
Learn how to optimize for the Time to First Byte metric.


Published: January 19, 2023, Last updated: November 28, 2025
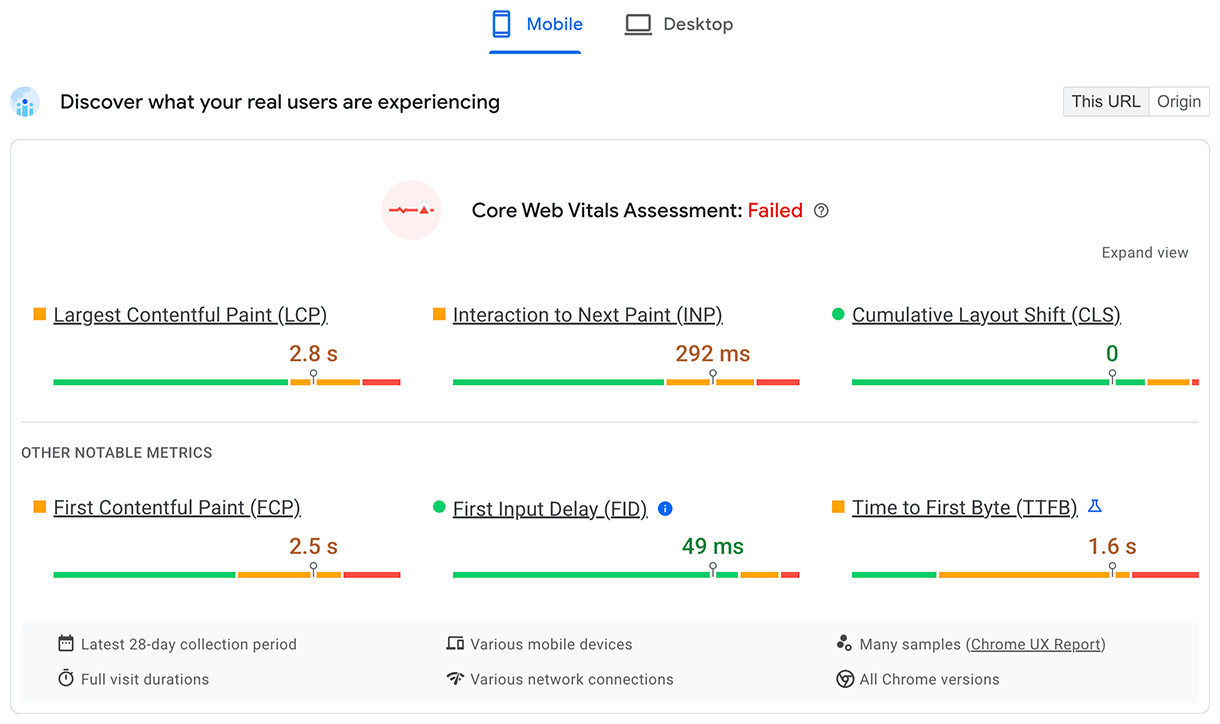
Time to First Byte (TTFB) is a foundational web performance metric that precedes every other meaningful user experience metric such as First Contentful Paint (FCP) and Largest Contentful Paint (LCP). This means that high TTFB values add time to the metrics that follow it.
It's recommended that your server responds to navigation requests quickly enough so that the 75th percentile of users experience an FCP within the "good" threshold. As a rough guide, most sites should strive to have a TTFB of 0.8 seconds or less.

How to Measure TTFB
Before you can optimize TTFB, you need to observe how it affects your website's users. You should rely on field data as a primary source of observing TTFB as it affected by redirects, whereas lab-based tools are often measured using the final URL therefore missing this extra delay.
PageSpeed Insights is one way to get both field and lab information for public websites that are available in the Chrome User Experience Report.
TTFB for real users is shown in the top Discover what your real users are experiencing section:
For lab data, TTFB issues are shown in the Document request latency insight:

To find out more ways how to measure TTFB in both the field and the lab, consult the TTFB metric page.
