
Antes de crear con IA, debes elegir la plataforma en la que se alojará. Tu elección afecta la velocidad, el costo, la escalabilidad y la confiabilidad de tu sistema de IA. Puedes elegir entre las siguientes opciones:
- IA del cliente: Se ejecuta directamente en el navegador. Esto significa que los datos pueden permanecer privados, en el dispositivo del usuario, y no hay latencia de red. Sin embargo, para que funcione bien, la IA del cliente necesita casos de uso muy específicos y bien definidos.
- IA del servidor: Se ejecuta en la nube. Es muy capaz y escalable, pero más costoso en términos de latencia y costo.
Cada opción tiene sus ventajas y desventajas, y la configuración adecuada depende de tu caso de uso, las habilidades de tu equipo y los recursos. Por ejemplo, puedes ofrecer una herramienta de resumen que se ejecute de forma local para que los usuarios puedan hacer preguntas personales sin necesidad de administrar información de identificación personal (PII). Sin embargo, un agente de asistencia al cliente podría brindar respuestas más útiles si usara un modelo basado en la nube que tenga acceso a una gran base de datos de recursos.
En este módulo, aprenderás a hacer lo siguiente:
- Compara las ventajas y desventajas de la IA del cliente y del servidor.
- Adapta tu plataforma a tu caso de uso y a las capacidades de tu equipo.
- Diseña sistemas híbridos que ofrezcan IA en el cliente y el servidor para crecer con tu producto.
Revisa las opciones
Para la implementación, piensa en las plataformas de IA en función de dos ejes principales. Puede elegir una de las siguientes opciones:
- Dónde se ejecuta el modelo: ¿Se ejecuta del lado del cliente o del servidor?
- Personalización: ¿Cuánto control tienes sobre el conocimiento y las capacidades del modelo? Si puedes controlar el modelo, es decir, modificar los pesos del modelo, puedes personalizar su comportamiento para que cumpla con tus requisitos específicos.
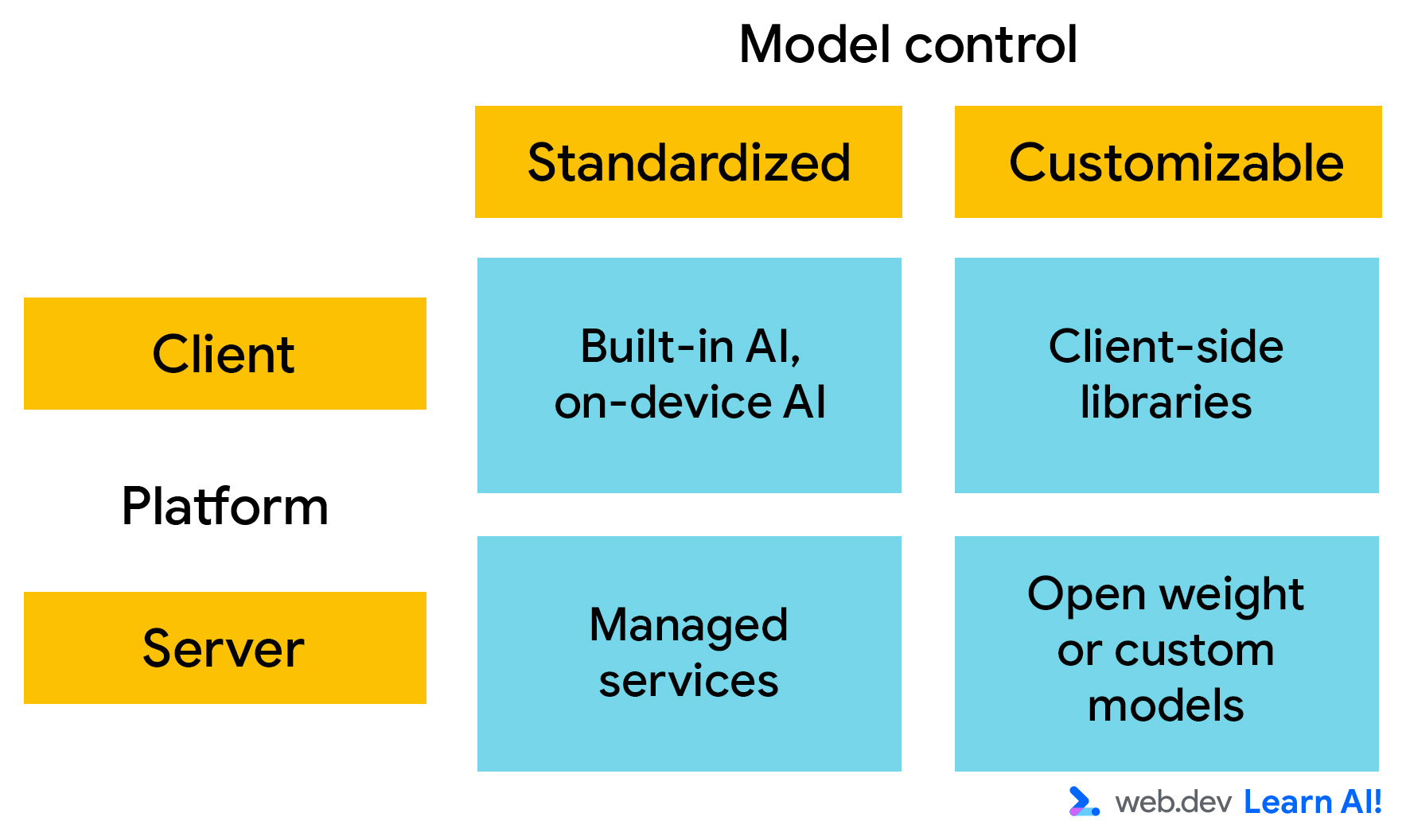
IA del cliente
La IA del cliente se ejecuta en el navegador y el procesamiento se realiza de forma local en el dispositivo del usuario. No necesitas proporcionar recursos de procesamiento en el tiempo de inferencia, y los datos permanecen en la máquina del usuario. Esto lo hace rápido, privado y adecuado para experiencias interactivas y ligeras.
Sin embargo, los modelos del cliente suelen ser bastante pequeños, lo que puede limitar sus capacidades y rendimiento. Son más adecuados para tareas muy especializadas, como la detección de toxicidad o el análisis de opiniones. A menudo, se trata de tareas de IA predictiva con un espacio de salida limitado.
