
Sebelum membangun dengan AI, Anda harus memilih platform tempat AI dihosting. Pilihan Anda memengaruhi kecepatan, biaya, skalabilitas, dan kredibilitas sistem AI Anda. Anda dapat memilih antara:
- AI sisi klien: Berjalan langsung di browser. Artinya, data dapat tetap bersifat pribadi, di perangkat pengguna, dan tidak ada latensi jaringan. Namun, agar dapat berfungsi dengan baik, AI sisi klien memerlukan kasus penggunaan yang sangat spesifik dan terdefinisi dengan baik.
- AI sisi server: Berjalan di cloud. Model ini sangat mumpuni dan dapat diskalakan, tetapi lebih mahal dalam hal latensi dan biaya.
Setiap opsi memiliki konsekuensi, dan penyiapan yang tepat bergantung pada kasus penggunaan, keterampilan tim, dan sumber daya Anda. Misalnya, Anda dapat menawarkan alat ringkasan yang berjalan secara lokal sehingga pengguna dapat mengajukan pertanyaan pribadi tanpa perlu mengelola informasi identitas pribadi (PII). Namun, agen dukungan pelanggan dapat memberikan jawaban yang lebih berguna dengan menggunakan model berbasis cloud yang memiliki akses ke database besar berisi resource.
Dalam modul ini, Anda akan mempelajari cara:
- Bandingkan kelebihan dan kekurangan AI sisi klien dan sisi server.
- Sesuaikan platform Anda dengan kasus penggunaan dan kemampuan tim Anda.
- Merancang sistem hybrid, yang menawarkan AI di klien dan server, untuk berkembang bersama produk Anda.
Meninjau opsi
Untuk deployment, pertimbangkan platform AI di sepanjang dua sumbu utama. Anda dapat memilih:
- Tempat model berjalan: Apakah berjalan di sisi klien atau sisi server?