Understand differences between field and lab TTFB
Lab and field TTFB can differ for a number of reasons and when they do differ, it's important to understand why to be able to effectively use the lab data to improve your user experiences.
When lab TTFB is much larger than field TTFB this indicates that the lab environment is more constrained that the typical user experiences. This isn't necessarily a problem, as the lab results and recommendations are still be valid, but may exaggerate the impact and the improvement.
When field TTFB is much larger than lab TTFB this indicates issues that aren't apparent in the lab run, such as use of server-side caching, redirects, or network differences. In this case, the lab results and recommendations may be less useful, as they miss one of the main issues.
To see if server-side caching is impacting lab TTFB, try testing less common pages or using different URL parameters to get uncached content to see if the TTFB is more inline with field TTFB. It can also be useful to you have the ability to bypass server-side caching with a particular URL parameter. See the cached content section.
For redirects and network differences, analytics of how traffic is coming to our site, and where it's coming from, can be useful to diagnose if those are potential issues.
Debug high TTFB in the field with Server-Timing
The Server-Timing response header can be used in your application backend to measure distinct backend processes that could contribute to high latency. The header value's structure is flexible, accepting, at minimum, a handle that you define. Optional values include a duration value (via dur), as well as an optional human-readable description (via desc).
Serving-Timing can be used to measure many application backend processes, but there are some that you may want to pay special attention to:
- Database queries
- Server-side rendering time, if applicable
- Disk seeks
- Edge server cache hits or misses (if using a CDN)
All parts of a Server-Timing entry are colon-separated, and multiple entries can be separated by a comma:
// Two metrics with descriptions and values
Server-Timing: db;desc="Database";dur=121.3, ssr;desc="Server-side Rendering";dur=212.2
The header can be set using your application backend's language of choice. In PHP, for example, you could set the header like so:
<?php
// Get a high-resolution timestamp before
// the database query is performed:
$dbReadStartTime = hrtime(true);
// Perform a database query and get results...
// ...
// Get a high-resolution timestamp after
// the database query is performed:
$dbReadEndTime = hrtime(true);
// Get the total time, converting nanoseconds to
// milliseconds (or whatever granularity you need):
$dbReadTotalTime = ($dbReadEndTime - $dbReadStartTime) / 1e+6;
// Set the Server-Timing header:
header('Server-Timing: db;desc="Database";dur=' . $dbReadTotalTime);
?>
When this header is set, it surfaces information you can use in both the lab, and in the field.
In the field, any page with a Server-Timing response header set populates the serverTiming property in the Navigation Timing API:
// Get the serverTiming entry for the first navigation request:
performance.getEntries('navigation')[0].serverTiming.forEach(entry => {
// Log the server timing data:
console.log(entry.name, entry.description, entry.duration);
});
In the lab, data from the Server-Timing response header is visualized in the
Timings panel of the Network tab in Chrome DevTools:

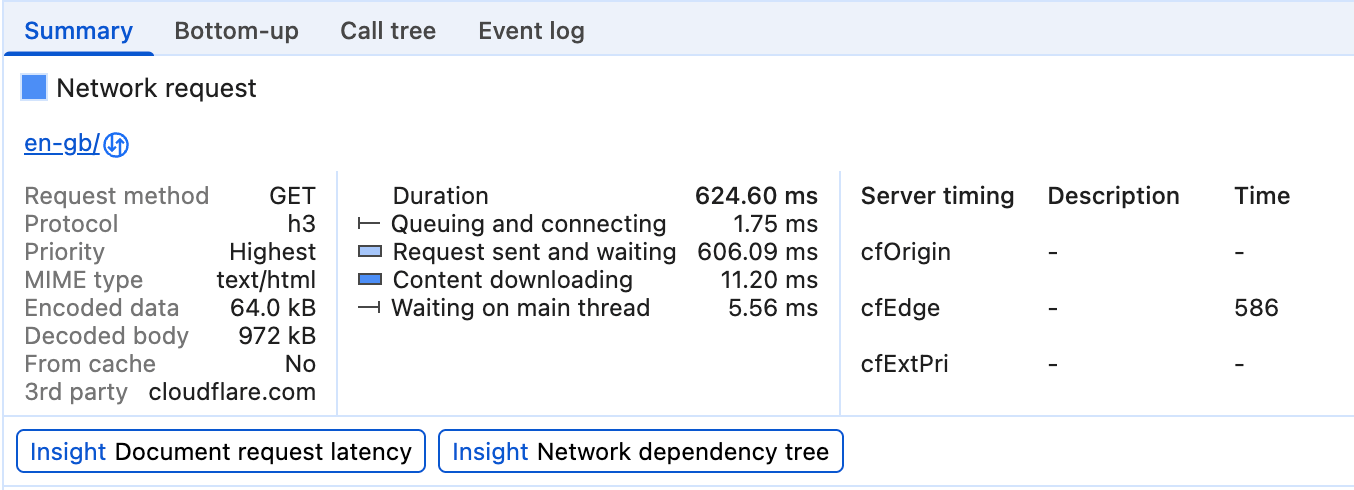