Existen dos opciones principales:
- IA integrada: Los navegadores, como Google Chrome y Microsoft Edge, están integrando modelos de IA. Se puede acceder a ellos a través de llamadas de JavaScript, sin necesidad de configuración ni hosting. Una vez que se descarga el modelo, todos los sitios web que lo usan pueden llamarlo.
- Modelos personalizados: Puedes usar bibliotecas del cliente, como Transformers.js y MediaPipe, para integrar modelos en tu aplicación. Esto significa que puedes controlar los pesos del modelo. Sin embargo, eso también significa que cada usuario de tu sitio web debe descargar tu modelo personalizado. Incluso los modelos de IA más pequeños son grandes en el contexto de un sitio web.
IA del servidor
Con la IA del servidor, tu aplicación web llama a una API para enviar entradas al modelo de IA y recibir sus salidas. Esta configuración admite modelos más grandes y complejos, y es independiente del hardware del usuario.
Las dos categorías de IA del servidor son las siguientes:
- Servicios administrados: Son modelos alojados en centros de datos por un tercero, como Gemini 3 y GPT-5. El propietario del modelo proporciona una API para acceder a él. Esto significa que puedes usar modelos de vanguardia con una configuración mínima. Son ideales para la creación rápida de prototipos, conversaciones abiertas y razonamiento de uso general. Sin embargo, el escalamiento en un servicio administrado puede ser costoso.
- Modelos autoalojados: Puedes implementar modelos de código abierto, como Gemma o Llama, en tu propia infraestructura o en un contenedor administrado, como Vertex AI o Hugging Face Inference. Este enfoque significa que puedes aprovechar el entrenamiento previo que realizó el creador del modelo, pero mantienes el control sobre el modelo, los datos de ajuste y el rendimiento.
Elige una plataforma inicial
Revisa las características de arquitectura de las plataformas de IA y analiza las compensaciones para decidir tu configuración inicial.
Define tus requisitos de arquitectura
Con cada decisión, debes llegar a acuerdos. Consulta las características clave que definen el costo y el valor de tu plataforma de IA:
- Potencia del modelo: Indica qué tan bien se desempeña el modelo en una amplia variedad de usuarios y tareas, sin necesidad de ajustarlo. A menudo, esto se correlaciona con el tamaño del modelo.
