
В то время как предиктивный ИИ извлекает полезную информацию из существующих данных, генеративный ИИ идёт ещё дальше и создаёт нечто новое. Он может писать текст, генерировать изображения, создавать код или даже проектировать полноценные пользовательские интерфейсы. Вот несколько распространённых примеров использования генеративного ИИ:
- Создание контента : помощники по написанию текстов на основе искусственного интеллекта могут создавать черновики и дорабатывать уже существующий текст.
- Резюмирование : Такие инструменты, как Google AI Overviews, позволяют сжимать длинные документы, записи совещаний или веб-страницы в краткие, практичные резюме.
- Генерация кода : Инструменты для разработчиков используют генеративный ИИ для написания и рефакторинга кода, повышая производительность разработчиков.
- Создание изображений и графических ресурсов : Используя модели компьютерного зрения, пользователи могут создавать визуальные ресурсы, такие как баннеры и миниатюры.
Цикл генеративного искусственного интеллекта
Большинство моделей генеративного ИИ обучаются с использованием нейронных сетей и трансформерных архитектур . Модели учатся предлагать следующий элемент в последовательности, например, следующее слово, пиксель или ноту, на основе предыдущих.
С математической точки зрения это не так уж далеко от предиктивного ИИ. Оба метода изучают закономерности на основе данных. Разница заключается в масштабе.
В предиктивном ИИ варианты выходных данных ограничены парой меток, таких как «отток» или «отсутствие оттока». В генеративном ИИ пространство выходных данных может включать сотни тысяч вариантов. Обученный на миллиардах примеров, механизм прогнозирования превращается в мощный движок, способный генерировать новые, ранее не встречавшиеся результаты.
Разработка генеративной системы искусственного интеллекта осуществляется итеративным методом.
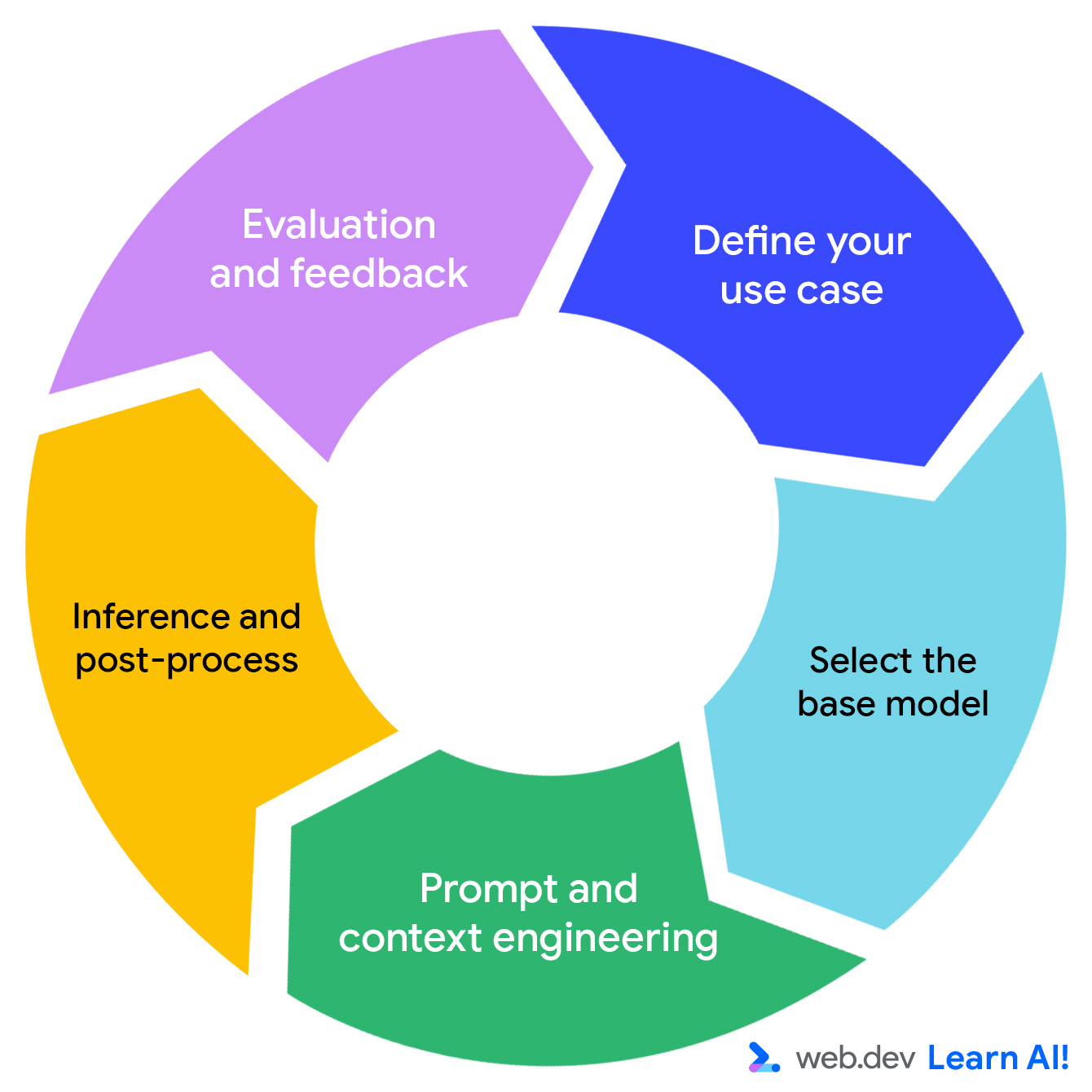
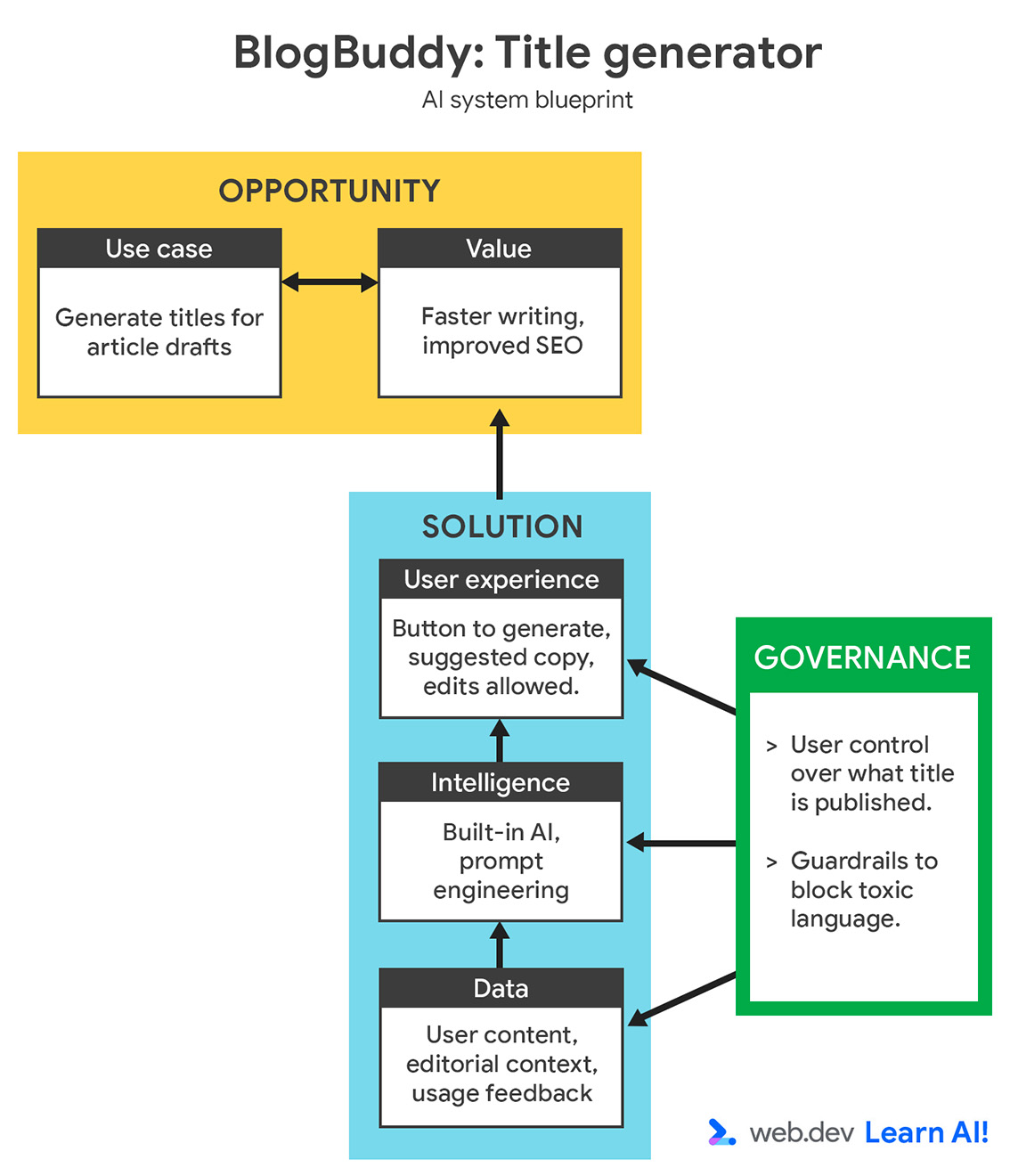
Мы рассмотрим, как это работает, на примере нашего приложения BlogBuddy — помощника в системе управления контентом, который помогает пользователям создавать привлекательные описания и заголовки статей, оптимизированные для поисковых систем.
