

Introdução
As Media Source Extensions (MSE, na sigla em inglês)
oferecem controle de buffer e reprodução estendidos para os elementos <audio> e
<video> do HTML5. Embora tenham sido desenvolvidas originalmente para facilitar
Dynamic Adaptive Streaming over HTTP (DASH)
players de vídeo baseados em, abaixo vamos mostrar como elas podem ser usadas para áudio, especificamente para
reprodução contínua.
Você provavelmente já ouviu um álbum de música em que as músicas fluíam perfeitamente entre as faixas. Talvez você esteja ouvindo um agora. Os artistas criam essas experiências de reprodução contínua tanto como uma escolha artística quanto como um artefato de discos de vinil e CDs em que o áudio era gravado como um fluxo contínuo. Infelizmente, devido à forma como os codecs de áudio modernos, como MP3 e AAC funcionam, essa experiência auditiva perfeita é frequentemente perdida hoje em dia.
Vamos entrar nos detalhes do motivo abaixo, mas, por enquanto, vamos começar com uma demonstração. Abaixo estão os primeiros 30 segundos do excelente Sintel, divididos em cinco arquivos MP3 separados e remontados usando MSE. As linhas vermelhas indicam lacunas introduzidas durante a criação (codificação) de cada MP3. Você vai ouvir falhas nesses pontos.
Que chato! Essa não é uma ótima experiência. Podemos fazer melhor. Com um pouco mais de trabalho, usando os mesmos arquivos MP3 na demonstração acima, podemos usar o MSE para remover essas lacunas irritantes. As linhas verdes na próxima demonstração indicam onde os arquivos foram unidos e as lacunas removidas. No Chrome 38 e versões mais recentes, isso será reproduzido perfeitamente.
Há várias maneiras de criar conteúdo contínuo. Para fins desta demonstração, vamos nos concentrar no tipo de arquivos que um usuário normal pode ter por aí. Em que cada arquivo foi codificado separadamente, sem considerar os segmentos de áudio anteriores ou posteriores.
Configuração básica
Primeiro, vamos voltar e abordar a configuração básica de uma instância MediaSource.
As Media Source Extensions, como o nome sugere, são apenas extensões dos elementos de mídia atuais. Abaixo, estamos atribuindo um
Object URL,
que representa nossa instância MediaSource, ao atributo de origem de um elemento de áudio
, assim como você definiria um URL padrão.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
Depois que o objeto MediaSource estiver conectado, ele vai realizar alguma inicialização
e, por fim, disparar um evento sourceopen Nesse momento, podemos criar um
SourceBuffer. No
exemplo acima, estamos criando um audio/mpeg, que pode analisar e
decodificar nossos segmentos MP3. Há vários
outros tipos disponíveis.
Formas de onda anômalas
Vamos voltar ao código em um momento, mas agora vamos analisar mais de perto o arquivo que acabamos de anexar, especificamente no final dele. Abaixo, há um gráfico das últimas 3.000 amostras com média nos dois canais da faixa sintel_0.mp3. Cada pixel na linha vermelha é uma
amostra de ponto flutuante
no intervalo de [-1.0, 1.0].

O que há de errado com todas essas amostras zero (silenciosas)? Elas são, na verdade, devido a artefatos de compactação introduzidos durante a codificação. Quase todos os codificadores introduzem algum tipo de preenchimento. Nesse caso, LAME adicionou exatamente 576 amostras de preenchimento ao final do arquivo.
Além do preenchimento no final, cada arquivo também tinha preenchimento adicionado ao início. Se avançarmos para a faixa sintel_1.mp3, vamos ver outras 576 amostras de preenchimento na frente. A quantidade
de preenchimento varia de acordo com o codificador e o conteúdo, mas sabemos os valores exatos com base nos
metadata incluídos em cada arquivo.
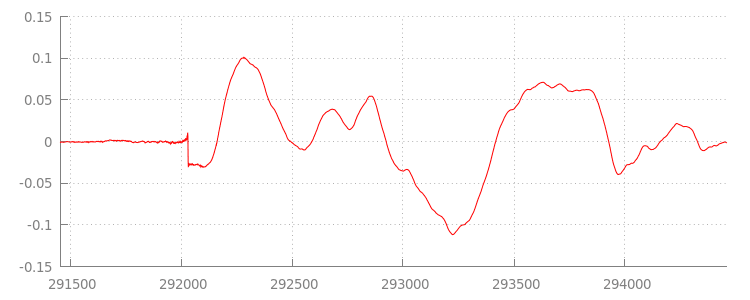
As seções de silêncio no início e no final de cada arquivo são o que causam as falhas entre os segmentos na demonstração anterior. Para conseguir uma reprodução contínua, precisamos remover essas seções de silêncio. Felizmente, isso é feito facilmente com MediaSource. Abaixo, vamos modificar nosso método onAudioLoaded() para usar uma
janela de anexação e um deslocamento
de carimbo de data/hora para remover esse silêncio.