- Capacidad de personalización: Es el grado en el que puedes ajustar, modificar o controlar el comportamiento y la arquitectura del modelo.
- Precisión: Calidad y confiabilidad generales de las predicciones o generaciones del modelo
- Privacidad: Es el grado en que los datos del usuario permanecen locales y bajo su control.
- Costo fijo: Es el gasto recurrente necesario para operar el sistema de IA, independientemente del uso, incluido el aprovisionamiento y el mantenimiento de la infraestructura.
- Costo por solicitud: Es el costo adicional de cada solicitud entrante.
- Compatibilidad: Indica qué tan ampliamente funciona el enfoque en diferentes navegadores, dispositivos y entornos sin lógica de resguardo.
- Comodidad del usuario: Indica si los usuarios deben realizar pasos adicionales para usar el sistema de IA, como descargar un modelo.
- Comodidad para los desarrolladores: Qué tan rápido y fácil es para la mayoría de los desarrolladores implementar, integrar y mantener el modelo, sin necesidad de experiencia especializada en IA
En la siguiente tabla, se proporciona un ejemplo de las estimaciones sobre el rendimiento de cada plataforma para cada criterio, en el que 1 es el valor más bajo y 5 es el más alto.
| Criterios | Cliente | Servidor | ||
| IA integrada o en el dispositivo | Modelo personalizado | Servicio administrado | Modelo alojado por el usuario | |
| Potencia del modelo |
¿Por qué se le asignan 2 estrellas a la potencia del modelo?La IA integrada y en el dispositivo usa modelos de navegador pequeños y precargados que están optimizados para funciones específicas y limitadas, en lugar de conversaciones o razonamientos abiertos. |
¿Por qué 3 estrellas para la potencia del modelo?Las bibliotecas personalizadas del cliente ofrecen más flexibilidad que la IA integrada, pero aún estás limitado por el tamaño de descarga, los límites de memoria y el hardware del usuario. |
¿Por qué 4 estrellas para la potencia del modelo?Con los servicios administrados y el alojamiento propio, tienes acceso a modelos grandes y de vanguardia, capaces de realizar razonamientos complejos, manejar contextos extensos y abarcar una amplia gama de tareas. |
|
| Personalización |
¿Por qué le otorgamos 1 estrella a la personalización?Los modelos integrados no permiten el acceso a los pesos del modelo ni a los datos de entrenamiento. La principal forma de personalizar su comportamiento es a través de la ingeniería de instrucciones. |
¿Por qué le otorgamos 5 estrellas a la capacidad de personalización?Esta opción te permite controlar la selección y los pesos del modelo. Muchas bibliotecas del cliente también permiten el ajuste y el entrenamiento de modelos. |
¿Por qué le otorgamos 1 estrella a la personalización?Los servicios administrados exponen modelos potentes, pero ofrecen un control mínimo sobre su comportamiento interno. Por lo general, la personalización se limita a las instrucciones y al contexto de entrada. |
¿Por qué 5 estrellas en la categoría de personalización?Los modelos alojados por el usuario proporcionan control total sobre los pesos del modelo, los datos de entrenamiento, la optimización y la configuración de la implementación. |
