
La IA predictiva (o analítica) es un conjunto de algoritmos que te ayudan a comprender los datos existentes y predecir lo que es probable que suceda a continuación. Según los patrones históricos, los modelos predictivos de IA aprenden diferentes tareas analíticas que ayudan a los usuarios a comprender sus datos:
- Clasificación: Agrupa elementos en categorías predefinidas según patrones en los datos. Por ejemplo, una tienda en línea puede clasificar a los visitantes según su intención (investigación, compra, devoluciones) para adaptar sus recomendaciones en consecuencia.
- Regresión: Predice valores numéricos, como el porcentaje de participación, la duración de la sesión o la probabilidad de conversión.
- Recomendación: Sugiere los elementos más relevantes para un usuario o contexto determinado. Piensa en "los usuarios como tú también vieron" o "instructivos recomendados según tu progreso".
- Previsión y detección de anomalías: El modelo predice eventos futuros, como un aumento repentino del tráfico, o identifica comportamientos inusuales, como anomalías en los pagos o fraudes.
Algunos productos se basan completamente en la IA predictiva, como las herramientas de descubrimiento de música. En otros, la IA predictiva mejora una experiencia determinística, como un sitio web de transmisión con recomendaciones personalizadas. La IA predictiva también puede ser un potente habilitador interno: puedes usarla para analizar los datos de los productos y los usuarios, descubrir estadísticas y guiar las próximas acciones de forma más inteligente.
El ciclo de la IA predictiva
