



Publicado em 21 de maio de 2025
A Policybazaar é uma das principais plataformas de seguros da Índia, com mais de 97 milhões de clientes registrados. Cerca de 80% dos clientes visitam a Policybazaar on-line a cada mês. Portanto, é fundamental que as plataformas ofereçam experiências de usuário tranquilas.
A equipe da Policybazaar notou que um número significativo de usuários estava visitando o site à noite, depois do horário de trabalho da equipe de assistência ao cliente. Em vez de esperar até o próximo dia útil para receber respostas ou contratar funcionários de última hora, a Policybazaar queria implementar uma solução para oferecer serviço imediato a esses usuários.
Os clientes têm muitas dúvidas sobre planos de seguro, como eles funcionam e qual seria o melhor para eles. Perguntas personalizadas são difíceis de responder com um FAQ ou chatbots baseados em regras. Para atender a essas necessidades, a equipe implementou assistência personalizada com IA generativa.
73%
Os usuários iniciaram e se engajaram em conversas de qualidade
2x
Taxa de cliques mais alta em comparação com a call-to-action anterior
10x
Inferência mais rápida com a WebGPU
Assistência personalizada com a IA da Finova
Para oferecer respostas personalizadas e melhor assistência ao cliente em inglês e na língua nativa de alguns usuários, a Policybazaar criou um bot de chat de assistente de seguros por texto e voz chamado Finova AI.
Foram necessárias muitas etapas para tornar isso possível. Assista a um tutorial detalhado na palestra Casos de uso e estratégias de IA da Web no mundo real do Google I/O 2025.
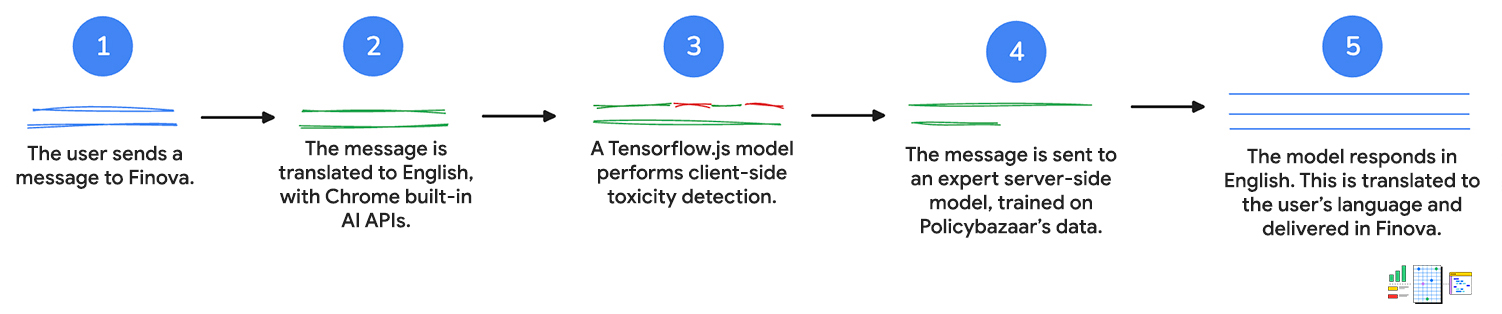
1. Entrada do usuário
Primeiro, o cliente envia uma mensagem para o chatbot, por texto ou por voz. Se o usuário falar com o chatbot, a API Web Speech será usada para converter a voz em texto.
2. Traduzir para o português
A mensagem do cliente é enviada à API Language Detector. Se a API detectar um idioma índico, a entrada será enviada para a API Translator para tradução para inglês.
Ambas as APIs executam a inferência do lado do cliente, o que significa que a entrada do usuário não sai do dispositivo durante a tradução.
3. A mensagem é avaliada com a detecção de toxicidade
Um modelo de detecção de toxicidade do lado do cliente é usado para avaliar se a entrada do cliente contém palavras inadequadas ou agressivas. Se isso acontecer, o cliente vai receber uma solicitação para reformular a mensagem. A mensagem não vai prosseguir para a próxima etapa se tiver linguagem tóxica.
Isso ajuda a manter conversas respeitosas para que a equipe de atendimento ao cliente analise e faça o acompanhamento, se necessário.