Определите сценарий использования.
{kind=link}
В формулировке вашей проблемы следует указать:
- Ввод и вывод данных . Это может быть текст (проза или код), изображения или аудио.
- Способ ввода . Получено ли содержимое из поля для загрузки, в виде свободного текста или из других структурированных полей ввода?
- Целевая аудитория . Кто выполняет это задание? Обладают ли они общими знаниями или им необходимы специализированные знания?
Функционал BlogBuddy основан на генерации текста. Ввод данных осуществляется в полуструктурированном формате: пользователи указывают тему или короткий черновик, а модель возвращает варианты. Целевая аудитория — специалисты по маркетингу со специальными знаниями в области редактирования.
Важно установить стандарты качества для результатов своей работы. В нашем случае мы хотим создавать короткие, легко читаемые тексты, насыщенные ключевыми словами, соответствующие тону издания.
Четкие показатели успеха помогут вам направлять весь остальной процесс. Подробнее о сборе показателей успеха вы узнаете в разделе «Разработка, основанная на оценке» .
Выберите базовую модель
Существует широкий спектр доступных моделей, предварительно обученных на больших универсальных наборах данных. Их поведение может быть адаптировано под конкретные потребности. Модели генеративного ИИ, как правило, намного больше и сложнее, чем прогностические модели, поэтому лучше всего использовать уже существующую модель, а не создавать и обучать собственную.
Ваш выбор определяет возможности продукта, его стоимость, возможность настройки и границы конфиденциальности. Выбор модели в значительной степени зависит от платформы, на которой вы развертываете свою систему искусственного интеллекта .
В дальнейшем в рамках этого курса вы научитесь выбирать свою платформу .
Разработка подсказок и контекста
После выбора модели необходимо задать ей правильные инструкции с помощью подсказки. Для BlogBuddy мы можем задать модели следующие инструкции:
Generate three short, engaging title suggestions for this article
В подсказку можно добавить информацию различных типов. Например:
- Системная подсказка, определяющая общее поведение.
- Контекст, специфичный для входных данных, необходимых для выполнения текущей задачи.
- Инструкции для пользователей в диалоговых приложениях, таких как чат-боты или агенты.
Выводы и постобработка
После того, как ваш запрос будет собран, он отправляется в модель для вывода. Вы можете изменить параметры модели , включая температуру (для креативности) и максимальное количество токенов (для длины и детализации), чтобы настроить реакцию модели. После генерации выходные данные часто обрабатываются с помощью дополнительных правил и ограничений.
Например, вы можете переформулировать текст, содержащий гендерные стереотипы, смягчить тон или отфильтровать запрещенные термины.
Для обеспечения прозрачности и калибровки доверия можно добавить меньшую, вторичную модель для классификации или обобщения результата. Например: " Вступление сгенерировано на основе 12 связанных статей. Уровень достоверности: высокий. "
Цикл оценки и обратной связи
Поскольку пространство выходных данных для генеративного ИИ практически бесконечно, большинство запросов не имеют единственно правильного ответа. Стандартизированные бенчмарки, такие как MMLU или SQuAD , могут измерять общие возможности модели, но они редко отражают специфические потребности пользователей. В контексте продукта вам необходимо определить собственное сочетание качественных и количественных метрик:
- Точность : Является ли результат фактически верным?
- Полезность : Соответствует ли результат ожиданиям, заданным в подсказке или намерениям пользователя?
- Читабельность и тон : Ясен ли результат и соответствует ли он стандартам бренда?
- Человеческий труд : Сколько ручной редактуры или отбора требуется?
- Понимание предметной области : Отражает ли результат знания, специфичные для данной предметной области?