| Exactitud |
¿Por qué 2 estrellas para la precisión?La precisión de los modelos integrados es suficiente para las tareas bien definidas, pero el tamaño y la generalización limitados del modelo reducen la confiabilidad para las entradas complejas o matizadas. |
¿Por qué 3 estrellas para la precisión?La exactitud del modelo personalizado del cliente se puede mejorar en el proceso de selección del modelo. Sin embargo, sigue estando limitado por el tamaño del modelo, la cuantificación y la variabilidad del hardware del cliente. |
¿Por qué 5 estrellas para la precisión?Por lo general, los servicios administrados ofrecen una exactitud relativamente alta, ya que se benefician de modelos grandes, datos de entrenamiento extensos y mejoras continuas del proveedor. |
¿Por qué 4 estrellas para la precisión?La precisión puede ser alta, pero depende del modelo seleccionado y del esfuerzo de ajuste. El rendimiento puede ser inferior al de los servicios administrados. |
| Latencia de red |
¿Por qué 5 estrellas para la latencia de red?El procesamiento ocurre directamente en el dispositivo del usuario. |
¿Por qué 2 estrellas para la latencia de la red?Hay un viaje de ida y vuelta a un servidor. |
||
| Privacidad |
¿Por qué 5 estrellas para la privacidad?De forma predeterminada, los datos del usuario deben permanecer en el dispositivo, lo que minimiza la exposición de los datos y simplifica el cumplimiento de la privacidad. |
¿Por qué le otorgamos 2 estrellas a la privacidad?Las entradas del usuario deben enviarse a servidores externos, lo que aumenta la exposición de los datos y los requisitos de cumplimiento. Sin embargo, existen soluciones específicas para mitigar los problemas de privacidad, como Private AI Compute. |
¿Por qué 3 estrellas para la privacidad?Los datos permanecen bajo el control de tu organización, pero aun así salen del dispositivo del usuario y requieren medidas de cumplimiento y manejo seguro. |
|
| Costo fijo |
¿Por qué 5 estrellas para el costo fijo?Los modelos se ejecutan en los dispositivos existentes de los usuarios, por lo que no hay costos adicionales de infraestructura. |
¿Por qué 5 estrellas para el costo fijo?La mayoría de las APIs cobran según el uso, por lo que no hay un costo fijo. |
¿Por qué 2 estrellas para el costo fijo?Los costos fijos incluyen la infraestructura, el mantenimiento y la sobrecarga operativa. |
|
| Costo por solicitud |
¿Por qué 5 estrellas para el costo por solicitud?No hay un costo por solicitud, ya que la inferencia se ejecuta en el dispositivo del usuario. |
¿Por qué 2 estrellas para el costo por solicitud?Los servicios administrados suelen tener precios por solicitud. Los costos de escalamiento pueden volverse significativos, en especial con volúmenes de tráfico altos. |
¿Por qué 3 estrellas para el costo por solicitud?No hay un costo directo por solicitud; el costo efectivo por solicitud depende del uso de la infraestructura. |
|
| Compatibilidad |
¿Por qué 2 estrellas para la compatibilidad?La disponibilidad varía según el navegador y el dispositivo, y requiere alternativas para los entornos no compatibles. |