El desarrollo de un sistema predictivo de IA sigue un ciclo iterativo: define tu oportunidad, prepara tus datos, entrena el modelo, evalúa el modelo y, luego, impleméntalo.
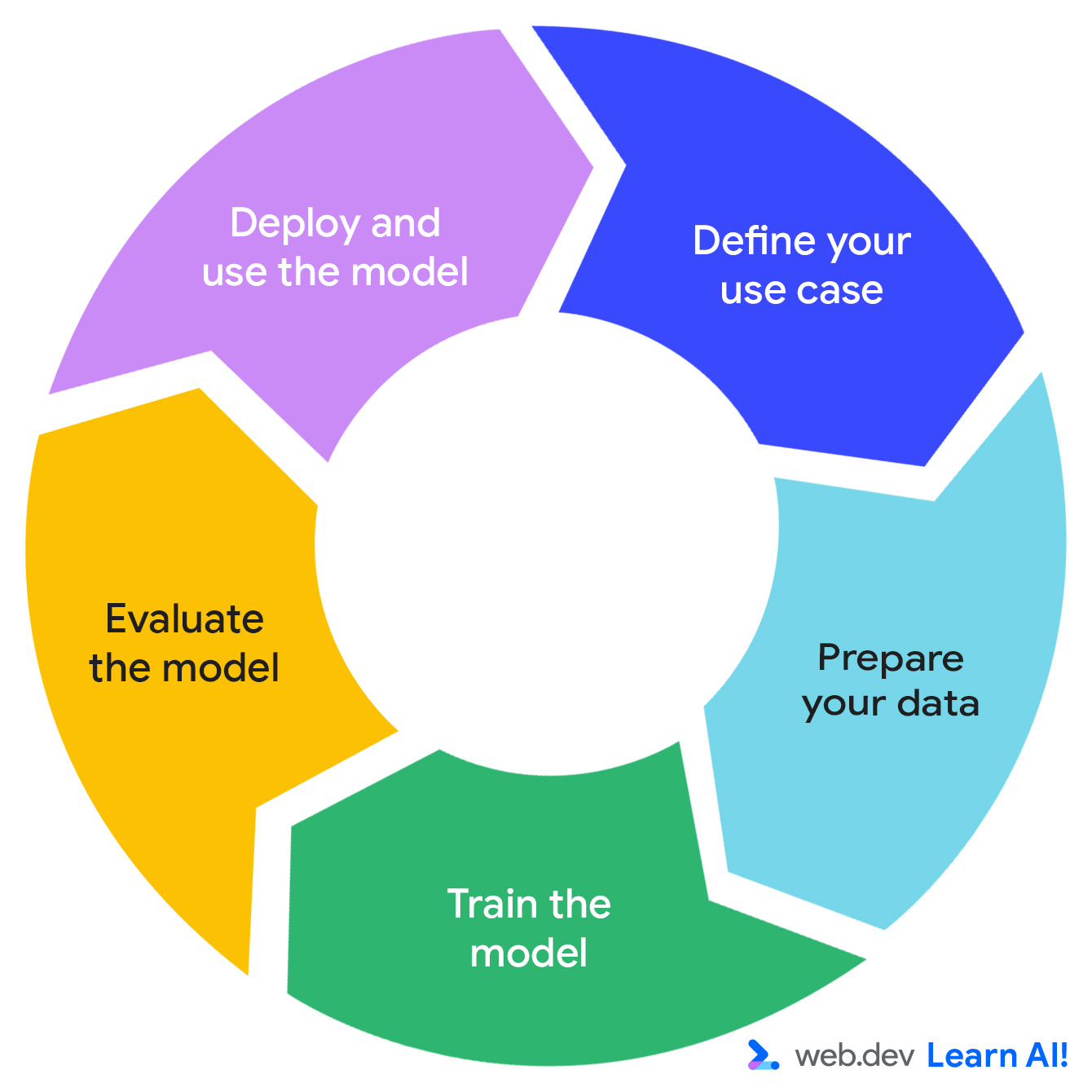
Imagina que estás trabajando en una app de productividad basada en suscripciones llamada Do All The Things. Ya recopilas datos de uso, como las vistas de página, la duración de la sesión, el uso de funciones y las renovaciones de suscripciones. Ahora, deseas extraer más valor práctico de los datos. A continuación, te explicamos cómo viajar por el ciclo de la IA predictiva.
Define tu caso de uso
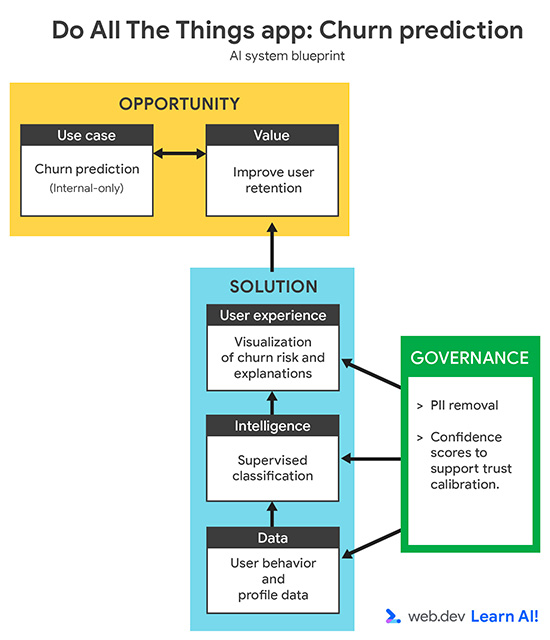
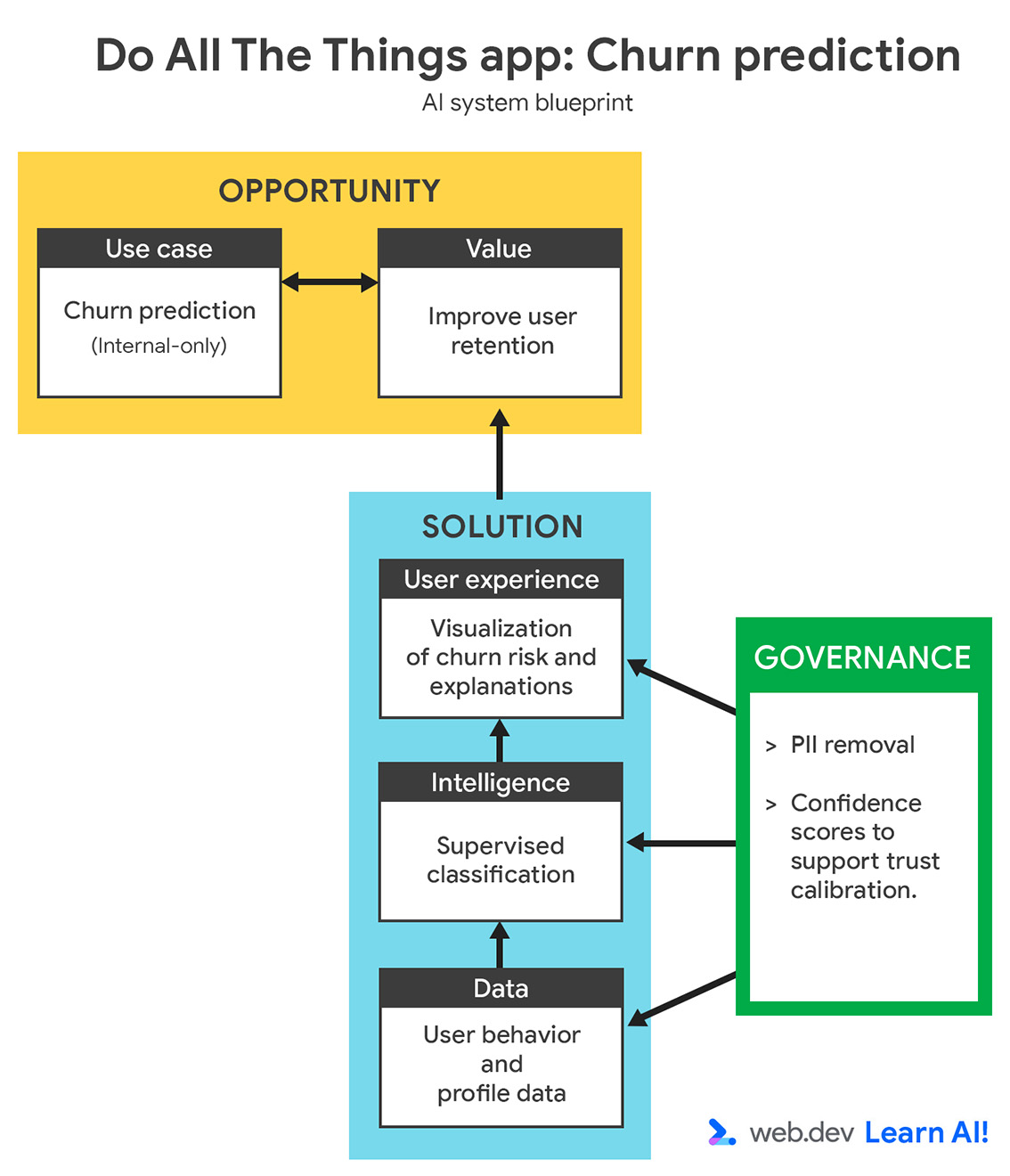{kind=link}
Tu tasa de deserción aumentó en los últimos tres meses. En lugar de reaccionar después de que los usuarios cancelan, debes usar la IA predictiva para identificar a los usuarios que probablemente abandonen la plataforma antes de que cancelen. El objetivo es brindar asistencia a tu equipo de éxito del cliente con indicadores anticipados para que puedan tomar medidas proactivas y específicas para retener a los usuarios en riesgo.
Cuando definas un caso de uso de IA predictiva, comienza por validar que la pregunta se pueda responder con datos. Pueden ser datos que ya recopilaste o que podrías recopilar de forma realista en el futuro. Este paso suele requerir la colaboración de expertos en el dominio, como los equipos de Éxito del Cliente, Crecimiento o Marketing, para garantizar que la predicción sea significativa y práctica.
Una definición del problema sólida debe especificar lo siguiente:
- Objetivo: ¿Qué resultado comercial intentas influir? Por ejemplo, deseas reducir la deserción habilitando la comunicación proactiva.
- Datos de entrada: ¿Qué indicadores históricos aprende el modelo? Por ejemplo, proporcionas patrones de uso, tipos de planes e interacciones de asistencia.
- Salida: ¿Qué producirá el modelo? Por ejemplo, deseas que el modelo cree una puntuación de probabilidad de abandono para cada usuario.
- Usuario: ¿Quién usa la predicción o actúa en función de ella? Por ejemplo, estos datos están destinados a los gerentes de Éxito del Cliente.
- Criterios de éxito: ¿Cómo mides el impacto? Por ejemplo, mides la tasa de retención para determinar si redujiste la deserción.
Si identificas estos detalles al principio, puedes evitar una trampa común: crear un modelo personalizado que sea técnicamente sólido, pero que nunca se use.
Prepara los datos
Para proporcionar a tu modelo indicadores de aprendizaje útiles, debes etiquetar tus datos históricos con predicciones ideales. Etiqueta a los usuarios de Do All The Things como "desertados" o "no desertados".
A continuación, colabora con tu equipo de éxito del cliente para identificar qué funciones de comportamiento son más relevantes para la predicción de la deserción. Reduce tu conjunto de datos a estas características clave y quita los campos innecesarios para que tu modelo no tenga que lidiar con el ruido. Recuerda tener en cuenta la privacidad de los datos. Quita la información de identificación personal (PII), como nombres o correos electrónicos, y solo almacena datos de comportamiento agregados.