Here, Server-Timing is used to measure whether a request for a resource has hit the CDN cache, and how long it takes for the request to hit the CDN's edge server and then the origin.
Server timings are also surfaced in the Network track of the Performance panel in Chrome DevTools:
Once you've determined that you have a problematic TTFB by analyzing the data available, then you can move onto fixing the problem.
Ways to optimize TTFB
The most challenging aspect of optimizing TTFB is that, while the web's frontend stack is always be HTML, CSS, and JavaScript, backend stacks can vary significantly. There are numerous backend stacks and database products that each have their own optimization techniques. Therefore, this guide focuses on what applies to most architectures, rather than focusing solely on stack-specific guidance.
Platform-specific guidance
The platform you use for your website can heavily impact TTFB. For example, WordPress performance is impacted by the number and quality of plugins, or what themes are used. Other platforms are similarly impacted when the platform is customized. You should consult the documentation for your platform for vendor-specific advice to supplement the more general performance advice in this post. The Lighthouse insight also includes some limited stack-specific guidance.
Hosting, hosting, hosting
Before you even consider other optimization approaches, hosting should be the first thing you consider. There's not much in the way of specific guidance that can be offered here, but a general rule of thumb is to ensure that your website's host is capable of handling the traffic you send to it.
Shared hosting is generally be slower. If you're running a small personal website that serves mostly static files, this is probably fine. Use some of the optimization techniques that follow to help you reduce your TTFB as much as possible.
However, if you're running a larger application with many users that involves personalization, database querying, and other intensive server-side operations, your choice of hosting becomes critical to lower TTFB in the field.
When choosing a hosting provider, these are some things to look out for:
- How much memory is your application instance allocated? If your application has insufficient memory, it will thrash and struggle to serve pages up as fast as possible.
- Does your hosting provider keep your backend stack up to date? As new versions of application backend languages, HTTP implementations, and database software are released, performance in that software improves over time. It's key to partner with a hosting provider that prioritizes this kind of crucial maintenance.
- If you have very specific application requirements and want the lowest level access to server configuration files, ask if it makes sense to customize your own application instance's backend.
There are many hosting providers that take care of these things for you, but if you start to observe long TTFB values even in dedicated hosting providers, it may be a sign that you might need to re-evaluate your current hosting provider's capabilities so that you can deliver the best possible user experience.
Use a Content Delivery Network (CDN)
The topic CDN usage is a well-worn one, but for good reason: you could have a very well-optimized application backend, but users located far from your origin server may still experience high TTFB in the field.
CDNs solve the problem of user proximity from your origin server by using a distributed network of servers that cache resources on servers that are physically closer to your users. These servers are called edge servers.