¿Por qué 1 estrella para la compatibilidad?La compatibilidad depende de las capacidades de hardware y la compatibilidad con el tiempo de ejecución, lo que limita el alcance en los dispositivos. |
¿Por qué 5 estrellas para la compatibilidad?Las plataformas del servidor son compatibles con todos los usuarios, ya que la inferencia se realiza en el servidor y los clientes solo consumen una API. |
|
| Comodidad del usuario |
¿Por qué 3 estrellas para la comodidad del usuario?Por lo general, es un proceso fluido una vez que está disponible, pero la IA integrada requiere una descarga inicial del modelo y compatibilidad con el navegador. |
¿Por qué 2 estrellas para la comodidad del usuario?Los usuarios pueden experimentar retrasos debido a descargas o hardware no compatible. |
¿Por qué 4 estrellas para la comodidad del usuario?Funciona de inmediato sin necesidad de descargas ni requisitos del dispositivo, lo que brinda una experiencia del usuario fluida. Sin embargo, es posible que haya un retraso si la conexión de red es baja. |
|
| Comodidad para los desarrolladores |
¿Por qué 5 estrellas para la comodidad del desarrollador?La IA integrada requiere una configuración mínima, no necesita infraestructura y requiere poca experiencia en IA, lo que facilita su integración y mantenimiento. |
¿Por qué 2 estrellas para la comodidad del desarrollador?Requiere la administración de modelos, tiempos de ejecución, optimización del rendimiento y compatibilidad en todos los dispositivos. |
¿Por qué 4 estrellas para la comodidad del desarrollador?Los servicios administrados simplifican la implementación y el escalamiento. Sin embargo, aún requieren integración de API, administración de costos y diseño de instrucciones. |
¿Por qué 1 estrella por la comodidad del desarrollador?Una implementación personalizada del servidor requiere una gran experiencia en infraestructura, administración de modelos, supervisión y optimización. |
| Esfuerzo de mantenimiento |
¿Por qué 4 estrellas para el esfuerzo de mantenimiento?Los navegadores controlan las actualizaciones y la optimización de los modelos, pero los desarrolladores deben adaptarse a los cambios en la disponibilidad. |
¿Por qué 2 estrellas para el esfuerzo de mantenimiento?Requiere actualizaciones continuas para los modelos, el ajuste del rendimiento y la compatibilidad a medida que evolucionan los navegadores y los dispositivos. |
¿Por qué 5 estrellas para el esfuerzo de mantenimiento?El proveedor se encarga del mantenimiento. |
¿Por qué 2 estrellas para el esfuerzo de mantenimiento?Requiere mantenimiento continuo, incluidas actualizaciones del modelo, administración de la infraestructura, escalamiento y seguridad. |
Analiza las ventajas y desventajas
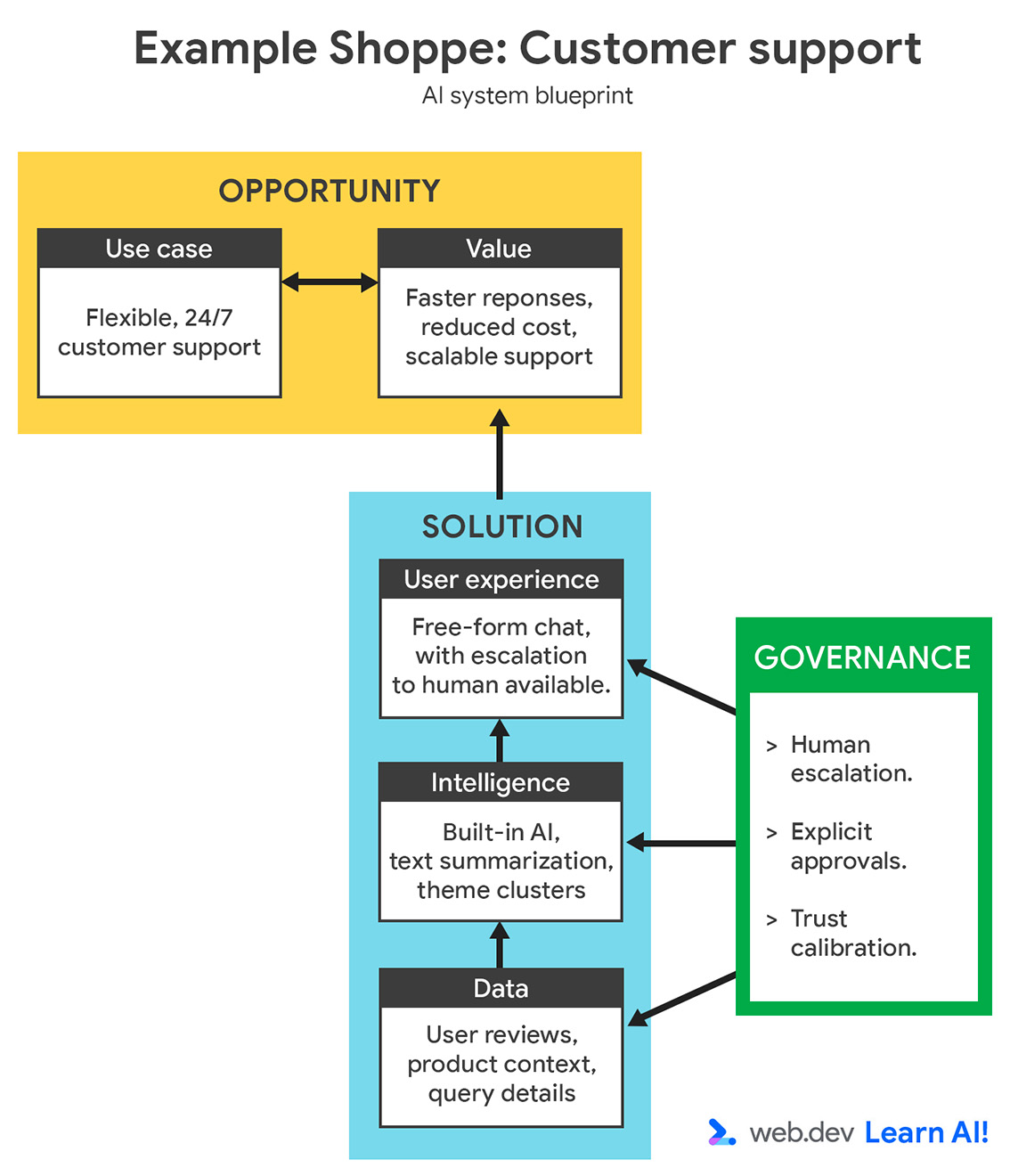
Para ilustrar el proceso de toma de decisiones, agregaremos otra función a Example Shoppe, una plataforma de comercio electrónico de tamaño mediano. Te interesa ahorrar costos en el servicio de atención al cliente fuera del horario de atención, por lo que decides crear un asistente potenciado por IA para responder las preguntas de los usuarios sobre pedidos, devoluciones y productos.