Exemplo de código
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Uma forma de onda contínua
Vamos ver o que nosso novo código brilhante realizou, analisando novamente a forma de onda depois de aplicarmos nossas janelas de anexação. Abaixo, você pode ver que a seção silenciosa no final de sintel_0.mp3 (em vermelho) e a seção silenciosa no início de sintel_1.mp3 (em azul) foram removidas, deixando uma transição contínua entre os segmentos.
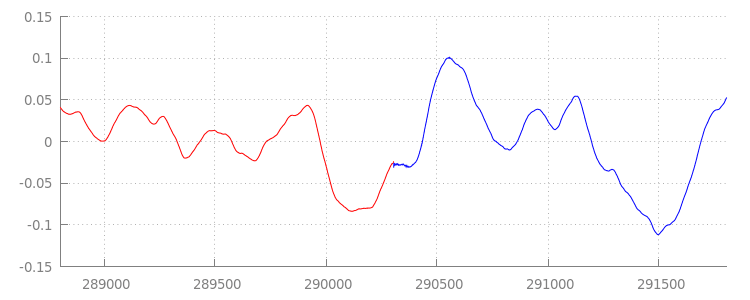
Conclusão
Com isso, unimos todos os cinco segmentos perfeitamente em um só e, consequentemente, chegamos ao final da nossa demonstração. Antes de prosseguirmos, você pode ter notado que nosso método onAudioLoaded() não considera contêineres ou codecs.
Isso significa que todas essas técnicas vão funcionar independentemente do contêiner ou do tipo de codec. Abaixo, você pode reproduzir a demonstração original do MP4 fragmentado pronto para DASH em vez de MP3.
Se quiser saber mais, confira os apêndices abaixo para uma análise mais detalhada da criação de conteúdo contínuo e da análise de metadados. Você também pode explorar
gapless.js para uma análise mais detalhada do
código que alimenta essa demonstração.
Agradecemos por ler.
Apêndice A: Como criar conteúdo contínuo
Criar conteúdo contínuo pode ser difícil. Abaixo, vamos explicar a criação da mídia Sintel usada nesta demonstração. Para começar, você vai precisar de uma cópia da trilha sonora FLAC sem perdas para Sintel. Para a posteridade, o SHA1 está incluído abaixo. Para ferramentas, você vai precisar do FFmpeg, MP4Box, LAME e uma instalação do OSX com afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Primeiro, vamos dividir os primeiros 31,5 segundos da faixa 1-Snow_Fight.flac. Também queremos adicionar um fade-out de 2,5 segundos começando aos 28 segundos para evitar cliques quando a reprodução terminar. Usando a linha de comando do FFmpeg abaixo, podemos realizar tudo isso e colocar os resultados em sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Em seguida, vamos dividir o arquivo em cinco arquivos de onda
de 6,5 segundos cada.É mais fácil usar a onda, já que quase todos os codificadores
oferecem suporte à ingestão dela. Novamente, podemos fazer isso com precisão usando o FFmpeg. Depois disso, teremos: sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav e sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
Agora, vamos criar os arquivos MP3. O LAME tem várias opções para criar conteúdo contínuo. Se você tiver controle sobre o conteúdo, considere usar --nogap com uma codificação em lote de todos os arquivos para evitar o preenchimento entre os segmentos.
No entanto, para fins desta demonstração, queremos esse preenchimento. Portanto, vamos usar uma codificação VBR padrão de alta qualidade dos arquivos de onda.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
Isso é tudo o que é necessário para criar os arquivos MP3. Agora, vamos abordar a criação dos arquivos MP4 fragmentados. Vamos seguir as instruções da Apple para criar mídia que é masterizada para o iTunes. Abaixo, vamos converter os arquivos de onda em arquivos CAF intermediários, de acordo com as instruções, antes de codificá-los como AAC em um contêiner MP4 usando os parâmetros recomendados.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Agora temos vários arquivos M4A que precisam ser
fragmentados
adequadamente antes de serem usados com
MediaSource. Para nossos fins, vamos usar um tamanho de fragmento de um segundo. O MP4Box vai gravar cada MP4 fragmentado como sintel_#_dashinit.mp4 junto com um manifesto MPEG-DASH (sintel_#_dash.mpd), que pode ser descartado.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
Pronto! Agora temos arquivos MP4 e MP3 fragmentados com os metadados corretos necessários para a reprodução contínua. Consulte o Apêndice B para mais detalhes sobre a aparência desses metadados.