Для оценки этих показателей можно сочетать ручную проверку и автоматическую оценку. Например, можно попросить пользователей оценить реальные результаты, использовать вторую модель автоматической оценки (также называемую LLM-в-роли судью ) и проводить периодические внутренние проверки на предмет предвзятости или иллюзорности.
Реальные данные об использовании — один из ваших главных ресурсов при разработке с помощью генеративных моделей. По возможности, регистрируйте эти взаимодействия, чтобы корректировать подсказки и контексты, тестировать различные модели или корректировать параметры с течением времени. Каждое взаимодействие пользователя, исправление или оценка становятся обратной связью, которая поможет вам определить следующие шаги по оптимизации:
- Неожиданные действия пользователя могут помочь определить, решаете ли вы правильную задачу.
- Повторяющиеся запросы, специфичные для конкретной предметной области, могут повлиять на выбор модели. Вы можете перейти от большой, общей модели LLM к небольшой, точно настроенной модели.
- Частые галлюцинации могут указывать на недостаток конкретного контекста в ваших вопросах.
- Значительные изменения могут свидетельствовать о недостаточном объеме общего контекста. Модель не учитывает информацию, которую пользователь принимает как данность.
Со временем эти циклы обратной связи превращают вашу функцию генеративного ИИ из статического вызова модели в живую систему, которая постоянно адаптируется к потребностям и предпочтениям ваших пользователей.
Распространенные ошибки и способы их предотвращения
Поскольку генеративный ИИ работает в открытом пространстве входных и выходных данных, его поверхность риска гораздо шире, чем у систем прогнозирования. Помимо выдачи неверных результатов, он может генерировать токсичный, предвзятый или вводящий в заблуждение контент, а также непреднамеренно манипулировать пользователями. Эти сбои могут подорвать доверие и подвергнуть вашу компанию финансовым или юридическим последствиям.
Именно поэтому генеративный ИИ требует проактивного и постоянного подхода к управлению рисками. Вот некоторые из наиболее распространенных рисков:
- Галлюцинация : Модель искажает факты или излагает детали неточно. Для смягчения последствий используйте RAG для подтверждения фактов.
- Чрезмерное доверие : Пользователи предполагают, что результаты всегда корректны. Чтобы смягчить это, поощряйте процесс проверки и редактирования, а не автоматическую публикацию. В книге «Управление ИИ: ответственное развитие» вы узнаете, как помочь пользователям регулировать уровень своего доверия.
- Непоследовательность : Результаты сильно различаются от запуска к запуску. Для смягчения этой проблемы используйте шаблоны подсказок, контроль температуры или примеры с небольшим количеством сэмплов, чтобы стабилизировать тон и структуру.
- Токсичный или вредный контент : модель генерирует предвзятый, оскорбительный или манипулятивный текст. Для смягчения последствий примените фильтры модерации и классификаторы токсичности перед отображением. Постоянно тестируйте результаты с реальными запросами и поддерживайте обратную связь для выявления и переобучения в крайних случаях.
- Задержка и стоимость : Большие модели могут быть медленными и дорогостоящими. Особенно если вы планируете широкое внедрение, оценить стоимость и потребление ресурсов моделями заранее может быть сложно. Для решения этой проблемы используйте кэширование, пакетную обработку и модели меньшего размера для коротких задач.
Ваши выводы
Вкратце, генеративный ИИ превращает сырые идеи в осязаемый контент, такой как тексты, изображения, код или диалоги. Он процветает там, где креативность и адаптивность важнее точности.
Успех веб-разработчика зависит от правильного проектирования подсказок, использования в модели правильных данных и постоянного согласования системы с предпочтениями пользователей.
Ресурсы
Прочитайте о выборе более компактных и экологичных моделей . Для более подробного изучения:
- Пройдите экспресс-курс по машинному обучению и генеративному искусственному интеллекту .
- Ознакомьтесь с набором инструментов ответственного генеративного искусственного интеллекта .
- Чтобы узнать больше о различных типах базовых моделей в генеративном ИИ, прочтите главу 5 в книге «Искусство разработки продуктов на основе ИИ» .
Проверьте свое понимание
В чём ключевое различие между результатами генеративного ИИ и прогнозного ИИ?
Какова роль модельной температуры?
Почему стандартизированные критерии оценки часто оказываются недостаточными для анализа генеративного ИИ?
Какое из следующих действий является распространенным способом смягчения симптомов галлюцинаций?
Что следует делать с отзывами пользователей в соответствии с принципами генеративного искусственного интеллекта?