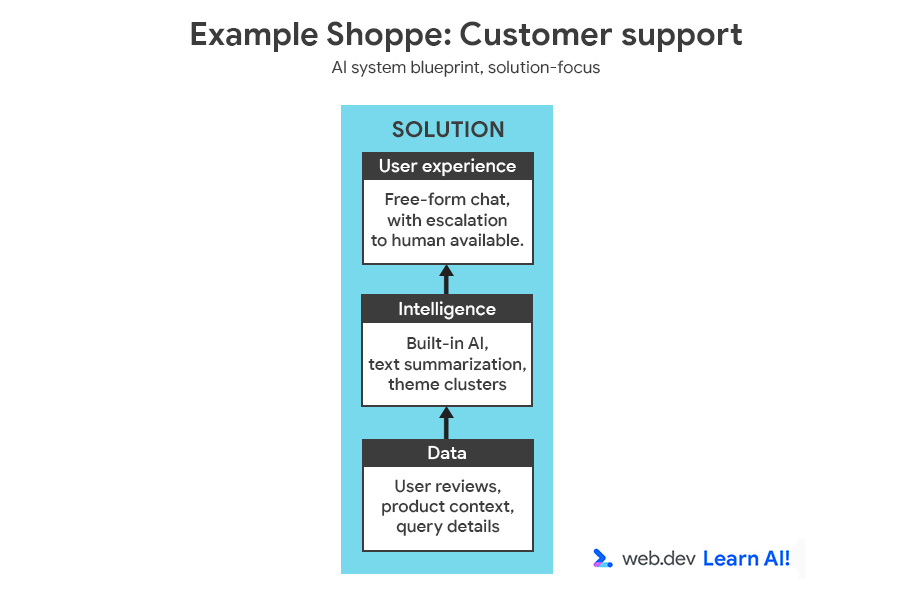
Puedes revisar el plano completo del sistema de IA, que incluye la oportunidad y la solución.
{kind=link}
Analiza la situación con dos enfoques: los requisitos del caso de uso y las restricciones comerciales o del equipo.
| Requisito | Análisis | Criterios | Implicación |
| Alta precisión y versatilidad | Los usuarios hacen una variedad de preguntas complejas sobre pedidos, productos y devoluciones. | Potencia y precisión del modelo | Requiere un modelo de lenguaje grande (LLM). |
| Especificidad de los datos | Debe responder preguntas específicas sobre los datos, los productos y las políticas de la empresa. | Personalización | Requiere transferencia de datos, como RAG, pero no ajuste del modelo. |
| Requisito | Análisis | Criterios | Implicación |
| Base de usuarios | Cientos de miles de usuarios | Escalabilidad y compatibilidad | Requiere una arquitectura que maneje un tráfico alto y confiable. |
| Enfoque posterior al lanzamiento | El equipo se dedicará a otros proyectos después del lanzamiento de la versión 1. | Esfuerzo de mantenimiento | Necesitas una solución con un mantenimiento continuo mínimo. |
| Experiencia del equipo | Desarrolladores web sólidos con experiencia limitada en IA/AA | Comodidad para los desarrolladores | La solución debe ser fácil de implementar e integrar sin necesidad de habilidades especializadas en IA. |
Ahora que priorizaste tus criterios, puedes consultar la tabla de estimación de compensaciones para determinar qué plataforma coincide con tus criterios de mayor prioridad:
En este desglose, queda claro que debes usar la IA del servidor y, probablemente, un servicio administrado. Esto ofrece un modelo versátil para preguntas complejas de los clientes. Minimiza el esfuerzo de mantenimiento y desarrollo, ya que delega la infraestructura, la calidad del modelo y el tiempo de actividad al proveedor.
Si bien la personalización es limitada, vale la pena hacer este intercambio para un equipo de desarrollo web con experiencia limitada en ingeniería de modelos.