4. A solicitação é enviada ao servidor
A consulta traduzida é transmitida a um modelo do lado do servidor treinado com os dados do Policybazaar e retorna uma resposta em inglês para a pergunta.
Os clientes podem receber respostas e recomendações personalizadas, além de respostas a perguntas mais complexas sobre produtos.
5. Traduzir para o idioma do cliente
A API Translator, usada para traduzir a consulta inicial, traduz a consulta de volta para o idioma do cliente, conforme detectado pela API Language Detector. Novamente, essas APIs são executadas do lado do cliente, então todo o trabalho acontece no dispositivo. Isso significa que os clientes podem receber assistência no idioma principal, o que torna o chatbot acessível para quem não fala inglês.
Arquitetura híbrida
A Finova AI, que é executada em plataformas para computador e dispositivos móveis, depende de vários modelos para gerar os resultados finais. A Policybazaar criou uma arquitetura híbrida, em que parte da solução é executada no lado do cliente e parte no lado do servidor.
Há vários motivos para implementar uma arquitetura híbrida, seja usando apenas um ou vários modelos.
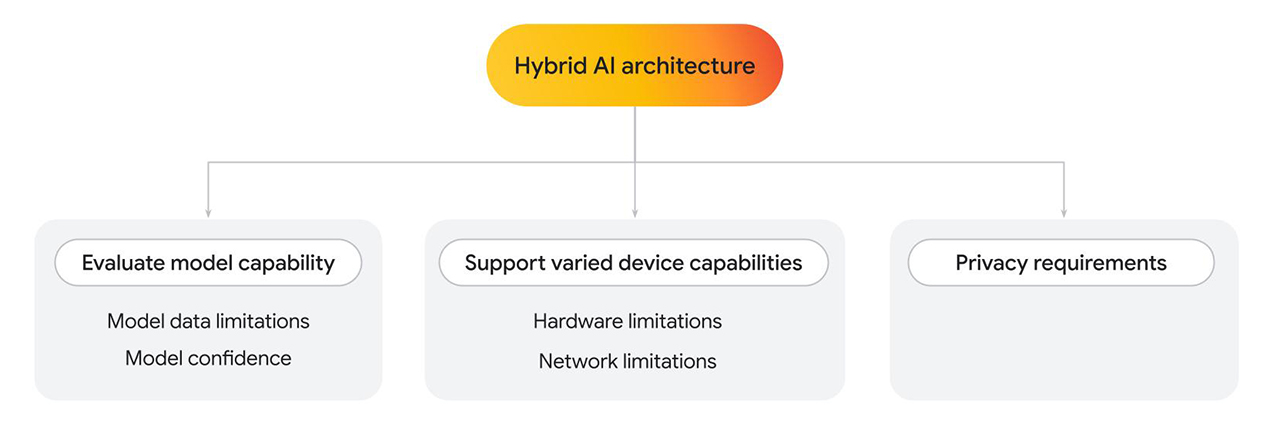
- Avalie o recurso do modelo do cliente. Use o lado do servidor quando necessário.
- Limitações de dados do modelo: os modelos de linguagem podem variar muito em tamanho, o que também determina recursos específicos. Por exemplo, considere uma situação em que um usuário faz uma pergunta pessoal relacionada a um serviço que você está fornecendo. Um modelo do lado do cliente pode responder à pergunta se for treinado nessa área específica. No entanto, se isso não for possível, você poderá usar uma implementação do lado do servidor, que é treinada em um conjunto de dados mais complexo e maior.
- Confiança do modelo: em modelos de classificação, como moderação de conteúdo ou detecção de fraude, um modelo do lado do cliente pode gerar uma pontuação de confiança mais baixa. Nesse caso, é recomendável usar um modelo mais poderoso do lado do servidor.
- Suporte a vários recursos do dispositivo.
- Limitações de hardware: o ideal é que os recursos de IA sejam acessíveis a todos os usuários. Na realidade, os usuários usam uma ampla variedade de dispositivos, e nem todos podem oferecer suporte à inferência de IA. Se um dispositivo não oferecer suporte à inferência do lado do cliente, você poderá usar o servidor como alternativa. Com essa abordagem, é possível tornar o recurso altamente acessível, minimizando o custo e a latência sempre que possível.