CDN providers may also offer benefits beyond edge servers:
- CDN providers usually offer extremely fast DNS resolution times.
- A CDN likely serves your content from edge servers using modern protocols such as HTTP/2 or HTTP/3.
- HTTP/3 in particular solves the head-of-line blocking problem present in TCP (which HTTP/2 relies on) by using the UDP protocol.
- A CDN likely provides modern versions of TLS, which lowers the latency involved in TLS negotiation time. TLS 1.3 in particular is designed to keep TLS negotiation as short as possible.
- Some CDN providers provide a feature often called an "edge worker", which uses an API similar to that of the Service Worker API to intercept requests, programmatically manage responses in edge caches, or rewrite responses altogether.
- CDN providers are very good at optimizing for compression. Compression is tricky to get right on your own, and may lead to slower response times in certain cases with dynamically generated markup, which must be compressed on the fly.
- Also, CDN providers automatically cache compressed responses for static resources, leading to the best mix of compression ratio and response time.
While adopting a CDN involves a varying amount of effort from trivial to significant, it should be a high priority to pursue in optimizing your TTFB if your website is not already using one.
Use cached content where possible
CDNs allow content to be cached at edge servers which are located physically closer to visitors, provided the content is configured with the appropriate Cache-Control HTTP headers. While this is not appropriate for personalized content, requiring a trip all the way back to the origin can negate much of the value of a CDN.
For sites that frequently update their content, even a short caching time can result in noticeable performance gains for busy sites, since only the first visitor during that time experiences the fully latency back to the origin server, while all other visitors can reuse the cached resource from the edge server. Some CDNs allow cache invalidation on site releases allowing the best of both worlds—long cache times, but instant updates when needed.
Even where caching is correctly configured, this can be ignored through the use of unique query string parameters for analytics measurement. These may look like different content to the CDN despite being the same, and so the cached version won't be used.
Older or less visited content may also not be cached, which can result in higher TTFB values on some pages than others. Increasing caching times can reduce the impact of this, but be aware that with increased caching times comes a greater possibility of serving potentially stale content.
The impact of cached content does not just affect those using CDNs. Server infrastructure may need to generate content from costly database lookups when cached content cannot be reused. More frequently accessed data or precached pages can often perform better.
Avoid multiple page redirects
One common contributor to a high TTFB is redirects. Redirects occur when a navigation request for a document receives a response that informs the browser that the resource exists at another location. One redirect can certainly add unwanted latency to a navigation request, but it can certainly get worse if that redirect points to another resource that results in another redirect—and so on. This can particularly impact sites that receive high volumes of visitors from advertisements or newsletters, since they often redirect through analytics services for measurement purposes. Eliminating redirects under your direct control can help to achieve a good TTFB.
There are two types of redirects:
- Same-origin redirects, where the redirect occurs entirely on your website.
- Cross-origin redirects, where the redirect occurs initially on another origin—such as from a social media URL shortening service, for example—before arriving at your website.
Focus on eliminating same-origin redirects, as this is something you have direct control over. This would involve checking links on your website to see if any of them result in a 302 or 301 response code. Often this can be the result of not including the https:// scheme (so browsers default to http:// which then redirects) or because trailing slashes are not appropriately included or excluded in the URL.
Cross-origin redirects are trickier as these are often outside of your control, but try to avoid multiple redirects where possible—for example, by using multiple link shorteners when sharing links. Ensure the URL provided to advertisers or newsletters is the correct final URL, so as not to add another redirect to the ones used by those services.
Another important source of redirect time can come from HTTP-to-HTTPS redirects. One way you can get around this is to use the Strict-Transport-Security header (HSTS), which enforces HTTPS on the first visit to an origin, and then tells the browser to immediately access the origin through the HTTPS scheme on future visits.
Once you have a good HSTS policy in place, you can speed things up on the first visit to an origin by adding your site to the HSTS preload list.