Una configuración de generación mejorada por recuperación (RAG) puede ayudarte a proporcionar el contexto pertinente al modelo en el momento de la inferencia.
Hybrid AI
Los sistemas de IA consolidados rara vez se ejecutan en una sola plataforma o con un solo modelo. En cambio, distribuyen las cargas de trabajo de IA para optimizar las compensaciones.
Identifica oportunidades para la IA híbrida
Una vez que lo lances, deberás definir mejor tus requisitos en función de los datos y los comentarios reales. En nuestro ejemplo, Example Shoppe, esperas unos meses para analizar los resultados y encuentras lo siguiente:
- Alrededor del 80% de las solicitudes son repetitivas ("¿Dónde está mi pedido?", "¿Cómo devuelvo este artículo?"). Enviar estas solicitudes a un servicio administrado genera muchos costos y sobrecarga.
- Solo el 20% de las solicitudes requieren un razonamiento más profundo y una conversación interactiva y abierta.
Un modelo local ligero podría clasificar las entradas del usuario y responder consultas de rutina, como "¿Cuál es su política de devoluciones?". Puedes enrutar preguntas complejas, poco frecuentes o ambiguas al modelo del servidor.
Si implementas la IA tanto del lado del servidor como del cliente, puedes reducir los costos y la latencia, y, al mismo tiempo, mantener el acceso a un razonamiento potente cuando sea necesario.
Distribuye la carga de trabajo
Para compilar este sistema híbrido para Example Shoppe, debes comenzar por definir el sistema predeterminado. En este caso, lo mejor es comenzar del lado del cliente. La aplicación debe enrutar a la IA del servidor en dos casos:
- Respaldo basado en la compatibilidad: Si el dispositivo o el navegador del usuario no pueden controlar la solicitud, se debe recurrir al servidor.
- Derivación basada en capacidades: Si la solicitud es demasiado compleja o abierta para el modelo del cliente, según los criterios predeterminados, se debe derivar a un modelo más grande del servidor. Podrías usar un modelo para clasificar la solicitud como común, de modo que realices la tarea del lado del cliente, o como poco común, y envíes la solicitud al sistema del servidor. Por ejemplo, si el modelo del cliente determina que la pregunta está relacionada con un problema poco común, como obtener un reembolso en una moneda diferente.
La flexibilidad introduce más complejidad
Distribuir las cargas de trabajo entre dos plataformas te brinda más flexibilidad, pero también agrega complejidad:
- Organización: Dos entornos de ejecución significan más partes móviles. Necesitas lógica para el enrutamiento, los reintentos y las copias de seguridad.
- Control de versiones: Si usas el mismo modelo en todas las plataformas, debe seguir siendo compatible en ambos entornos.
- Ingeniería de instrucciones y de contexto: Si usas diferentes modelos en cada plataforma, debes realizar ingeniería de instrucciones para cada uno.
- Supervisión: Los registros y las métricas se dividen y requieren un esfuerzo adicional de unificación.
- Seguridad: Mantienes dos superficies de ataque. Tanto los extremos locales como los de la nube deben reforzarse.
Esta es otra compensación que debes tener en cuenta. Si tienes un equipo pequeño o estás creando una función no esencial, es posible que no quieras agregar esta complejidad.
Tus conclusiones
Espera que tu elección de plataforma evolucione. Comienza con el caso de uso, alinea tu estrategia con la experiencia y los recursos de tu equipo, y realiza iteraciones a medida que crezcan tu producto y tu madurez en la IA. Tu tarea es encontrar la combinación adecuada de velocidad, privacidad y control para tus usuarios y, luego, crear con cierta flexibilidad. De esta manera, puedes adaptarte a los requisitos cambiantes y aprovechar las futuras actualizaciones de la plataforma y el modelo.
Recursos
- Dado que la elección de la plataforma y el modelo son interdependientes, obtén más información sobre la selección de modelos.
- Descubre cómo ir más allá de la nube con la IA híbrida y del cliente
Verifica tus conocimientos
¿Cuáles son las dos consideraciones principales a la hora de seleccionar una plataforma de IA para tu aplicación?
¿Cuándo un servicio administrado del servidor, como Gemini Pro, es la mejor opción para tu plataforma?
¿Cuál es el principal beneficio de implementar un sistema de IA híbrido?