- Kemampuan penyesuaian: Seberapa besar kontrol yang Anda miliki atas pengetahuan dan kemampuan model? Jika Anda dapat mengontrol model, yang berarti Anda dapat mengubah bobot model, Anda dapat menyesuaikan perilakunya untuk memenuhi persyaratan spesifik Anda.
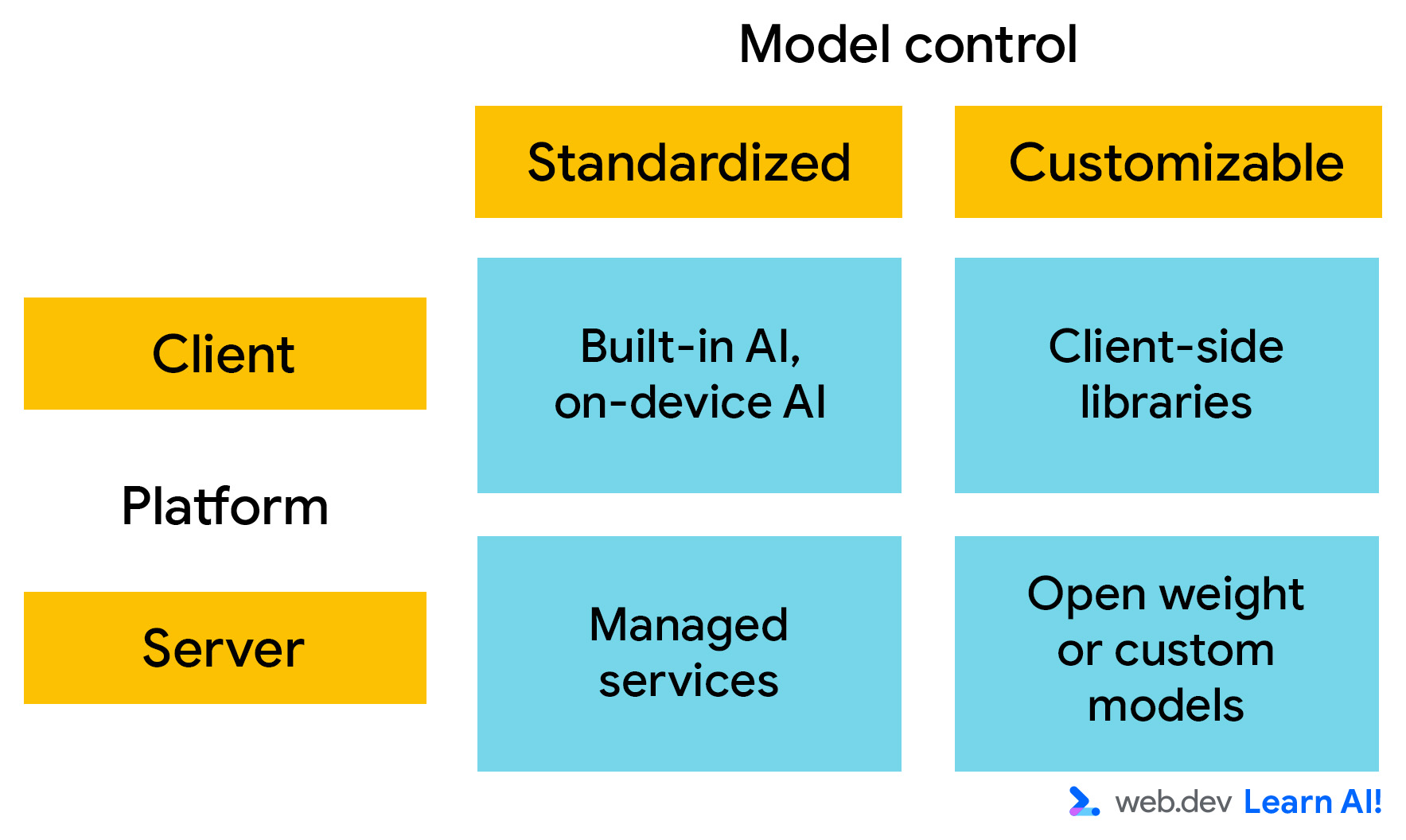
AI sisi klien
AI sisi klien berjalan di browser, dan komputasi dilakukan secara lokal di perangkat pengguna. Anda tidak perlu menyediakan komputasi waktu inferensi, dan data tetap berada di perangkat pengguna. Hal ini menjadikannya cepat, pribadi, dan cocok untuk pengalaman interaktif yang ringan.
Namun, model sisi klien biasanya cukup kecil, yang dapat membatasi kemampuan dan performanya. Model ini paling cocok untuk tugas yang sangat terspesialisasi, seperti deteksi toksisitas atau analisis sentimen. Biasanya, tugas ini adalah tugas AI prediktif dengan ruang output terbatas.
Ada dua opsi utama:
- AI bawaan: Browser, seperti Google Chrome dan Microsoft Edge, mengintegrasikan model AI. API ini dapat diakses melalui panggilan JavaScript, tanpa memerlukan penyiapan atau hosting. Setelah didownload, model dapat dipanggil oleh semua situs yang menggunakannya.
- Model kustom: Anda dapat menggunakan library sisi klien, seperti Transformers.js dan MediaPipe, untuk mengintegrasikan model ke dalam aplikasi Anda. Artinya, Anda dapat mengontrol bobot model. Namun, itu juga berarti setiap pengguna situs Anda harus mendownload model kustom Anda. Bahkan model AI terkecil pun berukuran besar dalam konteks situs.
AI sisi server
Dengan AI sisi server, aplikasi web Anda memanggil API untuk mengirim input ke model AI dan menerima outputnya. Penyiapan ini mendukung model yang lebih besar dan lebih kompleks serta tidak bergantung pada hardware pengguna.