Apêndice B: Como analisar metadados contínuos
Assim como criar conteúdo contínuo, analisar os metadados contínuos pode ser complicado, já que não há um método padrão para armazenamento. Abaixo, vamos abordar como os dois codificadores mais comuns, LAME e iTunes, armazenam os metadados contínuos. Vamos começar configurando alguns métodos auxiliares e um contorno para o ParseGaplessData() usado acima.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Vamos abordar o formato de metadados do iTunes da Apple primeiro, já que ele é o mais fácil de analisar e explicar. Nos arquivos MP3 e M4A, o iTunes (e o afconvert) gravam uma seção curta em ASCII, como esta:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Isso é gravado em uma tag ID3 dentro do contêiner MP3 e em um átomo de metadados dentro do contêiner MP4. Para nossos fins, podemos ignorar o primeiro token 0000000. Os três tokens seguintes são o preenchimento frontal, o preenchimento final e a contagem total de amostras sem preenchimento. Dividir cada um deles pela taxa de amostragem do áudio nos dá a duração de cada um.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
Por outro lado, a maioria dos codificadores MP3 de código aberto armazena os metadados contínuos em um cabeçalho Xing especial colocado dentro de um frame MPEG silencioso (é silencioso para que os decodificadores que não entendem o cabeçalho Xing simplesmente reproduzam o silêncio). Infelizmente, essa tag nem sempre está presente e tem vários campos opcionais. Para fins desta demonstração, temos controle sobre a mídia, mas, na prática, algumas verificações de sensibilidade adicionais serão necessárias para saber quando os metadados contínuos estão realmente disponíveis.
Primeiro, vamos analisar a contagem total de amostras. Para simplificar, vamos ler isso no
cabeçalho Xing, mas ele pode ser construído no
cabeçalho de áudio MPEG normal.
Os cabeçalhos Xing podem ser marcados por uma tag Xing ou Info. Exatamente quatro bytes após essa tag, há 32 bits que representam o número total de frames no arquivo. Multiplicar esse valor pelo número de amostras por frame nos dará o total de amostras no arquivo.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Agora que temos o número total de amostras, podemos passar para a leitura do número de amostras de preenchimento. Dependendo do codificador, isso pode ser gravado em uma tag LAME ou Lavf aninhada no cabeçalho Xing. Exatamente 17 bytes após esse cabeçalho, há três bytes que representam o preenchimento frontal e final em 12 bits cada, respectivamente.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Com isso, temos uma função completa para analisar a grande maioria do conteúdo contínuo. No entanto, os casos extremos são abundantes. Portanto, é recomendável ter cuidado antes de usar um código semelhante na produção.
Apêndice C: Sobre a coleta de lixo
A memória pertencente a instâncias SourceBuffer é coletada ativamente
de lixo
de acordo com o tipo de conteúdo, os limites específicos da plataforma e a posição de reprodução
atual. No Chrome, a memória será recuperada primeiro dos buffers já reproduzidos.
No entanto, se o uso da memória exceder os limites específicos da plataforma, ela vai remover a memória dos buffers não reproduzidos.
Quando a reprodução atinge uma lacuna na linha do tempo devido à memória recuperada, ela pode apresentar falhas se a lacuna for pequena o suficiente ou parar completamente se a lacuna for muito grande. Nenhuma delas é uma ótima experiência do usuário. Portanto, é importante evitar anexar muitos dados de uma só vez e remover manualmente os intervalos da linha do tempo da mídia que não são mais necessários.
Os intervalos podem ser removidos usando o
remove()
método em cada SourceBuffer; que usa um [start, end] intervalo em segundos.
Semelhante a appendBuffer(), cada remove() vai disparar um evento updateend quando for concluído. Outras remoções ou anexos não devem ser emitidos até que o evento seja disparado.
No Chrome para computador, é possível manter aproximadamente 12 megabytes de conteúdo de áudio e 150 megabytes de conteúdo de vídeo na memória de uma só vez. Não confie nesses valores em navegadores ou plataformas. Por exemplo, eles certamente não são representativos de dispositivos móveis.
A coleta de lixo afeta apenas os dados adicionados aos SourceBuffers. Não há limites para a quantidade de dados que podem ser armazenados em variáveis JavaScript. Você também pode anexar novamente os mesmos dados na mesma posição, se necessário.