Stream markup to the browser
Browsers are optimized to process markup efficiently when it's streamed, meaning that markup is handled in chunks as it arrives from the server. This is crucial where large markup payloads are concerned, as it means the browser can parse that the chunks of markup incrementally, as opposed to waiting for the entire response to arrive before parsing can begin.
Though browsers are great at handling streaming markup, it's crucial to do all that you can to keep that stream flowing so those initial bits of markup are on their way as soon as possible. If the backend is holding things up, that's a problem. Because backend stacks are numerous, it would be beyond the scope of this guide to cover every single stack and the issues that could arise in each specific one.
React, for example—and other frameworks that can render markup on demand on the server—have used a synchronous approach to server-side rendering. However, newer versions of React have implemented server methods for streaming markup as it's being rendered. This means you don't have to wait for a React server API method to render the entire response before it's sent.
Another way to ensure markup is streamed to the browser quickly is to rely on static rendering which generates HTML files during build time. With the full file available immediately, web servers can start sending the file immediately and the inherent nature of HTTP results in streaming markup. While this approach isn't suitable for every page on every website—such as those requiring a dynamic response as part of the user experience—it can be beneficial for those pages that don't require markup to be personalized to a specific user.
Use a service worker
The Service Worker API can have a big impact on the TTFB for both documents and the resources they load. The reason for this is that a service worker acts as a proxy between the browser and the server—but whether there is an impact on your website's TTFB depends on how you set up your service worker, and if that setup aligns with your application requirements.
- Use a stale-while-revalidate strategy for assets. If an asset is in the service worker cache, be it a document or a resource the document requires, the stale-while-revalidate strategy services that resource from the cache first, then downloads that asset in the background and serves it from the cache for future interactions.
- If you have document resources that don't change very often, using a stale-while-revalidate strategy can make a page's TTFB nearly instant. However, this doesn't work so well if your website sends dynamically generated markup—such as markup that changes based on whether a user is authenticated. In such cases, you'll always want to hit the network first, so the document is as fresh as possible.
- If your document loads non-critical resources that change with some frequency, but fetching the stale resource won't greatly affect the user experience—such as select images or other resources that aren't critical—the TTFB for those resources can be greatly reduced using a stale-while-revalidate strategy.
- Use the app shell model for client-rendered applications. This model fits best for SPAs where the "shell" of the page can be delivered instantly from the service worker cache, and the dynamic content of the page is populated and rendered later on in the page lifecycle.
Use 103 Early Hints for render-critical resources
No matter how well your application backend is optimized, there could still be a significant amount of work the server needs to do in order to prepare a response, including expensive (yet necessary) database work that delays the navigation response from arriving as quickly as it could. The potential effect of this is that some subsequent render-critical resources could be delayed, such as CSS or—in some cases—JavaScript that renders markup on the client.
The 103 Early Hints header is an early response code that the server can send to the browser while the backend is busy preparing markup. This header can be used to hint to the browser that there are render-critical resources the page should begin downloading while the markup is being prepared. For supporting browsers, the effect can be faster document rendering (CSS) and quicker page loading.
One downside to 103 Early Hints is that, like caching, they can mask the "real" TTFB of a site. If a server infrastructure is slow (either because it's underpowered or the code needs optimizing), then that can be less obvious when 103 Early Hints is used as the TTFB looks fast. Sites using 103 Early Hints should consider measuring the actual server time (though Server-Timing or finalResponseHeadersStart of the PerformanceNavigationTiming API).
Conclusion
Since there are so many combinations of backend application stacks, there's no one article that can encapsulate everything you can do to lower your website's TTFB. However, these are some options you can explore to try and get things going just a little bit faster on the server side of things.
As with optimizing every metric, the approach is largely similar: measure your TTFB in the field, use lab tools to drill down into the causes, and then apply optimizations where possible. While some techniques may not be viable for your situation, some likely are. As always, you'll need to keep a close eye on your field data, and make adjustments as needed to ensure the fastest possible user experience.