Dua kategori untuk AI sisi server adalah:
- Layanan terkelola: Model ini dihosting di pusat data oleh pihak ketiga, seperti Gemini 3 dan GPT-5. Pemilik model menyediakan API untuk mengaksesnya. Artinya, Anda dapat menggunakan model canggih dengan penyiapan minimal. Model ini ideal untuk pembuatan prototipe cepat, percakapan terbuka, dan penalaran serbaguna. Namun, penskalaan pada layanan terkelola bisa mahal.
- Model yang dihosting sendiri: Anda dapat men-deploy model dengan bobot terbuka, seperti Gemma atau Llama, di infrastruktur Anda sendiri atau di container terkelola, seperti Vertex AI atau Hugging Face Inference. Dengan pendekatan ini, Anda dapat memanfaatkan prapelatihan yang dilakukan oleh pembuat model, tetapi Anda tetap memiliki kontrol atas model, data penyesuaian, dan performa.
Memilih platform awal
Tinjau karakteristik arsitektur platform AI dan analisis trade-off untuk memutuskan penyiapan awal Anda.
Menentukan persyaratan arsitektur Anda
Dengan setiap keputusan, Anda harus membuat kompromi. Lihat karakteristik utama yang menentukan biaya dan nilai platform AI Anda:
- Kualitas model: Seberapa baik performa model di berbagai pengguna dan tugas, tanpa penyesuaian. Sering kali, hal ini berkorelasi dengan ukuran model.
- Kemampuan penyesuaian: Sejauh mana Anda dapat menyetel secara halus, mengubah, atau mengontrol perilaku dan arsitektur model.
- Akurasi: Kualitas dan keandalan keseluruhan prediksi atau generasi model.
- Privasi: Tingkat data pengguna tetap lokal dan di bawah kontrol pengguna.
- Biaya tetap: Biaya berulang yang diperlukan untuk mengoperasikan sistem AI terlepas dari penggunaan, termasuk penyediaan dan pemeliharaan infrastruktur.
- Biaya per permintaan: Biaya tambahan untuk setiap permintaan yang masuk.
- Kompatibilitas: Seberapa luas pendekatan ini berfungsi di berbagai browser, perangkat, dan lingkungan tanpa logika penggantian.
- Kemudahan pengguna: Apakah pengguna perlu melakukan langkah-langkah tambahan untuk menggunakan sistem AI, seperti mendownload model.
- Kemudahan developer: Seberapa cepat dan mudah sebagian besar developer dapat men-deploy, mengintegrasikan, dan memelihara model, tanpa keahlian AI khusus.
Tabel berikut memberikan contoh perkiraan seberapa baik performa setiap platform untuk setiap kriteria, dengan 1 adalah yang terendah dan 5 adalah yang tertinggi.
| Kriteria | Klien | Server | ||