- Limitações de rede: se o usuário estiver off-line ou em redes instáveis, mas tiver um modelo armazenado em cache no navegador, será possível executar o modelo do lado do cliente.
- Requisitos de privacidade.
- Você pode ter requisitos de privacidade rigorosos para seu aplicativo. Por exemplo, se parte do fluxo do usuário exigir a verificação de identidade com informações pessoais ou detecção facial, escolha um modelo do lado do cliente para processar dados no dispositivo e enviar a saída de verificação (como aprovação ou reprovação) para o modelo do lado do servidor para as próximas etapas.
Para a Policybazaar, em que baixa latência, eficiência de custo e privacidade eram necessários, uma solução do lado do cliente foi usada. Quando modelos mais complexos treinados em dados personalizados eram necessários, uma solução do lado do servidor era usada.
Aqui, analisamos mais de perto a implementação do modelo do lado do cliente.
Detecção de toxicidade do lado do cliente
Depois que as mensagens são traduzidas, a mensagem do cliente é transmitida ao modelo de detecção de toxicidade do TensorFlow.js, que é executado no lado do cliente, em computadores e dispositivos móveis. Como a transcrição é encaminhada para a equipe de assistência humana para acompanhamento, é importante evitar linguagem tóxica. As mensagens são analisadas no dispositivo do usuário antes de serem enviadas ao servidor, seguidas pela equipe de assistência humana final.
Além disso, a análise do lado do cliente permitiu a remoção de informações sensíveis. A privacidade do usuário é uma prioridade de primeira linha, e a inferência do lado do cliente ajuda a tornar isso possível.
Há várias etapas necessárias para cada mensagem. Com a detecção de toxicidade, além da detecção e tradução de idiomas, cada mensagem exigiria várias idas e vindas ao servidor. Ao realizar essas tarefas no lado do cliente, o Policybazaar poderia limitar significativamente o custo projetado do recurso.
O Policybazaar mudou de WebGL para um back-end da WebGPU (para navegadores com suporte) e o tempo de inferência melhorou 10 vezes. Os usuários receberam feedback mais rápido para revisar a mensagem, o que levou a um maior engajamento e satisfação do cliente.
// Create an instance of the toxicity model.
const createToxicityModelInstance = async () => {
try {
//use WebGPU backend if available
if (navigator.gpu) {
await window.tf.setBackend('webgpu');
await window.tf.ready();
}
return await window.toxicity.load(0.9).then(model => {
return model;
}).catch(error => {
console.log(error);
return null;
});
} catch (er) {
console.error(er);
}
}
Alto engajamento e taxa de cliques
Ao combinar vários modelos com APIs da Web, a Policybazaar conseguiu estender a assistência ao cliente após o horário comercial. Os primeiros resultados de uma versão limitada deste recurso indicaram alto engajamento dos usuários.
73% dos usuários que abriram o chatbot participaram de conversas com várias perguntas que duraram vários minutos, resultando em uma taxa de rejeição baixa. Além disso, o programa piloto demonstrou uma taxa de cliques duas vezes maior para essa nova call-to-action de assistência ao cliente, mostrando a interação bem-sucedida do cliente com a Finova para as consultas. Além disso, a mudança para um back-end da WebGPU para a detecção de toxicidade do lado do cliente acelerou a inferência em 10 vezes, resultando em um feedback do usuário mais rápido.
73%
Os usuários iniciaram e se engajaram em conversas de qualidade
2x
Taxa de cliques mais alta em comparação com a call-to-action anterior
10x
Inferência mais rápida com a WebGPU
Recursos
Se você quiser estender os recursos do seu próprio app da Web com a IA do lado do cliente:
- Saiba como implementar a detecção de toxicidade do lado do cliente.
- Confira uma coleção de demonstrações de IA do lado do cliente.
- Leia sobre o Mediapipe e o Transformers.js. Você pode trabalhar com modelos pré-treinados e integrá-los ao seu aplicativo com JavaScript.
- A coleção de IA no Chrome para desenvolvedores
oferece recursos, práticas recomendadas e atualizações sobre as tecnologias que
alimentam a IA no Chrome e em outros lugares.
- Isso inclui o estudo de caso sobre como Policybazaar e JioHotstar usam as APIs Translator e Language Detector para criar experiências multilíngues.
- Saiba mais sobre exemplos reais de IA da Web no I/O 2025.