En la siguiente tabla, se muestra un fragmento del conjunto de datos resultante:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | premium | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | Google AI Pro por 6 meses | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | gratis | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | premium | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | Google AI Pro por 6 meses | 4.2 | 2 | 1 | 3 | 1 |
Esto le proporciona a tu modelo entradas numéricas y categóricas limpias (como plan_type o avg_session_time) y una etiqueta objetivo clara (churned). Las categorías se deben convertir en identificadores numéricos únicos.
Por último, divide tu conjunto de datos en tres subconjuntos:
- Conjunto de entrenamiento (por lo general, entre el 70 y el 80%) para enseñarle al modelo
- Conjunto de validación (a veces también llamado conjunto de desarrollo) para ajustar los hiperparámetros y evitar el sobreajuste.
- Conjunto de prueba para evaluar el rendimiento del modelo en datos completamente no vistos.
Esto ayuda a tu modelo a generalizar las decisiones en lugar de depender de ejemplos históricos memorizados.
Entrena el modelo
A diferencia de la IA generativa, que a menudo se basa en modelos grandes previamente entrenados, la mayoría de los sistemas de IA predictiva se basan en modelos autoentrenados. Esto se debe a que las tareas predictivas son muy específicas para tu producto y tus usuarios. Herramientas como scikit-learn (Python), AutoML (sin código o con poco código) o TensorFlow.js (JavaScript) facilitan el entrenamiento y la evaluación de modelos predictivos sin preocuparse por las matemáticas subyacentes.
En nuestro ejemplo de deserción, alimentamos el conjunto de entrenamiento limpio en un algoritmo de clasificación supervisado, como la regresión logística o una red neuronal. Prueba varias opciones para determinar cuál funciona mejor para tus datos.
Tu modelo aprende qué patrones de comportamiento se correlacionan con la deserción. Al final, puede asignar una puntuación de probabilidad a cada usuario. Por ejemplo, existe un riesgo del 72% de que el usuario X cancele su suscripción el próximo mes.
Después de cada iteración de entrenamiento, evalúa el modelo resultante con el conjunto de validación. El rendimiento de un modelo se puede mejorar ajustando los hiperparámetros, pero también realizando mejoras específicas en tu conjunto de datos.
Evalúa el modelo
Las etiquetas de tu conjunto de datos proporcionan la verdad fundamental con la que puedes comparar los resultados del modelo. Las métricas clave que debes hacer un seguimiento son las siguientes:
- Precisión: De todos los usuarios marcados como "inactivos", ¿cuántos realmente lo están?
- Recuperación: De todos los usuarios que desertaron, ¿a cuántos detectó el modelo?
- Puntuación F1: Es un solo número que equilibra la precisión y la recuperación, y es útil cuando deseas una medida general de la exactitud sin optimizar demasiado una a expensas de la otra.
Demasiados falsos positivos generan un desperdicio de los esfuerzos de retención, mientras que demasiados falsos negativos provocan la pérdida de clientes. La compensación adecuada depende de las prioridades de tu empresa. Por ejemplo, es posible que tu empresa prefiera lidiar con un par de falsas alarmas si eso aumenta las probabilidades de captar a más usuarios antes de que se vayan.
Implementa y mantén el modelo
Una vez validado, puedes implementar el modelo con una API o como un servicio ligero del cliente integrado en tu panel de estadísticas. Cada día, puede calificar a los usuarios y actualizar una visualización del riesgo de abandono, lo que permite que tu equipo priorice la comunicación. Para mantener su precisión y confiabilidad, adopta estas lecciones de los equipos de operaciones de aprendizaje automático (MLOps):
- Supervisa la desviación de los datos: Detecta cuándo cambia el comportamiento del usuario y tus datos de entrenamiento ya no representan la realidad.
- Por ejemplo, después de lanzar un rediseño importante de la IU, los usuarios interactúan con las funciones de manera diferente, lo que hace que las predicciones de deserción sean menos precisas.
- Aprende de los errores: Identifica patrones comunes detrás de las predicciones incorrectas y agrega ejemplos específicos para mejorar el próximo ciclo de entrenamiento.