| AI bawaan atau di perangkat | Model kustom | Layanan terkelola | Model yang dihosting sendiri | |
| Daya model |
Mengapa 2 bintang untuk daya model?AI bawaan dan di perangkat menggunakan model browser kecil yang sudah dimuat sebelumnya dan dioptimalkan untuk fitur sempit dan khusus tugas, bukan percakapan atau penalaran terbuka. |
Mengapa 3 bintang untuk kemampuan model?Library sisi klien kustom menawarkan fleksibilitas lebih besar daripada AI bawaan, tetapi Anda masih dibatasi oleh ukuran download, batas memori, dan hardware pengguna. |
Mengapa daya model diberi 4 bintang?Dengan layanan terkelola dan hosting mandiri, Anda memiliki akses ke model canggih berukuran besar yang mampu melakukan penalaran kompleks, penanganan konteks panjang, dan cakupan tugas yang luas. |
|
| Kemampuan penyesuaian |
Mengapa bintang 1 untuk kemampuan penyesuaian?Model bawaan tidak mengizinkan akses ke bobot model atau data pelatihan. Cara utama untuk menyesuaikan perilakunya adalah melalui rekayasa perintah |
Mengapa 5 bintang untuk kemampuan penyesuaian?Opsi ini memberi Anda kontrol atas pemilihan dan bobot model. Banyak library sisi klien juga memungkinkan penyesuaian dan pelatihan model. |
Mengapa bintang 1 untuk kemampuan penyesuaian?Layanan terkelola mengekspos model yang canggih, tetapi menawarkan kontrol minimal atas perilaku internalnya. Penyesuaian biasanya terbatas pada perintah dan konteks input. |
Mengapa 5 bintang untuk Kemampuan Penyesuaian?Model yang dihosting sendiri memberikan kontrol penuh atas bobot model, data pelatihan, penyesuaian, dan konfigurasi deployment. |
| Akurasi |
Mengapa akurasi diberi 2 bintang?Akurasi dalam model bawaan sudah cukup untuk tugas yang memiliki cakupan baik, tetapi ukuran model dan generalisasi yang terbatas mengurangi keandalan untuk input yang kompleks atau bernuansa. |
Mengapa akurasi 3 bintang?Akurasi model sisi klien kustom dapat ditingkatkan dalam proses pemilihan model. Namun, hal ini tetap dibatasi oleh ukuran model, kuantisasi, dan variabilitas hardware klien. |
Mengapa akurasi diberi 5 bintang?Layanan terkelola biasanya menawarkan akurasi yang relatif tinggi, yang diuntungkan dari model besar, data pelatihan yang ekstensif, dan peningkatan berkelanjutan dari penyedia. |
Mengapa akurasi 4 bintang?Akurasi bisa tinggi, tetapi bergantung pada model yang dipilih dan upaya penyesuaian. Performa mungkin tertinggal dari layanan terkelola. |
