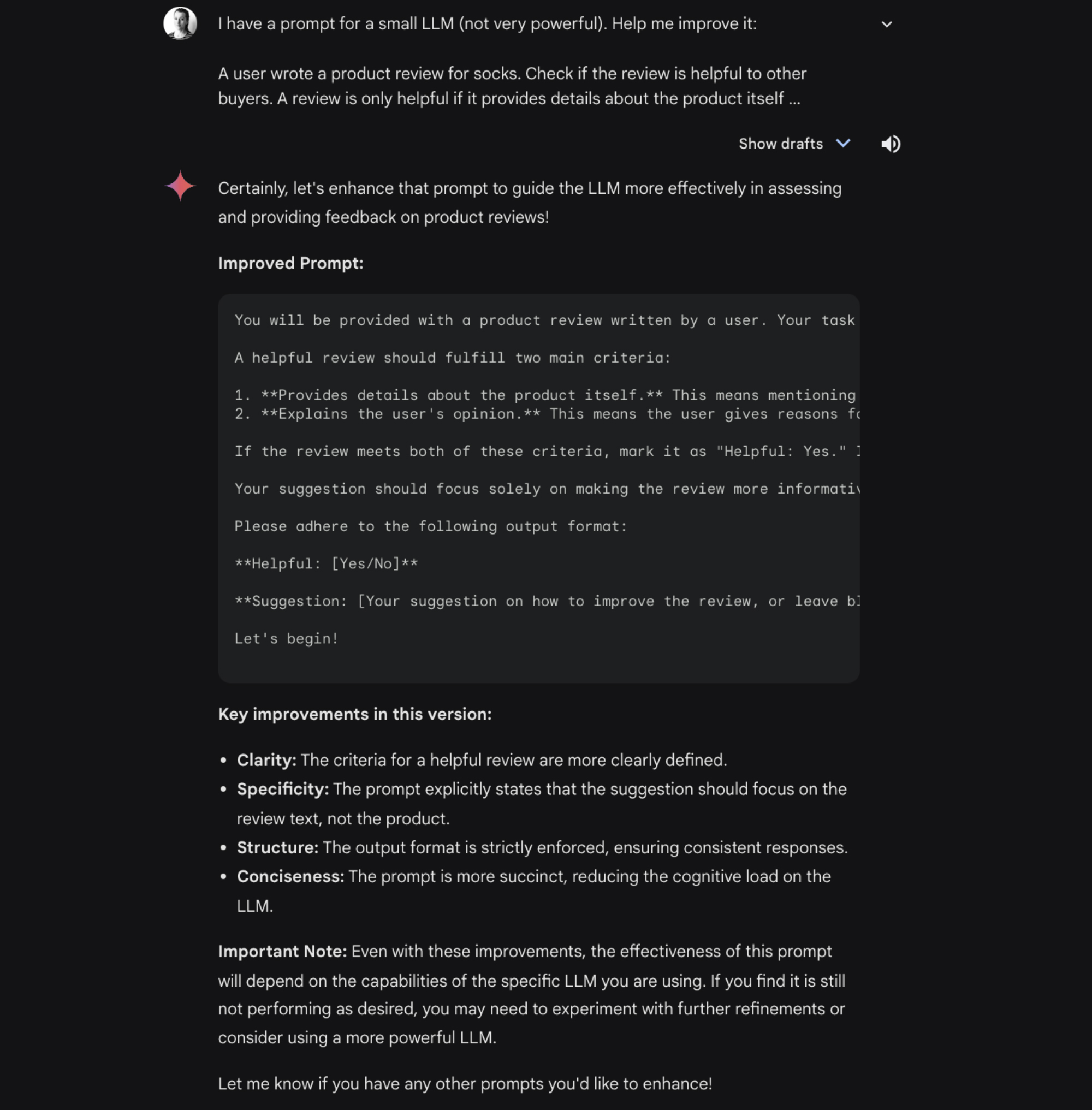
We used an LLM to iterate on our prompt.
- Few-shot prompting. To generate the examples for our few-shot prompts, we relied on Gemini Chat. Gemini Chat uses the most powerful Gemini models. This ensured we generated high-quality examples.
- Prompt polishing. Once the prompt's structure was ready, we also used Gemini Chat to refine the prompt. This improved the output quality.
Use context to increase quality
Including the product type into our prompt helped the model provide more relevant, higher-quality suggestions. In this demo, the product type is static. In a real application, you could include the product dynamically into your prompt, based on the page the user is visiting.
Review: "I love these."
Helpful: No
Fix: Be more specific, explain why you like these **socks**.
Example: "I love the blend of wool in these socks. Warm and not too heavy."
One of the examples in the few-shots section of our prompt: the product type ("socks") is included in the suggested fix, and in the example review.
LLM mishaps and fixes
Gemma 2B typically requires more prompt engineering than a more powerful, larger server-side model.
We encountered some challenges with Gemma 2B. Here's how we improved the results:
- Too nice. Gemma 2B struggled to mark reviews as "not helpful," seemingly hesitant to judge. We tried to make the label language more neutral ("specific" and "unspecific," instead of "helpful" and "not helpful") and added examples, but this didn't improve the results. What did improve results was insistence and repetition in the prompt. A chain-of-thought approach would likely yield improvements, too.
Instructions unclear. The model sometimes over-interpreted the prompt. Instead of assessing the review, it continued the example list. To fix this, we included a clear transition in the prompt:
I'll give you example reviews and outputs, and then give you one review to analyze. Let's go: Examples: <... Examples> Review to analyze: <... User input>Clearly structuring the prompt aids the model in differentiating between the example list (few shots) and the actual input.
Wrong target. Occasionally, the model suggested changes to the product instead of the review text. For example, for a review stating "I hate these socks", the model could suggest "Consider replacing the socks with a different brand or style", which isn't the desired effect. Splitting the prompt helped clarify the task, and improved the model's focus on the review.