- Por ejemplo, el modelo suele marcar a los usuarios avanzados como riesgos de abandono porque abren muchos tickets de asistencia. Después de la revisión, agrega funciones nuevas que distinguen la solución de problemas de la falta de participación.
- Vuelve a entrenar el modelo con regularidad: Incluso si el rendimiento parece estable, actualiza el modelo periódicamente para tener en cuenta los patrones estacionales, las actualizaciones de productos o los cambios de precios.
- Por ejemplo, puedes volver a entrenar el modelo después de introducir planes anuales, ya que la estructura de precios cambia el comportamiento de los usuarios antes de la renovación.
Este ciclo de vida es la columna vertebral de la IA predictiva. Con herramientas como MLflow y Weights & Biases, puedes ejecutar este proceso sin necesidad de ser experto en AA.
Errores y mitigaciones comunes
Si bien se producirán errores ocasionales, puedes protegerte contra las causas raíz comunes que pueden socavar el rendimiento y la confianza del usuario:
- Datos de baja calidad: Si tus datos de entrada son ruidosos o están incompletos, tus predicciones también lo estarán. Para mitigar este problema, visualiza y valida tus datos antes del entrenamiento. Asegúrate de tener los indicadores de aprendizaje necesarios y controla los valores faltantes. Supervisa la calidad de los datos en producción.
Sobreajuste: El modelo funciona muy bien con los datos de entrenamiento, pero falla en casos nuevos. Para mitigar este problema, usa la validación cruzada, la regularización y los conjuntos de datos de exclusión. Esto ayuda a que tu modelo se generalice más allá de los ejemplos de entrenamiento.
Desviación de los datos: El comportamiento y los entornos de los usuarios cambian, pero tu modelo no. Para mitigar el problema, programa el reentrenamiento y agrega la supervisión para detectar cuándo comienza a disminuir la precisión.
Métricas deficientes: La precisión general no siempre refleja las prioridades de tus usuarios. Por ejemplo, a veces, el "costo" de un error específico es más importante. En la detección de fraudes, no detectar un caso fraudulento (falso negativo) es mucho peor que marcar uno inocente (falso positivo). Para mitigar el problema, alinea las métricas con los objetivos del mundo real para la detección de fraudes.
La mayoría de estos problemas no son fatales. Lanza tu sistema de forma gradual y aborda los problemas a medida que surjan.
La clave de este enfoque flexible y eficiente es la observabilidad. Crea versiones de tus modelos, registra las características de exactitud y las herramientas que se usaron para crear el modelo, haz un seguimiento del rendimiento a lo largo del tiempo y mantén activa la supervisión. Cuando algo se desvíe o se rompa, podrás detectar y solucionar el problema antes de que los usuarios lo noten.
Tus conclusiones
La IA predictiva convierte tus datos existentes en previsión, ya que revela lo que es probable que suceda a continuación y dónde debes actuar. Es la forma más concreta y medible de la IA. Enfócate en problemas bien definidos que se puedan expresar en datos, sigue iterando a medida que evoluciona tu producto y supervisa el rendimiento con el tiempo.
En el próximo módulo, aprenderás sobre la IA generativa, que te ayuda a crear algo nuevo a partir de los datos disponibles.
Recursos
Si te interesa comprender las matemáticas detrás de la IA predictiva, te recomendamos que consultes estos recursos:
- Cursos intensivos de aprendizaje automático sobre clasificación, regresión lineal y regresión logística.
- La autora del curso, Janna Lipenkova, escribió más sobre el tema de la IA predictiva en el capítulo 4 de El arte del desarrollo de productos con IA: cómo generar valor empresarial.
- Artificial Intelligence: A Modern Approach, de Stuart Jonathan Russell y Peter Norvig Este libro se publicó inicialmente en 1995 y su edición más reciente se publicó en 2021. Se suele enseñar en los programas de ingeniería de IA.
- Pattern Recognition and Machine Learning de Christopher M. Bishop, por su enfoque académico y altamente integral del aprendizaje de la IA predictiva.
Verifica tus conocimientos
¿Cuál es la función principal de la IA predictiva?
¿Qué tarea implica agrupar elementos en categorías predefinidas según patrones?
En el "bucle de IA predictiva", ¿por qué deberías dividir tu conjunto de datos en conjuntos de entrenamiento, validación y prueba?
¿Qué métrica equilibra la precisión y la recuperación para proporcionar una medida general de la exactitud?
¿Qué es la desviación de datos y cómo se debe mitigar?