| Latensi jaringan |
Mengapa latensi jaringan diberi 5 bintang?Pemrosesan dilakukan langsung di perangkat pengguna. |
Mengapa latensi jaringan diberi 2 bintang?Ada perjalanan pulang pergi ke server. |
||
| Privasi |
Mengapa 5 bintang untuk privasi?Data pengguna harus tetap berada di perangkat secara default, sehingga meminimalkan eksposur data dan menyederhanakan kepatuhan privasi. |
Mengapa 2 bintang untuk privasi?Input pengguna harus dikirim ke server eksternal, sehingga meningkatkan eksposur data dan persyaratan kepatuhan. Namun, ada solusi khusus untuk memitigasi masalah privasi, seperti Private AI Compute. |
Mengapa 3 bintang untuk privasi?Data tetap berada di bawah kontrol organisasi Anda, tetapi tetap keluar dari perangkat pengguna dan memerlukan penanganan yang aman serta langkah-langkah kepatuhan. |
|
| Biaya tetap |
Mengapa 5 bintang untuk biaya tetap?Model berjalan di perangkat pengguna yang sudah ada, sehingga tidak ada biaya infrastruktur tambahan. |
Mengapa 5 bintang untuk biaya tetap?Sebagian besar API mengenakan biaya berdasarkan penggunaan, sehingga tidak ada biaya tetap. |
Mengapa 2 bintang untuk biaya tetap?Biaya tetap mencakup infrastruktur, pemeliharaan, dan overhead operasional. |
|
| Biaya per permintaan |
Mengapa 5 bintang untuk biaya per permintaan?Tidak ada biaya per permintaan, karena inferensi berjalan di perangkat pengguna. |
Mengapa 2 bintang untuk biaya per permintaan?Layanan terkelola cenderung memiliki harga per permintaan. Biaya penskalaan dapat menjadi signifikan, terutama pada volume traffic yang tinggi. |
Mengapa 3 bintang untuk biaya per permintaan?Tidak ada biaya langsung per permintaan; biaya efektif per permintaan bergantung pada pemanfaatan infrastruktur. |
|
| Kompatibilitas |
Mengapa 2 bintang untuk kompatibilitas?Ketersediaan bervariasi menurut browser dan perangkat, sehingga memerlukan penggantian untuk lingkungan yang tidak didukung. |
Mengapa diberi 1 bintang untuk kompatibilitas?Kompatibilitas bergantung pada kemampuan hardware dan dukungan runtime, sehingga membatasi jangkauan di seluruh perangkat. |
Mengapa 5 bintang untuk kompatibilitas?Platform sisi server kompatibel secara luas untuk semua pengguna, karena inferensi terjadi di sisi server dan klien hanya menggunakan API. |
|
| Kenyamanan pengguna |
Mengapa 3 bintang untuk kemudahan pengguna?Umumnya lancar setelah tersedia, tetapi AI bawaan memerlukan download model awal dan dukungan browser. |
Mengapa 2 bintang untuk kemudahan pengguna?Pengguna mungkin mengalami penundaan karena download atau hardware yang tidak didukung. |
Mengapa 4 bintang untuk kemudahan pengguna?Langsung berfungsi tanpa memerlukan download atau persyaratan perangkat, sehingga memberikan pengalaman pengguna yang lancar. Namun, mungkin ada jeda jika koneksi jaringan lemah. |
|
| Kemudahan developer |
Mengapa 5 bintang untuk kemudahan developer?AI bawaan memerlukan penyiapan minimal, tanpa infrastruktur, dan sedikit keahlian AI, sehingga mudah diintegrasikan dan dikelola. |
Mengapa 2 bintang untuk kemudahan developer?Memerlukan pengelolaan model, runtime, pengoptimalan performa, dan kompatibilitas di seluruh perangkat. |
Mengapa 4 bintang untuk kemudahan developer?Layanan terkelola menyederhanakan deployment dan penskalaan. Namun, model ini tetap memerlukan integrasi API, pengelolaan biaya, dan rekayasa perintah. |
Mengapa 1 bintang untuk kemudahan developer?Deployment sisi server kustom memerlukan keahlian yang signifikan dalam infrastruktur, pengelolaan model, pemantauan, dan pengoptimalan. |
| Upaya pemeliharaan |
Mengapa 4 bintang untuk upaya pemeliharaan?Browser menangani update dan pengoptimalan model, tetapi developer harus beradaptasi dengan perubahan ketersediaan. |
Mengapa 2 bintang untuk upaya pemeliharaan?Memerlukan update berkelanjutan untuk model, penyesuaian performa, dan kompatibilitas seiring berkembangnya browser dan perangkat. |
Mengapa upaya pemeliharaan diberi 5 bintang?Pemeliharaan ditangani oleh penyedia. |
Mengapa 2 bintang untuk upaya pemeliharaan?Memerlukan pemeliharaan berkelanjutan, termasuk update model, pengelolaan infrastruktur, penskalaan, dan keamanan. |
Menganalisis konsekuensi
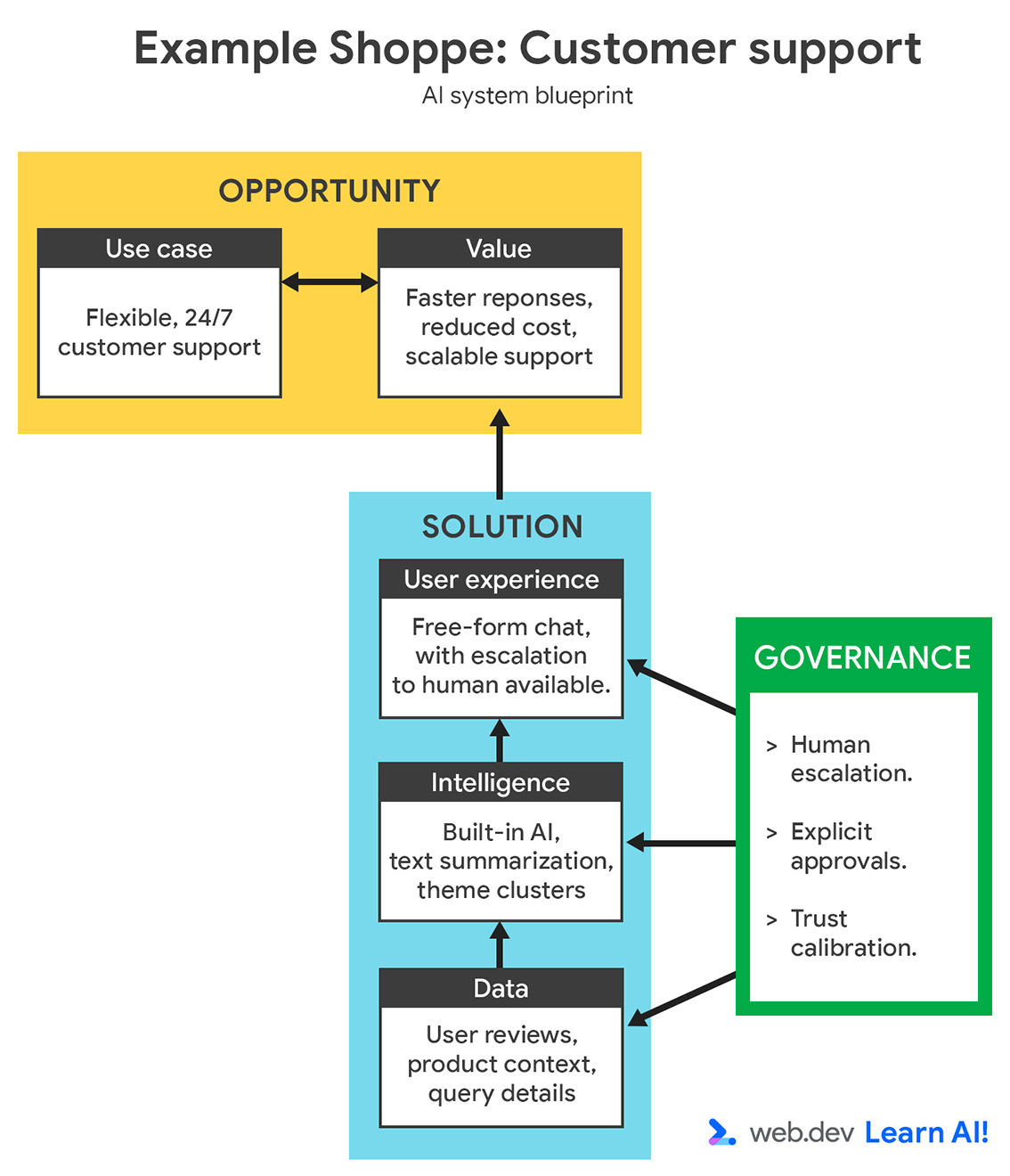
Untuk menggambarkan proses pengambilan keputusan, kita akan menambahkan fitur lain ke Example Shoppe, sebuah platform e-commerce berukuran sedang. Anda tertarik untuk menghemat biaya layanan pelanggan di luar jam kerja, jadi Anda memutuskan untuk membuat asisten berteknologi AI untuk menjawab pertanyaan pengguna tentang pesanan, pengembalian, dan produk.
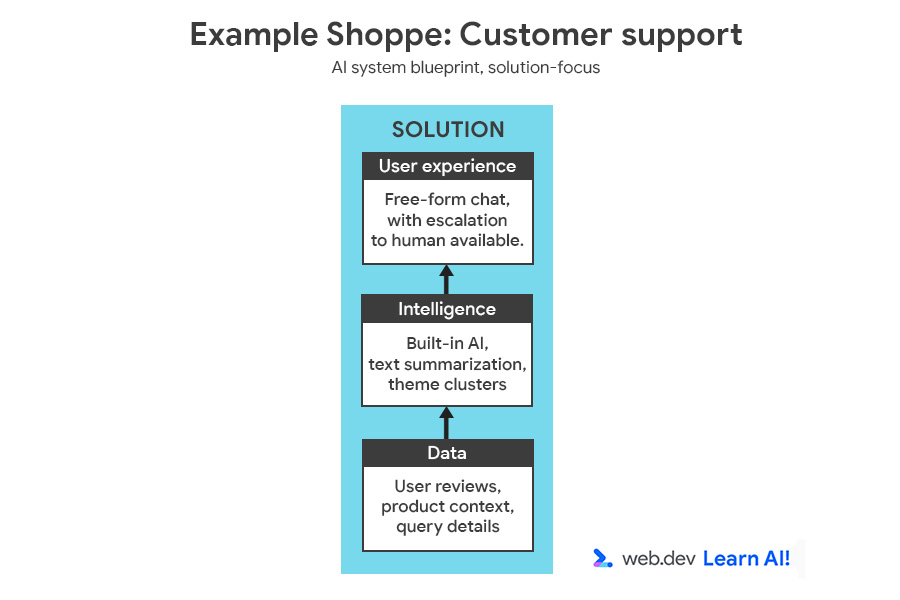
Anda dapat meninjau cetak biru sistem AI lengkap, yang menampilkan peluang dan solusi.
{kind=link}
Analisis skenario menggunakan dua sudut pandang: persyaratan kasus penggunaan dan batasan bisnis atau tim.
| Persyaratan | Analisis | Kriteria | Implikasi |
| Akurasi dan fleksibilitas tinggi | Pengguna mengajukan berbagai pertanyaan kompleks tentang pesanan, produk, dan pengembalian. | Performa dan akurasi model | Memerlukan model bahasa besar (LLM). |
| Kekhususan data | Chatbot ini harus dapat menjawab pertanyaan khusus tentang data, produk, dan kebijakan perusahaan. | Kemampuan Penyesuaian | Memerlukan penyerapan data, seperti RAG, tetapi tidak memerlukan penyesuaian model. |
| Persyaratan | Analisis | Kriteria | Implikasi |
| Basis pengguna | Ratusan ribu pengguna. | Skalabilitas, kompatibilitas | Memerlukan arsitektur yang menangani traffic tinggi dan andal. |
| Fokus pasca-peluncuran | Tim akan pindah ke project lain setelah peluncuran versi 1. | Upaya pemeliharaan | Memerlukan solusi dengan pemeliharaan berkelanjutan yang minimal. |
| Keahlian tim | Developer web yang andal, dengan keahlian AI/ML terbatas | Kemudahan developer | Solusi harus mudah di-deploy dan diintegrasikan tanpa memerlukan keterampilan AI khusus. |
Setelah memprioritaskan kriteria, Anda dapat melihat tabel estimasi kompromi untuk menentukan platform yang sesuai dengan kriteria prioritas tertinggi Anda:
Dari perincian ini, jelas bahwa Anda harus menggunakan AI sisi server, dan mungkin layanan terkelola. Hal ini menawarkan model serbaguna untuk pertanyaan pelanggan yang kompleks. Hal ini meminimalkan upaya pemeliharaan dan pengembangan dengan memindahkan infrastruktur, kualitas model, dan waktu aktif ke penyedia.
Meskipun penyesuaian terbatas, hal ini merupakan pertukaran yang berharga bagi tim pengembangan web dengan pengalaman rekayasa model yang terbatas.
Penyiapan retrieval-augmented generation (RAG) dapat membantu Anda memberikan konteks yang relevan kepada model pada waktu inferensi.
AI Hybrid
Sistem AI yang matang jarang berjalan di satu platform atau dengan satu model. Sebaliknya, mereka mendistribusikan workload AI untuk mengoptimalkan trade-off.
Menemukan peluang untuk AI hybrid
Setelah meluncurkan, Anda harus menyempurnakan persyaratan berdasarkan data dan masukan dari dunia nyata. Dalam contoh kita, Example Shoppe, Anda menunggu beberapa bulan untuk menganalisis hasilnya dan menemukan hal berikut:
- Sekitar 80% permintaan bersifat berulang ("Di mana pesanan saya?", "Bagaimana cara mengembalikan barang ini?"). Mengirim permintaan ini ke layanan terkelola akan menimbulkan banyak overhead dan biaya.
- Hanya 20% permintaan yang memerlukan penalaran yang lebih mendalam dan percakapan interaktif yang jawabannya tidak pasti.
Model lokal ringan dapat mengklasifikasikan input pengguna dan menjawab kueri rutin, seperti, "Apa kebijakan pengembalian Anda?" Anda dapat merutekan pertanyaan yang kompleks, jarang, atau ambigu ke model sisi server.
Dengan menerapkan AI sisi server dan sisi klien, Anda dapat mengurangi biaya dan latensi, sekaligus mempertahankan akses ke penalaran yang canggih jika diperlukan.
Mendistribusikan workload
Untuk membangun sistem hybrid ini untuk Example Shoppe, Anda harus memulai dengan menentukan sistem default. Dalam hal ini, sebaiknya mulai dari sisi klien. Aplikasi harus merutekan ke AI sisi server dalam dua kasus:
- Penggantian berbasis kompatibilitas: Jika perangkat atau browser pengguna tidak dapat menangani permintaan, permintaan tersebut harus kembali ke server
- Eskalasi berbasis kemampuan: Jika permintaan terlalu rumit atau tidak terbatas untuk model sisi klien, sebagaimana ditentukan oleh kriteria yang telah ditentukan sebelumnya, permintaan tersebut harus diekskalasikan ke model sisi server yang lebih besar. Anda dapat menggunakan model untuk mengklasifikasikan permintaan sebagai umum, sehingga Anda melakukan tugas di sisi klien, atau tidak umum, dan Anda mengirimkan permintaan ke sistem sisi server. Misalnya, jika model sisi klien menentukan bahwa pertanyaan terkait dengan masalah yang tidak umum, seperti mendapatkan pengembalian dana dalam mata uang yang berbeda.
Fleksibilitas menimbulkan lebih banyak kompleksitas
Mendistribusikan workload di antara dua platform membuat Anda lebih fleksibel, tetapi juga menambah kompleksitas:
- Orkestrasi: Dua lingkungan eksekusi berarti lebih banyak komponen yang bergerak. Anda membutuhkan logika untuk pemilihan rute, percobaan ulang, dan penggantian.
- Pembuatan versi: Jika Anda menggunakan model yang sama di seluruh platform, model tersebut harus tetap kompatibel di kedua lingkungan.
- Rekayasa perintah dan rekayasa konteks: Jika Anda menggunakan model yang berbeda di setiap platform, Anda harus melakukan rekayasa perintah untuk setiap platform.
- Pemantauan: Log dan metrik dibagi dan memerlukan upaya penyatuan ekstra.
- Keamanan: Anda mempertahankan dua area serangan. Endpoint lokal dan cloud harus diamankan.
Ini adalah pertimbangan lain yang perlu Anda pikirkan. Jika Anda memiliki tim kecil atau sedang membangun fitur yang tidak penting, Anda mungkin tidak ingin menambahkan kompleksitas ini.
Kesimpulan Anda
Antisipasi perubahan pilihan platform Anda. Mulailah dari kasus penggunaan, sesuaikan dengan pengalaman dan sumber daya tim Anda, dan lakukan iterasi seiring dengan pertumbuhan produk dan kematangan AI Anda. Tugas Anda adalah menemukan kombinasi yang tepat antara kecepatan, privasi, dan kontrol bagi pengguna Anda, lalu membangun dengan fleksibilitas tertentu. Dengan begitu, Anda dapat beradaptasi dengan persyaratan yang berubah dan mendapatkan manfaat dari update platform dan model di masa mendatang.
Resource
- Karena pilihan platform dan model saling terkait, baca selengkapnya tentang pemilihan model.
- Baca cara melampaui cloud dengan AI sisi klien dan hybrid
Uji pemahaman Anda
Apa dua pertimbangan utama saat memilih platform AI untuk aplikasi Anda?
Kapan Layanan yang dikelola di sisi server, seperti Gemini Pro, menjadi pilihan terbaik untuk platform Anda?
Apa manfaat utama penerapan sistem AI hibrida?